超详细!ComfyUI 全方位入门指南,初学者必看,附多个实践操作
本文正文字数约 8300 字,阅读时间 20 分钟。如果按照文章实操一遍,预计时间在半小时到两小时不等。在上一篇文章中,我向大家介绍了有关于 Stable Diffusion 的基本概览,同时也在文章里放置了一些相关的工具链接可以方便的使用 Stable Diffusion 生成图像。
前言
本文正文字数约 8300 字,阅读时间 20 分钟。如果按照文章实操一遍,预计时间在半小时到两小时不等。
在上一篇文章中,我向大家介绍了有关于 Stable Diffusion 的基本概览,同时也在文章里放置了一些相关的工具链接可以方便的使用 Stable Diffusion 生成图像。
但是在线生成器往往都有一些限制,有的还需要收费才能使用,所以为了能够更加全面深入地学习 Stable Diffusion,我还是推荐在自己电脑上自行搭建一套 GUI(也就是用户图形界面)来学习和使用 Stable Diffusion,也就是本文即将介绍的 ComfyUI。
本文将为你提供一份全面的 ComfyUI 入门指南,涵盖从 ComfyUI 的介绍,到它的生图工作流程,再到实操。我将通过简单的一些生图流程案例来向你介绍 ComfyUI 中的各项操作。
所有的AI设计工具,安装包、模型和插件,都已经整理好了,👇获取~
目录
-
• ComfyUI 简介
-
• ComfyUI 的安装
-
• ComfyUI 工作流:文生图
-
• ComfyUI 的工作机制
-
• ComfyUI 工作流:图生图
-
• ComfyUI 各模型对比
-
• ComfyUI Inpainting
-
• ComfyUI Outpainting
-
• ComfyUI Upscale
-
• ComfyUI Manager
-
• ComfyUI Embeddings
-
• ComfyUI LoRA
-
• 总结
ComfyUI 简介
ComfyUI 是一个基于节点的 GUI,为 Stable Diffusion 提供了一种更加直观、灵活的方式来操作和管理生成的过程。通过将不同的模块(也就是节点)组合在一起,我们可以构建一个图像生成的工作流。
ComfyUI vs. AUTOMATIC1111
AUTOMATIC1111 也是一款有着大量用户使用的 Web UI,那么它与 ComfyUI 的区别是什么呢?
相对于 AUTOMATIC1111 来说,使用 ComfyUI 有下面这些优势:
-
• 轻量化,运行速度更快
-
• 高度灵活可配置
-
• 数据流清晰可见
-
• 每个文件都是可复现的工作流,便于分享
不过,ComfyUI 的学习曲线相对于 AUTOMATIC1111 来说要更为陡峭,需要更多的耐心和摸索。
AUTOMATIC1111 官方 GitHub:https://github.com/AUTOMATIC1111/stable-diffusion-webui,这里有关于 AUTOMATIC1111 的安装和使用教程。
ComfyUI 的安装
关于 ComfyUI 的安装,可以直接参考官方文档:https://docs.comfy.org/get_started/pre_package。
Windows 用户可以直接访问上面的链接来下载安装包进行安装,但是 Mac 或者 Linux 用户需要参考手动安装教程:https://docs.comfy.org/get_started/manual_install。
手动安装 ComfyUI 需要你对命令行有所了解。
下载模型
ComfyUI 安装包里并没有包含模型文件,所以如果需要使用它来生图,需要我们自行下载模型文件并放置到 ComfyUI 的安装目录里。
可以在 HuggingFace 上根据自己电脑的配置来选择不同的 Stable Diffusion 模型:https://huggingface.co/models?search=stable-diffusion,同时,ComfyUI 还支持最新的 SDXL 模型。
我选择的是 stable-diffusion-3-medium 这个模型,总共大小在 50G 左右。
我这里也分享一下我下载模型的过程,毕竟这中间也遇到了一些问题,我会在这里列举出主要的步骤,你可以按照我给出的步骤来下载大模型,如果遇到问题也欢迎留言。
如果你也遇到了 Error while deserializing header: HeaderTooLarge 这种类似的问题,那可能就是模型文件没下载对。
1、安装 `git-lfs`
由于模型文件都特别大,所以不能使用常规的 git 命令来下载,需要安装 git-lfs,具体可以参考官方的安装说明:https://git-lfs.com/。
2、到 HuggingFace 上添加 SSH Key 或者 Access Token
3、开始下载模型
经过前两个步骤之后,现在就可以开始下载模型了。
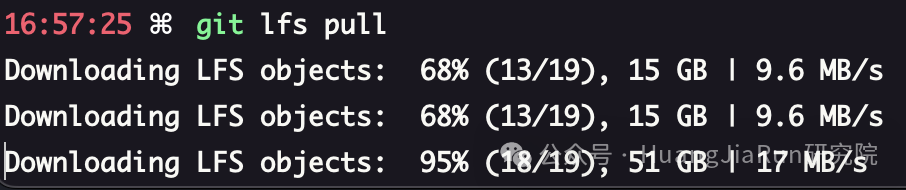
我们第一步可以先下载模型的文件指针,这些文件就很小,通常只有一两百 kb。
GIT_LFS_SKIP_SMUDGE=1 git clone git@hf.co:stabilityai/stable-diffusion-3-medium
随后,再执行下面这个命令就可以了,这一步根据你的网络情况耗费的时间可能会或长或短:
git lfs pull
4、将模型文件放入 ComfyUI 的安装目录
找到模型目录里的 .ckpt 或者 .safetensors 文件,将其放入 ComfyUI 目录下的 models/checkpoints 目录下就可以了。
要学习 ComfyUI,最好的方式就是直接通过案例来练习。所以我们将从最简单的文生图工作流程开始。
ComfyUI 工作流:文生图
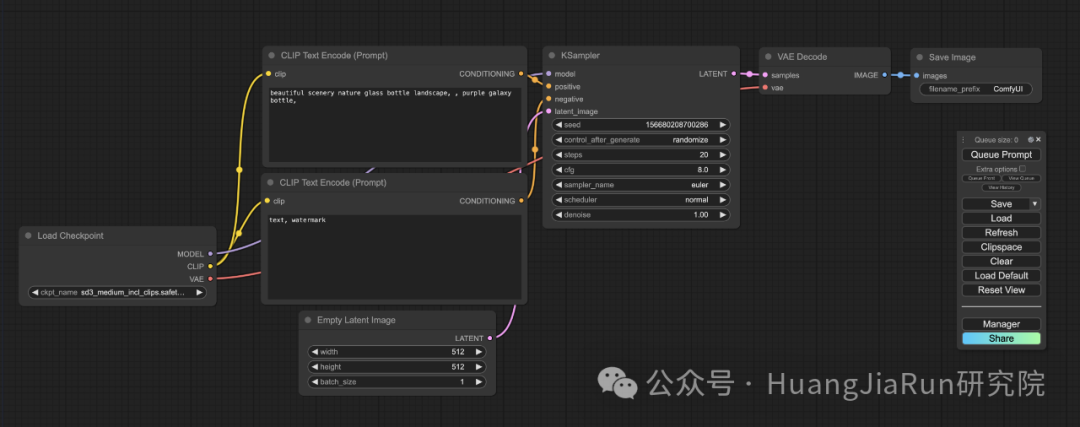
成功运行 ComfyUI 之后,按照其默认配置,在电脑浏览器上打开 http://127.0.0.1:8188/ 应该就能看到下面这样的界面。
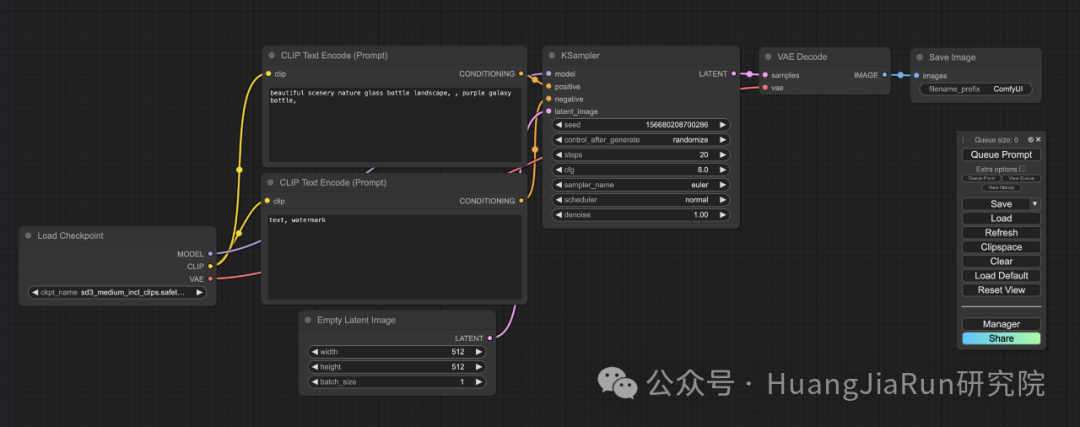
界面上的节点和整个画布都可以拖动,也可以放大缩小。
ComfyUI 为我们提供了一个默认的文生图工作流。直接点击右边的 Queue Prompt 就能够触发生图流程,你可以看到有个绿色的边框会随着流程的进展在不同的节点上显示。
整个工作流由两个基本的部分组成:节点(Nodes)和边(Edges)。
-
• 每一个矩形块就是一个节点,比如
Load CheckpointCLIP Text Encoder等。可以把每个节点看成是函数,它们都具有输入、输出和参数三个属性。 -
• 连接每个节点的输入和输出的线就是边。
其他还有很多的细节和概念,我将会在接下来的内容中逐步解释。
我们直接从这个默认工作流开始,它包含了下面这些步骤。
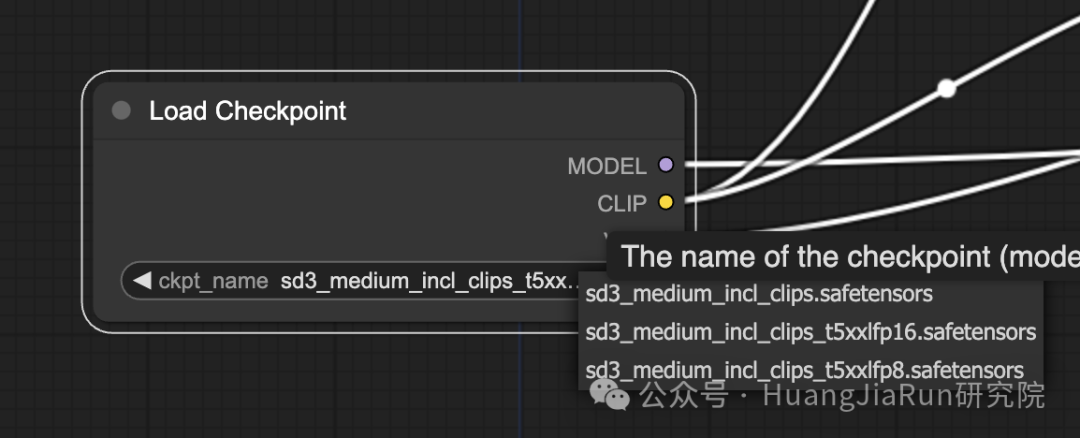
1、选择模型
首先需要在 Load Checkpoint 这个节点中选择一个模型,这里的模型选项就是在上文中下载的那些模型文件。比如我这里就放置了多个可选的模型,我可以根据自己的需求选择我想要使用的模型。
2、构造提示语
选择完模型,下一步就是构造提示语了。
在界面上,有两个 CLIP Text Encode (Prompt) 节点,这两个节点都是用来构造我们的提示语的。
其中,上面一个节点用来输入正向提示语(Positive Prompt),即告诉模型做什么,而下面一个节点则用来输入负面提示语(Negative Prompt),即告诉模型不要做什么。
如果觉得容易混淆,可以像我这样直接双击节点名称改成它对应的功能的名称,就像下面这样。
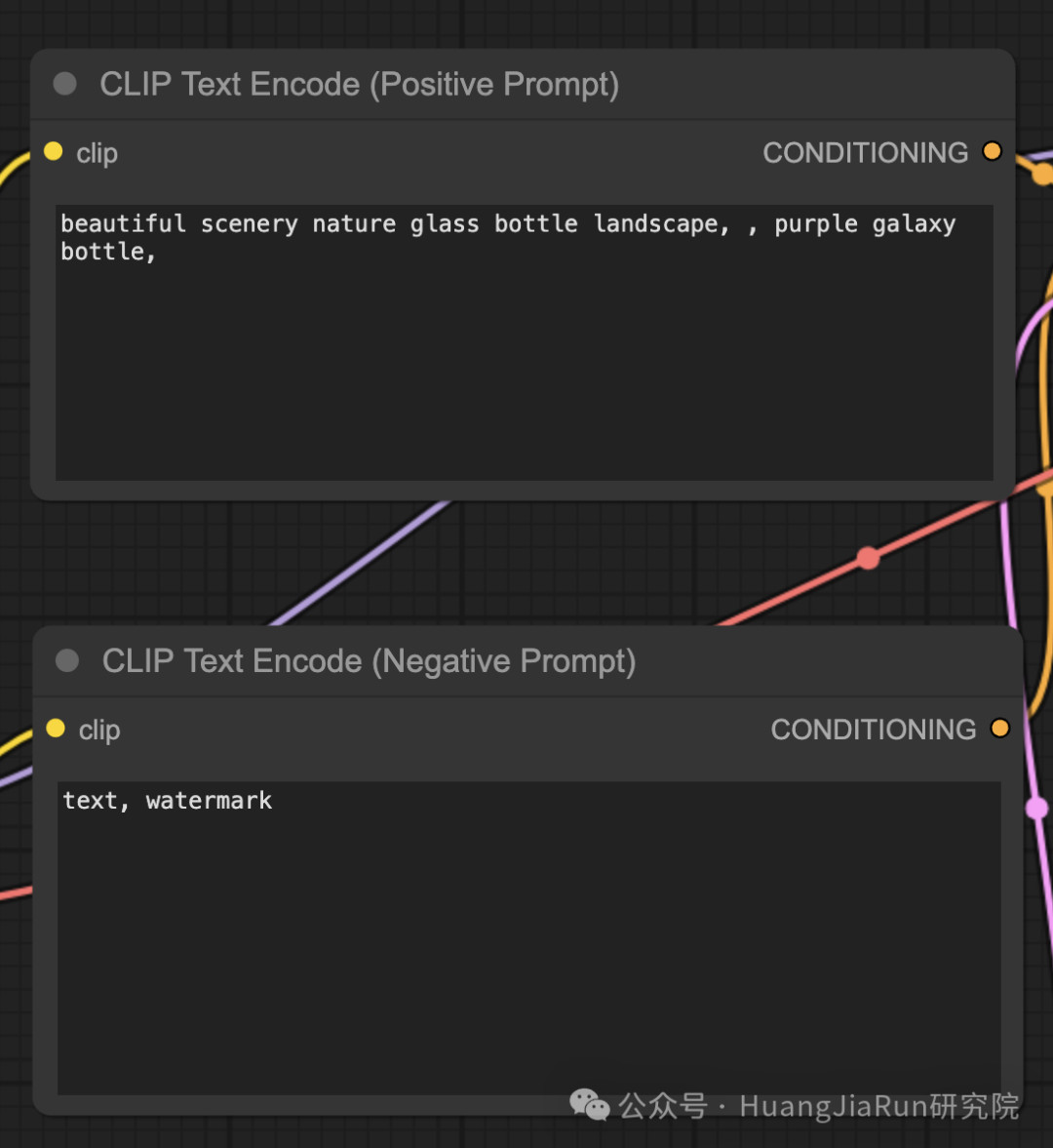
当然,其实从图上节点之间的连接方式也能看出来哪一个是正向哪一个是负向的。
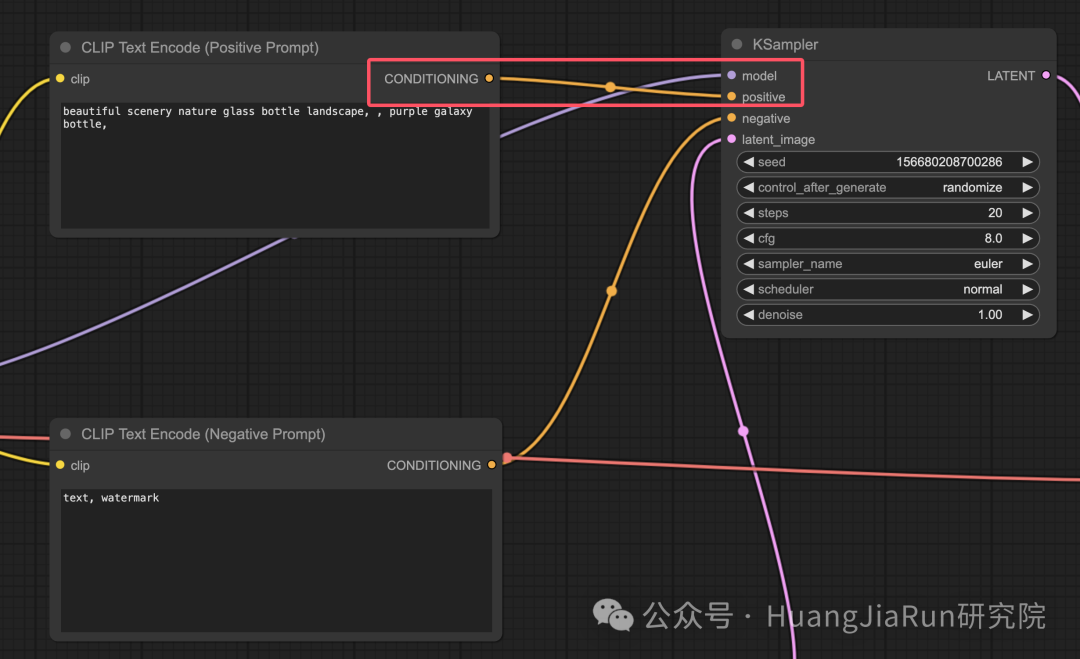
CLIP Text Encode 节点的作用是将提示语转换为标记,然后通过文本编码器将它们处理为嵌入(Embeddings)。
关于向量嵌入的介绍,可以参考:谈一谈向量嵌入(Vector Embeddings)
你可以使用 (关键词:权重) 的这样的语法来控制关键词的权重。
比如,使用 (keyword:1.2) 来增强效果,或 (keyword:0.8) 来减弱效果。
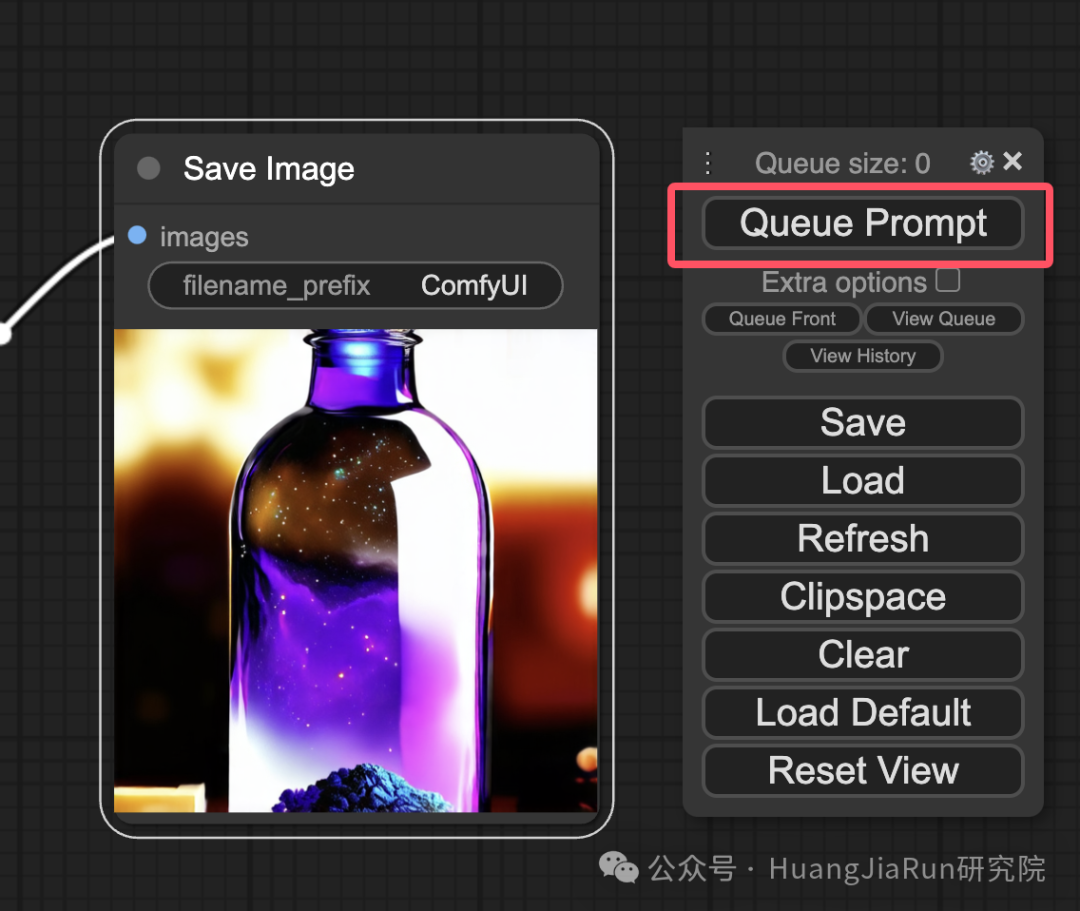
3、生成图像
点击右边的 Queue Prompt,等待一会儿就能够看到有一张图像生成完成了。
ComfyUI 的工作机制
这一个章节涉及一些 ComfyUI 底层的工作机制,如果不想看可以直接跳过。
ComfyUI 的强大之处就在于它的高度可配置性。熟悉每个节点的功能之后可以让我们轻易地根据需求来定制化操作。
在介绍图生图工作流之前,我需要先向你详细介绍一下 ComfyUI 的工作机制。
Stable Diffusion 的生图过程可以总结为以下三个主要步骤:
-
- 文本编码:用户输入的提示语通过一个称为文本编码器(Text Encoder) 的组件编译成各个单词的特征向量。这一步将文本转换为模型可以理解和处理的格式;
-
- 潜在空间(Latent space)转换:来自文本编码器的特征向量与一个随机噪声图像一起被转换到潜在空间。在这个空间中,随机图像根据特征向量进行去噪处理,得到一个中间产物。这一步生图过程的是关键所在,因为模型会在这里学习将文本特征与视觉表现相联系。
-
- 图像解码:最后,潜在空间中的中间产物由图像解码器(Image Decoder) 进行解码,转换为我们可以看到的实际图像。
潜在空间(Latent Space) 是机器学习和深度学习中用于表示高维复杂数据的一个低维空间。它是对数据的一种压缩和抽象,可以理解为对原始数据(如图像、文本等)的简化表示。
了解了 Stable Diffusion 层面的生图流程之后,接下来我们深入了解一下 ComfyUI 在实现这个过程中的关键组件和节点。
Load Checkpoint 节点
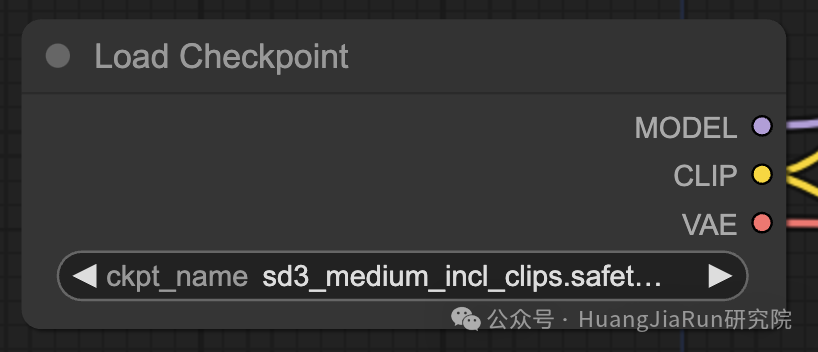
Load Checkpoint 节点会加载一个模型,一个 Stable Diffusion 模型主要包含以下三个部分:
MODEL
MODEL 组件是一个在潜在空间(Latent Space)中运行的噪声预测模型。
这句话的意思是 Stable Diffusion 模型在潜在空间中对图像的生成过程进行建模,并通过预测和去除噪声逐渐还原图像的过程。
具体来说就是,在 Stable Diffusion 中,图像生成首先在潜在空间中引入随机噪声,然后模型通过一系列步骤逐渐去除这些噪声,生成符合提示语的图像。
这种逐步去噪的过程由噪声预测模型来完成。潜在空间是图像的一个简化、高度抽象化的表示,可以降低模型的计算复杂度,可以让模型在生成图像时更高效。
在 ComfyUI 中,Load Checkpoint 节点的 MODEL 输出连接到 KSampler 节点,KSampler 节点执行反向扩散过程。
KSampler 节点利用 MODEL 在潜在表示中进行迭代去噪,逐步优化图像,直到它符合给定的提示语。
CLIP (Contrastive Language-Image Pre-training)
CLIP 其实是一个负责预处理用户提供的正向和负面提示语的语言模型。它将文本提示转换为 MODEL 可以理解的格式,指导图像生成过程。
在 ComfyUI 中,Load Checkpoint 节点的 CLIP 输出连接到 CLIP Text Encode 节点。CLIP Text Encode 节点获取用户提供的提示语,并将它们输入到 CLIP 语言模型中,转换为向量嵌入。
这些向量嵌入可以捕捉单词的语义,为 MODEL 生成符合提示语的图像提供更多的指导。
VAE (Variational AutoEncoder)
VAE 负责在像素空间和潜在空间之间转换图像。
它包含一个编码器和一个解码器,其中,编码器用于将图像压缩为低维的潜在表示,而解码器用于从潜在表示中重建图像。
在文生图的过程中,VAE 仅在最后一步使用,它的作用就是将生成的图像从潜在空间转换回像素空间。
ComfyUI 中的 VAE Decode 节点获取 KSampler 节点的输出,并利用 VAE 的解码器部分将潜在表示转换为最终的像素空间图像。
VAE 与 CLIP 语言模型是独立的组件。CLIP 主要处理文本提示语,而 VAE 负责在像素空间和潜在空间之间进行转换。
关于潜在空间和像素空间的区别,可以理解为像素空间是图像的可见表现形式,而潜在空间是对图像进行内部操作和处理的一种简化表示。Stable Diffusion 在潜在空间中生成图像,再通过 VAE 将其转换回像素空间,然后获得最终的图像。
到目前为止,我只介绍了整个工作流中的第一个节点,接下来我会继续介绍后续的节点。
CLIP Text Encode 节点
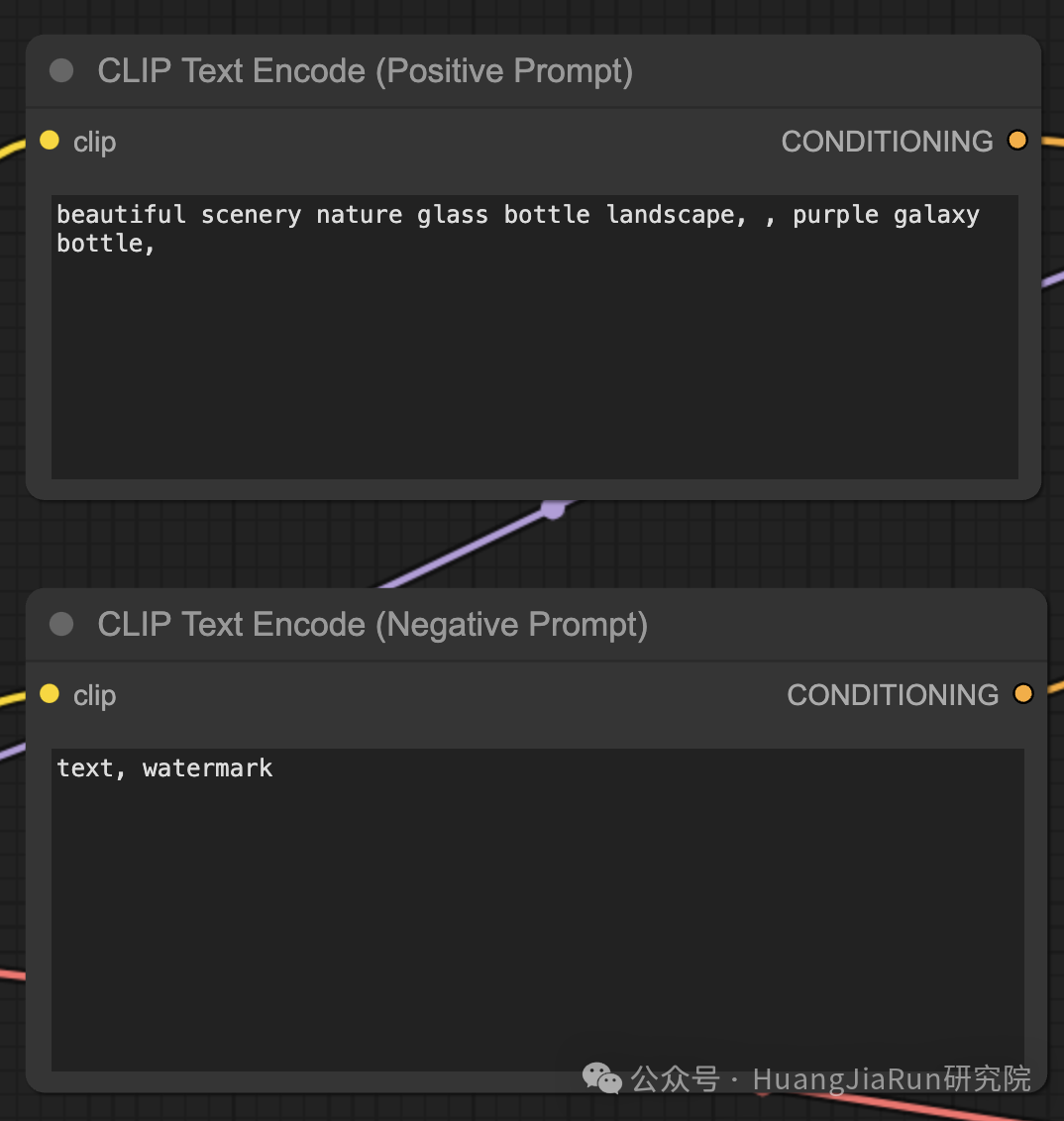
在上文中有提到,在 CLIP Text Encode 节点中我们可以输入生成图像的提示语,而这个节点的作用就是获取我们提供的提示语,并将其输入到 CLIP 语言模型中。
CLIP 是一个强大的语言模型,能够理解单词的语义并将其与视觉概念相关联。当提示语输入到 CLIP Text Encode 节点后,它会将每个单词转换为向量嵌入。向量嵌入是高维的数字表示,包含了单词的语义信息,模型能够根据这些信息生成符合提示语的图像。
Empty Latent Image 节点
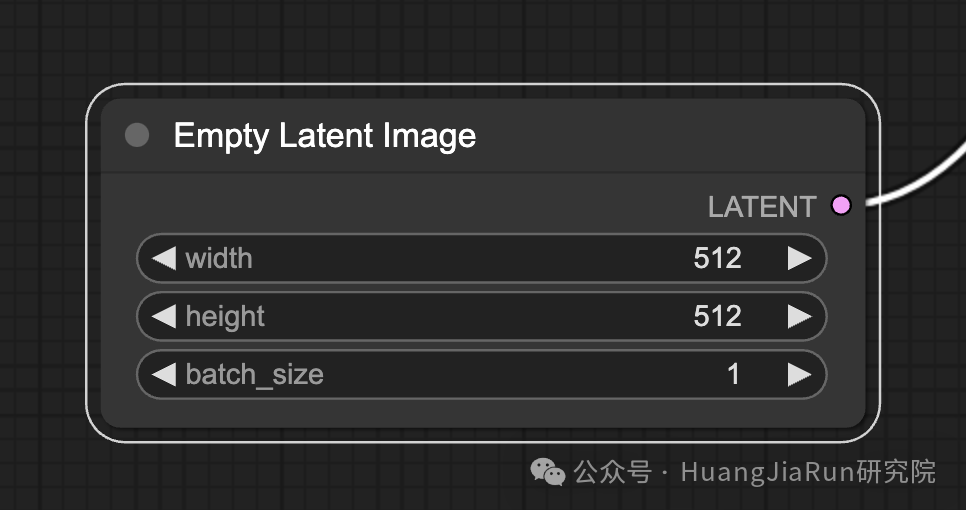
在 ComfyUI 的文生图的过程中,它首先会在潜在空间中生成一个随机图像,这个图像会作为模型处理的初始状态,它的大小与实际像素空间中的图像尺寸成比例。
在 ComfyUI 中,我们可以调整潜在图像的高度和宽度来控制生成图像的大小。此外,我们还可以设置批处理大小来确定每次运行生成的图像数量(batch_size)。
潜在图像的最佳尺寸取决于所使用的 Stable Diffusion 模型版本。
对于 v1.5 模型,推荐的尺寸是 512x512 或 768x768;对于 SDXL 模型,最佳尺寸是 1024x1024。ComfyUI 提供了多种常见的宽高比可供选择,但是需要注意的是,潜在图像的宽度和高度必须是 8 的倍数,这样才能确保与模型架构的兼容性。
VAE 节点
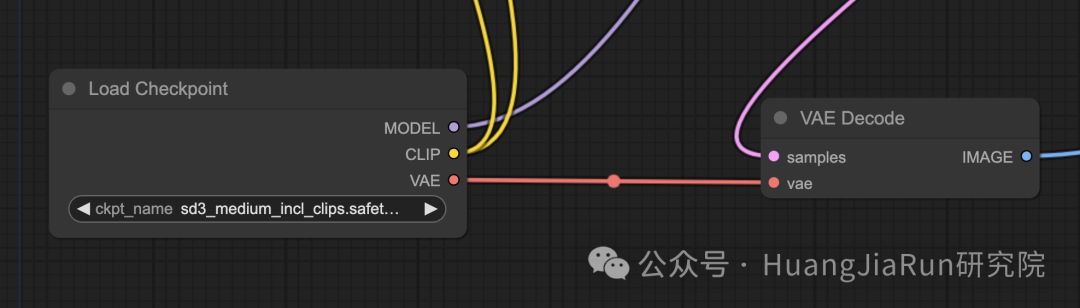
在界面中我们能看到 Load Checkpoint 节点的 VAE 属性就直接连接到了 VAE 节点。所以,这里的 VAE 节点其实就是上文中所提到的负责在像素空间和潜在空间之间转换图像的 VAE。
在此不再赘述。
KSampler 节点
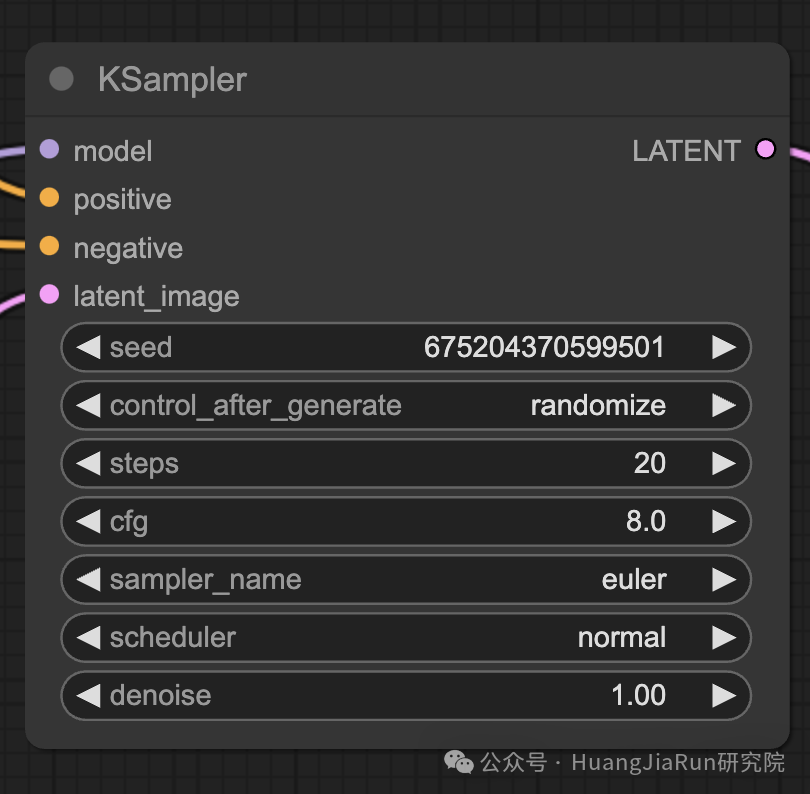
在 ComfyUI 中,生图过程的核心节点就是 KSampler 节点。它负责在潜在空间中对随机图像进行去噪,让生成的图像符合我们提供的提示语。
KSampler 使用的是一种称为反向扩散的技术,可以迭代地去除噪声,并根据 CLIP 向量嵌入添加有意义的细节。
反向扩散技术(Reverse Diffusion ) 就是从随机噪声中通过逐步去噪的方式生成图像的过程。模型利用这个技术,可以通过理解和还原图像的特征,将随机噪声转化为清晰、符合提示语的图像。
KSampler 节点提供了多个参数,让我们可以微调图像的生成过程:
Seed
Seed 值控制了初始噪声和最终图像的构图。设置特定的 Seed 值,我们可以获得可重复的结果,可以保持多次生成的一致性。
Control_after_generate
这个参数决定了每次生成后 Seed 值的变化方式,可以设置为随机化(每次运行生成新的随机 Seed)、递增、递减或者固定不变。
Step
采样步数决定了优化过程的强度。如果设置步数较大,则会产生更少的伪影和更精细的图像,但也会增加生成时间。
Sampler_name
这个参数用于选择 KSampler 所使用的特定采样算法。不同的采样算法可能会产生略有不同的结果,且生成速度也会有所不同。
Scheduler
这个参数用于控制在去噪过程中的每一步中噪声水平的变化速率,它决定了从潜在表示中去除噪声的速度。
Denoise
这个参数用于设置去噪过程应消除的初始噪声量。值为 1 表示去除所有噪声,从而生成干净且细节丰富的图像。
通过调整这些参数,我们可以微调图像的生成过程,从而获得理想的图像。
至此,我花了大量篇幅向你介绍了 ComfyUI 中的所有节点以及其对应的功能,希望到目前为止能够帮助你对 ComfyUI 有一个较为全面的认知和理解。
接下来我将继续介绍 ComfyUI 的图生图工作流。
ComfyUI 工作流:图生图
要在 ComfyUI 中使用图生图的工作流,我们需要先创建一个上传图像的节点,也就是 Load Image 节点。
在画布空白处点击右键,依次选择 Add Node > image > Load Image 就可以创建一个 Load Image 节点。
也可以直接双击空白处然后输入
Load Image搜索即可。
然后,还需要创建一个 VAE Encode 节点,同时删除 Empty Latent Image 节点。
依然是在画布空白处点击右键,依次选择 Add Node > latent > VAE Encode 就可以创建一个 VAE Encode 节点。
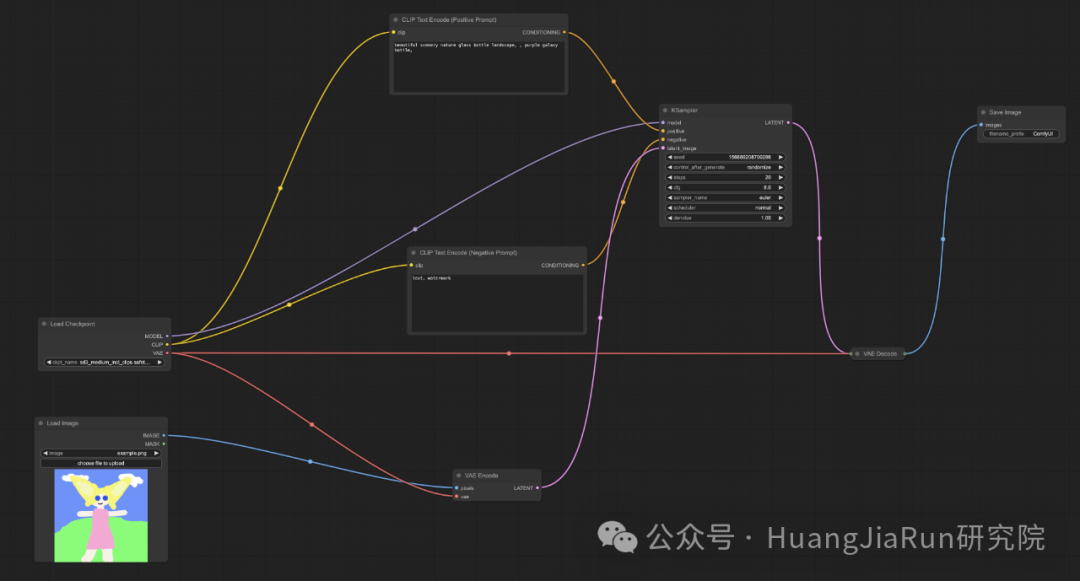
随后,将 Load Checkpoint 节点的 VAE 属性连接到 VAE Encode 节点的 vae 属性,将 Load Image 节点的 IMAGE 属性连接到 VAE Encode 节点的 pixels 属性,最后,将 VAE Encode 节点的 LATENT 属性连接到 KSampler 节点的 latent_image 属性即可。
具体可以参考下图。
这里我给出的例子是,将一张实拍的美食图转换为动漫风格,当然由于并没有进行微调,所以效果目前还只能算是将就。

输入图像

输出图像
具体的参数设置可以参考下表:
| 参数 | 建议设置 |
|---|---|
| Prompt | “anime style, vibrant colors, clean lines” |
| Denoise | 0.7 |
| Steps | 20 - 40 |
| Sampler_name | euler |
| 分辨率 | 768x768 |
注意,在图生图的工作流中,输入图像尽量保持与输出图像的分辨率一致,也不要使用过高的分辨率,直接使用对应模型的默认分辨率(参考下一章节)即可,过高的分辨率在生成图像的时候有可能会报错。
Stable Diffusion 各模型对比
截至 2024 年 9 月,Stable Diffusion 已经发展出多个主要版本,包括 v1、v2、v3 和 SDXL。每个版本都有独特的改进与变化,具体对比可以参考下表:
|
| v1 | v2 | v3 | SDXL |
| — | — | — | — | — |
| 发布时间 | 2022 年 8 月 | 2022 年 11 月 | 2024 年 5 月 | 2023 年 7 月 |
| 默认分辨率 | 512 * 512 | 768 * 768 | 1024 * 1024 | 1024 * 1024+ |
| 文本编码器 | CLIP | OpenCLIP | 最新版 OpenCLIP | 升级版多模态 CLIP |
| 模型能力 | 基础图像生成 | 更准确、更丰富细节 | 高细节、多模态输入 | 高分辨率、多功能性 |
| 训练数据 | LAION-5B | 更大多样化数据集 | 更多高质量数据集 | 超大规模、多样化 |
| 特色 | 基础框架 | 提升细节与安全性 | 更真实、更自然 | 最先进、高分辨率 |
相对于目前常见的 2k,4k 甚至 8k 分辨率来说,目前 Stable Diffusion 的分辨率可能不见得有多高,但是在生成式 AI 领域,这样的分辨率已经具有一定的代表性了,它牵涉到了生成图像的复杂性、速度和计算资源等多方面因素。
默认的分辨率已经能表现相当多的细节,特别是对许多艺术创作、插画、头像等用途来说,这个分辨率足以表现丰富的视觉元素。而且,由于 Stable Diffusion 是生成式模型,可以通过后续处理(如放大、补细节)来获得更高的分辨率。
ComfyUI Inpainting
相对于文生图和图生图工作流,我们可以来看看更复杂的工作流,也就是修复画作(Inpainting)。
Inpainting 可以用于替换或编辑图像中的特定区域,比如去除缺陷和伪影,甚至用全新的内容替换某个区域,它依赖于遮罩来确定图像中需要填充的区域。
我们可以直接延用上一步图生图中的工作流,然后按照下面的步骤来操作:
-
1. 在
Load Image节点中上传想要修复的图像,右键单击选择Open in MaskEditor; -
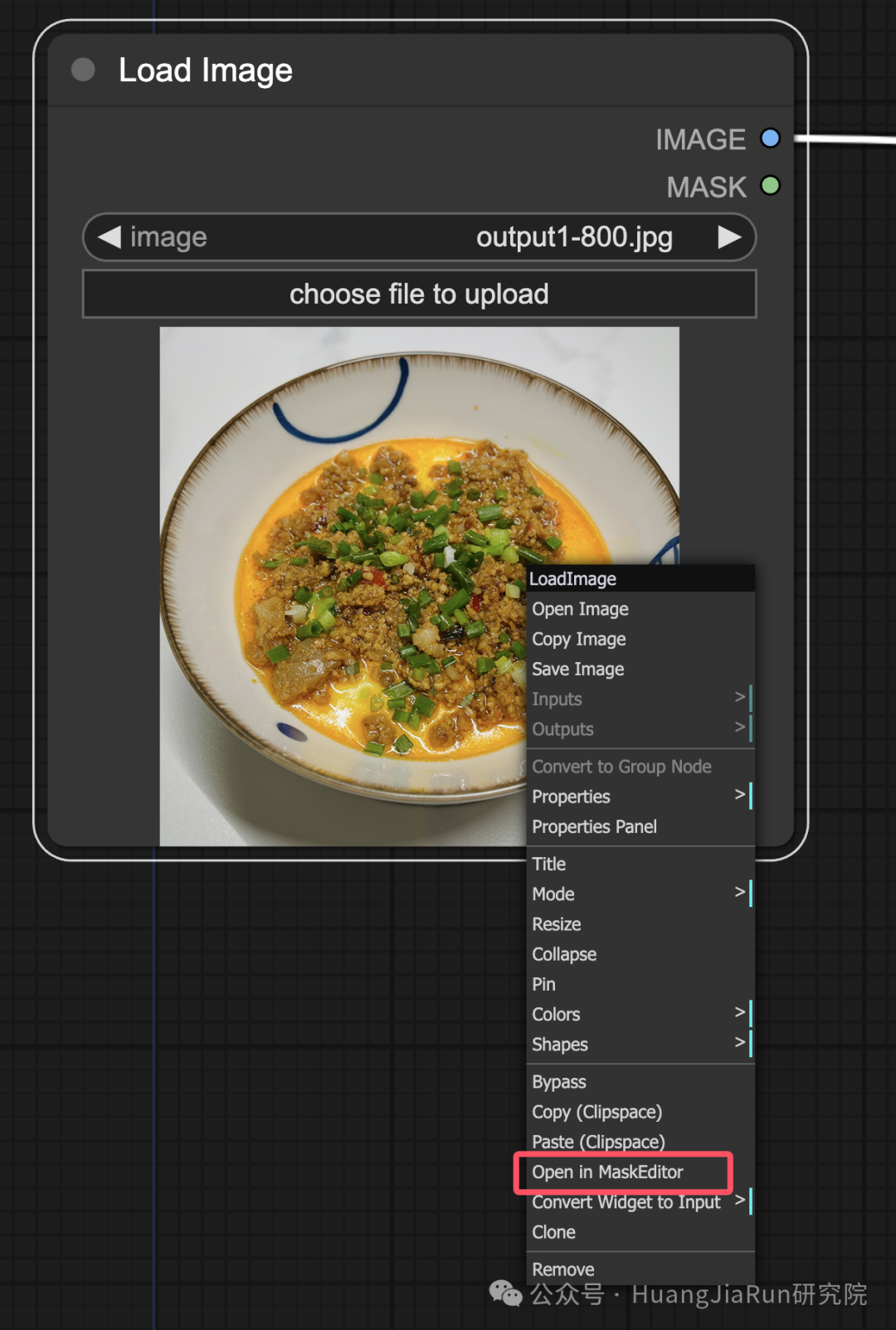
-
2. 在图像上对想要重新生成的区域设置遮罩,也就是用鼠标画阴影;
-

-
3. 随后点击
Save to node即可; -
4. 双击出现搜索框,输入
Set Latent Noise Mask选择创建一个节点; -
5. 重新创建连接:
-
1. 将
Load Image节点的MASK属性连接到Set Latent Noise Mask节点的mask属性; -
2. 同时,修改
VAE节点的LATENT连接到Set Latent Noise Mask节点的samples属性; -
3. 将
Set Latent Noise Mask节点的LATENT属性连接到KSampler节点的latent_image属性; -
6. 定义修复过程,也就是在
CLIP Text Encode节点中输入提示语信息来引导修复画作的方向; -
7. 设置
denoise参数,比如我们设置0.6; -
8. 最后点击
Queue Prompt即可。
具体连接可参考下图。


ComfyUI Outpainting
Outpainting 是一种将图像扩展到其原始边界之外的技术,可以让我们在保留原始图像的同时,添加、替换或修改其中的视觉元素。
基于 Inpainting 的工作流,我们需要对其修改一下,然后可以按照以下的步骤来在 ComfyUI 中使用 Outpainting。
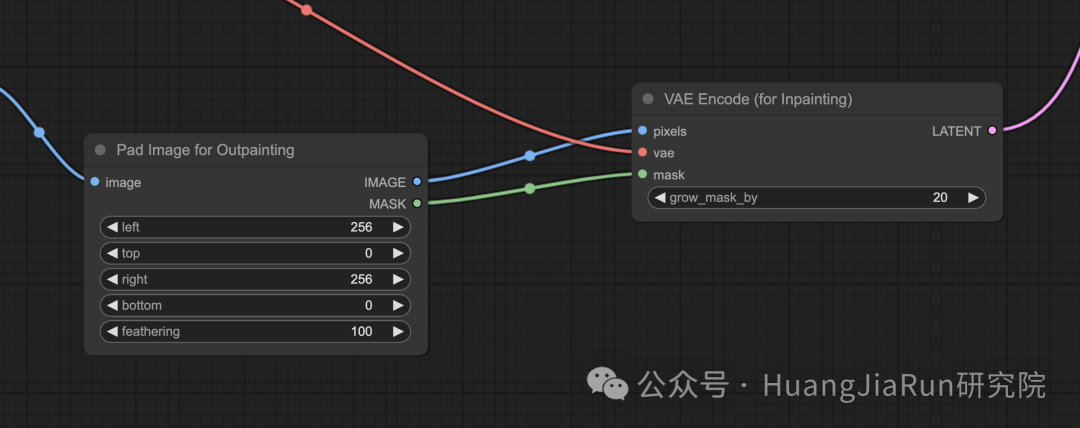
-
1. 在工作流中添加
Pad Image for Outpainting节点和VAE Encode(for Inpainting)节点,删除Set Latent Noise Mask和VAE Encode节点; -
2. 重新创建连接:
-
1. 将
Load Checkpoint节点的VAE属性连接到VAE Encode(for Inpainting)节点的vae属性; -
2. 将
Load Image节点的IMAGE属性连接到Pad Image for Outpainting节点的image属性; -
3. 将
Pad Image for Outpainting节点的IMAGE属性连接到VAE Encode(for Inpainting)节点的pixels属性; -
4. 将
Pad Image for Outpainting节点的MASK属性连接到VAE Encode(for Inpainting)节点的mask属性; -
5. 将
VAE Encode(for Inpainting)节点的LATENT属性连接到KSampler节点的latent_image属性; -
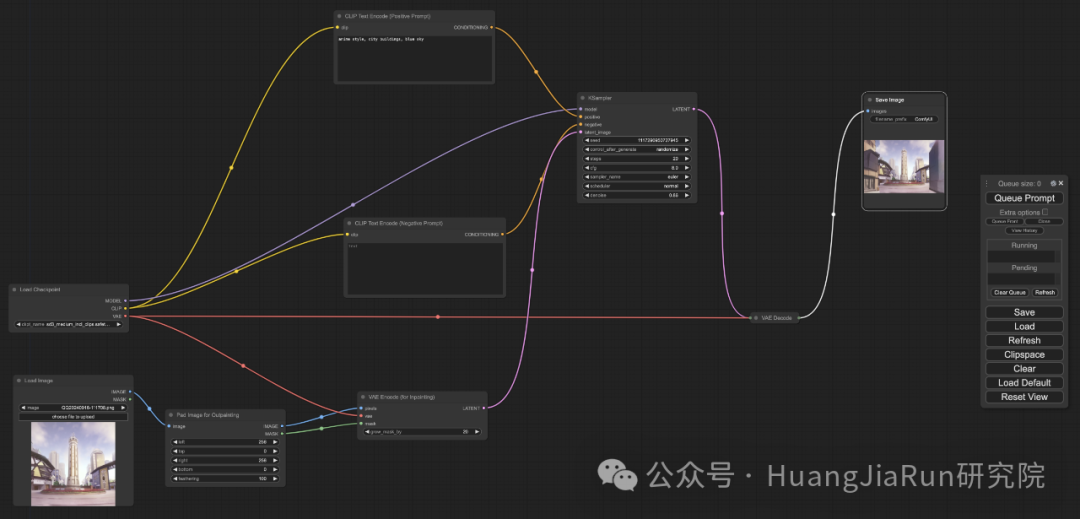
Pad Image for Outpainting节点配置:
-
lefttoprightbottom分别表示每个方向上扩展的像素数;
-
feathering:调整原始图像和扩展区域之间的过度平滑度;
-
4. 在
CLIP Text Encode节点配置提示语; -
5. 微调
VAE Encode (for Inpainting)节点,可以通过调整grow_mask_by参数来控制 Outpainting 的蒙版大小,这里推荐设置大于 10 的数值; -
6. 点击
Queue Prompt即可生成图像。
具体连接和参数配置可以参考下图。

输入图像

输出图像
Outpainting 工作流也是一个比较复杂的工作流,需要多次微调可能才会得到理想的效果。
ComfyUI Upscale
Upscale,也就是图像放大
在 ComfyUI 里,有两种主要的方式:
-
- 像素放大(Upscale Pixel):直接对可见图像进行放大;
-
- 潜在空间放大(Upscale Latent)
像素放大(Upscale Pixel)
对于像素放大,也有两种方式:
-
• 使用算法来放大图像,这种方式速度快,但是效果可能没有模型好
-
• 使用模型来放大图像,这种方式的效果可能会更好,但是速度会更慢
使用算法放大图像
如果要在 ComfyUI 中使用算法放大图像,则需要添加一个 Upscale Image By 节点,具体的连接方式和设置可参考下图:
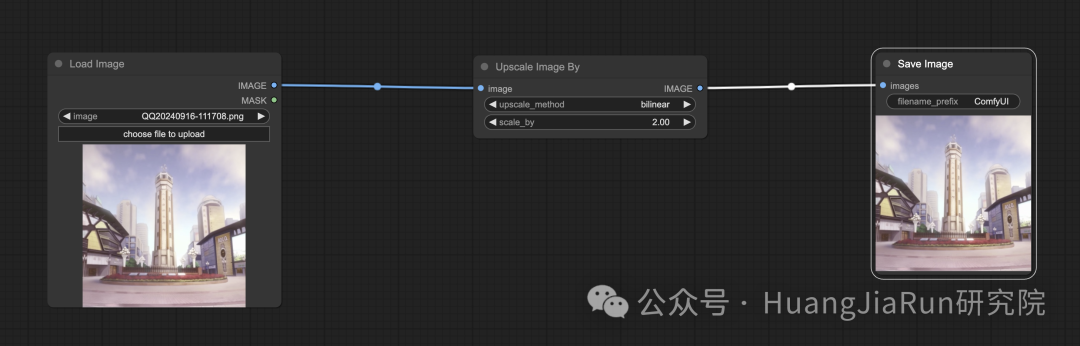
其中,upscale_method 指的就是算法,而 scale_by 指的就是放大的倍率,我这里设置的是 2,也就是放大两倍。
我的原始图像大小为 998 * 998,放大后的图像分辨率为 1996 * 1996。

使用模型放大图像
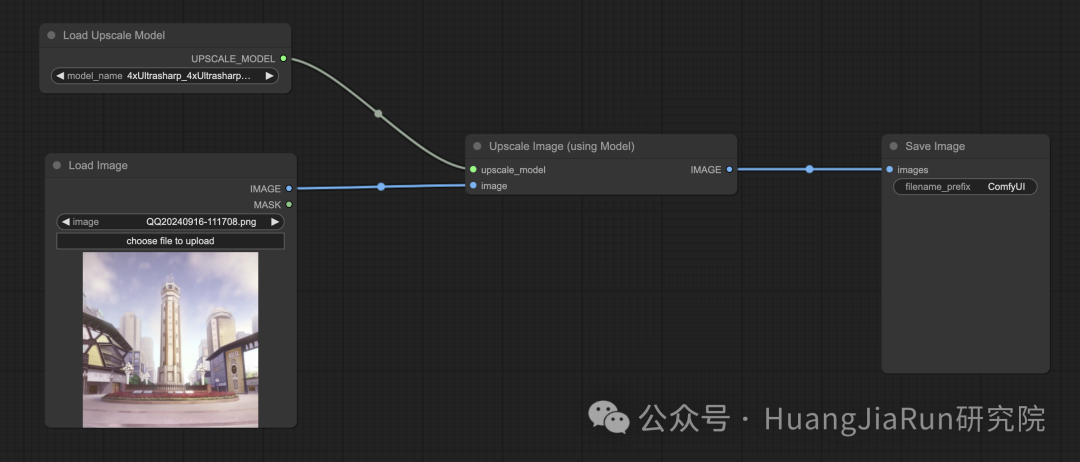
在本文中,我采用的 Upscale 模型是 4x-Ultrasharp,可以在此处下载并使用:https://civitai.com/models/116225/4x-ultrasharp。
下载之后,可以放到 ComfyUI 安装目录的 models/upscale_models 目录下。
要使用模型放大图像,就需要添加 Load Upscale Model 和 Upscale Image (using Model) 节点,具体连接方式可参考下图:
潜在空间放大(Upscale Latent)
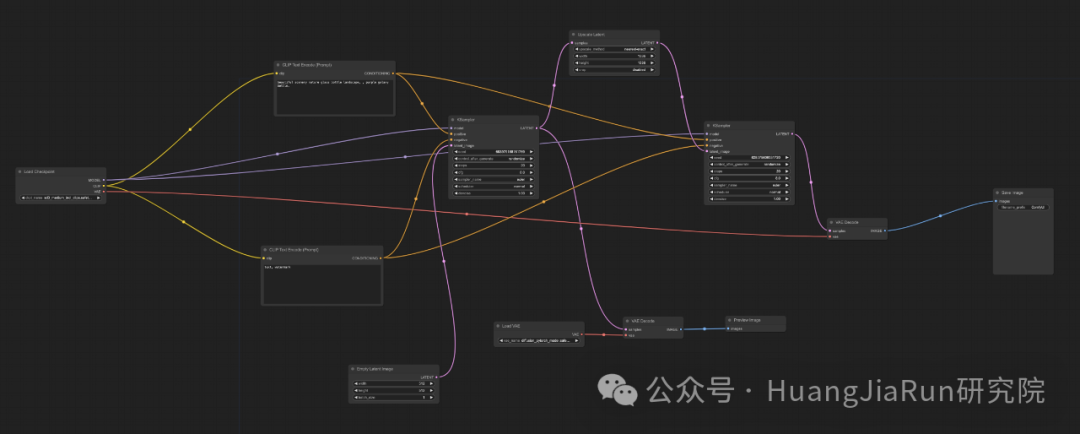
潜在空间放大也称为 Hi-res Latent Fix Upscale。
潜在空间放大的工作流比较复杂,但是简化理解就是,通过文生图的工作流拿到图像之后再对图像进行放大,这个过程直接在潜在空间中进行。
这里还涉及下载 VAE Model,比如可以使用:https://huggingface.co/stabilityai/sd-vae-ft-mse。下载完成之后放入 ComfyUI 的安装目录下的 models/vae 目录中即可。
具体流程可参考下图或者直接加载我给的工作流。

像素放大 vs. 潜在空间放大
这两种放大方式的区别如下:
-
• 像素放大:仅对图像进行放大,不会添加新的信息。生成速度相对来说比较快,但可能出现模糊效果,缺乏细节。
-
• 潜在空间放大:不仅放大了图像,还改变了部分原始图像信息,丰富了细节。可能与原始图像有偏差,生成速度相对较慢。
ComfyUI Manager
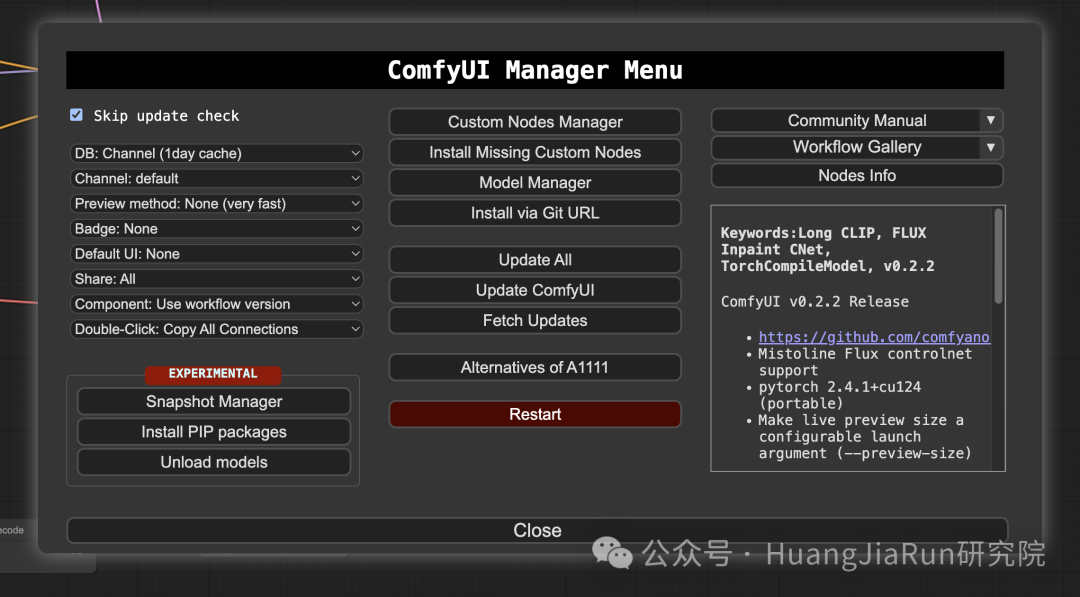
ComfyUI Manager 是一个提升 ComfyUI 可用性的扩展。它提供诸如安装、移除、禁用和启用各种 ComfyUI 自定义节点的功能。此外,ComfyUI Manager 还提供了一个集成中心和便捷功能,让我们能够在 ComfyUI 内轻松访问各种信息。
什么是自定义节点?
由于 ComfyUI 基于节点架构运作,其中界面元素被表示为相互连接的节点。每个节点都封装了特定的功能或行为,从而实现模块化和可扩展的界面开发。为了扩展 ComfyUI 的功能,开发者可以根据项目需求创建自定义节点。
在这里可以查看到所有的节点信息:https://ltdrdata.github.io/
安装
关于 ComfyUI Manager 的安装,可直接参考:https://github.com/ltdrdata/ComfyUI-Manager。
安装好了之后,重启 ComfyUI,就可以看到界面多了一个 Manager 按钮,点击就会出现下面这样的窗口。
关于自定义节点的使用示例,我将会结合下一章节来一起讲解。
ComfyUI Embeddings
这里的 Embeddings 又称为文本反演(Textual Inversion),其实和向量嵌入(Vector Embeddings) 本质上是相同的概念。在 ComfyUI 中,Embeddings 也是一种向量表示,可以用来捕捉和存储特定风格、概念或者视觉特征的信息。
当我们在生成图像的时候使用这些 Embeddings,模型可以根据这些特征来调整图像的生成过程,产生特定的视觉效果。
要在 ComfyUI 中使用 Embeddings,只需要在提示语的输入框里输入以下这样的语法即可:
embedding: [Embedding 名称]
比如我们输入:
embedding: Disney
那么,ComfyUI 会到安装目录的 models/embeddings 目录下寻找名为 Disney 的 Embedding 文文件,如果找到了,就会把对应的视觉风格应用到图像上。
可以直接到 https://civitai.com/ 网站上搜索喜欢的 Embedding 模型。
Embedding 名称自动补全
如果有多个 Embeddings,在输入的时候就不太方便了,所以,这时候就可以通过自定义节点来提高我们的输入效率。
点击 Manager 打开 ComfyUI Manager 窗口,在窗口上点击 Custom Nodes Manager,然后搜索 ComfyUI-Custom-Scripts,点击 Install 安装后重启 ComfyUI 即可。
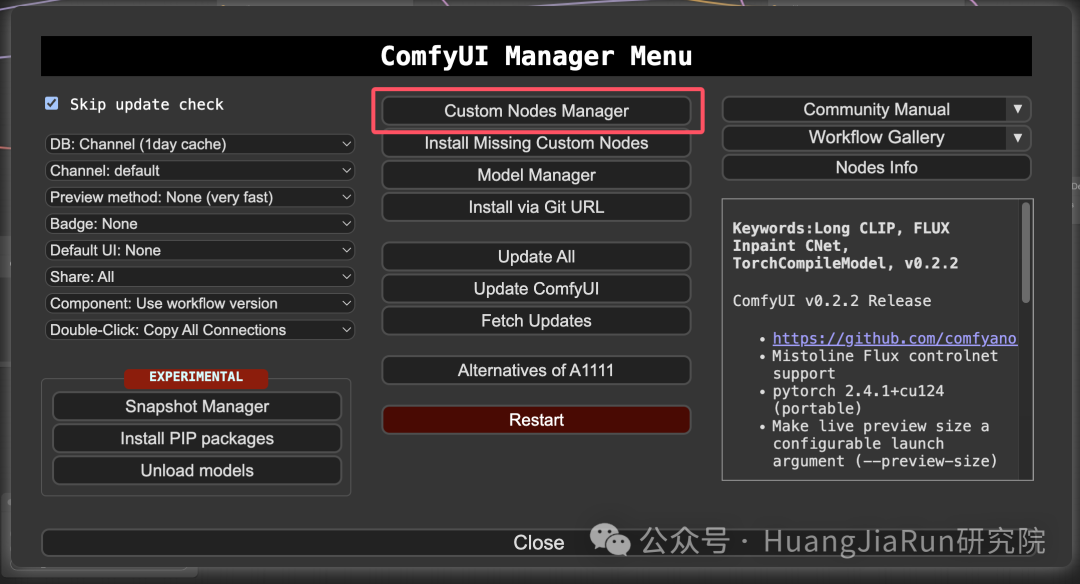

可以看到当我再次输入 embedding 的时候,下方就会有提示了。由于我目前只放置了一个 Embedding 文件,所以提示列表中也只有一个。
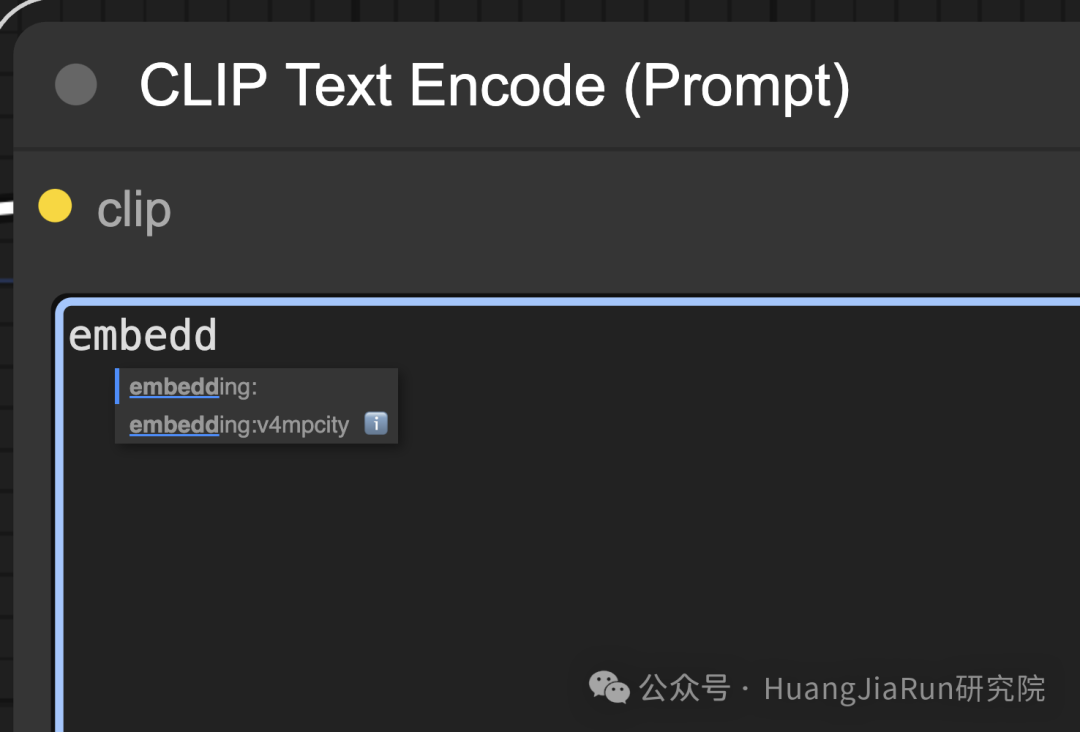
Embedding 权重
本质上来说,Embedding 也是关键词,所以也可以像调整提示语中的普通关键词那样来针对 Embedding 调整权重,只需要输入下面这样的语法即可:
(embedding: v4mpcity:1.2)

ComfyUI LoRA
LoRA(Low-rank Adaptation),称为低秩适应,可以用来修改和微调 Load Checkpoint 模型。
它本身是一个小型模型文件,常见的用例包括为模型添加特定风格的生成能力,或者更好地生成某些特定主题或动作。多个 LoRA 可以连接在一起来进一步调整模型。
LoRA 只会修改 MODEL 和 CLIP 组件,不会影响 VAE,所以 LoRA 不会改变图像的整体结构。
如何使用
要在 ComfyUI 中使用 LoRA,我们需要新添加一个 Load LoRA 节点,连接方式如下图所示。
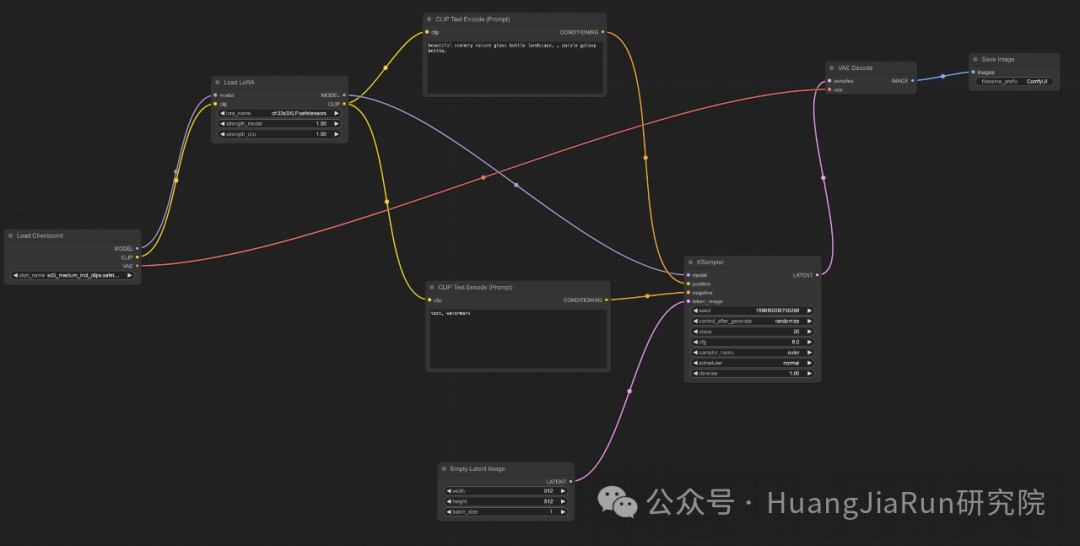

LoRA 生成效果示例
同时,需要下载对应的 LoRA 模型,也可以直接前往 https://civitai.com/ 网站上下载。
多个 LoRA 的使用方式与单个的类似,只需要按照顺序连接起来即可。
总结
当你阅读到这里的时候,希望你已经按照文中的实践操作完成了这一份入门指南。
本文涵盖了 ComfyUI 的基础操作、工作机制以及部分高级操作。说实话,要使用一篇文章的篇幅来将 ComfyUI 讲解全面基本上是不可能的,这里面涉及的每一个概念都值得用一篇单独的文章来细化讲解。
所以,我在这里也会附上一些相关资料,希望能够对你有所帮助。
-
• 线上可视化教程:https://comfyanonymous.github.io/ComfyUI_tutorial_vn/
-
• ComfyUI 快捷键:https://docs.comfy.org/tips/shortcuts
-
• 本文所有工作流均可以在我的 GitHub 上查看和下载:https://github.com/Huangjiarun/ai-application-demos/tree/main/ComfyUI-workflows
-
• Embedding、VAE、LoRA 等下载:https://civitai.com/
-
• 模型下载:https://huggingface.co/
为了帮助大家更好地掌握 ComfyUI,我在去年花了几个月的时间,撰写并录制了一套ComfyUI的基础教程,共六篇。这套教程详细介绍了选择ComfyUI的理由、其优缺点、下载安装方法、模型与插件的安装、工作流节点和底层逻辑详解、遮罩修改重绘/Inpenting模块以及SDXL工作流手把手搭建。
由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取
一、ComfyUI配置指南
- 报错指南
- 环境配置
- 脚本更新
- 后记
- …
二、ComfyUI基础入门
- 软件安装篇
- 插件安装篇
- …
三、 ComfyUI工作流节点/底层逻辑详解
- ComfyUI 基础概念理解
- Stable diffusion 工作原理
- 工作流底层逻辑
- 必备插件补全
- …
四、ComfyUI节点技巧进阶/多模型串联
- 节点进阶详解
- 提词技巧精通
- 多模型节点串联
- …
五、ComfyUI遮罩修改重绘/Inpenting模块详解
- 图像分辨率
- 姿势
- …

六、ComfyUI超实用SDXL工作流手把手搭建
- Refined模型
- SDXL风格化提示词
- SDXL工作流搭建
- …

由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐

 40
40 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)