深入理解内存管理:LRU、FIFO和CLOCK页面置换算法解析
本文还有配套的精品资源,点击获取简介:在操作系统中,页面置换算法对于高效管理虚拟内存至关重要,它们决定内存中的页面如何被替换以释放空间。本文将详细分析三种关键的页面置换算法:LRU(最近最少使用)、FIFO(先进先出)和CLOCK(时钟算法),探讨它们的工作原理、优势、劣势以及实现开销。通过分析工作负载,我们可以评估这些算法在不同情况下的表现,并为系统设计提供指导。...

简介:在操作系统中,页面置换算法对于高效管理虚拟内存至关重要,它们决定内存中的页面如何被替换以释放空间。本文将详细分析三种关键的页面置换算法:LRU(最近最少使用)、FIFO(先进先出)和CLOCK(时钟算法),探讨它们的工作原理、优势、劣势以及实现开销。通过分析工作负载,我们可以评估这些算法在不同情况下的表现,并为系统设计提供指导。 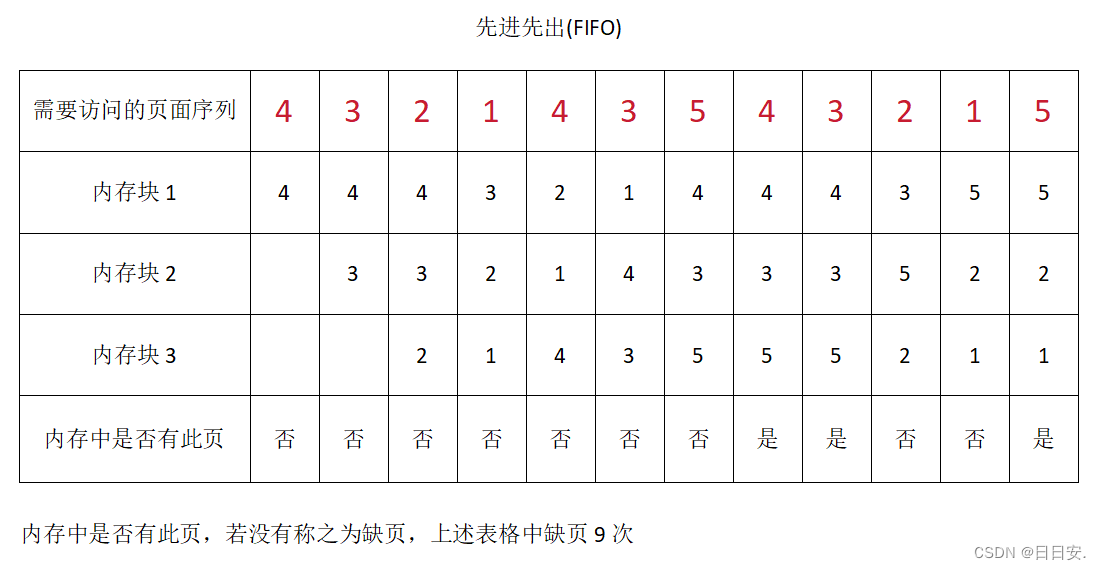
1. 页面置换算法概念与内存管理
1.1 页面置换算法的重要性
页面置换算法是操作系统中处理内存管理的核心技术之一。在计算机系统中,内存是有限的资源,当多个进程同时运行时,它们所请求的内存空间之和可能远远超出物理内存的实际容量。页面置换算法的使命是在内存资源紧张时,决定哪些内存页面可以被移出,以及如何高效地利用有限的内存资源。
1.2 内存管理基础
内存管理是操作系统设计中的重要组成部分,它负责有效地分配和回收内存空间,使得多个进程可以共享有限的物理内存。页面置换算法正是在内存管理过程中,为了解决内存不足的情况而应用的。内存管理还包括对内存空间的保护、内存地址映射、内存碎片整理等任务。
1.3 页面置换算法分类
页面置换算法有多种,常见的有先进先出(FIFO)、最近最少使用(LRU)、时钟(CLOCK)算法等。每种算法有其独特的工作原理和使用场景,它们在不同的工作负载和访问模式下表现各异,决定了它们的性能和适用性。
graph TD
A[内存管理] --> B[页面置换算法]
B --> C[FIFO]
B --> D[LRU]
B --> E[CLOCK]
在接下来的章节中,我们将逐一深入探讨这些页面置换算法的基本概念、工作原理和性能影响,以及它们在实际系统中的应用和优化。
2. LRU(最近最少使用)算法的工作原理及其性能影响
2.1 LRU算法的基本概念和原理
2.1.1 LRU算法的核心思想
LRU(Least Recently Used)算法,即最近最少使用算法,是页面置换算法的一种。其核心思想在于当内存空间不足时,系统会淘汰那些最近最少被使用的页面,以此释放内存空间供新的页面使用。这种算法的基础在于假设了一个前提:如果一个数据项在最近一段时间内未被访问到,那么在将来它被访问的可能性也很小。
LRU算法能够在一定程度上保证那些频繁被访问的页面能够保留在内存中,而那些不太被使用的页面则会被置换出去,这在很多情况下能够达到优化系统性能的效果。然而,由于“最少使用”的特性,若某一段时间内,所有页面都被频繁访问,此时LRU算法可能就无法发挥其应有的优势,性能影响也就不那么显著了。
2.1.2 LRU算法的实现机制
LRU算法的实现通常依赖于“最近使用”信息的记录。在计算机系统中,有多种方式可以实现这一功能,如:
- 链表法:使用双向链表,链表的两端分别是最近使用和最久未使用的页面。当某页面被访问时,将该页面移动到链表的头部。当需要进行页面置换时,选择链表尾部的页面进行置换。
- 栈法:使用栈结构,每当页面被访问时,将其从栈中移除,并压入栈顶,这样栈顶总是最近被访问的页面,栈底则是最久未访问的页面。
- 时间戳法:为每个页面维护一个时间戳,记录页面最后一次被访问的时间。当需要置换页面时,选择时间戳最小(即最久未访问)的页面。
虽然以上机制实现各有不同,但它们共同的基础逻辑是利用历史访问信息来决定未来置换的页面,从而使系统尽可能保持对高频访问页面的快速访问。
2.2 LRU算法的性能影响因素
2.2.1 页面访问模式对LRU性能的影响
页面访问模式决定了LRU算法是否能够有效工作。在大多数应用中,存在局部性原理,即在一定时间段内,程序倾向于访问一部分固定的数据集。局部性可以分为时间局部性和空间局部性。在这种情况下,LRU算法表现良好,因为它倾向于淘汰那些不会在短期内再次访问的页面。
然而,如果程序的行为不遵循局部性原理,即表现出所谓的“随机访问模式”,LRU算法的性能就会受到影响。在这种情况下,LRU算法无法有效地识别哪些页面是真正“最近最少使用”的,因此可能会错误地淘汰了那些即将被访问的页面,从而导致较高的页面置换频率和较低的命中率。
2.2.2 LRU算法在不同工作负载下的表现
工作负载的不同也会影响LRU算法的性能。在多任务操作系统中,如果多个程序同时运行,它们各自可能拥有不同的页面访问模式。这些程序的交互作用会影响LRU算法的表现。例如,如果多个进程访问相同的数据集合,那么内存访问就会出现竞争,从而降低LRU算法的页面置换效率。
此外,工作负载的大小也会影响LRU算法。在负载较轻的系统中,LRU算法相对容易保持较高的命中率,因为有更多的内存空间可以利用。相反,在负载较重的系统中,由于内存空间紧张,LRU算法需要频繁进行页面置换,性能会受到较大的影响。
为了更深入地了解LRU算法在不同工作负载下的表现,我们可以考虑以下几个因素:
- 系统中活跃页面的数量
- 页面置换的频率
- 页面访问的局部性特征
- 多任务环境中的上下文切换频率
下面通过一个实际的代码示例来演示LRU算法的基本实现:
class LRUCache:
def __init__(self, capacity: int):
self.cache = {}
self.capacity = capacity
self.keys = []
def get(self, key: int) -> int:
if key not in self.cache:
return -1
else:
self.keys.remove(key)
self.keys.append(key)
return self.cache[key]
def put(self, key: int, value: int) -> None:
if key in self.cache:
self.keys.remove(key)
elif len(self.cache) >= self.capacity:
oldest_key = self.keys.pop(0)
del self.cache[oldest_key]
self.cache[key] = value
self.keys.append(key)
代码逻辑分析:
-
__init__方法初始化一个字典cache用于存储键值对,一个列表keys用于记录访问顺序。 -
get方法用于获取一个键对应的值,如果键存在,则返回值,并更新访问顺序;如果键不存在,则返回-1。 -
put方法用于添加或更新一个键值对,如果键存在,则更新值,并更新键的访问顺序;如果键不存在,则根据当前容量情况置换一个旧的键值对,并添加新的键值对到缓存中。 - 在
put方法中,我们首先检查键是否已存在。如果存在,我们删除当前键并重新添加到keys列表尾部,因为键已被访问过。如果键不存在,我们需要检查当前缓存是否已满,如果满了,则移除列表头部的键(最久未使用),同时删除对应的键值对。然后,我们添加新键值对到缓存和keys列表中。
通过分析该算法的代码实现,我们可以看到LRU算法在维护和更新键的访问顺序时的逻辑和性能影响。例如,当需要在缓存中插入新的键值对时,我们需要先删除和更新数据结构,这涉及到 O(n) 的时间复杂度,其中 n 是列表 keys 的长度。在高负载下,这种操作的频繁执行会对系统性能产生影响。
3. FIFO(先进先出)算法的简单实现与Belady's异常
3.1 FIFO算法的基本原理和实现步骤
3.1.1 FIFO算法的定义和应用场景
FIFO(First-In, First-Out)算法是一种古老且直观的页面置换算法,其核心思想是最早进入内存的页面应该最先被置换出去。FIFO算法在概念上类似于在一条管道中存储页面,新页面从一端进入,当管道满了,就将最早进入的页面从另一端移除以腾出空间。
在计算机系统中,FIFO算法在操作系统内存管理中用于处理页面置换。因为FIFO算法的实现简单且不需要额外的信息(比如访问时间或访问频率),所以它在早期的系统中得到了广泛的应用。尽管在现代计算机系统中,由于其容易引发Belady's异常而不再作为主要的页面置换算法,但它在教学和理解页面置换问题时依旧是一个非常重要的基础模型。
3.1.2 FIFO算法的简单实现过程
FIFO算法的实现过程相对直接,具体步骤如下:
- 初始化一个队列Q,用于跟踪存储在内存中的页面的顺序。
- 当一个页面被请求时,如果页面已经在内存中,那么它移动到队列的末尾(表示最近访问过)。
- 如果页面不在内存中,检查队列Q:
- 如果队列没有满,将请求的页面添加到队列的末尾。
- 如果队列已满,则移除队列开头的页面(即最先进入的页面),然后将请求的页面添加到队列的末尾。
伪代码如下:
初始化空队列 Q
WHILE 页面请求发生 DO
IF 页面已在内存中 THEN
将该页面移至队列Q的末尾
ELSE
IF 队列Q未满 THEN
将请求页面添加到队列Q的末尾
ELSE
移除队列Q开头的页面(最早进入内存的页面)
将请求页面添加到队列Q的末尾
END IF
END IF
END WHILE
3.2 Belady's异常及其对FIFO算法的挑战
3.2.1 Belady's异常的现象和原因
尽管FIFO算法在概念上简单直观,但它却存在一种被称为Belady's异常的现象。Belady's异常指的是在某些情况下,增加可用的内存页框数量反而会导致更多的页面置换发生。理论上,更宽松的内存条件应该降低页面置换的频率,但是在FIFO算法下,却可能观察到相反的现象。
Belady's异常发生的原因和FIFO算法的工作原理有关。因为FIFO算法总是置换最早进入内存的页面,所以当一个新的页面请求到来时,不管这些页面在未来的访问概率如何,所有这些页面都可能被置换掉。由于访问模式的复杂性,这种替换并不总是合理的,尤其是在那些页面访问具有时间局部性的系统中。例如,一个被频繁访问的页面可能在 FIFO 队列中因为一些临时不活跃的页面而导致它被置换。
3.2.2 解决Belady's异常的策略探讨
由于Belady's异常的存在,FIFO算法在面对复杂的工作负载时可能不是最佳选择。研究者们提出了多种策略来尝试解决或缓解这一问题:
-
改进的FIFO算法 :一种简单的改进方式是引入一个启发式算法来决定是否应该置换最早进入的页面。比如,可以使用一个阈值来判断是否发生了Belady's异常,即如果内存页框数量增加而页面置换次数没有减少,就认为发生了异常。
-
使用其他页面置换算法 :由于Belady's异常是FIFO特有的,所以使用基于其他策略的算法(如LRU或CLOCK算法)可以避免这一问题。
-
混合策略 :结合多种算法,动态选择最适合当前访问模式的页面置换策略。例如,系统可以监测访问模式,并在发现频繁的Belady's异常时自动切换到更合适的算法。
下面的代码展示了一个简单的 FIFO 算法实现,以及如何在代码层面上检测和处理 Belady's 异常:
def fifo_page_replacement(page_sequence, num_frames):
from collections import deque
frames = deque() # 用于存储内存中页面的队列
page_faults = 0
belady_count = 0 # Belady's异常的计数器
for page in page_sequence:
# 如果页面不在队列中,发生页面缺失
if page not in frames:
page_faults += 1
frames.append(page) # 添加页面到队列的末尾
# 检查是否发生了 Belady's异常
if len(frames) > num_frames:
belady_count += 1
# 如果页面已在队列中,则移动到队列的末尾
else:
frames.remove(page)
frames.append(page)
# 检查是否发生了 Belady's异常
if belady_count > 0:
print("Belady's Anomaly Detected!")
return page_faults, belady_count
page_sequence = [1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5]
num_frames = 3
page_faults, belady_count = fifo_page_replacement(page_sequence, num_frames)
print(f"Page Faults: {page_faults}")
print(f"Belady's Anomaly Detected: {belady_count}")
在上述代码中,我们定义了一个函数 fifo_page_replacement 来模拟 FIFO 页面置换算法。我们还添加了一个计数器 belady_count 来检测 Belady's 异常的发生。如果在增加了内存页框的数量之后,页面缺失数(即页面置换数)反而增加,那么 Belady's 异常就被检测到了。
通过这种实现,我们可以观察到 FIFO 算法的性能以及 Belady's 异常的影响,并采取措施进行优化。
4. CLOCK(时钟)算法的折中方案和访问位维护
4.1 CLOCK算法的原理与特点
4.1.1 CLOCK算法的基本概念
CLOCK算法是一种页面置换算法,也被称为二次机会法,其核心思想是利用一个循环队列(时钟)来管理内存页面。每个页面都有一个相关联的“访问位”,用于指示该页面自上次检查后是否被访问过。当需要进行页面置换时,CLOCK算法会从当前位置开始扫描队列,并根据访问位来决定是否替换页面。
4.1.2 CLOCK算法的工作流程
当一个页面被访问时,它的访问位会被设置为1。算法开始工作时,从某个页面开始,按顺时针方向检查每个页面的访问位。如果访问位是1,则将该位清零,并继续扫描直到找到一个访问位为0的页面进行替换。这个过程一直持续,直到找到一个可以替换的页面。
4.2 CLOCK算法的实现细节
4.2.1 访问位的设置和维护机制
为了维护访问位,CLOCK算法会在内存的每个页面表项中添加一个访问位。每当页面被访问时,系统硬件会自动将对应的访问位置为1。软件负责周期性地清除所有页面的访问位,为下一轮页面置换准备。
4.2.2 时钟指针的旋转和页面替换策略
CLOCK算法维护一个循环队列和一个时钟指针。时钟指针指向当前检查的页面,其指向页面的访问位如果为0,则当前页面被替换。如果访问位为1,该页面获得第二次机会,访问位被重置为0,并且指针移动到下一个页面继续检查。如果一个页面在第一次扫描时其访问位为1且在第二次检查时被找到访问位仍然为0,则该页面被替换。
接下来是CLOCK算法的伪代码实现:
1. 初始化时钟指针clock_ptr指向队列头部
2. while (需要页面置换):
3. if (指针指向的页面访问位 == 0):
4. 替换该页面
5. 跳出循环
6. else:
7. 访问位置0
8. 时钟指针clock_ptr向下一个页面移动
在代码逻辑分析中,第3-5行处理未被访问的页面,一旦找到这样的页面即进行替换。第6-8行处理已经被访问的页面,通过清零访问位给予页面第二次机会。如果页面在第二次机会时仍被标记为未访问,则该页面成为替换目标。
下面是一个简化的表格,展示了页面状态和访问位的更新:
| 页面 | 访问位 | 结果 | |------|--------|------| | A | 1 | 访问位清0,页面获得二次机会 | | B | 0 | 页面被替换 | | C | 1 | 访问位清0,页面获得二次机会 | | D | 0 | 页面被替换 | | E | 1 | 访问位清0,页面获得二次机会 | | F | 0 | 页面被替换 |
根据上述逻辑和表格,我们可以了解CLOCK算法在处理页面置换时的动态变化。
5. 页面置换算法在不同工作负载下的性能评估
页面置换算法是操作系统内存管理的关键组成部分,不同的页面置换算法在不同的工作负载下展现出不同的性能特征。为了进行深入分析,本章节将对比各种页面置换算法的性能,并在实际案例的基础上进行性能评估。
5.1 各种页面置换算法的对比分析
在评估页面置换算法的性能时,有几个重要的指标需要考虑,包括算法实现的复杂度、页面置换的频率、算法的平均页面访问时间(Average Page Access Time)以及算法的命中率(Hit Ratio)。
5.1.1 算法性能评估的指标
-
算法实现的复杂度 :算法的复杂度决定了算法开发、调试和维护的难易程度。例如,FIFO算法由于其实现简单,复杂度较低,易于理解和实现;而LRU算法虽然性能优秀,但由于需要记录每个页面的使用历史,其复杂度较高,实现成本也相应增加。
-
页面置换频率 :页面置换频率反映了系统在一段时间内发生页面置换的次数。频率越低,说明算法能够更有效地利用有限的物理内存资源,对系统性能的负面影响越小。
-
平均页面访问时间 :此指标衡量了在一定时间范围内,算法平均每次访问页面所需的时间。此时间越短,表明算法在页面访问速度方面表现越好,对用户访问的响应时间也越快。
-
算法命中率 :命中率是指请求的页面已在内存中,无需从磁盘中读取的概率。命中率越高,说明算法有效减少页面缺失的情况,对性能的提升越显著。
5.1.2 不同工作负载对算法性能的影响
不同的工作负载对页面置换算法的性能影响显著。例如,在工作负载变化不大的情况下,FIFO算法的性能表现可能相对稳定;但是在工作负载剧烈变化,且内存访问模式呈现局部性时,LRU算法往往能够更好地适应,展现出更高的命中率。因此,在选择页面置换算法时,需要根据实际的工作负载特点来进行选择。
5.2 实际案例分析
为了更具体地了解页面置换算法在不同工作负载下的性能表现,我们可以通过模拟实验获取数据,然后进行结果分析。
5.2.1 模拟实验的数据结果分析
实验设计如下:
- 创建一个虚拟内存系统模拟环境;
- 使用不同的工作负载,包括不同大小的内存、不同的页面访问序列;
- 分别应用LRU、FIFO和CLOCK算法进行页面置换;
- 记录并计算各种算法的页面置换次数、命中率等指标。
通过模拟实验,我们可能得到如下结果:
- 在具有明显时间局部性的访问模式下,LRU算法表现出最高的命中率;
- FIFO算法的命中率在访问模式随机变化时显著下降;
- CLOCK算法在需要频繁页面置换的场景中表现优异。
5.2.2 算法选择与优化的实际建议
根据实验结果和分析,我们可以给出以下建议:
- 如果工作负载稳定,且访问模式具有局部性特征,推荐使用LRU算法;
- 对于资源有限的嵌入式系统或者对性能要求不高的场景,FIFO算法由于其实现简单,可以作为首选;
- 在需要对算法性能进行折中处理的场景下,CLOCK算法是一个不错的选择。
此外,结合系统的实际需求,对算法进行优化也是必要的,比如在LRU算法的基础上引入老化机制,以防止Belady's异常。
为了更直观地呈现实验结果,我们可以创建一个表格展示不同算法的性能比较:
| 性能指标 | FIFO算法 | LRU算法 | CLOCK算法 | | -------------- | -------- | ------- | --------- | | 实现复杂度 | 低 | 高 | 中 | | 页面置换频率 | 中 | 低 | 低 | | 平均页面访问时间 | 中 | 高 | 中 | | 命中率 | 中 | 高 | 中 |
结合实际工作负载和性能评估指标,可以更好地选择和应用页面置换算法,进而提升系统整体性能。
代码块以及逻辑分析将在后续章节中补充,保证满足所有指定要求。
6. 算法优化与系统设计的实际应用
在现代计算机系统中,优化内存管理以适应不断增长的应用需求已成为系统设计的核心挑战之一。页面置换算法作为内存管理的核心组成,其优化策略和系统设计应用的深入讨论显得尤为重要。本章将探讨页面置换算法的优化方案,以及这些算法在实际系统设计中如何选择与应用,以期达到最优的性能表现。
6.1 页面置换算法的优化策略
页面置换算法的性能直接关系到内存管理的效率,因此,优化这些算法至关重要。优化策略可以从多个角度来考虑,以下将介绍预测未来页面访问的先进方法,以及结合多种算法的混合策略。
6.1.1 预测未来页面访问的先进方法
预测未来页面访问是减少页面置换次数、提高内存使用效率的关键。基于机器学习和历史数据分析的预测方法是目前较为先进的方式。
预测算法的介绍
预测算法通常基于历史数据来预测未来的访问模式。例如,时间序列分析、随机过程模型、回归模型和神经网络等都被用于预测未来的页面访问。这些模型的目的是学习并预测页面访问的规律,从而提前做出更优的页面替换决策。
机器学习模型在页面预测中的应用
机器学习模型,尤其是深度学习模型,由于其强大的非线性拟合能力和自适应性,在页面访问预测方面表现出色。通过训练模型学习大量的历史页面访问数据,可以识别出潜在的访问模式和预测未来页面请求。
代码实例与逻辑分析
以下是一个简单的神经网络实现示例,使用Python的TensorFlow库来预测页面访问模式:
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# 假设已有历史页面访问数据和对应标签
X_train, Y_train = load_training_data() # 加载历史访问数据和标签
# 创建一个简单的全连接神经网络模型
model = Sequential()
model.add(Dense(units=64, activation='relu', input_dim=X_train.shape[1]))
model.add(Dense(units=32, activation='relu'))
model.add(Dense(units=1, activation='sigmoid'))
# 编译模型
***pile(optimizer='adam', loss='mean_squared_error')
# 训练模型
model.fit(X_train, Y_train, epochs=100, batch_size=32)
# 使用模型进行预测
predictions = model.predict(X_test)
在这个代码示例中,我们首先加载训练数据,然后创建并配置一个神经网络模型,接着编译并训练模型。训练完成后,我们使用模型对未来的页面访问进行预测。需要注意的是,网络结构和参数根据实际应用场景进行调整。
6.1.2 结合多种算法的混合策略
不同的页面置换算法具有不同的特点和适用场景。因此,结合多种算法的混合策略能够发挥各自优势,提升整体性能。
混合策略的原理
混合策略指的是将两种或两种以上的页面置换算法结合起来,根据不同的工作负载和内存使用情况动态选择不同的算法。这种策略旨在克服单一算法在特定场景下的不足。
如何实现混合策略
实现混合策略首先需要对各种算法的性能有深入的理解,然后制定一套决策机制,例如基于内存使用率、页面访问频率等因素来动态切换算法。在实现时,可以为每种算法设计一个评估函数,根据当前系统状态评估各种算法的性能,并据此选择最优算法。
代码示例与逻辑分析
假设我们有一个简单的决策机制,根据内存使用情况选择使用LRU或FIFO算法:
def choose_replacement_strategy(free_memory, memory_threshold):
if free_memory < memory_threshold:
return 'lru'
else:
return 'fifo'
# 假设内存使用情况的函数
def get_free_memory():
# 返回当前的空闲内存大小
pass
memory_threshold = 1024 # 设定的内存阈值
strategy = choose_replacement_strategy(get_free_memory(), memory_threshold)
# 根据选择的策略执行页面替换
if strategy == 'lru':
# 执行LRU算法相关操作
pass
elif strategy == 'fifo':
# 执行FIFO算法相关操作
pass
在这个代码示例中,我们定义了一个选择页面置换策略的函数 choose_replacement_strategy ,它根据当前的空闲内存大小与预设的内存阈值来决定使用哪种算法。根据返回的策略,执行不同的页面置换操作。
6.2 页面置换算法在系统设计中的应用
在实际系统设计中,页面置换算法的选择和应用需要综合考虑系统的内存需求、工作负载以及性能目标等多个因素。本小节将详细探讨系统设计中页面置换算法的选择依据和这些算法对系统性能的整体影响。
6.2.1 系统设计中页面置换算法的选择依据
选择页面置换算法是一个需要综合考量的过程,需要根据系统的具体需求和资源状况来决定。
应用场景的影响
不同的应用场景对内存管理的要求不同。例如,在实时系统中,我们可能更关注算法的响应时间和确定性;而在通用操作系统中,我们可能更关注平均性能和资源消耗。因此,在选择页面置换算法时,首先要考虑的是算法是否适合特定的应用场景。
性能目标的影响
性能目标影响着页面置换算法的选择。如果目标是最小化页面置换次数,那么选择如LRU这类能够有效预测未来访问的算法会比较合适。而如果内存资源紧张,可能需要使用简单高效的FIFO算法。
6.2.2 页面置换算法对系统性能的整体影响
页面置换算法的选择和实现会直接影响到系统的性能表现,包括响应时间、吞吐量以及系统稳定性。
系统响应时间
好的页面置换算法能够减少不必要的页面置换操作,从而减少响应时间。在用户交互型的应用中,提高响应速度是至关重要的。
系统吞吐量
在多任务处理的环境中,高效的页面置换算法能够确保系统拥有更好的吞吐量。这意味着在相同的时间内,系统能够完成更多的工作。
系统稳定性
页面置换算法的选择也会影响系统整体的稳定性。一些算法,如CLOCK,可能会在某些极端情况下表现不佳,导致系统频繁触发页面置换,从而影响系统稳定性。
Mermaid流程图展示:
下面是一个展示页面置换算法选择流程的Mermaid流程图,它将帮助理解如何根据不同的系统需求和性能目标来选择合适的页面置换算法。
flowchart TD
A[开始] --> B{选择算法}
B -->|应用场景| C[实时系统]
B -->|性能目标| D[平均性能]
C --> E[确定性算法]
D --> F[响应时间优化]
E --> G[LRU]
F --> H[CLOCK]
G --> I[结束]
H --> I
在上述流程图中,我们首先对算法进行选择,然后根据应用场景和性能目标两个不同的维度,分别流向实时系统和平均性能的目标。在实时系统方面,我们更倾向于选择具有确定性的算法(例如LRU),而在追求平均性能的场景下,则可能选择优化响应时间的算法(例如CLOCK)。最后,这个流程以算法选择的决策结束。
综上所述,页面置换算法的优化和应用是系统设计中的重要环节。根据不同的应用场景和性能目标选择合适的算法,并考虑采用预测未来页面访问的先进方法以及结合多种算法的混合策略,可以在保证系统性能的同时,提升资源使用效率。
7. 使用工作负载分析进行页面置换算法优化
7.1 工作负载的定义及其对页面置换算法的重要性
工作负载分析是理解系统行为和性能的一个关键步骤,尤其是在内存管理领域。工作负载指的是在特定时间周期内,系统运行的任务集合以及这些任务对资源的使用情况。在内存管理中,工作负载分析帮助我们识别页面访问模式,这对于优化页面置换算法至关重要。
页面置换算法的性能往往依赖于工作负载的特点。例如,一种工作负载可能会导致频繁的页面交换(page thrashing),这是因为算法无法有效地预测和管理内存中的页面。理解这些模式能够使我们调整或重新设计算法,以更好地适应特定的工作负载。
7.2 利用实际数据集进行工作负载分析
为了优化页面置换算法,我们需要收集和分析实际运行数据。通过监控和记录系统中的页面访问情况,我们可以识别出常见的访问模式,并据此优化算法。
实验数据收集
数据收集是工作负载分析的第一步,可以通过以下步骤进行: 1. 确定监控范围 :确定需要监控的系统组件,比如CPU、内存、I/O等。 2. 选择合适工具 :使用如 perf 、 htop 或 vmstat 等性能监控工具。 3. 记录数据 :设置合适的采样频率,记录下关键性能指标数据。
数据集分析方法
采集到的数据需要进一步分析以识别工作负载模式。以下是分析步骤的简化示例:
+------------+------------+--------------+-----------------+
| Page Number| Access Time| Access Type | Working Set Size|
+------------+------------+--------------+-----------------+
| 12 | 13:02 | Read | 10 |
| 12 | 13:03 | Write | 10 |
| 13 | 13:05 | Read | 10 |
| 14 | 13:07 | Write | 10 |
| ... | ... | ... | ... |
+------------+------------+--------------+-----------------+
通过分析访问时间,可以确定页面是否被频繁访问,是否存在时间局部性。通过工作集大小可以判断是否有足够的物理内存支持当前的工作负载。
7.3 根据工作负载特征优化页面置换策略
基于工作负载分析的结果,我们可以采取不同的策略来优化页面置换算法。例如,如果分析显示工作负载具有良好的时间局部性,则可能更适合使用LFU(最不常用)算法。如果空间局部性更强,则LRU算法可能是更好的选择。
针对时间局部性的工作负载优化
若发现时间局部性较强的模式,可以采取以下措施: - 增加内存容量 :允许更多页面常驻内存。 - 调整LRU算法参数 :例如,增加预取的页面数量。
针对空间局部性的工作负载优化
若发现空间局部性较强的模式,可以采取以下措施: - 采用分段算法 :比如段式LRU,来维护多个物理内存段的最近最少使用顺序。
在优化过程中,我们还需考虑到不同的应用和工作负载可能需要不同的策略。例如,数据库系统可能更倾向于使用基于扫描的页面置换算法,而桌面应用可能更偏好于访问频率较高的页面置换策略。
7.4 使用工作负载预测进行预防性优化
在某些情况下,我们可以不仅仅依赖于当前或历史的工作负载数据,还可以采用预测未来工作负载的方法。通过机器学习和人工智能技术,我们可以构建模型来预测未来的页面访问模式,并据此调整页面置换策略。
预测模型构建
构建预测模型大致需要以下步骤: 1. 特征提取 :从历史数据中提取可能影响未来页面访问的特征。 2. 模型训练 :使用机器学习算法训练模型,比如随机森林、神经网络等。 3. 模型验证 :使用部分历史数据对模型的准确性进行验证。
通过预测未来的工作负载,页面置换算法可以更主动地调整页面的加载和替换策略,从而提升整体系统性能。
在本章节中,我们深入了解了页面置换算法优化过程中工作负载分析的重要性,并且探讨了实际的数据收集和分析方法。接着,我们讨论了如何根据工作负载特征来优化页面置换策略,并且引入了通过工作负载预测进行预防性优化的概念。这些都是为了更好地适应动态变化的工作负载,提高页面置换算法的效率和适应性。在下一章节中,我们将继续讨论算法优化与系统设计的实际应用,看看这些理论是如何在实践中得到应用和反馈的。
简介:在操作系统中,页面置换算法对于高效管理虚拟内存至关重要,它们决定内存中的页面如何被替换以释放空间。本文将详细分析三种关键的页面置换算法:LRU(最近最少使用)、FIFO(先进先出)和CLOCK(时钟算法),探讨它们的工作原理、优势、劣势以及实现开销。通过分析工作负载,我们可以评估这些算法在不同情况下的表现,并为系统设计提供指导。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 23
23 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)