【监控】使用process-exporter监控进程
exporter在基于prometheus的监控系统中属于数据采集模块,每个exporter采集某类数据,由prometheus定时调用exporter接口拉取,因此,如果需要通过prometheus监控某个指标,就需要找到实现这个指标的exporter,或者自己实现exporter。exporter能够采集哪些指标(是否能够采集所需的指标数据)exporter的配置exporter提供的指标可能
0 前言
exporter在基于prometheus的监控系统中属于数据采集模块,每个exporter采集某类数据,由prometheus定时调用exporter接口拉取,因此,如果需要通过prometheus监控某个指标,就需要找到实现这个指标的exporter,或者自己实现exporter。
在使用开源的exporter时,需要关注三个点:
- exporter能够采集哪些指标(是否能够采集所需的指标数据)
- exporter的配置
- exporter提供的指标可能需要经过计算才能得到所需的指标
1 process-exporter的使用场景
process-exporter通过读取/proc文件系统获取进程信息,包括以下文件:
- /proc/pid/stat
- /proc/pid/status
- /proc/pid/io
- /proc/pid/task
可以读取到进程的cpu、内存、io等指标,没有网络指标,如果需要采集网络指标数据,可以基于一些工具提供的数据自行开发exporter。
2 process-exporter的安装
很多exporter都使用golang开发,下载的安装包直接包含可以执行的二进制,通常有三种部署方式:主机、docker、kubernetes。
从Github上下载的process-exporter的包解压后里面就只有一个二进制process-exporter以及LICENSE和README.md,可以给二进制加上可执行权限,然后执行就可以启动了,之后就可以执行curl 127.0.0.1:9256/metrics查看得到的指标数据。
docker和kubernetes的部署方式可以使用对应的镜像和yaml进行部署,此处不详细赘述。
3 process-exporter的配置
proces-exporter的配置包括两部分的配置项,一个是process-exporter的一些参数控制,另一个是进程信息的配置。
一般来说,exporter都会有几部分的参数控制采集:
- config/config.path:指定配置文件路径
- web.listen-address:指定监听端口,通常都会有默认的端口,prometheus就是访问该端口获取指标数据
- web.telemetry-path:指标数据的url,通常都是
/metrics
除了有以上配置项之外,process-exporter还有其他特有的配置项:
- children:如果某个进程被采集,那么它的子进程也属于该组
- namemapping:名称映射,
- procfs:proc文件系统的路径,默认是/proc
- procnames:需要采集的进程名列表
- threads:是否采集线程,默认为是
基于性能的考虑,process-exporter只能对事先配置的进程进行指标采集,因此,需要对进程进行过滤,只采集需要的进程的指标。
在过滤进程时,会将进程进行分组,因此,就会有分组的名称,以及将进程放到分组的规则。例如,如果使用deb/rpm安装process-exporter时,默认的配置文件是:
process_names:
- name: "{{.Comm}}"
cmdline:
- '.+'
process_names是个数组,每个成员表示一个分组。
name是分组的名称,这里使用模版。cmdline用于对分组中的进程进行过滤,这里的正则表达式就表示过滤所有进程。
因此,上述配置文件的含义是:采集所有进程的指标数据,当遍历到某个进程时,获取该进程的进程名,然后放到进程名对应的分组。
name字段可以使用固定的字符串,也可以使用以下模版:
{{.Comm}}:进程名{{.ExeBase}}:可执行文件的文件名,与进程的区别是,进程名有长度15的限制{{.ExeFull}}:可执行文件的全路径{{.Username}}:进程的有效用户名{{.Matches}}:用正则匹配cmdline等字段时得到的匹配项的map,例如下面的Cfgfile{{.PID}}:pid,使用pid表示这个组只会有这一个进程{{.StartTime}}:进程的起始时间{{.Cgroups}}:进程的cgoup,可以用于区分不同的容器
进行分组进程过滤除了使用cmdline字段,还可以使用comm和exe,分别表示进程名和二进制路径,并且遵循以下规则:
- 如果使用了多个字段,则必须都匹配,例如,如果既使用了comm,又使用了exe,两个过滤必须都满足
- 对于comm和exe,它们是字符串数组,并且是OR的关系
- 对于cmdline,则是正则表达式数组,并且是AND的关系
例如:
process_names:
# 进程名过滤,超过15个字符会被截断
- comm:
- bash
# argv[0],如果开头不是/,说明匹配进程名
# 如果开头是/,则需要使用二进制路径全匹配
- exe:
- postgres
- /usr/local/bin/prometheus
# 如果使用多个字段进行匹配,则需要都匹配
- name: "{{.ExeFull}}:{{.Matches.Cfgfile}}"
exe:
- /usr/local/bin/process-exporter
cmdline:
- -config.path\s+(?P<Cfgfile>\S+)
4 process-exporter主要指标介绍
在实际监控进程时,主要使用的指标就是cpu和内存。
process-exporter中进程的指标以namedprocess_namegroup开头:
- namedprocess_namegroup_cpu_seconds_total:cpu使用时间,通过mode区分是user还是system
- namedprocess_namegroup_memory_bytes:内存占用,通过memtype区分不同的占用类型
- namedprocess_namegroup_num_threads:线程数
- namedprocess_namegroup_open_filedesc:打开的文件句柄数
- namedprocess_namegroup_read_bytes_total:进程读取的字节数
- namedprocess_namegroup_thread_context_switches_total:线程上下文切换统计
- namedprocess_namegroup_thread_count:线程数量统计
- namedprocess_namegroup_thread_cpu_seconds_total:线程的cpu使用时间
- namedprocess_namegroup_thread_io_bytes_total:线程的io
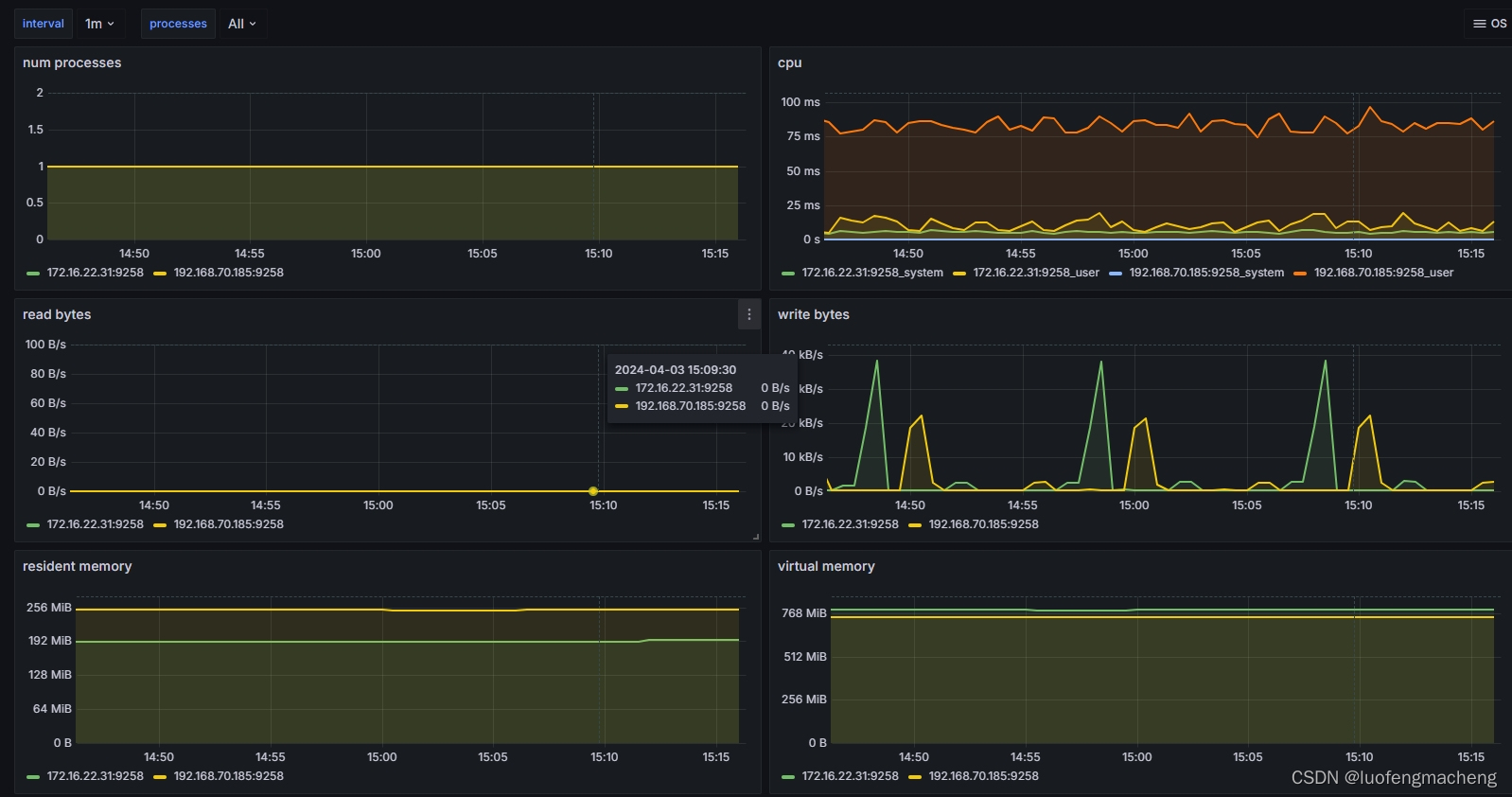
process-exporter基于上述指标提供了grafana的面板可以直接导入:https://grafana.com/grafana/dashboards/249-named-processes/

可以看到,面板中的cpu和读写是直接基于指标和rate函数得到的,内存则是直接基于指标而来的。
4.1 cpu
cpu是我们最经常关注的指标,如果使用node-exporter采集节点的指标数据,可以得到机器的cpu占比。
而使用process-exporter采集的是进程的指标,具体来说就是采集/proc/pid/stat中与cpu时间有关的数据:
- 第14个字段:utime,进程在
用户态运行的时间,单位为jiffies - 第15个字段:stime,进程在
内核态运行的时间,单位为jiffies - 第16个字段:cutime,子进程在用户态运行的时间,单位为jiffies
- 第17个字段:cstime,子进程在内核态运行的时间,单位为jiffies
那么通过上述值就可以得到进程的单核CPU占比:
- 进程的单核CPU占比=
(utime+stime+cutime+cstime)/时间差 - 进程的单核内核态CPU占比=
(stime+cstime)/时间差
因此,进程的单核CPU占比的promsql语句为increase(namedprocess_namegroup_cpu_seconds_total{mode="user",groupname="procname"}[30s])*100/30,单核内核态CPU占比的promsql语句为increase(namedprocess_namegroup_cpu_seconds_total{mode="system",groupname="procname"}[30s])*100/30。
注意:实测发现,process-exporter获取的数据与/proc/pid/stat中的有一定差异,需要进一步看下。
4.2 memory
process-exporter采集内存的指标时将内存分成5种类型:
- resident:进程实际占用的内存大小,包括共享库的内存空间,可以从/proc/pid/status中的
VmRSS获取 - proportionalResident:与resident相比,共享库的内存空间会根据进程数量平均分配
- swapped:交换空间,系统物理内存不足时,会将不常用的内存页放到硬盘的交换空间,可以从/proc/pid/status中的
VmSwap获取 - proportionalSwapped:将可能被交换的内存页按照可能性进行加权平均
- virtual:虚拟内存,描述了进程运行时所需要的总内存大小,包括哪些还没有实际加载到内存中的代码和数据,可以从/proc/pid/status中的
VmSize获取
对于一般的程序来说,重点关注的肯定是实际内存,也就是resident和virtual,分别表示实际在内存中占用的空间和应该占用的总空间。
5 总结
process-exporter可以用于采集进程的指标数据,主要的原理是通过读取/proc/pid获取进程的cpu、内存、线程等信息。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 11
11 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)