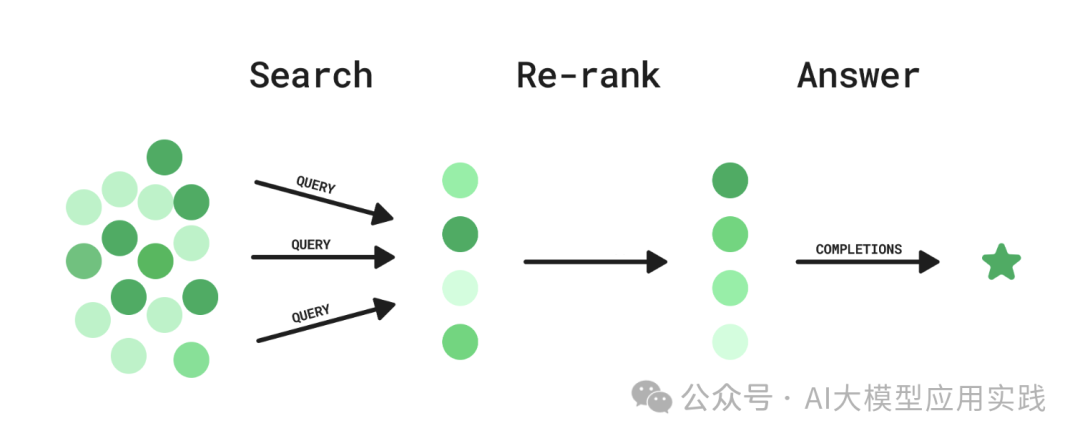
让RAG更进一步的利器:教你使用两种出色的Rerank排序模型
在高级RAG的应用中,常常会有一些“检索后处理(Post-Retrieval)”的环节。顾名思义,这是在检索出输入问题相关的多个Chunk后,在交给LLM合成答案之前的一个处理环节。在这个环节中,可以做一些诸如相似度过滤、关键词过滤、chunk内容替换等处理。其中,Rerank(重排序)是一种常见的,也是在RAG应用优化中很常见的一种技术处理环节。
前言
在高级RAG的应用中,常常会有一些“检索后处理(Post-Retrieval)”的环节。顾名思义,这是在检索出输入问题相关的多个Chunk后,在交给LLM合成答案之前的一个处理环节。在这个环节中,可以做一些诸如相似度过滤、关键词过滤、chunk内容替换等处理。其中,**Rerank(重排序)**是一种常见的,也是在RAG应用优化中很常见的一种技术处理环节。
简单的说,Rerank就是对检索出来的多个chunks(或者nodes)列表进行重新排序,使得其排名与用户输入问题的相关性更匹配,使得更相关、更准确的chunk排名更靠前,从而在 LLM生成时能够被优先考虑以提高输出质量。
那么,有了基于向量索引与语义相似度的检索,为什么还需要Rerank?
-
RAG应用中有多种索引类型,很多索引技术并非基于语义与向量构建,其检索的结果希望借助独立的Rerank实现语义重排
-
在一些复杂RAG范式中,很多时候会使用多路混合检索来获取更多相关知识;这些来自不同源、不同检索算法的chunks要借助Rerank做重排
-
即使是完全基于向量构建的索引,由于不同的嵌入模型、相似算法、语言环境、领域知识特点等影响,其语义检索的相关度排序也可能发生较大的偏差;此时借助独立的Rerank模型做纠正也非常有意义
Rerank通常需要借助于独立的算法或模型来实现。本文将实践与推荐两种被广泛使用的优秀Rerank模型:
-
在线模型 - Cohere Rerank模型
-
本地模型 - bge-reranker-large模型
Cohere Rerank模型
Cohere Rerank是一个商业闭源的Rerank模型。它根据与指定查询问题的语义相关性对多个文本输入进行排序,专门用于帮助关键词或向量搜索返回的结果做重新排序与提升质量。
为了使用Cohere Rerank,你首先需要在官方网站(https://cohere.com/)注册后申请测试的API-key(测试使用免费):
Cohere Rerank的使用非常简单,通常在LangChain与LlamaIndex框架中也会集成其SDK的使用。现在我们使用如下测试代码,来对比在Rerank之前和之后的chunk节点的排序区别(代码基于LlamaIndex框架构建,并利用其内置的cohere_rerank检索后处理器组件,这里使用了一段关于百度文心一言的介绍文档构建上下文知识库):
from llama\_index.postprocessor.cohere\_rerank import CohereRerank
`.....``#使用默认的嵌入模型构造向量索引 docs = SimpleDirectoryReader(input_files=["../../data/yiyan.txt"]).load_data() nodes = SentenceSplitter(chunk_size=100,chunk_overlap=0).get_nodes_from_documents(docs) vector_index = VectorStoreIndex(nodes) #检索器``retriever =vector_index.as_retriever(similarity_top_k=5)`` #不借助cohere rerank,直接检索出结果 nodes = retriever.retrieve("百度文心一言的逻辑推理能力怎么样?") print('================before rerank================') print_nodes(nodes) #借助cohere rerank模型重排结果 cohere_rerank = CohereRerank(model='rerank-multilingual-v3.0',api_key='***', top_n=2) rerank_nodes = cohere_rerank.postprocess_nodes(nodes,query_str='百度文心一言的逻辑推理能力怎么样?') print('================after rerank================') print_nodes(rerank_nodes)`
首先看不经过Rerank重排、直接向量检索的排序结果: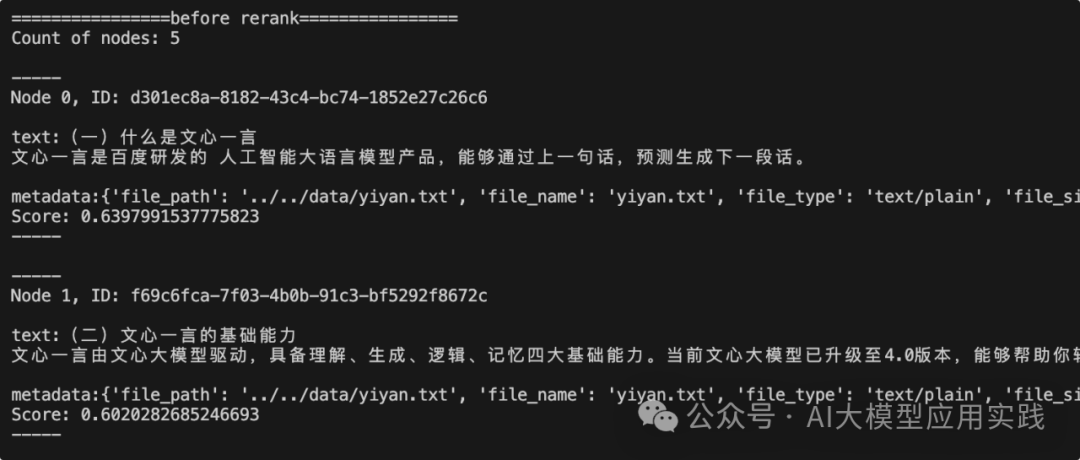
这里只打印了排名前两位的chunk节点内容,用来和后面Rerank之后的排名做对比。现在再看下经过Cohere Rerank模型重新排序后的前两名:
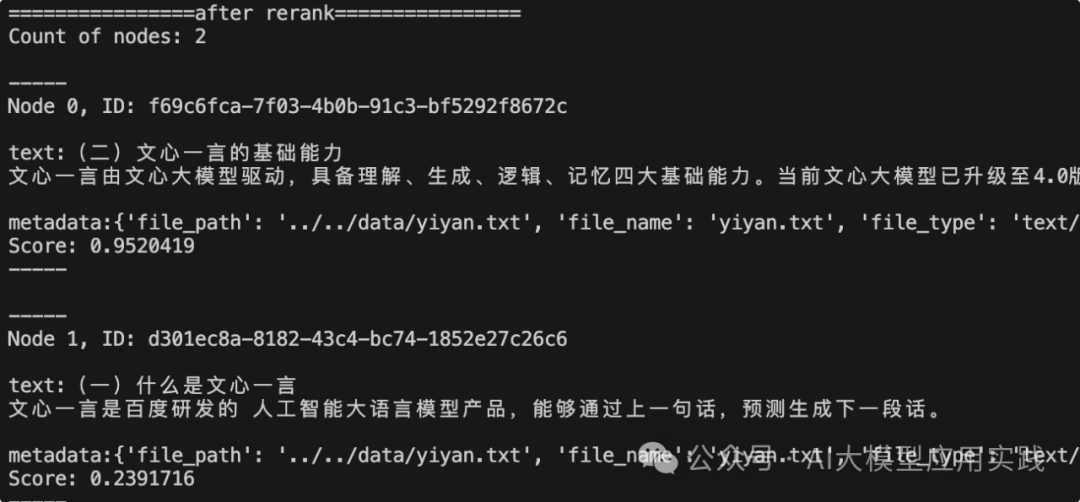
有意思的是,这里的前两名的排名结果刚好和未经过Rerank之前的排名相反!从chunk节点的内容与相应的评分(score)也能看出来,在调用Cohere Rerank之后,节点内容的相关性和其对应的评分更加匹配,排序也更加合理。这种更加合理的排名一方面有利于LLM生成更准确的回复;另一方面也可以帮助降低top_K数量,以节约上下文空间。
如果你不使用LlamaIndex,也可以导入官方cohere模块使用,这可以很方便的插入到你现有的各种应用代码中:
import cohere
co = cohere.Client(api_key="<YOUR API KEY>")
query = "你的问题..."
docs = ["相关文档1...","相关文档2...","相关文档3...",...]
results = co.rerank(model="rerank-multilingual-v3.0", query=query, documents=docs, top_n=5, return_documents=True)
注意如果需要中文支持,必须使用rerank-multilingual-v3.0模型。
bge-reranker-large模型
bge-reranker-large是国内智源开源的一个被广泛使用的Rerank模型,在众多的模型测试中有着非常优秀的成绩。为了使用这个Rerank模型,我们使用HuggingFace 的TEI来本地化部署这个模型并提供服务。在安装与部署TEI后,在命令行执行如下命令可自动下载该模型并启动TEI服务:
model=BAAI/bge-reranker-large
text-embeddings-router --model-id $model --port 8080
TEI,是HuggingFace 推出的开源 Text Embedding Inherence工具的简称,该工具主要是以部署 Embedding 模型为主(注意TEI本身不是模型,而是类似Ollama的模型部署工具),同时也支持 Rerank 模型的部署。在Mac上的基本安装过程如下(其他平台请参考官方文档):
#安装rust,如出现错误,需要修改.bash\_profile的权限
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
#下载TEI代码
git clone https://github.com/huggingface/text-embeddings-inference.git
#进入到代码目录,安装metal(m芯片,如果是intel芯片,则metal修改为mkl)
cd text-embeddings-inference
cargo install --path router -F metal
#启动向量服务(在linux可能需要安装gcc/openssl:#sudo apt-get install libssl-dev gcc -y)
\# 拉取模型,并启动模型服务
model=BAAI/bge-large-zh-v1.5
text-embeddings-inference % text-embeddings-router --model-id $model --port 8080
由于TEI使用了FastAPI规范暴露API接口,因此可以在浏览器中访问:http://localhost:8080/docs/查看当前TEI暴露的接口文档,甚至可以直接测试Rerank接口:
现在可以开始设计使用该本地的Rerank服务做重排序。由于LlamaIndex目前并没有直接内置集成使用该模型的组件,因此无法像Cohere Reranker那样快速集成。这里我们创建一个自定义的检索后处理器,来实现基于TEI与bge-reranker-large模型的Rerank方法,完整代码如下:
import requests
from typing import List, Optional
from llama_index.core.bridge.pydantic import Field, PrivateAttr
from llama_index.core.postprocessor.types import BaseNodePostprocessor
from llama_index.core.schema import NodeWithScore, QueryBundle
class BgeRerank(BaseNodePostprocessor):
url: str = Field(description="Rerank server url.")
top_n: int = Field(description="Top N nodes to return.")
def __init__(self,top_n: int,url: str):
super().__init__(url=url, top_n=top_n)
#调用TEI的rerank模型服务,实现rerank方法
def rerank(self, query, texts):
url = f"{self.url}/rerank"
request_body = {"query": query, "texts": texts, "truncate": False}
response = requests.post(url, json=request_body)
if response.status_code != 200:
raise RuntimeError(f"Failed to rerank, detail: {response}")
return response.json()
@classmethod
def class_name(cls) -> str:
return "BgeRerank"
#实现LlamaIndex要求的postprocessor的接口
def _postprocess_nodes(
self,
nodes: List[NodeWithScore],
query_bundle: Optional[QueryBundle] = None,
) -> List[NodeWithScore]:
if query_bundle is None:
raise ValueError("Missing query bundle in extra info.")
if len(nodes) == 0:
return []
#调用rerank
texts = [node.text for node in nodes]
results = self.rerank(
query=query_bundle.query_str,
texts=texts,
)
#组装返回nodes
new_nodes = []
for result in results[0 : self.top_n]:
new_node_with_score = NodeWithScore(
node=nodes[int(result["index"])].node,
score=result["score"],
)
new_nodes.append(new_node_with_score)
return new_nodes
构建好这个自定义的检索后处理器后,就可以像之前使用Cohere Rerank一样使用它,我们只需要把上一节的例子稍作修改即可:
......
#创建自定义的检索后处理器
customRerank = BgeRerank(url="http://localhost:8080",top_n=2)
#测试处理节点
rerank_nodes = customRerank.postprocess_nodes(nodes,query_str='百度文心一言的逻辑推理能力怎么样?')
......
在上面相同用例的情况下,最后输出重新排序的节点信息如下,可以看到,这里的排序结果和上一节使用的Cohere Rerank模型很类似:
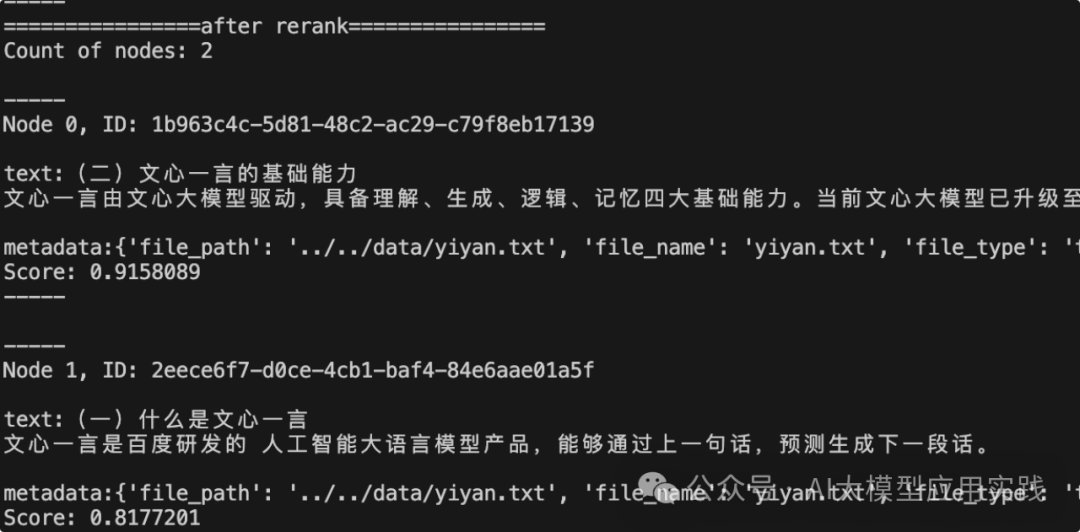
现在你就拥有了一个本地部署的强大的Rerank模型服务!
结束语
上面简单介绍了两种很出色的Rerank模型的使用,其中Cohere Rerank是一种商业在线的模型方案;而另外一种更具实用价值、且开源可部署在本地的是bge-reranker-large模型,由于其对资源要求较低,借助TEI工具你可以在本机或企业内部环境轻松部署,用来对自有RAG应用提供服务。
尽管Rerank在RAG管道中所处的环节似乎没有检索(Retrieval)或者生成(Generation)那么重要和必须,但由于其实现简单、资源要求较低、且不依赖于嵌入模型,但是却能够很好的改善最终生成的质量,用较小的代价让你的RAG应用百尺竿头,更进一步;此外Rerank也是一些高级检索的必要步骤,比如之前介绍的融合检索。因此有兴趣的朋友不妨一试,或许能带来意想不到的惊喜!
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 24
24 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)