科研学习|研究方法——扎根理论三阶段编码如何做?
主题标引”意指对文献内容进行分析, 然后对文献所表达的中心思想、所讨论的基本问题以及研究的对象等进行提取, 以形成主题概念, 然后在此基础上把可检索的主题词表示出来, 再将这些主题词按一定顺序 (如字顺) 排列, 对论述相同主题内容的文献加以集中, 从而提高文献的查全率与查准率。而在主题标引的过程中, 主题词的提取是非常关键的步骤之一, 但目前国内对主题词提取的相关实践, 一方面较偏重主题词的词义
一、背景介绍
“主题标引”意指对文献内容进行分析, 然后对文献所表达的中心思想、所讨论的基本问题以及研究的对象等进行提取, 以形成主题概念, 然后在此基础上把可检索的主题词表示出来, 再将这些主题词按一定顺序 (如字顺) 排列, 对论述相同主题内容的文献加以集中, 从而提高文献的查全率与查准率。
而在主题标引的过程中, 主题词的提取是非常关键的步骤之一, 但目前国内对主题词提取的相关实践, 一方面较偏重主题词的词义本身, 忽略主题词之间可能存在某种相互链接的“关系”;另一方面, 主题词的提取过程也缺乏一种可供检验的可视化路径。据此, 研究者尝试以“扎根理论”中的三阶段编码为方法, 希望能拓展相关思路, 为主题词的提取提供一定的帮助。
二、扎根理论研究法与辅助软件Atlas.ti的使用
2.1 扎根理论的缘起
一直以来, 量化研究因为遵循设定的步骤, 比较客观严谨, 有共识性的准绳来评价一个研究的严谨程度 (信度、效度) , 而广受学界的认可[1]。与此相反, 质性研究由于多是研究者通过访谈、观察、记录田野所发生事件来开展研究进路, 故主观性较高, 不容易形成普遍性的解释或通则, 很难进行有系统的比较, 加上又缺乏统一的标准, 故而长期被认为不符合科学要求, 最多只能作为辅助量化研究开展的前期铺垫。直到20世纪60年代Strauss和Corbin提出了扎根理论, “填平理论研究与经验研究之间尴尬的鸿沟”[2], 使得质性研究方法获得突破, 彻底扭转了量化研究占据主导地位、质性研究被严重低估的情况。
扎根理论是Glaser和Strauss在1967年共同提出的质性资料系统分析与理论构建的研究方法[3]。在扎根理论刚提出时, 存在着一些问题, 后来经过这两位学者以及其他研究者持续的补充与修正并提出更具体的数据分析技术和程序, 才使得扎根理论逐渐成熟。目前, 扎根理论被视为质性研究中最科学的一种研究方法[4]。
2.2 扎根理论的策略
扎根理论在提出时即融合了实证主义和实用主义两种哲学思维, 并遵循一套严格而系统化的步骤与程序, 包括开放编码、主轴编码与选择性编码, 以追求对数据的充分理解。同时并在符合逻辑及可重复检验的前提下, 由下而上逐步对研究数据进行提取并加以凝练, 进而构建“能解决问题的理论”, 让质性研究从描述走向解释与理论构建。换句话说, 扎根理论与一般常见的实证或后实证范式下的研究程序不同, 不会特意依据特定理论事先提出具体的研究概念与架构、假设来进行验证, 而是随着研究进度与数据编码过程, 逐渐扩充、舍弃或持续发展新的概念, 并针对研究核心现象提出一套说明性的诠释架构。因此可以说, 扎根理论所构建出的概念, 以及概念与概念间的关系, 是扎根于数据, 通过反复验证后而自然萌生。据此, 研究者认为在这方面补充了主题词提取时的两大空白——解释 (而非仅仅描述) 主题词的如何产生, 以及呈现了不同主题词彼此之间可能存在的内部联系。
2.3 扎根理论的具体思路
承上所述, 扎根理论严格说来并非“理论”, 而是一种构建理论的方法——研究者通过将收集的数据打散后、分别赋予概念 (conceptualized) , 重新命名, 再通过概念间彼此的关系隶属, 分别归类成类属过程, 经由这个分析、演绎与归纳的过程, 扎根理论替研究者形塑出一套结构严谨的理论构建程序。据此, 可以明显发现概念 (concepts) 、类属 (categories) 及命题 (proposition) 乃是扎根理论的三大基本要素。
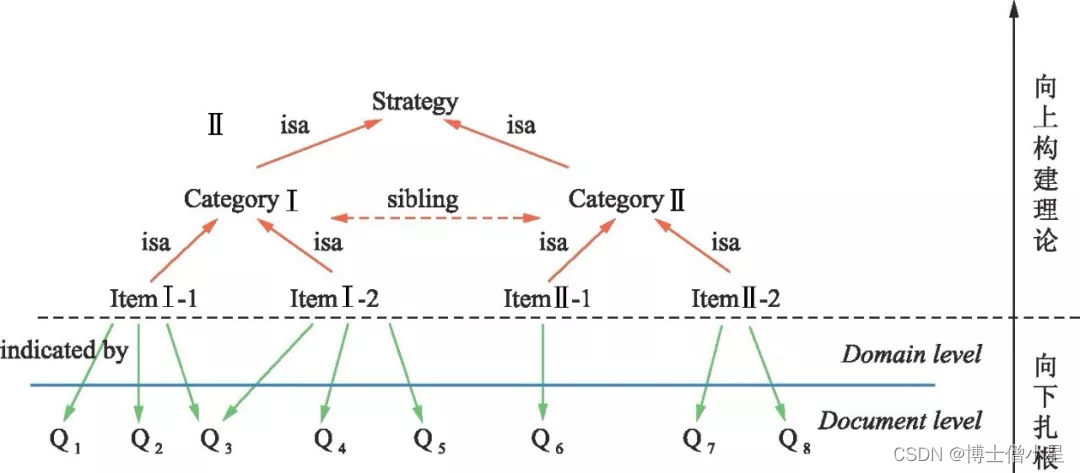
扎根理论的具体思路则始于对现实世界的观察, 研究者通过田野调查获取资料, 然后再从丰富的现实资料中提炼出概念, 再把相似概念归纳为范畴[5]。这样, 利用编码使得归纳、演绎二者得以交替运行, 进而将把庞大的田野数据进行数据缩减、转化、抽象化成为概念, 让译码中的主要范畴以及范畴间关系得以呈现 (见图1) 。而这个范畴亦可视为是主题词的提取, 由此, 我们得以揭示主题词提取的合理性以及主题词彼此间的内在联系。
2.4 辅助软件Atlas.ti的选用
一般来说, 质性研究者经常要处理多样性的研究素材, 如文本资料、信件、手写稿、观察笔记、访谈录音、记录照片、活动影片、网络讨论文章和网页数据等。为了协助研究者进行相关研究, 学界已开发了数十种的辅助分析软件。其中, 最常用的以编码为理论基础的软件有两种, 一种是柏林科技大学心理系1989年开始发展的Atlas.ti;另外一种是澳大利亚拉筹伯大学计算机科学系从1981年开始发展的Nudist/Nvivo[6]。而由于Atlas.ti具备以下特性: (1) 通过系统性的管理功能, 协助研究者比较各种数据, 以深度挖掘各数据彼此的关联性; (2) 高弹性的编码工具与拖曳式的译码整理机制, 能够更直观地进行概念聚拢和类别整并; (3) 图形化网状系统编辑器除了能够编辑概念网络图外, 还可以进行可视化处理, 协助研究者构建模型。据此, 本研究采用Atlas.ti 5.2 (繁体版) , 作为辅助分析工具。

三、扎根理论三阶段编码内涵
扎根理论以概念作为分析单位, 将访谈稿, 文件中的字句、大意, 或者是观察到的现象, 从既有的脉络中提取出来, 分解成一个个独立的观念、思维, 再对这些观念、思维进行重新命名, 使得它们能够被群组起来, 进而得以对其进行重新分类。这个对句子或段落命名的动作, 即是“编码”[7];而对概念命名的目的, 则是为了让研究者能够将类似的事件、事例、事物等加以群组, 并归类在一个共同的标题或分类之下[8]。扎根理论主要通过开放、主轴、选择等三阶段的编码, 提取事例或事件所共同的特征或相关的意义, 使得它们能够被群组起来, 以下分别阐述之。
3.1 开放性编码的内涵
开放编码是通过对现象的仔细研究, 以便进行命名和分类的分析工作, 亦即分析、检视数据并对其进行概念化的归纳、比较的过程。开放性编码的目的是从资料中发现概念类属, 对类属加以命名确定类属的属性和维度, 然后对研究的现象加以命名及类属化[9]。开放编码的过程类似于一个漏斗, 由一个较为宽广的范围逐渐缩小和集中, 直到译码呈现饱和。在开放编码的过程中, 会产生十几个甚至上百个概念, 因此研究人员必须将相似的概念分类, 进而成为类属 (categories) 。而此阶段中的类属概念是暂时性的, 随时可能会因为新发现而出现必须修改的情况。
在开放性编码的阶段, 对概念的命名一般采用三种方式: (1) 由研究者自行创建:研究者在数据对比测试的背景下, 借由事物所唤起的意义或意象, 授予能反映该意义或意象的名字; (2) 沿用已存在学术文献中的名字:这样的命名, 因为概念本身已包含了极为丰富的分析意义, 且都是已经发展得近乎完整的概念, 故而非常严谨, 但缺点则是缺乏弹性, 未必能与自己想表达的概念一致; (3) 见实编码 (Code in vivo) :研究者从受访者本身所使用的话语中所撷取字词作为编码。
3.2 主轴性编码的内涵
主轴编码是借由演绎与归纳, 通过不断比较的方法将近似编码链接在一起的复杂过程[10]。其主要任务是选择和构建主要类目的内容, 并将主要概念类属与次要概念类属连接起来, 以重新组织数据。主轴编码进行的步骤分别是: (1) 检查各次要概念类属与各现象彼此的关系, 在这个基础上思考主要概念类属与次概念类属间可能存在的假设性关系; (2) 检证实际资料是否支持上述这种假设性的关系; (3) 持续不断地寻找主要概念类属与次概念类属的性质, 并从实际的个案中确认它们在个别面向上的定位 (dimensional locations) ; (4) 检证实际应用数据中的证据、事故、事件, 并予以解释、说明。通过反复推导和归纳整理, 研究者将开发出一些针对研究现象的概念类属。
3.3 选择性编码的内涵
数据分析的最后阶段称之为选择性编码, 这一阶段的主要工作是通过整合与凝练, 在所有命名的概念类属中, 觉性一个“核心类属” (core category) 。核心类属是浓缩所有分析结果后得到的关键词, 这几个关键词足以说明整个研究的内涵, 即使条件改变导致所呈现出的现象有所不同, 但仍具备解释效力。
在选择核心类属后, 选择性编码主要通过5个步骤: (1) 创建一条清楚明确的故事线 (story line) ; (2) 通过译码范式模型连接主要概念类属之次概念类属; (3) 在面向的层级 (dimensional level) 发展派系类型; (4) 通过数据检证各派系中概念类属间的关系; (5) 填满可能需要补充或发展的类属。通过这些步骤, 研究者得以发展派系类型, 并在此基础上构建理论。
四、相关个案研究分析
为了表彰本研究的代表性, 本研究对2011-2016年《图书馆杂志》收录的文章进行检索后, 以被引频次最高的《图书馆需要怎样的“大数据”》一文为个案 (被引163次, 检索日期2017.3.25) , 尝试通过三阶段的编码, 揭示该文6个主题词 (大数据、云计算、非结构化、深度分析、Hadoop、Map Reduce) 的提取过程。
4.1 文献内容的概念提取
开放性编码是密集的检测数据, 以便对现象命名及进行概念化和类别化处理的过程。研究者吸收开放性编码的内涵后, 对文献内容 (7 967个文字) 进行概念提取。在操作步骤上, 研究者首先将文字内容存储为word文稿, 再将word文稿载入Atlas.ti 5.2软件 (繁体版) 中进行开放性编码;而在这个阶段, 研究者担心语意误差导致分析错误, 故除原话字数过多而不得不删减外, 其他皆采取“见实编码”方式对概念进行命名 (见图2) , 最后共提取出143个与研究主题相关的译码 (见图3) 。


4.2 建立主类属与次类属之间的关联
主轴性编码是通过演绎与归纳, 用新的方式对分散的数据进行重组, 同时区分为类属与次类属的复杂过程。研究者汲取主轴性编码的内涵后, 分为两阶段进行操作。在第一阶段的操作过程中, 以意义近似为原则, 将前一阶段操作所得的143个译码进行整理合并, 归纳成45个群组类属 (见表1) 。
第二阶段的操作再将此45个主要类属分别归属到8个类属 (Category Family) , 分别为:
- (1) 大数据:主要包含大数据的定义、用途、特性、发展热点, 以及图书馆应该应用大数据的原因等内容;
- (2) 云计算:主要包含云计算环境、云计算对大数据的支持、云计算对图书馆发展所能提供的帮助, 以及图书情报学领域对云计算的态度等内容;
- (3) 图书馆的问题与挑战:主要指图书馆当前亟待解决的问题, 如资料量大幅扩张、数据形式多样化、数据移动频繁, 以图书馆应发展自愈系统、完善知识服务架构、改善传统数据管理流程等内容;
- (4) Map Reduce:主要包含Map Reduce模型的优点、Map Reduce与关联数据库的有机融和、Map Reduce的局限性等内容;
- (5) Hadoop:主要包含Hadoop技术兴起的背景、Hadoop生态、Hadoop关键服务、Hadoop数据处理模型与应用等内容;
- (6) 知识的传播利用:主要包含数据分析利用的新趋势、新型知识服务引擎、知识分析技术, 以及知识传播的渠道与形式等内容;
- (7) 深度分析:主要包含深度分析模型、深度分析的需求与应用, 以及深度分析技术等内容;
- (8) 非结构化:主要包含非结构化数据的存储、非结构化数据的高效化发展、非结构化数据的特性、非结构化数据的价值以及非结构化数据的处理等内容。

4.3 主题词的提取
选择性编码是选择核心类属后, 不断发展与核心类属有关次类属进而构建理论体系的过程。研究者汲取选择性编码的内涵后, 重新对《图书馆需要怎样的“大数据”》一文的研究动机与问题意识进行检视, 发现该文写作目的在于探索大数据应用与图书馆的未来发展, 并对相关编程技术进行分析。据此, 该文题目本身已经包含了“图书馆的问题与挑战”此一核心类属。故本研究对前述主轴编码阶段所确立的8个主类属与45个次类属间的关系进行了以下的调整:
- (1) 由于题目本身已包含图书馆发展当前面临的困境, 以及未来应该的发展方向, 故将“图书馆的问题与挑战”此一主类属与其产生关系之次类属予以消除。
- (2) 本个案讨论的重点之一在于通过利用深度分析对于各种知识类型进分析, 从而掌握对知识分析的新趋势, 并在此基础上构建新型的知识服务引擎, 进而强化知识的利用, 最后得以协助图书情报领域面对知识传播形式与利用多样化的现况。所以, 应将“知识的传播利用”这一主类属及其属下的次类属改为隶属于“深度分析”这一主类属之下。
经由上述重新整理, 原有的8个类属调整为6个, 分别为“大数据”“深度分析”“云计算”“非结构化”“Hadoop”以及“Map Reduce”。此6个类属与其次类属的关系修正展开见表3, 修正图见图4。至此, 研究者完成了个案中的主题词提取。
五、三阶段编码对主题词提取的帮助
5.1 揭示主题词提取操作过程中的主观性因素
社会科学研究方法的应用, 其目的不在于构建一个绝对客观的研究结果 (因为所有的科学研究都无法避免主观性的涉入) , 而在于通过揭示主观性的涉入程度, 达到相对客观的研究要求。通过扎根理论的协助, 研究者第一步利用汲取开放性编码的内涵, 将《图书馆需要怎样的“大数据”》一文的7 967个文字概念化为143个译码;第二步汲取主轴性编码内涵, 首先将143个译码合并为概念相似的45个范畴;其次再利用类属关系的链接, 将45个类属区分为8个主类属与45个次类属的从属关系;第三步汲取选择性编码内涵, 依照本文的研究目的, 将这8个类属进一步的淬炼为“大数据”“深度分析”“云计算”“非结构化”“Hadoop”以及“Map Reduce”等6个类属, 亦即符合《图书馆需要怎样的“大数据”》一文研究目的的6个关键元素。此关键元素的提取即为本文主题词的提取。



研究者汲取扎根理论三阶段编码的内涵, 通过一步步由繁入简的提取步骤, 在成功揭示主题词提取操作过程的同时, 也将研究者提取主题词过程中的主观性毫无遮掩的呈现, 通过这样的呈现, 研究者的主观性得以受到大众的检视, 进而使研究者主题词的提取, 达到了相对性的客观。
5.2 呈现主题词间的内在联系
以往在主题标引的过程中, 所呈现均为主题词本身, 而这样的方式过度关注于主题词的词义本身, 较忽略主题词与主题词之间可能存在某种相互链接的“关系”, 而这种关系与主题词相较, 或许在某种程度上更能够反映出文章精义。以本研究为例, 研究者通过扎根理论三阶段编码之应用, 最后不但提取出“大数据”“深度分析”“云计算”“非结构化”“Hadoop”以及“Map Reduce”等6个主题词, 更以此呈现出各主题词彼此的关系;如“Hadoop”与“Map Reduce”之间非是“因果关系” (is cause of) 而是“部分关系” (a part of) ;“大数据”除与“深度分析”“非结构化”三者间构建了“相互联系关系” (is associated with) 外, 也与“Hadoop”“云计算”构建了“相互联系关系”。通过主题词与主题词彼此之间的关系网络, 读者更能从主题词中探悉一篇文章的内在结构 (见图4) 。
5.3 显示主题词在文章中的强弱程度
若本研究将“大数据”“深度分析”“云计算”“非结构化”“Hadoop”以及“Map Reduce”等6个主题词视为节点, 将这6个主题词彼此间的关系视为关系纽带;则各节点与节点间的关系纽带就则可视为是一个社会网络。而由于社会网络分析法中的点度中心性分析, 主要是利用网络中该点与其有联系的点的数目来衡量该点在此网络中的重要程度[11]。本研究即利用这一方法, 对图4中各节点 (主题词) 的强度进行分析。最后计算出各主题词的点度中心性分别为“大数据为5”, “非结构化为4”, “深度分析为3”, “Hadoop为3”, “云计算为2”, “Map Reduce为2”。由此可知前述6个主题词的强度大小依次分别是“大数据”>“非结构化”>“深度分析”=“Hadoop”>“云计算”=“Map Reduce”。
六、结论
提取主题词是主题标引的重要过程, 但目前的主题词提取方法一方面未能充分反映主题词提取操作过程中的主观因素, 另一方面也缺乏一种可供检验的可视化路径, 导致未能突显主题词之间的“关系”, 及主题词在文章中的强弱程度。据此, 研究者以《图书馆需要怎样的“大数据”》一文为个案, 并以“扎根理论”中的三阶段编码为方法进行分析。
在分析过程中, 研究者通过一步一步由繁入简的提取步骤, 不但成功揭示了主题词提取的操作过程, 同时也呈现出主题词彼此间的内在联系及其强度。通过这种方式, 读者不仅可以把握主观性对主题词提取过程的影响程度, 还可以通过主题词之间的“关系网”更加深入地了解文章的内在结构。
七、其他研究的编码示例


开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐

 28
28 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)