DSPy实战:三十分钟无痛上手自动化Prompt框架
DSPy 是一款功能强大的框架。它可以用来自动优化大型语言模型(LLM)的提示词和响应。还能让我们的 LLM 应用即使在 OpenAI/Gemini/Claude版本升级也能正常使用。无论你有多少数据,它都能帮助你优化模型,获得更高的准确度和性能。通过选择合适的优化器,并根据具体需求进行调优,你可以在各种任务中获得出色的结果。在官方教程中使用LLM 为,数据集为在线的ColBERTv2 服务器,托
前言:
伴随着LLM模型的发展,一个优秀的Prompt对于任务成功起到了关键的作用。但目前大模型使用中的Prompt调优愈发成为一个痛点问题。如何优雅的解决这个痛点?
DSPy框架的出现使自动生成解决复杂问题的Prompt成为了现实。
只需输入你的问题,Prompt的调整,思维链,知识库等使用全部交由框架自动执行,最终给出一个令人满意的结果,并且这一切过程都可以被查看。
DSPy作为一个高效的自动化Prompt框架,为开发者提供了强大的工具,简化了复杂的Prompt生成和管理过程。本教程将带您在三十分钟内快速上手DSPy,帮助您轻松实现自动化Prompt的创建和优化。
为了帮助读者更深入的理解框架使用,笔者在官方教程之外还会额外增加自定义数据的教程,注意官方教程代码块命名为
Repo-office, 自定义数据代码块命名为Repo-custom,两个代码块功能如未特别说明则完全一致。
本文面向的读者主要是有一定编程基础,特别是对自然语言处理感兴趣的开发者。无论您是技术小白还是资深开发者,都可以通过本文了解并掌握DSPy的基本使用方法。
一:DSPy介绍
DSPy 是一款功能强大的框架。它可以用来自动优化大型语言模型(LLM)的提示词和响应。还能让我们的 LLM 应用即使在 OpenAI/Gemini/Claude版本升级也能正常使用。无论你有多少数据,它都能帮助你优化模型,获得更高的准确度和性能。通过选择合适的优化器,并根据具体需求进行调优,你可以在各种任务中获得出色的结果。
1.1 传统LLM使用的挑战
使用 LLM 构建复杂系统通常需要以下步骤:
- 将问题分解为多个步骤。
- 对每个步骤进行良好的提示,使其单独运行良好。
- 调整各个步骤以实现良好协作。
- 生成合成示例来微调每个步骤。
- 使用这些示例对较小的 LLM 进行微调以降低成本。
这种方法既复杂又耗时,并且每次更改pipeline、LLM 或数据时都需要重新调整提示和微调步骤。
1.2 DSPy
DSPy 通过以下两种方式简化了 LLM 优化过程:
- 分离流程和参数: DSPy 将程序流程(称为“模块(Module)”)与每个步骤的参数(LLM 提示prompt和权重weight)分离。这使得可以轻松地重新组合模块并调整参数,而无需重新编写提示或生成合成数据。
- 引入 优化器: DSPy 引入了新的“优化器”,这是一种 LLM 驱动的算法,可以根据您想要最大化的“指标”调整 LLM 调用的提示和/或权重。优化器可以自动探索最佳提示和权重组合,而无需人工干预。
DSPy 具有以下优势:
- 更强大的模型: DSPy 可以训练强大的模型(如 GPT-3.5 或 GPT-4)和本地模型,并且支持使用第三方的框架(如 OLLAMA 等),使其在执行任务时更加可靠,即具有更高的质量和/或避免特定的失败模式。
- 更少的提示: DSPy 优化器会将相同的程序 “编译 “成不同的指令、少量提示和/或权重更新(finetunes)。 这意味着您只需要更少的提示就可以获得相同甚至更好的结果。
- 更系统的方法: DSPy 提供了一种更系统的方法来使用 LLM 解决困难任务。您可以使用通用的模块和优化器来构建复杂的pipeline,而无需每次更改代码或数据时都重新编写提示。
DSPy 通过以下步骤工作:
-
定义程序流程:使用 DSPy 模块定义程序流程。每个模块代表程序的一步,并可以包含 LLM 调用、条件检查和其他操作。
-
设置指标:指定要优化的指标。指标可以是任何可以衡量系统性能的度量,例如准确性、速度或效率。
-
优化器:运行 DSPy 优化器。优化器将探索不同的 LLM 提示和权重组合,并根据指定的指标选择最佳组合。
DSPy 可用于各种 LM 应用,包括:
-
问答系统: DSPy 可以用于优化问答系统的 LLM 提示,以提高准确性和效率。
-
机器翻译: DSPy 可以用于优化机器翻译系统的 LLM 权重,以提高翻译质量。
-
文本摘要: DSPy 可以用于优化文本摘要系统的 LLM 提示,以生成更准确和更具信息量的摘要。
DSPy 适用于以下情况:
- 您需要在Pipeline中多次使用 LM
- 您需要训练强大的模型以执行困难的任务
- 您希望以更系统的方式使用 LM
二:代码及模块讲解
Github: [stanfordnlp/dspy: DSPy: The framework for programming—not prompting—foundation models]
完整的官方教程:
Getting Started: 
Repo-office代码为完整官方教程中的部分实现讲解
2.1 配置环境, 安装DSPy并加载数据
配置环境
Repo-office|Repo-custom
%load_ext autoreload
%autoreload 2
import sys
import os
try: # When on google Colab, let's clone the notebook so we download the cache.
import google.colab
repo_path = 'dspy'
!git -C $repo_path pull origin || git clone https://github.com/stanfordnlp/dspy $repo_path
except:
repo_path = '.'
if repo_path not in sys.path:
sys.path.append(repo_path)
# Set up the cache for this notebook
os.environ["DSP_NOTEBOOK_CACHEDIR"] = os.path.join(repo_path, 'cache')
import pkg_resources # Install the package if it's not installed
if not "dspy-ai" in {pkg.key for pkg in pkg_resources.working_set}:
!pip install -U pip
!pip install dspy-ai
!pip install openai~=0.28.1
# !pip install -e $repo_path
import dspy
定义模型并加载数据
Repo-office
在官方教程中使用LLM 为 gpt-3.5-turbo,数据集为在线的ColBERTv2 服务器,托管维基百科 2017 年“摘要”搜索索引
问答数据集使用了HotPotQA数据集中的一个小样本
import openai
openai.api_key =
turbo = dspy.OpenAI(model='gpt-3.5-turbo')
colbertv2_wiki17_abstracts = dspy.ColBERTv2(url='http://20.102.90.50:2017/wiki17_abstracts')
dspy.settings.configure(lm=turbo, rm=colbertv2_wiki17_abstracts)
from dspy.datasets import HotPotQA
# Load the dataset.
dataset = HotPotQA(train_seed=1, train_size=20, eval_seed=2023, dev_size=50, test_size=0)
# Tell DSPy that the 'question' field is the input. Any other fields are labels and/or metadata.
trainset_q = [x.with_inputs('question') for x in dataset.train]
devset_q = [x.with_inputs('question') for x in dataset.dev]
len(trainset), len(devset)
在加载原始数据后,我们对每个示例应用了 x.with_inputs(‘question’),以告知DSPy我们在每个示例中的输入字段仅为question。其他字段则是标签或元数据,不会提供给系统。
Repo-custom
但是实现中我们时常需要自定义数据库和大模型,因此这里笔者给出几种常用的实现:
自定义大模型
- 基于OLLAMA的本地模型
需要先另开启一个终端开始服务 ollama serve
lm = dspy.OllamaLocal(model='mistral')
- 基于AzureOpenAI的API
由于AzureOpenAI和官方文档有一些不同,建议按照以下形式设置AzureOpenAI的参数
turbo = dspy.AzureOpenAI(api_base= "your azure endpoint",
api_key="",
api_version="2024-05-01-preview",
api_provider= "azure",
model_type="chat",
deployment_id = "your deployment name",)
- 基于ChatGPT
turbo = dspy.OpenAI(model='gpt-3.5-turbo')
import openai
openai.api_key = ""
自定义数据库
文档给出了多种自定义加载数据的方案,具体可以在官方文档中查阅,这里主要说明的是,官方教程/Repo-office中直接给出了数据库链接并直接加载,但是实际需要三步,
-
- 第一步加载自然文本数据库,
-
- 第二步使用句子向量模型转为向量,这里为了教学,句子向量采用了不同的模型。
-
- 第三使用向量数据库进行加载。
需要特别注意:
- 1:数据库最终加载进入的方式要求是
List
笔者给出一个示例:
import dspy
from dspy.datasets import DataLoader
from dspy.retrieve.faiss_rm import FaissRM
from dsp.modules.sentence_vectorizer import SentenceTransformersVectorizer
import pandas as pd
dl = DataLoader()
turbo = dspy.OpenAI(model='gpt-3.5-turbo')
# 从CSV文件加载数据集
dataset = dl.from_csv(
f"cmrc2018_sampled.csv",
fields=("question", "answer"),
input_keys=("Title", "question"))
# 划分训练集和测试集
splits = dl.train_test_split(dataset, train_size=0.8)
trainset = splits['train']
devset = splits['test']
# 将训练和测试数据集生成数据库
document_chunks = df['Context Text'].drop_duplicates().tolist()
vectorizer = SentenceTransformersVectorizer(
model_name_or_path="distiluse-base-multilingual-cased-v2", # 模型名称或路径
)
# 使用 Faiss 进行检索
frm = FaissRM(document_chunks, vectorizer=vectorizer)
dspy.settings.configure(lm=turbo, rm=frm)
笔者给出完整的自定义数据加载的代码。
使用的数据集为 [第二届中文机读理解评估研讨会 (CMRC 2018)] 数据集的部分代码,主要包括问答数据和回答问题需要的背景知识。
首先对cmrc2018_trial.json进行处理
- 数据问答对的列名必须分别是
question和answer,不然后面会报错
import json
import pandas as pd
import random
# Define the path to the input JSON file
input_file_path = 'cmrc2018_trial.json'
# Load the JSON data
with open(input_file_path, 'r', encoding='utf-8') as file:
data = json.load(file)
# Randomly select 100 entries from the dataset
sampled_data = random.sample(data, 100)
# Initialize a list to hold the extracted data
extracted_data = []
# Iterate through each entry in the sampled data
for entry in sampled_data:
context_id = entry['context_id']
title = entry['title']
context_text = entry['context_text']
qas = entry['qas']
# Iterate through each question-answer pair
for qa in qas:
question = qa['query_text']
answers = qa['answers']
# Add each answer to the extracted data list
for answer in answers:
extracted_data.append({
'question': question,
'answer': answer,
'Title': title,
'Context Text': context_text,
'Context ID': context_id
})
# Convert the extracted data to a pandas DataFrame
df = pd.DataFrame(extracted_data)
df.to_csv('cmrc2018_sampled.csv', index=False)
print(df.head())
加载数据,自定义数据集
import dspy
from dspy.datasets import DataLoader
from dspy.retrieve.faiss_rm import FaissRM
from dsp.modules.sentence_vectorizer import SentenceTransformersVectorizer
import pandas as pd
dl = DataLoader()
turbo = dspy.OpenAI(model='gpt-3.5-turbo')
# 从CSV文件加载数据集
dataset = dl.from_csv(
f"cmrc2018_sampled.csv",
fields=("question", "answer"),
input_keys=("Title", "question"))
# 划分训练集和测试集
splits = dl.train_test_split(dataset, train_size=0.8)
trainset = splits['train']
devset = splits['test']
# 将训练和测试数据集生成数据库
document_chunks = df['Context Text'].drop_duplicates().tolist()
vectorizer = SentenceTransformersVectorizer(
model_name_or_path="distiluse-base-multilingual-cased-v2", # 模型名称或路径
)
# 使用 Faiss 进行检索
frm = FaissRM(document_chunks, vectorizer=vectorizer)
dspy.settings.configure(lm=turbo, rm=frm)
trainset_q = [x.with_inputs('question') for x in trainset]
devset_q = [x.with_inputs('question') for x in devset]
DSPy适用于各种应用和任务。在本介绍性notebook中,我们将以数据库检索问答(QA)为示例任务进行工作。DSPy通常只需要非常少量的标注。虽然你的管道可能涉及六到七个复杂步骤,但你只需要标注初始问题和最终答案。DSPy会自动生成支持你的管道所需的任何中间标注。
查看示例数据
Repo-office|Repo-custom
train_example = trainset[0]
print(train_example)
print(f"Question: {train_example.question}")
print(f"Answer: {train_example.answer}")
dev_example = devset[10]
print(f"Question: {dev_example.question}")
print(f"Answer: {dev_example.answer}")
2.2 定义程序流程
在DSPy中,我们将以声明方式定义模块与在pipeline中调用它们以解决任务之间保持清晰的分离。
这让你能够专注于pipeline的信息流。DSPy会接管你的程序,并自动优化如何提示(或微调)语言模型以适应你的特定pipeline,使其效果良好。
在实际操作之前,先来了解一些关键部分。
使用语言模型:签名与预测器
在DSPy程序中,每次调用语言模型(LM)都需要有一个签名。
签名由三个简单元素组成:
- 一个关于语言模型要解决的子任务的简要描述。
- 描述我们将提供给语言模型的一个或多个输入字段(例如输入的问题)。
- 描述我们期望从语言模型获取的一个或多个输出字段(例如问题的答案)。
让我们为基本的问答定义一个简单的签名
Repo-office
class BasicQA(dspy.Signature):
"""Answer questions with short factoid answers."""
question = dspy.InputField()
answer = dspy.OutputField(desc="often between 1 and 5 words")
Repo-custom
class BasicQA(dspy.Signature):
"""Answer questions with short factoid answers."""
question = dspy.InputField()
answer = dspy.OutputField(desc="请简洁的回答问题")
在 BasicQA类 中,文档字符串描述了这个子任务(即回答问题)。每个 InputField 或 OutputField 可以选择包含一个描述 desc。如果没有提供描述,将从字段名称(例如 question)推断。
既然我们有了签名,现在让我们定义并使用一个预测器。预测器是一个知道如何使用语言模型来实现签名的模块。重要的是,预测器可以学习以适应任务的行为!
Repo-office|Repo-custom
generate_answer = dspy.Predict(BasicQA)
# Call the predictor on a particular input.
pred = generate_answer(question=dev_example.question)
# Print the input and the prediction.
print(f"Question: {dev_example.question}")
print(f"Predicted Answer: {pred.answer}")
print(f"label Answer: {dev_example.answer}")
# 查看直接的推理历史记录
turbo.inspect_history(n=1)
使用CoT思维链
加入CoT思维链使得模型重新回答,并输出思考过程
Repo-office|Repo-custom
# Define the predictor. Notice we're just changing the class. The signature BasicQA is unchanged.
generate_answer_with_chain_of_thought = dspy.ChainOfThought(BasicQA)
# Call the predictor on the same input.
pred = generate_answer_with_chain_of_thought(question=dev_example.question)
# Print the input, the chain of thought, and the prediction.
print(f"Question: {dev_example.question}")
print(f"Thought: {pred.rationale}")
print(f"Predicted Answer: {pred.answer}")
例如 Repo-custom的输出为
Question: 四川地区,将五月艾称之为什么?
Thought: Answer: 将五月艾称为“五月菠菜”。
Predicted Answer: 将五月艾称为“五月菠菜”。
使用检索模型
检索模型就是根据向量匹配度从之前定义好的数据库中检索到背景知识,用于后续和prompt一起送进大模型。 使用检索器非常简单。模块 dspy.Retrieve(k) 将搜索与给定查询最匹配的前k个段落。
Repo-office|Repo-custom
retrieve = dspy.Retrieve(k=3)
print(retrieve(dev_example.question))
topK_passages = retrieve(dev_example.question).passages
print(f"Top {retrieve.k} passages for question: {dev_example.question} \n", '-' * 30, '\n')
for idx, passage in enumerate(topK_passages):
print(f'{idx+1}]', passage, '\n')
你也可以随时检索任何信息:例如检索 china
retrieve("china").passages[0]
基础检索增强生成(“RAG”)
我们将构建一个检索增强的答案生成管道。
对于一个问题,我们将在训练数据集中搜索前3个相关段落,然后将它们作为上下文传递给生成模块以生成答案。
首先定义这个签名:context, question --> answer
Repo-office
class GenerateAnswer(dspy.Signature):
"""Answer questions with short factoid answers."""
context = dspy.InputField(desc="may contain relevant facts")
question = dspy.InputField()
answer = dspy.OutputField(desc="often between 1 and 5 words")
Repo-custom
class GenerateAnswer(dspy.Signature):
"""Answer questions with short factoid answers."""
context = dspy.InputField(desc="从数据库中检索相关的背景")
question = dspy.InputField()
answer = dspy.OutputField(desc="请简洁的回答问题")
下面我们需要定义一个用于RAG的执行程序,它需要两个方法:
__init__方法将声明它需要的子模块:dspy.Retrieve和dspy.ChainOfThought。后者用于实现我们的GenerateAnswer签名。forward方法将描述使用这些模块来回答问题的控制流程
Repo-office|Repo-custom
class RAG(dspy.Module):
def __init__(self, num_passages=3):
super().__init__()
self.retrieve = dspy.Retrieve(k=num_passages)
self.generate_answer = dspy.ChainOfThought(GenerateAnswer)
def forward(self, question):
context = self.retrieve(question).passages
prediction = self.generate_answer(context=context, question=question)
return dspy.Prediction(context=context, answer=prediction.answer)
定义了这个程序之后,现在让我们编译它。编译程序将更新每个模块中存储的参数。在我们的设置中,这主要是通过收集和选择好的示例来用在Prompt中。
设置指标和优化器
编译依赖于三件事:
- 一个训练集。 我们将使用上面提到的部分问答示例的trainset
- 一个验证指标。 我们将定义一个快速的validate_context_and_answer函数,检查预测的答案是否正确。
- 一个特定的提示优化器。 DSPy编译器包括许多提示优化器,可以优化你的程序。
不同的提示优化器在优化成本与质量等方面提供了不同的折中方案。在教程中,笔者将使用一个简单的默认提示优化器BootstrapFewShot。
同时定义评估模型validate_context_and_answer用于检查是否问题准确并且检索到准确的背景
Repo-office|Repo-custom
from dspy.teleprompt import BootstrapFewShot
# Validation logic: check that the predicted answer is correct.
# Also check that the retrieved context does actually contain that answer.
def validate_context_and_answer(example, pred, trace=None):
answer_EM = dspy.evaluate.answer_exact_match(example, pred)
answer_PM = dspy.evaluate.answer_passage_match(example, pred)
return answer_EM and answer_PM
# Set up a basic teleprompter, which will compile our RAG program.
teleprompter = BootstrapFewShot(metric=validate_context_and_answer)
# Compile!
compiled_rag = teleprompter.compile(RAG(), trainset=trainset_q
现在可以通过一些提问来进行验证:
例如:
Repo-office
# Ask any question you like to this simple RAG program.
my_question = "What castle did David Gregory inherit?"
# Get the prediction. This contains `pred.context` and `pred.answer`.
pred = compiled_rag(my_question)
# Print the contexts and the answer.
print(f"Question: {my_question}")
print(f"Predicted Answer: {pred.answer}")
print(f"Retrieved Contexts (truncated): {[c[:200] + '...' for c in pred.context]}")
也可以通过 turbo.inspect_history(n=1) 来看到底模型中发生了什么内容。
例如Repo-office 的部分输出:
Context:
[1] «Battle of Kursk | The Battle of Kursk was a Second World War engagement between German and Soviet forces on the Eastern Front near Kursk (450 km south-west of Moscow) in the Soviet Union during July and August 1943. The battle began with the launch of the German offensive, Operation Citadel (German: "Unternehmen Zitadelle" ), on 5 July, which had the objective of pinching off the Kursk salient with attacks on the base of the salient from north and south simultaneously. After the German offensive stalled on the northern side of the salient, on 12 July the Soviets commenced their Kursk Strategic Offensive Operation with the launch of Operation Kutuzov (Russian: Кутузов ) against the rear of the German forces in the northern side. On the southern side, the Soviets also launched powerful counterattacks the same day, one of which led to a large armoured clash, the Battle of Prokhorovka. On 3 August, the Soviets began the second phase of the Kursk Strategic Offensive Operation with the launch of Operation Polkovodets Rumyantsev (Russian: Полководец Румянцев ) against the German forces in the southern side of the Kursk salient.»
[2] «Operation Mars | Operation Mars, also known as the Second Rzhev-Sychevka Offensive Operation (Russian: Вторая Ржевско-Сычёвская наступательная операция), was the codename for an offensive launched by Soviet forces against German forces during World War II. It took place between 25 November and 20 December 1942 around the Rzhev salient in the vicinity of Moscow.»
[3] «Kholm Pocket | The Kholm Pocket (German: "Kessel von Cholm" ; Russian: Холмский котёл ) was the name given for the encirclement of German troops by the Red Army around Kholm south of Leningrad, during World War II on the Eastern Front, from 23 January 1942 until 5 May 1942. A much larger pocket was simultaneously surrounded in Demyansk, about 100 km to the northeast. These were the results of German retreat following their defeat during the Battle of Moscow.»
Question: What is the code name for the German offensive that started this Second World War engagement on the Eastern Front (a few hundred kilometers from Moscow) between Soviet and German forces, which included 102nd Infantry Division?
Reasoning: Let's think step by step in order to produce the answer. We know that the German offensive that started the Battle of Kursk was called Operation Citadel.
Answer: Operation Citadel
---
Context:
[1] «Kerry Condon | Kerry Condon (born 4 January 1983) is an Irish television and film actress, best known for her role as Octavia of the Julii in the HBO/BBC series "Rome," as Stacey Ehrmantraut in AMC's "Better Call Saul" and as the voice of F.R.I.D.A.Y. in various films in the Marvel Cinematic Universe. She is also the youngest actress ever to play Ophelia in a Royal Shakespeare Company production of "Hamlet."»
[2] «Corona Riccardo | Corona Riccardo (c. 1878October 15, 1917) was an Italian born American actress who had a brief Broadway stage career before leaving to become a wife and mother. Born in Naples she came to acting in 1894 playing a Mexican girl in a play at the Empire Theatre. Wilson Barrett engaged her for a role in his play "The Sign of the Cross" which he took on tour of the United States. Riccardo played the role of Ancaria and later played Berenice in the same play. Robert B. Mantell in 1898 who struck by her beauty also cast her in two Shakespeare plays, "Romeo and Juliet" and "Othello". Author Lewis Strang writing in 1899 said Riccardo was the most promising actress in America at the time. Towards the end of 1898 Mantell chose her for another Shakespeare part, Ophelia im Hamlet. Afterwards she was due to join Augustin Daly's Theatre Company but Daly died in 1899. In 1899 she gained her biggest fame by playing Iras in the first stage production of Ben-Hur.»
[3] «Judi Dench | Dame Judith Olivia "Judi" Dench, {'1': ", '2': ", '3': ", '4': "} (born 9 December 1934) is an English actress and author. Dench made her professional debut in 1957 with the Old Vic Company. Over the following few years, she performed in several of Shakespeare's plays in such roles as Ophelia in "Hamlet", Juliet in "Romeo and Juliet", and Lady Macbeth in "Macbeth". Although most of her work during this period was in theatre, she also branched into film work and won a BAFTA Award as Most Promising Newcomer. She drew strong reviews for her leading role in the musical "Cabaret" in 1968.»
Question: Who acted in the shot film The Shore and is also the youngest actress ever to play Ophelia in a Royal Shakespeare Company production of "Hamlet." ?
Reasoning: Let's think step by step in order to produce the answer. We know that the actress we are looking for is the youngest actress ever to play Ophelia in a Royal Shakespeare Company production of "Hamlet." We also know that she acted in the short film The Shore.
Answer: Kerry Condon ---
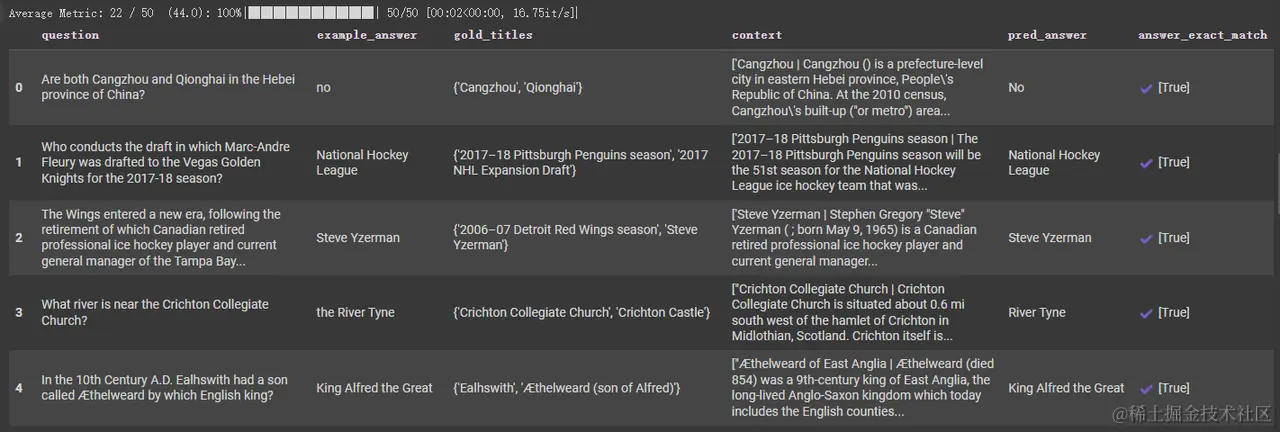
评估
首先,让我们评估预测答案的准确性(精确匹配)。用于后续结果的进一步优化 22/50
Repo-office|Repo-custom
from dspy.evaluate.evaluate import Evaluate
# Set up the `evaluate_on_hotpotqa` function. We'll use this many times below.
evaluate_on_hotpotqa = Evaluate(devset=devset, num_threads=1, display_progress=True, display_table=5)
# Evaluate the `compiled_rag` program with the `answer_exact_match` metric.
metric = dspy.evaluate.answer_exact_match
evaluate_on_hotpotqa(compiled_rag, metric=metric)
例如:Repo-office 的输出 
研究检索的准确性也可能具有指导意义。通常,我们可以检查检索到的段落是否包含答案。 13/50

这可能表明LM经常依赖于它在训练中记忆的知识来回答问题。
三:总结
通过以上的介绍中,基本可以掌握使用在Dspy框架上实现自己数据和模型的推理,至于解决目前这种弱检索问题,使得结果更加精确,可以继续深入官方的教程学习后续更高级搜索行为的代码。
相信您已经掌握了如何在三十分钟内快速上手DSPy框架。无论是自动化Prompt生成还是优化,DSPy都能为您的自然语言处理项目提供极大的帮助。希望您在今后的工作中能够充分利用DSPy,提高开发效率。
如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐

 9
9 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)