StableDiffusion 文生视频教程,从Mov2mov到AnimateDiff
本文介绍了如何使用Stable Diffusion模型进行文生视频的生成,包括三个发展阶段:Mov2mov、ffmpeg + Ebsynth和AnimateDiff。Stable Diffusion是文生视频的扩散模型,具备生成半AI视频和全AI视频的能力。Mov2mov是早期的文生视频插件,通过重新绘制每一帧生成新视频。ffmpeg + Ebsynth以关键帧+插帧为解决方案,提高了视频连贯性。
0. 前言
不知道你在刷各种短视频的时候有没有刷到过类似如下的视频:
这种视频就是AI生成的,准确说是Stable Diffusion生成的半AI视频。
Ebsynth
1. 简介
文生视频就是AI将用户传入的文字prompt生成视频的复杂任务。目前市面上主要分为半AI视频以及全AI视频 by 沃兹基.硕得 。
- 半AI视频:AI以已有视频为蓝本,在其基础上进行换脸、风格转绘等生成新视频的方式。
- 全AI视频:AI完全以用户的prompt为参照,生成符合用户描述的视频。最近大火的Sora就是类似的技术。
Stable Diffusion原本是文生视频的扩散模型,但是基于“视频是图片的延伸”这一观点,网上众多大神在其基础上开发了不同的插件以及辅助模型,使得其具备了文生视频的能力。
由于其本地部署以及低算力、显存的特性,我们本次用其来作为文生视频分享的创作工具。
基于Stable Diffusion做文生视频主要经历了三个发展阶段,印证着由半AI视频到全AI视频的发展历程:
- Mov2mov:早期的文生视频插件,是“视频是图片的延伸”这一观点的直接实现。
- ffmpeg + Ebsynth:由于Mov2mov生成视频连贯性差等缺点,后续又发展出了以关键帧+插帧为解决方案的工具插件,ebsynth是其中的佼佼者。
- AnimateDiff:StableDiffusion开始迈入全AI视频的标志点,通过对每X帧的剧本式描述,生成全AI视频。
2. 文生视频
2.1 Mov2mov
Mov2mov的作者是github 作者Scholar01,其工作原理是提取视频的帧,并根据用户设置的模型和提示词重新绘制每一帧。然后,它将生成的帧组合成一个新的视频,并输出结果。
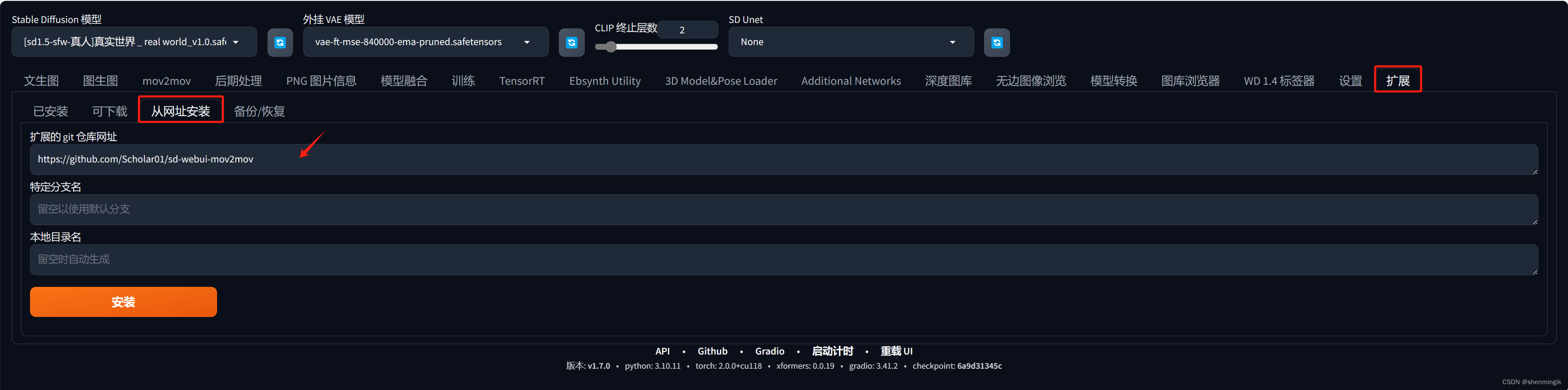
2.1.1 插件安装
点击【WebUI】-> 【扩展】-> 【从网址安装】,输入以下的github 网址:
https://github.com/Scholar01/sd-webui-mov2mov

2.1.2 视频生成
由于其必须基于原始视频,我们可以随意准备一个原始视频:
Stable 文生视频原始图片
准备正向提示词:

<lora:真人-顾清寒:0.8>,guqinghan,full body:1.2,Medium breast,beautiful detailed girl, light on face,cinematic lighting,1girl,looking at viewer,masterpiece, best quality, unity 8k wallpaper,(raw photo:1.2),((photorealistic:1.4)),best quality ,masterpiece, illustration, an extremely delicate and beautiful
反向提示词:
(badhandv4:1.2),ng_deepnegative_v1_75t,negative_hand-neg,(worst quality:2),(low quality:2),(normal quality:2),lowres,bad anatomy,bad hands,normal quality,((monochrome)),((grayscale)),Freckles,Too many hands and feet,Excess legs,Wrong human body structure
设置其他参数:
迭代步数:38
采样方法:DPM++ 2M SDE Karras
图片尺寸:512*768
重绘幅度:0.4
MoiveFPS:45帧
ControlNet:OpenPose_hand

点击生成即可:

最后我们就可以看到转绘结果:
Mov2mov转绘制
可以看到,mov2mov生成的视频的背景以及人物衣服在每一帧的变化都很大,人眼看起来不连贯,给人错乱的感觉。
2.2 ffmpeg + Ebsynth
Ebsynth的原理就是找出图片之中多个关键帧,对每一帧关键帧进行蒙版重绘,之后通过智能插帧的方式将多个关键帧连接起来,生成丝滑视频。
2.2.1 ffmpeg 安装
官网:ffmpeg
首先进入官网,选择合适的版本进行下载:

下载完后,我们对压缩包进行解压,会得到一个文件夹,将其命名为ffmpeg。

最后,将对应的可执行文件添加到系统的环境变量之中。
2.2.2 Ebsynth安装
官网:ebsynth
同样,到官网我们下载一下Ebsynth,下载完解压即可,不需要额外的操作。

2.2.3 Ebsynth 插件安装
第三个就是需要在Stable Diffusion之中安装一个叫做Ebsynth的扩展,我们使用老方式即可安装:
插件网址:https://github.com/s9roll7/ebsynth_utility

安装完之后,我们还需要安装transparent-backgroud插件,此插件用于进行蒙版识别裁剪,使用如下的指令即可安装:
pip install transparent-background
2.2.4 视频生成
Ebsynth这套解决方案的步骤会稍微复杂一些,总共分为8步,我们仅用到其中的以下几步即可:
- Step1: 蒙版裁剪
2.2.4.1 Step 1 蒙版裁剪
首先设置一下视频的文件和我们此次视频的工程目录:

然后设置一下蒙版参数,用于从原视频之中截取关键帧以及蒙版信息:

然后点击生成,我们就能在对应的工程目录之下得到如下的视频处理结果:
- video_frame: 视频帧
- video_mask: 视频帧蒙版信息

视频蒙版就是用来表示视频主体的技术,如下图:

2.2.4.2 Step2 识别关键帧
第二步,识别关键帧,在这一步,我们设置一下最小最大间隔,插件就会智能从刚刚的视频帧之中识别出关键帧。我们点击生成:

在工程目录下就会得到一个还有关键帧的文件夹。

2.2.4.3 Step3~4 关键帧重绘
之后利用StableDiffusion的批量图生图重绘能力,我们对刚刚得到的关键帧进行重绘。同样的,我们需要输入一些提示词:

重绘完成之后,我们就会在对应的工程目录之中得到如下的图生图文件:

2.2.4.3 Step5~6 生成Ebsynth工程文件
点击步骤5,生成Ebsynth工程文件:

运行完成之后,我们就能够在对应的文件夹之中得到多个ebs后缀的文件:

逐个双击打开文件,就会跳转到ebsynth之中,这一步是在不同的关键帧之中进行插帧处理,点击运行:

Ebsynth运行结束之后,就会在对应的文件目录下方生成视频处理结果:

2.2.4.3 Step7 合成帧,生成视频
最后,点击第七步,图片合成视频!

程序运行结束,我们就能在工程目录下找到两个视频文件:

Ebsynth
2.3 AnimateDiff
早起的半AI视频解决方案都是基于逐帧重绘的思路,但是具有闪烁严重以及耗时漫长等缺陷。
由于帧之间包含的运动元素是具有规律以及关联性的,AnimateDiff基于此对视频片段进行训练,让AI学习不同类型视频的运动方式,单独训练出了一个运动模块:Motion Module。

2.3.1 插件安装
同样,直接在StableDiffusion 之中通过网址安装此插件即可.
插件网址:https://github.com/continue-revolution/sd-webui-animatediff/

2.3.2 模型下载
使用AnimateDiff之前需要去HuggingFace下载一下对应的运动大模型:
模型地址:https://huggingface.co/guoyww/animatediff/tree/main

下载完成之后,需要将对应模型放到AnimateDiff 扩展的modle目录下面:

2.3.3 视频生成
首先我们先生成一张比较满意的图像,比如说:
1girl, upper body, detailed face, looking at viewer, outdoors, upper body, standing, best quality, unity 8k wallpaper,(raw photo:1.2),((photorealistic:1.4)),best quality ,masterpiece, illustration, an extremely delicate and beautiful
反向提示词:
(badhandv4:1.2),ng_deepnegative_v1_75t,negative_hand-neg,(worst quality:2),(low quality:2),(normal quality:2),lowres,bad anatomy,bad hands,normal quality,((monochrome)),((grayscale)),Freckles,Too many hands and feet,Excess legs,Wrong human body structure
设置其他参数:
迭代步数:30
采样方法:DPM++ 2M SDE
随机种子:
(需要固定)
之后点开AnimateDiff选项卡,设置相关参数,点击生成即可:

生成过程中,其就会按照运动推理的逻辑为我们生产这样一系列连续且相似的动画帧。

2.3.3.1 AnimateDiff参数
在生成动画的过程之中,发挥核心作用的就是运动模块,到目前为止总共有三代模型,其中v2、v3模型效果显著好于初始模型:

其他参数如下:
| 参数 | 解释 |
|---|---|
| 上下文单批数量 | 运动模块单运行批次输入绘制的图片数量 |
| 闭环 | N:不循环 A:总是循环 R+P:半循环 |
| 帧数、帧率 | 视频长度,帧数/帧率 |
| 帧插值 | AnimateDiff不支持高帧率绘制,使用此对关键帧进行插帧 |
2.3.3.2 剧本式生成
最后,我们来体验一下AnimateDiff最强大的能力:Prompt Travel,即通过在不同的帧输入不同的提示词来达到类似剧本式的视频能力。
想要使用这个也很简单,直接控制提示词即可,下面是一个夏东
两个季节变换的例子:
1girl, upper body, detailed face, looking at viewer, outdoors, upper body, standing, outdoors,
0: (spring:1.2), cherry blossoms, falling petals, pink theme,
16: (summer:1.2), sun flowers, hot summer, green theme
best quality, unity 8k wallpaper,(raw photo:1.2),((photorealistic:1.4)),best quality ,masterpiece, illustration, an extremely delicate and beautiful
反向提示词:
(badhandv4:1.2),ng_deepnegative_v1_75t,negative_hand-neg,(worst quality:2),(low quality:2),(normal quality:2),lowres,bad anatomy,bad hands,normal quality,((monochrome)),((grayscale)),Freckles,Too many hands and feet,Excess legs,Wrong human body structure

参考文献
[1] Stable Diffusion风格转换插件-EBSynth操作指南
[2] 10倍效率,打造无闪烁丝滑AI动画!EbSynth插件全流程操作解析与原理分析,超智能的“补帧”动画制作揭秘!| Stable Diffusion扩展插件教程
[3] AI视频时代的“开源先驱”:Sora来之前,你可以先掌握这些——AnimateDiff动画插件全方位教学,制作丝滑流畅动图!Stable Diffusion应用

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 25
25 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)