我把面试问烂了的⭐Spring面试题⭐总结了一下(带答案,万字总结,精心打磨,建议收藏)
我把面试问烂了的⭐Spring⭐面试题总结了一下(带答案,万字总结,精心打磨,建议收藏)
💂 个人主页: Java程序鱼
💬 如果文章对你有帮助,欢迎关注、点赞、收藏(一键三连)和订阅专栏
👤 微信号:hzy1014211086,想加入技术交流群的小伙伴可以加我好友,群里会分享学习资料、学习方法
| 序号 | 内容 | 链接地址 |
|---|---|---|
| 1 | Java基础知识面试题 | https://blog.csdn.net/qq_35620342/article/details/119636436 |
| 2 | Java集合容器面试题 | https://blog.csdn.net/qq_35620342/article/details/119947254 |
| 3 | Java并发编程面试题 | https://blog.csdn.net/qq_35620342/article/details/119977224 |
| 4 | Java异常面试题 | https://blog.csdn.net/qq_35620342/article/details/119977051 |
| 5 | JVM面试题 | https://blog.csdn.net/qq_35620342/article/details/119948989 |
| 6 | Java Web面试题 | https://blog.csdn.net/qq_35620342/article/details/119642114 |
| 7 | Spring面试题 | https://blog.csdn.net/qq_35620342/article/details/119956512 |
| 8 | Spring MVC面试题 | https://blog.csdn.net/qq_35620342/article/details/119965560 |
| 9 | Spring Boot面试题 | https://blog.csdn.net/qq_35620342/article/details/120333717 |
| 10 | MyBatis面试题 | https://blog.csdn.net/qq_35620342/article/details/119956541 |
| 11 | Spring Cloud面试题 | 待分享 |
| 12 | Redis面试题 | https://blog.csdn.net/qq_35620342/article/details/119575020 |
| 13 | MySQL数据库面试题 | https://blog.csdn.net/qq_35620342/article/details/119930887 |
| 14 | RabbitMQ面试题 | 待分享 |
| 15 | Dubbo面试题 | 待分享 |
| 16 | Linux面试题 | 待分享 |
| 17 | Tomcat面试题 | 待分享 |
| 18 | ZooKeeper面试题 | 待分享 |
| 19 | Netty面试题 | 待分享 |
| 20 | 数据结构与算法面试题 | 待分享 |
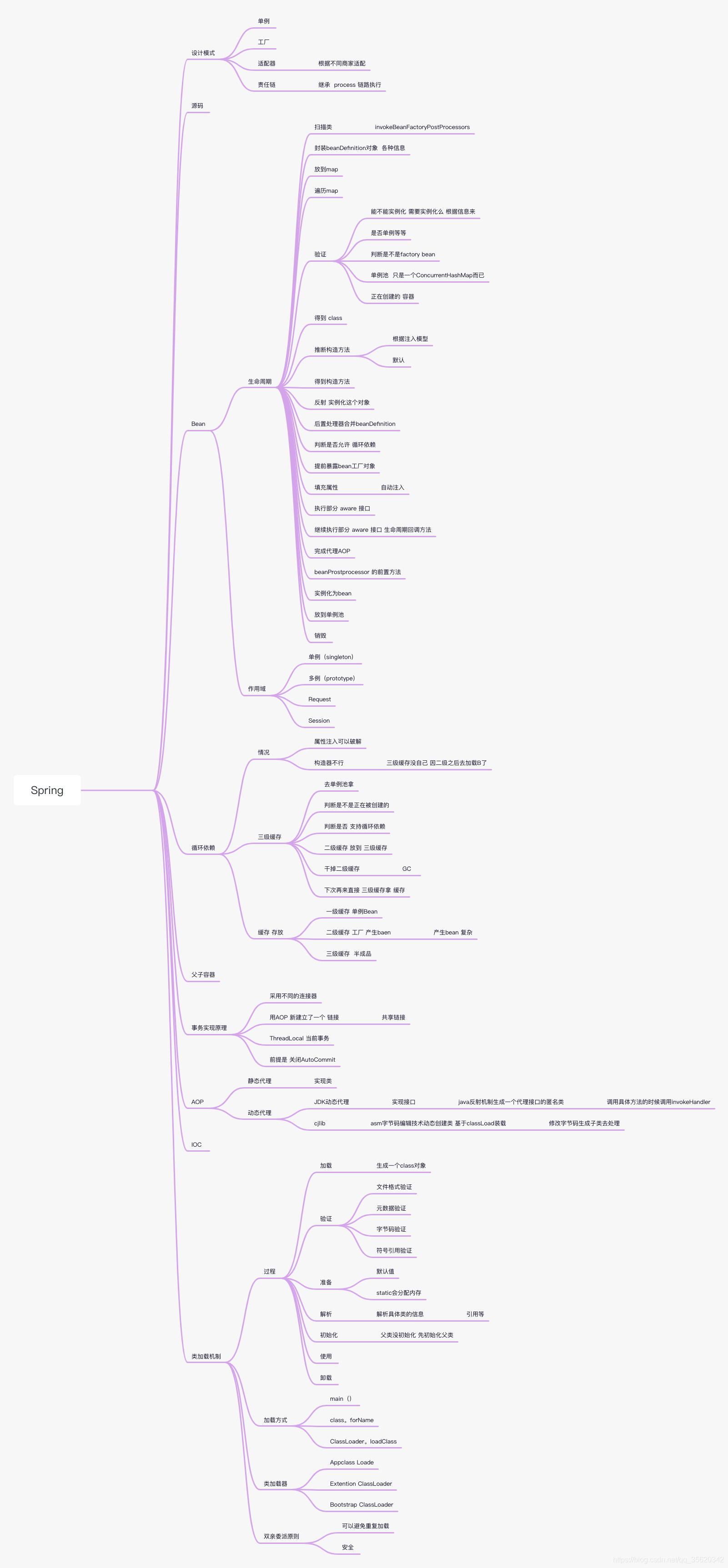
文章目录
- 一、Spring概述
- 二、Spring控制反转
- 三、Spring Beans
- 1.什么是 Spring beans?
- 2.一个 Spring Bean 定义包含什么?
- 3.如何给Spring 容器提供配置元数据?Spring有几种配置方式
- 4.Spring基于xml注入bean的几种方式
- 5.你怎样定义类的作用域?
- 6.解释Spring支持的几种bean的作用域
- 7.Spring框架中的单例bean是线程安全的吗?
- 8.Spring如何处理线程并发问题?
- 9.解释Spring框架中bean的生命周期
- 10.在 Spring中如何注入一个java集合?
- 12.什么是bean装配?
- 13.什么是bean的自动装配?
- 14.Sring 自动装配 bean 有哪些方式?
- 15.使用@Autowired注解自动装配的过程是怎样的?
- 16.自动装配有哪些局限性?
- 四、Spring注解
- 五、Spring数据访问
- 1.解释对象/关系映射集成模块
- 2.在Spring框架中如何更有效地使用JDBC?
- 3.解释JDBC抽象和DAO模块
- 4.Spring DAO 有什么用?
- 5.Spring JDBC API 中存在哪些类?
- 6.JdbcTemplate是什么
- 7.使用Spring通过什么方式访问Hibernate?使用 Spring 访问 Hibernate 的方法有哪些?
- 8.如何通过HibernateDaoSupport将Spring和Hibernate结合起来?
- 9.Spring支持的事务管理类型, spring 事务实现方式有哪些?
- 10.Spring事务的实现方式和实现原理
- 11.Spring的事务传播行为
- 12.Spring 的事务隔离?
- 13.Spring框架的事务管理有哪些优点?
- 14.你更倾向用那种事务管理类型?
- 六、Spring面向切面编程(AOP)
- 1.什么是AOP?
- 2.Spring AOP and AspectJ AOP 有什么区别?AOP 有哪些实现方式?
- 3.JDK动态代理和CGLIB动态代理的区别
- 4.如何理解 Spring 中的代理?
- 5.解释一下Spring AOP里面的几个名词
- 6.Spring在运行时通知对象
- 7.Spring只支持方法级别的连接点
- 8.在Spring AOP 中,关注点和横切关注的区别是什么?在 spring aop 中 concern 和 cross-cutting concern 的不同之处
- 9.Spring通知有哪些类型?
- 10.什么是切面 Aspect?
- 11.解释基于XML Schema方式的切面实现
- 12.解释基于注解的切面实现
- 13.有几种不同类型的自动代理?
一、Spring概述
1.什么是spring?
Spring是一个轻量级Java开发框架,最早由Rod Johnson创建,目的是为了解决企业级应用开发的业务逻辑层和其他各层的耦合问题。它是一个分层的JavaSE/JavaEE full-stack(一站式)轻量级开源框架,为开发Java应用程序提供全面的基础架构支持。Spring负责基础架构,因此Java开发者可以专注于应用程序的开发。
Spring最根本的使命是解决企业级应用开发的复杂性,即简化Java开发。
Spring可以做很多事情,它为企业级开发提供给了丰富的功能,但是这些功能的底层都依赖于它的两个核心特性,也就是依赖注入(dependency injection,DI)和面向切面编程(aspect-oriented programming,AOP)。
为了降低Java开发的复杂性,Spring采取了以下4种关键策略
- 基于POJO的轻量级和最小侵入性编程;
- 通过依赖注入和面向接口实现松耦合;
- 基于切面和惯例进行声明式编程;
- 通过切面和模板减少样板式代码。
2.Spring框架的设计目标,设计理念,和核心是什么?
Spring设计目标:Spring为开发者提供一个一站式轻量级应用开发平台;
Spring设计理念:在JavaEE开发中,支持POJO和JavaBean开发方式,使应用面向接口开发,充分支持OO(面向对象)设计方法;Spring通过IoC容器实现对象耦合关系的管理,并实现依赖反转,将对象之间的依赖关系交给IoC容器,实现解耦;
Spring框架的核心:IoC容器和AOP模块。通过IoC容器管理POJO对象以及他们之间的耦合关系;通过AOP以动态非侵入的方式增强服务。
IoC让相互协作的组件保持松散的耦合,而AOP编程允许你把遍布于应用各层的功能分离出来形成可重用的功能组件。
3.使用Spring的好处是什么?
-
轻量:Spring 是轻量的,基本的版本大约 2MB
-
控制反转:Spring 通过控制反转实现了松散耦合,对象们给出它们的依赖,而不是创建或查找依赖的对象们
-
面向切面的编程(AOP):Spring 支持面向切面的编程,并且把应用业务逻辑和系统服务分开
-
容器:Spring 包含并管理应用中对象的生命周期和配置
-
MVC 框架:Spring 的 WEB 框架是个精心设计的框架,是 Web 框架的一个很好的替代品
-
事务管理:Spring 提供一个持续的事务管理接口,可以扩展到上至本地事务下至全局事务(JTA)
-
异常处理:Spring 提供方便的 API 把具体技术相关的异常(比如由 JDBC,Hibernate or JDO抛出的)转化为一致的 unchecked 异常
4.Spring由哪些模块组成?

-
核心容器( Core Container)
核心容器提供Spring框架的基本功能。核心容器中的主要组件是BeanFactory类,它是工厂模式的实现,JavaBean的管理就由它来负责。BeanFactory类通过IOC将应用程序的配置以及依赖性规范与实际的应用程序代码相分离。
-
数据访问/集成模块(Data Access/Integration)
ORM模块为主流的对象关系映射(object-relation mapping)API提供了集成层,这些主流的对象关系映射API包括了JPA、JDO、hibernate和IBatis。该模块可以将O/R映射框架与Spring提供的特性进行组合来使用 -
Web模块
Web模块包括Web、Servlet、Protlet这几个模块。
Web模块提供了基本的面向Web的集成功能,如多文件上传、使用servlet监听器初始化IOC容器和面向Web的应用上下文,还包含Spring的远程支持中与Web相关的部分。
Servlet模块提供了Spring的Web应用的模型-视图-控制器(MVC)实现。
Protlet模块提供了一个在protlet环境中使用的MVC实现。 -
AOP模块
AOP模块提供了一个在AOP联盟标准的面向切面编程的实现 -
Messaging
模块包含发布和订阅消息的特性。 -
Test模块
Test模块支持使用JUnit和TestNG对Spring组件进行测试,它提供一致的ApplicationContexts并缓存这下上下文,他还提供了一些mock对象,使得开发者可以独立的测试代码。
5.Spring 框架中都用到了哪些设计模式?
(1)工厂设计模式
Spring使用工厂模式可以通过 BeanFactory 或 ApplicationContext 创建 bean 对象。
两者对比:
- BeanFactory :延迟注入(使用到某个 bean 的时候才会注入),相比于BeanFactory来说会占用更少的内存,程序启动速度更快。
- ApplicationContext :容器启动的时候,不管你用没用到,一次性创建所有 bean 。BeanFactory 仅提供了最基本的依赖注入支持,ApplicationContext 扩展了 BeanFactory ,除了有BeanFactory的功能之外还有额外更多功能,所以一般开发人员使用ApplicationContext会更多。
ApplicationContext的三个实现类:
- ClassPathXmlApplication:把上下文文件当成类路径资源。
- FileSystemXmlApplication:从文件系统中的 XML 文件载入上下文定义信息。
- XmlWebApplicationContext:从Web系统中的XML文件载入上下文定义信息。
(2)单例模式
Spring中bean的默认作用域就是singleton(单例)的
(3)代理模式
AOP(Aspect-Oriented Programming:面向切面编程)能够将那些与业务无关,却为业务模块所共同调用的逻辑或责任(例如事务处理、日志管理、权限控制等)封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可拓展性和可维护性。
Spring AOP就是基于动态代理的,如果要代理的对象实现了某个接口,那么Spring AOP会使用JDK Proxy,去创建代理对象,而对于没有实现接口的对象,Spring AOP会使用Cglib,这时候Spring AOP会使用Cglib生成一个被代理对象的子类来作为代理,如下图所示:

当然你也可以使用AspectJ,Spring AOP以及集成了AspectJ,AspectJ应该算得上是Java生态系统中最完整的AOP框架了。
使用AOP之后我们可以把一些通用的功能抽象出来,在在需要用到的地方直接使用即可,这样大大简化了代码量。我们需要增加新功能时也方便,这样也提高了系统扩展性。日志功能、事务管理等等场景都用到了 AOP 。
(4)模板方法
Spring 中 jdbcTemplate、hibernateTemplate 等以 Template 结尾的对数据库操作的类,它们就使用到了模板模式。一般情况下,我们都是使用继承的方式来实现模板模式,但是 Spring 并没有使用这种方式,而是使用Callback 模式与模板方法模式配合,既达到了代码复用的效果,同时增加了灵活性。
(5)观察者模式
定义对象键一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都会得到通知被制动更新,如Spring中listener的实现ApplicationListener。
(6)适配器模式
适配器模式(Adapter Pattern) 将一个接口转换成客户希望的另一个接口,适配器模式使接口不兼容的那些类可以一起工作,其别名为包装器(Wrapper)。
Spring AOP中的适配器模式:
我们知道 Spring AOP 的实现是基于代理模式,但是 Spring AOP 的增强或通知(Advice)使用到了适配器模式,与之相关的接口是AdvisorAdapter 。Advice 常用的类型有:BeforeAdvice(目标方法调用前,前置通知)、AfterAdvice(目标方法调用后,后置通知)、AfterReturningAdvice(目标方法执行结束后,return之前)等等。每个类型Advice(通知)都有对应的拦截器:MethodBeforeAdviceInterceptor、AfterReturningAdviceAdapter、AfterReturningAdviceInterceptor。Spring预定义的通知要通过对应的适配器,适配成 MethodInterceptor接口(方法拦截器)类型的对象(如:MethodBeforeAdviceInterceptor 负责适配 MethodBeforeAdvice)。
Spring MVC中的适配器模式:
在Spring MVC中,DispatcherServlet 根据请求信息调用 HandlerMapping,解析请求对应的 Handler。解析到对应的 Handler(也就是我们平常说的 Controller 控制器)后,开始由HandlerAdapter 适配器处理。HandlerAdapter 作为期望接口,具体的适配器实现类用于对目标类进行适配,Controller 作为需要适配的类。
6.详细讲解一下核心容器(spring context应用上下文) 模块
这是基本的Spring模块,提供spring 框架的基础功能,BeanFactory 是任何以spring为基础的应用的核心。Spring 框架建立在此模块之上,它使Spring成为一个容器。
Bean 工厂是工厂模式的一个实现,提供了控制反转功能,用来把应用的配置和依赖从真正的应用代码中分离。最常用的就是org.springframework.beans.factory.xml.XmlBeanFactory ,它根据XML文件中的定义加载beans。该容器从XML 文件读取配置元数据并用它去创建一个完全配置的系统或应用。
7.Spring框架中有哪些不同类型的事件
Spring 提供了以下5种标准的事件:
-
上下文更新事件(ContextRefreshedEvent):在调用ConfigurableApplicationContext 接口中的refresh()方法时被触发。
-
上下文开始事件(ContextStartedEvent):当容器调用ConfigurableApplicationContext的Start()方法开始/重新开始容器时触发该事件。
-
上下文停止事件(ContextStoppedEvent):当容器调用ConfigurableApplicationContext的Stop()方法停止容器时触发该事件。
-
上下文关闭事件(ContextClosedEvent):当ApplicationContext被关闭时触发该事件。容器被关闭时,其管理的所有单例Bean都被销毁。
-
请求处理事件(RequestHandledEvent):在Web应用中,当一个http请求(request)结束触发该事件。如果一个bean实现了ApplicationListener接口,当一个ApplicationEvent 被发布以后,bean会自动被通知。
8.Spring 应用程序有哪些不同组件?
Spring 应用一般有以下组件:
- 接口 - 定义功能。
- Bean 类 - 它包含属性,setter 和 getter 方法,函数等。
- Bean 配置文件 - 包含类的信息以及如何配置它们。
- Spring 面向切面编程(AOP) - 提供面向切面编程的功能。
- 用户程序 - 它使用接口。
9.使用 Spring 有哪些方式?
使用 Spring 有以下方式:
- 作为一个成熟的 Spring Web 应用程序。
- 作为第三方 Web 框架,使用 Spring Frameworks 中间层。
- 作为企业级 Java Bean,它可以包装现有的 POJO(Plain Old Java Objects)。
- 用于远程使用。
二、Spring控制反转
1.什么是Spring IOC 容器?
IOC 全称为 Inversion of Control,翻译为 “控制反转”。
如何理解“控制反转”好呢?理解好它的关键在于我们需要回答如下四个问题:
- 谁控制谁:在传统的开发模式下,我们都是采用直接 new 一个对象的方式来创建对象,也就是说你依赖的对象直接由你自己控制,但是有了 IOC 容器后,则直接由 IoC 容器来控制。所以“谁控制谁”,当然是 IoC 容器控制对象。
- 控制什么:控制对象。
- 为何是反转:没有 IoC 的时候我们都是在自己对象中主动去创建被依赖的对象,这是正转。但是有了 IoC 后,所依赖的对象直接由 IoC 容器创建后注入到被注入的对象中,依赖的对象由原来的主动获取变成被动接受,所以是反转。
- 哪些方面反转了:所依赖对象的获取被反转了。
2.控制反转(IoC)有什么作用?
-
管理对象的创建和依赖关系的维护。对象的创建并不是一件简单的事,在对象关系比较复杂时,如果依赖关系需要程序猿来维护的话,那是相当头疼的
-
解耦,由容器去维护具体的对象
-
托管了类的产生过程,比如我们需要在类的产生过程中做一些处理,最直接的例子就是代理,如果有容器程序可以把这部分处理交给容器,应用程序则无需去关心类是如何完成代理的
3.SpringIOC如何降低对象之间的耦合度?
在我们的日常开发中,创建对象的操作随处可见以至于对其十分熟悉的同时又感觉十分繁琐,每次需要对象都需要亲手将其new出来,甚至某些情况下由于坏编程习惯还会造成对象无法被回收,这是相当糟糕的。但更为严重的是,我们一直倡导的松耦合,少入侵原则,这种情况下变得一无是处。于是前辈们开始谋求改变这种编程陋习,考虑如何使用编码更加解耦合,由此而来的解决方案是面向接口的编程,于是便有了如下写法:
public class BookServiceImpl {
private BookDaoImpl bookDaoImpl;
public void oldCode(){
//原来的做法
bookDaoImpl = new bookDaoImpl();
bookDaoImpl.getAllCategories();
}
}
public class BookServiceImpl {
private BookDao bookDao;
public void newCode(){
//变为面向接口编程
bookDao = new bookDaoImpl();
bookDao.getAllCategories();
}
}
BookServiceImpl类中由原来直接与BookDaoImp打交互变为BookDao,即使BookDao最终实现依然是BookDaoImp,这样的做的好处是显而易见的,所有调用都通过接口bookDao来完成,而接口的真正的实现者和最终的执行者就是bookDaoImpl,当替换bookDaoImpl类,也只需修改bookDao指向新的实现类。

虽然上述的代码在很大程度上降低了代码的耦合度,但是代码依旧存在入侵性和一定程度的耦合性,比如在修改bookDao的实现类时,仍然需求修改BookServiceImpl的内部代码,当依赖的类多起来时,查找和修改的过程也会显得相当糟糕,因此我们仍需要寻找一种方式,它可以令开发者在无需触及BookServiceImpl内容代码的情况下实现修改bookDao的实现类,以便达到最低的耦合度和最少入侵的目的。实际上存在一种称为反射的编程技术可以协助解决上述问题,反射是一种根据给出的完整类名(字符串方式)来动态地生成对象,这种编程方式可以让对象在生成时才决定到底是哪一种对象,因此可以这样假设,在某个配置文件,该文件已写好bookDaoImpl类的完全限定名称,通过读取该文件而获取到bookDao的真正实现类完全限定名称,然后通过反射技术在运行时动态生成该类,最终赋值给bookDao接口,也就解决了刚才的存在问题,这里为简单演示,使用properties文件作为配置文件,className.properties如下:
bookDao.name=com.spring.dao.BookDaoImpl
获取该配置文件信息动态为bookDao生成实现类:
public class BookServiceImpl implements BookService
{
//读取配置文件的工具类
PropertiesUtil propertiesUtil=new PropertiesUtil("conf/className.properties");
private BookDao bookDao;
public void DaymicObject() throws ClassNotFoundException, IllegalAccessException, InstantiationException {
//获取完全限定名称
String className=propertiesUtil.get("bookDao.name");
//通过反射
Class c=Class.forName(className);
//动态生成实例对象
bookDao= (BookDao) c.newInstance();
}
}
的确如我们所愿生成了bookDao的实例,这样做的好处是在替换bookDao实现类的情况只需修改配置文件的内容而无需触及BookServiceImpl的内部代码,从而把代码修改的过程转到配置文件中,相当于BookServiceImpl及其内部的bookDao通过配置文件与bookDao的实现类进行关联,这样BookServiceImpl与bookDao的实现类间也就实现了解耦合,当然BookServiceImpl类中存在着BookDao对象是无法避免的,毕竟这是协同工作的基础,我们只能最大程度去解耦合。

了解了上述的问题再来理解IOC就显得简单多了。Spring IOC 也是一个java对象,在某些特定的时间被创建后,可以进行对其他对象的控制,包括初始化、创建、销毁等。简单地理解,在上述过程中,我们通过配置文件配置了BookDaoImpl实现类的完全限定名称,然后利用反射在运行时为BookDao创建实际实现类,包括BookServiceImpl的创建,Spring的IOC容器都会帮我们完成,而我们唯一要做的就是把需要创建的类和其他类依赖的类以配置文件的方式告诉IOC容器需要创建那些类和注入哪些类即可。Spring通过这种控制反转(IoC)的设计模式促进了松耦合,这种方式使一个对象依赖其它对象时会通过被动的方式传送进来(如BookServiceImpl被创建时,其依赖的BookDao的实现类也会同时被注入BookServiceImpl中),而不是通过手动创建这些类。我们可以把IoC模式看做是工厂模式的升华,可以把IoC看作是一个大工厂,只不过这个大工厂里要生成的对象都是在配置文件(XML)中给出定义的,然后利用Java的反射技术,根据XML中给出的类名生成相应的对象。从某种程度上来说,IoC相当于把在工厂方法里通过硬编码创建对象的代码,改变为由XML文件来定义,也就是把工厂和对象生成这两者独立分隔开来,目的就是提高灵活性和可维护性,更是达到最低的耦合度,因此我们要明白所谓为的IOC就将对象的创建权,交由Spring完成,从此解放手动创建对象的过程,同时让类与类间的关系到达最低耦合度。
4.IOC的优点是什么?
- IOC 或 依赖注入把应用的代码量降到最低。
- 它使应用容易测试,单元测试不再需要单例和JNDI查找机制。
- 最小的代价和最小的侵入性使松散耦合得以实现。
- IOC容器支持加载服务时的饿汉式初始化和懒加载。
5.Spring 的 IOC支持哪些功能
Spring 的 IoC 设计支持以下功能:
- 依赖注入
- 依赖检查
- 自动装配
- 支持集合
- 指定初始化方法和销毁方法
- 支持回调某些方法(但是需要实现 Spring 接口,略有侵入)
其中,最重要的就是依赖注入,从 XML 的配置上说,即 ref 标签。对应 Spring RuntimeBeanReference 对象。
对于 IoC 来说,最重要的就是容器。容器管理着 Bean 的生命周期,控制着 Bean 的依赖注入。
6.BeanFactory 和 ApplicationContext有什么区别?
BeanFactory和ApplicationContext是Spring的两大核心接口,都可以当做Spring的容器。其中ApplicationContext是BeanFactory的子接口。
(1)依赖关系
BeanFactory:是Spring里面最底层的接口,包含了各种Bean的定义,读取bean配置文档,管理bean的加载、实例化,控制bean的生命周期,维护bean之间的依赖关系。
ApplicationContext接口作为BeanFactory的派生,除了提供BeanFactory所具有的功能外,还提供了更完整的框架功能:
- 继承 MessageSource,提供国际化的标准访问策略。
- 继承 ApplicationEventPublisher ,提供强大的事件机制
- 扩展 ResourceLoader,可以用来加载多个 Resource,可以灵活访问不同的资源
- 对 Web 应用的支持
(2)加载方式
ApplicationContext接口继承BeanFactory接口,Spring核心工厂是BeanFactory,BranFactory采用延迟加载,第一次getBean时才会初始化Bean,ApplicationContext是会在加载配置文件时初始化Bean。
(3)创建方式
BeanFactory通常以编程的方式被创建,ApplicationContext还能以声明的方式创建,如使用ContextLoader。
(4)注册方式
BeanFactory和ApplicationContext都支持BeanPostProcessor、BeanFactoryPostProcessor的使用,但两者之间的区别是:BeanFactory需要手动注册,而ApplicationContext则是自动注册。
7.ApplicationContext通常的实现是什么?
-
FileSystemXmlApplicationContext:该容器从 XML 文件中加载已被定义的 bean。在这里,你需要提供给构造器 XML 文件的完整路径
-
ClassPathXmlApplicationContext:该容器从 XML 文件中加载已被定义的 bean。在这里,你不需要提供 XML 文件的完整路径,只需正确配置 CLASSPATH 环境变量即可,因为,容器会从 CLASSPATH 中搜索 bean 配置文件。
-
WebXmlApplicationContext:该容器会在一个 web 应用程序的范围内加载在 XML 文件中已被定义的 bean。
8.有哪些不同类型的依赖注入实现方式?
依赖注入是时下最流行的IoC实现方式,依赖注入分为接口注入(Interface Injection),Setter方法注入(Setter Injection)和构造器注入(Constructor Injection)三种方式。其中接口注入由于在灵活性和易用性比较差,现在从Spring4开始已被废弃。
构造器依赖注入:构造器依赖注入通过容器触发一个类的构造器来实现的,该类有一系列参数,每个参数代表一个对其他类的依赖。
Setter方法注入:Setter方法注入是容器通过调用无参构造器或无参static工厂 方法实例化bean之后,调用该bean的setter方法,即实现了基于setter的依赖注入。
9.构造器依赖注入和 Setter方法注入的区别
| 构造函数注入 | setter 注入 |
|---|---|
| 没有部分注入 | 有部分注入 |
| 不会覆盖 setter 属性 | 会覆盖 setter 属性 |
| 任意修改都会创建一个新实例 | 任意修改不会创建一个新实例 |
| 适用于设置很多属性 | 适用于设置少量属性 |
两种依赖方式都可以使用,构造器注入和Setter方法注入。最好的解决方案是用构造器参数实现强制依赖,setter方法实现可选依赖。
三、Spring Beans
1.什么是 Spring beans?
Spring beans 是那些形成 Spring 应用的主干的 java 对象。它们被 Spring IOC 容器初始化,装配,和管理。这些 beans 通过容器中配置的元数据创建。比如,以 XML 文件中的形式定义。
Spring 框架定义的 beans 都是单件 beans。在 bean tag 中有个属性”singleton”,如果它被赋为 TRUE,bean 就是单件,否则就是一个 prototype bean。默认是 TRUE,所以所有在Spring 框架中的 beans 缺省都是单件。
2.一个 Spring Bean 定义包含什么?
一个 Spring Bean 的定义包含容器必知的所有配置元数据,包括如何创建一个 bean,它的生命周期详情及它的依赖。
3.如何给Spring 容器提供配置元数据?Spring有几种配置方式
这里有三种重要的方法给Spring 容器提供配置元数据。
- XML配置文件。
- 基于注解的配置。
- 基于java的配置。
4.Spring基于xml注入bean的几种方式
-
Set方法注入;
-
构造器注入:①通过index设置参数的位置;②通过type设置参数类型;
-
静态工厂注入;
-
实例工厂;
5.你怎样定义类的作用域?
当定义一个 在Spring里,我们还能给这个bean声明一个作用域。它可以通过bean 定义中的scope属性来定义。如,当Spring要在需要的时候每次生产一个新的bean实例,bean的scope属性被指定为prototype。另一方面,一个bean每次使用的时候必须返回同一个实例,这个bean的scope 属性 必须设为 singleton。
6.解释Spring支持的几种bean的作用域
(1)Singleton作用域
所谓Bean的作用域是指spring容器创建Bean后的生存周期即由创建到销毁的整个过程。之前我们所创建的所有Bean其作用域都是Singleton,这是Spring默认的,在这样的作用域下,每一个Bean的实例只会被创建一次,而且Spring容器在整个应用程序生存期中都可以使用该实例。因此之前的代码中spring容器创建Bean后,通过代码获取的bean,无论多少次,都是同一个Bean的实例。我们可使用<bean>标签的scope属性来指定一个Bean的作用域,如下:
<!-- 默认情况下无需声明Singleton -->
<bean name="accountDao" scope="singleton"
class="com.spring.springIoc.dao.impl.AccountDaoImpl"/>
(2)prototype作用域
除了Singleton外还有另外一种比较常用的作用域,prototype,它代表每次获取Bean实例时都会新创建一个实例对象,类似new操作符。我们来简单测试一下:
<!-- 作用域:prototype -->
<bean name="accountDao" scope="prototype" class="com.spring.springIoc.dao.impl.AccountDaoImpl"/>
测试代码:
@Test
public void test2() {
ApplicationContext applicationContext=new
ClassPathXmlApplicationContext("spring/spring-ioc.xml");
AccountDao accountDao1 = (AccountDao) applicationContext.getBean("accountDao");
AccountDao accountDao2 = (AccountDao) applicationContext.getBean("accountDao");
System.out.println("accountDao1地址:"+accountDao1.toString());
System.out.println("accountDao2地址:"+accountDao2.toString());
}
执行结果:
accountDao1地址:com.spring.springIoc.dao.impl.AccountDaoImpl@579a0931
accountDao2地址:com.spring.springIoc.dao.impl.AccountDaoImpl@49ads019
显然是两个不同的实例对象。当然我们也可通过注解来声明作用域:
@Scope("prototype")
public class AccountDaoImpl {
//......
}
这里还需要说明一种特殊的情景,当一个作用域为Singleton的Bean依赖于一个作用域为prototype的Bean时如下:
<!-- 作用域prototype-->
<bean name="accountDao" scope="prototype"
class="com.spring.springIoc.dao.impl.AccountDaoImpl"/>
<!-- 作用域Singleton -->
<bean name="accountService" class="com.spring.springIoc.service.impl.AccountServiceImpl">
<!-- 注入作用域为prototype的accountDao对象,需要set方法 -->
<property name="accountDao" ref="accountDao"/>
</bean>
在这样的情况下希望的是每次getBean(“accountService”)处理的都是一个新的accountDao实例对象,但是由于accountService的依赖是在Bean被创建时注入的,而且accountService是一个Singleton,整个生存周期中只会创建一次,因此它所依赖的accountDao实例对象也只会被注入一次,此后不会再注入任何新的accountDao实例对象。为了解决这种困境,只能放弃使用依赖注入的功能,使用代码实现,如下:通过实现ApplicationContextAware接口,重写setApplicationContext,这样的话Spring容器在创建AccountServiceImpl实例时会自动注入ApplicationContext对象,此时便可以通过ApplicationContext获取accountDao实例了,这样可以保证每次获取的accountDao实例都是新的(这里的代码只是演示该过程,实际开发中一般不会要求accountDao每次都是新实例,因为accountDao无需记录状态信息,即无状态bean,一般默认singleton即可)
<bean name="accountDao" scope="prototype" class="com.zejian.spring.springIoc.dao.impl.AccountDaoImpl"/>
<!-- accountDao通过代码注入 -->
<bean name="accountService" class="com.zejian.spring.springIoc.service.impl.AccountServiceImpl" />
代码注入示范:
public class AccountServiceImpl implements AccountService , ApplicationContextAware {
private ApplicationContext applicationContext;
@Override
public void doSomething() {
System.out.println("AccountServiceImpl#doSomething......");
System.out.println("getAccountDao....."+ getAccountDao().toString());
}
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
this.applicationContext=applicationContext;
}
private AccountDao getAccountDao(){
return applicationContext.getBean(AccountDao.class);
}
}
测试代码:
//加载配置文件
ApplicationContext applicationContext=new ClassPathXmlApplicationContext("spring/spring-ioc.xml");
//测试获取不同实例的AccountDao
AccountService accountService= (AccountService) applicationContext.getBean("accountService");
accountService.doSomething();
AccountService accountService1= (AccountService) applicationContext.getBean("accountService");
accountService1.doSomething();
运行结果:
AccountServiceImpl#doSomething......
getAccountDao.....com.spring.springIoc.dao.impl.AccountDaoImpl@ab321564
AccountServiceImpl#doSomething......
getAccountDao.....com.spring.springIoc.dao.impl.AccountDaoImpl@2aga1580
显然这样的方式,每次获取的daoAccount都不一样,也就解决上述的问题,另外的一种情况是当一个作用域为propotype的Bean依赖于一个Singleton作用域的Bean时,解决方案跟上述是相同的。请注意,当一个Bean被设置为prototype 后Spring就不会对一个bean的整个生命周期负责,容器在初始化、配置、装饰或者是装配完一个prototype实例后,将它交给客户端,随后就对该prototype实例不闻不问了。因此我们需要慎用它,一般情况下,对有状态的bean应该使用prototype作用域,而对无状态的bean则应该使用singleton作用域。所谓有状态就是该bean有保存信息的能力,不能共享,否则会造成线程安全问题,而无状态则不保存信息,是线程安全的,可以共享,spring中大部分bean都是Singleton,整个生命周期过程只会存在一个。
(3)request与session作用域
在spring2.5中专门针对Web应该程序引进了request和session这两种作用域。关于request作用域,对于每次HTTP请求到达应用程序,Spring容器会创建一个全新的Request作用域的bean实例,且该bean实例仅在当前HTTP request内有效,整个请求过程也只会使用相同的bean实例,因此我们可以根据需要放心的更改所建实例的内部状态,而其他请求HTTP请求则创建新bean的实例互不干扰,当处理请求结束,request作用域的bean实例将被销毁,如在接收参数时可能需要一个bean实例来装载一些参数,显然每次请求参数几乎不会相同,因此希望bean实例每次都是足够新的而且只在request作用域范围内有效。关于Session可能你也已猜到,每当创建一个新的HTTP Session时就会创建一个Session作用域的Bean,并该实例bean伴随着会话的存在而存在。下面看一个测试程序:
@Component
@Scope(value = "singleton")
public class SingletonBean {
//......
}
@Component
@Scope(value = "prototype" , proxyMode = ScopedProxyMode.TARGET_CLASS)
public class PrototypeBean {
//......
}
@Component
@Scope(value = "request" , proxyMode = ScopedProxyMode.TARGET_CLASS)
public class RequestBean {
//......
}
@Component
@Scope(value = "session" , proxyMode = ScopedProxyMode.TARGET_CLASS)
public class SessionBean {
//........
}
上述代码,分别创建4个不同作用域的Bean,并使用注解的方式开发,@Component表名它们是组件类,需要Spring容器帮忙创建,@Scope注明作用域,value指明是哪种作用域,除了SingletonBean外,其它Bean还使用proxyMode指明哪种代理模式创建,这里没有接口,因此使用CGLib代理生成(后面会分析为什么这么做)。接着需要在xml注明扫描包告诉Spring容器它们在哪里(4个类都声明在com.zejian.spring.dto包下)。
<!-- 包扫描 -->
<context:component-scan base-package="com.spring.dto" />
使用SpringMVC创建Web访问层(如果不清楚springmvc,可以理解为web访问层即将类似Servlet):
@Controller
public class BookController {
@Autowired
private RequestBean requestBean;
@Autowired
private SessionBean sessionBean;
@Autowired
private PrototypeBean prototypeBean;
@Autowired
private SingletonBean singletonBean;
@RequestMapping(value = "/test")
public void test()
{
print();
}
public void print() {
System.out.println("first time singleton is :" + singletonBean);
System.out.println("second time singleton is :" + singletonBean);
System.out.println("first time prototype is :" + prototypeBean);
System.out.println("second time prototype is :" + prototypeBean);
System.out.println("first time requestBean is :" + requestBean);
System.out.println("second time requestBean is :" + requestBean);
System.out.println("first time sessionBean is :" + sessionBean);
System.out.println("second time sessionBean is :" + sessionBean);
System.out.println("===========================================");
}
}
现在启动tomcat服务器使用Chrome浏览器进行连续两次访问结果如下:
first time singletonBean is :com.zejian.spring.dto.SingletonBean@2ebdd720
second time singletonBean is :com.zejian.spring.dto.SingletonBean@2ebdd720
first time prototypeBean is :com.zejian.spring.dto.PrototypeBean@1ed53cde
second time prototypeBean is :com.zejian.spring.dto.PrototypeBean@35c052be
first time requestBean is :com.zejian.spring.dto.RequestBean@15b9dfe1
second time requestBean is :com.zejian.spring.dto.RequestBean@15b9dfe1
first time sessionBean is :com.zejian.spring.dto.SessionBean@5b355dae
second time sessionBean is :com.zejian.spring.dto.SessionBean@5b355dae
===========================================
first time singletonBean is :com.zejian.spring.dto.SingletonBean@2ebdd720
second time singletonBean is :com.zejian.spring.dto.SingletonBean@2ebdd720
first time prototypeBean is :com.zejian.spring.dto.PrototypeBean@7775fd09
second time prototypeBean is :com.zejian.spring.dto.PrototypeBean@79b20d97
first time requestBean is :com.zejian.spring.dto.RequestBean@7d8d9679
second time requestBean is :com.zejian.spring.dto.RequestBean@7d8d9679
first time sessionBean is :com.zejian.spring.dto.SessionBean@5b355dae
second time sessionBean is :com.zejian.spring.dto.SessionBean@5b355dae
===========================================
显然singletonBean永远只有一个实例,而PrototypeBean则每次被获取都会创建新的实例,对应RequestBean,在同一次Http请求过程中是同一个实例,当请求结束,RequestBean也随着销毁,在新的Http请求则会生成新的RequestBean实例,对于SessionBean,由于是在同一个浏览器中访问属于同一次会话,因此SessionBean实例都是同一个实例对象。现在使用另外一个浏览器启动访问,观察SessionBean是否变化。
first time singletonBean is :com.zejian.spring.dto.SingletonBean@2ebdd720
second time singletonBean is :com.zejian.spring.dto.SingletonBean@2ebdd720
first time prototypeBean is :com.zejian.spring.dto.PrototypeBean@5a85c6a7
second time prototypeBean is :com.zejian.spring.dto.PrototypeBean@54423387
first time requestBean is :com.zejian.spring.dto.RequestBean@507dadd7
second time requestBean is :com.zejian.spring.dto.RequestBean@507dadd7
first time sessionBean is :com.zejian.spring.dto.SessionBean@157f39bc
second time sessionBean is :com.zejian.spring.dto.SessionBean@157f39bc
===========================================
显然SessionBean已改变,也就说明不同的会话中SessionBean实例是不同的。但我们还是很诧异,为什么需要在其他3种作用域上设置代理模式?事实上这个问题的本质与前面Singleton作用域的bean依赖于Prototype作用域的bean原理是相同,Prototype前面已分析过了(使用注解时也必须声明代理模式),这里我们主要分析request和session作用域,由于Spring容器只会在创建bean实例时帮助我们注入该实例bean所依赖的其他bean实例,而且只会注入一次,这并不是request、session作用域所希望看到的,毕竟它们都需要在不同的场景下注入新的实例对象而不是唯一不变的实例对象。为了解决这种困境,必须放弃直接在xml中注入bean实例,改用java代码方式(实现ApplicationContextAware接口)或者注解的方式(@Autowired)注入。示例中选择了后者,并在bean的声明中声明了动态代理模式(关于动态代理自行查阅相关资料),幸运地是,Spring容器足够聪明,以至于spring容器通过代理的方式生成新的代理实例bean,以此来满足创建新实例的需求。在程序运行过程中,当一个方法调用到达该代理对象时,Spring容器便尝试在当前的请求(Request)或者会话(Session)获取目标对象Bean(真正的实例Bean)。如果已存在则使用该Bean,否则,代理方法将创建新实例bean处理请求或者会话,请注意,这里指的的是一次Http请求或者一次会话的过程。如果希望request和session作用域通过xml配置文件方式声明时必须在<bean>标签中放置<aop:scoped-proxy>作为子标签,该作用于注解声明代理模式效果相同(需要引用aop命名空间,关于aop不清楚的,这里可简单理解为声明代理即可)。请注意,经过测试这种声明代理的方式不适合prototype作用域,该作用域生效的方式目前测试中只有基于注解方式和前面基于实现ApplicationContextAware接口两种方式。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:mvc="http://www.springframework.org/schema/mvc"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:aop="http://www.springframework.org/schema/aop"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.2.xsd http://www.springframework.org/schema/mvc
http://www.springframework.org/schema/mvc/spring-mvc.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop.xsd"
>
<bean id="requestBean" scope="request" class="com.spring.dto.RequestBean" >
<!-- 声明aop代理 -->
<aop:scoped-proxy />
</bean>
<bean id="sessionBean" scope="request" class="com.spring.dto.SessionBean" >
<!-- 声明aop代理 -->
<aop:scoped-proxy />
</bean>
</beans>
最后还有一点需要明确的是,如果web层适用的是SpringMVC处理web请求,则不需要做任何事情就可以使Request和Session作用域生效。但倘若适用其他web层框架的实现,务必需要在web.xml中声明如下监听器,以便使Request和Session作用域正常工作:
<web-app>
<listener>
<listener-class> org.springframework.web.context.request.RequestContextListener <listener-class>
</listener>
</web-app>
(4)globalSession作用域
这种作用域类似于Session作用域,相当于全局变量,类似Servlet的Application,适用基于portlet的web应用程序,请注意,portlet在这指的是分布式开发,而不是portlet语言开发。
7.Spring框架中的单例bean是线程安全的吗?
不是,Spring框架中的单例bean不是线程安全的。
spring 中的 bean 默认是单例模式,spring 框架并没有对单例 bean 进行多线程的封装处理。
实际上大部分时候 spring bean 无状态的(比如 dao 类),所有某种程度上来说 bean 也是安全的,但如果 bean 有状态的话(比如 view model 对象),那就要开发者自己去保证线程安全了,最简单的就是改变 bean 的作用域,把“singleton”变更为“prototype”,这样请求 bean 相当于 new Bean()了,所以就可以保证线程安全了。
- 有状态就是有数据存储功能。
- 无状态就是不会保存数据。
8.Spring如何处理线程并发问题?
在一般情况下,只有无状态的Bean才可以在多线程环境下共享,在Spring中,绝大部分Bean都可以声明为singleton作用域,因为Spring对一些Bean中非线程安全状态采用ThreadLocal进行处理,解决线程安全问题。
ThreadLocal和线程同步机制都是为了解决多线程中相同变量的访问冲突问题。同步机制采用了“时间换空间”的方式,仅提供一份变量,不同的线程在访问前需要获取锁,没获得锁的线程则需要排队。而ThreadLocal采用了“空间换时间”的方式。
ThreadLocal会为每一个线程提供一个独立的变量副本,从而隔离了多个线程对数据的访问冲突。因为每一个线程都拥有自己的变量副本,从而也就没有必要对该变量进行同步了。ThreadLocal提供了线程安全的共享对象,在编写多线程代码时,可以把不安全的变量封装进ThreadLocal。
9.解释Spring框架中bean的生命周期

| 接口 | 方法 | 说明 |
|---|---|---|
| BeanFactoryPostProcessor | postProcessBeanFactory | 在Bean对象实例化之前执行, 通过beanFactory可以获取bean的定义信息, 并可以修改bean的定义信息。这点是和BeanPostProcessor最大区别 |
| BeanPostProcessor | postProcessBeforeInitialization | 实例化、依赖注入完毕,在调用显示的初始化之前完成一些定制的初始化任务 |
| postProcessAfterInitialization | 实例化、依赖注入、初始化完毕时执行 | |
| InstantiationAwareBeanPostProcessor | postProcessBeforeInstantiation | 在方法实例化之前执行,返回结果为null正常执行,返回结果如果不为null则会跳过相关方法而进入初始化完成后的流程 |
| postProcessAfterInstantiation | 在方法实例化之后执行,返回结果true才会执行postProcessPropertyValues方法 | |
| postProcessPropertyValues | 可以用来修改Bean中属性的内容 | |
| InitializingBean | afterPropertiesSet | 初始化的方法 |
| DisposableBean | destroy | 容器销毁前的回调方法 |
| Aware | setXXX | 感知对应Spring容器的内容 |
| @PostConstruct | 标注在方法头部,表示初始化的方法 | |
| @PreDestroy | 标注在方法头部,表示销毁前回调的方法 | |
| init-method属性 | 指定初始化的方法 | |
| destory-method属性 | 指定销毁前的回调方法 | |
(1)BeanFactoryPostProcessor接口
该接口中的方法是最先执行的。在Bean实例化之前执行
/**
* 自定义BeanFactoryPostProcessor
*
*/
public class MyBeanFactoryPostProcessor implements BeanFactoryPostProcessor {
/**
* 本方法在Bean对象实例化之前执行,
* 通过beanFactory可以获取bean的定义信息,
* 并可以修改bean的定义信息。这点是和BeanPostProcessor最大区别
*/
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
System.out.println("****** BeanFactoryPostProcessor 开始执行了");
/*String[] names = beanFactory.getBeanDefinitionNames();
for (String name : names) {
if("user".equals(name)){
BeanDefinition beanDefinition = beanFactory.getBeanDefinition(name);
MutablePropertyValues propertyValues = beanDefinition.getPropertyValues();
// MutablePropertyValues如果设置了相关属性,可以修改,如果没有设置则可以添加相关属性信息
if(propertyValues.contains("name")){
propertyValues.addPropertyValue("name", "bobo");
System.out.println("修改了属性信息");
}
}
}*/
System.out.println("******* BeanFactoryPostProcessor 执行结束了");
}
}
(2)BeanPostProcessor接口
该接口中定义了两个方法,分别在Bean对象实例化及装配后在初始化的前后执行
/**
* 自定义BeanPostProcessor实现类
* BeanPostProcessor接口的作用是:
* 我们可以通过该接口中的方法在bean实例化、配置以及其他初始化方法前后添加一些我们自己的逻辑
*
*/
public class MyBeanPostProcessor implements BeanPostProcessor{
/**
* 实例化、依赖注入完毕,在调用显示的初始化之前完成一些定制的初始化任务
* 注意:方法返回值不能为null
* 如果返回null那么在后续初始化方法将报空指针异常或者通过getBean()方法获取不到bena实例对象
* 因为后置处理器从Spring IoC容器中取出bean实例对象没有再次放回IoC容器中
*/
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
if("user".equals(beanName)){
System.out.println(">>后置处理器 before方法:"+bean+"\t"+beanName);
}
// 可以根据beanName不同执行不同的处理操作
return bean;
}
/**
* 实例化、依赖注入、初始化完毕时执行
* 注意:方法返回值不能为null
* 如果返回null那么在后续初始化方法将报空指针异常或者通过getBean()方法获取不到bena实例对象
* 因为后置处理器从Spring IoC容器中取出bean实例对象没有再次放回IoC容器中
*/
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
if("user".equals(beanName)){
System.out.println("<<后置处理器after方法:"+bean+"\t"+beanName);
}
// 可以根据beanName不同执行不同的处理操作
return bean;
}
}
(3)InstantiationAwareBeanPostProcessor接口
该接口是BeanPostProcessor接口的子接口,所以该接口肯定具有BeanPostProcessor接口的功能,同时又定义了三个自己的接口,这三个接口是在Bean实例化前后执行的方法。
/**
* 自定义处理器
*
*/
public class MyInstantiationAwareBeanPostProcessor implements InstantiationAwareBeanPostProcessor{
/**
* BeanPostProcessor接口中的方法
* 在Bean的自定义初始化方法之前执行
* Bean对象已经存在了
*/
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
// TODO Auto-generated method stub
if("user".equals(beanName)){
System.out.println("【---InstantiationAwareBeanPostProcessor---】 postProcessBeforeInitialization");
}
return bean;
}
/**
* BeanPostProcessor接口中的方法
* 在Bean的自定义初始化方法执行完成之后执行
* Bean对象已经存在了
*/
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
if("user".equals(beanName)){
System.out.println("【--InstantiationAwareBeanPostProcessor----】 postProcessAfterInitialization");
}
return bean;
}
/**
* InstantiationAwareBeanPostProcessor中自定义的方法
* 在方法实例化之前执行 Bean对象还没有
*/
@Override
public Object postProcessBeforeInstantiation(Class<?> beanClass, String beanName) throws BeansException {
if("user".equals(beanName)){
System.out.println("【--InstantiationAwareBeanPostProcessor----】postProcessBeforeInstantiation");
}
return null;
}
/**
* InstantiationAwareBeanPostProcessor中自定义的方法
* 在方法实例化之后执行 Bean对象已经创建出来了
*/
@Override
public boolean postProcessAfterInstantiation(Object bean, String beanName) throws BeansException {
if("user".equals(beanName)){
System.out.println("【--InstantiationAwareBeanPostProcessor----】postProcessAfterInstantiation");
}
return true;
}
/**
* InstantiationAwareBeanPostProcessor中自定义的方法
* 可以用来修改Bean中属性的内容
*/
@Override
public PropertyValues postProcessPropertyValues(PropertyValues pvs, PropertyDescriptor[] pds, Object bean,
String beanName) throws BeansException {
if("user".equals(beanName)){
System.out.println("【--InstantiationAwareBeanPostProcessor----】postProcessPropertyValues--->");
}
return pvs;
}
}
(4)BeanNameAware,BeanFactoryAware等Aware接口
Aware接口是用来让对象感知当前的IOC环境
(5)InitializingBean,DisposableBean接口
这两个接口是Bean初始化及销毁回调的方法。
(6)@PostConstruct和@PreDestroy注解
import javax.annotation.PostConstruct;
import javax.annotation.PreDestroy;
import org.springframework.beans.BeansException;
import org.springframework.beans.factory.BeanFactory;
import org.springframework.beans.factory.BeanFactoryAware;
import org.springframework.beans.factory.BeanNameAware;
import org.springframework.beans.factory.DisposableBean;
import org.springframework.beans.factory.InitializingBean;
/**
* 实现InitializingBean和DisposableBean接口
*
*/
public class User implements InitializingBean,DisposableBean,BeanNameAware,BeanFactoryAware{
private int id;
private String name;
//感知本对象在Spring容器中的id属性
private String beanName;
// 感知本对象所属的BeanFactory对象
private BeanFactory factory;
public User(){
System.out.println("构造方法被执行了...User 被实例化");
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
System.out.println("《注入属性》注入name属性"+name);
this.name = name;
}
public String getBeanName() {
return beanName;
}
@Override
public String toString() {
return "User [id=" + id + ", name=" + name + ", beanName=" + beanName + "]";
}
/**
* bean对象销毁前的回调方法
*/
@Override
public void destroy() throws Exception {
// TODO Auto-generated method stub
System.out.println("《DisposableBean接口》destory ....");
}
/**
* 初始化的方法
*/
@Override
public void afterPropertiesSet() throws Exception {
System.out.println("初始化:《InitializingBean接口》afterPropertiesSet....");
}
@Override
public void setBeanFactory(BeanFactory beanFactory) throws BeansException {
// TODO Auto-generated method stub
System.out.println("【BeanFactoryAware接口】setBeanFactory");
this.factory = beanFactory;
}
@Override
public void setBeanName(String name) {
System.out.println("【BeanNameWare接口】setBeanName");
this.beanName = name;
}
public BeanFactory getFactory() {
return factory;
}
/**
* 也是个初始化的方法
*/
@PostConstruct
public void postConstruct(){
System.out.println("初始化:【@PostConstruct】执行了...");
}
/**
* 销毁前的回调方法
*/
@PreDestroy
public void preDestory(){
System.out.println("【@preDestory】执行了...");
}
/**
* 初始化的方法
* 通过bean标签中的 init-method属性指定
*/
public void start(){
System.out.println("初始化:【init-method】方法执行了....");
}
/**
* 销毁前的回调方法
* 通过bean标签中的 destory-method属性指定
*/
public void stop(){
System.out.println("【destory-method】方法执行了....");
}
}
(7)init-method、destroy-method
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.3.xsd">
<context:annotation-config/>
<bean class="com.pojo.User" id="user" init-method="start" destroy-method="stop" >
<property name="name" value="烤鸭"></property>
</bean>
<!-- 注册后置处理器 -->
<bean class="com.processor.MyBeanPostProcessor"/>
<!-- 注册 InstantiationAwareBeanPostProcessor -->
<bean class="com.processor.MyInstantiationAwareBeanPostProcessor"></bean>
<!-- 注册 BeanFactoryPostProcessor对象-->
<bean class="com.factoryprocessor.MyBeanFactoryPostProcessor"/>
</beans>
(8)测试
@Test
public void test1() {
System.out.println("Spring容器开始加载....");
ClassPathXmlApplicationContext ac = new ClassPathXmlApplicationContext("applicationContext.xml");
User user = ac.getBean(User.class);
System.out.println("---------------"+user);
ac.registerShutdownHook();
System.out.println("Spring容器卸载完成....");
}
结果:
Spring容器开始加载....
三月 04, 2019 11:14:38 下午 org.springframework.context.support.ClassPathXmlApplicationContext prepareRefresh
信息: Refreshing org.springframework.context.support.ClassPathXmlApplicationContext@707f7052: startup date [Mon Mar 04 23:14:38 CST 2019]; root of context hierarchy
三月 04, 2019 11:14:39 下午 org.springframework.beans.factory.xml.XmlBeanDefinitionReader loadBeanDefinitions
信息: Loading XML bean definitions from class path resource [applicationContext.xml]
****** BeanFactoryPostProcessor 开始执行了
******* BeanFactoryPostProcessor 执行结束了
【--InstantiationAwareBeanPostProcessor----】postProcessBeforeInstantiation
构造方法被执行了...User 被实例化
【--InstantiationAwareBeanPostProcessor----】postProcessAfterInstantiation
【--InstantiationAwareBeanPostProcessor----】postProcessPropertyValues--->
《注入属性》注入name属性波波烤鸭
【BeanNameWare接口】setBeanName
【BeanFactoryAware接口】setBeanFactory
>>后置处理器 before方法:User [id=0, name=波波烤鸭, beanName=user] user
【---InstantiationAwareBeanPostProcessor---】 postProcessBeforeInitialization
初始化:【@PostConstruct】执行了...
初始化:《InitializingBean接口》afterPropertiesSet....
初始化:【init-method】方法执行了....
<<后置处理器after方法:User [id=0, name=烤鸭, beanName=user] user
【--InstantiationAwareBeanPostProcessor----】 postProcessAfterInitialization
---------------User [id=0, name=波波烤鸭, beanName=user]
Spring容器卸载完成....
三月 04, 2019 11:14:39 下午 org.springframework.context.support.ClassPathXmlApplicationContext doClose
信息: Closing org.springframework.context.support.ClassPathXmlApplicationContext@707f7052: startup date [Mon Mar 04 23:14:38 CST 2019]; root of context hierarchy
【@preDestory】执行了...
《DisposableBean接口》destroy ....
【destory-method】方法执行了....
(9)Bean对象生命周期总结
1.如果实现了BeanFactoryPostProcessor接口,那么在容器启动的时候,该接口中的postProcessBeanFactory方法可以修改Bean中元数据中的信息。该方法是在实例化对象之前执行
2.如果实现了InstantiationAwareBeanPostProcessor接口,那么在实例化Bean对象之前会调用postProcessBeforeInstantiation方法,该方法如果返回的不为null则会直接调用postProcessAfterInitialization方法,而跳过了Bean实例化后及初始化前的相关方法,如果返回null则正常流程,postProcessAfterInstantiation在实例化成功后执行,这个时候对象已经被实例化,但是该实例的属性还未被设置,都是null。因为它的返回值是决定要不要调用postProcessPropertyValues方法的其中一个因素(因为还有一个因素是mbd.getDependencyCheck());如果该方法返回false,并且不需要check,那么postProcessPropertyValues就会被忽略不执行;如果返回true, postProcessPropertyValues就会被执行,postProcessPropertyValues用来修改属性,在初始化方法之前执行。
3.如果实现了Aware相关的结果,那么相关的set方法会在初始化之前执行。
4.如果实现了BeanPostProcessor接口,那么该接口的方法会在实例化后的初始化方法前后执行。
5.如果实现了InitializingBean接口则在初始化的时候执行afterPropertiesSet
6.如果指定了init-method属性则在初始化的时候会执行指定的方法。
7.如果指定了@PostConstruct则在初始化的时候会执行标注的方法。
8.到此对象创建完成
9.当对象需要销毁的时候。
10.如果实现了DisposableBean接口会执行destroy方法
11.如果指定了destroy-method属性则会执行指定的方法
12.如果指定了@PreDestroy注解则会执行标注的方法
10.在 Spring中如何注入一个java集合?
Spring提供以下几种集合的配置元素:
类型用于注入一列值,允许有相同的值。
类型用于注入一组值,不允许有相同的值。
类型用于注入一组键值对,键和值都可以为任意类型。
类型用于注入一组键值对,键和值都只能为String类型。
12.什么是bean装配?
装配,或bean 装配是指在Spring 容器中把bean组装到一起,前提是容器需要知道bean的依赖关系,如何通过依赖注入来把它们装配到一起。
13.什么是bean的自动装配?
在Spring框架中,在配置文件中设定bean的依赖关系是一个很好的机制,Spring 容器能够自动装配相互合作的bean,这意味着容器不需要和配置,能通过Bean工厂自动处理bean之间的协作。这意味着 Spring可以通过向Bean Factory中注入的方式自动搞定bean之间的依赖关系。自动装配可以设置在每个bean上,也可以设定在特定的bean上。
14.Sring 自动装配 bean 有哪些方式?
Spring 容器能够自动装配 bean。也就是说,可以通过检查 BeanFactory 的内容让 Spring 自动解析 bean 的协作者。
自动装配的不同模式:
- no,这是默认设置,表示没有自动装配。应使用显式 bean 引用进行装配。
- byName,它根据 bean 的名称注入对象依赖项。它匹配并装配其属性与 XML 文件中由相同名称定义的 bean。
- byType,它根据类型注入对象依赖项。如果属性的类型与 XML 文件中的一个 bean 名称匹配,则匹配并装配属性。
- constructor,它通过调用类的构造函数来注入依赖项。它有大量的参数。
- autodetect,首先容器尝试通过构造函数使用 autowire 装配,如果不能,则尝试通过 byType 自动装配。
15.使用@Autowired注解自动装配的过程是怎样的?
使用@Autowired注解来自动装配指定的bean。在使用@Autowired注解之前需要在Spring配置文件进行配置,<context:annotation-config />。
在启动Spring IOC时,容器自动装载了一个AutowiredAnnotationBeanPostProcessor后置处理器,当容器扫描到@Autowied、@Resource或@Inject时,就会在IoC容器自动查找需要的bean,并装配给该对象的属性。在使用@Autowired时,首先在容器中查询对应类型的bean:
-
如果查询结果刚好为一个,就将该bean装配给@Autowired指定的数据;
-
如果查询的结果不止一个,那么@Autowired会根据名称来查找;
-
如果上述查找的结果为空,那么会抛出异常。解决方法时,使用required=false。
16.自动装配有哪些局限性?
自动装配的局限性是:
重写:你仍需用 和 配置来定义依赖,意味着总要重写自动装配。
基本数据类型:你不能自动装配简单的属性,如基本数据类型,String字符串,和类。
模糊特性:自动装配不如显式装配精确,如果有可能,建议使用显式装配。
四、Spring注解
1.什么是基于Java的Spring注解配置? 给一些注解的例子
基于Java的配置,允许你在少量的Java注解的帮助下,进行你的大部分Spring配置而非通过XML文件。
以@Configuration 注解为例,它用来标记类可以当做一个bean的定义,被Spring IOC容器使用。
另一个例子是@Bean注解,它表示此方法将要返回一个对象,作为一个bean注册进Spring应用上下文。
@Configuration
public class StudentConfig {
@Bean
public StudentBean myStudent() {
return new StudentBean();
}
}
2.怎样开启注解装配?
注解装配在默认情况下是不开启的,为了使用注解装配,我们必须在Spring配置文件中配置 <context:annotation-config/>元素。
3.@Component, @Controller, @Repository, @Service 有何区别?
@Component:这将 java 类标记为 bean。它是任何 Spring 管理组件的通用构造型。spring 的组件扫描机制现在可以将其拾取并将其拉入应用程序环境中。
@Controller:这将一个类标记为 Spring Web MVC 控制器。标有它的 Bean 会自动导入到 IoC 容器中。
@Service:此注解是组件注解的特化。它不会对 @Component 注解提供任何其他行为。您可以在服务层类中使用 @Service 而不是 @Component,因为它以更好的方式指定了意图。
@Repository:这个注解是具有类似用途和功能的 @Component 注解的特化。它为 DAO 提供了额外的好处。它将 DAO 导入 IoC 容器,并使未经检查的异常有资格转换为 Spring DataAccessException。
4.@Required 注解有什么作用
这个注解表明bean的属性必须在配置的时候设置,通过一个bean定义的显式的属性值或通过自动装配,若@Required注解的bean属性未被设置,容器将抛出BeanInitializationException。示例:
public class Employee {
private String name;
@Required
public void setName(String name){
this.name=name;
}
public string getName(){
return name;
}
}
5.@Autowired 注解有什么作用
@Autowired默认是按照类型装配注入的,默认情况下它要求依赖对象必须存在(可以设置它required属性为false)。@Autowired 注解提供了更细粒度的控制,包括在何处以及如何完成自动装配。它的用法和@Required一样,修饰setter方法、构造器、属性或者具有任意名称和/或多个参数的PN方法。
public class Employee {
private String name;
@Autowired
public void setName(String name) {
this.name=name;
}
public string getName(){
return name;
}
}
6.@Autowired和@Resource之间的区别
@Autowired可用于:构造函数、成员变量、Setter方法
@Autowired和@Resource之间的区别
-
@Autowired默认是按照类型装配注入的,默认情况下它要求依赖对象必须存在(可以设置它required属性为false)。
-
@Resource默认是按照名称来装配注入的,只有当找不到与名称匹配的bean才会按照类型来装配注入。
7.@Qualifier 注解有什么作用
当您创建多个相同类型的 bean 并希望仅使用属性装配其中一个 bean 时,您可以使用@Qualifier 注解和 @Autowired 通过指定应该装配哪个确切的 bean 来消除歧义。
8.@RequestMapping 注解有什么用?
@RequestMapping 注解用于将特定 HTTP 请求方法映射到将处理相应请求的控制器中的特定类/方法。此注释可应用于两个级别:
- 类级别:映射请求的 URL
- 方法级别:映射 URL 以及 HTTP 请求方法
五、Spring数据访问
1.解释对象/关系映射集成模块
Spring 通过提供ORM模块,支持我们在直接JDBC之上使用一个对象/关系映射映射(ORM)工具,Spring 支持集成主流的ORM框架,如Hiberate,JDO和 iBATIS,JPA,TopLink,JDO,OJB 。Spring的事务管理同样支持以上所有ORM框架及JDBC。
2.在Spring框架中如何更有效地使用JDBC?
使用Spring JDBC 框架,资源管理和错误处理的代价都会被减轻。所以开发者只需写statements 和 queries从数据存取数据,JDBC也可以在Spring框架提供的模板类的帮助下更有效地被使用,这个模板叫JdbcTemplate
3.解释JDBC抽象和DAO模块
通过使用JDBC抽象和DAO模块,保证数据库代码的简洁,并能避免数据库资源错误关闭导致的问题,它在各种不同的数据库的错误信息之上,提供了一个统一的异常访问层。它还利用Spring的AOP 模块给Spring应用中的对象提供事务管理服务。
4.Spring DAO 有什么用?
Spring DAO(数据访问对象) 使得 JDBC,Hibernate 或 JDO 这样的数据访问技术更容易以一种统一的方式工作。这使得用户容易在持久性技术之间切换。它还允许您在编写代码时,无需考虑捕获每种技术不同的异常。
5.Spring JDBC API 中存在哪些类?
JdbcTemplate
SimpleJdbcTemplate
NamedParameterJdbcTemplate
SimpleJdbcInsert
SimpleJdbcCall
6.JdbcTemplate是什么
JdbcTemplate 类提供了很多便利的方法解决诸如把数据库数据转变成基本数据类型或对象,执行写好的或可调用的数据库操作语句,提供自定义的数据错误处理。
7.使用Spring通过什么方式访问Hibernate?使用 Spring 访问 Hibernate 的方法有哪些?
在Spring中有两种方式访问Hibernate:
- 使用 Hibernate 模板和回调进行控制反转
- 扩展 HibernateDAOSupport 并应用 AOP 拦截器节点
8.如何通过HibernateDaoSupport将Spring和Hibernate结合起来?
用Spring的 SessionFactory 调用 LocalSessionFactory。集成过程分三步:
- 配置the Hibernate SessionFactory
- 继承HibernateDaoSupport实现一个DAO
- 在AOP支持的事务中装配
9.Spring支持的事务管理类型, spring 事务实现方式有哪些?
Spring支持两种类型的事务管理:
编程式事务管理:这意味你通过编程的方式管理事务,给你带来极大的灵活性,但是难维护。
声明式事务管理:这意味着你可以将业务代码和事务管理分离,你只需用注解和XML配置来管理事务。
10.Spring事务的实现方式和实现原理
Spring事务的本质其实就是数据库对事务的支持,没有数据库的事务支持,spring是无法提供事务功能的。真正的数据库层的事务提交和回滚是通过binlog或者redo log实现的。
11.Spring的事务传播行为
一共有7种事务传播行为:
(1)PROPAGATION_REQUIRED:这个是最常见的,就是说,如果ServiceA.method调用了ServiceB.method,如果ServiceA.method开启了事务,然后ServiceB.method也声明了事务,那么ServiceB.method不会开启独立事务,而是将自己的操作放在ServiceA.method的事务中来执行,ServiceA和ServiceB任何一个报错都会导致整个事务回滚。这就是默认的行为,其实一般我们都是需要这样子的。
(2)PROPAGATION_SUPPORTS:如果ServiceA.method开了事务,那么ServiceB就将自己加入ServiceA中来运行,如果ServiceA.method没有开事务,那么ServiceB自己也不开事务
(3)PROPAGATION_MANDATORY:必须被一个开启了事务的方法来调用自己,否则报错
(4)PROPAGATION_REQUIRES_NEW:ServiceB.method强制性自己开启一个新的事务,然后ServiceA.method的事务会卡住,等ServiceB事务完了自己再继续。这就是影响的回滚了,如果ServiceA报错了,ServiceB是不会受到影响的,ServiceB报错了,ServiceA也可以选择性的回滚或者是提交。
(5)PROPAGATION_NOT_SUPPORTED:就是ServiceB.method不支持事务,ServiceA的事务执行到ServiceB那儿,就挂起来了,ServiceB用非事务方式运行结束,ServiceA事务再继续运行。这个好处就是ServiceB代码报错不会让ServiceA回滚。
(6)PROPAGATION_NEVER:不能被一个事务来调用,ServiceA.method开事务了,但是调用了ServiceB会报错
(7)PROPAGATION_NESTED:开启嵌套事务,ServiceB开启一个子事务,如果回滚的话,那么ServiceB就回滚到开启子事务的这个save point。
大家回头想想那个面试题,其实就是ServiceA里循环51调用ServiceB,第51次调用ServiceB失败了。第一个选项,就是两个事务都设置为PROPAGATION_REQUIRED就好了,ServiceB的所有操作都加入了ServiceA启动的一个大事务里去,任何一次失败都会导致整个事务的回滚;第二个选项,就是将ServiceB设置为PROPAGATION_REQUIRES_NEW,这样ServiceB的每次调用都在一个独立的事务里执行,这样的话,即使第51次报错,但是仅仅只是回滚第51次的操作,前面50次都在独立的事务里成功了,是不会回滚的。
其实一般也就PROPAGATION_REQUIRES_NEW比较常用,要的效果就是嵌套的那个事务是独立的事务,自己提交或者回滚,不影响外面的大事务,外面的大事务可以获取抛出的异常,自己决定是继续提交大事务还是回滚大事务。
12.Spring 的事务隔离?
什么是事务的隔离性?
隔离性是指,多个用户的并发事务访问同一个数据库时,一个用户的事务不应该被其他用户的事务干扰,多个并发事务之间要相互隔离。
咱们举例子来说明:
建表语句:
CREATE TABLE `T` (
`id` int(11) NOT NULL,
`name` varchar(255) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE = INNODB;
数据列表:
| id | name |
|---|---|
| 1 | xiaohong |
| 2 | zhangsan |
| 3 | lisi |
案例一:
事务A,先执行,处于未提交的状态:
insert into T values(4, wangwu);
事务B,后执行,也未提交:
select * from T;
如果事务B能够读取到(4, wangwu)这条记录,事务A就对事务B产生了影响,这个影响叫做“读脏”,读到了未提交事务操作的记录。
案例二:
事务A,先执行:
select * from T where id=1;
结果集为:1, xiaohong
事务B,后执行,并且提交:
update T set name=hzy where id=1;
commit;
事务A,再次执行相同的查询:
select * from T where id=1;
结果集为:1, hzy
这次是已提交事务B对事务A产生的影响,这个影响叫做“不可重复读”,一个事务内相同的查询,得到了不同的结果。
案例三:
事务A,先执行:
select * from T where id>3;
结果集为: NULL
事务B,后执行,并且提交:
insert into T values(4, wangwu);
commit;
事务A,首次查询了id>3的结果为NULL,于是想插入一条为4的记录:
insert into T values(4, hzy);
结果集为: Error : duplicate key!
这次是已提交事务B对事务A产生的影响,这个影响叫做“幻读”。
可以看到,并发的事务可能导致其他事务:
-
读脏
-
不可重复读
-
幻读
InnoDB实现了四种不同事务的隔离级别:
- 读未提交(Read Uncommitted)
- 读提交(Read Committed, RC)
- 可重复读(Repeated Read, RR)
- 串行化(Serializable)
不同事务的隔离级别,实际上是一致性与并发性的一个权衡与折衷。
InnoDB的四种事务的隔离级别,分别是怎么实现的?
InnoDB使用不同的锁策略(Locking Strategy)来实现不同的隔离级别。
(1)读未提交(Read Uncommitted)
这种事务隔离级别下,select语句不加锁。
此时,可能读取到不一致的数据,即“读脏”。这是并发最高,一致性最差的隔离级别。
(2)串行化(Serializable)
这种事务的隔离级别下,所有select语句都会被隐式的转化为select … in share mode.
这可能导致,如果有未提交的事务正在修改某些行,所有读取这些行的select都会被阻塞住。
这是一致性最好的,但并发性最差的隔离级别。 在互联网大数据量,高并发量的场景下,几乎不会使用上述两种隔离级别。
(3)可重复读(Repeated Read, RR) 这是InnoDB默认的隔离级别,在RR下:
①普通的select使用快照读(snapshot read),这是一种不加锁的一致性读(Consistent Nonlocking Read),底层使用MVCC来实现;
②加锁的select(select … in share mode / select … for update), update, delete等语句,它们的锁,依赖于它们是否在唯一索引(unique index)上使用了唯一的查询条件(unique search condition),或者范围查询条件(range-type search condition):
- 在唯一索引上使用唯一的查询条件,会使用记录锁(record lock),而不会封锁记录之间的间隔,即不会使用间隙锁(gap lock)与临键锁(next-key lock)
- 范围查询条件,会使用间隙锁与临键锁,锁住索引记录之间的范围,避免范围间插入记录,以避免产生幻影行记录,以及避免不可重复的读
(4)读提交(Read Committed, RC) 这是互联网最常用的隔离级别,在RC下:
①普通读是快照读;
②加锁的select, update, delete等语句,除了在外键约束检查(foreign-key constraint checking)以及重复键检查(duplicate-key checking)时会封锁区间,其他时刻都只使用记录锁;
此时,其他事务的插入依然可以执行,就可能导致,读取到幻影记录。
13.Spring框架的事务管理有哪些优点?
- 为不同的事务API 如 JTA,JDBC,Hibernate,JPA 和JDO,提供一个不变的编程模式。
- 为编程式事务管理提供了一套简单的API而不是一些复杂的事务API
- 支持声明式事务管理。
- 和Spring各种数据访问抽象层很好得集成。
14.你更倾向用那种事务管理类型?
大多数Spring框架的用户选择声明式事务管理,因为它对应用代码的影响最小,因此更符合一个无侵入的轻量级容器的思想。声明式事务管理要优于编程式事务管理,虽然比编程式事务管理(这种方式允许你通过代码控制事务)少了一点灵活性。唯一不足地方是,最细粒度只能作用到方法级别,无法做到像编程式事务那样可以作用到代码块级别。
六、Spring面向切面编程(AOP)
1.什么是AOP?
OOP即面向对象的程序设计,谈起了OOP,我们就不得不了解一下POP即面向过程程序设计,它是以功能为中心来进行思考和组织的一种编程方式,强调的是系统的数据被加工和处理的过程,说白了就是注重功能性的实现,效果达到就好了,而OOP则注重封装,强调整体性的概念,以对象为中心,将对象的内部组织与外部环境区分开来。之前看到过一个很贴切的解释,博主把它们画成一幅图如下:

在这里我们暂且把程序设计比喻为房子的布置,一间房子的布局中,需要各种功能的家具和洁具(类似方法),如马桶、浴缸、天然气灶,床、桌子等,对于面向过程的程序设计更注重的是功能的实现(即功能方法的实现),效果符合预期就好,因此面向过程的程序设计会更倾向图1设置结构,各种功能都已实现,房子也就可以正常居住了。但对于面向对象的程序设计则是无法忍受的,这样的设置使房子内的各种家具和洁具间摆放散乱并且相互暴露的机率大大增加,各种气味相互参杂,显然是很糟糕的,于是为了更优雅地设置房屋的布局,面向对象的程序设计便采用了图2的布局,对于面向对象程序设计来说这样设置好处是显而易见的,房子中的每个房间都有各自的名称和相应功能(在java程序设计中一般把类似这样的房间称为类,每个类代表着一种房间的抽象体),如卫生间是大小解和洗澡梳妆用的,卧室是休息用的,厨房则是做饭用的,每个小房间都各司其职并且无需时刻向外界暴露内部的结构,整个房间结构清晰,外界只需要知道这个房间并使用房间内提供的各项功能即可(方法调用),同时也更有利于后期的拓展了,毕竟哪个房间需要添加那些功能,其范围也有了限制,也就使职责更加明确了(单一责任原则)。OOP的出现对POP确实存在很多颠覆性的,但并不能说POP已没有价值了,毕竟只是不同时代的产物,从方法论来讲,更喜欢将面向过程与面向对象看做是事物的两个方面–局部与整体(你必须要注意到局部与整体是相对的),因此在实际应用中,两者方法都同样重要。了解完OOP和POP各自的特点,接着看java程序设计过程中OOP应用,在java程序设计过程中,我们几乎享尽了OOP设计思想带来的甜头,以至于在这个一切皆对象,众生平等的世界里,狂欢不已,而OOP确实也遵循自身的宗旨即将数据及对数据的操作行为放在一起,作为一个相互依存、不可分割的整体,这个整体美其名曰:对象,利用该定义对于相同类型的对象进行分类、抽象后,得出共同的特征,从而形成了类,在java程序设计中这些类就是class,由于类(对象)基本都是现实世界存在的事物概念(如前面的不同的小房间)因此更接近人们对客观事物的认识,同时把数据和方法(算法)封装在一个类(对象)中,这样更有利于数据的安全,一般情况下属性和算法只单独属于某个类,从而使程序设计更简单,也更易于维护。基于这套理论思想,在实际的软件开发中,整个软件系统事实也是由系列相互依赖的对象所组成,而这些对象也是被抽象出来的类。相信大家在实际开发中是有所体验的(本篇文件假定读者已具备面向对象的开发思想包括封装、继承、多态的知识点)。但随着软件规模的增大,应用的逐渐升级,慢慢地,OOP也开始暴露出一些问题,现在不需要急于知道它们,通过案例,我们慢慢感受。
A类:
public class A {
public void executeA(){
//其他业务操作省略......
recordLog();
}
public void recordLog(){
//....记录日志并上报日志系统
}
}
B类:
public class B {
public void executeB(){
//其他业务操作省略......
recordLog();
}
public void recordLog(){
//....记录日志并上报日志系统
}
}
C类:
public class C {
public void executeC(){
//其他业务操作省略......
recordLog();
}
public void recordLog(){
//....记录日志并上报日志系统
}
}
假设存在A、B、C三个类,需要对它们的方法访问进行日志记录,在代码中各种存在recordLog方法进行日志记录并上报,或许对现在的工程师来说几乎不可能写出如此糟糕的代码,但在OOP这样的写法是允许的,而且在OOP开始阶段这样的代码确实并大量存在着,直到工程师实在忍受不了一次修改,到处挖坟时(修改recordLog内容),才下定决心解决该问题,为了解决程序间过多冗余代码的问题,工程师便开始使用下面的编码方式。
//通用父类
public class Dparent {
public void commond(){
//通用代码
}
}
//A 继承 Dparent
public class A extends Dparent {
public void executeA(){
//其他业务操作省略......
commond();
}
}
//B 继承 Dparent
public class B extends Dparent{
public void executeB(){
//其他业务操作省略......
commond();
}
}
//C 继承 Dparent
public class C extends Dparent{
public void executeC(){
//其他业务操作省略......
commond();
}
}
显然代码冗余也得到了解决,这种通过继承抽取通用代码的方式也称为纵向拓展,与之对应的还有横向拓展(现在不需急于明白,后面的分析中它将随处可见)。事实上有了上述两种解决方案后,在大部分业务场景的代码冗余问题也得到了实实在在的解决,原理如下图

但是随着软件开发的系统越来越复杂,工程师认识到,传统的OOP程序经常表现出一些不自然的现象,核心业务中总掺杂着一些不相关联的特殊业务,如日志记录,权限验证,事务控制,性能检测,错误信息检测等等,这些特殊业务可以说和核心业务没有根本上的关联而且核心业务也不关心它们,比如在用户管理模块中,该模块本身只关心与用户相关的业务信息处理,至于其他的业务完全可以不理会,我们看一个简单例子协助理解这个问题
public interface IUserService {
void saveUser();
void deleteUser();
void findAllUser();
}
//实现类
public class UserServiceImpl implements IUserService {
//核心数据成员
//日志操作对象
//权限管理对象
//事务控制对象
@Override
public void saveUser() {
//权限验证(假设权限验证丢在这里)
//事务控制
//日志操作
//进行Dao层操作
userDao.saveUser();
}
@Override
public void deleteUser() {
}
@Override
public void findAllUser() {
}
}
上述代码中我们注意到一些问题,权限,日志,事务都不是用户管理的核心业务,也就是说用户管理模块除了要处理自身的核心业务外,还需要处理权限,日志,事务等待这些杂七杂八的不相干业务的外围操作,而且这些外围操作同样会在其他业务模块中出现,这样就会造成如下问题
- 代码混乱:核心业务模块可能需要兼顾处理其他不相干的业务外围操作,这些外围操作可能会混乱核心操作的代码,而且当外围模块有重大修改时也会影响到核心模块,这显然是不合理的。
- 代码分散和冗余:同样的功能代码,在其他的模块几乎随处可见,导致代码分散并且冗余度高。
- 代码质量低扩展难:由于不太相关的业务代码混杂在一起,无法专注核心业务代码,当进行类似无关业务扩展时又会直接涉及到核心业务的代码,导致拓展性低。
显然前面分析的两种解决方案已束手无策了,那么该如何解决呢?事实上我们知道诸如日志,权限,事务,性能监测等业务几乎涉及到了所有的核心模块,如果把这些特殊的业务代码直接到核心业务模块的代码中就会造成上述的问题,而工程师更希望的是这些模块可以实现热插拔特性而且无需把外围的代码入侵到核心模块中,这样在日后的维护和扩展也将会有更佳的表现,假设现在我们把日志、权限、事务、性能监测等外围业务看作单独的关注点(也可以理解为单独的模块),每个关注点都可以在需要它们的时刻及时被运用而且无需提前整合到核心模块中,这种形式相当下图:

从图可以看出,每个关注点与核心业务模块分离,作为单独的功能,横切几个核心业务模块,这样的做的好处是显而易见的,每份功能代码不再单独入侵到核心业务类的代码中,即核心模块只需关注自己相关的业务,当需要外围业务(日志,权限,性能监测、事务控制)时,这些外围业务会通过一种特殊的技术自动应用到核心模块中,这些关注点有个特殊的名称,叫做“横切关注点”,上图也很好的表现出这个概念,另外这种抽象级别的技术也叫AOP(面向切面编程),正如上图所展示的横切核心模块的整面,因此AOP的概念就出现了,而所谓的特殊技术也就面向切面编程的实现技术,AOP的实现技术有多种,其中与Java无缝对接的是一种称为AspectJ的技术。那么这种切面技术(AspectJ)是如何在Java中的应用呢?不必担心,也不必全面了解AspectJ,本篇博文也不会这样进行,对于AspectJ,我们只会进行简单的了解,从而为理解Spring中的AOP打下良好的基础(Spring AOP 与AspectJ 实现原理上并不完全一致,但功能上是相似的,这点后面会分析),毕竟Spring中已实现AOP主要功能,开发中直接使用Spring中提供的AOP功能即可,除非我们想单独使用AspectJ的其他功能。这里还需要注意的是,AOP的出现确实解决外围业务代码与核心业务代码分离的问题,但它并不会替代OOP,如果说OOP的出现是把编码问题进行模块化,那么AOP就是把涉及到众多模块的某一类问题进行统一管理,因此在实际开发中AOP和OOP同时存在并不奇怪,后面将会慢慢体会带这点,好的,已迫不及待了,让我们开始了解神一样的AspectJ吧。
2.Spring AOP and AspectJ AOP 有什么区别?AOP 有哪些实现方式?
AOP实现的关键在于 代理模式,AOP代理主要分为静态代理和动态代理。静态代理的代表为AspectJ;动态代理则以Spring AOP为代表。
(1)AspectJ是静态代理的增强,所谓静态代理,就是AOP框架会在编译阶段生成AOP代理类,因此也称为编译时增强,他会在编译阶段将AspectJ(切面)织入到Java字节码中,运行的时候就是增强之后的AOP对象。
(2)Spring AOP使用的动态代理,所谓的动态代理就是说AOP框架不会去修改字节码,而是每次运行时在内存中临时为方法生成一个AOP对象,这个AOP对象包含了目标对象的全部方法,并且在特定的切点做了增强处理,并回调原对象的方法。
3.JDK动态代理和CGLIB动态代理的区别
Spring AOP中的动态代理主要有两种方式,JDK动态代理和CGLIB动态代理:
-
JDK动态代理只提供接口的代理,不支持类的代理。核心InvocationHandler接口和Proxy类,InvocationHandler 通过invoke()方法反射来调用目标类中的代码,动态地将横切逻辑和业务编织在一起;接着,Proxy利用 InvocationHandler动态创建一个符合某一接口的的实例, 生成目标类的代理对象。
-
如果代理类没有实现 InvocationHandler 接口,那么Spring AOP会选择使用CGLIB来动态代理目标类。CGLIB(Code Generation Library),是一个代码生成的类库,可以在运行时动态的生成指定类的一个子类对象,并覆盖其中特定方法并添加增强代码,从而实现AOP。CGLIB是通过继承的方式做的动态代理,因此如果某个类被标记为final,那么它是无法使用CGLIB做动态代理的。
静态代理与动态代理区别在于生成AOP代理对象的时机不同,相对来说AspectJ的静态代理方式具有更好的性能,但是AspectJ需要特定的编译器进行处理,而Spring AOP则无需特定的编译器处理。
InvocationHandler 的 invoke(Object proxy,Method method,Object[] args):proxy是最终生成的代理实例; method 是被代理目标实例的某个具体方法; args 是被代理目标实例某个方法的具体入参, 在方法反射调用时使用。
4.如何理解 Spring 中的代理?
将 Advice 应用于目标对象后创建的对象称为代理。在客户端对象的情况下,目标对象和代理对象是相同的。
Advice + Target Object = Proxy
5.解释一下Spring AOP里面的几个名词
(1)切面(Aspect):切面是通知和切点的结合。通知和切点共同定义了切面的全部内容。 在Spring AOP中,切面可以使用通用类(基于模式的风格) 或者在普通类中以 @AspectJ 注解来实现。
(2)连接点(Join point):指方法,在Spring AOP中,一个连接点 总是 代表一个方法的执行。 应用可能有数以千计的时机应用通知。这些时机被称为连接点。连接点是在应用执行过程中能够插入切面的一个点。这个点可以是调用方法时、抛出异常时、甚至修改一个字段时。切面代码可以利用这些点插入到应用的正常流程之中,并添加新的行为。
(3)通知(Advice):在AOP术语中,切面的工作被称为通知。
(4)切入点(Pointcut):切点的定义会匹配通知所要织入的一个或多个连接点。我们通常使用明确的类和方法名称,或是利用正则表达式定义所匹配的类和方法名称来指定这些切点。
(5)引入(Introduction):引入允许我们向现有类添加新方法或属性。
(6)目标对象(Target Object): 被一个或者多个切面(aspect)所通知(advise)的对象。它通常是一个代理对象。也有人把它叫做 被通知(adviced) 对象。 既然Spring AOP是通过运行时代理实现的,这个对象永远是一个 被代理(proxied) 对象。
(7)织入(Weaving):织入是把切面应用到目标对象并创建新的代理对象的过程。在目标对象的生命周期里有多少个点可以进行织入:
- 编译期:切面在目标类编译时被织入。AspectJ的织入编译器是以这种方式织入切面的。
- 类加载期:切面在目标类加载到JVM时被织入。需要特殊的类加载器,它可以在目标类被引入应用之前增强该目标类的字节码。AspectJ5的加载时织入就支持以这种方式织入切面。
- 运行期:切面在应用运行的某个时刻被织入。一般情况下,在织入切面时,AOP容器会为目标对象动态地创建一个代理对象。SpringAOP就是以这种方式织入切面。
6.Spring在运行时通知对象
通过在代理类中包裹切面,Spring在运行期把切面织入到Spring管理的bean中。代理封装了目标类,并拦截被通知方法的调用,再把调用转发给真正的目标bean。当代理拦截到方法调用时,在调用目标bean方法之前,会执行切面逻辑。
直到应用需要被代理的bean时,Spring才创建代理对象。如果使用的是ApplicationContext的话,在ApplicationContext从BeanFactory中加载所有bean的时候,Spring才会创建被代理的对象。因为Spring运行时才创建代理对象,所以我们不需要特殊的编译器来织入SpringAOP的切面。
7.Spring只支持方法级别的连接点
因为Spring基于动态代理,所以Spring只支持方法连接点。Spring缺少对字段连接点的支持,而且它不支持构造器连接点。方法之外的连接点拦截功能,我们可以利用Aspect来补充。
8.在Spring AOP 中,关注点和横切关注的区别是什么?在 spring aop 中 concern 和 cross-cutting concern 的不同之处
关注点(concern)是应用中一个模块的行为,一个关注点可能会被定义成一个我们想实现的一个功能。
横切关注点(cross-cutting concern)是一个关注点,此关注点是整个应用都会使用的功能,并影响整个应用,比如日志,安全和数据传输,几乎应用的每个模块都需要的功能。因此这些都属于横切关注点。
9.Spring通知有哪些类型?
在AOP术语中,切面的工作被称为通知,实际上是程序执行时要通过SpringAOP框架触发的代码段。
Spring切面可以应用5种类型的通知:
1.前置通知(Before):在目标方法被调用之前调用通知功能;
2.后置通知(After):在目标方法完成之后调用通知,此时不会关心方法的输出是什么;
3.返回通知(After-returning ):在目标方法成功执行之后调用通知;
4.异常通知(After-throwing):在目标方法抛出异常后调用通知;
5.环绕通知(Around):通知包裹了被通知的方法,在被通知的方法调用之前和调用之后执行自定义的行为。
同一个aspect,不同advice的执行顺序:
①没有异常情况下的执行顺序:
around before advice
before advice
target method 执行
around after advice
after advice
afterReturning②有异常情况下的执行顺序:
around before advice
before advice
target method 执行
around after advice
after advice
afterThrowing:异常发生
java.lang.RuntimeException: 异常发生
10.什么是切面 Aspect?
aspect 由 pointcount 和 advice 组成,切面是通知和切点的结合。 它既包含了横切逻辑的定义, 也包括了连接点的定义. Spring AOP 就是负责实施切面的框架, 它将切面所定义的横切逻辑编织到切面所指定的连接点中.
AOP 的工作重心在于如何将增强编织目标对象的连接点上, 这里包含两个工作:
- 如何通过 pointcut 和 advice 定位到特定的 joinpoint 上
- 如何在 advice 中编写切面代码.
可以简单地认为, 使用 @Aspect 注解的类就是切面.

11.解释基于XML Schema方式的切面实现
在这种情况下,切面由常规类以及基于XML的配置实现。
12.解释基于注解的切面实现
在这种情况下(基于@AspectJ的实现),涉及到的切面声明的风格与带有java5标注的普通java类一致。
13.有几种不同类型的自动代理?
BeanNameAutoProxyCreator
DefaultAdvisorAutoProxyCreator
Metadata autoproxying

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 93
93 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)