存内计算原理分类——数字存内计算与模拟存内计算
该成果已发表在《Science》上。2022年,国内的知存科技率先量产商用WTM2101芯片,结合了RISC-V指令集与NOR Flash存内计算阵列,使用特殊的电路设计抑制阈值电压漂移对计算精度的影响,可实现低功耗计算与低功耗控制,其阵列结构与芯片架构如图4所示,包括1.8 MB NOR Flash存内计算阵列,一个RISC-V核,一个数字计算加速器组,320 kB RAM以及多种外设接口[5]
存算一体作为一种新型架构,将数据存储和计算融合一体化,有望突破算力与功耗瓶颈。存内计算可分为模拟和数字两大类别。接下来我们将重点介绍数字存内计算与模拟存内计算及其优劣。
一.数字存内计算
数字存内计算利用全数字电路执行计算,指将数字逻辑集成到存内计算中,能够将逐位数字乘积累加运算直接集成到存储器阵列。由于数字存内计算结构上对乘积累加计算有良好的支持,在神经网络需求的运算场景中应用潜力巨大,如智能手表、蓝牙耳机中的语音处理,智能手机中的神经网络运算加速,模型训练加速卡等。
数字存内计算的主要优势就是存储器中权重可更换、高带宽以及高鲁棒性,但面积和功耗开销都比较大,适用于高精度、对功耗等要求不高的应用场景。

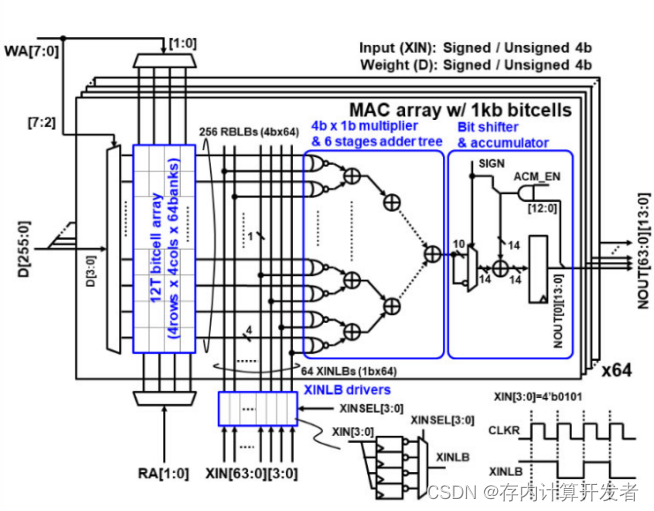
图 1 数字存内计算核结构[1]
以ISSCC 2022中的文献[1]中展示的数字存内计算总体结构为例,解释数字存内计算的运算方式,其结构如图1所示。
该运算核结构由64个如图中顶层所示的MAC array构成。在每一个MAC array中,存储器存储权重数据(图1中左侧12T bitcell array部分),乘法器计算输入数据与权重数据的元素乘积结果,加法器树计算元素乘积结果的和(图中4b×1b multiplier & 6 stages adder tree部分),移位累加器将加法器树计算得到的结果移位累加(图中Bit shifter & accumulator部分)。
运算核计算64×1的4bit输入向量XIN[63:0][3:0]与64×64的4bit权重矩阵的内积结果,其结果为一列64×1的14bit向量NOUT[63:0][13:0]。计算过程为:权重矩阵的权重信息被拆分为64个64×1的4bit权重向量存储在每一层MAC array的存储器中,写入过程受到WA[7:0]信号控制,每次写入向量中一个元素的4bit信息D[4:0],一共64个MAC array,一次需要写入D[255:0]。输入向量受XINSEL[3:0]控制按比特由高到低依次输入,每个时钟周期计算一个输入比特64 XINLBs与权重向量256 RBLBs的元素乘积,并求和,将四个周期的结果移位累加便得到该MAC array的权重向量与输入向量的内积,将每层MAC array的结果组成为一个向量,即为NOUT[63:0][13:0]。
据悉已有基于数字存内计算的产品产出。后摩于2023年5月推出鸿途™H30,该芯片基于SRAM存储介质,据其官网信息,该产品拥有极低的访存功耗和超高的计算密度,在Int8数据精度条件下,其AI核心IPU能效比高达15Tops/W,是传统架构芯片的7倍以上,暂未落地到市场化应用实测性能。
二.模拟存内计算[2]
不同于前述的数字存内计算,模拟存内计算主要基于物理定律(欧姆定律和基尔霍夫定律),在存算阵列上实现乘积累加运算。对于模拟存内计算,其存内计算电路的计算模式通过定制模拟计算电路模块来实现,通过这些模拟计算电路与存储单元的结合来实现高能效存内计算,一般使用RRAM(阻变随机存储器,又名忆阻器)和Flash(闪存)。
模拟存内计算面积、功耗等开销小,能量效率高,但是缺乏准确性,适用于需要低功耗、对精度要求不高的应用场景。
下面以RRAM为例,来描述模拟存内计算的原理。
忆阻器电路可以做成阵列结构,如下图2所示,与矩阵类似,利用其矩阵运算能力,可以广泛应用于人工智能推理场景中。在推理过程中,通过输入矢量与模型的参数(也即权重)矩阵完成乘加运算,便可以得到推理结果。

图 2 3×3交叉阵列的模拟型忆阻器[3]

图 3 交叉阵列进行矩阵乘加运算示意图[4]
关于矩阵乘加运算,如上图3所示,将模型的输入数据设为矩阵[V],模型的参数设为矩阵[G],运算后的输出数据设为矩阵[I]。运算前,先将模型参数矩阵按行列位置存入忆阻器(即[G]),在输入端给定电压值来表示输入矢量(即[V]),根据欧姆定律,便可在输出端得到对应的电流矢量,再根据基尔霍夫定律将电流相加,即得到输出结果(即[I])。此外,多个存算阵列并行,便可完成多个矩阵乘加计算。
目前模拟存内计算研究已经有了很多成果。例如,2023年10月,清华钱鹤、吴华强带领团队创新设计出适用于RRAM存算一体的高效片上学习的新型通用算法和架构(STELLAR),研制出全球首颗全系统集成的、支持高效片上学习的RRAM存算一体芯片,该成果已发表在《Science》上。此外,基于Flash的模拟存内计算也是研究重点。2022年,国内的知存科技率先量产商用WTM2101芯片,结合了RISC-V指令集与NOR Flash存内计算阵列,使用特殊的电路设计抑制阈值电压漂移对计算精度的影响,可实现低功耗计算与低功耗控制,其阵列结构与芯片架构如图4所示,包括1.8 MB NOR Flash存内计算阵列,一个RISC-V核,一个数字计算加速器组,320 kB RAM以及多种外设接口[5]。WTM2101芯片适配低功耗AIoT应用,可使用微瓦到毫瓦级功耗完成大规模深度学习运算,可应用于智能语音、智能健康等市场领域,目前已完成批量生产和市场应用。此外,知存科技也推出了WTM-8系列产品芯片,这是针对视频增强处理的一款高性能低功耗的存算一体AI处理芯片,采用第二代3D存内计算架构,为全球首粒端侧大算力存算一体芯片,即将量产,具备高算力、低功耗、高能效、低成本的核心优势,应用于1080P-4K视频的实时处理和空间计算[6]。WTM2101和WTM-8的主要产品性能如下表1所示, 未公开的数据用“-”表示,请酌情采信。
表1 WTM2101与WTM-8产品性能
| WTM2101 | WTM-8 | |
| 存内计算模式 | 模拟存内计算 | 模拟存内计算 |
| 存储介质 | Flash | Flash |
| 算力 | 50Gops | >24Tops |
| 制程 | 40nm | - |
| 面积 | 2.6✖3.2mm2 | - |
| 功耗 | 5uA-3mA | - |
| 最大模型参数 | 1.8M | 64M |
| 计算精度 | 8bit | 12bit |
| 备注 | 用于智能可穿戴设备的高算力低功耗定位,主要应用于智能语音和智能健康 | 定位为移动设备计算视觉芯片,具有4核高精度存内计算,支持linux,支持AI超分、插帧、HDR、识别和检测,应用于1080P-4K视频实时处理和空间计算 |

图 4 WTM2101芯片阵列及架构[7]
三.二者优劣对比分析
数字存内计算与模拟存内计算都是存算一体发展进程中的重点发展路径,二者有着不同的优缺点与应用场景。
数字存内计算主要以SRAM作为存储器件,采用先进逻辑工艺,具有高性能高精度的优势,且具备很好的抗噪声能力和可靠性,可以避免由于工艺变化、数据转换开销和模拟电路的可缩放性差而导致的不准确,因此更适合大规模高计算精度芯片的实现。然而,数字存内计算单位面积功耗高,在功率和面积等方面都遇到了新的问题,比如一个一般的CMOS全加器单元就需要28个晶体管,面积和功耗开销都比较大。综上,数字存内计算更适用于高精度、对功耗不敏感的大算力计算场景,比如云边AI场景。
模拟存内计算通常以RRAM、Flash等非易失性介质作为存储器件,存储密度大,并行度高,面积、功耗等开销小,成本较低,能量效率高。但是模拟存内计算对环境噪声和温度非常敏感,由于晶体管变化和ADC(模数转换器)等的影响,SNR(信噪比)不足,模拟存内计算往往缺乏准确性,更适用于低功耗、功能灵活性要求不高、对精度要求不高的高能效小算力应用场景,如端侧可穿戴设备等[8]。两种存内计算模式的优劣对比如下表2所示。
表 2 两种存内计算模式对比
| 数字存内计算 | 模拟存内计算 | |
| 运算精度 | 高 | 较低 |
| 抗噪性 | 强 | 弱 |
| 通用性、灵活性 | 较强 | 较弱 |
| 能量效率 | 较高 | 高 |
| 功耗 | 较高 | 低 |
| 存储介质 | 主要为SRAM | 各种非易失性介质 |
| 面积开销 | 面积较大 | 面积较小 |
| 适应场景 | 大算力、高精度、 云计算、边缘计算 | 小算力、低成本、 端侧、长时待机 |
总而言之,数字存内计算与模拟存内计算各有优劣,都是存算一体发展进程中的重点发展路径,数字存内计算由于其高速、高精度、抗噪性强、工艺技术成熟、能效比高等特点,更适用于大算力、云计算、边缘计算等应用场景;模拟存内计算由于其非易失性、高密度、低成本、功耗低等特点,更适用于小算力、端侧、需长时待机等的应用场景。在如今可穿戴设备、智能家具、玩具机器人等应用走进千家万户的背景下,模拟存内计算的高能效、小面积、低成本等市场优势逐渐凸显,比如前面所提到的知存科技WTM2101已率先进入市场规模化应用,在商业化进程中处于领先地位,且更高算力WTM-8系列即将量产,在端侧AI市场具有极大的应用潜力。
不论是数字存内计算还是模拟存内计算,目前都面临各自的一些挑战,比如编程模型的复杂性、硬件设计的复杂性、硬件系统的可靠性等等,但随着研究人员的不断努力,这些难题将逐步得到解决,存内计算芯片的未来将大有可期。
参考文献
[1] Yan B, Hsu J L, Yu P C, et al. A 1.041-Mb/MM 2 27.38-TOPS/W signed-INT8 dynamic-logic-based ADC-less SRAM compute-in-memory macro in 28nm with reconfigurable bitwise operation for AI and embedded applications[C]//2022 IEEE International Solid-State Circuits Conference (ISSCC). IEEE, 2022, 65: 188-190.
[2][4] 存算一体白皮书(2022年),中国移动通信有限公司研究院.
[3] 针对忆阻器的工作原理和发展的研究-知乎.
[5][7] 郭昕婕,王光燿,王绍迪.存内计算芯片研究进展及应用[J].电子与信息学报,2023,45(05):1888-1898.
[6] 知存科技官网 (witintech.com).
[8] Chih Y D, Lee P H, Fujiwara H, et al. 16.4 An 89TOPS/W and 16.3 TOPS/mm 2 all-digital SRAM-based full-precision compute-in memory macro in 22nm for machine-learning edge applications[C]//2021 IEEE International Solid-State Circuits Conference (ISSCC). IEEE, 2021, 64: 252-254.

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 14
14 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)