Linux笔记(二)重定向详解
重定向详解
一.标准输入,标准输出和标准错误
到目前为止,我们使用过的很多程序生成了不同种类的输出。这些输出通常包含两种类型。一种是程序运行的结果,即该程序生成的数据;另一种是状态和错误信息,表示当前程序的运行状况。比如输入ls命令,屏幕上将显示它的运行结果以及它的相关错误信息。
与UNIX“一切都是文件”的思想一致,类似ls的程序实际上把它们的运行结果发送到了一个称为标准输出(standard output,通常表示为stdout)的特殊文件中,他们的状态信息则发送到了另一个称为标准错误(standard error,通常表示为stderr)的文件中。默认情况下,标准输出和标准错误都将被链接到屏幕上,并且不会被保存在磁盘文件中。
另外,许多程序从一个称为标准输入(standard input,表示为stdin)的设备来得到输入。默认情况下,标准输入连接到键盘。
I/O重定向功能可以改变输出内容发送的目的地,也可以改变输入内容的来源地。通常来说,输出内容显示在屏幕上,输入内容来自于键盘。但是使用I/O重定向功能可以改变这一惯例。
(1)标准输出重定向
I/O重定向功能可以重新定义标准输出内容发送到哪里。使用重定向操作符“>”,后面接文件名,就可以把标准输出重定向到另一个文件中,而不是显示在屏幕上。
为什么我们需要这么做呢?它主要用于把命令的输出内容保存到一个文件中。比如,我们可以按照下面的形式把ls命令的输出保存到ls-output.txt文件中,而不是输出到屏幕上。
ls -l /sur/bin > ls-output.txt
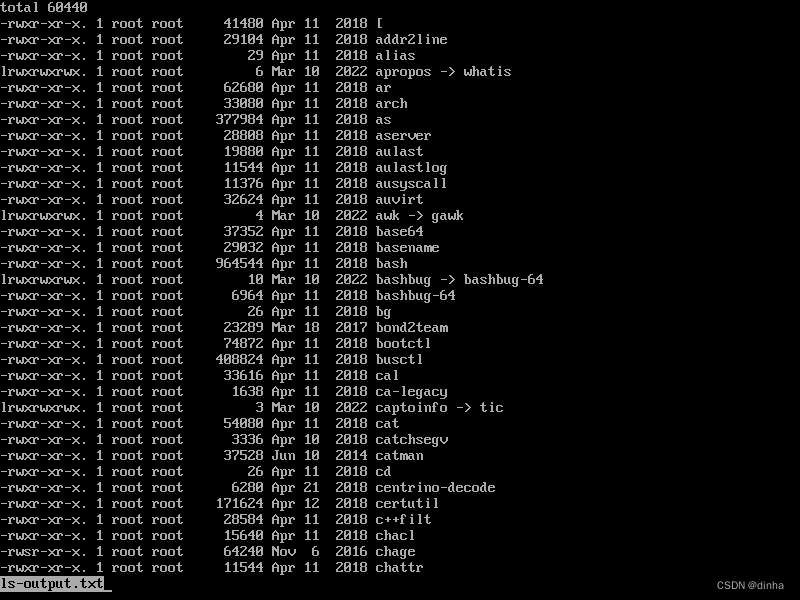
这里我们将创建/usr/bin目录的一个长列表信息,并把这个结果输出到ls-output,txt文件中。检查下该命令被重定向的输出内容。

这是一个不错的大型文本文件。如果使用less命令查看这个文件,我们可以看到ls-output.txt文件确实包含了ls命令的执行结果。
现在我们重复重定向测试,但是这次做一点变化。我们把目录名称换成一个不存在的目录。

我们会收到一个错误信息。因为我们指定的是一个不存在的目录/bin/usr,所以这个错误信息是正确的。但是为什么这个错误信息显示在屏幕上,而不是重定向到ls-output.txt文件中呢?原因是ls程序并不会把它运行的错误信息发送到标准输出文件中。而是与大多数写的很好的UNIX程序一样,它把错误信息发送到标准错误文件中。因为我们只重定向了标准输出,并没有重定向标准错误,所有这个错误信息仍然输出到屏幕上。

当前这个文件大小为零!
这是因为当使用重定向符“>”来重定向标准输出时,目的文件通常会从文件的开头部分重新改写。由于ls命令执行后没有输出任何内容,只是显示一条错误信息,所以重定向操作开始重新改写这个文件,并在出现错误的情况下停止操作,最终导致了该文件内容被删除。
事实上,如果我们需要删除一个文件内容(或者创建一个新的空文件),可以采用这种方式。
> ls-output.txt
仅仅使用重定向符,并在它之前不加任何命令,就可以删除一个已存在的文件内容或者创建一个新的空文件。
那么,我们如何能够不从文件的首位置开始覆盖文件,而是从文件的尾部开始添加输出内容呢?
我们可以使用“>>”来实现,比如:
ls -l /usr/bin >> ls-output.txt
使用重定向符“>>”将使的输出内容添加在文件的尾部。如果这个文件并不存在,将与操作符“>”的作用一样创建这个文件。

重复执行这条命令三次,系统将最终生成一个为原来三倍大小的输出文件。
(2)标准错误重定向
标准错误的重定向并不能简单的使用一个专用的重定向符实现。要实现标准错误的重定向,不得不提到它的文件描述符(file descriptor)。一个程序可以把生成的输出内容发送到任意文件流中。如果把这些文件流中的前三个分别对应标准输入文件,标准输出文件和标准错误文件,那么shell将在内部用文件描述符分别索引它们为0,1和2。shell提供了使用文件描述符编号来重定向文件的表示法。由于标准错误等同于文件描述2,所以可以使用这种表示法来重定向标准错误。
ls -l /bin/usr 2> ls-error.txt
文件描述符“2”紧放在重定向符之前,将标准错误重定向到ls-error.txt文件中。
(3)将标准输出和标准错误重定向到同一个文件
在许多情况下,我们会希望把一个命令的所有输出内容都放在同一个独立的文件中。为此,我们必须同时重定向标准输出和标准错误。有两种方法可以满足要求。
第一种是传统的方法,在旧版本的shell中使用。
ls -l /bin/usr > ls-output.txt 2>&1
使用这个方法,将执行两个重定向操作。首先重定向标准输出到ls-output.txt文件中,然后使用标记符2>&1把文件描述符2(标准错误)重定向到文件描述符1(标准输出)中。
注意:这些重定向操作的顺序是非常重要的。标准错误的重定向操作通常发生在标准输出重定向操作后,否则它将不起作用。在上面的例子中,> ls-output.txt 2>&1 把标准错误重定向到ls-output.txt文件中,但是如果顺序发生改变为 2>&1 > ls-output.txt,那么标准错误将会重定向到屏幕上。
第二种方式更为高效
ls -l /bin/usr &> ls-output.txt
***在这个例子中,只使用一个标记符“&>”就把标准输出和标准错误都重定向到了ls-output.txt文件中。
(4)处理不想要的输出
有时候“沉默是金”,命令执行后我们并不希望得到输出,而是想把这个输出丢弃,尤其是在输出错误和状态信息的情况下更为需要。系统提供了一种方法,即通过把输出重定向到一个称为/dev/null 的特殊文件中来实现它。这个文件是一个称为位桶(bit bucket)的系统设备,它接受输入但是不对输入进行任何处理。以下命令可以用来抑制(即隐藏)一个命令的错误信息。
ls -l /bin/usr 2> /dev/null
(5)标准输入重定向
我们先介绍一个命令
cat:合并文件
cat命令读取一个或多个文件,并把他们复制到标准输出文件中,格式如下:
cat [file...]
在大多数情况下,你可以认为cat命令和DOS中的TYPE命令相似。使用它显示文件而不需要分页,例如
cat ls-output.txt
将显示的ls-output.txt文件的内容。cat经常用来显示短的文本文件。由于cat可以接受多个文件作为输入参数,所以它也可以用来把文件连接在一起。假设我们下载了一个很大的文件,它已被拆分为多个部分(Usenet上的多媒体文件经常采用拆分这种方式),现在我们想要把各个部分连接在一起,并还原为原来的文件。如果这些文件命名为movie.mpeg.001 movie.mepg.002 … movie.mepg.099
我们可以使用这个命令让他们重新连接在一起。
cat movie.mpge.0* > movie.mpeg
通配符一般都是按照顺序来扩展的。因此这些参数将按正确的顺序来排列。
虽然这样很好,但是这跟标准输入有什么关系呢?确实没有什么关系,但是我们可以试试其他的情况。如果输入cat命令却不带任何参数会出现什么结果呢?
cat
没有任何结果,它只是停在那边不动,好像它已经挂起了。看起来好像是这样,但是实际上它正在执行我们期望它做的事情。
如果cat命令没有给定任何参数,它将从标准输入读取内容。由于标准输入在默认情况下是连接到键盘,所以实际上它正在等待着从键盘输入内容

下一步同时按下CTRL+D,告知cat命令他已经达到了标准输入的文件尾(end-of-file,EOF)。

在缺少文件名参数的情况下,cat将把标准输入内容复制到标准输出文件中,因此我们将看到文本行重复显示。用这种方法我们可以创建短的文本文件。如果想要创建一个名叫lazy_dog.txt的文件,文件中包含之前例子中的文本内容,我们可以这样做:
cat > lazy_dog.txt
The quick brown fox jumped over the lazy dog.
在cat命令后输入想要放在文件中的文本内容。记住在文件结束时按下CTRL+D。
为了看到结果,我们可以使用cat命令再次把文件复制到标准输出文件中。

现在我们已经知道cat命令除了接收文件名参数以外,是如何接受标准输入的。接下来尝试标准输入的重定向。

使用重定向符“<”,我们将把标准输入源从键盘变温lazy_dog.txt文件。可以看到,得到的结果和只传递单个文件名参数的结果一样。和传输一个文件名参数的方式作对比,这种方式并不是特别的有用,但是可以用来说明把一个文件作为标准输入的源文件。
二.管道
命令从标准输入到读取数据,并将数据发送到标准输出的能力,是使用了名为管道的shell特性。使用管道操作符“|”(竖线)可以把一个命令的标准输出传送到另一个命令的标准输入中。
Command1 | Command2
为了充分证明这一点,我们需要一些命令。之前说过有一条命令可以接受标准输入,它就是less命令。使用less命令可以分页显示任意命令的输入,该命令将他的结果发送到标准输出。
ls -l /usr/bin | less
通过使用该技术,可以很方便的检查任意一条生成标准输出的命令的运行结果。
(1)过滤器
管道功能经常用来对数据执行复杂的操作。也可以把多条命令合在一起构成一个管道。这种方式中用到的命令通常被称为过滤器。
过滤器接受输入,按照某种方式对输入进行改变,然后再输出它。第一个要用到的命令是sort。假设要把/bin和/usr/bin目录下的所有可执行程序合并成一个列表,并且按照顺序排列,最后再查看这个列表

由于我们指定了两个目录(/bin和/usr/bin),ls的输出将包含两个排好序的列表,每个对应一个目录。通过在管道中包含sort命令,我们改变输出数据,从而产生一个排好的列表。
(2)uniq:报告或忽略文件中重复的行
uniq命令经常和sort命令结合使用。uniq可以接受来自于标准输入或者一个单一文件名参数对应的已排好序的数据列表(可以查看uniq命令的man页面获取详细信息)。默认情况下,该命令删除列表中的所有重复行。因此,在管道中添加uniq命令,可以确保所有的列表都没有重复行(即在/bin和/usr/bin目录下都出现的相同名字的任意程序)。
ls -l /bin /usr/bin | sort | uniq | less
在这个例子中,我们使用了uniq命令来删除来自sort命令输出内容中的任意重复行。如果反过来想要查看重复行的列表,可以在uniq命令后面添加-d选项,如下图
ls -l /bin /usr/bin | sort | uniq -d | less
(3)wc : 打印行数,字数和字节数
wc(字数统计:word count)命令用来显示文件中包含的行数,字数和字节数。例如

在这个例子中,我们打印输出了三个数据,即ls-output.txt文件中包含的行数,字数和字节数。和前面的命令一样,如果在执行wc时没有输入输入命令行参数,它将接受标准输入内容。-l选项限制命令只报告行数,把它添加在管道中可以很方便的实现计数功能。如果我们要查看已排好序的列表中的条目数,可以按以下方法输入

(4)grep:打印匹配行
grep是一个功能强大的程序,它用来在文件中查找匹配文本,其使用方式如下
grep pattern [file...]
当grep在文件中遇到“模式”的时候,将打印出包含该模式的行。
如果我们想从列出的程序中搜索出文件名中包含zip的所有文件,该搜索将获悉系统中与文件压缩相关的程序,操作如下:

grep存在一对方便的选项:-i 和 -v
-i:该选项使得grep在搜索时忽略大小写(通常情况下,搜索是区分大小写的)
-v:该选项使得grep只输出和模式不匹配的行
(5)head/tail:打印文件的开头部分/结尾部分
有的时候,你并不需要命令输出的所有内容,可能只需要开头几行或者最后几行。head命令将输出文件的前10行,tail命令则输出文件的最后10行。默认情况下,这两条命令都是输出文件的10行内容,不过可以使用-n选项来调整输出的行数。
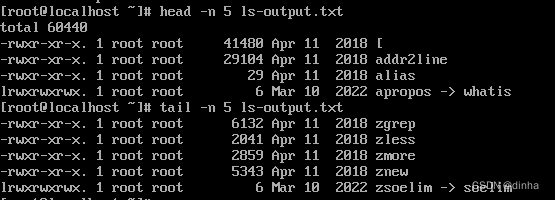
这些命令选项也可以应用到管道中
tail中有一个选项用来实时查看文件,该选项在观察正在被写入的日志文件的进展状态时很有用。在下面的例子中,我们将观察/var/log目录下的messages文件。因为/var/log/messages文件可能包含安全信息,所以在一些linux发行版本中,需要超级用户的权限才能执行该操作。
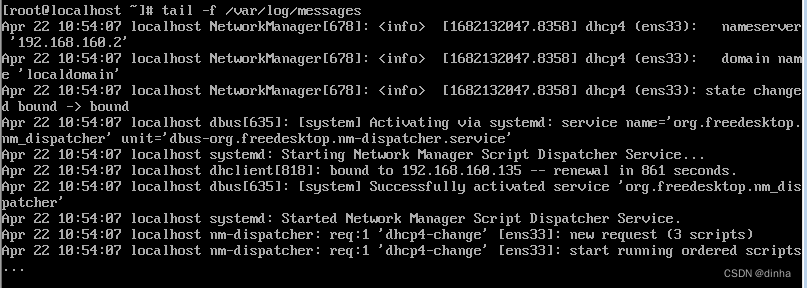
使用-f选项,tail将持续监视这个文件,一旦添加了新行,新行将会立即显示在屏幕上。该动作在按下CTRL+C后停止。
(6)tee:从stdin读取数据,并同时输出到stdout和文件
为了和我们的管道隐喻保持一致,Linux提供了一个叫做tee的命令,就好像安装了一个“T”在管道上。tee程序读取标准输入,再把读到的内容复制到标准输出(允许数据可以继续向下传递到管道中)和一个或更多的文件中去。当在某个中间处理阶段来捕获一个管道的内容时,会很有用。这里我们重复使用之前的一个例子,这次在使用grep命令过滤管道内容之前,我们先使用tee命令来获取整个目录列表并输出到ls.txt文件中。


开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)