向量检索(一)Faiss 在工业界的应用和常见问题解决
传统的搜索,使用关键做精确的查找,利用倒排索引在索引库中搜索。日常在用的百度,Google都属于关键词搜索。在 AI 时代我们需要查找一张相似的图片,一个问题的答案,或者根据一段音乐查找对应的歌曲,这些情况下没有准确的关键词用来做检索。 这些图片,问题(文本),语音,不再是简单的一个一维量化的数字,而是包含了大量的属性特征。 因而不合适使用传统的关键字搜索引擎来查找。对于文本,图片,语音,视频,D
一、向量检索的场景
传统的搜索,使用关键做精确的查找,利用倒排索引在索引库中搜索。日常在用的百度,Google都属于关键词搜索。
在 AI 时代,我们需要查找一张相似的图片,一个问题的答案,或者根据一段音乐查找对应的歌曲,这些情况下没有准确的关键词用来做检索。 这些图片,问题(文本),语音,不再是简单的一个一维量化的数字,而是包含了大量的属性特征。 因而不合适使用传统的关键字搜索引擎来查找。
对于文本,图片,语音,视频,DNA信息等等,都可以用向量来表示,数据被特征化处理后,用来表示这条数据的向量称之为 Embedding。
比如 I love China, and I love the world. 这一句话, 假设在特定的语料集中, I, love, China, and, the, world 这几个 词语的词频分别是 2000, 300, 80, 1550, 2650, 850,
那么这个句子可以表示成 [2000, 300, 80, 1550, 2000, 300, 2650, 850] 的向量。 这是一个简单的用向量来表示文本的例子, 当然实际的情况会更复杂一些。
二、向量检索的4个要素
向量检索引擎里面包含了下面的这四个要素。
-
特征提取算法
-
距离度量算法
-
检索算法
-
数据存储
特征提取算法,对于不同类别的数据,有不同的提取方法,分别提取出来 Word Embedding, image feature, audio feature 等等。
词语的 Embedding 特征提取,可以使用 Word2Vec,也可以使用 Glove, Elmo, BERT, fastText 等方法。
图片的特征提取,可以使用 CNN 卷积,人脸特征可以使用 DLIB。
语音的特征提取,可以使用 FFT 做傅里叶变换。
距离的度量算法,常用的有 L2 欧几里得距离(空间距离), IP 内积算法(相似度计算),Cosine 相似度等等。 距离越近则表示两个数据越相近。
不同距离计算值的含义: 利用L2 欧几里得距离,计算向量的相似度,欧式距离越小相似度越大(两个点的绝对距离)。 IP内积/夹角余弦越小表示两向量的夹角越大,则两个向量差异越大。当两个向量的方向重合时夹角余弦取最大值1,当两个向量的方向完全相反夹角余弦取最小值-1。 如果向量没有归一化,IP 内积的值大小是可以大于1的,且跟两个向量的长度有关。
检索的算法,可以使用暴力检索,可以使用 KNN (K Nearest Neighbor) 的聚类算法。也可以使用各种 KNN 的演进版本做更有效的检索。 KNN 通过聚类,把数据聚集到 K 个中心点,然后查找目标数据的时候,通过首先跟这 K 个中心点做距离比较,快速找到目标数据最近的中心点(可以是1个或者多个), 然后再找附近的相似点,从而减少要查找的数据量,高效地检索到相近的数据。
向量索引学术上对应的专有名词叫Approximate Nearest Neighbor Search (ANNS),即近似最近邻搜索。为什么是近似,而不是我们想要的精确?这就是精度与时间、算力资源的折中,采用了牺牲精度换取时间和空间的方式,从海量的样本中实时获取跟查询最相似的样本。
所谓近似检索,就是通过聚类、降维或者编码等方式,将原来需要在整个高维向量空间内的搜索,转换为在小范围空间或者相对低维的向量空间内搜索的算法。这类算法的特点是,检索的时间复杂度小于 O(Nd),但是真正用来搜索之前,需要用一个向量分布类似的一个训练集来训练,获得一个产生合理数据划分或者编码的模型。然后再利用这个模型,使用额外的存储空间,建立对整个高维向量的索引。
虽然是近似的搜索,但在实际的生产环境应用中,可以通过调整参数,比较容易得达到 99%以上的召回率,甚至更接近 100% 的召回率的效果。
三、向量检索库 Faiss
Faiss的全称是Facebook AI Similarity Search,是FaceBook的AI团队针对大规模相似度检索问题开发的一个工具,使用C++编写,有python接口,对10亿量级的索引可以做到毫秒级检索的性能。
以 Python 为例, 使用 pip 安装 Faiss
pip install faiss-cpu ## for cpu version
pip install faiss-gpu ## for gpu version也可以使用 conda 安装:
# 更新conda
conda update conda
# 先安装mkl
conda install mkl
# faiss提供gpu和cpu版,根据服务选择
# cpu版本
conda install faiss-cpu
# gpu版本 -- 记得根据自己安装的cuda版本安装对应的faiss版本,不然会出异常。使用命令:nvcc -V 查看
conda install faiss-gpu cudatoolkit=9.0 -c pytorch # For CUDA9
conda install faiss-gpu cudatoolkit=10.0 -c pytorch # For CUDA10
# 校验是否安装成功
python -c "import faiss"使用 faiss 的3个步骤:
-
准备向量的输入集合,即准备需要用来搜索的数据集,计算其中每一条数据的向量;
-
用 faiss 构建index,并将向量批量添加到index中;
-
用faiss index 来执行检索。

注意,IndexPQ, IndexIVFFlat, IndexIVFPQ, IndexIVFPQR 需要训练;
因此这些索引类不支持增量索引。 HNSW,Flat,LSH 是支持的。
3.1 使用 Faiss 构建索引的2种方法
可以使用具体的索引类来创建索引,也可以使用通用的 index_factory 来创建索引。
比如如下代码,分别用 具体的索引类,通用的 index_factory 来创建 FLAT_L2 的暴力检索索引(实际上没有索引,只是把数据放入到内存中)。
准备数据, 创建 128 维的随机数据,总共构建 10w 个向量, 最后使用 1w 个向量来做检索
# 准备数据
import numpy as np
d = 128 # 向量维度
nb = 100000 # index向量库的数据量
nq = 10000 # 待检索query的数目
np.random.seed(1234)
xb = np.random.random((nb, d)).astype('float32')
xb[:, 0] += np.arange(nb) / 1000. # index向量库的向量使用具体的类来创建索引
import faiss
index = faiss.IndexFlatL2(d)
print(index.is_trained) # 输出为True,代表该类index不需要训练,只需要add向量进去即可
index.add(xb) # 将向量库中的向量加入到index中
print(index.ntotal) # 输出index中包含的向量总数,为100000 使用 index_factory 来创建 FLAT_L2 的索引
dim, measure = 128, faiss.METRIC_L2
description = 'Flat'
index = faiss.index_factory(dim, description, measure)执行搜索,生成 10000 个随机的向量,查找与这些向量相似的 top k 数据
### 生成 nq = 10000 个随机向量
xq = np.random.random((nq, d)).astype('float32')
xq[:, 0] += np.arange(nq) / 1000. # 待检索的query向量
k = 4 # topK = 4, 搜索取 top 4 个最相似的结果
D, I = index.search(xq, k) # xq为待检索向量,返回的I为每个待检索query最相似TopK的索引list,D为其对应的距离
print(I[:5])
print(D[-5:])measure为计算距离的方法,支持欧几里得距离和 inner product 内积。由于内积的特性,要计算余弦相似度,只需要将向量归一化后,使用内积度量即可,效果等同于使用 cosine 距离。
3.2 Faiss 中的几种基础索引
不同索引的构建方法
1)Flat 索引(IndexFlatL2):
-
优点:该方法是Faiss所有index中最准确的,召回率最高的方法,没有之一;
-
缺点:检索速度慢,占内存大,构建索引快。(不需要训练,可以逐条添加数据)
-
使用情况:向量候选集很少,数据量在50万以内,可以考虑使用内存索引,在普通的 PC 机上检索时间在 < 10ms 的级别。
2) .IVFx Flat (IndexIVFFlat):倒排暴力检索 Inverted Flat
-
优点:检索的性能快于暴力检索,内存消耗不大
-
缺点:数据需要训练,需要批量训练和一次性批量插入(训练的数据跟插入的集合是相同的集合,不合适插入新的数据,创建的索引适合用作不变的数据集) IVF利用近似于倒排索引的思想,对训练集做聚类之后,数据被划分到 n 个聚类中心下。检索时, 计算每个聚类中心的向量跟目标向量的距离,找到 p 个最相近的聚类中心,然后再检索各个聚类中心附近的所有非中心点的距离,从而找出最近的 k 个点。IVF 通过减小搜索范围,提升了搜索效率。
对于百万的数据,通常可以采用 4096, 或者 16384 个聚类中心的 IVF_Flat 索引。具体的参数根据你的数据集做相应的 召回率, 准确率和检索性能的测试,最终选择合适的参数。
dim, measure = 128, faiss.METRIC_L2
description = 'IVF4096,Flat' # 代表k-means聚类中心为100,
index = faiss.index_factory(dim, description, measure)
print(index.is_trained) # 此时输出为False,因为倒排索引需要训练k-means,
index.train(xb) # 因此需要先训练index,再add向量
index.add(xb) IVFx 中的 x 是聚类中心的数量 nlist。上面的例子中, nlist 取的 4096。
| 索引名 Index Name | 类名 Class Name | index_factory 参数 | 主要参数列表 | 字节数/向量 | 精准检索 | 备注 |
|---|---|---|---|---|---|---|
| Exact search for L2 | IndexFlatL2 | "Flat" | d | 4*d | yes | brute-force |
| Exact search for inner product | IndexFlatIP | "Flat" | d | 4*d | yes | 归一化向量计算cos |
| Hierarchical Navigable Small World graph exploration | IndexHNSWFlat | "HNSWx,Flat" | d, M | 4*d + 8 * M | no | - |
| Inverted File | IndexIVFFlat | "IVFx,Flat" | quantizer, d, nlists, metric | 4*d | no | 需要另一个量化器来建立倒排 |
| Locality-Sensitive Hashing (binary flat index) | IndexLSH | - | d, nbits | nbits/8 | yes | optimized by using random rotation instead of random projections |
| Scalar quantizer (SQ) in flat mode | IndexScalarQuantizer | "SQ8" | d | d | yes | 每个维度项可以用4 bit表示,但是精度会受到一定影响 |
| Product quantizer (PQ) in flat mode | IndexPQ | "PQx" | d, M, nbits | M (if nbits=8) | yes | - |
| IVF and scalar quantizer | IndexIVFScalarQuantizer | "IVFx,SQ4" "IVFx,SQ8" | quantizer, d, nlists, qtype | d or d/2 | no | 有两种编码方式:每个维度项4bit或8bit |
| IVFADC (coarse quantizer+PQ on residuals) | IndexIVFPQ | "IVFx,PQy" | quantizer, d, nlists, M, nbits | M+4 or M+8 | no | 内存和数据id(int、long)相关,目前只支持 nbits <= 8 |
| IVFADC+R (same as IVFADC with re-ranking based on codes) | IndexIVFPQR | "IVFx,PQy+z" | quantizer, d, nlists, M, nbits, M_refine, nbits_refine | M+M_refine+4 or M+M_refine+8 | no | - |
表格中的参数说明:
-
d: 向量维度;
-
nlists: 用于有倒排表的索引,比如IndexIVFPQ,指的是倒排表的数量(聚类的簇数);
-
quantizer:量化方法,用于有倒排的索引,实际上它指的是倒排表中每个子空间的索引类型,可以是IndexFlat*、IndexLSH、IndexPQ或者其他全量查找索引类型;
-
nbits:向量编码维度,取值只能为8, 12 或者16,并且d是nbits的整数倍;
-
M:矢量量化时被切分的段数,d必须时M的整数倍;
-
Metric:距离度量方式,0表示内积,1表示L2。
index_factory 的 description 参数
注意 index_factory 需要的 description 是构建索引的参数, 可以由三个部分组成: 预处理、倒排、编码。 另外可以加一个 IDMap 前缀来指定索引对于 add_with_ids 的支持 。非倒排索引默认不支持 add_with_ids() ,增加 IDMap 组件后,支持添加数据的时候指定 id。
预处理参数:
PCA:PCA64表示通过PCA降维到64维(PCAMatrix实现);PCAR64表示PCA后添加一个随机旋转。
OPQ:OPQ16表示为数据集进行16字节编码进行预处理(OPQMatrix实现),对PQ索引很有效但是训练时也会慢一些。
预处理参数包含了向量的转换器如 PCA,OPQ 量化转化器,L2norm 标准化预处理等。
索引文件参数:
IVF:IVF4096表示使用粗量化器IndexFlatL2将数据分为4096份
IMI:IMI2x8表示通过Mutil-index使用2x8个bits(MultiIndexQuantizer)建立2^(2*8)份的倒排索引。
IDMap:如果不使用倒排但需要add_with_ids,可以通过IndexIDMap来添加id。
倒排索引如 IVF4096, IMI2x9,IVF65536_HNSW32,IVF65536(PQ16x4) 等;图索引如:"HNSW32, HNSW",HNSW32_SQ8, HNSW32_PQ12 等
编码参数:
Flat:存储原始向量,通过IndexFlat或IndexIVFFlat实现
PQ:PQ16使用16个字节编码向量,通过IndexPQ或IndexIVFPQ实现
PQ8+16:表示通过8字节来进行PQ,16个字节对第一级别量化的误差再做PQ,通过IndexIVFPQR实现。
对于倒排索引, description 参数里面, 索引文件格式后,需要制定编码方式。编码方式有: Flat, PQ16, PQ16x12, PQ28x4fs, Residual128, LSH 等等
如: index = index_factory(128, "OPQ16_64,IMI2x8,PQ8+16"): 处理128维的向量,使用OPQ来预处理数据,16是OPQ内部处理的blocks大小,64为OPQ后的输出维度;使用multi-index建立65536(2^16)和倒排列表;编码采用8字节PQ和16字节refine的Re-rank方案。
The index factory · facebookresearch/faiss Wiki · GitHub Pre and post processing · facebookresearch/faiss Wiki · GitHub
3).PQx :乘积量化 Product Quantization IndexScalarQuantizer
-
优点:利用乘积量化的方法,改进了普通检索,将一个向量的维度切成x段,每段分别进行检索,每段向量的检索结果取交集后得出最后的TopK。因此速度很快,而且占用内存较小。
-
缺点:召回率相较于 IVF_Flat 要低。
-
适用场景:内存受限,召回率要求不高,需要较快的检索速度的场景
-
参数:PQx中的x为将向量切分的段数,因此,x需要能被向量维度整除,且x越大,切分越细致,时间复杂度越高
faiss使用了PCA和PQ(Product quantization乘积量化)两种技术进行向量压缩和编码,PCA和PQ是其中最核心部分,参考:
4).HNSWx IndexHNSWFlat
-
优点:不需要训练,基于图检索的改进方法,检索速度极快,10亿级别秒出检索结果,而且召回率几乎可以媲美Flat,能达到惊人的97%。检索的时间复杂度为loglogn,几乎可以无视候选向量的量级了。并且支持分批导入,极其适合线上任务,毫秒级别 RT。
-
缺点:构建索引极慢,占用内存极大(是Faiss中最大的,大于原向量占用的内存大小);添加数据不支持指定数据ID,不支持从索引中删除数据。
-
参数:HNSWx中的x为构建图时每个点最多连接多少个节点,x越大,构图越复杂,查询越精确,当然构建index时间也就越慢,x取4~64中的任何一个整数。
-
使用情况:内存充裕,并且有充裕的时间来构建index
dim, measure = 128, faiss.METRIC_L2
param = 'HNSW64'
index = faiss.index_factory(dim, param, measure)
print(index.is_trained) # 此时输出为True
index.add(xb)从检索的性能上, 基于图的算法 HNSW 的检索性能,远远优于基于倒排的 IVF_Flat。 从检索的召回率上,基于图的算法 HNSW,要优于目前其他一些主流 ANN 搜索方法,比如乘积量化方法(PQ、OPQ)、哈希方法等。
HNSWx 中的 x 的范围是[4, 64],它表示了每个向量的链接数量,越大越精确,但是会使用越多的内存。速度-精确比(speed-accuracy tradeoff)可以通过 efSearch 参数来设置。 每个向量的内存使用是情况是(d * 4 + x * 2 * 4 )。
HNSW 的限制: HNSW 只支持顺序添加(不是add_with_ids),所以在这里再次使用 IDMap 作为前缀(如果需要)。 HNSW 不需要训练,也不支持从索引中删除矢量。
5).PCA 降维
coarse_quantizer = faiss.IndexFlatL2(256)
sub_index = faiss.IndexIVFPQ (coarse_quantizer, 1024, ncoarse, 16, 8)
pca_matrix = faiss.PCAMatrix (2048, 256, 0, True)
index = faiss.IndexPreTransform (pca_matrix, sub_index)
index.train(xb)
index.add(xb)6).其他索引 IVFxPQy, LSH 等
Faiss 支持的索引中, 倒排乘积量化,局部敏感哈希等索引算法,由于召回率低,通常不建议使用。
如何选择索引: https://github.com/facebookresearch/faiss/wiki/Guidelines-to-choose-an-index
3.3 索引在实际使用场景中的用法
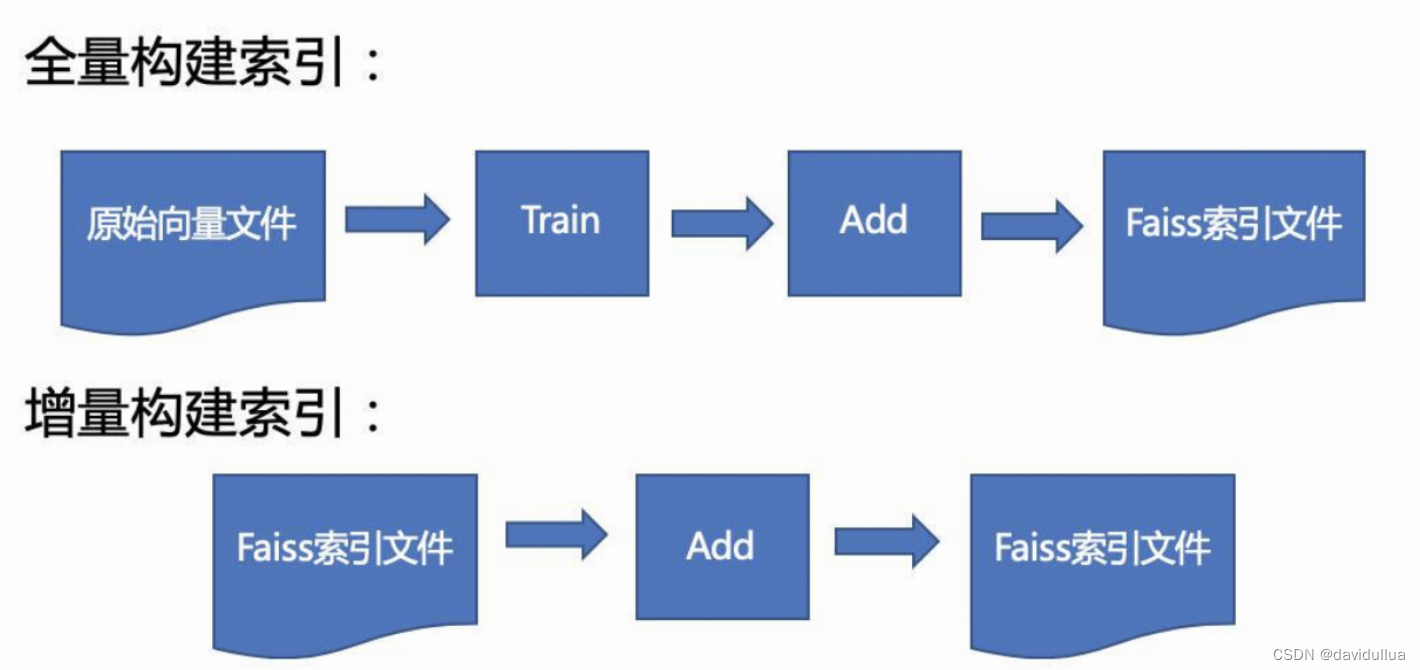
1).分批插入/动态插入: 可以分批添加数据的index为:HNSW、Flat、LSH。 IVF 的索引只能一次 train, 一次添加到索引中。
2).并行加速: 通过使用例如 Intel MKL,AVX2,AVX512,或者使用 NVIDIA GPU 的 cublas 等并行计算库加速。可以大幅提升索引,并行搜索的性能。 比如索引性能的提升可以达到 60倍以上。
3).添加数据的时候如何指定数据ID:
-
IndexIVF 天生支持 add_with_ids 方法,
-
对于不支持 add_with_ids方法的类型,可以使用IndexIDMap 辅助
-
可是使用 index.add_with_ids() 构建复合索引,或者传入 "IDMap, XXX" 到 index_factory 中
index = faiss.IndexFlatL2(xb.shape[1])
ids = np.arange(xb.shape[0])
index.add_with_ids(xb, ids) # this will crash, because IndexFlatL2 does not support add_with_ids
index2 = faiss.IndexIDMap(index)
index2.add_with_ids(xb, ids) # works, the vectors are stored in the underlying index4).使用 index_factory 创建复合索引
使用 IDMap 和 Flat 格式创建一个内存中暴力检索检索的"索引"。
ids = [2,10, 100,...]
ids = np.array(ids)
index = faiss.index_factory(768, "IDMap, Flat")
index.add_with_ids(save_embedding, ids) # 指定id,save_embedding为向量库支持先将向量PCA降维, 再构建index,description 参数设置如下:
description = 'PCA32, IVF256, Flat'代表将向量先降维成32维,再用IVF256 Flat的方法构建索引。
同理可以通过 PCA32 预处理,来优化 HNSW 内存占用过大的问题:
description = 'PCA32, HNSW32'创建支持 add_with_ids() 的 HNSW 索引
description = 'IDMap,HNSW32,Flat'
index = faiss.index_factory(256, description)5).如何保存索引到文件,从文件中加载索引
#创建内存索引
d = 1024
index = faiss.index_factory(d, "IVF1024,Flat")
#保存内存索引到文件中
faiss.write_index(index, '/data/IVF1024_Flat.index')
#从文件中加载索引
new_index = faiss.read_index('/data/IVF1024_Flat.index')6).通过 index_factory构建的索引, 或者从文件中加载的索引,如何设置 nprobe
IndexIVFFlat 可以直接设置 nprobe:
index.setNumProbes(128)
nprob = index.getNumProbes(128)从文件中加载的索引, 可以通过 ParameterSpace() 来设置参数
nprob = 128
#cpu index
faiss.ParameterSpace().set_index_parameter(index, "nprobe", nprob)
#gpu index
faiss.GpuParameterSpace().set_index_parameter(gpu_index, "nprobe", nprob)
#或者
faiss.downcast_index(index.index).nprobe = 123 对于 Java jni 调用 faiss, 可以这样设置从文件中加载的 IVF 索引的 nprobe,或者 设置 hnsw 的 efSearch 参数
// for IVF index:
ParameterSpace parameterSpace = new ParameterSpace();
parameterSpace.set_index_parameter(this.index, "nprobe", Integer.parseInt(param.get("nprobe")));
// for hnsw index:
ParameterSpace parameterSpace = new ParameterSpace();
parameterSpace.set_index_parameter(this.index, "efSearch", Integer.parseInt(param.get("efSearch")));7).多线程并行 不支持并行添加向量,不支持搜索与添加向量到索引的并行请求;仅在CPU模式下支持并行搜索;
8).内存不够用怎么办:On-disk storage
参考 faiss 项目中的faiss/contrib/ondisk.py。
9).性能与 Faiss 其他的约束
-
如果需要精确的搜索结果,不要降维、不要量化,使用 Flat,同时使用Flat 意味着数据不会被压缩,将占用同等大小的内存;
-
如果内存很紧张,可以使用 PCA 降维、PQ 量化编码,来减少内存占用,
-
只有继承了IndexIVF 的算法才支持向量的 remove() 操作,但由于是连续存储,remove的时间复杂度是 O(n),建议另外维护一个列表记录被删除的或尚存的向量;
-
faiss 针对批量搜索做了优化;
-
IndexPQ, IndexIVFFlat, IndexIVFPQ, IndexIVFPQR 需要训练;不支持重新训练,建议新建一个索引;
-
只接受 32-bit 浮点类型的输入数据;
使用 index = faiss.index_factory(dim, "PCA32,IVF256,PQ8") 这种形式创建索引更灵活, 这行代码的参数含义:使用PCA降维将原始向量降至32维,使用 IVF 建立索引,子list(即bucket 分桶)个数为 256,使用 Product Quantizer (乘积量化) 将每个向量压缩编码成 8 字节;
四、向量检索算法的性能
Benchmark: ANN-Benchmarks hnsw(nmslib) GitHub - nmslib/nmslib: Non-Metric Space Library (NMSLIB): An efficient similarity search library and a toolkit for evaluation of k-NN methods for generic non-metric spaces.
-
hnsw 的性能优于 IVF_Flat, 消耗内存更大,索引创建的时间更长
-
hnsw,NGT等基于图的算法性能,优于基于索引,基于树的结构; NGT
-
相同的算法,不同的实现性能有所差异,比如 hnsw(nmslib) 的性能优于 hnsw(faiss) 的实现
-
同样的召回率下,scann 的性能优于 hnsw 的性能
-
scann: https://github.com/google-research/google-research/tree/master/scann
五、向量检索库 Faiss 没有解决的其他问题
-
标量的检索/过滤,范围查询,比如查询某个类别/标签下的数据,查询库存数 > 0 的商品
-
索引的动态更新方式,增量更新,全量重建
-
索引构建的超参数查找与优化,以在检索精度、检索性能之间达到最佳平衡
-
系统容灾、分布式检索、负载均衡、水平扩展
faiss-6: index pre-processing and post-processing
What is the relation between k-means clustering and PCA? - Cross Validated
Choose the k-NN algorithm for your billion-scale use case with OpenSearch | AWS Big Data Blog 十亿数据向量索引的内存消耗
What is vector search and why might you need it? - /aidanf/
HNSW算法开源库对比 - 知乎 hsnw, nmslib, hnswlib 的性能对比
Faiss入门及应用经验记录 - 知乎 不同索引的选择
特征向量的距离度量 - 知乎 不同距离的计算
向量数据库入坑指南:聊聊来自元宇宙大厂 Meta 的相似度检索技术 Faiss - 知乎 训练文本数据
笔记︱几款多模态向量检索引擎:Faiss 、milvus、Proxima、vearch、Jina等 - 知乎 向量检索的场景和案例
faiss技术积累_杨树_的博客-CSDN博客_faiss index_factory
向量检索算法综述_jevenabc的博客-CSDN博客_向量搜索 不同算法的性能对比
faiss 相似特征向量搜索_Horson Liu的博客-CSDN博客 索引类型选择
faiss入门+使用的索引原理_波波虾遁地兽的博客-CSDN博客_faiss索引原理
Faiss入门及应用经验记录_在知识的海洋中遨游的博客-CSDN博客
Faiss(4):索引(Index)_翔底的博客-CSDN博客_faiss index search 图像检索:再叙ANN Search
推荐算法:HNSW算法简介_Espresso Macchiato的博客-CSDN博客 HNSW 算法简介
https://zh.wikipedia.org/wiki/欧几里得距离
https://zh.wikipedia.org/wiki/余弦相似性

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)