Hive的面试题
目录1.请谈一下hive的特点?2.Hive底层与数据库存交互原理?3.Hive内部表和外部表的区别?4.Hive导入数据的五种方式是什么?举例说明5.hive与传统关系型数据库的区别6.Hive中创建表有哪几种方式,其区别是什么?7.Hive的窗口函数有哪些8.row_number(),rank()和dense_rank()的区别9.Hive如何实现分区10.Hive的两张表关联,使用MapRe
目录
8.row_number(),rank()和dense_rank()的区别
10.Hive的两张表关联,使用MapReduce怎么实现?
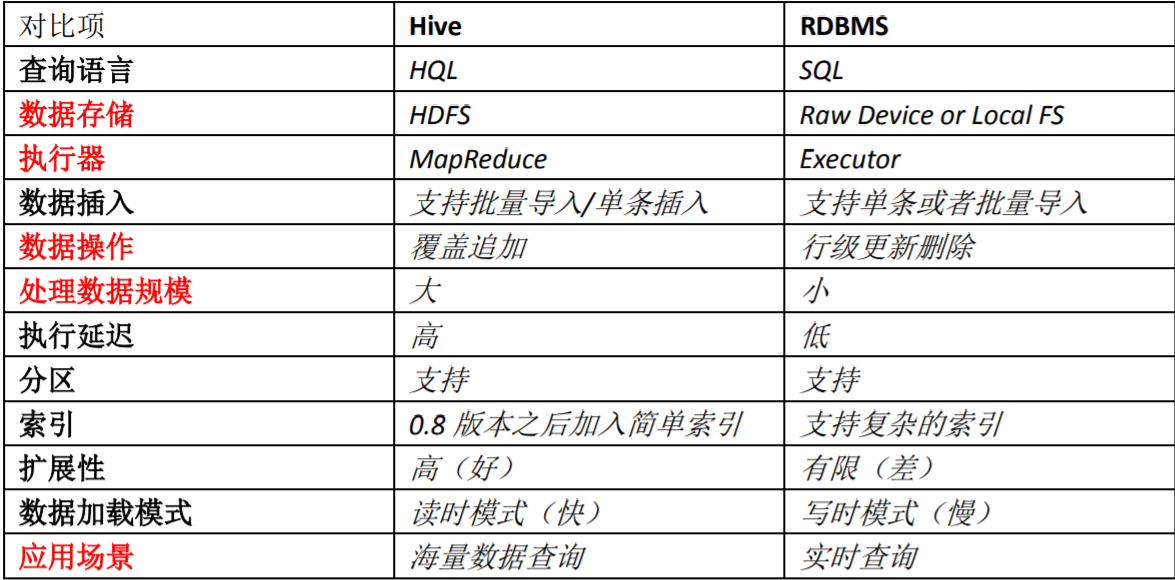
11.请说明hive中 Sort By,Order By,Cluster By,Distrbute By各代表什么意思?
12.写出Hive中split、coalesce及collect_list函数的用法(可举例)?
18.Hive 中的压缩格式TextFile、SequenceFile、RCfile 、ORCfile各有什么区别?
1.请谈一下hive的特点?
答:hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为Mapreduce任务进行运行.其优点是学习成本低,可以通过类SQL语句快速实现简单MapReduce统计,不必开发专门MapReduce应用,十分适合数据仓库的统计分析,但是Hive不支持实时查询!
2.Hive底层与数据库存交互原理?
答案:由于Hive的元数据可能要面临不断地更新/修改和读取操作,所以它显然不适合使用Hadoop文件系统进行存储,目前Hive将元数据存储在RDBMS中,比如存储在MySQL,Derby中,元数据信息包括:存在的表/表的列/权限和更多的其他信息.
3.Hive内部表和外部表的区别?
答案:创建表时:创建内部表时,会将数据移动到数据仓库指向的路径;若创建外总表,仅记录数据所在的路径,不对数据的位置做任何改变.
删除表时:在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据.这样外部表相对来说更加安全些,数据组织也更灵活,方便共享源数据.
4.Hive导入数据的五种方式是什么?举例说明
答案:1. Load方式,可以从本地或HDFS上导入,本地是copy,HDFS是移动
本地:load data local inpath ‘/root/student.txt’ into table student;
HDFS:load data inpath ‘/user/hive/data/student.txt’ into table student;
2. Insert方式,往表里插入
insert into table student values(1,’zhanshan’);
3. As select方式,根据查询结果创建表并插入数据
create table if not exists stu1 as select id,name from student;
4. Location方式,创建表并指定数据的路径
create external if not exists stu2 like student location '/user/hive/warehouse/student/student.txt';
5. Import方式,先从hive上使用export导出在导入
import table stu3 from ‘/user/export/student’;
5.hive与传统关系型数据库的区别
由于HIVE采用了SQL查询语言HQL,因此很容易将hive理解为数据库。其实从结构上来看,hive和数据库除了拥有类似的查询语言,再无类似之处。

6. Hive中创建表有哪几种方式,其区别是什么?
内部表:删除时,删除的时表结构,数据不会没有
外部表:删除数据也就没了
7.Hive的窗口函数有哪些
在SQL处理中,窗口函数都是最后一步执行,仅位于order by之前
over():指定分析函数工作的数据窗口大小随行变化(跟在聚合函数 [wh2]后面,只对聚合函数有效)
current row 当前行
n preceding 往前n行数据
n following 往后n行数据
unbounded:
unbounded preceding 从前面开始 |————>
unbounded following 直到终点 ————>|
lag(col,n) 往前第n行数据
lead(col,n) 往后第n行数据
8.row_number(),rank()和dense_rank()的区别
都有对数据进行排序的功能
row_number():根据查询结果的顺序计算排序,多用于分页查询
rank():排序相同时序号重复,总序数不变
dense_rank():排序相同时序号重复时,总序数减少
9.Hive如何实现分区
建表:create table tablename(col1 string) partitioned by(col2 string);
添加分区:alter table tablename add partition(col2=’202101’);
删除分区:alter table tablename drop partition(col2=’202101’);
10.Hive的两张表关联,使用MapReduce怎么实现?
如果其中有一张表为小表,直接使用map端join的方式(map端加载小表)进行聚合。
如果两张都是大表,那么采用联合key,联合key的第一个组成部分是join on中的公共字段,第二部分是一个flag,0代表表A,1代表表B,由此让Reduce区分客户信息和订单信息;在Mapper中同时处理两张表的信息,将join on公共字段相同的数据划分到同一个分区中,进而传递到一个Reduce中,然后在Reduce中实现聚合。
11.请说明hive中 Sort By,Order By,Cluster By,Distrbute By各代表什么意思?
Order by:会对输入做全局排序,因此只有一个reducer(多个reducer无法保证全局有序)。只有一个reducer,会导致当输入规模较大时,需要较长的计算时间。
Sort by:不是全局排序,其在数据进入reducer前完成排序。1
Distribute by:按照指定的字段对数据进行划分输出到不同的reduce中。
Cluster by:除了具有 distribute by 的功能外还兼具 sort by 的功能。
12.写出Hive中split、coalesce及collect_list函数的用法(可举例)?
split将字符串转化为数组,即:split('a,b,c,d' , ',') ==> ["a","b","c","d"]。
coalesce(T v1, T v2, …) 返回参数中的第一个非空值;如果所有值都为 NULL,那么返回NULL。
collect_list列出该字段所有的值,不去重 => select collect_list(id) from table。
13.Hive有哪些方式保存元数据,各有哪些特点?
Hive支持三种不同的元存储服务器,分别为:内嵌式元存储服务器、本地元存储服务器、远程元存储服务器,每种存储方式使用不同的配置参数。
- 内嵌式元存储主要用于单元测试,在该模式下每次只有一个进程可以连接到元存储,Derby是内嵌式元存储的默认数据库。
- 在本地模式下,每个Hive客户端都会打开到数据存储的连接并在该连接上请求SQL查询。
- 在远程模式下,所有的Hive客户端都将打开一个到元数据服务器的连接,该服务器依次查询元数据,元数据服务器和客户端之间使用Thrift协议通信。
14.Hive的函数:UDF、UDAF、UDTF的区别?
- UDF:单行进入,单行输出
- UDAF:多行进入,单行输出
- UDTF:单行输入,多行输出
15.所有的Hive任务都会有MapReduce的执行吗?
不是,从Hive0.10.0版本开始,对于简单的不需要聚合的类似SELECT from
LIMIT n语句,不需要起MapReduce job,直接通过Fetch task获取数据。
16.说说对Hive桶表的理解?
- 桶表是对数据某个字段进行哈希取值,然后放到不同文件中存储。
- 数据加载到桶表时,会对字段取hash值,然后与桶的数量取模。把数据放到对应的文件中。物理上,每个桶就是表(或分区)目录里的一个文件,一个作业产生的桶(输出文件)和reduce任务个数相同。
- 桶表专门用于抽样查询,是很专业性的,不是日常用来存储数据的表,需要抽样查询时,才创建和使用桶表。
17.Hive本地模式
大多数的Hadoop Job是需要Hadoop提供的完整的可扩展性来处理大数据集的。不过,有时Hive的输入数据量是非常小的。在这种情况下,为查询触发执行任务时消耗可能会比实际job的执行时间要多的多。对于大多数这种情况,Hive可以通过本地模式在单台机器上处理所有的任务。对于小数据集,执行时间可以明显被缩短。
用户可以通过设置hive.exec.mode.local.auto的值为true,来让Hive在适当的时候自动启动这个优化。
18.Hive 中的压缩格式TextFile、SequenceFile、RCfile 、ORCfile各有什么区别?
1.TextFile
默认格式,存储方式为行存储,数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,压缩后的文件不支持split,Hive不会对数据进行切分,从而无法对数据进行并行操作。并且在反序列化过程中,必须逐个字符判断是不是分隔符和行结束符,因此反序列化开销会比SequenceFile高几十倍。
2、SequenceFile
SequenceFile是Hadoop API提供的一种二进制文件支持,存储方式为行存储,其具有使用方便、可分割、可压缩的特点。
SequenceFile支持三种压缩选择:NONE,RECORD,BLOCK。Record压缩率低,一般建议使用BLOCK压缩。
优势是文件和hadoop api中的MapFile是相互兼容的
3、RCFile
存储方式:数据按行分块,每块按列存储。结合了行存储和列存储的优点:
首先,RCFile 保证同一行的数据位于同一节点,因此元组重构的开销很低;
其次,像列存储一样,RCFile 能够利用列维度的数据压缩,并且能跳过不必要的列读取;
4、ORCFile
存储方式:数据按行分块 每块按照列存储。
压缩快、快速列存取。
效率比rcfile高,是rcfile的改良版本。
小结:
相比TEXTFILE和SEQUENCEFILE,RCFILE由于列式存储方式,数据加载时性能消耗较大,但是具有较好的压缩比和查询响应。
数据仓库的特点是一次写入、多次读取,因此,整体来看,RCFILE相比其余两种格式具有较明显的优势。
19.Hive表关联查询,如何解决数据倾斜的问题?
1)倾斜原因:map输出数据按key Hash的分配到reduce中,由于key分布不均匀、业务数据本身的特、建表时考虑不周、等原因造成的reduce 上的数据量差异过大。
(1)key分布不均匀;
(2)业务数据本身的特性;
(3)建表时考虑不周;
(4)某些SQL语句本身就有数据倾斜;
如何避免:对于key为空产生的数据倾斜,可以对其赋予一个随机值。
2)解决方案
(1)参数调节:
hive.map.aggr = true
hive.groupby.skewindata=true
有数据倾斜的时候进行负载均衡,当选项设定位true,生成的查询计划会有两个MR Job。第一个MR Job中,Map的输出结果集合会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的Group By Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MR Job再根据预处理的数据结果按照Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个Reduce中),最后完成最终的聚合操作。
(2)SQL 语句调节:
① 选用join key分布最均匀的表作为驱动表。做好列裁剪和filter操作,以达到两表做join 的时候,数据量相对变小的效果。
② 大小表Join:
使用map join让小的维度表(1000 条以下的记录条数)先进内存。在map端完成reduce。
③ 大表Join大表:
把空值的key变成一个字符串加上随机数,把倾斜的数据分到不同的reduce上,由于null 值关联不上,处理后并不影响最终结果。
④ count distinct大量相同特殊值:
count distinct 时,将值为空的情况单独处理,如果是计算count distinct,可以不用处理,直接过滤,在最后结果中加1。如果还有其他计算,需要进行group by,可以先将值为空的记录单独处理,再和其他计算结果进行union。
20.Fetch抓取
Fetch抓取是指,Hive中对某些情况的查询可以不必使用MapReduce计算。例如:SELECT * FROM employees;在这种情况下,Hive可以简单地读取employee对应的存储目录下的文件,然后输出查询结果到控制台。
在hive-default.xml.template文件中hive.fetch.task.conversion默认是more,老版本hive默认是minimal,该属性修改为more以后,在全局查找、字段查找、limit查找等都不走mapreduce。
21.小表、大表Join
将key相对分散,并且数据量小的表放在join的左边,这样可以有效减少内存溢出错误发生的几率;再进一步,可以使用Group让小的维度表(1000条以下的记录条数)先进内存。在map端完成reduce。
实际测试发现:新版的hive已经对小表JOIN大表和大表JOIN小表进行了优化。小表放在左边和右边已经没有明显区别。
22.大表Join大表
1)空KEY过滤 有时join超时是因为某些key对应的数据太多,而相同key对应的数据都会发送到相同的reducer上,从而导致内存不够。此时我们应该仔细分析这些异常的key,很多情况下,这些key对应的数据是异常数据,我们需要在SQL语句中进行过滤。例如key对应的字段为空。2)空key转换 有时虽然某个key为空对应的数据很多,但是相应的数据不是异常数据,必须要包含在join的结果中,此时我们可以表a中key为空的字段赋一个随机的值,使得数据随机均匀地分不到不同的reducer上。
23.Group By
默认情况下,Map阶段同一Key数据分发给一个reduce,当一个key数据过大时就倾斜了。 并不是所有的聚合操作都需要在Reduce端完成,很多聚合操作都可以先在Map端进行部分聚合,最后在Reduce端得出最终结果。
1)开启Map端聚合参数设置
(1)是否在Map端进行聚合,默认为True hive.map.aggr = true
(2)在Map端进行聚合操作的条目数目 hive.groupby.mapaggr.checkinterval = 100000 (3)有数据倾斜的时候进行负载均衡(默认是false) hive.groupby.skewindata = true 当选项设定为 true,生成的查询计划会有两个MR Job。第一个MR Job中,Map的输出结果会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的Group By Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MR Job再根据预处理的数据结果按照Group By Key分布到Reduce中(这个过程可以保证相同的Group By Key被分布到同一个Reduce中),最后完成最终的聚合操作。
24.Count(Distinct) 去重统计
数据量小的时候无所谓,数据量大的情况下,由于COUNT DISTINCT操作需要用一个Reduce Task来完成,这一个Reduce需要处理的数据量太大,就会导致整个Job很难完成,一般COUNT DISTINCT使用先GROUP BY再COUNT的方式替换
25.笛卡尔积
列处理:在SELECT中,只拿需要的列,如果有,尽量使用分区过滤,少用SELECT *。
行处理:在分区剪裁中,当使用外关联时,如果将副表的过滤条件写在Where后面,那么就会先全表关联,之后再过滤。
26.并行执行
Hive会将一个查询转化成一个或者多个阶段。这样的阶段可以是MapReduce阶段、抽样阶段、合并阶段、limit阶段。或者Hive执行过程中可能需要的其他阶段。默认情况下,Hive一次只会执行一个阶段。不过,某个特定的job可能包含众多的阶段,而这些阶段可能并非完全互相依赖的,也就是说有些阶段是可以并行执行的,这样可能使得整个job的执行时间缩短。不过,如果有更多的阶段可以并行执行,那么job可能就越快完成。
通过设置参数hive.exec.parallel值为true,就可以开启并发执行。不过,在共享集群中,需要注意下,如果job中并行阶段增多,那么集群利用率就会增加

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)