HTTPX从入门到放弃
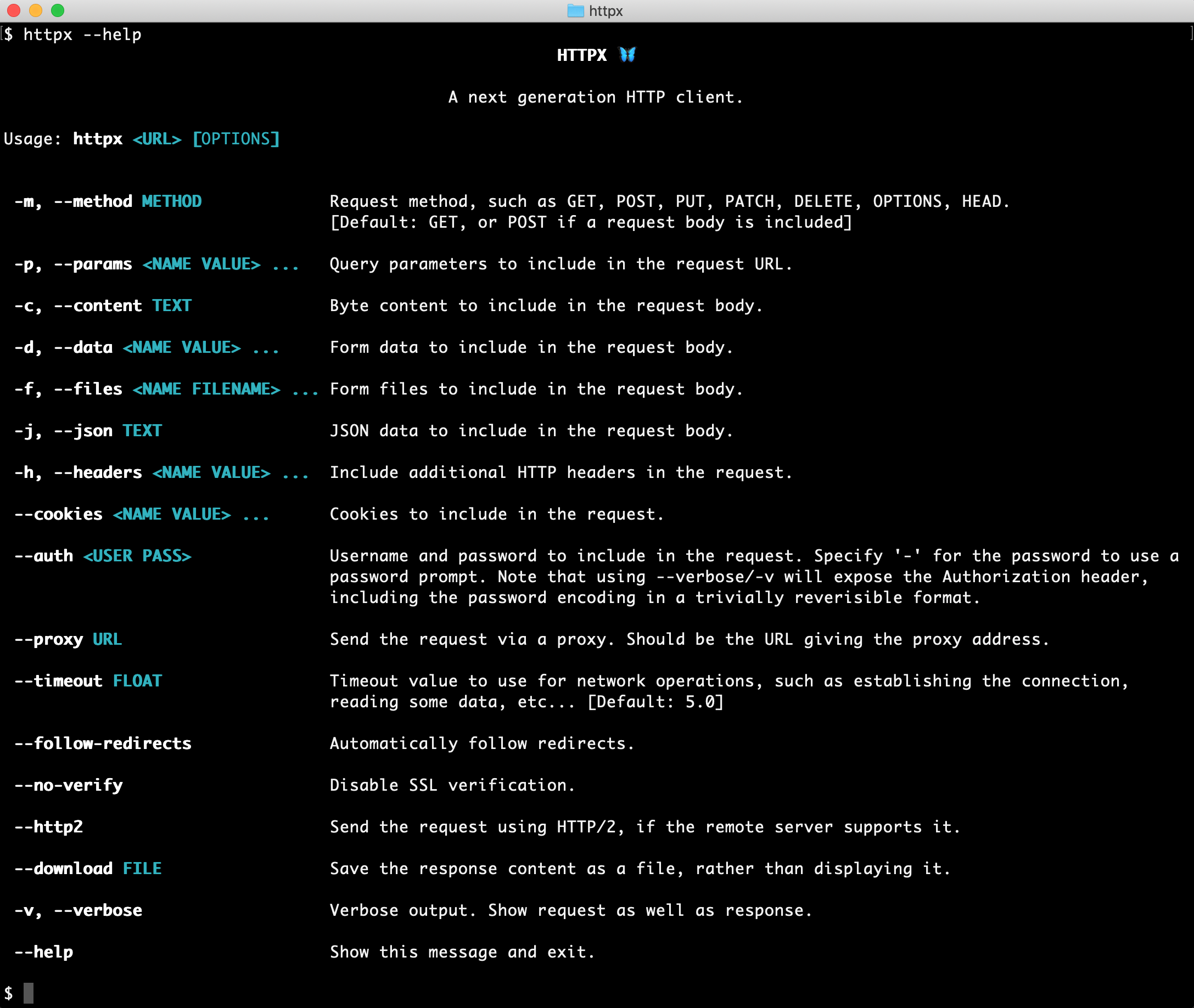
HTTPX是一款Python栈HTTP客户端库,它提供了比标准库更高级别、更先进的功能,如连接重用、连接池、超时控制、自动繁衍请求等等。HTTPX同时也支持同步和异步两种方式,因此可以在同步代码和异步代码中通用。HTTPX功能如下:1. 发送HTTP请求:HTTPX支持发送HTTP GET、POST等请求,并提供了丰富的选项进行定制化。2. 请求头和查询参数:HTTPX可以方便地添加请求头和查询参
1. 什么是HTTPX?
HTTPX是一款Python栈HTTP客户端库,它提供了比标准库更高级别、更先进的功能,如连接重用、连接池、超时控制、自动繁衍请求等等。HTTPX同时也支持同步和异步两种方式,因此可以在同步代码和异步代码中通用。
HTTPX功能如下:
1. 发送HTTP请求:HTTPX支持发送HTTP GET、POST等请求,并提供了丰富的选项进行定制化。
2. 请求头和查询参数:HTTPX可以方便地添加请求头和查询参数到HTTP请求中。
3. 超时设置:HTTPX支持对HTTP请求的超时时间进行设置,以避免长时间等待响应。
4. SSL/TLS证书验证:当使用HTTPS协议时,HTTPX可以验证SSL/TLS证书。
5. 文件上传和下载:HTTPX可以用于上传和下载文件。
6. Cookie管理:HTTPX可以管理cookie。
7. 连接池:HTTPX提供连接池以提高性能。
8. 异步请求:HTTPX支持异步请求,在异步代码中提供了更好的性能表现。
相比其他HTTP客户端库,HTTPX有以下优势:
- 性能更好:HTTPX采用异步IO模型实现高效的并发处理,使得其在处理大量数据和并发请求时比同类库要快得多。
- 功能更全面:HTTPX提供了更多的功能,如连接池、自动繁衍请求等等,使得它可以胜任更多不同的HTTP场景。
- 更为灵活:HTTPX提供了更多可用的选项以满足不同的HTTP场景和使用需求,从而使得它更为灵活。
- 更加安全:HTTPX在处理HTTPS请求时提供更完善的SSL/TLS证书验证机制,从而更加安全。

2. HTTPX功能
1. 发送HTTP请求
import httpx
# 发送GET请求
response = httpx.get('https://www.example.com')
print(response.status_code) # 状态码
print(response.text) # 响应内容
# 发送POST请求
data = {'name': 'example', 'age': 18}
response = httpx.post('https://www.example.com', data=data)
print(response.status_code) # 状态码
print(response.text) # 响应内容2. 请求头和查询参数
HTTPX发送HTTP请求时往往需要在请求中添加一些头部信息或查询参数,下面介绍如何在HTTPX中添加和定制这些信息。
添加请求头
可以通过headers参数向HTTP请求中添加头部信息。以下是一个示例代码:
import httpx
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response = httpx.get('https://www.example.com', headers=headers)
print(response.status_code)
print(response.text)可以看到,在发送GET请求时,使用了一个 headers 字典来指定请求头。其中 User-Agent 是模拟浏览器发送请求的标准请求头之一。可以根据实际需求添加更多的请求头信息。
添加查询参数
除了请求头外,还可以通过 params 参数向HTTP请求中添加查询参数。以下是一个示例代码:
import httpx
params = {'key1': 'value1', 'key2': 'value2'}
response = httpx.get('https://www.example.com', params=params)
print(response.status_code)
print(response.text)在上述代码中,params 参数被用于将查询参数添加到 GET 请求中。具体而言,HTTPX 会根据键值对自动生成查询字符串并将其附加到 URL 的末尾,就像在浏览器中一样。
3. 超时设置
在发送HTTP请求时,往往需要设置超时时间以避免等待过长时间的响应。HTTPX 提供了设置超时时间的方法,下面介绍如何在 HTTPX 中设置超时时间:
发送单次请求时设置超时时间
可以通过 timeout 参数来设置单个请求的超时时间,单位为秒(s)。以下是一个示例代码:
import httpx
# 设置 5 秒超时时间
timeout = httpx.Timeout(5)
response = httpx.get('https://www.example.com', timeout=timeout)
print(response.status_code)
print(response.text)在上述代码中,timeout 参数被用于将超时时间设置为 5 秒。如果在 5 秒内没有收到服务器的响应,HTTPX 将自动取消该请求并抛出 httpx.ReadTimeout 异常。
全局设置超时时间
除了可以在单个请求中设置超时时间外,还可以全局设置所有请求的超时时间。可以通过创建一个 Client 实例并指定超时时间来实现。以下是一个示例代码:
import httpx
# 全局设置 5 秒超时时间
client = httpx.Client(timeout=5)
response = client.get('https://www.example.com')
print(response.status_code)
print(response.text)在上述代码中,创建了一个 Client 实例,并将超时时间设置为 5 秒。在之后的所有请求中,都会默认使用这个超时时间。需要注意的是,全局设置会影响所有请求,因此需要根据实际情况合理地设置超时时间。
4. 异步请求
异步请求示例
首先,需要安装异步标准库 asyncio 和 HTTPX 库。
安装完成后,就可以在 Python 脚本中使用异步请求了。以下是一个简单的异步 GET 请求示例:
import asyncio
import httpx
async def main():
async with httpx.AsyncClient() as client:
response = await client.get('https://www.example.com')
print(response.status_code)
print(response.text)
asyncio.run(main())在上述代码中,我们使用异步函数 main() 来发送异步 GET 请求。其中,使用了 httpx.AsyncClient() 创建了一个异步客户端实例,然后调用了 client.get() 函数来发送 GET 请求。
在异步请求中,需要使用关键字 await 等待异步操作执行完成,这样才能保证程序按照正确的顺序执行。
进一步使用示例
除了简单的 GET 请求外,HTTPX 还支持复杂的异步操作和定制化需求。以下是一个使用异步 POST 请求并上传文件的示例:
import asyncio
import httpx
async def main():
async with httpx.AsyncClient() as client:
# 上传文件
files = {'file': ('example.txt', 'Hello, world!')}
response = await client.post('https://www.example.com/upload', files=files)
# 显示响应信息
print(response.status_code)
print(response.text)
asyncio.run(main())在上述代码中,使用了 client.post() 函数向服务器上传文件。其中,files 参数被用于指定上传的文件信息。
需要注意的是,在异步请求过程中,需使用 async with httpx.AsyncClient() as client: 的方式创建异步客户端实例,并通过 async/await 关键字等待异步操作完成,这样才能确保程序正确执行。
5. SSL/TLS证书验证
SSL/TLS证书验证是保证HTTP通信安全的重要手段之一。HTTPX提供了对SSL/TLS证书的验证机制,下面介绍如何在HTTPX中进行SSL/TLS证书验证:
验证服务器证书
HTTPX 默认会验证服务器证书,如果证书无效或不可信,则会抛出 httpx.RemoteProtocolError 异常。以下是一个示例代码:
import httpx
response = httpx.get('https://www.example.com')
print(response.status_code)
print(response.text)在上述代码中,使用 httpx.get() 函数向服务器发送 GET 请求,并默认启动 SSL/TLS 证书验证。如果服务器证书无效,则 HTTPX 会抛出 httpx.RemoteProtocolError 异常。
禁用服务器证书验证
虽然 SSL/TLS 证书验证是确保通信安全的重要手段,但在一些特殊情况下需要禁用证书验证,例如调试时使用自签名证书等。可以通过将 verify 参数设置为 False 来禁用 SSL/TLS 证书验证。以下是一个示例代码:
import httpx
response = httpx.get('https://www.example.com', verify=False)
print(response.status_code)
print(response.text)在上述代码中,verify=False 参数被用于禁用服务器证书验证。需要注意的是,这种方法会降低通信安全性,应谨慎使用。
指定客户端证书
除了验证服务器证书外,HTTPX 还支持指定客户端证书。可以通过 cert 参数来指定客户端证书和私钥文件的路径。以下是一个示例代码:
import httpx
client_cert = ('path/to/cert.pem', 'path/to/key.pem')
response = httpx.get('https://www.example.com', cert=client_cert)
print(response.status_code)
print(response.text)在上述代码中,client_cert 变量被用于指定客户端证书和私钥的路径。需要注意的是,客户端证书应该由受信任的第三方机构颁发,并且应该进行保护。
6. 文件上传和下载
HTTPX支持文件上传和下载,可以通过httpx.post() 和 httpx.get() 函数向服务器上传和下载文件。下面分别介绍如何在 HTTPX 中进行文件上传和下载:
- 文件上传示例
可以通过 files 参数来实现文件上传功能。以下是一个文件上传的示例代码:
import httpx
with open('example.txt', 'rb') as f:
files = {'file': ('example.txt', f)}
response = httpx.post('https://www.example.com/upload', files=files)
print(response.status_code)
print(response.text)
在上述代码中,使用了 open() 函数打开本地文件,并将文件数据添加到 files 参数中。然后,使用 httpx.post() 函数向服务器发送 POST 请求并上传文件。
需要注意的是,('example.txt', f) 中,第一个参数是文件名,第二个参数是文件内容。具体而言,文件内容应该以二进制格式表示。
文件下载示例
可以通过 stream=True 参数将文件下载至内存中,并逐步写入本地文件。以下是一个文件下载的示例代码:
import httpx
response = httpx.get('https://www.example.com/image.jpg', stream=True)
with open('image.jpg', 'wb') as f:
for chunk in response.iter_bytes():
f.write(chunk)
print(response.status_code)在上述代码中,使用了 httpx.get() 函数向服务器发送 GET 请求。其中,stream=True 参数被用于启动响应流模式,这样可以将文件下载到内存中,然后逐步写入本地文件。需要注意的是,在下载大文件时,响应流模式可以减少内存占用并提高性能。
Cookie管理
HTTPX提供了用于管理Cookie的工具,可以通过httpx.CookieJar()对象来管理Cookie。下面介绍如何在HTTPX中进行Cookie管理:
使用CookieJar管理Cookie
可以使用 httpx.CookieJar() 对象来管理 Cookie。以下是一个示例代码:
import httpx
# 创建 CookieJar 实例
cookie_jar = httpx.CookieJar()
# 将 Cookie 添加到 CookieJar 中
cookie = httpx.cookies.Cookie(name='name', value='value')
cookie_jar.set_cookie(cookie)
# 使用 CookieJar 发送请求
with httpx.Client(cookie_jar=cookie_jar) as client:
response = client.get('https://www.example.com')
print(response.status_code)在上述代码中,首先创建了一个 httpx.CookieJar() 实例,并将 httpx.cookies.Cookie() 对象添加到 CookieJar 中。然后,在使用 HTTPX 发送请求时,通过 cookie_jar=cookie_jar 参数来指定使用 CookieJar 管理 Cookie。
需要注意的是,通过 set_cookie() 方法向 httpx.CookieJar() 添加 Cookie 后,这些 Cookie 将被自动附加到后续的 HTTP 请求中。
使用Session管理Cookie
除了使用 httpx.CookieJar() 对象管理 Cookie 外,还可以使用 httpx.Client() 对象的 Session 来管理 Cookie。以下是一个示例代码:
import httpx
# 创建 Session 实例
session = httpx.Client()
# 向 Session 中添加 Cookie
cookie = httpx.cookies.Cookie(name='name', value='value')
session.cookies.set_cookie(cookie)
# 使用 Session 发送请求
response = session.get('https://www.example.com')
print(response.status_code)在上述代码中,通过 httpx.Client() 创建了一个 HTTP 客户端实例,并使用 session.cookies.set_cookie() 方法向 Session 中添加 Cookie。然后,在使用 HTTPX 发送请求时,不需要指定 cookie_jar 参数,而是使用 Session 自动管理 Cookie。
需要注意的是,httpx.Client() 的 Session 会自动保存并发送所有 Cookie,因此在发送多个 HTTP 请求时,可以方便地管理 Cookie。
连接池
HTTPX 是一个 Python 的异步 HTTP 客户端库。它支持连接池来重用已建立的 HTTP 连接,从而提高性能并减少网络延迟。
创建连接池
要创建连接池,请使用 httpx.AsyncClient() 构造函数并指定 limits 参数。
import httpx limits = httpx.Limits(max_connections=100, max_keepalive=10) client = httpx.AsyncClient(limits=limits)
此代码将创建一个最大连接数为 100,最大保持活动连接数为 10 的连接池。
使用连接池
一旦你创建了连接池,你可以像正常地发送请求一样使用 httpx.AsyncClient() 实例发送请求。在创建客户端时,HTTPX 将自动管理连接池中的连接。
response = await client.get("https://www.example.com")
print(response.text)
这将使用连接池中的空闲连接来发送 HTTP GET 请求,并返回响应。如果没有可用的连接,HTTPX 将自动创建一个新连接。
3. 使用HTTPX编写Web爬虫
import asyncio
import httpx
from bs4 import BeautifulSoup
async def fetch(url):
async with httpx.AsyncClient() as client:
response = await client.get(url)
return response.text
async def scrape():
url = "https://book.douban.com/top250"
html = await fetch(url)
soup = BeautifulSoup(html, "html.parser")
books = []
for book in soup.select(".indent > table"):
title = book.select_one(".pl2 > a")["title"]
link = book.select_one(".pl2 > a")["href"]
rating = book.select_one(".rating_num").text.strip()
author = book.select_one(".pl").text.strip().split("/")[0]
books.append({"title": title, "link": link, "rating": rating, "author": author})
return books
if __name__ == "__main__":
books = asyncio.run(scrape())
for book in books:
print(book)
开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)