python-DrissonPage实现手爬淘宝网
推荐学习的网址:据某GPT搜索,淘宝的难度有以下:反爬机制:淘宝网使用了一些反爬虫技术,如验证码、IP封锁、动态页面加载等。这些机制会使得爬取数据变得困难,因为你需要找到解决这些反爬措施的方法。动态页面加载:淘宝网的页面通常采用了动态加载技术,也就是说,页面内容可能会通过JavaScript动态生成。这意味着你需要使用工具或库,如Selenium或PhantomJS来模拟浏览器行为并获取完整的页面
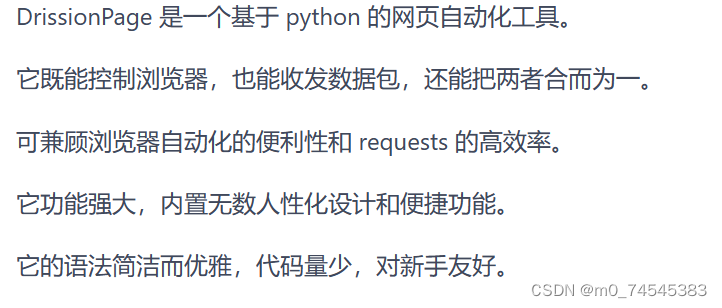
推荐学习的网址:DrissionPage (gitee.io) https://g1879.gitee.io/drissionpagedocs/
https://g1879.gitee.io/drissionpagedocs/
据某GPT搜索,淘宝的难度有以下:
-
反爬机制:淘宝网使用了一些反爬虫技术,如验证码、IP封锁、动态页面加载等。这些机制会使得爬取数据变得困难,因为你需要找到解决这些反爬措施的方法。
-
动态页面加载:淘宝网的页面通常采用了动态加载技术,也就是说,页面内容可能会通过JavaScript动态生成。这意味着你需要使用工具或库,如Selenium或PhantomJS来模拟浏览器行为并获取完整的页面内容。
-
数据结构和处理:淘宝网的页面结构复杂,数据分散在多个层级和标签中。你需要仔细分析页面结构,使用HTML解析库(如Beautiful Soup)来提取所需的数据。
-
登录和会话管理:如果你需要访问需要登录的页面或进行交互操作(如添加商品到购物车),你还需要处理登录和会话管理。这可能涉及到模拟用户登录、保存和管理会话Cookie等操作。
但这一次我用的全新的方式,简单且粗暴,————一款全新的自动化框架DrissionPage
DrissionPage概述: 
其中唯一的难点就是滑块验证,这就要涉及到opencv。在以后的教程中会详细的讲解。
我们从这个淘宝网 - 淘!我喜欢 (taobao.com)https://login.taobao.com/member/login.jhtml网址走起,整个过程大家可以自己过一遍,而自动化就是一个模仿人的操作,如果大家尝试了各种点击,那么使用DrissionPage就是要完成这样一个操作。
1.登录页面
def login(drission):
# 定位账号文本框,并输入账号
account_input = drission.ele('@id=fm-login-id').input('账号') # 定位密码文本框,并输入密码
password_input = drission.ele('@id=fm-login-password').input('密码')
if '向右滑动验证' in drission.html:
login_huakuai()
# 点击登录按钮
login_button = drission.ele('@class =fm-button fm-submit password-login').click()
time.sleep(2)
return drission2.验证码登录
第一次登录,或者清楚了缓存,都会要验证码登录,之后可有可无
def yanzhenam(drission):
try:
# 查找 iframe 元素
drission.driver.switch_to.frame(iframe=drission.get_frame(1).html)
# print(drission.html) #获取验证码
drission.ele('@id=J_GetCode').click()
drission.driver.waite.display()
yzm = input('enter code:')
drission.ele('@id=J_Phone_Checkcode').input(yzm)
drission.ele('@id=submitBtn').click()
time.sleep(3)
except:
return drission3.点击首页,点击手机
跳转到手机相关页面,这里演示的是爬取手机相关信息
def gotoindex_and_phone(drission):
try:
drission.ele('xpath:/html/body/div[1]/div/ul[2]/li[1]/div/div/span').click()
except:
pass
drission.driver.wait.display() # 等待直到出现
drission.ele('xpath:/html/body/div[3]/div[1]/div/ul/li[5]/a[1]').click()
drission.to_tab(drission.latest_tab) # 切换至最新的窗口
return drission4.滑块验证
自动化爬取淘宝最难的地方就是滑块验证、点击验证,这里我只展示了滑块验证。其他验证后续发出
def huakai():
page = ChromiumPage()
ac = ActionChains(page)
while True:
try:
ac.hold('xpath:/html/body/div/div[2]/div/div[1]/div[2]/center/div[1]/div/div/div/span') # 抓住元素
huakuai_size = drission.ele( # 获取滑块区域的长度
'xpath:/html/body/div/div[2]/div/div[1]/div[2]/center/div[1]/div/div/div').size[0]
print(huakuai_size)
lenth = huakuai_size / 3 # 求滑块的长
print(lenth)
lenth_ = [random.uniform(0, lenth) for i in range(3)] # 三次随机长度
sum_ = sum(lenth_)
for i in lenth_:
ac.move(i, 0)
ac.wait(random.uniform(0, 1.1))
ac.move(lenth - sum_ + 1)
time.sleep(5)
if "error" in drission.html:
drission.ele('xpath:/html/body/div/div[2]/div/div[1]/div[2]/center/div[1]/div/div/div').click()
continue
except:
return5.连接数据库
根据自己需要爬取的字段,创库创表
def init_sql():
conn = pymysql.connect(host='localhost', port=3306, user='root', password='root')
cur = conn.cursor()
cur.execute('create database if not exists taobao1;')
cur.execute('use taobao1;')
cur.execute('drop table if exists T_label;') # 先删从表再删主表
cur.execute('drop table if exists T_region;')
cur.execute('drop table if exists T_phone;')
cur.execute("""create table T_phone(id varchar(100) primary key,
Title varchar(100) not null,
Price varchar(100) not null,
Number varchar(100) not null,
business varchar(100) not null);""")
cur.execute("""create table T_region(id int auto_increment primary key,
city varchar(100) not null,
region_id varchar(100) not null,
foreign key(region_id) references T_phone(id));""")
cur.execute("""create table T_label(id int auto_increment primary key,
label varchar(100) not null,
label_id varchar(100) not null,
foreign key(label_id) references T_phone(id));""")
return conn, cur6.爬取信息,保存至数据库
以下代码涉及到翻页、保存数据、元素定位、已经随机滑块验证。
def get_tags(tags):
tag = []
for t in tags:
tag.append(t.select_one('span').text)
return tag
def get_value(page, id):
page.wait.load_start() # 等待页面进入加载状态
drission.driver.waite.display()
html = page.html # 获取源码
req = BeautifulSoup(html, 'lxml') # 转成beautifulSOUp对象
huakai() # 是否出现滑块
drission.driver.waite.display() # 休眠
time.sleep(1) # 休眠
divs = req.select('div.Content--content--sgSCZ12 > div.Content--contentInner--QVTcU0M > div') # 最每一个手机的div
# 获取每个div的内容
for div in divs:
# drission.driver.waite.display()
# time.sleep(1)
Title = re.sub('\s+', '', div.select_one(
'div > a > div > div.Card--mainPicAndDesc--wvcDXaK > div.Title--descWrapper--HqxzYq0 > div > span').get_text())
print(Title)
div1 = div.select_one(
'div > a > div > div.Card--mainPicAndDesc--wvcDXaK > div.Price--priceWrapper--Q0Dn7pN')
Price = div1.select_one('.Price--unit--VNGKLAP').text + div1.select_one(
'.Price--priceInt--ZlsSi_M').text + div1.select_one('.Price--priceFloat--h2RR0RK').text
Number = div1.select_one('.Price--realSales--FhTZc7U').text
print(Price)
print(Number)
div2 = div1.select('div')
citys = get_tags(div2)
print(citys)
div3 = div.select('div > a > div > div.SalesPoint--subIconWrapper--s6vanNY > div')
labels = get_tags(div3)
print(labels)
business = div.select_one(
'div > a > div > div.ShopInfo--shopInfo--ORFs6rK > div.ShopInfo--TextAndPic--yH0AZfx > a').text
print(business)
insert_sql(Title, Price, Number, citys, labels, business) # 每爬取一个就插入数据库
print(id)
next_page(page, id + 1)
def next_page(page, id):
try: # 点击下一页
page.ele('@class=next-btn next-medium next-btn-normal next-pagination-item next-next').click()
# page.wait.load_start() # 等待页面进入加载状态
if page is not None:
get_value(page, id)
except:
return None
# 数据库
def get_id():
id = ''.join([random.choice(string.digits + string.ascii_letters) for i in range(10)])
return id
7.关闭数据库
def close_sql():
cur.close()
conn.close()8.调用整个函数
if __name__ == '__main__':
# 创建页面对象,并启动或接管浏览器
# 设置Edge浏览器的路径
set_paths(browser_path=r'C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe')
# 创建Drission对象,并指定浏览器名称为"edge"
drission = WebPage()
# 打开淘宝登录页面
drission.get('https://login.taobao.com/member/login.jhtml')
drission = login(drission) # 登录函数
drission = yanzhenam(drission) # 验证码登录
drission = gotoindex_and_phone(drission) # 去到首页和点击手机
huakai() # 滑块验证
conn, cur = init_sql() # 初始化数据库
print('数据库创建完成')
get_value(drission, 1)
close_sql() # 关闭数据库

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)