Batch Normalization和Layer Normalization和Group normalization
批量规范化和层规范化在神经网络中的每个批次或每个层上进行规范化,而GroupNorm将特征分成多个组,并在每个组内进行规范化。这种规范化技术使得每个组内的特征具有相同的均值和方差,从而减少了特征之间的相关性。通常,组的大小是一个超参数,可以手动设置或自动确定。相对于批量规范化,GroupNorm的一个优势是它对批次大小的依赖性较小。这使得GroupNorm在训练小批量样本或具有不同批次大小的情况下
文章目录
前言
批量规范化和层规范化在神经网络中的每个批次或每个层上进行规范化,而GroupNorm将特征分成多个组,并在每个组内进行规范化。这种规范化技术使得每个组内的特征具有相同的均值和方差,从而减少了特征之间的相关性。通常,组的大小是一个超参数,可以手动设置或自动确定。
相对于批量规范化,GroupNorm的一个优势是它对批次大小的依赖性较小。这使得GroupNorm在训练小批量样本或具有不同批次大小的情况下更加稳定。另外,GroupNorm还可以应用于一维、二维和三维的输入,适用于不同类型的神经网络架构。
GroupNorm的一种变体是分组卷积(Group Convolution),它将输入通道分成多个组,并在每个组内进行卷积操作。这种结构可以减少计算量,并提高模型的效率。

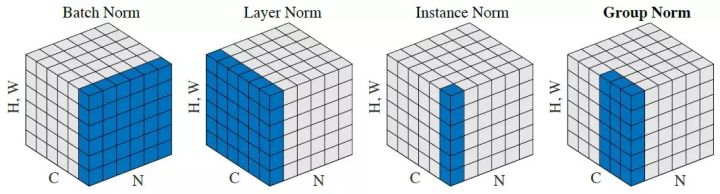
- BatchNorm:batch方向做归一化,算N* H*W的均值
- LayerNorm:channel方向做归一化,算C* H* W的均值
- InstanceNorm:一个channel内做归一化,算H*W的均值
- GroupNorm:将channel方向分group,然后每个group内做归一化,算(C//G) * H * W的均值

一、Group normalization
Group normalization(GroupNorm)是深度学习中用于规范化神经网络激活的一种技术。它是一种替代批量规范化(BatchNorm)和层规范化(LayerNorm)等其他规范化技术的方法。
import torch
import torch.nn as nn
class GroupNorm(nn.Module):
def __init__(self, num_groups, num_channels, eps=1e-5):
super(GroupNorm, self).__init__()
self.num_groups = num_groups
self.num_channels = num_channels
self.eps = eps
self.weight = nn.Parameter(torch.ones(1, num_channels, 1, 1))
self.bias = nn.Parameter(torch.zeros(1, num_channels, 1, 1))
def forward(self, x):
batch_size, num_channels, height, width = x.size()
# 将特征重塑成 (batch_size * num_groups, num_channels // num_groups, height, width)
x = x.view(batch_size, self.num_groups, -1, height, width)
# 计算每个组内的均值和方差
mean = x.mean(dim=(2, 3, 4), keepdim=True)
var = x.var(dim=(2, 3, 4), keepdim=True)
# 规范化
x = (x - mean) / torch.sqrt(var + self.eps)
# 重塑特征
x = x.view(batch_size, num_channels, height, width)
# 应用缩放和平移
x = x * self.weight + self.bias
return x
# 使用示例
group_norm = GroupNorm(num_groups=4, num_channels=64)
inputs = torch.randn(32, 64, 32, 32)
outputs = group_norm(inputs)
print(outputs.shape)
二、批量规范化(Batch Normalization)
BatchNorm的基本思想是对每个特征通道在一个小批次(即一个批次中的多个样本)的数据上进行规范化,使得其均值接近于0,方差接近于1。这种规范化可以有助于加速神经网络的训练,并提高模型的泛化能力。

具体而言,对于给定的一个特征通道,BatchNorm的计算过程如下:
- 对于一个小批次中的输入数据,计算该特征通道上的均值和方差。
- 使用计算得到的均值和方差对该特征通道上的数据进行规范化,使得其均值为0,方差为1。
- 对规范化后的数据进行缩放和平移操作,使用可学习的参数进行调整,以恢复模型对数据的表示能力。
通过在训练过程中对每个小批次的数据进行规范化,BatchNorm有助于解决梯度消失和梯度爆炸等问题,从而加速模型的收敛速度。此外,BatchNorm还具有一定的正则化效果,可以减少模型对输入数据的依赖性,增强模型的鲁棒性。
import torch
import torch.nn as nn
class BatchNorm(nn.Module):
def __init__(self, num_features, eps=1e-5, momentum=0.1):
super(BatchNorm, self).__init__()
self.num_features = num_features
self.eps = eps
self.momentum = momentum
# 可学习的参数
self.weight = nn.Parameter(torch.ones(num_features))
self.bias = nn.Parameter(torch.zeros(num_features))
# 移动平均的均值和方差
self.running_mean = torch.zeros(num_features)
self.running_var = torch.ones(num_features)
def forward(self, x):
if self.training:
# 在训练模式下,计算当前Batch的均值和方差
mean = x.mean(dim=(0, 2, 3), keepdim=True)
var = x.var(dim=(0, 2, 3), keepdim=True)
# 更新移动平均的均值和方差
self.running_mean = (1 - self.momentum) * self.running_mean + self.momentum * mean.squeeze()
self.running_var = (1 - self.momentum) * self.running_var + self.momentum * var.squeeze()
else:
# 在推理模式下,使用移动平均的均值和方差
mean = self.running_mean.unsqueeze(0).unsqueeze(2).unsqueeze(3)
var = self.running_var.unsqueeze(0).unsqueeze(2).unsqueeze(3)
# 归一化
x = (x - mean) / torch.sqrt(var + self.eps)
# 缩放和平移
x = x * self.weight.unsqueeze(0).unsqueeze(2).unsqueeze(3) + self.bias.unsqueeze(0).unsqueeze(2).unsqueeze(3)
return x
batch_norm = BatchNorm(num_features=64)
inputs = torch.randn(32, 64, 32, 32)
outputs = batch_norm(inputs)
print(outputs.shape)
三、层规范化(Layer Normalization)
与批量规范化相比,层规范化更适用于对序列数据或小批次样本进行规范化,例如自然语言处理任务中的文本序列。它在每个样本的特征维度上进行规范化,使得每个样本在特征维度上具有相似的分布。

层规范化的计算过程如下:
对于每个样本,计算该样本在特征维度上的均值和方差。
- 使用计算得到的均值和方差对该样本的特征进行规范化,使得其均值为0,方差为1。
- 对规范化后的特征进行缩放和平移操作,使用可学习的参数进行调整,以恢复模型对数据的表示能力。
import torch
import torch.nn as nn
class LayerNorm(nn.Module):
def __init__(self, num_features, eps=1e-5):
super(LayerNorm, self).__init__()
self.num_features = num_features
self.eps = eps
# 可学习的参数
self.weight = nn.Parameter(torch.ones(num_features))
self.bias = nn.Parameter(torch.zeros(num_features))
def forward(self, x):
# 计算输入张量的均值和方差
mean = x.mean(dim=(1, 2, 3), keepdim=True)
var = x.var(dim=(1, 2, 3), keepdim=True)
# 归一化
x = (x - mean) / torch.sqrt(var + self.eps)
# 缩放和平移
x = x * self.weight.unsqueeze(0).unsqueeze(2).unsqueeze(3) + self.bias.unsqueeze(0).unsqueeze(2).unsqueeze(3)
return x
# 使用示例
layer_norm = LayerNorm(num_features=64)
inputs = torch.randn(32, 64, 32, 32)
outputs = layer_norm(inputs)
print(outputs.shape)
四、Layer Normalization和Batch Normalization作用
Layer Normalization (LN):
LN是一种对神经网络每一层的特征进行归一化处理的方法。与BN不同,LN是对每个样本的特征进行归一化,而不是对小批量样本进行归一化。LN的作用包括:
- 独立于批次大小:LN对每个样本独立操作,不受批次大小的影响,因此适用于小批量训练或单个样本推断的情况。
- 保留样本间的信息:LN保留了样本间的相关信息,因为它是对每个样本的特征进行归一化,有助于保持样本间的差异性。
- 适用于循环神经网络:LN在循环神经网络中的应用更为常见,因其对每个时间步的样本进行归一化,有助于缓解梯度消失和梯度爆炸问题。
Batch Normalization (BN):
BN是一种对神经网络每一层的输入进行归一化处理的方法。它通过对每个小批量训练样本的特征进行归一化,使得特征在每个小批量上具有相似的分布。BN的作用有以下几个方面:
-
加速训练收敛:BN可以减少内部协变量偏移(Internal Covariate Shift),使得网络在训练过程中更稳定,加速收敛速度。
-
提高泛化能力:通过规范化特征分布,BN有助于减少模型对于特定数据分布的依赖,提高泛化能力。
-
正则化效果:BN在一定程度上具有正则化的作用,可以减少模型的过拟合。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 52
52 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)