多模态情感分析——基于交叉多头注意力CMA进行图文多模态融合(含MVSA数据集)
由两个独立的数据集组成,分别是MVSA-Single数据集和 MVSA-Multi数据集,前者的每条图文对只有一个标注,后者的每条图文对由三个标注者给出。删除 MVSA-Single 数据集中图片和文字标注情感的正负极性不同(存在positive和negative)的图文对,剩余的图文对中,如果图片或者文本的情感有一者为中性(neutral),则选择另一个积极或者消极的标签作为该图文对的情感标签,
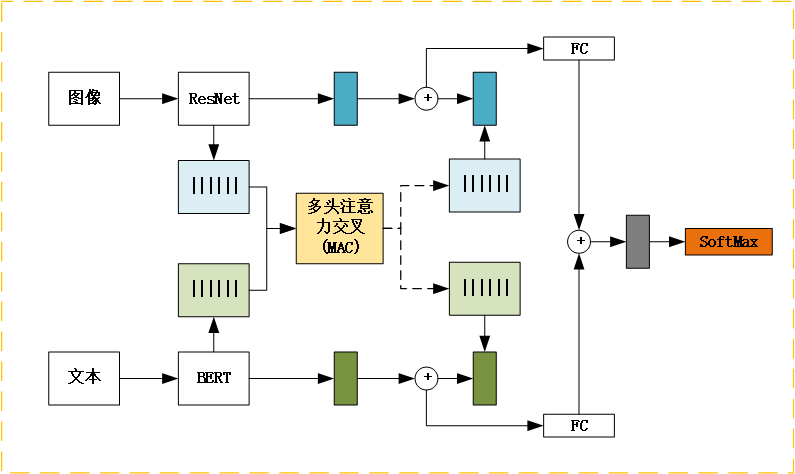
1.模型结构
模型以BERT系列和ResNet系列为基础,分别处理文本和图像输入。文本处理模块基于预训练的BERT系列模型进行文本特征提取,并通过一个全连接层进行进一步的特征变换。图像处理模块采用预训练的ResNet系列模型,提取图像特征,并进行特征变换。多模态融合模块利用交叉多头注意力机制(CMA)将文本和图像特征进行融合,并通过全连接层进行分类。

2.对比模型
(1)图文特征直接进行拼接:TICat
text_feature = self.text_model(texts, texts_mask)
img_feature = self.img_model(imgs)
prob_vec = self.classifier(torch.cat([text_feature, img_feature], dim=1))
pred_labels = torch.argmax(prob_vec, dim=1)(2)图文特征进行加和:TIAdd
text_feature = self.text_model(texts, texts_mask)
img_feature = self.img_model(imgs)
text_prob_vec = self.text_classifier(text_feature)
img_prob_vec = self.img_classifier(img_feature)
prob_vec = torch.softmax((text_prob_vec + img_prob_vec), dim=1)
pred_labels = torch.argmax(prob_vec, dim=1)3.数据集介绍
数据集链接:
https://mcrlab.net/research/mvsa-sentiment-analysis-on-multi-view-social-data/
数据集介绍:由两个独立的数据集组成,分别是MVSA-Single数据集和 MVSA-Multi数据集,前者的每条图文对只有一个标注,后者的每条图文对由三个标注者给出。官方声明MVSA-Single数据集包含 5,129 条图文对(实际只有4869条),MVSA-Multi 包含了 19,600 条图文对(实际19600条)。
(1)MVSA-Single数据集
删除 MVSA-Single 数据集中图片和文字标注情感的正负极性不同(存在positive和negative)的图文对,剩余的图文对中,如果图片或者文本的情感有一者为中性(neutral),则选择另一个积极或者消极的标签作为该图文对的情感标签,最终得到4511个图文对。
(2)MVSA-Multi数据集
采用投票机制,即有 2 个或 2 个以上的标注者给出的情感极性标注一致,则保留该条数据,否则删除。先基于MVSA-Single 的方法确定每个人的标签,然后根据三个人统计结果进行投票,最终得到17510个图文对。
注:由于数据集中存在损坏图片:3151.jpg、3910.jpg、5995.jpg,因此将其进行去除,最终实际得到17507个图文对。
4.MAC运行结果
本次实验,文本选择albert-base-v2,图像选择resnet-152,按照8:1:1进行划分,其他情况请自行测试。具体参数设置如下:
def init_argparse():
# args
parser = argparse.ArgumentParser()
parser.add_argument('--do_train', action='store_true', help='训练模型')
parser.add_argument('--text_pretrained_model', default='roberta-base', help='文本分析模型', type=str)
parser.add_argument('--fuse_model_type', default='CMA', help='融合模型类别', type=str)
parser.add_argument('--lr', default=5e-5, help='设置学习率', type=float)
parser.add_argument('--weight_decay', default=1e-2, help='设置权重衰减', type=float)
parser.add_argument('--epoch', default=10, help='设置训练轮数', type=int)
parser.add_argument('--seed', default=42, help='设置随机种子', type=int)
parser.add_argument('--do_test', action='store_true', help='预测测试集数据')
parser.add_argument('--load_model_path', default=None, help='已经训练好的模型路径', type=str)
parser.add_argument('--text_only', action='store_true', help='仅用文本预测')
parser.add_argument('--img_only', action='store_true', help='仅用图像预测')
return parser(1)MVSA-Single数据集(8:1:1划分)
![]()
之所以比实际数量多1,是因为统计了首行表头“guid,tag”。运行结束后会将结果保存在output文件夹,包含训练集和验证集每轮的loss值和acc值,以及权重文件。

经过10轮生成的结果如下:



测试集混淆矩阵

(2)MVSA-multiple数据集(8:1:1划分)
![]()
之所以比实际数量多1,是因为统计了首行表头“guid,tag”。运行结束后会将结果保存在output文件夹,包含训练集和验证集每轮的loss值和acc值,以及权重文件。



测试集混淆矩阵

5.对比结果(RoBERT+ResNet152)

6.完整内容获取
多模态情感分析——基于交叉多头注意力CMA进行图文多模态融合(含MVSA数据集)
小编会不定期发布相关设计内容包括但不限于如下内容:信号处理、通信仿真、算法设计、matlab appdesigner,gui设计、simulink仿真......希望能帮到你!


开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 12
12 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)