
【MySQL】17-超详细的MySQL聚合函数总结
超详细的MySQL聚合函数总结,以及SELECT语句的语句结构和执行顺序的讲解。

目录
上一篇博文介绍了MySQL中的单行函数,这一章介绍MySQL中的多行函数,也称为聚合函数,是一种多进单出的函数 (如查询所有员工中工资最大的那一个员工) 。
1. 聚合函数介绍
这里我们只介绍常用的几个聚合函数。
1.1 AVG和SUM函数
| 函数 | 作用 |
|---|---|
| AVG() | 返回该字段的平均值 |
| SUM() | 返回该字段的总和 |
【注意】
AVG和SUM函数只适用于数值类型的字段,对字符串和日期时间类型的字段使用这些函数是没有意义的,在Oracle中甚至会直接报错。
举个栗子:
SELECT AVG(salary), SUM(salary)
FROM employees;
查询结果:

1.2 MIN和MAX函数
| 函数 | 作用 |
|---|---|
| MIN() | 返回该字段的最小值 |
| MAX() | 返回该字段的最大值 |
MIN和MAX函数支持数值类型、字符串类型 (ASCII码值) 和日期时间类型的字段。
举个栗子:
SELECT MAX(salary), MIN(salary),
MAX(last_name), MIN(last_name),
MAX(hire_date), MIN(hire_date)
FROM employees;
查询结果:

1.3 COUNT函数
COUNT函数作用是统计指定字段在查询结果中出现的个数。也就是查询结果有多少条记录。
举个栗子:
SELECT COUNT(employee_id), COUNT(salary)
FROM employees;
查询结果:

如果COUNT()函数括号内是数字、字符串或者 * 号,是能统计表中一共有多少条数据的。如下代码所示:
SELECT COUNT('a'), COUNT(*), COUNT(1)
FROM employees;
查询结果:

【注意】
如果字段中有NULL,那么COUNT()函数只会计算该字段中不是NULL的数据的个数。
举个栗子:
SELECT COUNT(commission_pct)
FROM employees;
查询结果:

- 公式:AVG() = SUM() / COUNT()
举个栗子:
SELECT AVG(commission_pct), SUM(commission_pct) / COUNT(commission_pct)
FROM employees;
查询结果:

但是这个计算结果,意思是计算公司内有奖金的员工的平均奖金率。而如果要计算公司所有员工 (包括没有奖金的员工) 的评价奖金率,我们应该进行如下的计算:
# 方式一
SELECT SUM(commission_pct) / COUNT(IFNULL(commission_pct, 0)) AS "avg_pct"
FROM employees;
# 方式二
SELECT AVG(IFNULL(commission_pct, 0)) AS "avg_pct"
FROM employees;
查询结果:

统计表中的记录数,上面介绍了3种方式:COUNT(*) 、COUNT(1) 和 COUNT(具体字段) 。那么这里有一个自然的问题:这三种方式那个效率更高呢?
- 如果使用的是 MyISAM 存储引擎,则三者效率相同,都是 O ( 1 ) O(1) O(1) 。因为MyISAM中专门有一个变量实时记录表的行数。
- 如果使用的是 InnoDB 存储引擎,则三者效率从高到低分别是:COUNT(*) = COUNT(1) > COUNT(具体字段) 。
2. GROUP BY
GROUP BY是对某个字段进行分组操作。上一节中的求平均函数 AVG() 函数针对的都是整个员工表 employees 的平均工资,那么有没有办法查询某个部门 department_id 或某个工种 job_id 的员工的平均工资呢?只需要使用关键字 GROUP BY 对字段进行分组即可。
2.1 基本使用
【例子1】想查询员工表 employees 中各个部门的平均工资和最高工资。如下图所示:

SELECT department_id, AVG(salary), MAX(salary)
FROM employees
GROUP BY department_id;
查询结果:

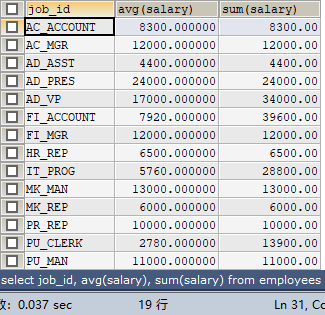
【例子2】查询员工表 employees 中各个工种 job_id 的平均工资和工资总和。
SELECT job_id, AVG(salary), SUM(salary)
FROM employees
GROUP BY job_id;
查询结果:
2.2 使用多个列分组
上一节中只是按照一个字段 (如部门 department_id 或 工种 job_id ) 进行分组。那有没有可能,可以先按照部门 department_id 分组,再按照工种 job_id 分组呢?答案是可以的。
在MySQL中,只需要在关键字 GROUP BY 后添加你想要分组的所有字段,并用逗号分隔,即可实现多列分组。
举个栗子:查询各个部门 department_id 中各个工种 job_id 的平均工资。
SELECT department_id, job_id, AVG(salary)
FROM employees
GROUP BY department_id, job_id;
查询结果:

【注意】
department_id和job_id的先后顺序对查询结果没有影响。
【知识点2】SELECT中出现的非组函数的字段必须声明在 GROUP BY 中;反之,GROUP BY中声明的字段可以不出现在SELECT中。
举个例子,下面的代码中是错误的:
SELECT department_id, job_id, AVG(salary)
FROM employees
GROUP BY department_id;
第3行中只对部门 department_id 进行了分组,意思是查询各个部门的平均工资。而第1行代码中却又加了查询工种 job_id 字段,这是错误且没有意义的。
查询结果:

虽然在MySQL中没有报错,但是在Oracle是会报错的。
【知识点3】GROUP BY 声明位置在FROM后面、WHERE后面、ORDER BY前面、LIMIT前面。
2.3 GROUP BY中使用WITH ROLLUP
WITH ROLLUP 关键字声明在 GROUP BY 最后面,意思是除了查询各个分组的信息,还会查询整个表的信息。
举个栗子:查询员工表 employees 中各个部门的平均工资。加上WITH ROLLUP后,在查询结果表的最后一行会加上所有员工的平均工资。
SELECT department_id, AVG(salary)
FROM employees
GROUP BY department_id WITH ROLLUP;
查询结果:

【注意】
WITH ROLLUP与ORDER BY是相互排斥的。这两个关键字不能同时使用。
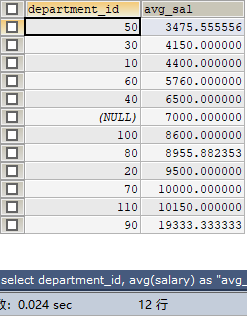
举个栗子:查询员工表 employees 中各个部门的平均工资,并按平均工资从低到高排列。在MySQL5.7中会报错,在MySQL8.0中会把全员工的平均工资参与排序。
# 正确写法
SELECT department_id, AVG(salary) AS "avg_sal"
FROM employees
GROUP BY department_id
ORDER BY avg_sal ASC;
查询结果:
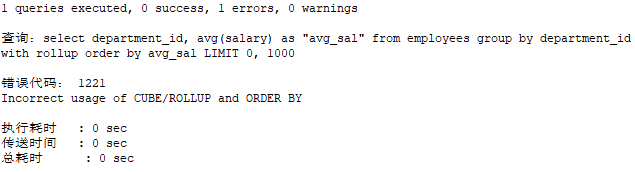
【MySQL8.0】
SELECT department_id, AVG(salary) AS "avg_sal"
FROM employees
GROUP BY department_id WITH ROLLUP
ORDER BY avg_sal ASC;
查询结果:

【MySQL5.7】
SELECT department_id, AVG(salary) AS "avg_sal"
FROM employees
GROUP BY department_id WITH ROLLUP
ORDER BY avg_sal;
查询结果:
3. HAVING
HAVING关键字的作用是过滤数据。与WHERE不同,HAVING是与GROUP BY结合使用的。
3.1 基本使用
【例子1】查询员工表 employees 中各个部门中最高工资比10000高的部门信息。
# 错误的写法1
SELECT department_id, MAX(salary) AS "max_sal"
FROM employees
GROUP BY department_id
WHERE max_sal > 10000;
# 错误的写法2
SELECT department_id, MAX(salary)
FROM employees
GROUP BY department_id
WHERE MAX(salary) > 10000;
查询结果:

【结论1】
如果过滤条件中使用了聚合函数,则必须使用HAVING来替换WHERE。否则报错。
HAVING必须放在GROUP BY后面。
# 正确的写法1
SELECT department_id, MAX(salary) AS "max_sal"
FROM employees
GROUP BY department_id
HAVING max_sal > 10000;
# 正确的写法2
SELECT department_id, MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary) > 10000;
查询结果:

【注意】
虽说HAVING与GROUP BY结合使用,但没有GROUP BY的情况下,使用HAVING并不会报错。但是这样做没有意义。
SELECT last_name, salary
FROM employees
HAVING salary > 8000;
查询结果:

【例子2】查询员工表 employees 中各个部门编号 department_id 为 10, 20, 30, 40 的这四个部门中最高工资比10000高的部门信息。
# 方式一:推荐,执行效率高于方式二
SELECT department_id, MAX(salary)
FROM employees
WHERE department_id IN(10, 20, 30, 40)
GROUP BY department_id
HAVING MAX(salary) > 10000;
# 方式二
SELECT department_id, MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary) > 10000 AND department_id IN(10, 20, 30, 40);
查询结果:

【结论】
- 当过滤条件中有聚合函数时,过滤条件必须写在HAVING中。
- 当过滤条件中没有聚合函数时,过滤条件写在HAVING和WHERE中都可以。但是建议优先写在WHERE中,因为WHERE执行效率比HAVING高。
3.2 WHERE和HAVING的对比
- 从适用范围上来讲,HAVING的适用范围比WHERE更广。因为HAVING既可以写聚合函数的过滤条件,又可以写非聚合函数的过滤条件。而WHERE只能写非聚合函数的过滤条件。
- 如果过滤条件都是非聚合函数的前提下,WHERE的执行效率要比HAVING高。
4. SELECT的执行过程
4.1 查询的结构
学习至今,SQL中的所有基础查询操作都已经介绍完毕了。总结一下学习过的所有查询语句,其结构顺序如下代码所示:
# SQL92语法
SELECT ..., ..., ...(存在聚合函数)
FROM ..., ...
WHERE 多表查询的连接条件 AND 不包含聚合函数的过滤条件
GROUP BY ..., ...
HAVING 包含聚合函数的过滤条件
ORDER BY ..., ...(ASC / DESC)
LIMIT ..., ...
# SQL99语法
SELECT ..., ..., ...(存在聚合函数)
FROM ... (LEFT / RIGHT OUTER)JOIN ... ON 多表查询的连接条件
(LEFT / RIGHT OUTER)JOIN ... ON 多表查询的连接条件
WHERE 不包含聚合函数的过滤条件
GROUP BY ..., ...
HAVING 包含聚合函数的过滤条件
ORDER BY ..., ...(ASC / DESC)
LIMIT ..., ...
上述关键字的顺序不能错,否则会报错。
4.2 SELECT执行顺序
下面的内容是查询章节的核心内容。理解了这节的内容,前面很多问题都能得到解答。
在SQL中,查询语句的执行顺序并不是按顺序从上往下执行的。SELECT语句的实行顺序为:
FROM --> ON --> (LEFT / RIGHT OUTER)JOIN --> WHERE --> GROUP BY --> HAVING --> SELECT --> DISTINCT --> ORDER BY --> LIMIT
- 执行顺序在前的别名可以用在执行顺序在后的语句中。这就解释了为什么SELECT中起的别名能在ORDER BY中使用,却不能在WHERE中使用。因为WHERE的执行顺序在SELECT的前面,ORDER BY在SELECT的后面。
- 这也解释了为什么使用WHERE要比HAVING效率高。WHERE在前面先过滤了很多不要的数据,再进行分组,防止为很多的数据分好组,却被过滤掉而做无用功。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 8
8 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)