英伟达 vs. 华为海思:GPU性能一览
NVIDIA NVLink采用全网状拓扑,如下所示,(双向)GPU-to-GPU 最大带宽可达到400GB/s (需要注意的是,下方展示的是8*A100模块时的600GB/s速率,8*A800也是类似的全网状拓扑);和华为/海思主流 GPU 的型号性能,供个人参考使用,文中使用数据均源自官网。本文转自SDNLAB,编译自arthurchiao的博客,主要介绍了。以上内容来自架构师联盟。
本文转自SDNLAB,编译自arthurchiao的博客,主要介绍了英伟达和华为/海思主流 GPU 的型号性能,供个人参考使用,文中使用数据均源自官网。
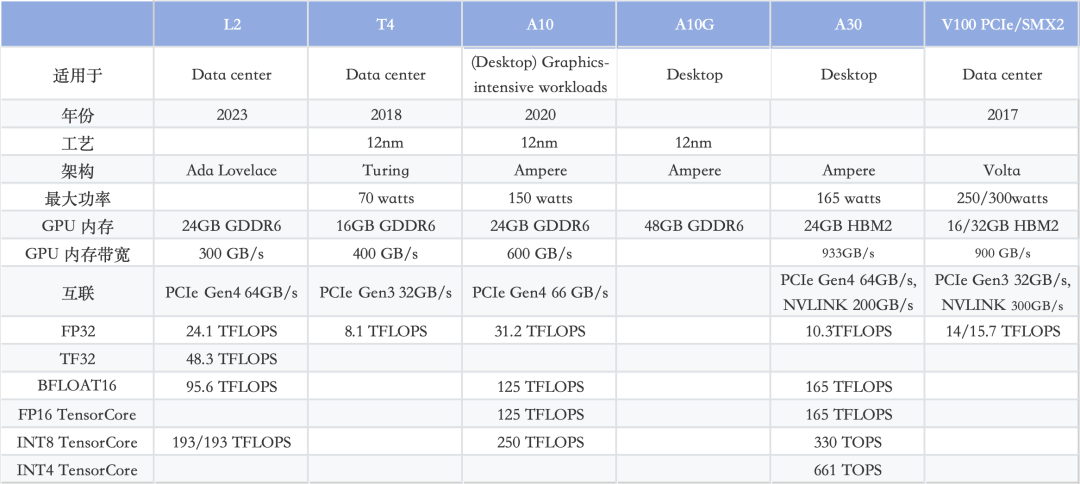
英伟达GPU L2/T4/A10/A10G/V100对比:

英伟达A100/A800/H100/H800/华为Ascend 910B对比:

一句话总结,H100 vs. A100:3 倍性能,2 倍价格
值得注意的是,HCCS vs. NVLINK的GPU 间带宽。
对于 8 卡 A800 和 910B 模块而言,910B HCCS 的总带宽为392GB/s,与 A800 NVLink (400GB/s) 相当。然而,两者之间也存在一些区别。
NVIDIA NVLink采用全网状拓扑,如下所示,(双向)GPU-to-GPU 最大带宽可达到400GB/s (需要注意的是,下方展示的是8*A100模块时的600GB/s速率,8*A800也是类似的全网状拓扑);

华为HCCS采用对等拓扑(没有 NVSwitch 芯片之类的东西),所以(双向) GPU-to-GPU 最大带宽是56GB/s;

H20/L20/Ascend 910B对比:

以上内容来自架构师联盟
台湾突发7.4级强震!全球GPU、存储、芯片或将大震荡? - 知乎 (zhihu.com)
大模型训练推理如何选择GPU?一篇文章带你走出困惑(附模型大小GPU推荐图) - 知乎 (zhihu.com)
一文看懂英伟达A100、A800、H100、H800各个版本有什么区别? - 知乎 (zhihu.com)
AI核弹B200发布:超级GPU新架构30倍H100单机可训15个GPT-4模型,AI进入新摩尔时代 - 知乎 (zhihu.com)
紧跟“智算中心”这波大行情!人工智能引领算力基建革命! - 知乎 (zhihu.com)
先进计算技术路线图(2023) - 知乎 (zhihu.com)
建议收藏!大模型100篇必读论文 - 知乎 (zhihu.com)
马斯克起诉 OpenAI:精彩程度堪比电视剧,马斯克与奥特曼、OpenAI的「爱恨纠缠史」 - 知乎 (zhihu.com)
2023第一性原理科研服务器、量化计算平台推荐 - 知乎 (zhihu.com)
Llama-2 LLM各个版本GPU服务器的配置要求是什么? - 知乎 (zhihu.com)
人工智能训练与推理工作站、服务器、集群硬件配置推荐

整理了一些深度学习,人工智能方面的资料,可以看看
机器学习、深度学习和强化学习的关系和区别是什么? - 知乎 (zhihu.com)
人工智能 (Artificial Intelligence, AI)主要应用领域和三种形态:弱人工智能、强人工智能和超级人工智能。
买硬件服务器划算还是租云服务器划算? - 知乎 (zhihu.com)
深度学习机器学习知识点全面总结 - 知乎 (zhihu.com)
自学机器学习、深度学习、人工智能的网站看这里 - 知乎 (zhihu.com)
2023年深度学习GPU服务器配置推荐参考(3) - 知乎 (zhihu.com)

多年来一直专注于科学计算服务器,入围政采平台,H100、A100、H800、A800、L40、L40S、RTX6000 Ada,RTX A6000,单台双路256核心服务器等。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)