聚类算法(K-means)代码实现(鸢尾花数据集)
本文主要实现K-means这一算法,根据聚类算法理论篇(K-means,DBSCAN原理)可知:输入:数据dataK值输出:簇组其工作流程:1.根据K值,随机创建K个初始化质心点(Initialozation Randomly selecr K center points。2. 算出所有样本点到质心点的距离,得到样本属于那个簇。3. 更新,根据簇内样本重新算出簇内的质心。4. 重复执行2,3步,重
目录
2. 得到当前每一个样本到K个中心点的距离,得到每个样本距离最近的那个中心点并返回中心点
4. 进行训练(迭代)返回最后一次的中心点和簇类中的样本(每个样本距离最近的中心点)
一、前言
本文主要实现K-means这一算法,根据聚类算法理论篇(K-means,DBSCAN原理)可知:
输入:数据data
K值
输出:簇组
其工作流程:
1.根据K值,随机创建K个初始化质心点(Initialozation Randomly selecr K center points。
2. 算出所有样本点到质心点的距离,得到样本属于那个簇。
3. 更新,根据簇内样本重新算出簇内的质心。
4. 重复执行2,3步,重新划分簇类,直至质心不在变化。
二、代码实现
K-means的实现
1. 随即给定初始点并返回,其点个数就是K值
def centeroids_init(data,num_clusters):
num_examples = data.shape[0]
random_ids = np.random.permutation(num_examples) #洗牌操作
centeroids = data[random_ids[:num_clusters],:] #random_ids[:num_clusters]选择num_clusters个样本 [:num_clusters],:]所有特征
return centeroids2. 得到当前每一个样本到K个中心点的距离,得到每个样本距离最近的那个中心点并返回中心点
def centeroids_find_closet(data,centroids):
num_examples = data.shape[0]
num_centeroids = centroids.shape[0]
#closet_centeroids_ids = np.zeros((num_examples,1))
#c初始化
closet_centeroid_ids = np.zeros((num_examples, 1))
for example_index in range(num_examples):
distance = np.zeros((num_centeroids,1)) #簇表
for centeroid_index in range(num_centeroids):
distance_diff = data[example_index,:] - centroids[centeroid_index,:] # 算出距离
distance[centeroid_index] = np.sum(distance_diff**2) #将距离的平方值存入 簇表内
closet_centeroid_ids[example_index] = np.argmin(distance)
return closet_centeroid_ids3.更新中心点并返回
def centroids_updata(data,closet_centroid_ids,num_clusters):
num_features = data.shape[1]
centroids = np.zeros((num_clusters,num_features)) # 有num_clusters个质心,每个质心有num_features个维度,即num_clusters*num_features矩阵
for centroid_id in range(num_clusters):
closet_id = closet_centroid_ids == centroid_id #最近的点
centroids[centroid_id] = np.mean(data[closet_id.flatten(),:],axis=0) #各个维度的均值
return centroids4. 进行训练(迭代)返回最后一次的中心点和簇类中的样本(每个样本距离最近的中心点)
def train(self,max_iterations):
#1.先随机选择K个中心点
centroids = KMeans.centeroids_init(self.data,self.num_clusters)
#
num_examples = self.data.shape[0]
#最近的中心点
closet_centroid_ids = np.empty((num_examples,1))
#2.开始训练
for _ in range(max_iterations):
#3.当前距离 得到当前每一个样本到K个中心点的距离,得到最近的那个
closet_centroid_ids = KMeans.centeroids_find_closet(self.data,centroids)
#4.进行中心点的更新
centroids = KMeans.centroids_updata(self.data,closet_centroid_ids,self.num_clusters)
return centroids,closet_centroid_ids5.完整代码
import numpy as np
class KMeans:
def __init__(self,data,num_clusters):
self.data = data
self.num_clusters = num_clusters
def train(self,max_iterations):
#1.先随机选择K个中心点
centroids = KMeans.centeroids_init(self.data,self.num_clusters)
#
num_examples = self.data.shape[0]
#最近的中心点
closet_centroid_ids = np.empty((num_examples,1))
#2.开始训练
for _ in range(max_iterations):
#3.当前距离 得到当前每一个样本到K个中心点的距离,得到最近的那个
closet_centroid_ids = KMeans.centeroids_find_closet(self.data,centroids)
#4.进行中心点的更新
centroids = KMeans.centroids_updata(self.data,closet_centroid_ids,self.num_clusters)
return centroids,closet_centroid_ids
@staticmethod
def centeroids_init(data,num_clusters):
num_examples = data.shape[0]
random_ids = np.random.permutation(num_examples) #洗牌操作
centeroids = data[random_ids[:num_clusters],:] #random_ids[:num_clusters]选择num_clusters个样本 [:num_clusters],:]所有特征
return centeroids
@staticmethod
def centeroids_find_closet(data,centroids):
num_examples = data.shape[0]
num_centeroids = centroids.shape[0]
#closet_centeroids_ids = np.zeros((num_examples,1))
#c初始化
closet_centeroid_ids = np.zeros((num_examples, 1))
for example_index in range(num_examples):
distance = np.zeros((num_centeroids,1)) #簇表
for centeroid_index in range(num_centeroids):
distance_diff = data[example_index,:] - centroids[centeroid_index,:] # 算出距离
distance[centeroid_index] = np.sum(distance_diff**2) #将距离的平方值存入 簇表内
closet_centeroid_ids[example_index] = np.argmin(distance)
return closet_centeroid_ids
@staticmethod
#更新质心点
def centroids_updata(data,closet_centroid_ids,num_clusters):
num_features = data.shape[1]
centroids = np.zeros((num_clusters,num_features)) # 有num_clusters个质心,每个质心有num_features个维度,即num_clusters*num_features矩阵
for centroid_id in range(num_clusters):
closet_id = closet_centroid_ids == centroid_id #最近的点
centroids[centroid_id] = np.mean(data[closet_id.flatten(),:],axis=0) #各个维度的均值
return centroids
三、应用案例
本例主要使用鸢尾花数据集,数据集读者可以自行下载
1.代码实现
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from Kmeans_lab.kmeans.k_means import KMeans
data = pd.read_csv('../data/iris.csv')
iris_types = ['SETOSA','VERSICOLOR','VIRGINICA']
x_axis = 'petal_length'
y_axis = 'petal_width'
plt.figure(figsize=(12,5))
plt.subplot(1,2,1)
for iris_type in iris_types:
plt.scatter(data[x_axis][data['class']==iris_type],data[y_axis][data['class']==iris_type],label = iris_type)
plt.title('label known')
plt.legend()
plt.subplot(1,2,2)
plt.scatter(data[x_axis][:],data[y_axis][:])
plt.title('label unknown')
plt.show()
num_examples = data.shape[0]
x_train = data[[x_axis,y_axis]].values.reshape(num_examples,2)
#指定好训练所需的参数
num_clusters = 3
max_iteritions = 50
k_means = KMeans(x_train,num_clusters)
centroids,closest_centroids_ids = k_means.train(max_iteritions)
# 对比结果
plt.figure(figsize=(12,5))
plt.subplot(1,2,1)
for iris_type in iris_types:
plt.scatter(data[x_axis][data['class']==iris_type],data[y_axis][data['class']==iris_type],label = iris_type)
plt.title('label known')
plt.legend()
plt.subplot(1,2,2)
for centroid_id, centroid in enumerate(centroids):
current_examples_index = (closest_centroids_ids == centroid_id).flatten()
plt.scatter(data[x_axis][current_examples_index],data[y_axis][current_examples_index],label = centroid_id)
for centroid_id, centroid in enumerate(centroids):
plt.scatter(centroid[0],centroid[1],c='black',marker = 'x')
plt.legend()
plt.title('label kmeans')
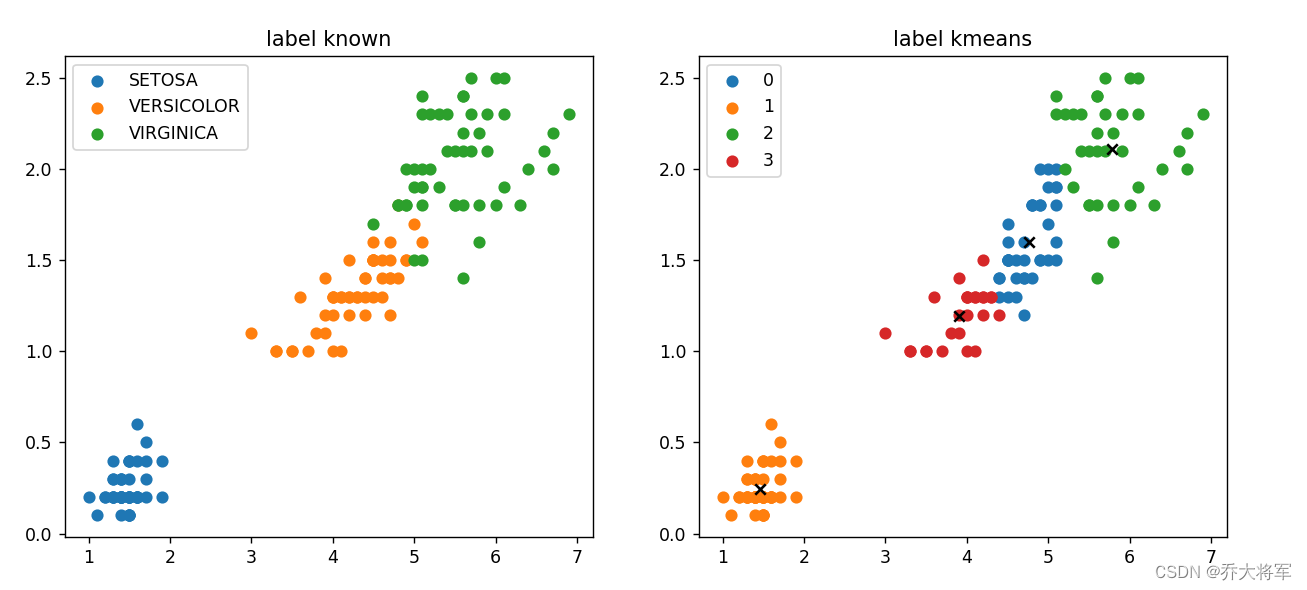
plt.show()2. 结果显示
 3. K=3的聚类结果
3. K=3的聚类结果
 4. K=4的聚类结果
4. K=4的聚类结果

5.总结
从实验可以看出K-means只适合一些简单的数据集,最好是开始就成堆的数据。并且K值对结果的影响非常大。
多种聚类读者可以进行尝试

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 26
26 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)