【iLQR】—— 基于最优控制ilqr/ddp的运动规划
iLQR推导以及在轨迹规划的应用
1 iLQR背景
对于非线性模型,求解最优控制问题:
对于一个非线性的函数,为了计算极值,我们用原来的函数,线性近似或者二次函数近似,从而计算近似函数的下降点,通过迭代,最终得到原来函数的极值。
iLQR思想也借鉴了数值优化的迭代思想,对一个非线性极值问题,使用二阶泰勒展开去近似原始函数,求解每一次近似函数的极值,通过这种方式迭代地计算非线性曲线的极值

对于iLQR问题,因为
x
˙
=
f
(
x
,
u
)
\dot x=f(x,u)
x˙=f(x,u)是非线性的,如果直接在原始的 LQR 计算框架中,无法得到解析解,此时V(x)是一个复杂的高维度非线性函数。观察LQR框架,Q(x,u)和V(x)都是二次函数。
将f(x,u)线性化,把复杂的cost-to-go函数V(x)泰勒展开为二阶,近似原来的V(x),这样就可以用LQR框架计算轨迹
求解最优轨迹:先给定一条轨迹,然后设定需要的代价函数cost(x,u),每一次迭代中都计算最优解,然后 cost 函数用来调整解,直到收敛

DDP ----->iLQR
DDP状态转移方程:二阶
iLQR状态转移方程:一阶
2 线性化
LQR:状态方程是线性的,代价函数是二次的,可以通过Riccai方程得到解析解。
然而对于非线性方程,得不到解析解,只能通过数值解来计算。所以在处理非线性方程问题时,可以将状态方程线性化,转化为常规LQR可以求解的方式
一般求解求解连续的 lqr 问题,使用 HJB 方程来计算。在 iLQR 中,一般将连续的状态方程转换成离散方程,从而使用动态规划原理来计算轨迹。
离散状态方程:
x
t
+
1
=
f
(
x
t
,
u
t
)
x_{t+1}=f(x_t,u_t)
xt+1=f(xt,ut)
代价函数:
min
u
1
,
…
,
u
T
∑
t
=
1
T
c
(
x
t
,
u
t
)
s.t.
x
t
+
1
=
f
(
x
t
,
u
t
)
\min _{\mathbf{u}_{1}, \ldots, \mathbf{u}_{T}} \sum_{t=1}^{T} c\left(\mathbf{x}_{t}, \mathbf{u}_{t}\right) \quad \text { s.t. } \mathbf{x}_{t+1}=f\left(\mathbf{x}_{t}, \mathbf{u}_{t}\right)
u1,…,uTmint=1∑Tc(xt,ut) s.t. xt+1=f(xt,ut)
展开求和公式:
min
u
1
,
…
,
u
T
c
(
x
1
,
u
1
)
+
c
(
f
(
x
1
,
u
1
)
,
u
2
)
+
⋯
+
c
(
f
(
f
(
…
)
…
)
,
u
T
)
\min _{\mathbf{u}_{1}, \ldots, \mathbf{u}_{T}} c\left(\mathbf{x}_{1}, \mathbf{u}_{1}\right)+c\left(f\left(\mathbf{x}_{1}, \mathbf{u}_{1}\right), \mathbf{u}_{2}\right)+\cdots+c\left(f(f(\ldots) \ldots), \mathbf{u}_{T}\right)
u1,…,uTminc(x1,u1)+c(f(x1,u1),u2)+⋯+c(f(f(…)…),uT)
这个方程只包括控制量u,对控制量
u
=
u
0
,
u
1
,
.
.
.
,
u
N
u={u_0,u_1,...,u_N}
u=u0,u1,...,uN求偏导,为了求出最优解。但是代价函数嵌套太多,求导不易。
贝尔曼最优性原理:未来状态只和当前状态有关,而和过去状态无关。
贝尔曼最优性原理:
Q
k
=
g
(
x
k
,
u
k
)
+
V
k
+
1
(
x
k
+
1
)
V
k
=
min
{
Q
k
}
\begin{array}{c} Q_{k}=g\left(x_{k}, u_{k}\right)+V_{k+1}\left(x_{k+1}\right) \\ V_{k}=\min \left\{Q_{k}\right\} \end{array}
Qk=g(xk,uk)+Vk+1(xk+1)Vk=min{Qk}
要想使得 k 阶段的 cost-to-go V k V_k Vk最优,只需要 Q k Q_k Qk取极小值,因为 V k + 1 ( x k + 1 ) V_{k+1}(x_{k+1}) Vk+1(xk+1)在上一个阶段已经计算出来了,此时 Q k Q_k Qk和 x k , u k x_k,u_k xk,uk有关,状态量是受控制量影响的,所以计算得到最优的 u k u_k uk即可
动态规划DP将计算 u = u 0 , u 1 , . . . , u N u={u_0,u_1,...,u_N} u=u0,u1,...,uN的过程,转变成了计算单步 u k u_k uk的过程,然后 k = N k=N k=N->0迭代,整体地控制量也就可以得到,这样求解就简单多了。然后利用上 DP 的整个 backward pass 和 forward pass,就可以得到整个解。
对于 ilqr 而言,将非线性的状态转移方程、目标函数泰勒展开,然后使用 lqr 求解方式去计算近似解,得到最后结果。
泰勒展开:
f
(
x
t
,
u
t
)
≈
f
(
x
^
t
,
u
^
t
)
+
∇
x
t
,
u
t
f
(
x
^
t
,
u
^
t
)
[
x
t
−
x
^
t
u
t
−
u
^
t
]
c
(
x
t
,
u
t
)
≈
c
(
x
^
t
,
u
^
t
)
+
∇
x
t
,
u
t
c
(
x
^
t
,
u
^
t
)
[
x
t
−
x
^
t
u
t
−
u
^
t
]
+
1
2
[
x
t
−
x
^
t
u
t
−
u
^
t
]
T
∇
x
t
,
u
t
2
c
(
x
^
t
,
u
^
t
)
[
x
t
−
x
^
t
u
t
−
u
^
t
]
\begin{array}{l} f\left(\mathbf{x}_{t}, \mathbf{u}_{t}\right) \approx f\left(\hat{\mathbf{x}}_{t}, \hat{\mathbf{u}}_{t}\right)+\nabla_{\mathbf{x}_{t}, \mathbf{u}_{t}} f\left(\hat{\mathbf{x}}_{t}, \hat{\mathbf{u}}_{t}\right)\left[\begin{array}{l} \mathbf{x}_{t}-\hat{\mathbf{x}}_{t} \\ \mathbf{u}_{t}-\hat{\mathbf{u}}_{t} \end{array}\right] \\ c\left(\mathbf{x}_{t}, \mathbf{u}_{t}\right) \approx c\left(\hat{\mathbf{x}}_{t}, \hat{\mathbf{u}}_{t}\right)+\nabla_{\mathbf{x}_{t}, \mathbf{u}_{t}} c\left(\hat{\mathbf{x}}_{t}, \hat{\mathbf{u}}_{t}\right)\left[\begin{array}{l} \mathbf{x}_{t}-\hat{\mathbf{x}}_{t} \\ \mathbf{u}_{t}-\hat{\mathbf{u}}_{t} \end{array}\right]+\frac{1}{2}\left[\begin{array}{l} \mathbf{x}_{t}-\hat{\mathbf{x}}_{t} \\ \mathbf{u}_{t}-\hat{\mathbf{u}}_{t} \end{array}\right]^{T} \nabla_{\mathbf{x}_{t}, \mathbf{u}_{t}}^{2} c\left(\hat{\mathbf{x}}_{t}, \hat{\mathbf{u}}_{t}\right)\left[\begin{array}{l} \mathbf{x}_{t}-\hat{\mathbf{x}}_{t} \\ \mathbf{u}_{t}-\hat{\mathbf{u}}_{t} \end{array}\right] \end{array}
f(xt,ut)≈f(x^t,u^t)+∇xt,utf(x^t,u^t)[xt−x^tut−u^t]c(xt,ut)≈c(x^t,u^t)+∇xt,utc(x^t,u^t)[xt−x^tut−u^t]+21[xt−x^tut−u^t]T∇xt,ut2c(x^t,u^t)[xt−x^tut−u^t]
移项:
f
(
x
t
,
u
t
)
−
f
(
x
^
t
,
u
^
t
)
≈
∇
x
t
,
u
t
f
(
x
^
t
,
u
^
t
)
[
x
t
−
x
^
t
u
t
−
u
^
t
]
c
(
x
t
,
u
t
)
−
c
(
x
^
t
,
u
^
t
)
≈
∇
x
t
,
u
t
c
(
x
^
t
,
u
^
t
)
[
x
t
−
x
^
t
u
t
−
u
^
t
]
+
1
2
[
x
t
−
x
^
t
u
t
−
u
^
t
]
T
∇
x
t
,
u
t
2
c
(
x
^
t
,
u
^
t
)
[
x
t
−
x
^
t
u
t
−
u
^
t
]
\begin{aligned} f\left(\mathbf{x}_{t}, \mathbf{u}_{t}\right)-f\left(\hat{\mathbf{x}}_{t}, \hat{\mathbf{u}}_{t}\right) & \approx \nabla_{\mathbf{x}_{t}, \mathbf{u}_{t}} f\left(\hat{\mathbf{x}}_{t}, \hat{\mathbf{u}}_{t}\right)\left[\begin{array}{l} \mathbf{x}_{t}-\hat{\mathbf{x}}_{t} \\ \mathbf{u}_{t}-\hat{\mathbf{u}}_{t} \end{array}\right] \\ c\left(\mathbf{x}_{t}, \mathbf{u}_{t}\right)-c\left(\hat{\mathbf{x}}_{t}, \hat{\mathbf{u}}_{t}\right) & \approx \nabla_{\mathbf{x}_{t}, \mathbf{u}_{t}} c\left(\hat{\mathbf{x}}_{t}, \hat{\mathbf{u}}_{t}\right)\left[\begin{array}{l} \mathbf{x}_{t}-\hat{\mathbf{x}}_{t} \\ \mathbf{u}_{t}-\hat{\mathbf{u}}_{t} \end{array}\right]+\frac{1}{2}\left[\begin{array}{l} \mathbf{x}_{t}-\hat{\mathbf{x}}_{t} \\ \mathbf{u}_{t}-\hat{\mathbf{u}}_{t} \end{array}\right]^{T} \nabla_{\mathbf{x}_{t}, \mathbf{u}_{t}}^{2} c\left(\hat{\mathbf{x}}_{t}, \hat{\mathbf{u}}_{t}\right)\left[\begin{array}{l} \mathbf{x}_{t}-\hat{\mathbf{x}}_{t} \\ \mathbf{u}_{t}-\hat{\mathbf{u}}_{t} \end{array}\right] \end{aligned}
f(xt,ut)−f(x^t,u^t)c(xt,ut)−c(x^t,u^t)≈∇xt,utf(x^t,u^t)[xt−x^tut−u^t]≈∇xt,utc(x^t,u^t)[xt−x^tut−u^t]+21[xt−x^tut−u^t]T∇xt,ut2c(x^t,u^t)[xt−x^tut−u^t]
δ
x
,
δ
u
\delta x,\delta u
δx,δu
f
ˉ
(
δ
x
t
,
δ
u
t
)
=
F
t
⏟
∇
x
t
,
u
t
f
(
x
^
t
,
u
^
t
)
[
δ
x
t
δ
u
t
]
\bar{f}\left(\delta \mathbf{x}_{t}, \delta \mathbf{u}_{t}\right)=\underbrace{\mathbf{F}_{t}}_{\nabla_{\mathbf{x}_{t}, \mathbf{u}_{t}} f\left(\hat{\mathbf{x}}_{t}, \hat{\mathbf{u}}_{t}\right)}\left[\begin{array}{l} \delta \mathbf{x}_{t} \\ \delta \mathbf{u}_{t} \end{array}\right]
fˉ(δxt,δut)=∇xt,utf(x^t,u^t)
Ft[δxtδut]

这样整个状态转移方程、目标函数变成和 lqr 一样的形式
状态转移方程:
f
(
x
k
+
δ
x
,
u
k
+
δ
u
)
=
f
(
x
)
+
∂
f
∂
x
δ
x
+
∂
f
∂
u
δ
u
+
高阶项
f\left(x_{k}+\delta x, u_{k}+\delta u\right)=f(x)+\frac{\partial f}{\partial x} \delta x+\frac{\partial f}{\partial u} \delta u+\text { 高阶项 }
f(xk+δx,uk+δu)=f(x)+∂x∂fδx+∂u∂fδu+ 高阶项
对于非线性方程,通过泰勒展开,可以对原始的函数有不同程度的局部近似

3 离散化
前向欧拉离散化:
χ
~
˙
=
χ
~
(
k
+
1
)
−
χ
~
(
k
)
T
=
A
χ
~
+
B
u
~
\dot{\tilde{\chi}}=\frac{\tilde{\chi}(k+1)-\tilde{\chi}(k)}{T}=A \tilde{\chi}+B \tilde{\mathbf{u}}
χ~˙=Tχ~(k+1)−χ~(k)=Aχ~+Bu~
离散时间状态空间表达式:

G(T) ≈ TA+1
H(T) ≈ TB
4 Backward pass反向传播
动态规划两个常见的概念:动作价值函数
Q
(
x
,
u
)
Q(x,u)
Q(x,u)和价值函数
V
(
x
)
V(x)
V(x)

阶段k到阶段N,最优的cost叫做价值函数cost-to-go(
V
k
−
>
N
V_{k->N}
Vk−>N,简写为
V
k
V_k
Vk)
在阶段 k 这里,
u
k
u_k
uk可以有多种选择,每一种选择都会带来不同的 cost,所以,在这里又新增加一个概念叫做 action-value 函数 Q,影响 Q 取值的变量包括 x 和 u,所以一般写成
Q
(
x
k
,
u
k
)
Q(x_k,u_k)
Q(xk,uk)
动作价值函数有2个代价组成,一个代价是,在阶段 k,系统处于状态 x,当前动作 u 带来的代价 g(x,u)。另一个代价是上一个阶段 k+1 的最优代价 cost to go。所以,Q 表达式为 Q ( x i , u i ) = g ( x i , u i ) + V ( x i + 1 ) = g ( x i , u i ) + V ( f ( x i , u i ) ) Q\left(x_{i}, u_{i}\right)=g\left(x_{i}, u_{i}\right)+V\left(x_{i+1}\right)=g\left(x_{i}, u_{i}\right)+V\left(f\left(x_{i}, u_{i}\right)\right) Q(xi,ui)=g(xi,ui)+V(xi+1)=g(xi,ui)+V(f(xi,ui))
在 k 阶段,如果得到最优的 u k u_k uk,那么得到最优的 V k V_k Vk, V ( x i ) = min { Q ( x i , u i ) } V\left(x_{i}\right)=\min \left\{Q\left(x_{i}, u_{i}\right)\right\} V(xi)=min{Q(xi,ui)}
Q泰勒展开:


1
2
[
δ
x
i
δ
u
i
]
T
[
Q
x
i
2
Q
x
i
u
i
Q
u
i
x
i
Q
u
i
2
]
[
δ
x
i
δ
u
i
]
+
[
Q
x
i
Q
u
i
]
T
[
δ
x
i
δ
u
i
]
=
1
2
[
1
δ
x
δ
u
]
T
[
0
Q
x
T
Q
u
T
Q
x
Q
x
x
Q
x
u
Q
u
Q
u
x
Q
u
u
]
[
1
δ
x
δ
u
]
\frac{1}{2}\left[\begin{array}{l} \delta x_{i} \\ \delta u_{i} \end{array}\right]^{T}\left[\begin{array}{cc} Q_{x_{i}^{2}} & Q_{x_{i} u_{i}} \\ Q_{u_{i} x_{i}} & Q_{u_{i}^{2}} \end{array}\right]\left[\begin{array}{l} \delta x_{i} \\ \delta u_{i} \end{array}\right]+\left[\begin{array}{l} Q_{x_{i}} \\ Q_{u_{i}} \end{array}\right]^{T}\left[\begin{array}{l} \delta x_{i} \\ \delta u_{i} \end{array}\right] \\ =\frac{1}{2}\left[\begin{array}{c} 1 \\ \delta x \\ \delta u \end{array}\right]^{T}\left[\begin{array}{ccc} 0 & Q_{x}^{T} & Q_{u}^{T} \\ Q_{x} & Q_{x x} & Q_{x u} \\ Q_{u} & Q_{u x} & Q_{u u} \end{array}\right]\left[\begin{array}{c} 1 \\ \delta x \\ \delta u \end{array}\right]
21[δxiδui]T[Qxi2QuixiQxiuiQui2][δxiδui]+[QxiQui]T[δxiδui]=21
1δxδu
T
0QxQuQxTQxxQuxQuTQxuQuu
1δxδu
价值函数 V 泰勒展开


𝛿𝑄也可以将泰勒展开式移项,表达为

𝛿𝑄的表达式中,其中


为了求解上式,将 g 展开(代价函数有时的符号也可以为𝑙)
ℓ
(
x
i
+
δ
x
i
,
u
i
+
δ
u
i
)
=
ℓ
(
x
i
,
u
i
)
+
δ
ℓ
(
x
i
,
u
i
)
≈
ℓ
(
x
i
,
u
i
)
+
∂
ℓ
(
x
i
,
u
i
)
∂
x
i
δ
x
i
+
∂
ℓ
(
x
i
,
u
i
)
∂
u
i
δ
u
i
+
1
2
δ
x
i
T
∂
2
ℓ
(
x
i
,
u
i
)
∂
x
i
2
δ
x
i
+
1
2
δ
u
i
T
∂
2
ℓ
(
x
i
,
u
i
)
∂
u
i
2
δ
u
i
+
1
2
δ
x
i
T
∂
2
ℓ
(
x
i
,
u
i
)
∂
x
i
∂
u
i
δ
u
i
+
1
2
δ
u
i
T
∂
2
ℓ
(
x
i
,
u
i
)
∂
u
i
∂
x
i
δ
x
i
≜
ℓ
(
x
i
,
u
i
)
+
ℓ
x
i
T
δ
x
i
+
ℓ
u
i
T
δ
u
i
+
1
2
δ
x
i
T
ℓ
x
i
2
δ
x
i
+
1
2
δ
u
i
T
ℓ
u
i
2
δ
u
i
+
1
2
δ
x
i
T
ℓ
x
i
u
i
δ
u
i
+
1
2
δ
u
i
T
ℓ
u
i
x
i
δ
x
i
\begin{aligned} \ell\left(x_{i}+\delta x_{i}, u_{i}+\delta u_{i}\right) & =\ell\left(x_{i}, u_{i}\right)+\delta \ell\left(x_{i}, u_{i}\right) \\ & \approx \ell\left(x_{i}, u_{i}\right)+\frac{\partial \ell\left(x_{i}, u_{i}\right)}{\partial x_{i}} \delta x_{i}+\frac{\partial \ell\left(x_{i}, u_{i}\right)}{\partial u_{i}} \delta u_{i} \\ & +\frac{1}{2} \delta x_{i}^{T} \frac{\partial^{2} \ell\left(x_{i}, u_{i}\right)}{\partial x_{i}^{2}} \delta x_{i}+\frac{1}{2} \delta u_{i}^{T} \frac{\partial^{2} \ell\left(x_{i}, u_{i}\right)}{\partial u_{i}^{2}} \delta u_{i} \\ & +\frac{1}{2} \delta x_{i}^{T} \frac{\partial^{2} \ell\left(x_{i}, u_{i}\right)}{\partial x_{i} \partial u_{i}} \delta u_{i}+\frac{1}{2} \delta u_{i}^{T} \frac{\partial^{2} \ell\left(x_{i}, u_{i}\right)}{\partial u_{i} \partial x_{i}} \delta x_{i} \\ & \triangleq \ell\left(x_{i}, u_{i}\right)+\ell_{x_{i}}^{T} \delta x_{i}+\ell_{u_{i}}^{T} \delta u_{i}+\frac{1}{2} \delta x_{i}^{T} \ell_{x_{i}^{2}} \delta x_{i}+\frac{1}{2} \delta u_{i}^{T} \ell_{u_{i}^{2}} \delta u_{i} \\ & +\frac{1}{2} \delta x_{i}^{T} \ell_{x_{i} u_{i}} \delta u_{i}+\frac{1}{2} \delta u_{i}^{T} \ell_{u_{i} x_{i}} \delta x_{i} \end{aligned}
ℓ(xi+δxi,ui+δui)=ℓ(xi,ui)+δℓ(xi,ui)≈ℓ(xi,ui)+∂xi∂ℓ(xi,ui)δxi+∂ui∂ℓ(xi,ui)δui+21δxiT∂xi2∂2ℓ(xi,ui)δxi+21δuiT∂ui2∂2ℓ(xi,ui)δui+21δxiT∂xi∂ui∂2ℓ(xi,ui)δui+21δuiT∂ui∂xi∂2ℓ(xi,ui)δxi≜ℓ(xi,ui)+ℓxiTδxi+ℓuiTδui+21δxiTℓxi2δxi+21δuiTℓui2δui+21δxiTℓxiuiδui+21δuiTℓuixiδxi
继续定义符号:

所以,根据向量的链式求导法则

已知
Q
x
T
Q_x^T
QxT,根据矩阵运算性质,计算他的转置矩阵,


根据 bellman 最优性原理,可以对系统的状态进行反向传播,即从终端状态{
x
N
,
u
N
x_N,u_N
xN,uN}计算到{
x
0
,
u
0
x_0,u_0
x0,u0}
(1)首先计算终端的 Q,V
V
N
(
x
N
+
δ
x
N
)
=
V
N
(
x
N
)
+
∂
V
N
∂
x
δ
x
N
+
1
2
(
∂
x
)
T
∂
2
V
N
∂
x
2
δ
x
V_{N}\left(x_{N}+\delta x_{N}\right)=V_{N}\left(x_{N}\right)+\frac{\partial V_{N}}{\partial x} \delta x_{N}+\frac{1}{2}(\partial x)^{T} \frac{\partial^{2} V_{N}}{\partial x^{2}} \delta x
VN(xN+δxN)=VN(xN)+∂x∂VNδxN+21(∂x)T∂x2∂2VNδx
对于末端
x
N
x_N
xN而言,一般不再施加控制,所以控制量
u
N
=
0
u_N=0
uN=0,此时的最优值函数往往是一个平方项
V
N
(
x
N
)
=
g
N
(
x
N
)
=
1
2
(
x
N
−
x
r
N
)
T
R
N
(
x
N
−
x
r
N
)
V_{N}\left(x_{N}\right)=g_{N}\left(x_{N}\right)=\frac{1}{2}\left(x_{N}-x_{r N}\right)^{T} R_{N}\left(x_{N}-x_{r N}\right)
VN(xN)=gN(xN)=21(xN−xrN)TRN(xN−xrN)
那么

这样的话,得到终点的
V
x
T
,
V
x
x
V_{x}^{T},\quad V_{x x}
VxT,Vxx,就可以得到前一个点的
Q
u
,
Q
x
x
,
Q
x
u
Q_u,Q_{xx},Q_{xu}
Qu,Qxx,Qxu
(2)继续分析剩余状态,已知动作值函数 Q,为了计算最优控制序列,对𝛿𝑢直接求导

为了使得𝛿𝑄最小,令导数为 0

得到最优𝛿u

其中,
得到最优𝛿𝑢 之后,将其代入到𝛿𝑄中,利用 bellman 最优性原理,Q 和 V 的关系是

𝛿𝑄和𝛿𝑉的关系是什么呢?在
Q
k
Q_k
Qk是最优动作值函数时,那么
V
k
(
x
k
)
=
Q
k
(
x
k
)
V_k(x_k)=Q_k(x_k)
Vk(xk)=Qk(xk),那么即使再增加一个小扰动𝛿𝑥,
V
k
(
x
k
+
δ
x
)
=
Q
k
(
x
k
+
δ
x
)
V_{k}\left(x_{k}+\delta x\right)=Q_{k}\left(x_{k}+\delta x\right)
Vk(xk+δx)=Qk(xk+δx)
 联立
联立



综述:
对于反向传播:如果知道𝑘+1阶段的
V
x
(
k
+
1
)
V_x(k+1)
Vx(k+1),
V
x
x
(
k
+
1
)
V_{xx}(k+1)
Vxx(k+1),那么就能得到 k 阶段的
Q
x
,
Q
u
,
Q
x
x
,
Q
x
u
Q_x,Q_u,Q_{xx},Q_{xu}
Qx,Qu,Qxx,Qxu,那么继续可以得到 k 阶段的反馈增益𝐾 𝑑,那么继续得到
δ
u
k
\delta u_k
δuk,然而由于
δ
x
k
\delta x_k
δxk具体值未知,不能确定具体的
δ
x
k
\delta x_k
δxk,没关系,这里不知道具体值并不影响整体计算。然后此时再刷新 k 阶段的
V
x
(
k
)
V_x(k)
Vx(k),
V
x
x
(
k
)
V_{xx}(k)
Vxx(k),进入下一个循环

在反向传播中,并没有更新具体的 x 值和 u 值,但是更新了反馈增益 K,后续在正向传播的时候就可以利用上
5 Forward pass正向传播
和常规的 LQR 不同,iLQR 的 forward pass 的时候需要使用非线性的状态转移方程来更新。在反向传播的时候,已经更新了反馈增益序列{ K 1 , K 2 , . . . , K N K_1,K_2,...,K_N K1,K2,...,KN},根据方程 δ u k ∗ = − Q u u − 1 ( Q u x δ x k + Q u k ) = K δ x k + d \delta u_{k}{ }^{*}=-Q_{u u}^{-1}\left(Q_{u x} \delta x_{k}+Q_{u_{k}}\right)=K \delta x_{k}+d δuk∗=−Quu−1(Quxδxk+Quk)=Kδxk+d,如果已知 δ x \delta x δx,那么就可以得到 δ u k ∗ \delta u_k^* δuk∗
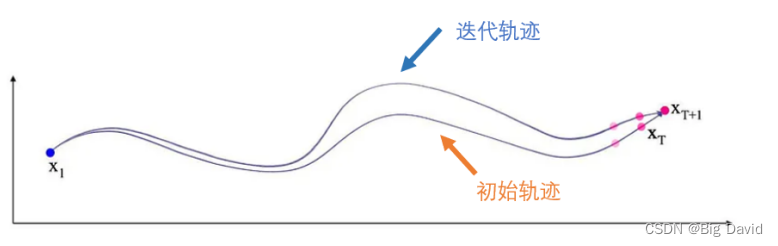
使用两次迭代轨迹点 k 的差分,更新 δ x k \delta x_k δxk,注意,这里并不是使用轨迹上前后两个点的位置差分,而是使用两条轨迹点,例如,在迭代i-1次,得到一条轨迹,在迭代i次,也会产生一条轨迹,那么在轨迹点k处,有 δ x k = x k i − x k i − 1 \delta x_k=x_k^i-x_k^{i-1} δxk=xki−xki−1,这样可以更新 δ u k ∗ \delta u_k^* δuk∗,因为 δ u k = d k + K k δ x k \delta u_k=d_k+K_k\delta x_k δuk=dk+Kkδxk,然后更新控制量 u k u_k uk,因为 u k i = u k i − 1 + δ u k u_k^i=u_k^{i-1}+\delta u_k uki=uki−1+δuk,再根据状态转移方程,使用当前点的状态值和控制值,来更新下一个 k+1 轨迹点的值 x k + 1 i = f ( x k i , u k i ) x_{k+1}^{i}=f\left(x_{k}^{i}, u_{k}^{i}\right) xk+1i=f(xki,uki),这样一直增大 k 的值,整条轨迹就得到更新
6 iLQR 的迭代
在一次循环中,轨迹得到更新,那么 cost 和值函数 V 也得到更新,为了让 cost 最小,继续微调𝛿𝑢的值,直到算法收敛。假设已经给出一个较好的初始轨迹,我们对初始轨迹进行调整优化即可。收敛的准则是,

即可以使用最优值函数 V 来计算,起点到终点的cost_to_go是
J
=
V
0
−
>
N
J=V_{0->N}
J=V0−>N,每一次迭代,都有
J
=
V
0
−
>
N
J=V_{0->N}
J=V0−>N,然后使用前后两次迭代的性能指标,判断是否收敛
iLQR 可以存在 3 个循环
- 一个外循环,负责调整𝛿𝑢的值,从而改善轨迹性能
- 一个内循环,用来反向传播计算反馈增益
- 还有一个内环,正向传播计算具体的𝛿𝑢,𝛿𝑥,以及u,x

7 iLQR

iLQR vs DDP
f(x,u)泰勒展开,一个取一阶,一个取二阶,与DDP相比,iLQR不再具有2阶收敛性,然而使用二阶计算,会增加计算负担,影响后面的计算性能
对于iLQR问题,优化问题形式:
经典iLQR:
x
∗
,
u
∗
=
arg
min
x
,
u
{
ϕ
(
x
N
)
+
∑
k
=
0
N
−
1
L
k
(
x
k
,
u
k
)
}
s.t.
x
k
+
1
=
f
k
(
x
k
,
u
k
)
,
k
=
0
,
1
,
…
,
N
−
1
x
0
=
x
start
\begin{aligned} x^{*}, u^{*} & =\underset{x, u}{\arg \min }\left\{\phi\left(x_{N}\right)+\sum_{k=0}^{N-1} L^{k}\left(x_{k}, u_{k}\right)\right\} \\ \text { s.t. } \quad x_{k+1} & =f^{k}\left(x_{k}, u_{k}\right), k=0,1, \ldots, N-1 \\ x_{0} & =x_{\text {start }} \end{aligned}
x∗,u∗ s.t. xk+1x0=x,uargmin{ϕ(xN)+k=0∑N−1Lk(xk,uk)}=fk(xk,uk),k=0,1,…,N−1=xstart 优化变量包括x(状态量)和u(控制量),目标就是找到最优的x和u,使得cost function达到最小。
cost function第一项描述终点状态,一般终点没有控制量,最后一个点的控制量不定义或者默认为0。后一项可以说是转移的cost,也就是给一个输入量,从一个状态转移到另一个状态过程中的cost是多少,一共有N-1步
系统约束:第一项就是运动学/状态转移的约束,第二项是给定一个初始状态,需要给一个初始状态,才能设计出最好的u来驱动系统获得一条轨迹。
带约束的iLQR
x
∗
,
u
∗
=
arg
min
x
,
u
ϕ
(
x
N
)
+
∑
k
=
0
L
k
(
x
k
,
u
k
)
s.t.
x
k
+
1
=
f
(
x
k
,
u
k
)
,
k
=
0
,
1
,
…
,
N
−
1
x
0
=
x
start
d
(
x
k
,
O
j
k
)
>
0
,
k
=
1
,
2
,
…
,
N
⋅
j
=
1
,
2
,
…
,
m
u
‾
<
u
k
<
u
ˉ
,
k
=
1
,
2
,
…
,
N
−
1
\begin{aligned} x^{*}, u^{*} & =\underset{x, u}{\arg \min } \phi\left(x_{N}\right)+\sum_{k=0} L^{k}\left(x_{k}, u_{k}\right) \\ \text { s.t. } \quad x_{k+1} & =f\left(x_{k}, u_{k}\right), k=0,1, \ldots, N-1 \\ x_{0} & =x_{\text {start }} \\ d\left(x_{k}, O_{j}^{k}\right) & >0, k=1,2, \ldots, N \cdot j=1,2, \ldots, m \\ \underline{u} & <u_{k}<\bar{u}, k=1,2, \ldots, N-1 \end{aligned}
x∗,u∗ s.t. xk+1x0d(xk,Ojk)u=x,uargminϕ(xN)+k=0∑Lk(xk,uk)=f(xk,uk),k=0,1,…,N−1=xstart >0,k=1,2,…,N⋅j=1,2,…,m<uk<uˉ,k=1,2,…,N−1施加一些显式的约束,第一项是轨迹点的距离与障碍物的距离要大于0,第二项是动力学可行性约束。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 41
41 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)