快速了解机器学习中的交叉验证(简单易懂)
在机器学习中,我们通常将数据集分成训练集和测试集。我们使用训练集来训练模型,并在测试集上进行评估。然而,这种方法存在一个问题:我们可能会偶然地选择一个特别适合测试集的模型,但在实际应用中却表现不佳。这种现象被称为“过拟合”。交叉验证通过重复使用数据集来解决这个问题。它将数据集分成 k 个折叠,每个折叠都会被用作一次测试集。然后我们使用剩下的 k-1 个折叠作为训练集来训练模型,并在每个折叠上进行评
目录
引言:
机器学习领域中最常见的问题之一是如何评估和选择适合的模型。在现实世界中,我们无法预先知道模型在未见过的数据上的性能表现。为了解决这一问题,机器学习中引入了一项有趣的技术——交叉验证(cross-validation)。这种评估方法不仅可以帮助我们评估模型的表现,并且还能让模型“学而不倦”,从而为我们提供更满意的结果。让我们来探索一下这项技术吧!
1.什么是交叉验证?
交叉验证是一种统计学上将数据样本切割成较小子集的实用方法,其基本思想是把在某种意义下将原始数据进行分组,一部分做为训练集,另一部分做为验证集。它的目的是为了得到可靠稳定的模型,即通过将数据集划分成训练集和验证集,利用训练集训练模型,然后利用验证集对模型进行评估,进而选择最优的超参数,并计算预测误差。
作用:
解决模型泛化能力不足、过拟合或欠拟合的问题。当模型只进行单次的训练数据拟合时,可能会出现模型过拟合的情况,即模型对训练数据的拟合程度过高,导致对新的数据预测不准确。交叉验证通过将数据划分成训练集和验证集,避免了模型只对一部分数据集过度拟合的问题,从而更好地评估模型在新数据上的表现。
选择最优的超参数。在机器学习中,超参数的设置往往会对模型的精度和泛化能力产生较大的影响,因此需要根据模型的训练效果和测试效果来调整超参数。通过交叉验证,我们可以得到多组模型在不同参数设置下的评估结果,从而比较不同参数下模型的表现,进而选择最优的超参数。
交叉验证还可以帮助我们评估模型的稳定性。通过在不同的数据子集上训练模型并验证其性能,我们可以了解模型是否在不同的数据子集上保持一致的表现,进而评估模型的稳定性。
例子:
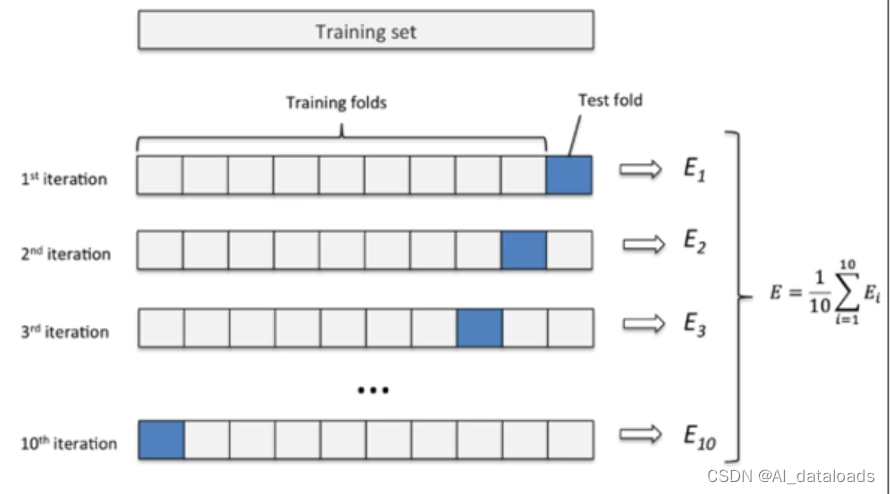
在机器学习中,交叉验证是一种非常常用的方法,它可以有效地评估模型的泛化能力和稳定性,以及优化模型的超参数。它将数据集分成 k 个折叠,每个折叠都会被用作一次测试集。然后我们使用剩下的 k-1 个折叠作为训练集来训练模型,并在每个折叠上进行评估结果为Ei。最终,我们将所有 k 次评估的结果平均,得到最终的模型性能评估。常见的交叉验证方法有K折交叉验证、留一法交叉验证、随机划分交叉验证等。在本文中,我们将主要关注K折交叉验证。

2.交叉验证实例
例如,如果我们有一个由 100 个样本组成的数据集,我们可以将其分成 5 个折叠,每个折叠包含 20 个样本。然后我们使用其中的 4 个折叠作为训练集,剩下的 1 个折叠作为测试集。我们重复这个过程 5 次,每次使用不同的折叠作为测试集。最终,我们将所有 5 次评估的结果平均,得到最终的模型性能评估。(红色为训练数据,蓝色为测试数据)
| 20 | 20 | 20 | 20 | 20 |
| 20 | 20 | 20 | 20 | 20 |
| 20 | 20 | 20 | 20 | 20 |
| 20 | 20 | 20 | 20 | 20 |
| 20 | 20 | 20 | 20 | 20 |
假设每次的验证结果为,那么最终的结果为:
这里的例子对应的K值为5,即5折交叉验证.
3.python实现5折交叉验证:
下面让我们们用python代码实现一下这一过程。下面我们来使用scikit-learn库中的cross_val_score来实现交叉验证,我们无需自己将数据分割,只需传入数据。scikit-learn提供了一些方便的函数和类来进行交叉验证,包括K折交叉验证。(更详细的实现过程可以参考我的博客:交叉验证)
代码中每个 C 值下实例化逻辑回归模型(LogisticRegression),并使用 cross_val_score 函数进行交叉验证。我们使用 scoring='recall' 来评估召回率。最后,我们打印出每个 C 值下交叉验证后的召回率。iris = load_iris() 是常用的代码片段,用于从scikit-learn库加载鸢尾花数据集(Iris dataset)。鸢尾花数据集是机器学习中常用的数据集之一,它包含了三种不同种类的鸢尾花(山鸢尾、变色鸢尾和维吉尼亚鸢尾)的四个特征(花萼长度、花萼宽度、花瓣长度和花瓣宽度)的测量数据。

from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
# 加载示例数据集
iris = load_iris()
#data:一个NumPy数组,存储鸢尾花的特征数据(测量值)。
X = iris.data
# target:一个NumPy数组,存储鸢尾花的目标变量(种类)。
y = iris.target
# 定义不同的 C 值
c_test = [0.01, 0.1, 1, 10, 100]
# 用于存储交叉验证后的召回率
scores = []
# 执行交叉验证
for c in c_test:
lr = LogisticRegression(C=c, solver='lbfgs', max_iter=1000)
# 使用 5 折交叉验证评估召回率 (scoring='recall')
cv_scores = cross_val_score(lr, X, y, cv=5, scoring='recall')
scores.append(cv_scores.mean())
# 打印不同 C 值下的召回率
for c, score in zip(c_test, scores):
print(f'C: {c}, Mean Recall: {score}')
4.K折交叉验证对模型的优势
- 提供更稳健的性能评估:K折交叉验证能够避免单次训练集和验证集划分所带来的偶然性。通过多次迭代和平均化,我们可以获得更准确和稳定的性能评估结果。
- 最大限度地利用数据:K折交叉验证充分利用了原始数据集中的所有样本。每个样本都被用于验证模型的性能,并且每个样本也都参与了训练模型的过程。
- 评估模型的泛化能力:K折交叉验证能够很好地估计模型在未知数据上的表现,从而更好地反映模型的泛化能力。这使得我们能够更好地选择适合的模型。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 6
6 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)