OpenResty使用Lua大全(八)OpenResty执行流程与阶段详解
之前也介绍过。语境:http阶段:loading-config当nginx master进程在加载nginx配置文件时运行指定的lua脚本,语境:http阶段:starting-worker在每个nginx worker进程启动时调用指定的lua代码。用于启动一些定时任务,比如心跳检查,定时拉取服务器配置等等;此处的任务是跟Worker进程数量有关系的,比如有2个Worker进程那么就会启动两个完
系列文章索引
OpenResty使用Lua大全(一)Lua语法入门实战
OpenResty使用Lua大全(二)在OpenResty中使用Lua
OpenResty使用Lua大全(三)OpenResty使用Json模块解析json
OpenResty使用Lua大全(四)OpenResty中使用Redis
OpenResty使用Lua大全(五)OpenResty中使用MySQL
OpenResty使用Lua大全(六)OpenResty发送http请求
OpenResty使用Lua大全(七)OpenResty使用全局缓存
OpenResty使用Lua大全(八)OpenResty执行流程与阶段详解
OpenResty使用Lua大全(九)实战:nginx-lua-redis实现访问频率控制
OpenResty使用Lua大全(十)实战: Lua + Redis 实现动态封禁 IP
OpenResty使用Lua大全(十一)实战: nginx实现接口签名安全认证
OpenResty使用Lua大全(十二)实战: 动手实现一个网关框架
一、OpenResty的执行流程概览
1、引出问题
location /test {
set $a 32;
echo $a;
set $a 56;
echo $a;
}
输出结果:

为什么是56 56?
Nginx 处理每一个用户请求时,都是按照若干个不同阶段依次处理的。而不是根据配置文件上的顺序。
之上的例子 涉及到了 两个阶段 rewrite和content阶段
set属于rewrite阶段
echo属于content阶段
而且 rewrite阶段的指令 在 content阶段指令 之前执行。
实际的执行顺序应当是
set $a 32;
set $a 56;
echo $a;
echo $a;
所以输出 56
在我们配置文件中执行的指令,可以理解为对我们的执行阶段进行入栈。
2、Nginx请求处理的11个阶段
Nginx处理请求的过程一共划分为11个阶段,按照执行顺序依次是post-read、server-rewrite、
find-config、rewrite、post-rewrite、 preaccess、access、post-access、try-files、content、log。
所以,整个请求的过程,是按照不同的阶段执行的,在某个阶段执行完该阶段的指令之后,再进行下一个阶段的指令执行。
1、post-read
读取请求内容阶段,nginx读取并解析完请求头之后就立即开始运行;
例如模块 ngx_realip 就在 post-read 阶段注册了处理程序,
它的功能是迫使 Nginx 认为当前请求的来源地址是指定的某一个请求头的值。
2、server-rewrite
server请求地址重写阶段;当ngx_rewrite模块的set配置指令直接书写在server配置块中时,
基本上都是运行在server-rewrite 阶段
3、find-config
配置查找阶段,这个阶段并不支持Nginx模块注册处理程序,
而是由Nginx核心来完成当前请求与location配置块之间的配对工作。
4、rewrite
location请求地址重写阶段,当ngx_rewrite指令用于location中,就是再这个阶段运行的;
另外ngx_set_misc(设置md5、encode_base64等)模块的指令,
还有ngx_lua模块的set_by_lua指令和rewrite_by_lua指令也在此阶段。
5、post-rewrite
请求地址重写提交阶段,当nginx完成rewrite阶段所要求的内部跳转动作,如果rewrite阶段有这个要求的话;
6、preaccess
访问权限检查准备阶段,ngx_limit_req和ngx_limit_zone在这个阶段运行,
ngx_limit_req可以控制请求的访问频率,ngx_limit_zone可以控制访问的并发度;
7、access
访问权限检查阶段,标准模块ngx_access、第三方模块ngx_auth_request以及第三方模块ngx_lua的access_by_lua
指令就运行在这个阶段。配置指令多是执行访问控制相关的任务,如检查用户的访问权限,检查用户的来源IP是否合法;
8、post-access
访问权限检查提交阶段;主要用于配合access阶段实现标准ngx_http_core模块提供的配置指令satisfy的功能。
satisfy all(与关系),satisfy any(或关系)
9、try-files
配置项try_files处理阶段;专门用于实现标准配置指令try_files的功能,
如果前 N-1 个参数所对应的文件系统对象都不存在,
try-files 阶段就会立即发起“内部跳转”到最后一个参数(即第 N 个参数)所指定的URI.
10、content
内容产生阶段,是所有请求处理阶段中最为重要的阶段,
因为这个阶段的指令通常是用来生成HTTP响应内容并输出 HTTP 响应的使命;
11、log
日志模块处理阶段;记录日志
NGX_HTTP_POST_READ_PHASE:
#读取请求内容阶段
NGX_HTTP_SERVER_REWRITE_PHASE:
#Server请求地址重写阶段
NGX_HTTP_FIND_CONFIG_PHASE:
#配置查找阶段:
NGX_HTTP_REWRITE_PHASE:
#Location请求地址重写阶段,常用
NGX_HTTP_POST_REWRITE_PHASE:
#请求地址重写提交阶段
NGX_HTTP_PREACCESS_PHASE:
#访问权限检查准备阶段
NGX_HTTP_ACCESS_PHASE:
#访问权限检查阶段,常用
NGX_HTTP_POST_ACCESS_PHASE:
#访问权限检查提交阶段
NGX_HTTP_TRY_FILES_PHASE:
#配置项try_files处理阶段
NGX_HTTP_CONTENT_PHASE:
#内容产生阶段 最常用
NGX_HTTP_LOG_PHASE:
#日志模块处理阶段 常用
到此,应该明白Nginx 的conf中指令的书写顺序和执行顺序是两码事。
有些阶段是支持 Nginx 模块注册处理程序,有些阶段并不可以。
最常用的是 rewrite阶段,access阶段 以及 content阶段;
不支持 Nginx 模块注册处理程序的阶段 find-config, post-rewrite, post-access,
主要是 Nginx 核心完成自己的一些逻辑。
3、OpenResty处理阶段与使用范围
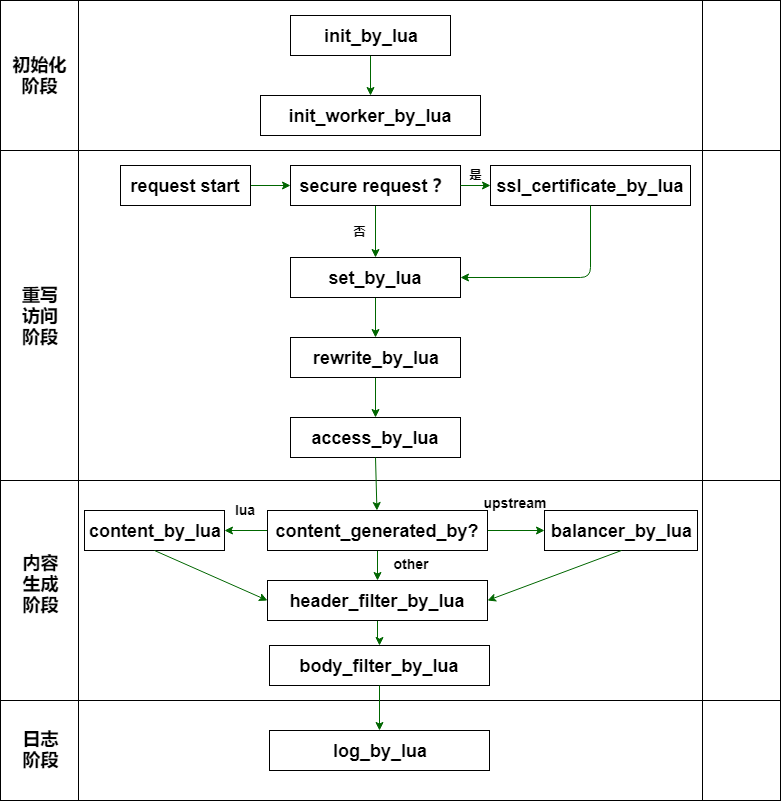
openresty发起一个请求时,会有相应的执行流程

从图中可知,OpenResty 处理请求大致分为四个阶段:
1)初始化阶段(Initialization Phase)
2)重写与访问阶段(Rewrite / Access Phase)
3)内容生成阶段(Content Phase)
4)日志记录阶段(Log Phase)
4、示例
我们OpenResty做个测试,示例代码如下:
init_by_lua 'ngx.log(ngx.ERR, "init_by_lua")';
init_worker_by_lua 'ngx.log(ngx.ERR, "init_worker_by_lua")';
server {
listen 80;
location /exec {
rewrite_by_lua 'ngx.log(ngx.ERR, "rewrite_by_lua")';
set_by_lua $a 'ngx.log(ngx.ERR, "set_by_lua")';
access_by_lua 'ngx.log(ngx.ERR, "access_by_lua")';
header_filter_by_lua 'ngx.log(ngx.ERR, "header_filter_by_lua")';
body_filter_by_lua 'ngx.log(ngx.ERR, "body_filter_by_lua")';
log_by_lua 'ngx.log(ngx.ERR, "log_by_lua")';
content_by_lua 'ngx.log(ngx.ERR, "content_by_lua")';
}
}
查看nginx的日志:

这几个阶段的存在,应该是openresty不同于其他多数Web server编程的最明显特征了。
由于nginx把一个会话分成了很多阶段,这样第三方模块就可以根据自己行为,挂载到不同阶段进行处理达到目的。
这样我们就可以根据我们的需要,在不同的阶段直接完成大部分典型处理了。
5、指令详细解释
指令可以在http、server、server if、location、location if几个范围进行配置:
指令 所处处理阶段 使用范围 解释
init_by_lua
init_by_lua_file loading-config http
nginx Master进程加载配置时执行;通常用于初始化全局配置/预加载Lua模块
init_worker_by_lua
init_worker_by_lua_file starting-worker http
每个Nginx Worker进程启动时调用的计时器,如果Master进程不允许则只会在init_by_lua之后调用;
通常用于定时拉取配置/数据,或者后端服务的健康检查
set_by_lua
set_by_lua_file rewrite server,server if,location,location if
设置nginx变量,可以实现复杂的赋值逻辑;此处是阻塞的,Lua代码要做到非常快;
rewrite_by_lua
rewrite_by_lua_file rewrite tail http,server,location,location if
rrewrite阶段处理,可以实现复杂的转发/重定向逻辑;
access_by_lua
access_by_lua_file access tail http,server,location,location if
请求访问阶段处理,用于访问控制、限流等
content_by_lua
content_by_lua_file content location,location if
内容处理器,接收请求处理并输出响应
header_filter_by_lua
header_filter_by_lua_file output-header-filter http,server,location,location if
响应 HTTP过滤处理(例如添加头部信息),设置header和cookie
body_filter_by_lua
body_filter_by_lua_file output-body-filter http,server,location,location if
响应 BODY过滤处理(例如完成应答内容统一成大写) 对响应数据进行过滤,比如截断、替换。
log_by_lua
log_by_lua_file log http,server,location,location if
响应完成后本地异步完成日志记录(日志可以记录在本地,还可以同步到其他机器)
阶段处理,比如记录访问量/统计平均响应时间
实际上我们只使用其中一个阶段content_by_lua,也可以完成所有的处理。但这样做,
会让我们的代码比较臃肿,越到后期越发难以维护。把我们的逻辑放在不同阶段,分工明确,代码独立
二、初始化阶段
1、指令:init_by_lua
(1)概述
总共三个指令:init_by_lua init_by_lua_block init_by_lua_file,之前也介绍过。
语法:init_by_lua <lua-script-str>
语境:http
阶段:loading-config
当nginx master进程在加载nginx配置文件时运行指定的lua脚本,
(2)使用示例
通常用来注册lua的全局变量或在服务器启动时预加载lua模块:
init_by_lua_block {
-- 预加载 + 全局变量
cjson = require "cjson"
}
server {
listen 80;
location = /api {
content_by_lua_block {
ngx.say(cjson.encode({dog = 5, cat = 6}))
}
}
}
从上面段配置代码,我们可以看出,其实这个指令就是初始化一些lua的全局变量,以便后续的代码使用。
初始化lua_shared_dict共享数据:
lua_shared_dict dogs 1m;
init_by_lua_block {
local dogs = ngx.shared.dogs;
dogs:set("Tom", 50)
dogs:set("flag",1)
}
server {
location = /api {
content_by_lua_block {
local dogs = ngx.shared.dogs;
ngx.say(dogs:get("Tom"))
}
}
}
lua_shared_dict的内容不会在nginx reload时被清除。所以如果你不想在init_by_lua中重复初始化共享数据,
那么你需要在你的共享内存中设置一个标志位并在init_by_lua中进行检查。(因为init_by_lua方法会在nginx reload时会执行)
因为这个阶段的lua代码是在nginx forks出任何worker进程之前运行,
数据和代码的加载将享受由操作系统提供的copy-on-write的特性,从而节约了大量的内存。
不要在这个阶段初始化你的私有lua全局变量,因为使用lua全局变量会照成性能损失,并且可能导致全局命名空间被污染。
这个阶段只支持一些小的LUA Nginx API设置:ngx.log和print、ngx.shared.DICT;
2、指令:init_worker_by_lua
(1)概述
语法:init_worker_by_lua <lua-script-str>
语境:http
阶段:starting-worker
在每个nginx worker进程启动时调用指定的lua代码。
用于启动一些定时任务,比如心跳检查,定时拉取服务器配置等等;此处的任务是跟Worker进程数量有关系的,
比如有2个Worker进程那么就会启动两个完全一样的定时任务。
(2)使用示例
案例:nginx.conf配置文件中的http部分添加如下代码
init_worker_by_lua_file /usr/local/openresty/nginx/conf/init_worker.lua;
init_worker.lua:
local count = 0
local delayInSeconds = 3
local heartbeatCheck = nil
heartbeatCheck = function(args)
count = count + 1
ngx.log(ngx.ERR, "do check ", count)
local ok, err = ngx.timer.at(delayInSeconds, heartbeatCheck)
if not ok then
ngx.log(ngx.ERR, "failed to startup heartbeart worker...", err)
end
end
heartbeatCheck()
ngx.timer.at:延时调用相应的回调方法;ngx.timer.at(秒单位延时,回调函数,回调函数的参数列表);
可以将延时设置为0即得到一个立即执行的任务,任务不会在当前请求中执行不会阻塞当前请求,
而是在一个轻量级线程中执行。
另外根据实际情况设置如下指令
lua_max_pending_timers 1024; #最大等待任务数
lua_max_running_timers 256; #最大同时运行任务数
3、指令:lua_package_path
语法:lua_package_path <lua-style-path-str>
默认:由lua的环境变量决定
适用上下文:http
设置lua代码的寻找目录。
例如:lua_package_path "/usr/nginx/conf/lua/?.lua;;";
这样就可以直接require 加载我们的lua脚本就行了。
三、重写赋值阶段
1、指令:set_by_lua
(1)概述
语法:set_by_lua $res <lua-script-str> [$arg1 $arg2 …]
语境:server、server if、location、location if
阶段:rewrite
设置nginx变量,我们用的set指令即使配合if指令也很难实现负责的赋值逻辑;
传入参数到指定的lua脚本代码中执行,并得到返回值到res中。
<lua-script-str>中的代码可以使从ngx.arg表中取得输入参数(顺序索引从1开始)。
这个指令是为了执行短期、快速运行的代码因为运行过程中nginx的事件处理循环是处于阻塞状态的。
耗费时间的代码应该被避免。
禁止在这个阶段使用下面的API:
1、output api(ngx.say和ngx.send_headers);
2、control api(ngx.exit);
3、subrequest api(ngx.location.capture和ngx.location.capture_multi);
4、cosocket api(ngx.socket.tcp和ngx.req.socket);
5、sleep api(ngx.sleep)
(2)简单变量赋值
示例:比如说我们如果变量赋值比较简单,可以这样实现:
location /lua {
set $jump "1";
echo $jump;
}
set 命令对变量进行赋值,但有些场景的赋值业务比较复杂,需要用到lua脚本,所以用到set_by_lua
(3)复杂变量赋值
案例需求:书店网站改造把之前的skuid为8位商品,请求到以前的页面,为9位的请求到新的页面
书的商品详情页进行了改造,美化了一下;上线了时候,不要一下子切换美化页面;;做AB概念
把新录入的书的商品 采用 新的商品详情页,,之前维护的书的商品详情页 用老的页面
以前书的id 为8位,新的书id为9位
location /book {
set_by_lua $to_type '
local skuId = ngx.var.arg_skuId
ngx.log(ngx.ERR,"skuId=",skuId)
local r = ngx.re.match(skuId, "^[0-9]{8}$")
local k = ngx.re.match(skuId, "^[0-9]{9}$")
if r then
return "1"
end;
if k then
return "2"
end;
';
if ($to_type = "1") {
echo "skuId为8位" ;
proxy_pass http://127.0.0.1/old_book/$arg_skuId.html;
}
if ($to_type = "2") {
echo "skuId为9位" ;
proxy_pass http://127.0.0.1/new_book/$arg_skuId.html;
}
}
(4)同时为多个变量赋值
set_by_lua 这个指令只能一次写出一个nginx变量,但是使用ngx.var接口可以解决这个问题:
location /foo {
set $diff '';
set_by_lua $sum '
local a = 32
local b = 56
ngx.var.diff = a - b; --写入$diff中
return a + b; --返回到$sum中
';
echo "sum = $sum, diff = $diff";
}
2、指令:set_by_lua_file
语法set_by_lua_file $var lua_file arg1 arg2...;
在lua代码中可以实现所有复杂的逻辑,但是要执行速度很快,不要阻塞;
location /lua_set_1 {
default_type "text/html";
set_by_lua_file $num /usr/local/luajit/test_set_1.lua;
echo $num;
}
test_set_1.lua:
local uri_args = ngx.req.get_uri_args()
local i = uri_args["i"] or 0
local j = uri_args["j"] or 0
return i + j
得到请求参数进行相加然后返回。
访问如http://192.168.56.10/lua_set_1?i=1&j=10进行测试。 这是我们用纯set指令是无法实现的。
四、重写rewrite阶段(常用)
1、if指令
(1)概述
语法:if (condition){...}
默认值:无
作用域:server,location
对给定的条件condition进行判断。如果为真,大括号内的指令将被执行。
上面的if和(之间需要留空格,否则会报错。
(2)条件可以为一个变量
如果一个变量名进行条件判断,空字符串’’ 或 字符串为’0’,都表示为假 false
location /api {
set $a '';
if ($a){
return 200 "00000";
}
}
(3)条件为表达式
正则表达式匹配:
= ,!= 比较的一个变量和字符串
~:与指定正则表达式模式匹配时返回“真”,判断匹配与否时区分字符大小写;
~*:与指定正则表达式模式匹配时返回“真”,判断匹配与否时不区分字符大小写;
!~:与指定正则表达式模式不匹配时返回“真”,判断匹配与否时区分字符大小写;
!~*:与指定正则表达式模式不匹配时返回“真”,判断匹配与否时不区分字符大小写;
location /api {
if ($request_uri ~* "/api/[0-9]+") {
return 200 "api";
}
}
(4)文件及目录匹配判断
-f, !-f:判断指定的路径是否为存在且为文件;
-d, !-d:判断指定的路径是否为存在且为目录;
-e, !-e:判断指定的路径是否存在,文件或目录均可;
-x, !-x:判断指定路径的文件是否存在且可执行;
location /api {
if (-f "/usr/local/lua/test.lua") {
return 200 "test存在";
}
}
(5)注意
1)nginx if 没有对应的else
2)if 表达式中 是不能用 && ||
nginx的配置中不支持if条件的逻辑与&& 逻辑或|| 运算等逻辑运算符
而且不支持if的嵌套语法,否则会报错。
如:
location /api {
if ( $arg_a != '1' && $arg_a != '2' ) {
rewrite ^/(.*)$ https://www.baidu.com permanent;
}
}
会报错nginx: [emerg] invalid condition
修改为:
set $flag 0;
if ($arg_a != '1') {
set $flag "${flag}1"; ---》 01
}
if ($arg_a != '2'){
set $flag "${flag}1"; ---》 011
}
if ($flag = "011"){
rewrite ^/(.*)$ https://www.baidu.com permanent;
}
2、Rewrite规则
(1)http status code 301 与 302区别
301 redirect: 301 代表永久性转移(Permanently Moved)
302 redirect: 302 代表暂时性转移(Temporarily Moved)
详细来说,301和302状态码都表示重定向,就是说浏览器在拿到服务器返回的这个状态码后会自动跳转到一个
新的URL地址,这个地址可以从响应的Location首部中获取,用户看到的效果就是他输入的地址A瞬间变成了另一个地址B
—这是它们的共同点。他们的不同在于。301表示旧地址A的资源已经被永久地移除了(这个资源不可访问了),
搜索引擎在抓取新内容的同时也将旧的网址交换为重定向之后的网址;302表示旧地址A的资源还在(仍然可以访问),
这个重定向只是临时地从旧地址A跳转到地址B,搜索引擎会抓取新的内容而保存旧的网址。
(2)rewrite指令
语法rewrite regex replacement [flag];
regex:perl兼容正则表达式语句进行规则匹配
replacement:将正则匹配的内容替换成replacement
flag标记:rewrite支持的flag标记
rewrite功能就是,使用nginx提供的全局变量或自己设置的变量,结合正则表达式和标志位实现url重写以及重定向。
rewrite只能放在server{},location{},if{}中,并且只能对域名后边的除去传递的参数外的字符串起作用,
例如http://www.a.com/api/index.jsp?id=1&u=str 只对api/index.jsp重写。
正则表达式元字符:
. :匹配除换行符以外的任意字符
? :重复0次或1次
+ :重复1次或更多次
* :重复0次或更多次
\d :匹配数字
^ :匹配字符串的开始字符
$ :匹配字符串的结束字符
{n} :重复n次
{n,} :重复n次或更多次
[c] :匹配单个字符c
[a-z] :匹配a-z小写字母的任意一个
在rewrite中,如果使用小括号(),那么在小括号之间匹配的内容,可以在后面通过$1来引用,
$2表示的是前面第二个()里的内容
flag标志位
last : 相当于Apache的[L]标记,表示完成rewrite
break : 停止执行当前虚拟主机的后续rewrite指令集
redirect : 返回302临时重定向,地址栏会显示跳转后的地址
permanent : 返回301永久重定向,地址栏会显示跳转后的地址
(3)示例
location /foo {
rewrite ^ /bar redirect;
}
location /bar {
echo "bar";
}
location /api {
rewrite ^/(.*) https://www.baidu.com/s?wd=$1 permanent;
}
请求:http://192.168.31.150/api —> $1 = api
请求:http://192.168.31.150/api/pro —> $1 = api/pro
(4)last 和 break 区别
last: 停止当前这个请求,并根据rewrite匹配的规则重新发起一个请求。新请求又从第一阶段开始执行…
break:相对last,break并不会重新发起一个请求,只是跳过当前的rewrite阶段,并执行本请求后续的执行阶段…
break与last都停止处理后续rewrite指令集,不同之处在与last会重新发起新的请求,
而break不会。当请求break时,如匹配内容存在的话,可以直接请求成功
案例:
location /break/ {
rewrite ^/break/(.*) /test/$1 break; #----break;/test/$1 会在根目录下的查找/test/$1文件
}
location /last/ {
rewrite ^/last/(.*) /test/$1 last; #----last;/test/$1 会重新走一遍location匹配流程
}
location /test/ {
echo "test page";
}
(5)伪静态
location = /pro {
echo "pro_$arg_pid";
}
location /{
rewrite ^/product/(\d+).html$ /pro?pid=$1 last;
}
应用场景:
a)可以调整用户浏览的URL,看起来更规范,合乎开发及产品人员的需求。
b)为了让搜索引擎搜录网站内容及用户体验更好,企业会将动态URL地址伪装成静态地址提供服务。
c)网址换新域名后,让旧的访问跳转到新的域名上。例如,访问京东的360buy.com会跳转到jd.com
d)根据特殊变量、目录、客户端的信息进行URL调整等
可应用在server,location,if标签
执行顺序是:
a)执行server块的rewrite指令
b)执行location匹配
c)执行选定的location中的rewrite指令
如果其中某步URI被重写,则重新循环执行a-c,直到找到真实存在的文件;循环超过10次,
则返回500 Internal Server Error错误。
3、rewrite_by_lua
(1)概述
语法:rewrite_by_lua <lua-script-str>
语境:http、server、location、location if
阶段:rewrite tail
作为rewrite阶段的处理,为每个请求执行指定的lua代码。注意这个处理是在标准HtpRewriteModule之后进行的:
执行内部URL重写或者外部重定向,典型的如伪静态化的URL重写。其默认执行在rewrite处理阶段的最后
(2)ngx.redirect :重定向
语法:ngx.redirect(uri, status?)
该方法会给客户端返回一个301/302重定向,具体是301还是302取决于设定的status值,
如果不指定status值,默认是返回302
rewrite ^ /bar redirect; 等价于 ngx.redirect(“https://www.baidu.com”, 302)
rewrite ^ /bar permanent; 等价于 ngx.redirect(“https://www.baidu.com”, 301)
--------------nginx.conf配置文件
location /lua_rewrite_1 {
rewrite_by_lua_block {
if ngx.req.get_uri_args()["jump"] == "1" then
return ngx.redirect("https://www.baidu.com", 302)
end
}
echo "no rewrite";
}
当我们请求http://192.168.56.10/lua_rewrite_1时发现没有跳转,
而请求http://192.168.56.10/lua_rewrite_1?jump=1时发现跳转到百度首页了。
此处需要 301/302跳转根据自己需求定义。
再取个案例
location /foo {
set $a 12;
set $b '';
rewrite_by_lua 'ngx.var.b = tonumber(ngx.var.a) + 1';
if ($b = '13') {
rewrite ^ /bar redirect;
break;
}
echo "res = $b";
}
location /bar {
echo "bar";
}
因为if会在rewrite_by_lua之前运行,所以判断将不成立。正确的写法应该是这样:
location /foo {
set $a 12;
set $b '';
rewrite_by_lua_block {
ngx.var.b = tonumber(ngx.var.a) + 1
if tonumber(ngx.var.b) == 13 then
return ngx.redirect("/bar");
end
}
echo "res = $b";
}
(3)ngx.req.set_uri :内部重写
语法: ngx.req.set_uri(uri, jump?)
通过参数uri重写当前请求的uri;参数jump,表明是否进行locations的重新匹配。
当jump为true时,调用ngx.req.set_uri后,nginx将会根据修改后的uri,重新匹配新的locations;
如果jump为false,将不会进行locations的重新匹配,而仅仅是修改了当前请求的URI而已。jump的默认值为false。
rewrite ^ /lua_rewrite_3; 等价于 ngx.req.set_uri(“/lua_rewrite_3”, false);
rewrite ^ /lua_rewrite_3 break; 等价于 ngx.req.set_uri(“/lua_rewrite_3”, false);
rewrite ^ /lua_rewrite_4 last; 等价于 ngx.req.set_uri(“/lua_rewrite_4”, true);
---------------nginx.conf配置文件
location /foo {
rewrite_by_lua_block {
ngx.req.set_uri_args({a = 1, b = 2});
ngx.req.set_uri("/bar/index.html", true);
}
}
location /bar {
echo "bar uri : $uri,a : $arg_a,b : $arg_b";
}
ngx.req.set_uri_args:重写请求参数;
注意 ngx.req.set_uri(uri, true) 时,ngx.req.set_uri_args的顺序
五、访问阶段
1、用法
用途:访问权限限制 返回403
nginx:allow 允许,deny 禁止
allow ip;
deny ip;
涉及到的网关,有很多的业务 都是在access阶段处理的,有复杂的访问权限控制
nginx:allow deny 功能太弱
2、access_by_lua
语法:access_by_lua <lua-script-str>
语境:http,server,location,location if
阶段:access tail
为每个请求在访问阶段的调用lua脚本进行处理。主要用于访问控制,能收集到大部分的变量。
用于在 access 请求处理阶段插入用户 Lua 代码。这条指令运行于 access 阶段的末尾,
因此总是在 allow 和 deny 这样的指令之后运行,虽然它们同属 access 阶段。
location /foo {
access_by_lua_block {
ngx.log(ngx.DEBUG,"12121212");
}
allow 192.168.56.1;
echo "access";
}
access_by_lua 通过 Lua 代码执行一系列更为复杂的请求验证操作,比如实时查询数据库或者其他后端服务,
以验证当前用户的身份或权限。
利用 access_by_lua 来实现 ngx_access 模块的 IP 地址过滤功能:
location /access {
access_by_lua_block {
if ngx.var.arg_a == "1" then
return
end
if ngx.var.remote_addr == "192.168.56.1" then
return
end
ngx.exit(403)
}
echo "access";
}
对于限制ip的访问,等价于
location /hello {
allow 192.168.56.1;
deny all;
echo "hello world";
}
3、access_by_lua_file
1.1、nginx.conf配置文件
location /lua_access {
access_by_lua_file /usr/local/luajit/test_access.lua;
echo "access";
}
1.2、test_access.lua
if ngx.req.get_uri_args()["token"] ~= "123" then
return ngx.exit(403)
end
即如果访问如http://192.168.56.10/lua_access?token=234将得到403 Forbidden的响应。
这样我们可以根据如cookie/用户token来决定是否有访问权限。
六、content 内容阶段
1、用法
content 阶段属于一个比较靠后的处理阶段,运行在先前介绍过的 rewrite 和 access 这两个阶段之后。
当和 rewrite、access 阶段的指令一起使用时,这个阶段的指令总是最后运行,例如:
location /content {
# 重写阶段
set $age 1;
rewrite_by_lua "ngx.var.age = ngx.var.age + 1";
# 访问阶段
deny 127.0.0.1;
access_by_lua "ngx.var.age = ngx.var.age * 2";
# 内容阶段
echo "age = $age";
}
启动nginx ,访问 输出 age = 4
改变它们的书写顺序,也不会影响到执行顺序。其中,
set 指令来自 ngx_rewrite 模块,运行于 rewrite 阶段;
而 rewrite_by_lua 指令来自 ngx_lua 模块,运行于 rewrite 阶段的末尾;
接下来,deny 指令来自 ngx_access 模块,运行于 access 阶段;
再下来,access_by_lua 指令同样来自 ngx_lua 模块,运行于 access 阶段的末尾;
最后,echo 指令则来自 ngx_echo 模块,运行在 content 阶段
2、content_by_lua
语法:content_by_lua <lua-script-str>
默认值:无
上下文:location, location if
说明:行为类似与一个“content handler”,给每个请求执行定义于lua-script-str中的lua code。
每一个 location 只能有一个“内容处理程序”,因此,当在 location 中同时使用多个模块的 content 阶段指令时,
只有其中一个模块能成功注册“内容处理程序”。例如这个指令和proxy_pass指令不能同时使用在相同的location中
例中的 set 指令和 rewrite_by_lua 指令同处于 rewrite 阶段,
而 deny 指令和 access_by_lua 指令则同处于 access 阶段。
但不幸的是echo指令,不能同时content_by_lua处于 content 阶段。
考虑下面这个有问题的例子:
location /content1 {
echo hello;
content_by_lua 'ngx.say("world")';
}
这里,ngx_echo 模块的 echo 指令和 ngx_lua 模块的 content_by_lua 指令同处 content 阶段,
于是只有其中一个模块能注册和运行这个 location 的“内容处理程序”:
访问输出 world
输出了后面的 content_by_lua 指令;而 echo 指令则完全没有运行。
例中的 echo 语句和 content_by_lua 语句交换顺序,则输出就会变成 hello。
所以我们应当避免在同一个 location 中使用多个模块的 content 阶段指令。
location /content1 {
echo hello;
echo world;
}
这里使用多条 echo 指令是没问题的,因为它们同属 ngx_echo 模块,而且 ngx_echo模块规定和实现了它们之间的
执行顺序。并非所有模块的指令都支持在同一个 location 中被使用多次,例如 content_by_lua 就只能使用一次,
所以下面这个例子是错误的:
location /content1 {
content_by_lua 'ngx.say("hello")';
content_by_lua 'ngx.say("world")';
}
报错nginx: [emerg] “content_by_lua” directive is duplicate
正确写法:
location /content1 {
content_by_lua 'ngx.say("hello") ngx.say("world")';
}
3、如果一个 location 中未使用任何 content 阶段的指令,会如何处理
(1)静态资源服务模块
- ngx_index
- ngx_autoindex
- ngx_static
location /content {
}
nginx会把当前请求的 URI 映射到文件系统的静态资源服务模块。
当存在“内容处理程序”时,这些静态资源服务模块并不会起作用;反之,请求的处理权就会自动落到这些模块上。
Nginx 一般会在 content 阶段安排三个这样的静态资源服务模块(除非你的 Nginx 在构造时显式禁用了这三个模块中
的一个或者多个,又或者启用了这种类型的其他模块)。按照它们在 content 阶段的运行顺序,依次是 ngx_index
模块,ngx_autoindex 模块,以及 ngx_static 模块。
下面就来逐一介绍一下这三个模块
ngx_index 和 ngx_autoindex 模块都只会作用于那些 URI 以 / 结尾的请求
例如请求 GET /cats/,而对于不以 / 结尾的请求则会直接忽略,同时把处理权移交给 content 阶段的下一个模块。
而 ngx_static 模块则刚好相反,直接忽略那些 URI 以 / 结尾的请求。
以 / 结尾的请求 ===》 ngx_index 和 ngx_autoindex 模块 进行处理
不以 / 结尾的请求 ===》 ngx_static 进行处理
(2)ngx_index 模块
主要用于在文件系统目录中自动查找指定的首页文件,类似 index.html 和 index.htm 这样的,
例如:
location / {
root html;
index index.html index.htm;
}
当用户请求 / 地址时,Nginx 就会自动在 root 配置指令指定的文件系统目录下依次寻找 index.htm 和 index.html
这两个文件。如果 index.htm 文件存在,则直接发起“内部跳转”到 /index.htm 这个新的地址;
而如果 index.htm 文件不存在,则继续检查 index.html 是否存在。如果存在,同样发起“内部跳转”到 /index.html;
如果 index.html 文件仍然不存在,则放弃处理权给 content 阶段的下一个模块。
内部跳转:rewrite last 内容跳转
验证 ngx_index 模块在找到文件时的“内部跳转”行为,看下面的例子
location / {
root html;
index index.html;
}
location /index.html {
set $a 32;
echo "a = $a";
}
输出 a = 32
为什么输出不是 index.html 文件的内容?首先对于用户的原始请求 GET /,Nginx 匹配出 location / 来处理它,
然后 content 阶段的 ngx_index 模块在 html 下找到了 index.html,于是立即发起一个到 /index.html
位置的“内部跳转”。在重新为 /index.html 这个新位置匹配 location 配置块时,
location /index.html 的优先级要高于 location /,因为 location 块按照 URI 前缀来匹配时遵循所谓的
“最长子串匹配语义”。这样,在进入 location /index.html 配置块之后,又重新开始执行 rewrite 、access、
以及 content 等阶段。最终输出 a = 32
如果此时把 /html/index.html 文件删除,再访问 / 又会发生什么事情呢?
答案是返回 403 Forbidden 出错页。
为什么呢?因为 ngx_index 模块找不到 index 指令指定的文件index.html,
接着把处理权转给 content 阶段的后续模块,而后续的模块也都无法处理这个请求,
于是 Nginx 只好放弃,输出了错误页,并且在 Nginx 错误日志中留下了类似这一行信息:
[error] 28789#0: *1 directory index of "/html/" is forbidden
(3)ngx_autoindex 模块
所谓 directory index 便是生成“目录索引”的意思,典型的方式就是生成一个网页,
上面列举出 /html/ 目录下的所有文件和子目录。而运行在 ngx_index 模块之后的
ngx_autoindex 模块就可以用于自动生成这样的“目录索引”网页。我们来把上例修改一下:
location / {
root /html/;
index index.html;
autoindex on;
}
此时仍然保持文件系统中的 /html/index.html 文件不存在。我们再访问 / 位置时,就会得到目录下的文件列表
(4)ngx_static 模块
在 content 阶段默认“垫底”的最后一个模块便是极为常用的 ngx_static 模块。
这个模块主要实现服务静态文件的功能。比方说,一个网站的静态资源,包括静态 .html 文件、静态 .css 文件、
静态 .js 文件、以及静态图片文件等等,全部可以通过这个模块对外服务。
前面介绍的 ngx_index 模块虽然可以在指定的首页文件存在时发起“内部跳转”,但真正把相应的首页文件服务出去
(即把该文件的内容作为响应体数据输出,并设置相应的响应头),还是得靠这个 ngx_static 模块来完成。
在下面例子
location / {
root html;
}
在html目录下创建hello.html文件
访问http://192.168.56.10/hello.html
不妨来分析一下这里发生的事情:location / 中没有使用运行在 content 阶段的模块指令,
于是也就没有模块注册这个 location 的“内容处理程序”,处理权便自动落到了在 content 阶段“垫底”的
那 3 个静态资源服务模块。
a)首先运行的 ngx_index 和 ngx_autoindex 模块先后看到当前请求的 URI,/hello.html,并不以 / 结尾,
于是直接弃权,
b)将处理权转给了最后运行的 ngx_static 模块。ngx_static 模块根据 root 指令指定的“文档根目录”
(document root),分别将请求 /hello.html 映射为文件系统路径 /html/hello.html,在确认这个文件存在后,
将它们的内容分别作为响应体输出,并自动设置 Content-Type、Content-Length 以及 Last-Modified 等响应头。
七、响应阶段
1、header_filter_by_lua
语法:header_filter_by_lua <lua-script-str>
语境:http,server,location,location if
阶段:output-header-filter
一般用来设置cookie和headers,在该阶段不能使用如下几个API:
1、output API(ngx.say和ngx.send_headers)
2、control API(ngx.exit和ngx.exec)
3、subrequest API(ngx.location.capture和ngx.location.capture_multi)
4、cosocket API(ngx.socket.tcp和ngx.req.socket)
案例一:
location / {
# 设置响应头
header_filter_by_lua 'ngx.header.Foo = "blah"';
echo "Hello World!";
}
案例二:
http {
log_format main '$msec $status $request $request_time '
'$http_referer $remote_addr [ $time_local ] '
'$upstream_response_time $host $bytes_sent '
'$request_length $upstream_addr';
access_log logs/access.log main buffer=32k flush=1s;
upstream remote_world {
server 127.0.0.1:8080;
}
server {
listen 80;
location /exec {
content_by_lua '
local cjson = require "cjson"
local headers = {
["Etag"] = "662222165e216225df78fbbd47c9333",
["Last-Modified"] = "Fri, 12 May 2018 12:22:22 GMT",
}
ngx.var.my_headers = cjson.encode(headers)
ngx.var.my_upstream = "remote_world"
ngx.var.my_uri = "/world"
ngx.exec("/upstream")
';
}
location /upstream {
internal;
set $my_headers $my_headers;
set $my_upstream $my_upstream;
set $my_uri $my_uri;
proxy_pass http://$my_upstream$my_uri;
header_filter_by_lua '
local cjson = require "cjson"
headers = cjson.decode(ngx.var.my_headers)
for k, v in pairs(headers) do
ngx.header[k] = v
end
';
}
}
server {
listen 8080;
location /world {
echo "hello world";
}
}
}
2、body_filter_by_lua
语法:body_filter_by_lua <lua-script-str>
语境:http,server,location,location if
阶段:output-body-filter
输入的数据时通过ngx.arg1,通过ngx.arg[2]这个bool类型表示响应数据流的结尾。
这个指令可以用来篡改http的响应正文的;会调用几次
在该阶段不能利用如下几个API:
1、output API(ngx.say和ngx.send_headers)
2、control API(ngx.exit和ngx.exec)
3、subrequest API(ngx.location.capture和ngx.location.capture_multi)
4、cosocket API(ngx.socket.tcp和ngx.req.socket)
输入的数据时通过ngx.arg[1],通过ngx.arg[2]这个bool范例暗示响应数据流的末了。
基于这个原因,’eof’只是nginx的链接缓冲区的last_buf(对主requests)或last_in_chain(对subrequests)的标志。
运行以下呼吁可以当即终止运行接下来的lua代码:
return ngx.ERROR
这会将响应体截断导致无效的响应。lua代码可以通过修改ngx.arg[1]的内容将数据传输到下游的
nginx output body filter阶段的其它模块中去。譬喻,将response body中的小写字母举办反转,我们可以这么写:
案例一
location /t {
echo hello world12;
echo hi yile;
body_filter_by_lua '
ngx.log(ngx.ERR,"ngx.arg[1]=",ngx.arg[1]," arg[2]=",ngx.arg[2])
ngx.arg[1] = string.upper(ngx.arg[1])
';
}
尽管只有两个 echo,但是 body_filter_by_lua* 会被调用三次!
第三次调用的时候,ngx.arg[1] 为空字符串,而 ngx.arg[2] 为 true。
这是因为,Nginx 的 upstream 相关模块,以及 OpenResty 的 content_by_lua,
会单独发送一个设置了 last_buf 的空 buffer,来表示流的结束。这算是一个约定俗成的惯例,所以有必要在运行相关逻辑之前,
检查 ngx.arg[1] 是否为空。当然反过来不一定成立,ngx.arg[2] == true 并不代表 ngx.arg[1] 一定为空。
案例二
location /t {
echo hello world;
echo hiya globe;
body_filter_by_lua '
ngx.log(ngx.ERR,"ngx.arg[1]=",ngx.arg[1]," arg[2]=",ngx.arg[2])
local chunk = ngx.arg[1]
if string.match(chunk, "hello") then
ngx.arg[2] = true -- new eof
return
end
ngx.arg[1] = nil
';
}
这是因为,当body filter看到了一块包括”hello“的字符块后当即将”eof“标志配置为了true,
从而导致响应被截断了但仍然是有效的回覆。
3、log_by_lua,log_by_lua_file
在log阶段指定的lua日志,并不会替换access log,而是在那之后调用。
在该阶段不能利用如下几个API:
1、output API(ngx.say和ngx.send_headers)
2、control API(ngx.exit和ngx.exec)
3、subrequest API(ngx.location.capture和ngx.location.capture_multi)
4、cosocket API(ngx.socket.tcp和ngx.req.socket)
可以利用此阶段,把日志统一收集到日志服务器中
location / {
echo "Hello World!";
log_by_lua_block {
ngx.log(ngx.ERR,msg)
}
}
可以用于elk日志收集分析

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 43
43 0
0- 0



 已为社区贡献48条内容
已为社区贡献48条内容

所有评论(0)