《深度学习之迁移学习》详解
迁移学习是一种先进的机器学习技术,它允许将一个任务中获得的知识迁移到另一个相关任务上,尤其适用于数据量有限或难以获取标注数据的情况。它基于不同任务之间存在相关性的原则,通过迁移预训练模型的参数来加速新任务的学习过程,并提高模型性能。
《迁移学习》
一、什么是迁移学习
迁移学习(Transfer learning) 顾名思义就是就是把已学训练好的模型参数迁移到新的模型来帮助新模型训练。考虑到大部分数据或任务是存在相关性的,所以通过迁移学习我们可以将已经学到的模型参数(也可理解为模型学到的知识)通过某种方式来分享给新模型从而加快并优化模型的学习效率不用像大多数网络那样从零学习(starting from scratch,tabula rasa)。
迁移学习的本质是适应(adaptation)。适应可以是适应一个任务、适应一种模态、适应一个领域、适应一种语言、适应一份新数据等。所谓“适应”,有两方面的内涵:一是只有已经能用的东西才能“适应”新东西,二是这个能用的东西需要在别的场景下发挥作用。
在传统分类学习中,为了保证训练得到的分类模型具有准确性和高可靠性,都有两个基本的假设:
(1) 用于学习的训练样本与新的测试样本满足独立同分布;
(2) 必须有足够可用的训练样本才能学习得到一个好的分类模型。
但是,在实际应用中这两个条件往往无法满足。首先,随着时间的推移,原先可利用的有标签样本数据可能变得不可用,与新来的测试样本的分布产生语义、分布上的缺口。另外,有标签样本数据往往很缺乏,而且很难获得。这就引起了机器学习中另外一个重要问题,如何利用少量的有标签训练样本或者源领域数据,建立一个可靠的模型对具有不同数据分布的目标领域进行预测。
迁移学习是运用已存有的知识对不同但相关领域问题进行求解的新的一种机器学习方法。它放宽了传统机器学习中的两个基本假设,目的是迁移已有的知识来解决目标领域中仅有少量有标签样本数据甚至没有的学习问题[1]。在美国国防部高级研究计划局的信息处理技术办公室发表的公告中,给出的迁移学习的定义是:
把之前任务中学习到的知识和技能应用到新的任务中的能力。
迁移学习是机器学习领域中的一种技术,它涉及将从一个任务学到的知识应用到另一个不同但相关的任务上。这种方法特别适用于新任务的数据量有限的情况,或者新任务的标注数据获取成本很高时。通过迁移学习,可以利用已有的模型(通常是在大数据集上预训练的模型)来加速新任务的学习过程,并提高模型的性能。
例如将猫狗分类的学习模型迁移到其它相似的任务上面,用来分辨老鹰和布谷鸟(因为都是拍摄的真实图片,所以属于相同的域,抽取特征的方法相同),或者是分别卡通图像(卡通图像和真实图片属于不同的域,迁移时要消除域之间的差异)


了解迁移学习中有两对主要的概念,域和任务以及源和目标:
Domain(域):包括两部分:feature space(特征空间)和probability(概率)。所以当domain不同的时候,分两种情况。可能是feature space不同,也可能是feature space一样但probability不同;
Task(任务):包括两部分: label space(标记空间)和objective predictive function(目标预测函数)。同理,当task不同的时候,也分两种情况。可能是label space不同,也可能是label space一样但function不同;
**Source(源)**是用于训练模型的域/任务;
Targe(任务)是要用前者的模型对自己的数据进行预测/分类/聚类等机器学习任务的域/任务。
迁移学习广泛存在于人类的活动中,两个不同的领域共享的因素越多,迁移学习就越容易,否则就越困难,甚至出现“负迁移”,产生副作用。所以迁移学习的能力也是有限的,我们需要关注迁移学习的边界在哪里,以在迁移之前先看看source和domain之间的transferability(可迁移性)。近十几年来,很多学者对迁移学习展开了广泛的研究,而且很多集中在算法研究上,即采用不同的技术对迁移学习算法展开研究。
二、分类
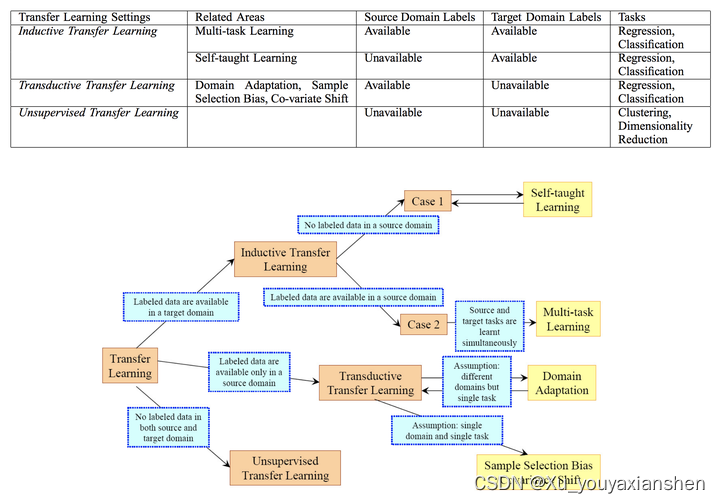
2010年时Sinno Jialin Pan和 Qiang Yang[2]详细介绍了迁移学习的分类问题。当以迁移学习的场景为标准时分为三类,如图 1:归纳式迁移学习(Inductive Transfer Learning)、直推式迁移学习(Transductive Transfer Learning)、和直推式迁移学习(Unsupervised Transfer Learning)。


根据迁移的知识表示形式又可以分为四类:基于实例的迁移学习(instance-based transfer learning)、基于特征表示的迁移学习(feature-representation transfer learning)、基于参数的迁移学习(parameter-transfer learning、基于关系的迁移学习(relational-knowledge transfer learning)。
基于实例的迁移学习:通过将源任务中的实例(或数据点)迁移到目标任务中来实现知识的迁移。
基于特征的迁移学习:将源任务中学习到的特征表示迁移到目标任务中,这些特征可能在源任务和目标任务之间共享。
基于模型的迁移学习:直接迁移源任务中训练好的模型参数到目标任务中,可能需要对模型进行一些调整或微调(Fine-tuning)。
基于关系的迁移学习:在某些情况下,源任务和目标任务之间的知识迁移是基于它们之间的关系,而不仅仅是特征或实例。

迁移学习在许多领域都有应用,包括计算机视觉、自然语言处理、语音识别等。例如,在计算机视觉中,一个在大规模图像数据集上训练好的深度学习模型(如ImageNet上的模型)可以被迁移到较小的特定任务上,如医学图像分析,通过微调模型的某些层来适应新任务。
下表是总结的各种迁移学习与传统机器学习之间的关系:

表 1 迁移学习与传统机器学习的关系对比]
优势
迁移学习的关键优势在于它能够利用已有的知识和资源,减少对大量标注数据的依赖,加快学习速度,并在新任务上获得更好的性能。
三、为什么要进行迁移学习
使用深度学习技术解决问题的过程中,最常见的障碍在于:模型有大量的参数需要训练,因此需要海量的训练数据作支撑,在面对某一领域的具体问题时,通常可能无法得到构建模型所需的规模的数据。借助迁移学习,在一个模型训练任务中针对某种类型数据获得的关系也可以轻松地应用于同一领域的不同问题

迁移学习的关键优势在于它能够利用已有的知识和资源,减少对大量标注数据的依赖,加快学习速度,并在新任务上获得更好的性能。
四、学习路线?

第一阶段:基础知识
机器学习基础
学习机器学习的基本概念,包括监督学习、无监督学习、强化学习等。
理解过拟合、欠拟合、模型评估、特征工程等关键概念。
深度学习基础
学习深度学习的基本原理,包括神经网络、前馈网络、反向传播等。
熟悉常见的深度学习框架,如TensorFlow或PyTorch。
数据预处理
学习数据清洗、标准化、归一化、特征编码等预处理技术。
第二阶段:迁移学习理论
迁移学习概念
理解迁移学习的定义、目标和应用场景。
学习迁移学习的不同类型和策略。
特征提取与迁移
学习如何从源任务中提取有用的特征,并迁移到目标任务。
模型微调
理解模型微调的概念,包括冻结层、解冻层、学习率调整等。
第三阶段:实践与应用
预训练模型
熟悉常用的预训练模型,如VGG、ResNet、BERT等。
学习如何使用这些模型作为迁移学习的起点。
项目实践
选择一个具体的应用领域,如图像分类、文本分类或语音识别。
实践迁移学习流程,包括数据准备、模型选择、迁移策略设计、模型微调等。
性能评估
学习如何评估迁移学习模型的性能,包括准确率、召回率、F1分数等。
第四阶段:高级主题
多任务学习
探索多任务学习与迁移学习的关系和应用。
零样本学习与少样本学习
学习零样本学习和少样本学习的概念和方法。
迁移学习中的挑战与解决方案
研究迁移学习中的常见问题,如领域适应、负迁移等,并探索解决方案。
第五阶段:研究与创新
最新研究
阅读最新的学术论文,了解迁移学习的最新进展和趋势。
创新项目
设计和实现自己的迁移学习项目,解决实际问题。
社区参与
加入机器学习和迁移学习的社区,参与讨论和分享。
资源推荐
在线课程:如Coursera、edX、Udacity等平台上的机器学习和深度学习课程。
书籍:如《深度学习》(Ian Goodfellow et al.)、《机器学习》(Tom Mitchell)等。
研究论文:通过Google Scholar、arXiv等平台查找相关论文。
开源项目:GitHub上的相关项目和代码库。
学习计划
每日学习:每天安排固定时间学习理论和实践。
项目实践:定期进行实践项目,将理论应用到实际中。
社区互动:积极参与线上和线下的机器学习社区。
通过遵循这个路线,你可以系统地学习迁移学习,并逐步提高你的技能和知识。记住,实践是学习的关键,不断尝试和实验将帮助你更好地理解和掌握迁移学习。
五、迁移学习研究现状总结
迁移学习已在文本分类、文本聚类、情感分类、图像分类、协同过滤等方面进行了应用研究。下面我们将根据迁移学习知识的表示形式分类方式进行研究总结。
基于实例的迁移学习方法代表有Dai 等人[3]提出的基于实例的 TrAdaBoost 迁移学习算法。当目标域中的样本被错误地分类之后,可以认为这个样本是很难分类的,因此增大这个样本的权重,在下一次的训练中这个样本所占的比重变大。如果源域中的一个样本被错误地分类了,可以认为这个样本对于目标数据是不同的,因此降低这个样本的权重,降低这个样本在分类器中所占的比重。Masashi Sugiyama等人[4],考虑了模型选择的重要性,在协变量变换下,根据测试和训练输入密度的比例一致,标准学习方法(如最大似然估计)不再是一致加权变量,首先分别估计训练和测试输入密度,然后通过取估计密度的比率来估计重要性。
基于特征的迁移学习方法可以分为基于特征选择的迁移学习方法和基于特征映射的迁移学习方法。基于特征选择的迁移学习方法是识别出源领域与目标领域中共有的特征表示,然后利用这些特征进行知识迁移。Jiang等人[5]认为与样本类别高度相关的那些特征应该在训练得到的模型中被赋予更高的权重,因此他们在领域适应问题中提出了一种两阶段的特征选择框架。第一阶段首先选出所有领域(包括源领域和目标领域)共有的特征来训练一个通用的分类器;然后从目标领域无标签样本中选择特有特征来对通用分类器进行精化从而得到适合于目标领域数据的分类器。Dai等人[6]提出了一种基于联合聚类(Co-clustering)的预测领域外文档的分类方法CoCC,该方法通过对类别和特征进行同步聚类,实现知识与类别标签的迁移。CoCC算法的关键思想是识别出领域内(也称为目标领域)与领域外(也称为源领域)数据共有的部分,即共有的词特征。然后类别信息以及知识通过这些共有的词特征从源领域传到目标领域。Fang等人[7]利用迁移学习对跨网络中的协作分类进行研究,试图从源网络迁移共同的隐性结构特征到目标网络。该算法通过构造源网络和目标网络的标签传播矩阵来发现这些隐性特征。
基于特征映射的迁移学习方法是把各个领域的数据从原始高维特征空间映射到低维特征空间,在该低维空间下,源领域数据与目标领域数据拥有相同的分布。这样就可以利用低维空间表示的有标签的源领域样本数据训练分类器,对目标测试数据进行预测。Pan等人[8]提出了一种新的维度降低迁移学习方法,他通过最小化源领域数据与目标领域数据在隐性语义空间上的最大均值偏差(Maximun Mean Discrepancy),从而求解得到降维后的特征空间。在该隐性空间上,不同的领域具有相同或者非常接近的数据分布,因此就可以直接利用监督学习算法训练模型对目标领域数据进行预测。Blitzer等人[9]提出了一种结构对应学习算法(Structural Corresponding Learning, SCL),该算法把领域特有的特征映射到所有领域共享的“轴”特征,然后就在这个“轴”特征下进行训练学习。
基于模型的迁移学习方法由源域学习到的模型应用到目标域上,再根据目标域学习新的模型。代表工作有中科院计算所的Zhao等人[10]提出了TransEMDT方法。该方法首先针对已有标记的数据,利用决策树构建鲁棒性的行为识别模型,然后针对无标定数据,利用K-Means聚类方法寻找最优化的标定参数。在2014年的CVPR上Oquab等人[11]提出了TRCNN,主要解决深度学习需要大量的数据,对于小的数据集,如何进行深度学习训练的问题。作者提出了可以在大型数据集(如ImageNet)上进行预训练,然后将训练好的网络权重迁移到小的数据集,即用小的数据集对网络进行微调,从而使网络可以适用于小的数据集。
基于关系的迁移学习方法利用源域学习逻辑关系网络,再应用与目标域上。这种方法比较关注源域和目标域的样本之间的关系。就目前来说,基于关系的迁移学习方法的相关研究工作非常少,仅有几篇连贯式的文章讨论,这些文章都借助于马尔科夫逻辑网络(Markov Logic Net)来挖掘不同领域之间的关系相似性。如Davis等人[12]提出的二阶马尔科夫逻辑。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)