赛博炼丹师手记
本文提供了详细的炼丹(训练AI模型)指南,主要针对的是使用Lora模型进行个性化定制。文章首先介绍了丹炉(训练工具)的选择和下载方式,然后详细阐述了炼丹手法,包括前置准备、数据标注、开始炼丹和结果验收等步骤。在炼丹心法部分,作者深入讲解了炼丹过程中的一些重要参数,如步数、效率和质量相关参数,这些参数的设置会直接影响到模型的训练效果。最后,作者还提供了一些相关的参考文献,以供读者进一步学习和探索。
0. 丹炉安置
个人推荐b站up主朱尼酱出品的道玄丹炉,新手易懂,老手易用。
丹炉下载地址如下:
1. 炼丹手法
1.1 前置准备
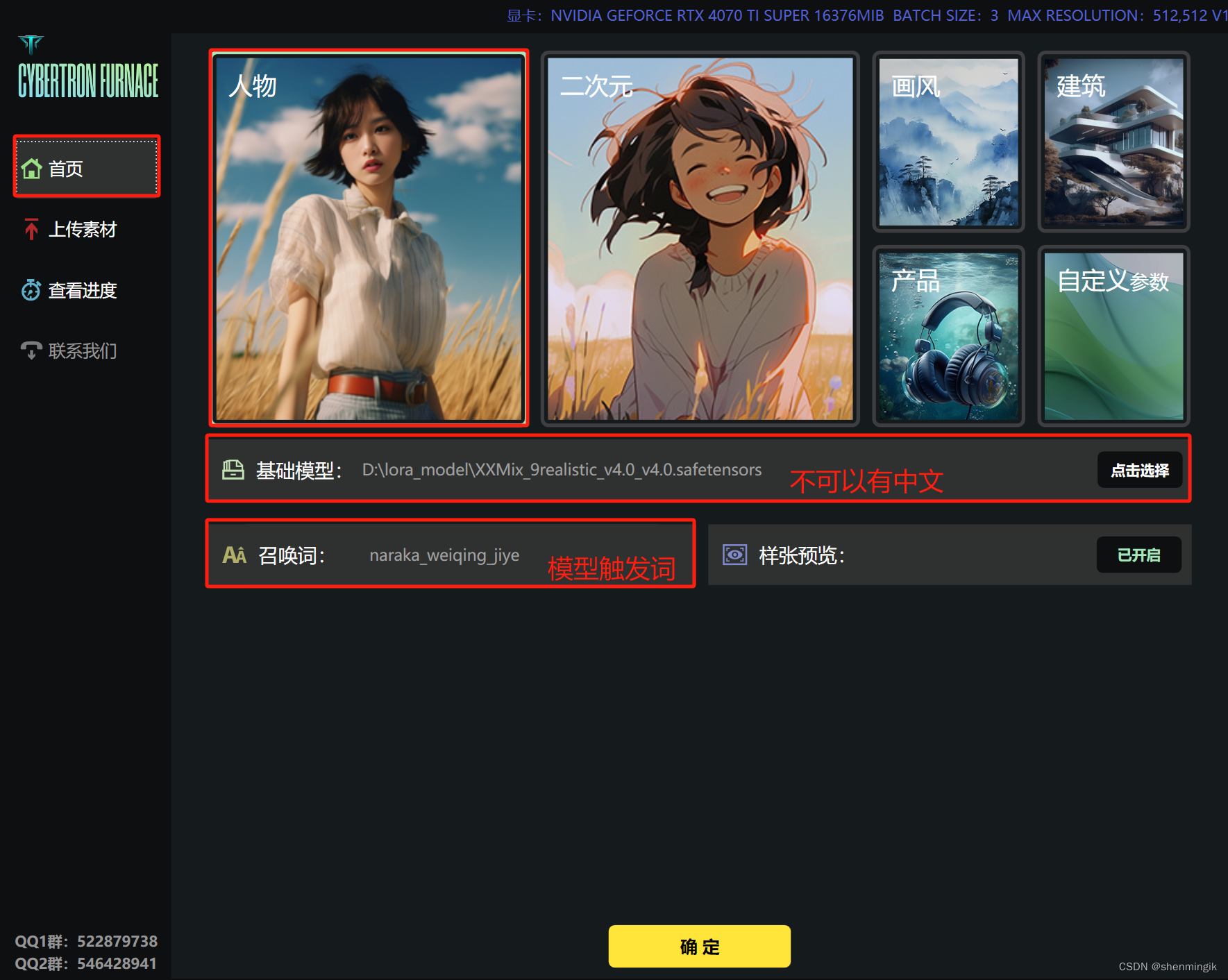
- 首先我们需要准备好我们的底模和触发关键词,同时选择丹炉的风格(一些预制好的参数)。

- 收集20~30张的素材,对其裁剪为固定尺寸大小,然后上传到丹炉之中
注:裁剪可以使用如下网站进行批量裁剪:birme

1.2 数据标注
勾选【脸部加强训练】,点击预处理,即可进行AI自动标注:
注:勾选了之后就会再多裁剪出来一组只有脸的照片,这样AI能学到更多的脸部细节

点击【TAG编辑】,这里面就是形容照片的一些标签,右边是所有照片的标签,单独点击某一张照片就可以看到这张照片的标签。
注1:如果你想保留人物的某个特征,那就要把对应的标签删掉,这样AI就会默认这个人就是有这个特征
注2:如果你想灵活调整某个特征,那就要把这个特征打上标签

1.3 开始炼丹
点击【开始训练】即可开始炼丹。其中Steps”就是训练步数,每训练50步右下角就会出现一张图片,那样就可以实时看到Lora的泛化能力。
注:Loss可以用来参考模型的好坏,一个好的模型Loss值在0.07~0.09之间具体好不好还是要在Stable Diffusion实际测试才知道

1.4 结果验收
等训练完了之后,点击【模型】,就可以看到生成出来模型按照默认参数训练会出来N个模型,但不是说最后一个模型就是最好的。有可能炼到第六第七个模型就已经够了,再往后的模型就已经训练过度了。所以这些模型还要实际在SD测试一下,才知道哪个是最好的

选了Lora之后,我们就会在关键词的文本框里看到这串Lora的编号

然后把“000006”那段数值改成“NUM”,把最后的数字“1”改成“STRENGTH”,也就是权重的意思。

然后滑到最下面找到【脚本】,在脚本里面选择 【X/Y/Z图表】,X轴、Y轴类型都选择 【提示词搜索/替换】:
- X轴的值输入:NUM,000001,000002,000003,000004,000005,000006,000007,000008,000009,000010
注:这里的序号对应的就是我们10个Lora的编号
- Y轴值输入:STRENGTH,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1
注:这里的序号代表的是Lora的权重

最后点击【生成】,可以得到如下的图表,大家根据自己的需要选择合适的模型。

2. 炼丹心法
注:此章节主要会介绍有关lora 模型训练的超参数
炼制模型的本质是在如下的图像中,找到全局最低点(函数最优解):

2.1 步数相关
丹炉的步数设置主要给我们暴露的时候如下的两个参数:
- Repeat:学习步数,其指的是对于一张图片模型要学习多少次。
注:理论上学习次数越多,模型越能习得图片特征。但是这个数值并不是越大越好,当到达某个临界点之后,模型对图片认知就会得到固化,失去了创造能力。这就是模型训练之中的过拟合现象。
| 经验参数 | Repeat |
|---|---|
| 人物 | 80~120 |
| 风景 | 20~30 |
| 二次元 | 20~50 |
- Epoch:模型训练循环次数。在每个epoch之中,都需要对一张图片进行Repeat次学习。
注:假如当前的 r e p e a t = 150 , e p o c h = 15 , i m a g e s i z e = 10 repeat = 150, epoch = 15, image_{size} = 10 repeat=150,epoch=15,imagesize=10,则本次模型的总训练步数为 r e p e a t ∗ b a t c h ∗ i m a g e s i z e = 22500 repeat*batch*image_{size}=22500 repeat∗batch∗imagesize=22500

2.1 效率相关
- BatchSize:模型一次参数更新中使用的样本数量。
注1:训练数据会被划分为多个小批次进行处理,每次处理的样本(图片)数量就是BatchSize。
注2:此参数会直接影响模型的内存占用和训练速度。假设每一步训练的时间是1s,总步数为22500,BatchSize为5,那么总得训练时间为: ( 22500 / 5 ) ∗ 1 = 4500 s (22500/5)*1 = 4500s (22500/5)∗1=4500s
注3:此时的模型训练Loss Function为BatchSize个样本结果的平均值,这以为着当BatchSize过大的时候,模型在每次更新时的梯度更新将更为平均,失去一定的拟合泛化能力。当前样本数量仅为20时,建议这个值不要超过4
- Optimizer:优化器,其用于更新和调整模型参数以最小化训练误差的算法。优化器能够使用损失函数的梯度来指导模型参数的更新,从而帮助模型更好地学习和适应数据。
| 优化器 | 推荐 | 备注 |
|---|---|---|
| AdamW8bit | 1e-4 | - |
| DAdaptation | 1 | 常用作测试最优学习率 |
| Lion | - | DA最优结果的1/3 |
- Save Every N Epochs:每N轮保存一个模型。
注:假设其值为1, E p o c h = 15 Epoch = 15 Epoch=15 ,则每个Epoch结束之后都会保存一个模型,总共会保存15个模型
- Lr Scheduler:学习率调度器,用于动态调整学习率,避免模型训练中得到局部最优解。
| 调度器 | 解释 |
|---|---|
| constant | 恒定学习率,此时学习率为静态学习率 |
| constant with warmup | 带预热恒定学习率,前期会有一个预热抬升,帮助AI在不熟悉训练集的时候慢慢接触,防止掉入局部最优的陷阱 |
| cosine | 余弦退火,一开始给出较高学习率,后期使得学习率更加平稳的降低,帮助跳出局部最优 |
| cosine with restarts | 余弦退火重启,每隔几步会重启 |


2.2 质量相关
- Unet Lr:特征提取学习率,其表示学习样本的速度。
注1:学习率高(对应下图中下面那一行,会导致模型得不到最优解)可以更快的完成对样本的学习,但是会导致囫囵吞枣,失去图片的一些细节。学习率过低会导致每一步都学习的特别慢,学习不完整个样本,导致欠拟合。
注2:一般设置为1e-4 到1e-3之间

- Text Lr:文本学习率,其主要用于将我们对图片打标的tag转换为AI能够理解的模型或者算法。
注:其通常为Unet Lr的1/10,不超过1e-4
- Network Dim:神经网络维度,其值越高,网络越密集,可以表现的特征越多,也越容易过拟合。
| Network Dim | 模型大小 | 场景 |
|---|---|---|
| 128 | 144MB | 实物,风景,人物 |
| 64 | 72MB | 人物 |
| 32 | 40MB | 二次元 |
- Network Alpha:生成器和判别器的特征图的数量和分辨率。
注:值越高会学习到更多的特征,但是也会导致过拟合。

3. 相关文献
[1] 保姆级Lora炼丹教程,一站式整合包,让你实现真人模特定制
[2] [全网最细lora模型训练教程]这时长?你没看错。还教不会的话,我只能说,师弟/妹,仙缘已了,你下山去吧!
[3] 深度学习中的优化器原理(SGD,SGD+Momentum,Adagrad,RMSProp,Adam)
[4]【现代炼丹基础】手动档优化器迭代传奇 持续为您播出
[5] 【AI绘画教程】天书LORA训练进阶——(高级设置讲解|梯度累加|带示例对比)

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 21
21 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)