[大模型]Qwen-7B-Chat 接入langchain搭建知识库助手
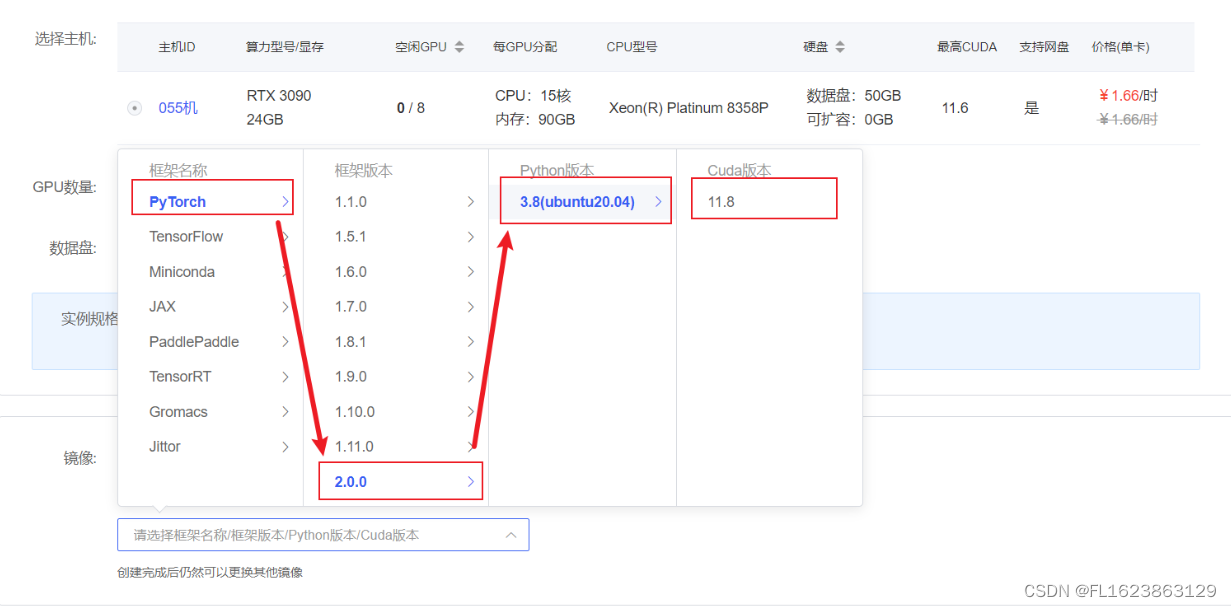
在autodl平台中租一个3090等24G显存的显卡机器,如下图所示镜像选择PyTorch–>2.0.0–>3.8(ubuntu20.04)–>11.8接下来打开刚刚租用服务器的JupyterLab,并且打开其中的终端开始环境配置、模型下载和运行demo。pip换源和安装依赖包。
Qwen-7B-Chat 接入langchain搭建知识库助手
环境准备
在autodl平台中租一个3090等24G显存的显卡机器,如下图所示镜像选择PyTorch–>2.0.0–>3.8(ubuntu20.04)–>11.8

接下来打开刚刚租用服务器的JupyterLab,并且打开其中的终端开始环境配置、模型下载和运行demo。
pip换源和安装依赖包
# 升级pip
python -m pip install --upgrade pip
# 更换 pypi 源加速库的安装
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install modelscope==1.9.5
pip install "transformers>=4.32.0" accelerate tiktoken einops scipy transformers_stream_generator==0.0.4 peft deepspeed
pip install -U huggingface_hub
模型下载
在已完成Qwen-7B-chat部署的基础上,我们还需要还需要安装以下依赖包。
请在终端复制粘贴以下命令,并按回车运行:
pip install langchain==0.0.292
pip install gradio==4.4.0
pip install chromadb==0.4.15
pip install sentence-transformers==2.2.2
pip install unstructured==0.10.30
pip install markdown==3.3.7
同时,我们还需要使用到开源词向量模型 Sentence Transformer
这里使用huggingface镜像下载到本地 /root/autodl-tmp/embedding_model,你也可以选择其它的方式下载
在 /root/autodl-tmp 路径下新建 download.py 文件并在其中输入以下内容,粘贴代码后记得保存文件,如下图所示。并运行 python /root/autodl-tmp/download.py执行下载。
import os
# 设置环境变量
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
# 下载模型
os.system('huggingface-cli download --resume-download sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 --local-dir /root/autodl-tmp/embedding_model')
使用 modelscope 中的snapshot_download函数下载模型,第一个参数为模型名称,参数cache_dir为模型的下载路径。
在 /root/autodl-tmp 路径下新建 download.py 文件并在其中输入以下内容,粘贴代码后记得保存文件,如下图所示。并运行 python /root/autodl-tmp/download.py执行下载,模型大小为 15 GB,下载模型大概需要 10~20 分钟
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
import os
model_dir = snapshot_download('qwen/Qwen-7B-Chat', cache_dir='/root/autodl-tmp', revision='master')
知识库建设
我们选用以下两个开源仓库作为知识库来源
首先我们需要将上述远程开源仓库 Clone 到本地,可以使用以下命令:
# 进入到数据库盘
cd /root/autodl-tmp
# 打开学术资源加速
source /etc/network_turbo
# clone 开源仓库
git clone https://github.com/QwenLM/Qwen.git
# 关闭学术资源加速
unset http_proxy && unset https_proxy
接着,为语料处理方便,我们将选用上述仓库中所有的 markdown、txt 文件作为示例语料库。注意,也可以选用其中的代码文件加入到知识库中,但需要针对代码文件格式进行额外处理。
我们首先将上述仓库中所有满足条件的文件路径找出来,我们定义一个函数,该函数将递归指定文件夹路径,返回其中所有满足条件(即后缀名为 .md 或者 .txt 的文件)的文件路径:
import os
def get_files(dir_path):
# args:dir_path,目标文件夹路径
file_list = []
for filepath, dirnames, filenames in os.walk(dir_path):
# os.walk 函数将递归遍历指定文件夹
for filename in filenames:
# 通过后缀名判断文件类型是否满足要求
if filename.endswith(".md"):
# 如果满足要求,将其绝对路径加入到结果列表
file_list.append(os.path.join(filepath, filename))
elif filename.endswith(".txt"):
file_list.append(os.path.join(filepath, filename))
return file_list
得到所有目标文件路径之后,我们可以使用 LangChain 提供的 FileLoader 对象来加载目标文件,得到由目标文件解析出的纯文本内容。由于不同类型的文件需要对应不同的 FileLoader,我们判断目标文件类型,并针对性调用对应类型的 FileLoader,同时,调用 FileLoader 对象的 load 方法来得到加载之后的纯文本对象:
from tqdm import tqdm
from langchain.document_loaders import UnstructuredFileLoader
from langchain.document_loaders import UnstructuredMarkdownLoader
def get_text(dir_path):
# args:dir_path,目标文件夹路径
# 首先调用上文定义的函数得到目标文件路径列表
file_lst = get_files(dir_path)
# docs 存放加载之后的纯文本对象
docs = []
# 遍历所有目标文件
for one_file in tqdm(file_lst):
file_type = one_file.split('.')[-1]
if file_type == 'md':
loader = UnstructuredMarkdownLoader(one_file)
elif file_type == 'txt':
loader = UnstructuredFileLoader(one_file)
else:
# 如果是不符合条件的文件,直接跳过
continue
docs.extend(loader.load())
return docs
使用上文函数,我们得到的 docs 为一个纯文本对象对应的列表。得到该列表之后,我们就可以将它引入到 LangChain 框架中构建向量数据库。由纯文本对象构建向量数据库,我们需要先对文本进行分块,接着对文本块进行向量化。
LangChain 提供了多种文本分块工具,此处我们使用字符串递归分割器,并选择分块大小为 500,块重叠长度为 150:
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, chunk_overlap=150)
split_docs = text_splitter.split_documents(docs)
接着我们选用开源词向量模型 Sentence Transformer 来进行文本向量化
LangChain 提供了直接引入 HuggingFace 开源社区中的模型进行向量化的接口:
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(model_name="/root/autodl-tmp/embedding_model")
同时,我们选择 Chroma 作为向量数据库,基于上文分块后的文档以及加载的开源向量化模型,将语料加载到指定路径下的向量数据库:
from langchain.vectorstores import Chroma
# 定义持久化路径
persist_directory = 'data_base/vector_db/chroma'
# 加载数据库
vectordb = Chroma.from_documents(
documents=split_docs,
embedding=embeddings,
persist_directory=persist_directory # 允许我们将persist_directory目录保存到磁盘上
)
# 将加载的向量数据库持久化到磁盘上
vectordb.persist()
将上述代码整合在一起为知识库搭建的脚本:
# 首先导入所需第三方库
from langchain.document_loaders import UnstructuredFileLoader
from langchain.document_loaders import UnstructuredMarkdownLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from tqdm import tqdm
import os
# 获取文件路径函数
def get_files(dir_path):
# args:dir_path,目标文件夹路径
file_list = []
for filepath, dirnames, filenames in os.walk(dir_path):
# os.walk 函数将递归遍历指定文件夹
for filename in filenames:
# 通过后缀名判断文件类型是否满足要求
if filename.endswith(".md"):
# 如果满足要求,将其绝对路径加入到结果列表
file_list.append(os.path.join(filepath, filename))
elif filename.endswith(".txt"):
file_list.append(os.path.join(filepath, filename))
return file_list
# 加载文件函数
def get_text(dir_path):
# args:dir_path,目标文件夹路径
# 首先调用上文定义的函数得到目标文件路径列表
file_lst = get_files(dir_path)
# docs 存放加载之后的纯文本对象
docs = []
# 遍历所有目标文件
for one_file in tqdm(file_lst):
file_type = one_file.split('.')[-1]
if file_type == 'md':
loader = UnstructuredMarkdownLoader(one_file)
elif file_type == 'txt':
loader = UnstructuredFileLoader(one_file)
else:
# 如果是不符合条件的文件,直接跳过
continue
docs.extend(loader.load())
return docs
# 目标文件夹
tar_dir = [
"/root/autodl-tmp/qwen",
"/root/autodl-tmp/Qwen",
]
# 加载目标文件
docs = []
for dir_path in tar_dir:
docs.extend(get_text(dir_path))
# 对文本进行分块
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, chunk_overlap=150)
split_docs = text_splitter.split_documents(docs)
# 加载开源词向量模型
embeddings = HuggingFaceEmbeddings(model_name="/root/autodl-tmp/embedding_model")
# 构建向量数据库
# 定义持久化路径
persist_directory = 'data_base/vector_db/chroma'
# 加载数据库
vectordb = Chroma.from_documents(
documents=split_docs,
embedding=embeddings,
persist_directory=persist_directory # 允许我们将persist_directory目录保存到磁盘上
)
# 将加载的向量数据库持久化到磁盘上
vectordb.persist()
运行上述脚本,即可在本地构建已持久化的向量数据库,后续直接导入该数据库即可,无需重复构建。
QwenLM 接入LangChain
为便捷构建 LLM 应用,我们需要基于本地部署的 QwenLM,自定义一个 LLM 类,将 QwenLM 接入到 LangChain 框架中。完成自定义 LLM 类之后,可以以完全一致的方式调用 LangChain 的接口,而无需考虑底层模型调用的不一致。
基于本地部署的 QwenLM 自定义 LLM 类并不复杂,我们只需从 LangChain.llms.base.LLM 类继承一个子类,并重写构造函数与 _call 函数即可:
from langchain.llms.base import LLM
from typing import Any, List, Optional
from langchain.callbacks.manager import CallbackManagerForLLMRun
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
class QwenLM(LLM):
# 基于本地 Qwen 自定义 LLM 类
tokenizer : AutoTokenizer = None
model: AutoModelForCausalLM = None
def __init__(self, model_path :str):
# model_path: Qwen 模型路径
# 从本地初始化模型
super().__init__()
print("正在从本地加载模型...")
model_dir = '/root/autodl-tmp/qwen/Qwen-7B-Chat'
self.tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
self.model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True).eval()
# Specify hyperparameters for generation
self.model.generation_config = GenerationConfig.from_pretrained(model_dir, trust_remote_code=True) # 可指定不同的生成长度、top_p等相关超参
print("完成本地模型的加载")
def _call(self, prompt : str, stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any):
# 重写调用函数
response, history = self.model.chat(self.tokenizer, prompt , history=[])
return response
@property
def _llm_type(self) -> str:
return "QwenLM"
在上述类定义中,我们分别重写了构造函数和 _call 函数:对于构造函数,我们在对象实例化的一开始加载本地部署的 Qwen 模型,从而避免每一次调用都需要重新加载模型带来的时间过长;_call 函数是 LLM 类的核心函数,LangChain 会调用该函数来调用 LLM,在该函数中,我们调用已实例化模型的 chat 方法,从而实现对模型的调用并返回调用结果。
在整体项目中,我们将上述代码封装为 LLM.py,后续将直接从该文件中引入自定义的 LLM 类。
构建检索问答链
LangChain 通过提供检索问答链对象来实现对于 RAG 全流程的封装。即我们可以调用一个 LangChain 提供的 RetrievalQA 对象,通过初始化时填入已构建的数据库和自定义 LLM 作为参数,来简便地完成检索增强问答的全流程,LangChain 会自动完成基于用户提问进行检索、获取相关文档、拼接为合适的 Prompt 并交给 LLM 问答的全部流程。
首先我们需要将上文构建的向量数据库导入进来,我们可以直接通过 Chroma 以及上文定义的词向量模型来加载已构建的数据库:
from langchain.vectorstores import Chroma
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
import os
# 定义 Embeddings
embeddings = HuggingFaceEmbeddings(model_name="/root/autodl-tmp/embedding_model")
# 向量数据库持久化路径
persist_directory = 'data_base/vector_db/chroma'
# 加载数据库
vectordb = Chroma(
persist_directory=persist_directory,
embedding_function=embeddings
)
上述代码得到的 vectordb 对象即为我们已构建的向量数据库对象,该对象可以针对用户的 query 进行语义向量检索,得到与用户提问相关的知识片段。
接着,我们实例化一个基于 QwenLM 自定义的 LLM 对象:
from LLM import QwenLM
llm = QwenLM(model_path = "/root/autodl-tmp/qwen")
llm.predict("你是谁")
构建检索问答链,还需要构建一个 Prompt Template,该 Template 其实基于一个带变量的字符串,在检索之后,LangChain 会将检索到的相关文档片段填入到 Template 的变量中,从而实现带知识的 Prompt 构建。我们可以基于 LangChain 的 Template 基类来实例化这样一个 Template 对象:
from langchain.prompts import PromptTemplate
# 我们所构造的 Prompt 模板
template = """使用以下上下文来回答最后的问题。如果你不知道答案,就说你不知道,不要试图编造答案。尽量使答案简明扼要。总是在回答的最后说“谢谢你的提问!”。
{context}
问题: {question}
有用的回答:"""
# 调用 LangChain 的方法来实例化一个 Template 对象,该对象包含了 context 和 question 两个变量,在实际调用时,这两个变量会被检索到的文档片段和用户提问填充
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],template=template)
最后,可以调用 LangChain 提供的检索问答链构造函数,基于我们的自定义 LLM、Prompt Template 和向量知识库来构建一个基于 Qwen 的检索问答链:
from langchain.chains import RetrievalQA
qa_chain = RetrievalQA.from_chain_type(llm,retriever=vectordb.as_retriever(),return_source_documents=True,chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})
得到的 qa_chain 对象即可以实现我们的核心功能,即基于 QwenLM 模型的专业知识库助手。我们可以对比该检索问答链和纯 LLM 的问答效果:
question = "什么是QwenLM"
result = qa_chain({"query": question})
print("检索问答链回答 question 的结果:")
print(result["result"])
# 仅 LLM 回答效果
result_2 = llm(question)
print("大模型回答 question 的结果:")
print(result_2)

可以看到,使用检索问答链生成的答案更接近知识库里的内容。
部署WebDemo
在完成上述核心功能后,我们可以基于 Gradio 框架将其部署到 Web 网页,从而搭建一个小型 Demo,便于测试与使用。
我们首先将上文的代码内容封装为一个返回构建的检索问答链对象的函数,并在启动 Gradio 的第一时间调用该函数得到检索问答链对象,后续直接使用该对象进行问答对话,从而避免重复加载模型:
# 导入必要的库
import gradio as gr
from langchain.vectorstores import Chroma
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
import os
from LLM import QwenLM
from langchain.prompts import PromptTemplate
def load_chain():
# 加载问答链
# 定义 Embeddings
embeddings = HuggingFaceEmbeddings(model_name="/root/autodl-tmp/embedding_model")
# 向量数据库持久化路径
persist_directory = 'data_base/vector_db/chroma'
# 加载数据库
vectordb = Chroma(
persist_directory=persist_directory, # 允许我们将persist_directory目录保存到磁盘上
embedding_function=embeddings
)
llm = QwenLM(model_path = "/root/autodl-tmp/qwen")
template = """使用以下上下文来回答最后的问题。如果你不知道答案,就说你不知道,不要试图编造答
案。尽量使答案简明扼要。总是在回答的最后说“谢谢你的提问!”。
{context}
问题: {question}
有用的回答:"""
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],
template=template)
# 运行 chain
from langchain.chains import RetrievalQA
qa_chain = RetrievalQA.from_chain_type(llm,
retriever=vectordb.as_retriever(),
return_source_documents=True,
chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})
return qa_chain
接着我们定义一个类,该类负责加载并存储检索问答链,并响应 Web 界面里调用检索问答链进行回答的动作:
class Model_center():
"""
存储问答 Chain 的对象
"""
def __init__(self):
self.chain = load_chain()
def qa_chain_self_answer(self, question: str, chat_history: list = []):
"""
调用不带历史记录的问答链进行回答
"""
if question == None or len(question) < 1:
return "", chat_history
try:
chat_history.append(
(question, self.chain({"query": question})["result"]))
return "", chat_history
except Exception as e:
return e, chat_history
def clear_history(self):
self.chain.clear_history()
然后我们只需按照 Gradio 的框架使用方法,实例化一个 Web 界面并将点击动作绑定到上述类的回答方法即可:
import gradio as gr
model_center = Model_center()
block = gr.Blocks()
with block as demo:
with gr.Row(equal_height=True):
with gr.Column(scale=15):
gr.Markdown("""<h1><center>QwenLM</center></h1>
<center>通义千问</center>
""")
# gr.Image(value=LOGO_PATH, scale=1, min_width=10,show_label=False, show_download_button=False)
with gr.Row():
with gr.Column(scale=4):
chatbot = gr.Chatbot(height=450, show_copy_button=True)
# 创建一个文本框组件,用于输入 prompt。
msg = gr.Textbox(label="Prompt/问题")
with gr.Row():
# 创建提交按钮。
db_wo_his_btn = gr.Button("Chat")
with gr.Row():
# 创建一个清除按钮,用于清除聊天机器人组件的内容。
clear = gr.ClearButton(
components=[chatbot], value="Clear console")
# 设置按钮的点击事件。当点击时,调用上面定义的 qa_chain_self_answer 函数,并传入用户的消息和聊天历史记录,然后更新文本框和聊天机器人组件。
db_wo_his_btn.click(model_center.qa_chain_self_answer, inputs=[msg, chatbot], outputs=[msg, chatbot])
# 点击后清空后端存储的聊天记录
clear.click(model_center.clear_history)
gr.Markdown("""提醒:<br>
1. 初始化数据库时间可能较长,请耐心等待。
2. 使用中如果出现异常,将会在文本输入框进行展示,请不要惊慌。 <br>
""")
# threads to consume the request
gr.close_all()
# 启动新的 Gradio 应用,设置分享功能为 True,并使用环境变量 PORT1 指定服务器端口。
# demo.launch(share=True, server_port=int(os.environ['PORT1']))
# 直接启动
demo.launch()
通过将上述代码封装为 run_gradio.py 脚本,直接通过在终端运行命令 python run_gradio.py ,即可在本地启动知识库助手的 Web Demo,默认会在 7860 端口运行,使用类似于部署的方式将服务器端口映射到本地端口即可访问:


开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐

 31
31 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)