【序列推荐、Transformer】SASRec:Self-Attentive Sequential Recommendation
《SASRec:基于自注意力机制的序列推荐》transformer最早提出是用在NLP领域做机器翻译的,本文将transformer中的注意力机制用在序列推荐上,**对于给定的物品序列来预测下一个最可能出现的物品是什么**(采用自注意力机制来对用户的历史行为信息建模,提取更为有价值的信息。最后将得到的信息分别与所有的物品embedding内容做内积,根据相关性的大小排序、筛选,得到Top-k个推荐
#论文题目:SASRec:Self-Attentive Sequential Recommendation(SASRec-基于自注意力机制的序列推荐)
#论文地址:https://arxiv.org/abs/1808.09781v1
#论文源码开源地址:https://github.com/kang205/SASRec
#论文所属会议:ICDM 2018
一、创新点
transformer最早提出是用在NLP领域做机器翻译的,本文将transformer中的注意力机制用在序列推荐上,对于给定的物品序列来预测下一个最可能出现的物品是什么(采用自注意力机制来对用户的历史行为信息建模,提取更为有价值的信息。最后将得到的信息分别与所有的物品embedding内容做内积,根据相关性的大小排序、筛选,得到Top-k个推荐。)。该方法在稀疏和密集数据集上都优于各种先进的序列模型。
二、模型结构

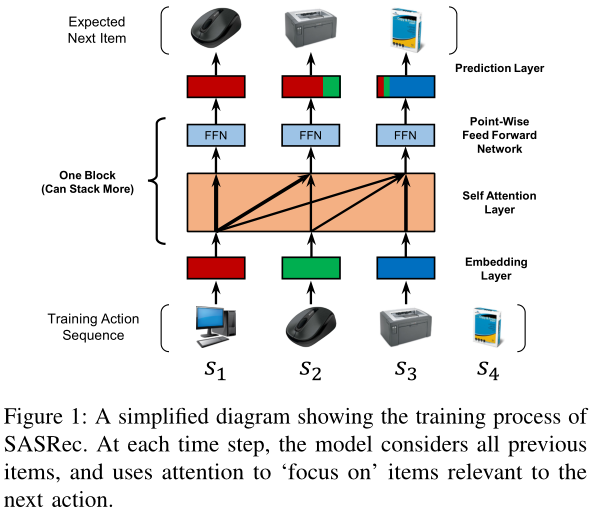
这个结构是不是非常熟悉呢?没错,其实它就是Transformer中的Encoder部分,每个block包括Self-Attention和FFN等。
首先得到商品序列后,Embedding Layer得到物品的向量表示,之后加以聚合,通过Self Attention得到每个物品之间的注意力数值大小,为了避免线性问题导致模型过拟合,Feed Forward NetWork考虑到不同维度隐藏特征的非线性交互,采用两层前馈网络(ReLU),最后通过Predication Layer进行计算商品的数值大小并进行排序,最终取其Top-K的物品作为推荐。
通俗来说:已知用户历史行为,通过SASRec模型得到一个对历史行为的建模,然后我们将其与每一个候选物品(也可以说是目标物品)的表示(Embedding向量)进行交互(文章采用的是内积方式),得到一个 r r ri,t,表示一种相关性。然后将所有的分数进行排序、筛选,完成推荐。
三、方法
3.1 参数定义
对于序列推荐,我们定义一个用户的行为序列:Su = (S1u, S2u, …, S{|Su|}u),目标是预测下一个用户可能发生交互的物品但需要依赖之前用户的交互历史,如下图所示。论文中所需的参数表示见下表:

3.2 Embedding层
文章中重点提到了关于用户行为序列的表示:将行为序列
S
S
Su = (
S
S
S1u,
S
S
S2u, …,
S
S
S{|Su|}u)转化为一个适宜长度的序列
s
s
s = (
s
s
s1,
s
s
s2, …,
s
s
sn)。对于用户
u
u
u,若其行为序列的长度大于
n
n
n,则取离当前最近的
n
n
n个行为;若小于
n
n
n,则采用0在左边进行填充,直至长度为
n
n
n。经过Embedding操作得到物品的向量矩阵
M
M
M∈
R
R
R|I|×d,
I
I
I表示物品集合,
d
d
d是embedding的维度。
对于每一个用户行为序列,都可以检索得到Embedding向量,最终得到
E
E
E∈
R
R
Rn×d,
E
E
Ei =
M
M
MSi。

Positional Embedding
在Transformer中,我们知道,self-attention本身是不具备一种位置关系的,即交换序列中元素的位置,并不影响最终的结果。(但是如果对于一句话“hello, my friend. ”,就拿my这个单词举例,attention的数值只是和“my”前面的词有关,因此不能考虑句子中“my”后面的单词。)同理,用户在预览某些商品的时候,下一件商品可能和上一件商品有关联,(如我们买电脑,下一件商品极有可能买鼠标等),因此Transformer中引入Positional Embedding(位置嵌入),来表示序列中的一种先后位置关系。假设位置Embedding为P∈Rn×d,与行为序列的Embedding相加:

此时的E^就是模型训练时候的输入矩阵。
与Transformer不同的就是,这里的P矩阵是跟随模型一起训练得到的,并不是手动设计的了。(作者说尝试了那种方式,效果不太好)。那这显然就引入了SASRec的一个弊端,这种跟随模型学到的矩阵P,并不能处理长列,可扩展性不强,在实际系统中基本无法确定n的长度。
3.3 Self-Attention层
该部分与Transformer的「编码层」大体上是一致的,是由「多个(或单个)【自注意力机制+(残差连接、LayerNormalization、Dropout)+前馈网络】」 组成。但其中也有一些作者自己的一些想法创新,重点记录下该内容,Self-Attention部分比较简略。
3.3.1 Self-Attention Block
对于普通的单个自注意力层模块:
- 简单的注意力机制函数(这里指采用点积方式计算注意力分数)定义如下:

在NLP中,一般 K K K= V V V - 在自注意力方法中,
Q
Q
Q,
K
K
K,
V
V
V都来自同一对象。在本文中,对输入E^通过线性投影转化为三个矩阵,并使用于上述注意力函数:

其中WQ, WK, WV∈Rd×d是线性投影矩阵,最后得到的Q, K, V∈Rn×d,具体见下图:

- 前馈网络:虽然自注意力通过权重聚合了所有先前的item embedding,但是它最终依旧是一个线性模型。因此考虑到不同维度隐藏特征的非线性交互,本文与Transformer一样,在self-attention之后,采取两层的前馈网络:

创新点:文章该部分的创新点主要在自注意力函数中的QKT,自注意力函数将Q, K, V都经过线性投影得到,这增加了模型的灵活性。
Due to the nature of sequences, the model should consider only the first t items when predicting the (t + 1 ) - st item. However, the t-th output of the self-attention layer (St) contains embeddings of subsequent items, which makes the model ill-posed.
即在QiKjT中,当i < j时候,存在一种超前查询的现象,因此作者禁止该情况的交互。(Q是查询向量,不能与之后的历史物品的信息进行交互)
3.3.2 Stacking Self-Attention Blocks
这里与Transformer的思想类似,认为叠加多个自注意力机制层能够学习更复杂的特征转换。第[b]个自注意力block定义为:

然而网络层数越深,会存在一些问题:
模型更容易过拟合;
- 训练过程不稳定(梯度消失问题等);
- 模型需要学习更多的参数以及需要更长的时间训练;
- 因此,作者在自注意力机制层和前馈网络(加入残差连接、Layer Normalization、Dropout)来抑制模型的过拟合。(其实依旧与Transformer类似),下图为Transformer结构做参考:

用公式表示为:


3.4 预测层
3.4.1
在经过b个self-attention block之后,用户行为中的信息得到有效的提取,即Ft(b),模型最终的目标是预测下一个用户感兴趣的物品,因此,作者通过一个MF层来预测物品i的相关性:

【注】:物品的Embedding矩阵表示是不同的,模型之前训练得到的是M,而这是N,结合下文内容,这里N应该指的是一个已经训练好的物品Embedding矩阵。
3.4.2
为了减小模型大小以及过拟合,作者使用了SASRec模型训练的单个商品的Embedding矩阵进行交互:

Ft(b)作为一个依赖于M的函数:

这里,作者称之为Shared Item Embedding。作者提到如果采用相同的Embedding表示,会产生一个问题:无法通过内积表示一种不对称的转换。文中举例:如果在物品j之后会频繁的买物品i,但是反过来却不可能。但是用相同的Embedding表示,进行内积操作后,却没有区分:
使用同质(homogeneous)商品embedding的一个潜在问题是,它们的内部产品不能代表不对称的商品转换。然而,我们的模型没有这个问题,因为它学习了一个非线性变换。例如,前馈网络可以很容易地实现同项嵌入的不对称性,经验上使用共享的商品embedding也可以大大提升模型的效果;

像FPMC模型通过不同的Embedding解决这个问题。不过,作者指出,SASRec模型不会有这个问题:

3.5 模型训练
将每一个用户行为序列转化成s = {s1, s2, …, st},并且定义输出ot:

如果输入为填充值,输出也是填充值。定义最终的交叉损失函数为:

文章采用Adam优化器,并且针对每一时刻的正样本,都会随机生成一个物品[公式]来作为负样本,平衡训练过程中正负样本的比例。
四、数据集
文章在选取数据集也很严谨。选择了两个稀疏数据集(Amazon-Beauty、Amazon-Games)、物品平均交互多,用户平均交互少的Steam和密集型数据集(Movielens-1m),内容如下所示:

附录
也在知乎上搜了搜该方法的创新点,但是通过自己和transformer进行比较,感觉也没什么创新点。


链接:https://www.zhihu.com/question/482682947

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)