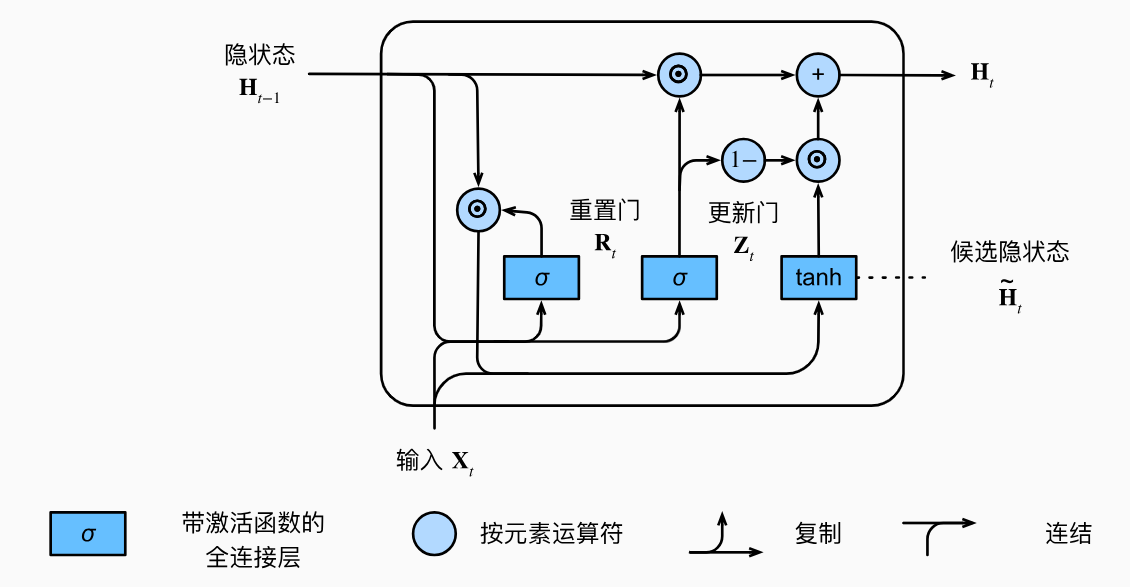
门控循环单元(GRU)
门控循环神经网络可以更好地捕获时间步距离很长的序列上的依赖关系。重置门有助于捕获序列中的短期依赖关系。更新门有助于捕获序列中的长期依赖关系。重置门打开时,门控循环单元包含基本循环神经网络;更新门打开时,门控循环单元可以跳过子序列。
概述
门控循环单元(Gated Recurrent Unit, GRU)由Junyoung Chung等人于2014年提出,原论文为《Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling》。GRU是循环神经网络(Recurrent Neural Network, RNN)的一种,和LSTM(Long-Short Term Memory)一样,也是为了解决长期记忆和反向传播中的梯度等问题而提出来的。其优势就在于,在有和LSTM相似的表现的情况下,比LSTM更简单,更容易训练或计算。
详解
重置门和更新门
我们首先介绍重置门(Reset Gate)和更新门(Update Gate)。所谓门就是一种控制单元,用来控制一个事物是有还是无。它们被设计成(0,1)区间中的向量来方便进行凸组合。所谓凸组合就是加权平均。
重置门用于控制前一个隐状态在当前时间步骤的计算中保留多少历史信息。重置门的输出接近于0表示较多地忽略前一个隐状态的信息,而接近于1表示较多地保留前一个隐状态的信息。
更新门用于控制当前时间步骤的候选隐状态(candidate hidden state)对最终的隐状态更新的贡献程度。更新门的输出接近于0表示较少地更新当前时间步骤的隐状态,而接近于1表示较多地更新当前时间步骤的隐状态。
这些门并不是人为指定的,而是机器通过当前时间步的输入和前一个隐状态进行学习得到的。下图描述了门控循环单元中的重置门和更新门的输入,输入是由当前时间步的输入和前一时间步的隐状态给出。两个门的输出是由使用sigmoid激活函数的两个全连接层给出。

图中,输入和隐状态分别通过两个不同的带激活函数的全连接层得到两个门的值。这两个门将在后面发挥它们的控制效果,现在先来看一下他们的数学表达。对于给定的时间步
t
t
t,假设输入是一个小批量
X
t
∈
R
n
×
d
\mathbf{X}_t\in\mathbb{R}^{n\times d}
Xt∈Rn×d(样本个数n,输入个数d), 上一个时间步的隐状态是
H
t
−
1
∈
R
n
×
h
\mathbf{H}_{t-1}\in\mathbb{R}^{n\times h}
Ht−1∈Rn×h(隐藏单元个数h)。那么,重置门
R
t
∈
R
n
×
h
\mathbf{R}_{t}\in\mathbb{R}^{n\times h}
Rt∈Rn×h和更新门
Z
t
∈
R
n
×
h
\mathbf{Z}_{t}\in\mathbb{R}^{n\times h}
Zt∈Rn×h的计算如下所示:
R
t
=
σ
(
X
t
W
x
r
+
H
t
−
1
W
h
r
+
b
r
)
,
Z
t
=
σ
(
X
t
W
x
z
+
H
t
−
1
W
h
z
+
b
z
)
,
\begin{gathered} \mathbf{R}_{t} =\sigma(\mathbf{X}_t\mathbf{W}_{xr}+\mathbf{H}_{t-1}\mathbf{W}_{hr}+\mathbf{b}_r), \\ \mathbf{Z}_t =\sigma(\mathbf{X}_t\mathbf{W}_{xz}+\mathbf{H}_{t-1}\mathbf{W}_{hz}+\mathbf{b}_z), \end{gathered}
Rt=σ(XtWxr+Ht−1Whr+br),Zt=σ(XtWxz+Ht−1Whz+bz),
其中,W权重参数,b是偏置参数。
候选隐状态
接下来,重置门
R
t
\mathbf{R}_{t}
Rt就要发挥它的控制作用了。前面我们说到,重置门和更新门都被设计成(0,1)区间的向量。只要将它们和被控制对象做一个简单的乘法(按元素乘),就能发挥它们的控制作用。重置门中的项接近于0表示较多地忽略前一个隐状态的信息,而接近于1表示较多地保留前一个隐状态的信息。然后,我们就可以很容易理解候选隐状态
H
~
t
∈
R
n
×
h
\tilde{\mathbf{H}}_t\in\mathbb{R}^{n\times h}
H~t∈Rn×h的计算了:
H
~
t
=
tanh
(
X
t
W
x
h
+
(
R
t
⊙
H
t
−
1
)
W
h
h
+
b
h
)
\tilde{\mathbf{H}}_t=\tanh(\mathbf{X}_t\mathbf{W}_{xh}+(\mathbf{R}_t\odot\mathbf{H}_{t-1})\mathbf{W}_{hh}+\mathbf{b}_h)
H~t=tanh(XtWxh+(Rt⊙Ht−1)Whh+bh)
其中,W权重参数,b是偏置参数, 符号
⊙
\odot
⊙是Hadamard积(按元素乘积)运算符。 在这里,我们使用tanh非线性激活函数来确保候选隐状态中的值保持在区间(−1,1)中。
候选隐状态将之前的历史信息和当前时间步的输入进行了结合,GRU的记忆能力就体现在这里。候选隐状态的计算有点类似普通的RNN,只不过多了一个重置门和前一个时间步的隐状态做乘法。当重置门打开时,即重置门为1时,计算候选隐状态的过程就相当于普通的RNN了。有了这个重置门,GRU就可以灵活控制需要保留多少历史信息,不至于像普通RNN那样历史信息过度传递或过度保留,从而避免模型在处理长序列或长期依赖关系时出现梯度消失或梯度爆炸的问题。
下图说明了应用了重置门之后的计算流程。

图中,在上一步的基础上,计算出重置门的值后,将其和前一个时间步的隐状态做乘法,然后和当前输入 X t \mathbf{X}_t Xt一起输入进一个带激活函数的全连接层得到候选隐状态。
隐状态
上述的计算结果只是候选隐状态,我们仍然需要结合更新门
Z
t
\mathbf{Z}_{t}
Zt的效果。 这一步确定新的隐状态
H
t
∈
R
n
×
h
\mathbf{H}_t\in\mathbb{R}^{n\times h}
Ht∈Rn×h在多大程度上来自旧的状态
H
t
−
1
\mathbf{H}_{t-1}
Ht−1和新的候选状态
H
~
t
\tilde{\mathbf{H}}_t
H~t。更新门
Z
t
\mathbf{Z}_{t}
Zt仅需要在
H
t
−
1
\mathbf{H}_{t-1}
Ht−1和
H
~
t
\tilde{\mathbf{H}}_t
H~t之间进行按元素的凸组合就可以实现这个目标。这就得出了门控循环单元的最终更新公式:
H
t
=
Z
t
⊙
H
t
−
1
+
(
1
−
Z
t
)
⊙
H
~
t
\mathbf{H}_t=\mathbf{Z}_t\odot\mathbf{H}_{t-1}+(1-\mathbf{Z}_t)\odot\mathbf{\tilde{H}}_t
Ht=Zt⊙Ht−1+(1−Zt)⊙H~t
每当更新门 Z t \mathbf{Z}_{t} Zt接近1时,模型就倾向只保留旧状态。此时,来自 X t \mathbf{X}_t Xt的信息基本上被忽略,从而有效地跳过了依赖链条中的时间步 t t t。相反,当 Z t \mathbf{Z}_{t} Zt接近0时,新的隐状态 H t \mathbf{H}_t Ht就会接近候选隐状态 H ~ t \tilde{\mathbf{H}}_t H~t。这些设计可以帮助我们处理循环神经网络中的梯度消失问题,并更好地捕获时间步距离很长的序列的依赖关系。例如,如果整个子序列的所有时间步的更新门都接近于1,则无论序列的长度如何,在序列起始时间步的旧隐状态都将很容易保留并传递到序列结束。
下图说明了应用了更新门之后的计算流程。

图中,在上一步的基础上,前一个时间步的隐状态和更新门的乘积再加上候选隐状态和 1 − Z t 1-\mathbf{Z}_t 1−Zt的乘积得到当前时间步的隐状态。
总之,门控循环单元具有以下两个显著特征:
- 重置门有助于捕获序列中的短期依赖关系;
- 更新门有助于捕获序列中的长期依赖关系。
最终输出
GRU的最终输出通常与隐状态相关联。可以根据任务的具体要求,将隐状态传递给其他层或将其用作最终输出。例如,在语言模型中,可以将隐状态传递给全连接层进行分类或生成。
总结
- 门控循环神经网络可以更好地捕获时间步距离很长的序列上的依赖关系。
- 重置门有助于捕获序列中的短期依赖关系。
- 更新门有助于捕获序列中的长期依赖关系。
- 重置门打开时,门控循环单元包含基本循环神经网络;更新门打开时,门控循环单元可以跳过子序列。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 20
20 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)