『scrapy爬虫』03. 爬取多个页面(详细注释步骤)
『scrapy爬虫』03. 爬取多个页面(详细注释步骤)
欢迎关注 『scrapy爬虫』 专栏,持续更新中
欢迎关注 『scrapy爬虫』 专栏,持续更新中
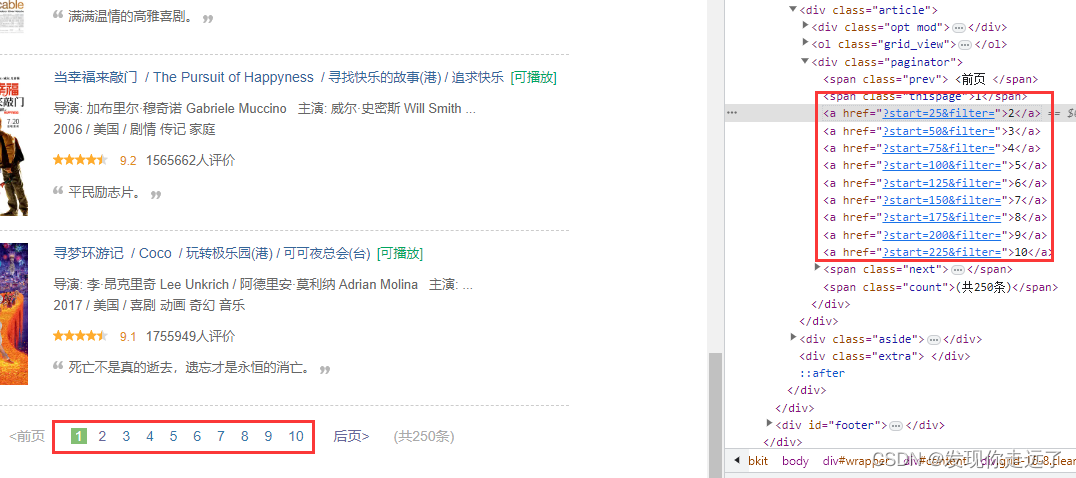
1. 分析网页试着拿到多个页面的url
看到了一个个a标签对应的几页的页码url

这是1页到3页,因为是top250,总共10页.每一页就是25个,也对应着url中的参数0,25,50````````
https://movie.douban.com/top250?start=0&filter=
https://movie.douban.com/top250?start=25&filter=
https://movie.douban.com/top250?start=25&filter=
我们的douban.py
import scrapy
from scrapy import Selector
from myscrapy.items import MovieItem
class DoubanSpider(scrapy.Spider):
name = "douban"
allowed_domains = ["movie.douban.com"]# 限制或允许访问的域名列表
start_urls = ["https://movie.douban.com/top250"] # 起始url
def parse(self, response):
myselector=Selector(text=response.text)
# 拿到了所有的li,也就是所有的电影,每一个li代表一个电影,list_items是由250个电影li组成的list
list_items=myselector.css("#content > div > div.article > ol > li")
for list_item in list_items:
movie_item=MovieItem()#新建类的对象
# 电影标题的 Selector
# content > div > div.article > ol > li:nth-child(1) > div > div.info > div.hd > a > span:nth-child(1)
movie_item['title']=list_item.css("span.title::text").extract_first() # extract_first()从选择器中提取第一个匹配的数据。
# 电影评分
# content > div > div.article > ol > li:nth-child(1) > div > div.info > div.bd > div > span.rating_num
movie_item['score']=list_item.css("span.rating_num::text").extract_first() # extract_first()从选择器中提取第一个匹配的数据。
# # 电影影评
# content > div > div.article > ol > li:nth-child(1) > div > div.info > div.bd > p.quote > span
movie_item['quato']=list_item.css("span.inq::text").extract_first() # extract_first()从选择器中提取第一个匹配的数据。
yield movie_item#把整理得到的数据给管道
# 单个页面selector
# content > div > div.article > div.paginator > a:nth-child(3)
# ::attr(href)表示选取元素的href属性。使用.getall()方法可以获取匹配到的所有元素的href属性值,并将其存储在一个列表中。
hrefs_list=myselector.css('div.paginator > a::attr(href)')
for href in hrefs_list:
url=response.urljoin(href.extract())
print(url)
cmd运行,可以看到获取了url
scrapy crawl douban

2. 抓取250个电影
这里要用到scrapy中的request库,注意不是我们之前的requests这一个s的区别很大,不要导错包了.
我们之前不是定义过一个MovieItem类吗?这个request是scrapy内部定义好的,我们在这里传入的url都会和我们前面的start_urls = ["https://movie.douban.com/top250"] # 起始url 一样用于爬虫.
import scrapy
from scrapy import Selector,Request
from myscrapy.items import MovieItem
class DoubanSpider(scrapy.Spider):
name = "douban"
allowed_domains = ["movie.douban.com"]# 限制或允许访问的域名列表
start_urls = ["https://movie.douban.com/top250"] # 起始url
def parse(self, response):
myselector=Selector(text=response.text)
# 拿到了所有的li,也就是所有的电影,每一个li代表一个电影,list_items是由250个电影li组成的list
list_items=myselector.css("#content > div > div.article > ol > li")
for list_item in list_items:
movie_item=MovieItem()#新建类的对象
# 电影标题的 Selector
# content > div > div.article > ol > li:nth-child(1) > div > div.info > div.hd > a > span:nth-child(1)
movie_item['title']=list_item.css("span.title::text").extract_first() # extract_first()从选择器中提取第一个匹配的数据。
# 电影评分
# content > div > div.article > ol > li:nth-child(1) > div > div.info > div.bd > div > span.rating_num
movie_item['score']=list_item.css("span.rating_num::text").extract_first() # extract_first()从选择器中提取第一个匹配的数据。
# # 电影影评
# content > div > div.article > ol > li:nth-child(1) > div > div.info > div.bd > p.quote > span
movie_item['quato']=list_item.css("span.inq::text").extract_first() # extract_first()从选择器中提取第一个匹配的数据。
yield movie_item#把整理得到的数据给管道
# 单个页面selector
# content > div > div.article > div.paginator > a:nth-child(3)
# ::attr(href)表示选取元素的href属性。使用.getall()方法可以获取匹配到的所有元素的href属性值,并将其存储在一个列表中。
hrefs_list=myselector.css('div.paginator > a::attr(href)')
for href in hrefs_list:
url=response.urljoin(href.extract())
# print(url)
# 将 Request 对象加入到爬虫的请求队列中,以便发送请求,相当于对每个页面执行抓取数据
yield Request(url=url) #注意这个Request是来自scrapy的. from scrapy import Selector,Request
cmd运行
scrapy crawl douban -o douban250.csv

3. start_requests的使用
修复一个bug(为什么250条数据变多了)?
我们的起始页面start_urls = ["https://movie.douban.com/top250"] # 起始url
但是我们知道,页面的规则,因为是第一页比较特殊,省略了参数0,实际上第一页的url应该是https://movie.douban.com/top250?start=0&filter=,这导致我们重复2次爬取了第一页的数据,出现了2次肖申克的救赎

解决方案1,直接修改起始页面
start_urls = ["https://movie.douban.com/top250"] # 起始url
改为
start_urls = ["https://movie.douban.com/top250?start=0&filter="] # 起始url
优雅方案2,start_requests一开始就设置要解析的url,不爬取页面url,告诉爬虫要爬的页面有哪些
import scrapy
from scrapy import Selector,Request
from myscrapy.items import MovieItem
class DoubanSpider(scrapy.Spider):
name = "douban"
allowed_domains = ["movie.douban.com"]# 限制或允许访问的域名列表
start_urls = ["https://movie.douban.com/top250"] # 起始url
def start_requests(self) :
for page in range(10): #10页
yield Request(url=f'https://movie.douban.com/top250?start={page*25}&filter=')
def parse(self, response):
myselector=Selector(text=response.text)
# 拿到了所有的li,也就是所有的电影,每一个li代表一个电影,list_items是由250个电影li组成的list
list_items=myselector.css("#content > div > div.article > ol > li")
for list_item in list_items:
movie_item=MovieItem()#新建类的对象
# 电影标题的 Selector
# content > div > div.article > ol > li:nth-child(1) > div > div.info > div.hd > a > span:nth-child(1)
movie_item['title']=list_item.css("span.title::text").extract_first() # extract_first()从选择器中提取第一个匹配的数据。
# 电影评分
# content > div > div.article > ol > li:nth-child(1) > div > div.info > div.bd > div > span.rating_num
movie_item['score']=list_item.css("span.rating_num::text").extract_first() # extract_first()从选择器中提取第一个匹配的数据。
# # 电影影评
# content > div > div.article > ol > li:nth-child(1) > div > div.info > div.bd > p.quote > span
movie_item['quato']=list_item.css("span.inq::text").extract_first() # extract_first()从选择器中提取第一个匹配的数据。
yield movie_item#把整理得到的数据给管道
# # 单个页面selector
# # content > div > div.article > div.paginator > a:nth-child(3)
# # ::attr(href)表示选取元素的href属性。使用.getall()方法可以获取匹配到的所有元素的href属性值,并将其存储在一个列表中。
# hrefs_list=myselector.css('div.paginator > a::attr(href)')
# for href in hrefs_list:
# url=response.urljoin(href.extract())
# # print(url)
# # 将 Request 对象加入到爬虫的请求队列中,以便发送请求,相当于对每个页面执行抓取数据
# yield Request(url=url) #注意这个Request是来自scrapy的. from scrapy import Selector,Request
cmd运行
scrapy crawl douban -o douban250_true.csv

4. 代码规范
导库的优化
在优化 Python 代码的导入语句时,通常会按照一定的规则和顺序进行排序和分组。这些规则和顺序有助于提高代码的可读性和维护性。以下是一般情况下推荐的导入规则和顺序:
- 标准库导入:首先导入Python标准库中的模块,每个导入语句占一行。
python
import os
import sys
- 第三方库导入:接着导入第三方库或框架的模块,每个导入语句占一行。
python
import requests
import pandas as pd
本地应用/模块导入:最后导入项目中的自定义模块或应用程序模块。
python
from myapp import utils
from myapp.models import User
-
空行分隔:在不同类型的导入之间加入空行,以提高可读性。
-
按字母顺序排序:可以按照字母顺序对每个导入组进行排序,或者使用工具自动排序。
-
避免通配符导入:尽量避免使用 from module import * 的方式,应该明确导入需要的内容。
-
别名处理:合理使用别名来简化长模块名,但不要过度缩写或使用难以理解的别名。用一些约定俗成的别名.
import pandas as pd
可以使用pycharm的快捷整理你的导包书写规范

关于重写
可以看到警告.

Signature of method 'DoubanSpider.parse()' does not match signature of the base method in class 'Spider'
这是因为我们的parse继承的DoubanSpider类的scrapy.Spider,我们按住ctrl点击scrapy.Spider前往观察这个被重写的方法,从图中可以看到这几个def都是重写这个spide的方法

class DoubanSpider(scrapy.Spider):
def parse(self, response):
可以看到被重写的方法原型

统一格式
改为下面代码即可消除警告
def parse(self,response, **kwargs):
最终修改后的代码
import scrapy
from scrapy import Selector,Request
from myscrapy.items import MovieItem
class DoubanSpider(scrapy.Spider):
name = "douban"
allowed_domains = ["movie.douban.com"]# 限制或允许访问的域名列表
start_urls = ["https://movie.douban.com/top250"] # 起始url
def start_requests(self) :
for page in range(10): #10页
yield Request(url=f'https://movie.douban.com/top250?start={page*25}&filter=')
def parse(self,response, **kwargs):
myselector=Selector(text=response.text)
# 拿到了所有的li,也就是所有的电影,每一个li代表一个电影,list_items是由250个电影li组成的list
list_items=myselector.css("#content > div > div.article > ol > li")
for list_item in list_items:
movie_item=MovieItem()#新建类的对象
# 电影标题的 Selector
# content > div > div.article > ol > li:nth-child(1) > div > div.info > div.hd > a > span:nth-child(1)
movie_item['title']=list_item.css("span.title::text").extract_first() # extract_first()从选择器中提取第一个匹配的数据。
# 电影评分
# content > div > div.article > ol > li:nth-child(1) > div > div.info > div.bd > div > span.rating_num
movie_item['score']=list_item.css("span.rating_num::text").extract_first() # extract_first()从选择器中提取第一个匹配的数据。
# # 电影影评
# content > div > div.article > ol > li:nth-child(1) > div > div.info > div.bd > p.quote > span
movie_item['quato']=list_item.css("span.inq::text").extract_first() # extract_first()从选择器中提取第一个匹配的数据。
yield movie_item#把整理得到的数据给管道
# # 单个页面selector
# # content > div > div.article > div.paginator > a:nth-child(3)
# # ::attr(href)表示选取元素的href属性。使用.getall()方法可以获取匹配到的所有元素的href属性值,并将其存储在一个列表中。
# hrefs_list=myselector.css('div.paginator > a::attr(href)')
# for href in hrefs_list:
# url=response.urljoin(href.extract())
# # print(url)
# # 将 Request 对象加入到爬虫的请求队列中,以便发送请求,相当于对每个页面执行抓取数据
# yield Request(url=url) #注意这个Request是来自scrapy的. from scrapy import Selector,Request
总结
大家喜欢的话,给个👍,点个关注!给大家分享更多计算机专业学生的求学之路!
版权声明:
发现你走远了@mzh原创作品,转载必须标注原文链接
Copyright 2024 mzh
Crated:2024-3-1
欢迎关注 『scrapy爬虫』 专栏,持续更新中
欢迎关注 『scrapy爬虫』 专栏,持续更新中
『未完待续』

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 19
19 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)