手把手教你:基于深度残差网络(ResNet)的水果分类识别系统
本文主要介绍如何使用python搭建:一个基于深度残差网络(ResNet)的水果图像分类识别系统。项目只是用水果分类作为抛砖引玉,其中包含了使用ResNet进行图像分类的相关代码。主要功能如下:- 数据预处理,生成用于输入TensorFlow模型的TFRecord的数据。- 模型构建及训练,使用tensorflow.keras构建深度残差网络。- 预测水果分类并进行模型评估。如各位童鞋需要更换训练
系列文章
手把手教你:基于粒子群优化算法(PSO)优化卷积神经网络(CNN)的文本分类
目录
一、项目简介
本文主要介绍如何使用python搭建:一个基于深度残差网络(ResNet)的水果图像分类识别系统。
项目只是用水果分类作为抛砖引玉,其中包含了使用ResNet进行图像分类的相关代码。主要功能如下:
- 数据预处理,生成用于输入TensorFlow模型的TFRecord的数据。
- 模型构建及训练,使用tensorflow.keras构建深度残差网络。
- 预测水果分类并进行模型评估。
如各位童鞋需要更换训练数据,完全可以根据源码将图像和标注文件更换即可直接运行。
博主也参考过网上图像分类的文章,但大多是理论大于方法。很多同学肯定对原理不需要过多了解,只需要搭建出一个预测系统即可。
本文只会告诉你如何快速搭建一个基于ResNet的图像分类系统并运行,原理的东西可以参考其他博主。
也正是因为我发现网上大多的帖子只是针对原理进行介绍,功能实现的相对很少。
如果您有以上想法,那就找对地方了!
不多废话,直接进入正题!
二、水果分类结果预测
首先我们来看下模型最终预测的水果类别的情况。本项目采用的数据集共有13种水果:香蕉、樱桃、无花果、芒果等等。博主英语不好就不在这献丑了,感兴趣的同学可以百度翻译

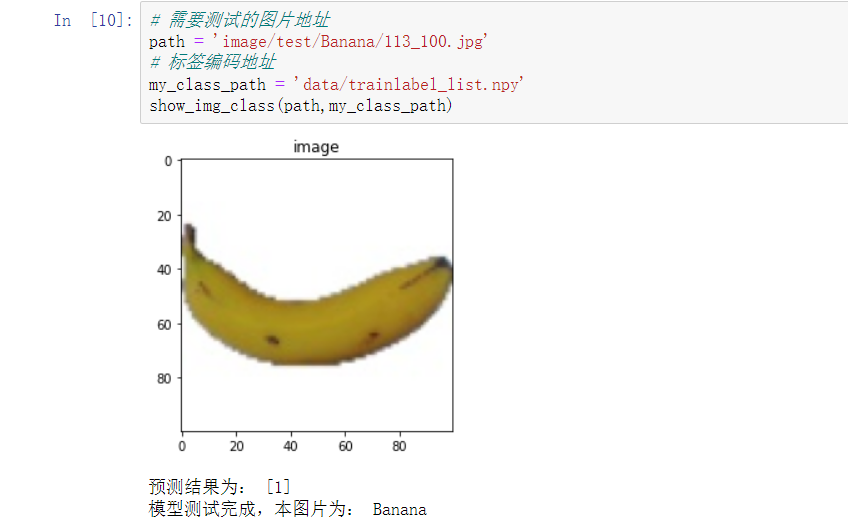
- 接下来是模型预测的结果,这里我输入了2个单张图片,来验证模型的分类结果:


- 可以看到2张图片分别为:香蕉、桔柚,模型都准确预测并分类正确。
三、环境安装
1.环境要求
本项目开发IDE使用的是:Anaconda中的jupyter notebook,大家可以直接csdn搜索安装指南非常多,这里就不再赘述。
因为本项目基于TensorFlow因此需要以下环境:
- tensorflow >= 2.0
- pandas
- scikit-learn
- numpy
- OpenCV2
- matplotlib
2.环境安装示例
环境都可以通过pip进行安装。如果只是想要使用博主训练的模型直接进行预测,不需要对模型重新训练的话,这边建议tensorflow安装cpu版的。
如果没使用过jupyter notebook通过pip安装包的同学可以参考如下:
- 新建一个terminal窗口:

- 在新建的窗口中使用pip进行安装:

点开“终端”,然后通过pip进行安装pandas,其他环境包也可以通过上面的方法安装。
四、重要代码介绍
环境安装好后就可以打开jupyter notebook开始愉快的执行代码了。由于代码众多,博客中就不放入最终代码了,有需要的童鞋可以在博客最下方找到下载地址。
1.数据预处理
- 首先我们将需要处理的图像分为训练集、测试集。

-
其中按13类的水果分别建立文件夹放入对应水果图片:

-
这里拿芒果举例:

-
使用opencv2来读取图像生成:(100,100,3)的三通道图像数据。
# 定义图像处理函数
def read_img(path):
print("数据集地址:"+path)
imgs = []
labels = []
for root, dirs, files in tqdm(os.walk(path)):
for file in files:
# print(path+'/'+file+'/'+folder)
# 读取的图片
img = cv2.imread(os.path.join(root, file))
# 将读取的图片数据加载到imgs[]列表中
imgs.append(img)
# 将图片的label加载到labels[]中,与上方的imgs索引对应
labels.append(str(os.path.basename(root)))
return imgs,labels
- 并处理图像,和对类别进行LabelEncoder编码处理,处理后情况如下:
- 训练集共计:6560张图片,测试集共计:2207张图片。

- 然后将数据储存为TFRecord:

2.分类模型构建
- 使用TensorFlow搭建一个ResNet模型:

3.模型训练
- 模型训练,设置批处理batch_size:64,每2个epoch保存一次模型,博主总共跑了30个epoch。
from tensorflow.keras.callbacks import (
ReduceLROnPlateau,
EarlyStopping,
ModelCheckpoint,
TensorBoard)
# 编译模型来配置学习过程
ResNet_model.compile(optimizer=optimizer,loss='sparse_categorical_crossentropy',metrics=['accuracy'])
callbacks = [
# ReduceLROnPlateau(verbose=1),
# 提前结束解决过拟合
# EarlyStopping(patience=10, verbose=1),
# 保存模型
ModelCheckpoint(checkpoints + 'resnet_train_{epoch}.tf', monitor='accuracy',verbose=0,
# 当设置为True时,将只保存在验证集上性能最好的模型
save_best_only=True, save_weights_only=True,
# CheckPoint之间的间隔的epoch数
period=2),
TensorBoard(log_dir='logs')
]
# 模型训练
history = ResNet_model.fit(data_train, epochs = epoch,callbacks=callbacks,validation_data = data_test)
- 训练和测试集的准确率如下,可以看到训练至15个epoch左右已经能达到很高的准确率了。

五、训练自己的数据
1.项目目录如下

2.分类模型训练
- 需要将自己的数据集整理后放入以下项目目录中:
./img/train/
和
./img/test/
下目录设置,一个类别的图片放入一个文件夹中,如下:
然后按顺序执行下述代码:
a数据预处理.ipynb
b加载并训练模型.ipynb
c模型评估及预测.ipynb
即可开始分类模型训练
六、完整代码地址
由于项目代码量和数据集较大,感兴趣的同学可以下载完整代码,使用过程中如遇到任何问题可以在评论区进行评论,我都会一一解答。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)