运筹系列7:大规模线性规划的Benders/DW分解
1. 行生成算法行生成就是指的不断添加约束的算法。因为在求解矩阵中,一个约束条件对应一行,因此添加约束条件的方法自然叫做行生成算法。相对应的,添加变量的方法就叫做列生成算法。这一节先看行生成算法,用在求解变量不多,但是约束条件特别多的情况下。2. Benders分解Benders分解(Benders Decomposition,BD)的基本思路是:使用子问题(primal ...
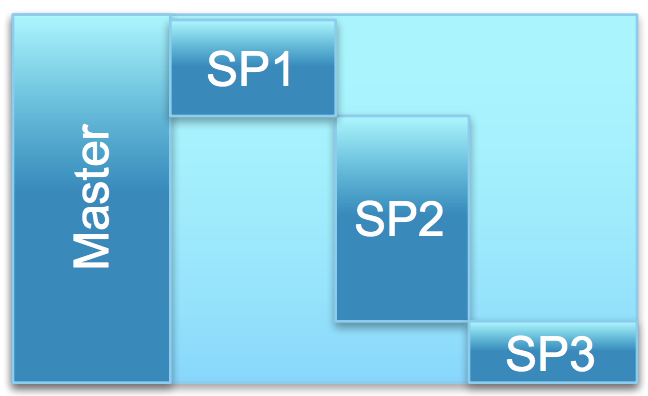
Benders/DW分解算法常常用于具有分块结构的大规模线性规划问题中。
因为在求解矩阵中,一个约束条件对应一行,因此添加约束条件的方法自然叫做行生成算法(Benders分解)。相对应的,添加变量的方法就叫做列生成算法(DW分解)。
1. Benders分解
1.1 问题描述
Benders分解算法,常常用于有一部分约束条件有明显的”对角线分块“结构,可以拆下来求解的情形:

Benders求解的基本思路是:使用子问题(primal problem)来寻找合适的约束不断添加到松弛主问题(relaxed master problem)中,具体可以参考论文,这里做一下简单的概述:
假设Benders分解问题的标准型为:
max
w
b
+
v
d
\max wb+vd
maxwb+vd
s.t.
w
A
+
v
B
≤
c
wA+vB ≤ c
wA+vB≤c
w
,
v
≥
0
w,v\ge 0
w,v≥0,
w
w
w为主问题变量,对偶变量为子问题变量。在分块结构中,对偶问题也是分块的,变量可以拆分开来求解。
1.2 主问题
原问题等价于
max
w
≥
0
{
w
b
+
max
v
:
v
B
≤
c
−
w
A
,
v
≥
0
v
d
}
\max_{w\ge0}\{wb+\max_{v:vB\le c-wA,v\ge0}vd\}
maxw≥0{wb+maxv:vB≤c−wA,v≥0vd}
等价于
max
w
≥
0
{
w
b
+
min
x
:
B
x
≥
d
,
x
≥
0
(
c
−
w
A
)
x
}
\max_{w\ge 0}\{wb+\min_{x:Bx\ge d,x\ge 0}(c-wA)x\}
maxw≥0{wb+minx:Bx≥d,x≥0(c−wA)x}
内部的min问题是个线性规划问题,枚举可行域{ x : B x ≥ d , x ≥ 0 x : Bx\ge d,x\ge 0 x:Bx≥d,x≥0}的极点便可以求解了。我们逐步找新的极点作为约束添加进松弛主问题(RMP):
max
z
z
z
s.t.
z
≤
w
b
+
(
c
−
w
A
)
x
i
z\le wb+(c-wA)x_i
z≤wb+(c−wA)xi
w
≥
0
w\ge 0
w≥0
或者换一个理解方式:每次移动到新的极点时,必须是对原问题的目标函数有改进:
max
w
b
wb
wb
s.t.
(
c
−
w
A
)
x
i
≥
0
(c-wA)x_i\ge 0
(c−wA)xi≥0
w
≥
0
w\ge 0
w≥0
两者是等价的。
1.3 子问题
将求出来的
w
w
w带入下式(DSP)求解
x
x
x:
min
(
c
−
w
A
)
x
+
w
b
\min (c-wA)x+wb
min(c−wA)x+wb
s.t.
B
x
≥
d
Bx \ge d
Bx≥d
x
≥
0
x\ge 0
x≥0
求出来的
x
x
x是原问题的一个极点,将其添加到松弛主问题上继续求解。
在Benders分解中,松弛主问题和对偶子问题分别可以给出原问题的上界UB和下界LB,进行迭代直至LB = UB。
2. DW分解
2.1 问题描述
DW分解和Benders分解步骤非常相似,完全是对偶形式。具体可以参考这篇https://imada.sdu.dk/u/jbj/DM209/Notes-DW-CG.pdf
Benders分解的图转过来就是DW分解的情形:

Benders分解每次求出来的极点用于给主问题添加有效约束,而DW分解每次求出来的极点用于给主问题添加基变量。DW问题模型是:
min
c
x
\min cx
mincx
s.t.
A
x
≤
b
Ax \le b
Ax≤b(主问题约束,包含connecting constraints)
D
x
≤
d
Dx \le d
Dx≤d(包含independent constraints)
x
≥
0
x\ge 0
x≥0
2.2 主问题
回顾一下Benders的松弛主问题:
max
z
z
z
s.t.
z
−
(
b
−
A
x
i
)
w
≤
c
x
i
,
i
=
1...
m
z-(b-Ax_i)w\le cx_i, i=1...m
z−(b−Axi)w≤cxi,i=1...m
w
≥
0
w\ge 0
w≥0
求对偶即可得DW分解的松弛主问题:
min
c
Σ
x
i
u
i
\min c\Sigma x_iu_i
mincΣxiui
s.t.
Σ
u
i
=
1
\Sigma u_i=1
Σui=1
Σ
(
b
−
A
x
i
)
u
i
≥
0
\Sigma (b-Ax_i)u_i\ge 0
Σ(b−Axi)ui≥0
u
i
≥
0
u_i\ge0
ui≥0
2.3 子问题
构造定价子问题(pricing sub problem, PSP)求解新的极点 x x x,一般使用单纯形法的判别规则,令 u i = arg max i u u_i=\arg \max_i u ui=argmaxiu,然后求 min j ( B − 1 b ) i j \min_j (B^{-1}b)_{ij} minj(B−1b)ij,对应对应新的基变量 u j u_j uj,将其添加到松弛主问题上继续求解。注意单纯型法本身就是一种列生成的方法。
3. 例子
举一个例子:

前两个约束比较复杂,而后四个约束有明显的”对角线分块“结构,因此将前两个约束和后四个约束分开,转化为对偶问题用Benders分解求解,主问题为下式:

3.1 第1轮迭代
x
=
(
0
,
0
,
0
,
0
)
x=(0,0,0,0)
x=(0,0,0,0)是复杂问题(前两个约束)的一个可行解,求解主问题

得到
w
=
(
0
,
0
)
w=(0,0)
w=(0,0),
U
B
=
0
UB=0
UB=0,求解子问题:
min
−
2
x
1
−
x
2
−
x
3
+
x
4
\min -2x_1-x_2-x_3+x_4
min−2x1−x2−x3+x4
s.t.

分块求解(
x
1
,
x
2
x_1,x_2
x1,x2)和(
x
3
,
x
4
x_3,x_4
x3,x4),可以得到
x
=
(
2
,
1.5
,
3
,
0
)
x=(2,1.5,3,0)
x=(2,1.5,3,0),最优值为
L
B
=
−
8.5
LB=-8.5
LB=−8.5
3.2 第2轮迭代
使用新的
x
x
x添加一条约束,得到新的主问题:

得到
w
=
(
−
1.7
,
0
)
w=(-1.7,0)
w=(−1.7,0),最优值为
U
B
=
−
3.4
UB=-3.4
UB=−3.4,求解子问题
min
−
3.4
−
0.3
x
1
−
x
2
−
2.7
x
3
+
x
4
\min -3.4-0.3x_1-x_2-2.7x_3+x_4
min−3.4−0.3x1−x2−2.7x3+x4
s.t.
得到
x
=
(
0
,
2.5
,
0
,
0
)
x=(0,2.5,0,0)
x=(0,2.5,0,0),最优值为
L
B
=
−
5.9
LB=-5.9
LB=−5.9
3.3 第3轮迭代
使用新的
x
x
x添加一条约束,得到新的主问题:

得到
w
=
(
−
1.2
,
0
)
w=(-1.2,0)
w=(−1.2,0),最优值为
U
B
=
−
4.9
UB=-4.9
UB=−4.9,求解子问题
min
−
2.4
−
0.8
x
1
−
x
2
+
0.2
x
3
+
x
4
\min -2.4-0.8x_1-x_2+0.2x_3+x_4
min−2.4−0.8x1−x2+0.2x3+x4
s.t.
得到
x
=
(
2
,
1.5
,
0
,
0
)
x=(2,1.5,0,0)
x=(2,1.5,0,0),最优值为
L
B
=
−
5.5
LB=-5.5
LB=−5.5
不断迭代下去即可,直到LB=UB
3.4 参考代码(julia)
using JuMP,GLPK
c = [-2,-1,-1,1]
bm = [2,3] # 主问题变量
b = [2,5,2,6] # 子问题变量
Am = [[1,0,1,0],[1,1,0,2]]
A = [[1,0,0,0],[1,2,0,0],[0,0,-1,1],[0,0,2,1]]
# 松弛主问题为前两个变量,主问题给出max的上界
rmp = Model(GLPK.Optimizer)
@variable(rmp,w[1:length(bm)]<=0)
@objective(rmp, Max, sum(bm.*w))
optimize!(rmp)
w_val = JuMP.value.(w)
ub = objective_value(rmp)
# 子问题为消去w1和w2后的对偶问题,给出的是下界
m = Model(GLPK.Optimizer)
@variable(m,x[1:length(b)]>=0)
@objective(m, Min, ub+sum((c.-sum(w_val.*Am)).*x))
@constraint(m, cons[i = 1:length(b)], sum(A[i].*x) <= b[i])
optimize!(m)
x_val = JuMP.value.(x)
lb = objective_value(m)
@info lb,ub
# 迭代直至ub=lb
while ub>lb
# 固定子问题变量,更新主问题变量。
# 要求目标函数不变差,因此松弛主问题中添加一个新的约束条件
@constraint(rmp, sum(x_val.*(c.-sum(w.*Am)))>=0)
optimize!(rmp)
w_val = JuMP.value.(w)
ub = objective_value(rmp)
# 固定主问题变量,更新子问题变量。
@objective(m, Min, ub+sum((c.-sum(w_val.*Am)).*x))
optimize!(m)
x_val = JuMP.value.(x)
lb = objective_value(m)
@info lb,ub
end
@info x_val
输出结果如下:


开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 36
36 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)