【深度学习】伪造指定图像——CGAN原理解析及其代码实现
本篇介绍条件GAN——CGAN,这其实是一个挺简单的模型,只要你知道GAN这个模型,就很容易能够看懂这个,因为CGAN就是在GAN的基础上加上了一个条件,CGAN的作用就是可以依据标签生成对应的图像。【伪造指定图像——CGAN原理解析-哔哩哔哩】
1、前言
本篇介绍条件GAN——CGAN,这其实是一个挺简单的模型,只要你知道GAN这个模型,就很容易能够看懂这个,因为CGAN就是在GAN的基础上加上了一个条件,CGAN的作用就是可以依据标签生成对应的图像。
2、GAN回顾及其问题
2.1、回顾

训练流程:从标准正太分布中采用出一份数据z,送给生成网络G(G(z)),得到服从 P g P_g Pg的伪造图像A;接着,从服从 P d a t a P_{data} Pdata的训练数据中采样出真实图像B,把图像A,B一起送给判别网络D,让它判别真假,输出该图像是真实图像的概率。
对判别网络,最大化真实图像的概率 max D D ( x ) \max\limits_{D} D(x) DmaxD(x),最小化伪造图像 min D D ( G ( z ) ) \min\limits_{D} D(G(z)) DminD(G(z))
由
min
D
D
(
G
(
z
)
)
=
max
D
1
−
D
(
G
(
z
)
)
\min\limits_{D} D(G(z)) = \max\limits_{D}1-D(G(z))
DminD(G(z))=Dmax1−D(G(z))
所以判别网络目标函数(损失函数)为
max
D
D
(
x
)
+
(
1
−
D
(
G
(
z
)
)
\max\limits_{D}D(x)+(1-D(G(z))
DmaxD(x)+(1−D(G(z))
取log不影响最终变量D的取值
max
D
log
D
(
x
)
+
log
(
1
−
D
(
G
(
z
)
)
(1)
\max\limits_{D}\log D(x)+\log (1-D(G(z))\tag{1}
DmaxlogD(x)+log(1−D(G(z))(1)
对生成网络,希望判别网络判断它的图像为真的概率最大,所以(同样取log)
min
G
log
(
1
−
D
(
G
(
z
)
)
(2)
\min\limits_{G} \log (1-D(G(z))\tag{2}
Gminlog(1−D(G(z))(2)
以上为单个样本,将(1)、(2)写一块儿,并求所有样本期望,得到最终损失函数
min
G
max
D
E
x
∼
P
d
a
t
a
[
log
D
(
x
)
]
+
E
z
∼
P
z
[
log
(
1
−
D
(
G
(
z
)
)
]
(3)
\min\limits_{G}\max\limits_{D}\mathbb{E}_{x\sim P_{data}}\left[\log D(x)\right]+\mathbb{E}_{z\sim P_{z}}\left[\log (1-D(G(z))\right]\tag{3}
GminDmaxEx∼Pdata[logD(x)]+Ez∼Pz[log(1−D(G(z))](3)
2.2、问题
模型训练好后,从标准正态分布中采样出数据送给生成网络,生成的图像都是随机的。CGAN就是希望可以送一个标签进去,生成对应的图像,如输入标签1,生成手写数字1;
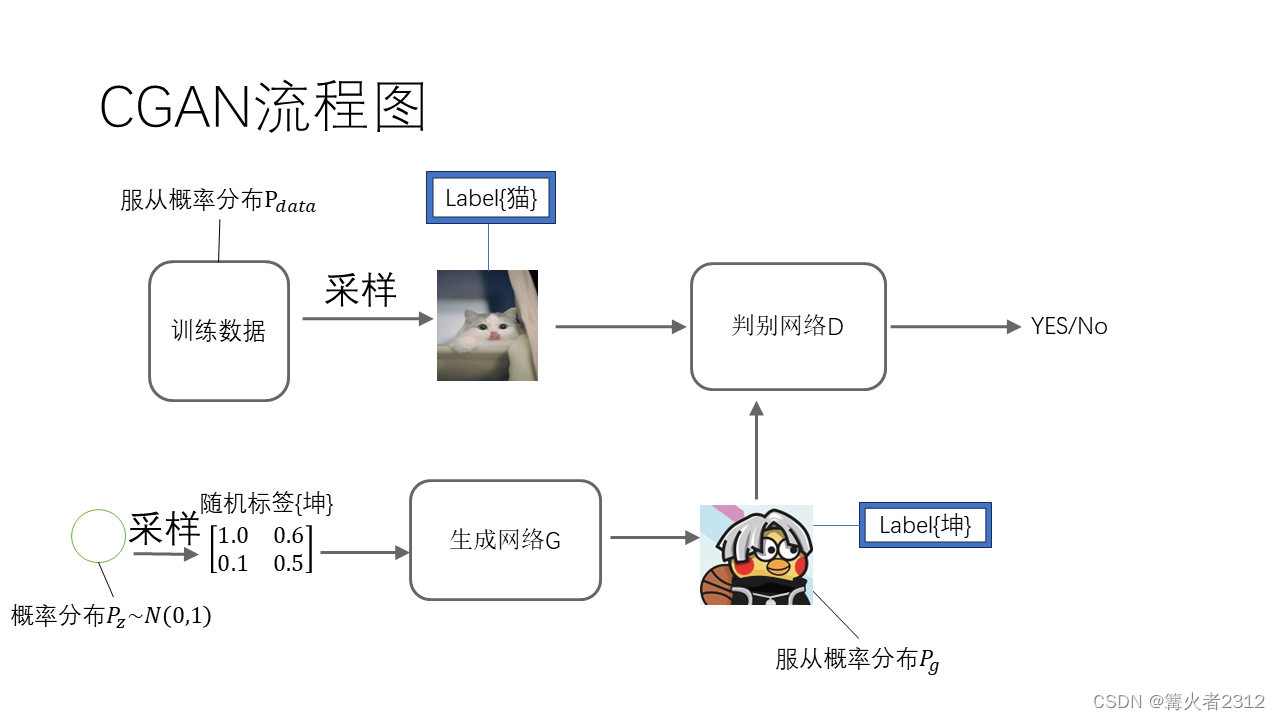
3、CGAN
CGAN训练的时候,在送真实图像进去的的同时,也将标签送进去,然后判别网络才判别(如图,x为图像,y为标签)

生成网络生成图像的时候,随机采样数据,并随机生成标签,然后一并送给生成网络得到假图像(如图)

综上,模型图变成这样

同样的,CGAN的损失函数变成条件概率的形式
min
G
max
D
E
x
∼
P
d
a
t
a
[
log
D
(
x
∣
y
)
]
+
E
z
∼
P
z
[
log
(
1
−
D
(
G
(
z
∣
y
)
)
]
(4)
\min\limits_{G}\max\limits_{D}\mathbb{E}_{x\sim P_{data}}\left[\log D(x|y)\right]+\mathbb{E}_{z\sim P_{z}}\left[\log (1-D(G(z|y))\right]\tag{4}
GminDmaxEx∼Pdata[logD(x∣y)]+Ez∼Pz[log(1−D(G(z∣y))](4)
3.1、单个类别标签
值得注意的是,里面的标签,如果一张图像只有一个类别,那么作者采用独热编码的形式对类别进行编码,比如数字1(0~9数据集),其标签就被编码成【0,1,0,0,0,0,0,0,0,0】,数字5就编码成【0,0,0,0,0,1,0,0,0,0】。
3.2、描述性的标签
有意思的是,作者提出,在图像标记的情况下可能有许多不同的标签可以适当地应用于给定的图像,并且不同的(人类)标注者可能使用不同的(但通常是同义的或相关的)术语来描述同一图像。
比如,一张这样的图像

不去描述它的类别,而去描述它的整体——{这是一块自制的三明治}(emmmmm,应该是三明治吧,看着挺像)
但是,我们也可以有其他描述——{这是一盘由鸡蛋,奶油,花生,面包等等制作出来的食物}
像这样的,作者提出,可以给图像多个标签用来生成图像,比如上图,用{chicken,fattening,cooked, peanut, cream,cookie, house made,bread, biscuit, bakes}这些标签一起输进去,生成上图。
如果我们生成图像的是这种描述,而不再是某个标签,也就是最近挺流行的文生图。值得注意的是,这篇论文是2014年提出的,这种想法的提出(我不晓得是不是这篇论文首先提出的)本身就挺前沿。
作者使用MIR Flickr 25000这个数据集进行实验,图像里面带有描述。作者提取关键词,使用a Skip-gram将关键词转为向量,然后作为多个标签,传进网络;而对生成网络,也是生成多个标签,然后生成图像。
4、代码实现
根据0~9的标签生成数据(来自论文)

PS:代码不是我写的,我太懒了,于是在Github上面找了一个pytorch_MNIST_cGAN
import os, time
import matplotlib.pyplot as plt
import itertools
import pickle
import imageio
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
# G(z)
class generator(nn.Module):
# initializers
def __init__(self):
super(generator, self).__init__()
self.fc1_1 = nn.Linear(100, 256)
self.fc1_1_bn = nn.BatchNorm1d(256)
self.fc1_2 = nn.Linear(10, 256)
self.fc1_2_bn = nn.BatchNorm1d(256)
self.fc2 = nn.Linear(512, 512)
self.fc2_bn = nn.BatchNorm1d(512)
self.fc3 = nn.Linear(512, 1024)
self.fc3_bn = nn.BatchNorm1d(1024)
self.fc4 = nn.Linear(1024, 784)
# weight_init
def weight_init(self, mean, std):
for m in self._modules:
normal_init(self._modules[m], mean, std)
# forward method
def forward(self, input, label):
x = F.relu(self.fc1_1_bn(self.fc1_1(input)))
y = F.relu(self.fc1_2_bn(self.fc1_2(label)))
x = torch.cat([x, y], 1)
x = F.relu(self.fc2_bn(self.fc2(x)))
x = F.relu(self.fc3_bn(self.fc3(x)))
x = F.tanh(self.fc4(x))
return x
class discriminator(nn.Module):
# initializers
def __init__(self):
super(discriminator, self).__init__()
self.fc1_1 = nn.Linear(784, 1024)
self.fc1_2 = nn.Linear(10, 1024)
self.fc2 = nn.Linear(2048, 512)
self.fc2_bn = nn.BatchNorm1d(512)
self.fc3 = nn.Linear(512, 256)
self.fc3_bn = nn.BatchNorm1d(256)
self.fc4 = nn.Linear(256, 1)
# weight_init
def weight_init(self, mean, std):
for m in self._modules:
normal_init(self._modules[m], mean, std)
# forward method
def forward(self, input, label):
x = F.leaky_relu(self.fc1_1(input), 0.2)
y = F.leaky_relu(self.fc1_2(label), 0.2)
x = torch.cat([x, y], 1)
x = F.leaky_relu(self.fc2_bn(self.fc2(x)), 0.2)
x = F.leaky_relu(self.fc3_bn(self.fc3(x)), 0.2)
x = F.sigmoid(self.fc4(x))
return x
def normal_init(m, mean, std):
if isinstance(m, nn.Linear):
m.weight.data.normal_(mean, std)
m.bias.data.zero_()
temp_z_ = torch.rand(10, 100)
fixed_z_ = temp_z_
fixed_y_ = torch.zeros(10, 1)
for i in range(9):
fixed_z_ = torch.cat([fixed_z_, temp_z_], 0)
temp = torch.ones(10,1) + i
fixed_y_ = torch.cat([fixed_y_, temp], 0)
fixed_z_ = Variable(fixed_z_.cuda(), volatile=True)
fixed_y_label_ = torch.zeros(100, 10)
fixed_y_label_.scatter_(1, fixed_y_.type(torch.LongTensor), 1)
fixed_y_label_ = Variable(fixed_y_label_.cuda(), volatile=True)
def show_result(num_epoch, show = False, save = False, path = 'result.png'):
G.eval()
test_images = G(fixed_z_, fixed_y_label_)
G.train()
size_figure_grid = 10
fig, ax = plt.subplots(size_figure_grid, size_figure_grid, figsize=(5, 5))
for i, j in itertools.product(range(size_figure_grid), range(size_figure_grid)):
ax[i, j].get_xaxis().set_visible(False)
ax[i, j].get_yaxis().set_visible(False)
for k in range(10*10):
i = k // 10
j = k % 10
ax[i, j].cla()
ax[i, j].imshow(test_images[k].cpu().data.view(28, 28).numpy(), cmap='gray')
label = 'Epoch {0}'.format(num_epoch)
fig.text(0.5, 0.04, label, ha='center')
plt.savefig(path)
if show:
plt.show()
else:
plt.close()
def show_train_hist(hist, show = False, save = False, path = 'Train_hist.png'):
x = range(len(hist['D_losses']))
y1 = hist['D_losses']
y2 = hist['G_losses']
plt.plot(x, y1, label='D_loss')
plt.plot(x, y2, label='G_loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend(loc=4)
plt.grid(True)
plt.tight_layout()
if save:
plt.savefig(path)
if show:
plt.show()
else:
plt.close()
# training parameters
batch_size = 128
lr = 0.0002
train_epoch = 50
# data_loader
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))
])
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('data', train=True, download=True, transform=transform),
batch_size=batch_size, shuffle=True)
# network
G = generator()
D = discriminator()
G.weight_init(mean=0, std=0.02)
D.weight_init(mean=0, std=0.02)
G.cuda()
D.cuda()
# Binary Cross Entropy loss
BCE_loss = nn.BCELoss()
# Adam optimizer
G_optimizer = optim.Adam(G.parameters(), lr=lr, betas=(0.5, 0.999))
D_optimizer = optim.Adam(D.parameters(), lr=lr, betas=(0.5, 0.999))
# results save folder
if not os.path.isdir('MNIST_cGAN_results'):
os.mkdir('MNIST_cGAN_results')
if not os.path.isdir('MNIST_cGAN_results/Fixed_results'):
os.mkdir('MNIST_cGAN_results/Fixed_results')
train_hist = {}
train_hist['D_losses'] = []
train_hist['G_losses'] = []
train_hist['per_epoch_ptimes'] = []
train_hist['total_ptime'] = []
print('training start!')
start_time = time.time()
for epoch in range(train_epoch):
D_losses = []
G_losses = []
# learning rate decay
if (epoch+1) == 30:
G_optimizer.param_groups[0]['lr'] /= 10
D_optimizer.param_groups[0]['lr'] /= 10
print("learning rate change!")
if (epoch+1) == 40:
G_optimizer.param_groups[0]['lr'] /= 10
D_optimizer.param_groups[0]['lr'] /= 10
print("learning rate change!")
epoch_start_time = time.time()
for x_, y_ in train_loader:
# train discriminator D
D.zero_grad()
mini_batch = x_.size()[0]
y_real_ = torch.ones(mini_batch)
y_fake_ = torch.zeros(mini_batch)
y_label_ = torch.zeros(mini_batch, 10)
y_label_.scatter_(1, y_.view(mini_batch, 1), 1)
x_ = x_.view(-1, 28 * 28)
x_, y_label_, y_real_, y_fake_ = Variable(x_.cuda()), Variable(y_label_.cuda()), Variable(y_real_.cuda()), Variable(y_fake_.cuda())
D_result = D(x_, y_label_).squeeze()
D_real_loss = BCE_loss(D_result, y_real_)
z_ = torch.rand((mini_batch, 100))
y_ = (torch.rand(mini_batch, 1) * 10).type(torch.LongTensor)
y_label_ = torch.zeros(mini_batch, 10)
y_label_.scatter_(1, y_.view(mini_batch, 1), 1)
z_, y_label_ = Variable(z_.cuda()), Variable(y_label_.cuda())
G_result = G(z_, y_label_)
D_result = D(G_result, y_label_).squeeze()
D_fake_loss = BCE_loss(D_result, y_fake_)
D_fake_score = D_result.data.mean()
D_train_loss = D_real_loss + D_fake_loss
D_train_loss.backward()
D_optimizer.step()
D_losses.append(D_train_loss.data[0])
# train generator G
G.zero_grad()
z_ = torch.rand((mini_batch, 100))
y_ = (torch.rand(mini_batch, 1) * 10).type(torch.LongTensor)
y_label_ = torch.zeros(mini_batch, 10)
y_label_.scatter_(1, y_.view(mini_batch, 1), 1)
z_, y_label_ = Variable(z_.cuda()), Variable(y_label_.cuda())
G_result = G(z_, y_label_)
D_result = D(G_result, y_label_).squeeze()
G_train_loss = BCE_loss(D_result, y_real_)
G_train_loss.backward()
G_optimizer.step()
G_losses.append(G_train_loss.data[0])
epoch_end_time = time.time()
per_epoch_ptime = epoch_end_time - epoch_start_time
print('[%d/%d] - ptime: %.2f, loss_d: %.3f, loss_g: %.3f' % ((epoch + 1), train_epoch, per_epoch_ptime, torch.mean(torch.FloatTensor(D_losses)),
torch.mean(torch.FloatTensor(G_losses))))
fixed_p = 'MNIST_cGAN_results/Fixed_results/MNIST_cGAN_' + str(epoch + 1) + '.png'
show_result((epoch+1), save=True, path=fixed_p)
train_hist['D_losses'].append(torch.mean(torch.FloatTensor(D_losses)))
train_hist['G_losses'].append(torch.mean(torch.FloatTensor(G_losses)))
train_hist['per_epoch_ptimes'].append(per_epoch_ptime)
end_time = time.time()
total_ptime = end_time - start_time
train_hist['total_ptime'].append(total_ptime)
print("Avg one epoch ptime: %.2f, total %d epochs ptime: %.2f" % (torch.mean(torch.FloatTensor(train_hist['per_epoch_ptimes'])), train_epoch, total_ptime))
print("Training finish!... save training results")
torch.save(G.state_dict(), "MNIST_cGAN_results/generator_param.pkl")
torch.save(D.state_dict(), "MNIST_cGAN_results/discriminator_param.pkl")
with open('MNIST_cGAN_results/train_hist.pkl', 'wb') as f:
pickle.dump(train_hist, f)
show_train_hist(train_hist, save=True, path='MNIST_cGAN_results/MNIST_cGAN_train_hist.png')
images = []
for e in range(train_epoch):
img_name = 'MNIST_cGAN_results/Fixed_results/MNIST_cGAN_' + str(e + 1) + '.png'
images.append(imageio.imread(img_name))
imageio.mimsave('MNIST_cGAN_results/generation_animation.gif', images, fps=5)
5、结束
以上,就是CGAN这篇论文的全部内容了,如有问题,还望指出,阿里嘎多!


开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 33
33 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)