ESRGAN(ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks)超分辨网络
Contents1 Introduction2 Related Work3 Proposed Methods3.1 Network Architecture3.2 Relativistic Discriminator3.3 Perceptual Loss3.4 Network Interpolation4 Experiments4.1 Training Details4.2 Qualitative
对超分有兴趣的同学们可直接关注微信公众号,这个号的定位就是针对图像超分辨的,会不断更新最新的超分算法解读。

正文开始
Contents
1 Introduction
这篇文章,作者主要从三个方面对SRGAN进行改进:网络结构、对抗损失、感知损失。
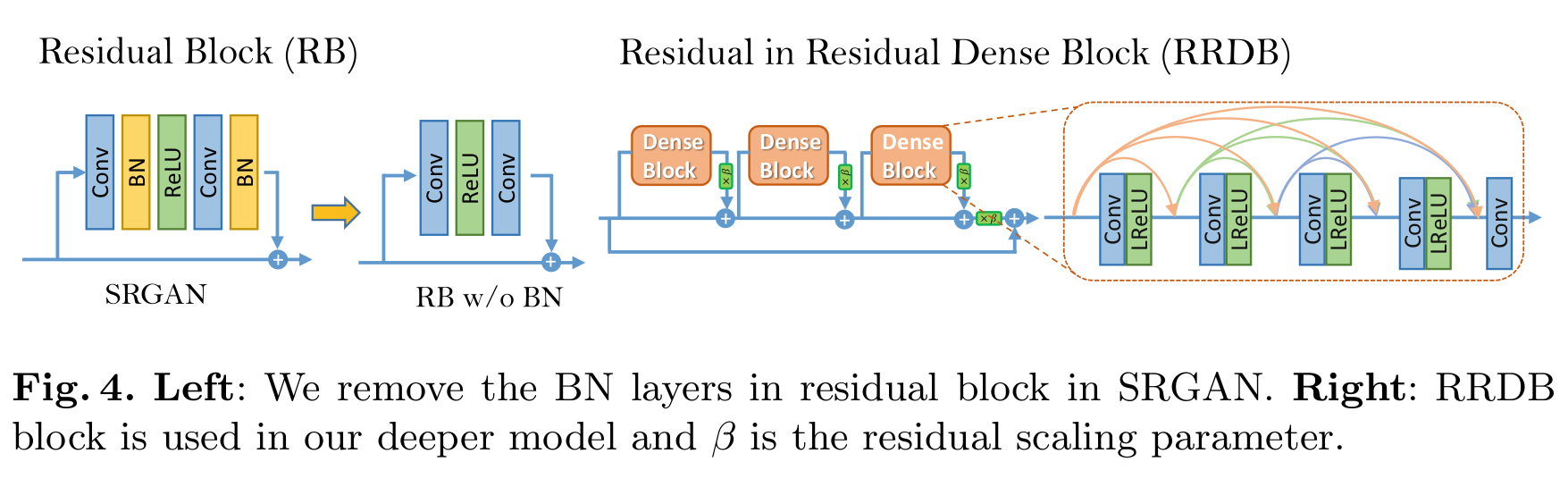
网络结构:引入了 Residual-in-Residual Dense Block (RRDB)来代替SRGAN中的resblock;移除了网络单元的BN层;增加了residual scaling,来消除部分因移除BN层对深度网络训练稳定性的影响。我认为,这主要是借用了EDSR的网络思想。
对抗损失:SRGAN的对抗损失的目的是为了让真实图像的判决概率更接近1,让生成图像的判决概率更接近0。而改进的ESRGAN的目标是,让生成图像和真实图像之间的距离保持尽可能大,这是引入了真实图像和生成图像间的相对距离(Relativistic average GAN简称RaGAN),而不是SRGAN中的衡量和0或1间的绝对距离。(具体说来,ESRGAN目的是:让真实图像的判决分布减去生成图像的平均分布,再对上述结果做sigmoid处理,使得结果更接近于1;让生成图像的判决分布减去真实图像的平均分布,再对上述结果做sigmoid处理,使得结果更接近于0。)
感知损失:(基于特征空间的计算,而非像素空间)使用VGG网络激活层前的特征图,而不像SRGAN中使用激活层后的特征图。因为激活层后的特征图有更稀疏的特征,而激活前的特征图有更详细的细节,因此可以带来更强的监督。并且,通过使用激活后的特征图作为感知损失的计算,可以带来更加锐化的边缘和更好视觉体验。

之前的网络大都以优化PSNR为导向,但这样会使生成的图像更光滑,而损失掉高频细节信息。自从SRGAN以来,网络开始使用残差块和以感知损失为导向,这样,虽然PSNR会降低,但人对图像的感受会变好。从而也可知PSNR指标并不可靠。而ESRGAN则对SRGAN的三个部分做进一步的改进,以进一步提升网络表现。
文章中提到了新的图像质量评估标准(无参照评估):Ma’s score 和NIQE,计算公式为:perceptual index(即PI) = 1/2 ((10 − Ma) + NIQE),PI值越小,感知质量越好。

上图中,对于不同的评价标准而言,PSNR and SSIM越高越好,而RMSE and PI越低越好。可以看出,虽然EDSR and RCAN的RMSE很低,但PI却很高,说明感知质量并不好,ESRGAN则相反。
最后,为了平衡感知质量和PSNR指标,作者提出了网络插值。这能够调整重建风格和光滑度。同时,作者将在3.4节对比网络插值和基于像素空间的图像插值的关系。
2 Related Work
该部分主要列出了今年的一些trick。
整体网络:最近提出的网络结构思想如下:扩展模型尺寸;使用高效残差密集块、使用channel attention机制加深网络、强化学习、无监督学习。
深度网络的稳定训练:残差通道、残差因子、网络(无BN)参数初始化的方法、residual-in-residual dense block替换残差块。
感知损失:目标是最小化特征空间的误差而不是像素空间的误差。
判别损失:相关性判别器作为优化目标,不仅增加了生成数据为真的概率,也减小了真实数据为真的概率。
评价标准:否定了PSNR 和SSIM。肯定了基于人类感知的无线照评价方法Ma’s score和NIQE,从而根据这种评价标准创建了perceptual index(PI)评价方法。
3 Proposed Methods
网络目标为提升图片的整体感知质量,主要涉及四个方面:
- 网络结构;
- 判别器;
- 感知损失;
- 网络插值(平衡感知质量和PSNR).
3.1 Network Architecture
ESRGAN对SRGAN的生成器部分做了两处修改:
- 移除BN层;
- 将原始的resblock替换为Residual-in-Residual Dense Block (RRDB)。这样的block既融合了多级残差网络的思想,也融合了密集连接的思想。
修改如下图所示:

移除BN层的好处:1. 增加了网络的表现;2. 降低了以PSNR为导向的图像重建任务的计算复杂度,在一定程度上也节约了存储资源。BN层是通过使用每个batch的均值和方差对特征完成正规化,而在测试时,BN则使用整个训练集数据的均值和方差完成对测试数据的正规化。这变出现一个问题,用训练接数据的均值和方差来估计测试数据的均值和方差是否合理?答案往往是否定的,且这样做可能使越深的GAN网络生成的SR图像引入越多的伪影。并且由于不同网络的不同参数设置,BN的引入有时还能造成网络不稳定。
使用图4中的RRDB替代下图3中的basic block(resblock):

首先的目的是在网络深度上下功夫,因为已经被证明越深的网络感受野越好,利用周围环境的信息量越大,越能够构建出出色的SR图像。并且,更深的网络往往有更复杂的非线性映射和复杂的计算。而dense connection是为了避免正反向传递过程中的信息丢失问题(图像信息、梯度等)。
除了上述的两个对于网络结构的较大变化外,作者还提到了两个小的点子:
- residual scaling:通过对学习到的残差乘上一个0-1间的常数,然后再和主通路上的特征信息做加法,有利于增强网络的稳定性。参考文献2
- smaller initialization:实验得出,初始化方差越小,网络越容易训练。具体方法参考文献3
3.2 Relativistic Discriminator
这个函数我起初很不好理解,所以把我忽略的点讲给大家。
首先,提一下sigmoid函数的图像:

可以看出自变量区域负无穷时因变量趋于0,自变量区域正无穷时因变量趋于1。

图5中,C表示判别器的原始输出结果(论文表达是:C(x) is the non-transformed discriminator output),fake表示生成图片SR而非LR,E[·]表示求期望,σ表示sigmoid函数。
标准的GAN网络的目的是为了让真实图像的判别结果的概率更趋进于1(真),让生成图像的判别结果的概率更趋近于0(假)。
==改进后的Relativistic average Discriminator(DRa)==可解释如下:首先需要明确的是判别器对真实数据判决的原始值大于对生成数据判决的原始值。因此考虑第一个等式左侧,有C(REAL)-E[C(FAKE)]>0,且差值越大,表明二者距离越远,也就是该差值经过sigmoid后的值越接近于1。因此D的目的是使得该sigmoid值尽可能接近于1,这就将真实图片和生成图片很好的区分开来;考虑第二个等式左侧,有C(FAKE)-E[C(REAL)]<0,且差值越小(负的越多),表明二者距离越远,也就是该差值经过sigmoid后的值越接近于0。因此D的目的是使得该sigmoid值尽可能接近于0,这就将真实图片和生成图片很好的区分开来。
我们给出更新后的判别器DRa的数学表达式,通过上述分析,该优化函数便很好理解:

生成器的对应于判别器的对称目标函数如下:

xf = G(xi),xi表示LR图像,xf表示生成图像SR。站在直观的角度上解释:因为判别器是为了更好的区分真实和生成,而生成器是为了更难区分真实和生成。因为生成器的优化函数中同时涉及生成数据xf和真实数据xr,所以更有利于梯度的生成,可以更有利于生成图像中的边缘和细节信息。
3.3 Perceptual Loss
提出了一种在VGG激活层前获取的感知损失Lpercep(通过计算抽象出来的SR和HR的特征图间的距离),而非传统的SRGAN在激活层后计算感知损失。在激活层后计算感知损失由两个缺点:
-
激活层后的特征是已经稀疏化了的,越深的网络越明显(如图6)。稀疏的特征会导致更弱的监督,从而网络性能变差。

-
使用激活层后的特征图计算感知损失会使得重建图像的亮度和ground-truth图像不一致。
现在,我们的生成器的优化函数可表达如下:

其中:

表示L1范数,表示生成图像G(xi)和ground-truth之间的距离。λ和η是平衡不同损失函数的系数。
作者为了 PIRM-SR比赛,还探索了一种不同于SRGAN网络的感知损失函数,称为SR – MINC loss。这种损失函数是建立在微调的用于识别材料VGG网络(而不是物体识别)上的,这样的网络可以将特征图的构建更多的集中在细节上。但目前为止,这种新构建的损失函数对于提高PI指标仍然很微弱。
3.4 Network Interpolation
目的是为了在保证感知质量的前提下消除噪声。
首先以PSNR为目标训练网络GPSNR,在在GPSNR的基础上微调得到GGAN,然后对两个网络对应的参数进行插值得到插值模型GINTERP,各模型间的参数关系可表示为:

其中θ表示个网络中的参数,α ∈ [0, 1]是插值参数。这样一个插值网络有两个优点。1. 插值网络在不引入伪影的情况下可以产生更有意义的结果。2. 平衡感知质量(GAN-base为导向,GAN-base指的是ESRGAN)和保真度(PSNR指标为导向)。
4 Experiments
4.1 Training Details
放大倍数:x4
获取LR方式:对HR进行bicubic
patch size:128x128
batch size:16
训练过程:
- 以PSNR为导向,以优化L1损失为目标训练模型,初始化学习率2x0.0001,每200,000次迭代学习率衰减一半。
- 以PSNR为导向的模型参数为生成器网络的初始化参数,再通过等式3训练网络,其中λ = 5x0.001,η= 0.01,学习率0.0001, 每[50k, 100k, 200k, 300k] 次迭代衰减一半。优化器使用Adam。以PSNR为导向的预训练网络能够帮助GAN-base网络更快的收敛。
training data:DIV2K、Flickr2k、OutdoorSceneTraining(OST)
数据增强:翻转+旋转
评估benchmark datasets:set5,set14, BSD100, Urban100, 比赛方自己的数据集。
4.2 Qualitative Results
ESRGAN和以往的各SOTA在两个指标下的比较:用于评估YCbCr空间亮度通道的PSNR指标和被用于PIRM-SR挑战赛的PI指标。如图7




ESRGAN能够带来更多的细节信息和锐化,并且相比之前的GAN网络生成的图像,本文的方法有更少的伪影,使得生成的图像更自然。
4.3 Ablation Study
通过在SRGAN的基础上一步一步改进模型,进而实现ESRGAN,我们在此探索中间的每一步改进的效果。




移除BN:为了网络的稳定性和消除伪影移除了BN,此操作也节约了计算和存储资源。比较第二列和第三列,网络表现有轻微提升(如image 39)。越深的网络,移除BN对消除伪影的作用越大。
激活前计算感知损失:能够提升生成图像亮度分量的精度,对比第三第四列。

由图9a所示,通过高斯核对图像进行模糊得到图像的亮度直方图,可以看出,在亮度直方图中,激活前的图像的亮度直方图更接近真实图像的亮度直方图。由图9b所示,利用激活前的特征图做损失函数有利于生成更锐化的边缘和丰富的细节。因为激活前的特征图有更密集的特征,因此有更强的监督。
RaGAN:能够生成更锐化的边缘和丰富的细节,比较第四第五列(如image 39和image 43074)。
Deep Network with RRDB:更深的模型对图像的语义信息有更强大捕捉能力,能够产生更真实的细节纹理,比较第五第六列(如image 6),更深的模型更能减小噪声(如image 20)。
4.4 Network Interpolation

网络插值好,图像插值不好。
4.5 The PIRM-SR Challenge
挑战赛中,网络使用了16个residual block,以MINC作为损失函数来优化PI指标。再次强调探索集中在细节方面的感知损失对于SR的重要性。
5 Conclusion
总结网络中值得注意的几个点:RRDB替代传统的resblock、移除BN、residual scaling、smaller initialization、relativistic average GAN(discriminator)、features before activation。
References
- ESRGAN超分辨网络
- Szegedy, C., Ioffe, S., Vanhoucke, V.: Inception-v4, inception-resnet and the impact of residual connections on learning. arXiv preprint arXiv:1602.07261
- He, K., Zhang, X., Ren, S., Sun, J.: Delving deep into rectififiers: surpassing human level performance on imagenet classifification

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)