毫米波雷达视觉融合3D目标检测论文综述(一)
最近在研究基于毫米波雷达雷达和视觉融合的3D目标,于是查找了相关文献,在这里把看过的论文做个总结。给予自己的理解,希望大家批评指正。
最近在研究基于雷达和视觉融合的3D目标,于是查找了相关文献,在这里把看过的论文做个总结,结果是val下的NDS和mAP。
毫米波雷达视觉融合3D目标检测论文综述(二)
毫米波雷达视觉融合3D目标检测论文综述(三)
| paper | 发表地方 | 融合方法 | 代码链接 | backbone | NDS | mAP |
|---|---|---|---|---|---|---|
| CenterFusion | WACV2021 | 3D框与雷达点关联 | pytorch代码 | DAL34 | 0.453 | 0.332 |
| RADIANT | AAAI2023 | 3D框与雷达点关联 | pytorch代码 | R101 | - | 0.384 |
| CRAFT | AAAI2023 | 3D框与雷达点关联 | - | DLA34 | 0.517 | 0.411 |
接下来上述论文进行分析:
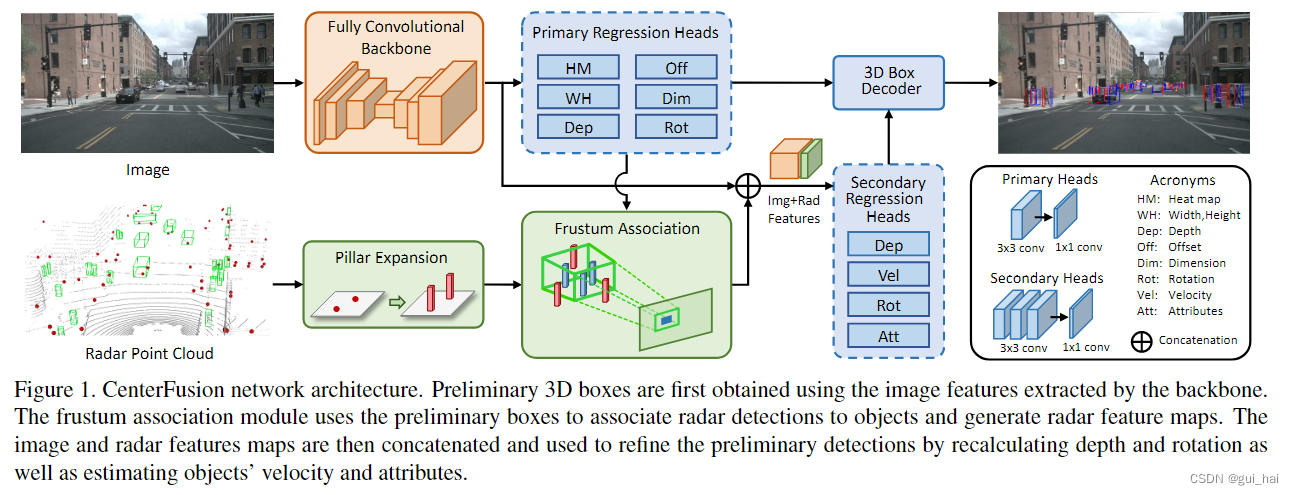
一、CenterFusion:Center-based Radar and Camera Fusion for 3D Object Detection

1、雷达点云的预处理:首先聚集三帧的雷达点(大约0.25s),并将所有的雷达点投影到车辆坐标系(egocentric coordinate system)记录每个雷达点的特征为(
x
,
y
,
z
,
v
x
,
v
y
x,y,z,v_x,v_y
x,y,z,vx,vy)其中
x
,
y
,
z
x,y,z
x,y,z为位置信息,
v
x
,
v
y
v_x,v_y
vx,vy为
x
,
y
x,y
x,y方向的径向速度。
2、利用CenterNet预先生成3D检测框:关于centernet可以看这篇博客:CenterNet.
3、CenterFusion流程:
- 出发点:CenterNet的思想时通过利用所生成的热力图来预测物体的中心。其中他热力图的峰值代表这可能存在的物体,所以作者想通过将雷达点映射到物体上来增强热力图对应位置的特征。由于雷达没有高度信息,所以在投影到图像上的时候不准确,所以如何将雷达点准确的图像中物体关联是一个棘手的问题。作者提出了一个基于视锥体的雷达图像关联方法。
- 具体流程:
3.1、 利用CenterNet生成一个精确的2D包围框以及一个初步的3D包围框。其中特征提取使用的时DLA,之后利用回归头来会馆相关属性(2d框的中心点的偏移,长宽,3d框的长宽高、深度、偏角)。
3.2、利用所提出的视锥体方法来进行特征和雷达点关联,视锥体关联主要有两部,给一个要关联的2d框以及对应的3d检测框的深度,首先判断投影到图像上的点是不是在2d框内,留下所有的2d框内的点;其次根据预测的深度,在前方和后方生成要给深度区间,雷达点的深度如果在该区间内,那么就保留,同时满足上述两个条件的雷达点表示和这个物体时关联的,最后如果有多个雷达点都满足的话利用最近的雷达点最为该2d框关联的雷达点,对一幅图像内所有的2d框进行上述操作来获取对应的关联雷达点。训练的时候3d框和2d框使用的都是groundtruth,测试时候使用的是预测值。
3.3、为了更有效地对特显特征进行增强,作者设计了一个3D pillars来扩展雷达点。同时将深度、x、y方向的速度3个特征作为雷达的特征。
3.4、将获取到的雷达特征和图像特征进行拼接来重新估计更准确的深度、速度、旋转和物体所属的属性。
关于CenterFusion的代码分析可以看一下三个链接:
二、RADIANT: Radar-Image Association Network for 3D Object Detection

1、出发点:单目相机无法预测正确的深度信息,作者想通过雷达来更新预测的深度信息。为了实现这一目的需要解决两个问题:
-
雷达回波可能处于物体的表面,内部或者其他地方导致深度信息相对于物体中心有一定的偏移
-
雷达回波有可能处于GT框的外边,但是有可能该雷达点与GT框表示的是同一个物体
2、解决方法:通过训练一个雷达相关的网络来预测每个雷达点相对于GT框中心的偏移量(深度偏移量、雷达点偏移量)。由于作者直接把雷达点当作所有的候选框,在这里预测这些偏执,之后可以直接对雷达点的相关属性进行纠正。假如预测的偏移量是正确的话那么就可以通过闻值的方法来对雷达点和物体进行关联。
3、具体流程:
- 如上图所示,网络分为两个分支,一个为图像分支,作者在这里使用的是FCOS3D没有对网络进行改变,另一个雷达分支,也是将雷达点投影到图像平面,之后去雷达特征作为投影到图像上的特征值,由于雷达点的稀疏性,在进行特征提取的时候使用的是ReSNet-18。之后在特征提取结束后和图像特征进行拼接从而预测3D框需要的值。由于雷达分支特征的稀疏性,作者在雷达头进行预测的时候只是预测了类分数以及相对于雷达点的相对位置,即深度偏移和位置偏移。图像分支则预测了所有的和3d框相关的值。之后将者预测的结果输入到深度融合模型中来融合二者预测出来的深度值。
深度融合模型:主要包含两步:雷达相机关联,深度信息融合
雷达相机关联: 首先该模块中图像分支预测要用的结果包括投影中心( u ^ i c , v ^ i c \widehat{u}_i^c,\widehat{v}_i^c u ic,v ic),预测的深度 z ^ i c \widehat{z}_i^c z ic,类别 y ^ i c \widehat{y}_i^c y ic,以及检测的分数 σ ^ i c \widehat{\sigma}_i^c σ ic,雷达分支结果为:相对于雷达投影点的偏移量( ∇ u ^ j r , ∇ v ^ j r \nabla\widehat{u}_j^r,\nabla\widehat{v}_j^r ∇u jr,∇v jr),雷达点深度和框中心对应深度的深度偏差 ∇ z ^ j r \nabla\widehat{z}_j^r ∇z jr,类别 y ^ j r \widehat{y}_j^r y jr,检测分数 σ ^ j r \widehat{\sigma}_j^r σ jr。
b i c = u ^ i c , v ^ i c , z ^ i c , y ^ i c , σ ^ i c b j r = ∇ u ^ j r , ∇ v ^ j r , ∇ z ^ j r , y ^ j r , σ ^ j r \begin{align} b_i^c = {\widehat{u}_i^c,\widehat{v}_i^c,\widehat{z}_i^c,\widehat{y}_i^c,\widehat{\sigma}_i^c}\\ b_j^r = {\nabla\widehat{u}_j^r,\nabla\widehat{v}_j^r,\nabla\widehat{z}_j^r,\widehat{y}_j^r,\widehat{\sigma}_j^r} \end{align} bic=u ic,v ic,z ic,y ic,σ icbjr=∇u jr,∇v jr,∇z jr,y jr,σ jr
这里说明一下我理解的预测的偏差:中心偏差:作者偏差是由于雷达没有高度信息从而导致投影在图像平面上不准确的问题。所以作者在这里想预测雷达点投影的位置相对于图像中2d框中心的偏移量,之后通过用原始雷达点减去偏移量来得到准确的雷大投影点,深度偏差:由于雷达可能在物体表面任何位置,但是实际进行推测的时候使用的是3d框中小的深度值,所以希望通过预测雷达点深度偏差来纠正雷达的深度。也就有了如下两个公式:
( u ^ j r , v ^ j r ) = ( u j r , v j r ) − ( ∇ u ^ j r , ∇ v ^ j r ) z ^ j r = z j r + ∇ z ^ j r \begin{align} (\widehat{u}_j^r,\widehat{v}_j^r) = ({u}_j^r,{v}_j^r)-(\nabla\widehat{u}_j^r,\nabla\widehat{v}_j^r)\\ \widehat{z}_j^r = z_j^r+\nabla\widehat{z}_j^r \end{align} (u jr,v jr)=(ujr,vjr)−(∇u jr,∇v jr)z jr=zjr+∇z jr
通过上述两个公式可以得到纠正后的雷达点的坐标和雷达的深度信息,之后通过设计的阈值关联方法将相机建议框和雷达点进行关联,关联规则如下:
a、雷达预测的类别标签和图像的相同
b、雷达纠正后的位置和建议框的中心距离不超过阈值 T p T_p Tp
c、雷达纠正后的深度信息和建议框的深度差距不找过 T d T_d Td
y ^ i c = y ^ j r ∣ ∣ ( u ^ i c , v ^ i c ) − ( u ^ j r , v ^ j r ) ∣ ∣ 2 < T p ∣ ∣ z ^ i c − z ^ j r ∣ ∣ 2 < T d \begin{align} \widehat{y}_i^c = \widehat{y}_j^r\\ ||(\widehat{u}_i^c,\widehat{v}_i^c)-(\widehat{u}_j^r,\widehat{v}_j^r)||_2<T_p\\ ||\widehat{z}_i^c-\widehat{z}_j^r||_2<T_d \end{align} y ic=y jr∣∣(u ic,v ic)−(u jr,v jr)∣∣2<Tp∣∣z ic−z jr∣∣2<Td
深度信息融合:通过上述所设计的雷达图像关联方法可以得到建议框所关联的雷达点,这里将利用所关联的雷达点对建议狂的深度信息进行更新。通过设计一个2分类网络来判断是否使用该雷达点来更新深度信息,网络的结构是4层的MLP,输入为雷达点对应的14D的特征,输入为0,1二值来表示是否用该雷达点来更新深度信息。标签通过如下规则得到:如果box的GT深度 z z z更接近雷达估计的深度,则GT标签 α \alpha α = 1,否则为零。
α = { 1 , ∣ z ^ j r − z ∣ < ∣ z ^ i c − z ∣ 0 , o t h e r w i s e . \begin{align} \alpha = \begin{cases} 1, |\widehat{z}_j^r-z|<|\widehat{z}_i^c-z|\\ 0, otherwise. \end{cases} \end{align} α={1,∣z jr−z∣<∣z ic−z∣0,otherwise.
通过利用分类网络可以得到使用每个雷达的概率,如果概率大于阈值 T α T_\alpha Tα,那么就利用该雷达点,之后将所有的雷达点的深度信息加权融合来作为最后的深度,否则如果所有的概率都小于阈值,那么就用视觉分支的深度信息作为最后的深度。公式如下:
z ^ f u s e = { ∑ j α j z ^ j r ∑ j α j , i f ∃ j , α j > T α z ^ i c , i f ∀ j , α j ≤ T α \begin{align} \widehat{z}_{fuse} = \begin{cases} \frac{\sum_j{\alpha_j\widehat{z}_j^r}}{\sum_j{\alpha_j}},& if \exists j,\alpha_j>T_\alpha \\ \widehat{z}_i^c,& if \forall j,\alpha_j \leq T_\alpha \end{cases} \end{align} z fuse={∑jαj∑jαjz jr,z ic,if∃j,αj>Tαif∀j,αj≤Tα
三、CRAFT: Camera-Radar 3D Object Detection with Spatio-Contextual Fusion Transformer
RADIANT从欧式空间上对图像建议框和雷达点进行关联,为了处理有效处理坐标系和空间属性之间的差异(作者在消融实验中证明了在极坐标系下相对于笛卡尔坐标系效果更好),CRAFT从极坐标系上对图像建议框和雷达点进行关联。

1、出发点: 文章出发点强调的是现有方法大多从决策层面进行融合(但是按照这个论文的时间推算的话当时应该已经有了特征层面的论文比如Centerfusion,或者一些2d融合的论文也是从特征层面出发的。不是很理解。。。),因此设计了一个早期融合的方法。
2、具体流程:
- 图像建议框生成: 通过利用CenterNet网络并对网络进行修改后得到图像建议框。修改的部分如下:
a、在检测头部分增加了深度方差头预测。并将CenterNet的L1回归损失替换为不确定性感知回归损失
b、预测投影中心方法不同
c、利用预测的深度方差对深度的置信度进行修改,使得方差较大的时候置信度较低。 - 雷达点的预处理: 利用PointNet++将雷达特征映射到新的特征空间
- 图像预测框和雷达点关联: 首先将图像框的8个点以及雷达坐标从欧氏空间转换到极坐标下分别表示为
O
(
p
)
=
{
(
r
,
ϕ
,
z
)
j
,
m
}
m
,
j
=
1
M
,
8
O^{(p)}=\{(r, \phi,z)_{j,m}\}_{m,j=1}^{M,8}
O(p)={(r,ϕ,z)j,m}m,j=1M,8和
v
(
p
)
=
{
(
r
,
ϕ
,
z
)
k
}
k
=
1
K
v^{(p)}=\{(r, \phi,z)_k\}_{k=1}^{K}
v(p)={(r,ϕ,z)k}k=1K,之后利用如下规则对于每个图像预测框来找到一个雷达点的子集。
ϕ m , l < ϕ i < ϕ m , r r m , f − ( γ + σ r c δ ) < r i < r m , b − ( γ + σ r c δ ) \begin{align} \phi_{m,l}<\phi_i<\phi_{m,r} \\ r_{m,f}-(\gamma+ \sigma\frac{r_c}{\delta})<r_i<r_{m,b}-(\gamma+ \sigma\frac{r_c}{\delta}) \end{align} ϕm,l<ϕi<ϕm,rrm,f−(γ+σδrc)<ri<rm,b−(γ+σδrc)
其中公式10表示雷达点的方位角的阈值应该在图像预测框方位角的最大角度和最小角度之间,同时半径也是,只是加了个松弛因子进去。通过上述规则得到与图像预测框相关联的雷达点。 - 利用Transformer对雷达和图像进行融合:

a、图像到雷达特征的编码器:上图中的左边部分,首先将雷达点投影到图像上,之后利用雷达的距离信息在雷达周围去patch块,距离越小表示物体越近,对应的patch块也就越大。之后利用双三次插值得到固定大小的patch块。之后利用可变形DETR来对找到对应的图像特征来获取语义信息,同时利用一个辅助网络判断该雷达点在不在3d框内来更有效地获取图像中有用的部分。(这里我感觉用到的雷达点就是关联部分的雷达点,没有关联的雷达点没有利用)最后获取到了含有图像语义信息的雷达特征。
b、雷达到图像特征的解码器:上图中的右边部分,之后利用所关联的雷达点和对应3d框对应位置的图像特征利用Cross attention来获取雷达编码的图像特征。
最后利用检测头来对各个指标进行回归来得到最终的结果。
至此通过利用关联方法的三篇论文都讲解结束了。关联方法存在一个明显的问题就是在进行图像和雷达进行关联的时候假设图像预测框的数量为N,雷达点的数量为M,那么他们的时间复杂度就是NM的,所以设计一种方法减少该部分的耗时有可能是一个研究方向。
之后介绍剩下的自适应融合的的方法,大家感兴趣的话可以参考:毫米波雷达视觉融合3D目标检测论文综述二

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐

 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)