搭建hadoop集群
搭建hadoop集群
文章目录
搭建Hadoop集群
1,准备环节
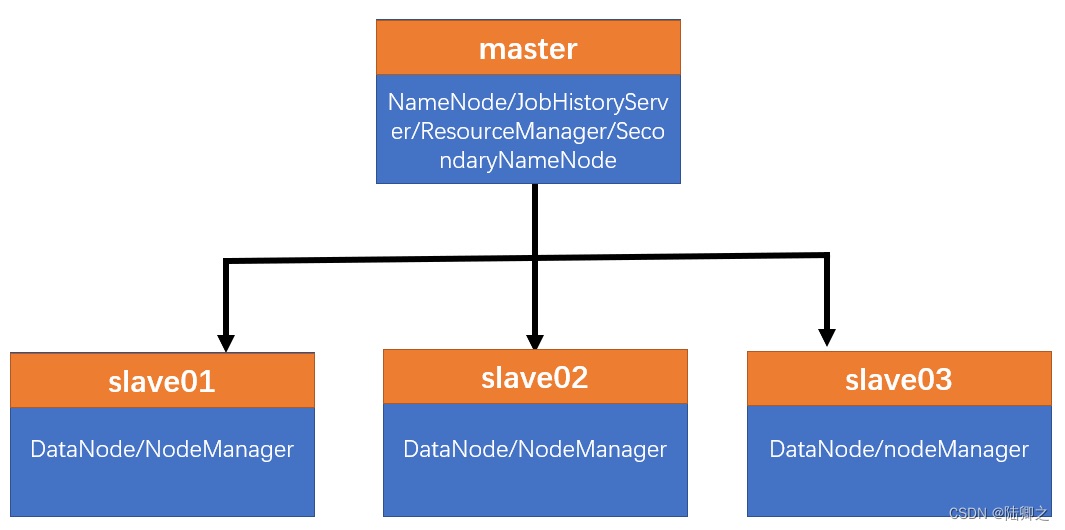
Hadoop完全分布式集群式(master/slave)主从架构。

因为Hadoop是由java编写的,所以需要Java的环境支持,作为开发者我们需要安装jdk。
安装jdk的教程:http://t.csdnimg.cn/zK3oR
下载Hadoop的安装包
Hadoop官网:http://hadoop.apache.org/
Hadoop版本下载地址:http://archive.apache.org/dist/hadoop/core/hadoop-3.3.1/hadoop-3.3.1.tar.gz
注意:安装jdk之后再克隆



1.1,设置节点
- 主节点:192.168.184.136
# 设置虚拟机名称
[root@192.168.184.136 ~]# hostnamectl set-hostname master
# 重启虚拟机
[root@192.168.184.136 ~]# reboot
[root@master ~]#
# 设置集群网络
[root@master ~]# vi /etc/hosts
# 主节点ip 虚拟机名称 域名
192.168.184.136 master hadoop.master.com
# 从节点1ip 虚拟机名称 域名
192.168.184.137 slave01 hadoop.slave01.com
# 从节点2ip 虚拟机名称 域名
192.168.184.138 slave02 hadoop.slave02.com
# 从节点3ip 虚拟机名称 域名
192.168.184.139 slave03 hadoop.slave03.com
- 从节点192.168.184.137
# 设置虚拟机名称
[root@192.168.184.137 ~]# hostnamectl set-hostname slave01
# 重启虚拟机
[root@192.168.184.137 ~]# reboot
[root@slave01 ~]#
# 设置集群网络
[root@slave01 ~]# vi /etc/hosts
# 主节点ip 虚拟机名称 域名
192.168.184.136 master hadoop.master.com
# 从节点1ip 虚拟机名称 域名
192.168.184.137 slave01 hadoop.slave01.com
# 从节点2ip 虚拟机名称 域名
192.168.184.138 slave02 hadoop.slave02.com
# 从节点3ip 虚拟机名称 域名
192.168.184.139 slave03 hadoop.slave03.com
- 从节点192.168.184.138
# 设置虚拟机名称
[root@192.168.184.138 ~]# hostnamectl set-hostname slave02
# 重启虚拟机
[root@192.168.184.138 ~]# reboot
[root@slave02 ~]#
# 设置集群网络
[root@slave02 ~]# vi /etc/hosts
# 主节点ip 虚拟机名称 域名
192.168.184.136 master hadoop.master.com
# 从节点1ip 虚拟机名称 域名
192.168.184.137 slave01 hadoop.slave01.com
# 从节点2ip 虚拟机名称 域名
192.168.184.138 slave02 hadoop.slave02.com
# 从节点3ip 虚拟机名称 域名
192.168.184.139 slave03 hadoop.slave03.com
- 从节点192.168.184.139
# 设置虚拟机名称
[root@192.168.184.139 ~]# hostnamectl set-hostname slave03
# 重启虚拟机
[root@192.168.184.139 ~]# reboot
[root@slave03 ~]#
# 设置集群网络
[root@slave03 ~]# vi /etc/hosts
# 主节点ip 虚拟机名称 域名
192.168.184.136 master hadoop.master.com
# 从节点1ip 虚拟机名称 域名
192.168.184.137 slave01 hadoop.slave01.com
# 从节点2ip 虚拟机名称 域名
192.168.184.138 slave02 hadoop.slave02.com
# 从节点3ip 虚拟机名称 域名
192.168.184.139 slave03 hadoop.slave03.com
1.2,关闭防火墙
四台虚拟机的防火墙都需要关闭
systemctl stop firewalld
1.3,设置集群ssh免密登录
# 生成一个RSA密钥对包含一个私钥和公钥,密钥用于SSH连接的身份验证和加密通信
[root@master ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:83y1SQv5wiYdQFuHuTvnWeSRGfhZJYLjs+za+mdkt+4 root@master
The key's randomart image is:
+---[RSA 2048]----+
| ..oo+ o|
| .ooo+ o.|
| .o. .. *|
| o... *.|
| S. o+.oo.|
| +oo=*o+o|
| .+o*==+ |
| ..+o.+ |
| o+oo oE |
+----[SHA256]-----+
1.4,将公钥复制到其他机器中
# 将密钥分发给主节点
[root@master ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub master
# 将密钥分发给从节点1
[root@master ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub slave01
# 将密钥分发给从节点2
[root@master ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub slave02
# 将密钥分发给从节点3
[root@master ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub slave03
验证ssh是否能够免密登录,
# 使用ssh工具登陆从节点1,并无需密码校验
[root@master ~]# ssh slave01
Last login: Tue May 23 16:01:11 2023 from master
# 登出
[root@slave01 ~]# exit
登出
Connection to slave01 closed.
# 使用ssh工具登陆从节点2,并无需密码校验
[root@master ~]# ssh slave02
Last login: Tue May 23 15:57:48 2023 from slave01
# 登出
[root@slave02 ~]# exit
登出
Connection to slave02 closed.
# 使用ssh工具登陆从节点3,并无需密码校验
[root@master ~]# ssh slave03
Last login: Tue May 23 15:58:01 2023 from slave01
# 登出
[root@slave03 ~]# exit
登出
Connection to slave03 closed
2,安装环节
主要在 master节点中安装即可,安装完毕可以通过scp命令直接拷贝文件分发到不同的节点中。赋予用户/data/hadoop目录的读写权限:
2.1,进入文件夹
[root@master ~]# cd /usr/local
2.2,存放安装包
安装包:hadoop-3.3.1.tar.gz放置在/usr/local文件夹中
[root@master local]# ls
hadoop-3.3.1.tar.gz jdk1.8.0_291 jdk-8u291-linux-x64.tar.gz
2.3,解压
[root@ master hadoop]# tar -zxvf hadoop-3.3.1.tar.gz
2.3,更改环境变量
[root@ master ~]# vi /etc/profile
# 将 HADOOP_HOME 环境变量设置为 /usr/local/hadoop-3.3.1,指定了 Hadoop 的安装目录
export HADOOP_HOME=/usr/local/hadoop-3.3.1
# 将 Hadoop 的可执行文件目录($HADOOP_HOME/bin 和 $HADOOP_HOME/sbin)添加到系统的 PATH 环境变量中,这样系统就可以直接识别和执行 Hadoop 命令。
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 指定 HDFS 的 NameNode 组件运行时使用的用户为 root
export HDFS_NAMENODE_USER=root
# 指定 HDFS 的 DataNode 组件运行时使用的用户为 root
export HDFS_DATANODE_USER=root
# 指定 HDFS 的 SecondaryNameNode 组件运行时使用的用户为 root
export HDFS_SECONDARYNAMENODE_USER=root
# 指定 YARN 的 ResourceManager 组件运行时使用的用户为 root
export YARN_RESOURCEMANAGER_USER=root
# 指定 YARN 的 NodeManager 组件运行时使用的用户为 root
export YARN_NODEMANAGER_USER=root

2.4,更新环境变量
[root@ master ~]# source /etc/profile
2.5,验证安装
主要在 master节点中安装即可,安装完毕可以通过scp命令直接拷贝文件分发到不同的节点中。赋予用户/data/hadoop目录的读写权限:
[root@ master ~]# hadoop version
# 有以下信息说明安装成功
Hadoop 3.3.1
Source code repository https://github.com/apache/hadoop.git -r a3b9c37a397ad4188041dd80621bdeefc46885f2
Compiled by ubuntu on 2021-06-15T05:13Z
Compiled with protoc 3.7.1
From source with checksum 88a4ddb2299aca054416d6b7f81ca55
This command was run using /usr/local/hadoop/hadoop-3.3.1/share/hadoop/common/hadoop-common-3.3.1.jar
2.6,修改配置文件
[root@master ~]# cd /usr/local/hadoop-3.3.1/etc/hadoop/
[root@master hadoop]# ll
总用量 176
-rw-r--r--. 1 1000 1000 9213 6月 15 2021 capacity-scheduler.xml
-rw-r--r--. 1 1000 1000 1335 6月 15 2021 configuration.xsl
-rw-r--r--. 1 1000 1000 2567 6月 15 2021 container-executor.cfg
-rw-r--r--. 1 1000 1000 774 6月 15 2021 core-site.xml
-rw-r--r--. 1 1000 1000 3999 6月 15 2021 hadoop-env.cmd
-rw-r--r--. 1 1000 1000 16654 6月 15 2021 hadoop-env.sh
-rw-r--r--. 1 1000 1000 3321 6月 15 2021 hadoop-metrics2.properties
-rw-r--r--. 1 1000 1000 11765 6月 15 2021 hadoop-policy.xml
-rw-r--r--. 1 1000 1000 3414 6月 15 2021 hadoop-user-functions.sh.example
-rw-r--r--. 1 1000 1000 683 6月 15 2021 hdfs-rbf-site.xml
-rw-r--r--. 1 1000 1000 775 6月 15 2021 hdfs-site.xml
-rw-r--r--. 1 1000 1000 1484 6月 15 2021 httpfs-env.sh
-rw-r--r--. 1 1000 1000 1657 6月 15 2021 httpfs-log4j.properties
-rw-r--r--. 1 1000 1000 620 6月 15 2021 httpfs-site.xml
-rw-r--r--. 1 1000 1000 3518 6月 15 2021 kms-acls.xml
-rw-r--r--. 1 1000 1000 1351 6月 15 2021 kms-env.sh
-rw-r--r--. 1 1000 1000 1860 6月 15 2021 kms-log4j.properties
-rw-r--r--. 1 1000 1000 682 6月 15 2021 kms-site.xml
-rw-r--r--. 1 1000 1000 13700 6月 15 2021 log4j.properties
-rw-r--r--. 1 1000 1000 951 6月 15 2021 mapred-env.cmd
-rw-r--r--. 1 1000 1000 1764 6月 15 2021 mapred-env.sh
-rw-r--r--. 1 1000 1000 4113 6月 15 2021 mapred-queues.xml.template
-rw-r--r--. 1 1000 1000 758 6月 15 2021 mapred-site.xml
drwxr-xr-x. 2 1000 1000 24 6月 15 2021 shellprofile.d
-rw-r--r--. 1 1000 1000 2316 6月 15 2021 ssl-client.xml.example
-rw-r--r--. 1 1000 1000 2697 6月 15 2021 ssl-server.xml.example
-rw-r--r--. 1 1000 1000 2681 6月 15 2021 user_ec_policies.xml.template
-rw-r--r--. 1 1000 1000 10 6月 15 2021 workers
-rw-r--r--. 1 1000 1000 2250 6月 15 2021 yarn-env.cmd
-rw-r--r--. 1 1000 1000 6329 6月 15 2021 yarn-env.sh
-rw-r--r--. 1 1000 1000 2591 6月 15 2021 yarnservice-log4j.properties
-rw-r--r--. 1 1000 1000 690 6月 15 2021 yarn-site.xml
2.6.1,core-site.xml
core-site.xml是Hadoop 的核心配置文件之一,用于配置 Hadoop 的核心参数。比如文件系统、Hadoop临时目录等。
# 查看本机名称
[root@ master hadoop]# hostname
master
[root@ master hadoop]# vi core-site.xml
添加如下代码
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/temp</value>
</property>
</configuration>
fs.defaultFS:nameNode的HDFS协议的文件系统通信地址。Hadoop将使用HDFS(Hadoop分布式文件系统)作为默认文件系统,并连接到主节点master的8020端口。hadoop.tmp.dir:Hadoop集群在工作的时候存储的一些临时文件的目录。临时文件将存储在/data/hadoop/temp目录中
2.6.2,hadoop-env.sh
hadoop-env.sh 是 Hadoop 配置文件之一,通常用于设置 Hadoop 的环境变量。比如 Java 环境、Hadoop用户和日志目录等。
[root@master hadoop]# vi hadoop-env.sh
# 指定Java的安装路径
export JAVA_HOME=/usr/local/jdk1.8.0_291
# 指定Hadoop日志输出的目录
export HADOOP_LOG_DIR=/var/hadoop/log/env
2.6.3,yarn-env.sh
yarn-env.sh 是 Apache Hadoop YARN(Yet Another Resource Negotiator)的配置文件之一,通常用于设置 YARN 的环境变量。可以影响 YARN 组件的运行和行为。
[root@master hadoop]# vi yarn-env.sh
# 指定Java的安装路径
export JAVA_HOME=/usr/local/jdk1.8.0_291
# 指定ResourceManager的堆内存大小
export YARN_RESOURCEMANAGER_HEAPSIZE=1024
# 指定NodeManager的堆内存大小
export YARN_NODEMANAGER_HEAPSIZE=2048
# 指定YARN日志输出的目录
export YARN_LOG_DIR=/var/hadoop/log/yarn
2.6.4,hdfs-site.xml
hdfs-site.xml 是 Apache Hadoop HDFS(Hadoop Distributed File System)的配置文件之一,用于配置 HDFS 的相关参数和属性。在这个 XML 格式的配置文件中,可以设置各种与 HDFS 相关的配置选项,如数据块大小、副本数量、数据节点存储路径等。
[root@hadoop1 hadoop]# vi hdfs-site.xml
添加如下代码:
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.nomenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.http.address</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
</configuration>
dfs.namenode.name.dir:NameNode存储元数据的目录路径,这里设置为file:///data/hadoop/dfs/namedfs.datanode.data.dir:DataNode存储数据块的目录路径,这里设置为file:///data/hadoop/dfs/datadfs.replication:HDFS数据块的副本数量,这里设置为3dfs.secondary.http.address:SecondaryNameNodeSecondaryNameNode 的 HTTP 地址,这里设置为master:50090dfs.http.address:通过HTTP访问HDFS的Web管理界面的地址dfs.blocksize:指定数据块的大小为128MB
2.6.5,mapred-site.xml
apred-site.xml 是 Apache Hadoop MapReduce 的配置文件之一,用于配置 MapReduce 框架的相关参数和属性。在这个 XML 格式的配置文件中,可以设置各种与 MapReduce 作业执行相关的配置选项,如作业跟踪器地址、任务并发数、任务重试次数等。
[root@master hadoop]# vi mapred-site.xml
添加如下代码:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<property>
<name>mapreduce.job.tracker</name>
<value>master:54311</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>1024</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
mapreduce.framework.name:指定 MapReduce 框架的名称,这里设置为yarn表示使用 YARN 作为资源管理器。mapreduce.jobhistory.address:指定 JobHistoryServer 的地址和端口号,这里设置为master:10020mapreduce.jobhistory.webapp.address:指定 JobHistoryServer 的 Web 应用地址和端口号,这里设置为master:19888。mapreduce.job.tracker:指定 JobTracker 的地址,这里设置为master:54311。mapreduce.map.memory.mb:指定每个 Mapper 任务可用的内存量。mapreduce.reduce.memory.mb:指定每个 Reducer 任务可用的内存量。yarn.app.mapreduce.am.env:设置 MapReduce ApplicationMaster 的环境变量,这里将HADOOP_MAPRED_HOME设置为${HADOOP_HOME}。mapreduce.map.env:设置 Mapper 任务的环境变量,同样将HADOOP_MAPRED_HOME设置为${HADOOP_HOME}。mapreduce.reduce.env:设置 Reducer 任务的环境变量,同样将HADOOP_MAPRED_HOME设置为${HADOOP_HOME}。
2.6.6,yarn-site.xml文件
yarn-site.xml 是 Apache Hadoop YARN 的配置文件,用于配置 YARN(Yet Another Resource Negotiator)资源管理器的相关参数和属性。在这个 XML 格式的配置文件中,可以设置各种与集群资源管理、作业调度和容器执行等相关的配置选项。
[root@master hadoop]# vi yarn-site.xml
添加如下代码:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>8192</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>6144</value>
</property>
</configuration>
yarn.resourcemanager.hostname:指定 ResourceManager 的主机名为master。yarn.nodemanager.aux-services:指定 NodeManager 的辅助服务,这里设置为mapreduce_shuffle表示启用 MapReduce Shuffle 服务。yarn.resourcemanager.address:指定 ResourceManager 的地址和端口号,这里设置为master:8032。yarn.resourcemanager.scheduler.address:指定 ResourceManager 的调度器地址和端口号,这里设置为master:8030。yarn.resourcemanager.resource-tracker.address:指定 ResourceManager 的资源跟踪器地址和端口号,这里设置为master:8031。yarn.resourcemanager.admin.address:指定 ResourceManager 的管理员地址和端口号,这里设置为master:8033。yarn.resourcemanager.webapp.address:指定 ResourceManager 的 Web 应用地址和端口号,这里设置为master:8088。yarn.log-aggregation-enable:开启日志聚集功能,将节点上的日志聚集到 HDFS 中。yarn.nodemanager.resource.memory-mb:指定每个 NodeManager 可用的内存量为 8192 MB。yarn.scheduler.maximum-allocation-mb:指定单个容器的最大内存分配量为 6144 MB。
3.6.7,workers
用于承担实际的计算和存储任务。这些节点包括 DataNode、NodeManager 和其他从节点,负责存储数据、执行任务并处理资源管理。
[root@master hadoop]# vi workers
# 删除localhost
# 添加
slave01
slave02
slave03
- DataNode:DataNode 是 Hadoop 分布式文件系统(HDFS)中的节点,负责存储实际的数据块。它们会接收来自客户端或其他节点的读写请求,并根据需要将数据块复制到其他节点以提供容错性和可靠性。
- NodeManager:NodeManager 是 YARN 中的节点管理器,负责接收来自 ResourceManager 的资源分配请求,并启动和监控容器以执行特定的应用程序任务。NodeManager 运行在每个“worker”节点上,并管理该节点上的资源利用情况。
- 其他从节点:除了 DataNode 和 NodeManager 外,还可能存在其他类型的从节点,根据集群的具体配置和需求而定。这些节点可能承担特定的任务或服务,例如运行其他计算框架或服务。
2.6.8,start-dfs.sh和stop-dfs.sh
start-dfs.sh是 Apache Hadoop 中用于启动分布式文件系统(HDFS)的脚本文件之一。执行start-dfs.sh脚本时,它会启动 HDFS 集群中的各个组件,包括 NameNode、DataNode 等,以使集群正常运行。stop-dfs.sh是 Apache Hadoop 中用于停止分布式文件系统(HDFS)的脚本文件之一。执行stop-dfs.sh脚本时,它会停止 HDFS 集群中的各个组件,包括 NameNode、DataNode 等。
[root@master ~]# cd /usr/local/hadoop-3.3.1/sbin/
[root@master sbin]# vi start-dfs.sh
# 指定 DataNode 组件在运行时所使用的用户为 root。DataNode 负责存储数据块,并在 HDFS 中扮演从节点的角色
HDFS_DATANODE_USER=root
# 指定了安全模式下 DataNode 运行时所使用的用户为 hdfs。在安全模式下,Hadoop 集群会采取额外的安全措施来保护数据和资源。
HADOOP_SECURE_DN_USER=hdfs
# 指定 NameNode 组件在运行时所使用的用户为 root。NameNode 是 HDFS 的主节点,负责管理文件系统的元数据信息。
HDFS_NAMENODE_USER=root
# 指定 SecondaryNameNode 组件在运行时所使用的用户为 root。SecondaryNameNode 用于辅助 NameNode 备份编辑日志。
HDFS_SECONDARYNAMENODE_USER=root
[root@master sbin]# vi stop-dfs.sh
# 指定 DataNode 组件在运行时所使用的用户为 root。DataNode 负责存储数据块,并在 HDFS 中扮演从节点的角色
HDFS_DATANODE_USER=root
# 指定了安全模式下 DataNode 运行时所使用的用户为 hdfs。在安全模式下,Hadoop 集群会采取额外的安全措施来保护数据和资源。
HADOOP_SECURE_DN_USER=hdfs
# 指定 NameNode 组件在运行时所使用的用户为 root。NameNode 是 HDFS 的主节点,负责管理文件系统的元数据信息。
HDFS_NAMENODE_USER=root
# 指定 SecondaryNameNode 组件在运行时所使用的用户为 root。SecondaryNameNode 用于辅助 NameNode 备份编辑日志。
HDFS_SECONDARYNAMENODE_USER=root
2.6.9,start-yarn.sh和stop-yarn.sh
start-yarn.sh是 Apache Hadoop 中用于启动 YARN(Yet Another Resource Negotiator)的脚本。YARN 是 Hadoop 的资源管理平台,负责集群资源的管理和作业调度。执行start-yarn.sh脚本时,它将启动 YARN 集群中的各个组件,包括 ResourceManager、NodeManager 等。stop-yarn.sh是 Apache Hadoop 中用于停止 YARN(Yet Another Resource Negotiator)的脚本。执行stop-yarn.sh脚本时,它会停止 YARN 集群中的各个组件,包括 ResourceManager、NodeManager 等。
[root@master sbin]# vi start-yarn.sh
# 指定了 ResourceManager 组件在运行时所使用的用户为 root。ResourceManager 是 YARN 的资源管理器,负责全局的资源分配和作业调度。
YARN_RESOURCEMANAGER_USER=root
# 指定了安全模式下 DataNode(DataNode 负责存储数据块)运行时所使用的用户为 yarn。在安全模式下,Hadoop 集群会采取额外的安全措施来保护数据和资源。
HADOOP_SECURE_DE_USER=yarn
# 指定了 NodeManager 组件在运行时所使用的用户为 root。NodeManager 负责管理节点上的资源,并与 ResourceManager 进行通信。
YARN_NODEMANAGER_USER=root
[root@master sbin]# vi stop-yarn.sh
# 指定了 ResourceManager 组件在运行时所使用的用户为 root。ResourceManager 是 YARN 的资源管理器,负责全局的资源分配和作业调度。
YARN_RESOURCEMANAGER_USER=root
# 指定了安全模式下 DataNode(DataNode 负责存储数据块)运行时所使用的用户为 yarn。在安全模式下,Hadoop 集群会采取额外的安全措施来保护数据和资源。
HADOOP_SECURE_DE_USER=yarn
# 指定了 NodeManager 组件在运行时所使用的用户为 root。NodeManager 负责管理节点上的资源,并与 ResourceManager 进行通信。
YARN_NODEMANAGER_USER=root
2.7,分发Hadoop安装包到其他节点
- 所有节点的
Hadoop安装包位置和配置信息必须一致
在节点 master使用scp命令进行分发:
# 分发给从节点1
[root@ master ~]# scp -r /usr/local/hadoop-3.3.1 root@slave01:/usr/local
# 分发给从节点2
[root@ master ~]# scp -r /usr/local/hadoop-3.3.1 root@slave02:/usr/local
# 分发给从节点3
[root@ master ~]# scp -r /usr/local/hadoop-3.3.1 root@slave03:/usr/local
3,启动环节
3.1,初始化文件系统
[root@master hadoop]# hdfs namenode -format
出现下以下情况说明成功
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bNL8KWTf-1684897919374)(E:\Java笔记\大数据\Hadoop\安装Hadoop\Hadoop.assets\image-20230516143924690.png)]](https://i-blog.csdnimg.cn/blog_migrate/dd0b595ad0a4149a3b5b185feccb8384.png)
3.2,修改宿主机的host文件地址
C:\Windows\System32\drivers\etc\host
host是一个没有扩展名的系统文件,起作用是将一些常用的域名与其对应的ip地址建立一个关联,
# 主节点地址,名称,域名
192.168.184.136 master hadoop.master.com
# 从节点地址,名称,域名
192.168.184.137 slave01 hadoop.slave01.com
# 从节点地址,名称,域名
192.168.184.138 slave02 hadoop.slave02.com
# 从节点地址,名称,域名
192.168.184.139 slave03 hadoop.slave03.com
3.3,启动hdfs和启动yarn
[root@master hadoop]# start-dfs.sh
[root@master hadoop]# start-yarn.sh
[root@master hadoop]# jps
4150 SecondaryNameNode
5053 Jps
3886 NameNode
3498 resourcemanager
# 查看三个三台从机的信息
[root@slave01 hadoop]# jps
1376 DataNode
1656 Jps
7655 NodeManager
[root@slave02 hadoop]# jps
1378 DataNode
1610 Jps
7659 NodeManager
[root@slave03 hadoop]# jps
1380 DataNode
1661 Jps
7658 NodeManager
3.4,访问
http://master:50070

http://master:8088/cluster

切记开放防火墙,放行相关端口号:http://t.csdnimg.cn/dPkUc

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)