PowerQuery 汇总系列 - 多文件、单工作表数据
PowerQuery汇总多Excel工作薄文件,从入门到进阶。从掌握函数Excel.Workbook开始,逐步从鼠标点击过渡到修改函数及函数嵌套。
文章目录
-
Authors
- @ 樊笼星海
- @ w180361
- @ Email:ou251@outlook.com
1. 唠叨几句
在汇总多个Excel或csv文件数据的实践中,我发现没有比PowerQuery更合适的工具。常常听说的有VBA、WPS、Python等工具,Python有着丰富的Excel库,支持Excel数据的读取与修改。
使用PowerQuery只因为方便,不用敲代码(当然也可以选择敲代码-M公式),不用打开文件,不会修改源数据,只需要你的数据源结构规范一致即可。
1. 其一是请不要使用组合功能,组合功能将会成为学习PowerQuery的阻碍,它会打击你的学习热情。2. 其二是保证文件中的数据结构规范且一致,否则请先整理好数据再使用PowerQuery,即使你在使用VBA或Python。
2. 从文件夹中获取Excel工作薄数据
选项卡【数据】-【获取数据】-【来自文件】-【从文件夹】。
-
粘贴文件夹路径后,显示如下:文件数量不少,都是Excel工作薄文件;多说一点,内部数据结构一致。
![[]](https://i-blog.csdnimg.cn/direct/c64fd0b467dc4685b5e6225820bdd8d1.png)
-
点击【转换数据】,PowerQuery编辑器界面如下:
重要:Excel的所有数据均存储在[Content]列,需要使用Excel.Workbook([Binary],true)解析二进制数据文件。其他列属于文件的属性信息。
![[图片]](https://i-blog.csdnimg.cn/direct/9af4ce45263e47fc8fc4ea3ec240e0fa.png)
2.1. 常规解法:【添加自定义列】
- Power Query的每一个操作要熟练,因为只有熟练了,才能在面对一个具体问题时形成整体的解决思路,并在哪些功能点不能达到目的时,怎样借助已有功能来生成初步的代码,然后去修改其参数来实现。
- 在练的时候,你可以适当的看一下每个基础操作生成的代码是什么样子的,这个不需要你记,能简单看懂里面大概什么意思就可以了
具体步骤:
-
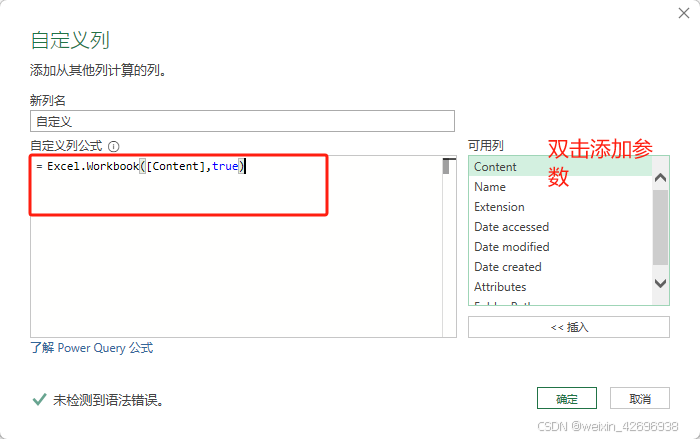
新增列:【添加列】-【自定义列】
新列名可不必修改,默认即可。
- 上文提到过
Excel.Workbook([Binary],true),这里的[Binary]引用列名[Content]。 - 记住解析函数的第二参数
[true],前文提到此参数用来识别标题(即是否使用第一行作为字段标题)。 - 点击确定后自动生成公式:
Table.AddColumn(Source, "自定义", each Excel.Workbook([Content],true))
- 上文提到过
-
删除【自定义】以外的其他列
- 删除后更利于后面的操作,不然影响我们的阅读。
- 点击【自定义】列的单元格,可预览表格中数据,此时预览的结果是工作表结构,包含工作表名称以及是否被隐藏
【Hidden】 - 点击确定后自动生成公式:
Table.SelectColumns(已添加自定义,{"自定义"})
Tips:若工作表中的数据被人为的筛选过,在此处会显示出隐藏的数据子集,注意在汇总的时候要删除掉

-
PowerQuery在每个查询返回的表格中,每一列的右上角都会有一个图标,点击【它】
- 默认【展开】,无需点击【聚合】
- 取消勾选【使用原始列名作为前缀】,这一步其实看习惯。
- 点击【确定】后,会显示前面预览的数据表格

-
点击
[Data]列的单元格,可预览工作表中的数据,此时预览的结果是我们需要汇总的源数据之一。

-
删除
[Data]列以外的其他列,没有已隐藏的表格数据,删除后点击右上角【展开】数据。- 自动生成的公式:
Table.SelectColumns(#"(展开的“自定义”)", {"Data"})

- 自动生成的公式:
-
最终结果:
![[图片]](https://i-blog.csdnimg.cn/direct/a4f9ceffe60a4d79b52ccecf318117ee.png)
最后,读者自己可以多练习,在这个过程中去了解查询步骤对表格的变化。
- Power Query的每一个操作要熟练,因为只有熟练了,才能在面对一个具体问题时形成整体的解决思路,并在哪些功能点不能达到目的时,怎样借助已有功能来生成初步的代码,然后去修改其参数来实现。
- 在练的时候,你可以适当的看一下每个基础操作生成的代码是什么样子的,这个不需要你记,能简单看懂里面大概什么意思就可以了
2.2. 进阶解法:修改【转换】功能生成的M公式
实现进阶需要掌握此函数:Table.TransformColumns,此函数的功能是表格的某一列或某几列进行修改。可先根据PowerQuery的可视化界面的功能,自动生成此公式,然后对公式进行修改。
一开始的数据表格:

整个汇总过程如下:
-
选中
[Name列,使用功能【转换】-【格式】-【大写】,将整列的内容转换成大写字母。-
功能位置:
![[图片]](https://i-blog.csdnimg.cn/direct/5ed48ccc56b14f94b5433ca843fb24c8.png)
-
自动生成的公式:
Table.TransformColumns(Source,{{"Name", Text.Upper, type text}}),对【Name】列的内容转换成了大写字母。 -
此公式的等效写法:
Table.TransformColumns(Source,{{"Name",each Text.Upper(_), type text}}) -
each _ 是 (x)=>x函数传参的语法糖形式,_可省略。知道即可.

-
-
对生成的公式进行修改,主要是修改大括号内的三个参数{}
-Name→Content:Table.TransformColumns(Source,{{"Content", Text.Upper, type text}})Text.Upper→each Excel.Workbook(_, true),Excel.Workbook在此处,需要使用each _。- 删除
type text,代表第二参数(即函数)返回的数据类型,修改后是返回一个表格,需要删除第三参数。 - 修改后结果如下:

-
让我们来继续修改,在预览
table数据时,发现还只是工作表结构,需要继续获取工作表数据。-
each Excel.Workbook(_, true)后面再加点东西,先取[Data]列。 -
each Excel.Workbook(_, true)[Data]取Data列的表格,返回一个列表,下一步取第一行。

-
each Excel.Workbook(_, true)[Data]{0},PowerQuery中计数从0开始,并非从1开始,这一点与python一样。现在距离我们想要的结果已经很近了。

-
-
按照常规解法的思路,到了这一步,应该是删除其他列,然后进行展开即可。
-
让我们来点不一样的,先取
[Content]列,然后直接把数据纵向合并- 在查询步骤中,点击右键,再点击【插入步骤后】然后再修改公式。

- 在公式后面写上
[Content],返回一个列表。

- 在公式外层再套上
Table.Combine。

- 在查询步骤中,点击右键,再点击【插入步骤后】然后再修改公式。
-
进阶写法的优势:整个查询过程中,并没有依赖表格内部数据字段名称,只有公式。在这里感受并不明显,其他许多需求中,若是在查询过程中使用了工作薄文件名、工作表名称、数据字段,要小心这些名称的变更或是新增。
-
进阶的关键知识:看懂公式,尝试做出修改,是进阶路上必须掌握的。
Table.TransformColumns对表格的某一列循环执行某个动作,并返回相应结果。Excel.Workbook解析Excel二进制数据,对[Content]列的每一行执行此动作并返回工作表结构。- 表格的行列索引,知道怎么取,知道会返回什么样的结果,然后对返回的结果如何去处理。这些都是需要去思考的过程,这个过程对于是否了解三大容器的概念并不是那么重要,可以通过实践来进行总结。但这个习惯不能用来学习
DAX,有点偏题了。 - 接下来的进阶解法,通过行列索引,列表循环函数、列表合并函数来解决。
-
Power Query的每一个操作要熟练,因为只有熟练了,才能在面对一个具体问题时形成整体的解决思路,并在哪些功能点不能达到目的时,怎样借助已有功能来生成初步的代码,然后去修改其参数来实现。
-
在练的时候,你可以适当的看一下每个基础操作生成的代码是什么样子的,这个不需要你记,能简单看懂里面大概什么意思就可以了
2.3. 高阶解法:一行搞定,一个查询步骤搞定多文件汇总
一行并非一次写成,不过是观察到了每一步的结果,然后在外部再套一个函数。
- 具体步骤:
-
源Source:
Folder.Files("E:\A=Project\Other\P=BI\xlsx")

-
文件中的数据都在
[Content]列,所以先取[Content],返回一个列表list。
Folder.Files("E:\A=Project\Other\P=BI\xlsx")[Content]

-
前面我们使用了
Table.TranformColumns来处理[Content]列的每一行,现在使用List.Transforms,同样在处理每一行/元素(单元格)时,使用Excel.Workbook来解析二进制数据,不要忘记true。List.Transform( Folder.Files("E:\A=Project\Other\P=BI\xlsx")[Content], each Excel.Workbook(_,true) )
-
还不是我们想要的,加上
{0}[Data]或[Data]{0}。List.Transform( Folder.Files("E:\A=Project\Other\P=BI\xlsx")[Content], each Excel.Workbook(_,true){0}[Data] )
-
最后套上
Table.Combine,将列表中的表格进行合并。Table.Combine( List.Transform( Folder.Files("E:\A=Project\Other\P=BI\xlsx")[Content], each Excel.Workbook(_,true){0}[Data] ) )
2.4. 一点细节
- 如何获取到工作薄文件中的某个工作表?
细心的朋友们可能会发现了,在常规解法中,并没有筛选Excel工作薄文件中的某一个工作表数据,也就是说这个过程中,其实合并的是所有工作表的数据。
作者本人使用的示例数据,每一个Excel工作薄文件仅仅有一个工作表,不必担心此问题,但如果遇到多工作表呢?该如何解决?
看下图,到了解析Excel工作薄展开工作表这一步骤时,没有序号,不过咱们有工作表名称,在这里我们可以工作表名称进行筛选。点击列的右上角即可进行筛选。到了这一步就很难通过筛选第1个工作表的方式来解决问题。

在进阶解法之后,都是通过{0}来取第一行,即取第一个工作表的数据,要知道咱们在解析Excel工作薄文件时,是在循环函数内部,自然可以直接取第一个工作表。
如若需要按工作表名称来获取,修改即可:{[Name="Sheet1"]}。
- 重复行是哪里来的?
若工作表中的数据被人为的筛选过,PowreQuery会识别出隐藏的数据子集,这一点在解析出工作表结构的时候,容易忽略。
如何让PQ也忽略掉呢?PQ能识别出来,我们就有办法筛选掉。看下图,除了[Data]列,其他列均显示有区别。

可是[Data]列真的一样吗?是真的重复吗?来测试,点击第一个Table,然后计算[Data]列中的表格数据有多少行。
下图可以看到数据的行数是一样的,若不注意此现象,将会导致最终的数据汇总有大量的重复行。

- 无法访问临时文件
Excel文件打开状态时,会生成临时文件,临时文件以~$开头,可以根据此特征先筛选剔除掉。PowerQuery在运行过程中会报错


-
比较粗暴的方法是使用PowerQuery的功能,直接将错误忽略掉。
自动生成的公式如下:Table.RemoveRowsWithErrors(自定义1, {"Content"})

-
或是使用筛选行的方式,将临时文件剔除掉。
自动生成的公式如下:Table.SelectRows(Source, each not Text.Contains([Name], "~$"))

-
最后,也可先关闭文件,临时文件也会被程序自动删除。
4.2 从文件夹中获取csv文本数据
汇总csv文件与汇总Excel工作薄文件,异曲同工。
- 主要修改如下:
Excel.Workbook([Binary],true)→Table.PromoteHeaders( Csv.Document([Binary]) ),Csv.Document函数很多参数,不写能不能行?能行!但有时候很需要这些参数,因为csv的存储格式会有好几种,这时候我们并不确定。我们能做的就是先不写试试,如果解析出来的结果有乱码,那就把参数补进去。
- 参数补充方法:使用PQ获取单个csv文件的数据,会自动生成相关参数,把我们需要的参数复制过来即可。
- PowerQuery的M公式,不是写出来的,是改出来的。
3. 版本建议
PowerQuery 是自PowerPivot以来,Excel的最佳免费插件。
Excel2010版、Excel2013版,PowerQuery还只是Excel的插件,需要单独下载并安装。
Excel2016版开始,PowerQuery作为Excel的内置功能。
现在已经2024年,最低也建议使用Excel2021版。没有公式提示(语法提示)在使用时是痛苦的。
使用office365订阅版那就更好不过了。
4. 留点问题
- 有多层文件夹怎么办?
若多层文件夹下的是同类型数据,需要汇总在一起,通常需要将文件夹名称添加至数据字段。若是数据中原本就有此字段,那当我没说。
- 需要提取文件夹的名称或关键词,甚至是工作表名称,然后添加进数据字段,怎么办?
方法简单,在展开数据时,保留这些文件夹、工作表名称的字段,PQ会自动进行扩展。这在python-numpy里面叫广播。
另外还可以通过Table.TransformRows将外层的字段直接添加至内层的表格,这将有助于理解:(x)=>x、each _ 的行为。
随手改公式,不仅能减少操作步骤,还能提升对Power Query函数的熟悉和理解。很多时候,注意观察一下Power Query操作时生成的步骤,是理解函数的用法和发现隐藏参数的一个很好的途径!
后续的章节,大多围绕修改公式展开 。
文章难免有疏漏,若读者发现某处编辑有误,可评论留言。
相关问题也可找作者进行咨询,DIY定制皆可。
-
Authors
- @ 樊笼星海
- @ w180361
- @ Email:ou251@outlook.com

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)