【阅读笔记】多任务学习之PLE(含代码实现)
本文作为自己阅读论文后的总结和思考,不涉及论文翻译和模型解读,适合大家阅读完论文后交流想法,文末含PLE的Pytorch实现及Synthetic Data的生成代码。
本文作为自己阅读论文后的总结和思考,不涉及论文翻译和模型解读,适合大家阅读完论文后交流想法。
一. 全文总结
在MMoE的基础上改进,提出了全新的多任务学习框架Progressive Layered Extraction(PLE),通过分离Shared Experts和Task-Specific Experts,逐层提取深层信息,有利于解决多任务学习中的负迁移问题和跷跷板问题

二. 研究方法
传统的MTL Models和MMoE均存在跷跷板问题,于是提出PLE模型,验证了其在视频推荐系统和公开数据集上的有效性;最后验证了MMoE(ML-MMoE)在理论上可以达到CGC(PLE)的效果,但是在实际中前者却几乎不可能收敛到后者。
图为三种模型在人工数据集中的表现:

下图为四种模型中不同专家的权重分布情况,在基于MMoE的模型中不会出现其中一个专家权重为0的情况,说明基于MMoE的模型几乎不能收敛到CGC或PLE:

三. 结论
提出了一种新的MTL模型Progressive Layered Extraction(PLE),该模型将任务共享和任务特定参数显式分离,并引入了一种创新的递进路由方式(即多层提取结构),避免了负迁移和跷跷板现象,实现了更高效的信息共享和联合表示学习。在工业数据集和公共基准数据集上的离线和在线实验结果表明,与SOTA MTL模型相比,PLE模型有显著和一致的改进。
四. 创新点
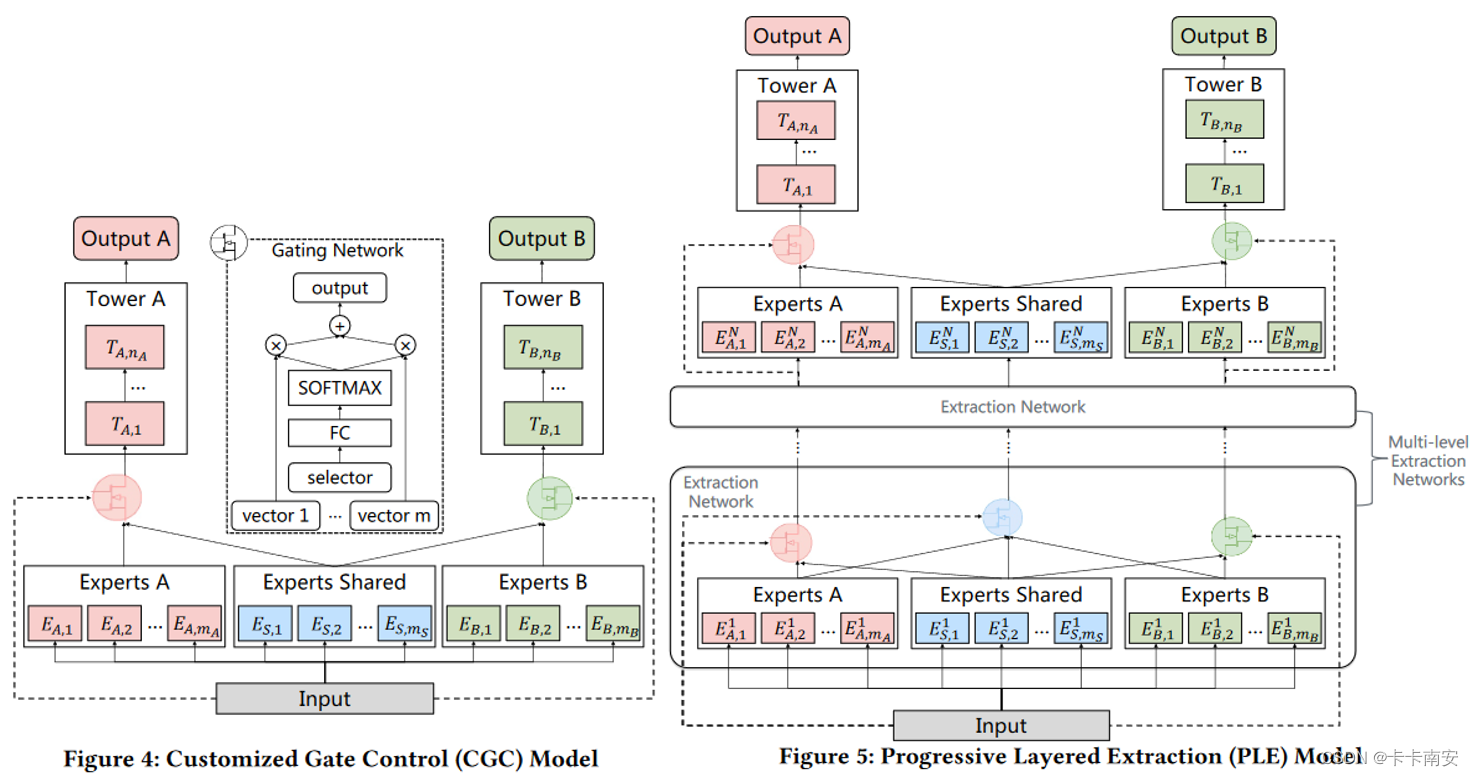
- 在MMoE的基础上,将所有Shared Experts显示分离,分为Shared Experts和Task-Specific Experts,减少公共知识和特定任务知识之间的的干扰,称为Customized Gate Control(CGC)。
- 引入多层专家和门控网络,采用分层渐进路由机制**(分层萃取)**,低层专家提取深层信息,越往高层专家逐渐分离任务特定参数。
- 以往的研究都没有明确地解决表示学习和路由的联合优化问题,特别是以不可分割的联合方式进行联合优化,而本研究首次在联合学习和路由的总体框架上提出了一种新的渐进分离方式。
五. 思考
- PLE可以有效地解决多任务学习中的跷跷板问题,无论是在推荐系统或是回归预测等领域都有突出的表现,具有非常强的适用性。
- 由于PLE将Expert分成两部分,因此对于相关性不强的任务间的信息共享有更出色的效果。
- 从模型结构上来看,PLE在每个模块中都引入了多个expert,并且采用多层提取的模式,导致模型结构复杂度大大提升,是否是因为模型参数的增加导致性能的提升是一个值得讨论的问题。
- 对于过于稀疏的目标,拥有独享专家会增加过拟合的风险。
六. 参考文献
七. Pytorch实现⭐
'''专家网络'''
class Expert_net(nn.Module):
def __init__(self,feature_dim,expert_dim):
super(Expert_net, self).__init__()
p = 0
self.dnn_layer = nn.Sequential(
nn.Linear(feature_dim, 64),
nn.ReLU(),
nn.Dropout(p),
nn.Linear(64, expert_dim),
nn.ReLU(),
nn.Dropout(p)
)
def forward(self, x):
out = self.dnn_layer(x)
return out
上面部分为专家网络的具体实现,如下图方框所示:

'''特征提取层'''
class Extraction_Network(nn.Module):
'''FeatureDim-输入数据的维数; ExpertOutDim-每个Expert输出的维数; TaskExpertNum-任务特定专家数;
CommonExpertNum-共享专家数; GateNum-gate数(2表示最后一层,3表示中间层)'''
def __init__(self,FeatureDim,ExpertOutDim,TaskExpertNum,CommonExpertNum,GateNum):
super(Extraction_Network, self).__init__()
self.GateNum = GateNum #输出几个Gate的结果,2表示最后一层只输出两个任务的Gate,3表示还要输出中间共享层的Gate
'''两个任务模块,一个共享模块'''
self.n_task = 2
self.n_share = 1
'''TaskA-Experts'''
for i in range(TaskExpertNum):
setattr(self, "expert_layer"+str(i+1), Expert_net(FeatureDim,ExpertOutDim))
self.Experts_A = [getattr(self,"expert_layer"+str(i+1)) for i in range(TaskExpertNum)]#Experts_A模块,TaskExpertNum个Expert
'''Shared-Experts'''
for i in range(CommonExpertNum):
setattr(self, "expert_layer"+str(i+1), Expert_net(FeatureDim,ExpertOutDim))
self.Experts_Shared = [getattr(self,"expert_layer"+str(i+1)) for i in range(CommonExpertNum)]#Experts_Shared模块,CommonExpertNum个Expert
'''TaskB-Experts'''
for i in range(TaskExpertNum):
setattr(self, "expert_layer"+str(i+1), Expert_net(FeatureDim,ExpertOutDim))
self.Experts_B = [getattr(self,"expert_layer"+str(i+1)) for i in range(TaskExpertNum)]#Experts_B模块,TaskExpertNum个Expert
'''Task_Gate网络结构'''
for i in range(self.n_task):
setattr(self, "gate_layer"+str(i+1), nn.Sequential(nn.Linear(FeatureDim, TaskExpertNum+CommonExpertNum),
nn.Softmax(dim=1)))
self.Task_Gates = [getattr(self,"gate_layer"+str(i+1)) for i in range(self.n_task)]#为每个gate创建一个lr+softmax
'''Shared_Gate网络结构'''
for i in range(self.n_share):
setattr(self, "gate_layer"+str(i+1), nn.Sequential(nn.Linear(FeatureDim, 2*TaskExpertNum+CommonExpertNum),
nn.Softmax(dim=1)))
self.Shared_Gates = [getattr(self,"gate_layer"+str(i+1)) for i in range(self.n_share)]#共享gate
def forward(self, x_A, x_S, x_B):
'''Experts_A模块输出'''
Experts_A_Out = [expert(x_A) for expert in self.Experts_A] #
Experts_A_Out = torch.cat(([expert[:,np.newaxis,:] for expert in Experts_A_Out]),dim = 1) # 维度 (bs,TaskExpertNum,ExpertOutDim)
'''Experts_Shared模块输出'''
Experts_Shared_Out = [expert(x_S) for expert in self.Experts_Shared] #
Experts_Shared_Out = torch.cat(([expert[:,np.newaxis,:] for expert in Experts_Shared_Out]),dim = 1) # 维度 (bs,CommonExpertNum,ExpertOutDim)
'''Experts_B模块输出'''
Experts_B_Out = [expert(x_B) for expert in self.Experts_B] #
Experts_B_Out = torch.cat(([expert[:,np.newaxis,:] for expert in Experts_B_Out]),dim = 1) # 维度 (bs,TaskExpertNum,ExpertOutDim)
'''Gate_A的权重'''
Gate_A = self.Task_Gates[0](x_A) # 维度 n_task个(bs,TaskExpertNum+CommonExpertNum)
'''Gate_Shared的权重'''
if self.GateNum == 3:
Gate_Shared = self.Shared_Gates[0](x_S) # 维度 n_task个(bs,2*TaskExpertNum+CommonExpertNum)
'''Gate_B的权重'''
Gate_B = self.Task_Gates[1](x_B) # 维度 n_task个(bs,TaskExpertNum+CommonExpertNum)
'''GateA输出'''
g = Gate_A.unsqueeze(2) # 维度(bs,TaskExpertNum+CommonExpertNum,1)
experts = torch.cat([Experts_A_Out,Experts_Shared_Out],dim=1) #维度(bs,TaskExpertNum+CommonExpertNum,ExpertOutDim)
Gate_A_Out = torch.matmul(experts.transpose(1,2),g)#维度(bs,ExpertOutDim,1)
Gate_A_Out = Gate_A_Out.squeeze(2)#维度(bs,ExpertOutDim)
'''GateShared输出'''
if self.GateNum == 3:
g = Gate_Shared.unsqueeze(2) # 维度(bs,2*TaskExpertNum+CommonExpertNum,1)
experts = torch.cat([Experts_A_Out,Experts_Shared_Out,Experts_B_Out],dim=1) #维度(bs,2*TaskExpertNum+CommonExpertNum,ExpertOutDim)
Gate_Shared_Out = torch.matmul(experts.transpose(1,2),g)#维度(bs,ExpertOutDim,1)
Gate_Shared_Out = Gate_Shared_Out.squeeze(2)#维度(bs,ExpertOutDim)
'''GateB输出'''
g = Gate_B.unsqueeze(2) # 维度(bs,TaskExpertNum+CommonExpertNum,1)
experts = torch.cat([Experts_B_Out,Experts_Shared_Out],dim=1) #维度(bs,TaskExpertNum+CommonExpertNum,ExpertOutDim)
Gate_B_Out = torch.matmul(experts.transpose(1,2),g)#维度(bs,ExpertOutDim,1)
Gate_B_Out = Gate_B_Out.squeeze(2)#维度(bs,ExpertOutDim)
if self.GateNum == 3:
return Gate_A_Out,Gate_Shared_Out,Gate_B_Out
else:
return Gate_A_Out,Gate_B_Out
上面为一层特征提取层的实现,当GateNum=2时表示由两个门控输出两组值,如下图中方框1所示;当GateNum=3时表示由三个门控输出三组值,如下图中方框2所示:

class PLE(nn.Module):
#FeatureDim-输入数据的维数;ExpertOutDim-每个Expert输出的维数;TaskExpertNum-任务特定专家数;CommonExpertNum-共享专家数;n_task-任务数(gate数)
def __init__(self,FeatureDim,ExpertOutDim,TaskExpertNum,CommonExpertNum,n_task=2):
super(PLE, self).__init__()
'''一层Extraction_Network,一层CGC'''
self.Extraction_layer1 = Extraction_Network(FeatureDim,ExpertOutDim,TaskExpertNum,CommonExpertNum,GateNum=3)
self.CGC = Extraction_Network(ExpertOutDim,ExpertOutDim,TaskExpertNum,CommonExpertNum,GateNum=2)
'''TowerA'''
p1 = 0
hidden_layer1 = [64,32]
self.tower1 = nn.Sequential(
nn.Linear(ExpertOutDim, hidden_layer1[0]),
nn.ReLU(),
nn.Dropout(p1),
nn.Linear(hidden_layer1[0], hidden_layer1[1]),
nn.ReLU(),
nn.Dropout(p1),
nn.Linear(hidden_layer1[1], 1))
'''TowerB'''
p2 = 0
hidden_layer2 = [64,32]
self.tower2 = nn.Sequential(
nn.Linear(ExpertOutDim, hidden_layer2[0]),
nn.ReLU(),
nn.Dropout(p2),
nn.Linear(hidden_layer2[0], hidden_layer2[1]),
nn.ReLU(),
nn.Dropout(p2),
nn.Linear(hidden_layer2[1], 1))
def forward(self, x):
Output_A, Output_Shared, Output_B = self.Extraction_layer1(x, x, x)
Gate_A_Out,Gate_B_Out = self.CGC(Output_A, Output_Shared, Output_B)
out1 = self.tower1(Gate_A_Out)
out2 = self.tower2(Gate_B_Out)
return out1,out2
Model = PLE(FeatureDim=X_train.shape[1],ExpertOutDim=64,TaskExpertNum=1,CommonExpertNum=1).to(device)
optimizer = torch.optim.Adam(Model.parameters(), lr=0.01)
loss_func = nn.MSELoss().to(device)
nParams = sum([p.nelement() for p in Model.parameters()])
print('* number of parameters: %d' % nParams)
上面则为整个PLE输入数据格式为(batchsize,feature_dim),输出为(batchsize,2)。
⭐在MoSE论文中作者构造了具有时序关系的多任务人工数据集,我参考作者给的公式和MMoE模型中的方法,总结了可以控制任务相关性的时间序列多任务学习数据集生成方法:MoSE论文中Sequential Synthetic Dataset生成代码(时间序列多任务学习数据集)

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 9
9 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)