DSP——从入门到放弃系列1(持续更新)
以下为本人在学习和使用TI C6678或国产FT2000的总结和感想,属于基础内容,欢迎各位同学同行交流。最近在学习国产化DSP处理器FT系列,因此下面的一些例子会以FT举例。
讲在前面
以下为本人在学习和使用TI C6678或国产FT2000的总结和感想,属于基础内容,欢迎各位同学同行交流。最近在学习国产化DSP处理器FT系列,因此下面的一些例子会以FT举例。与TIC6678相比飞腾的M6678没有了包加速作用的QMSS、CPPI,在这里原有的Teranet总线被替换为Crossnet总线。
1、DSP的架构
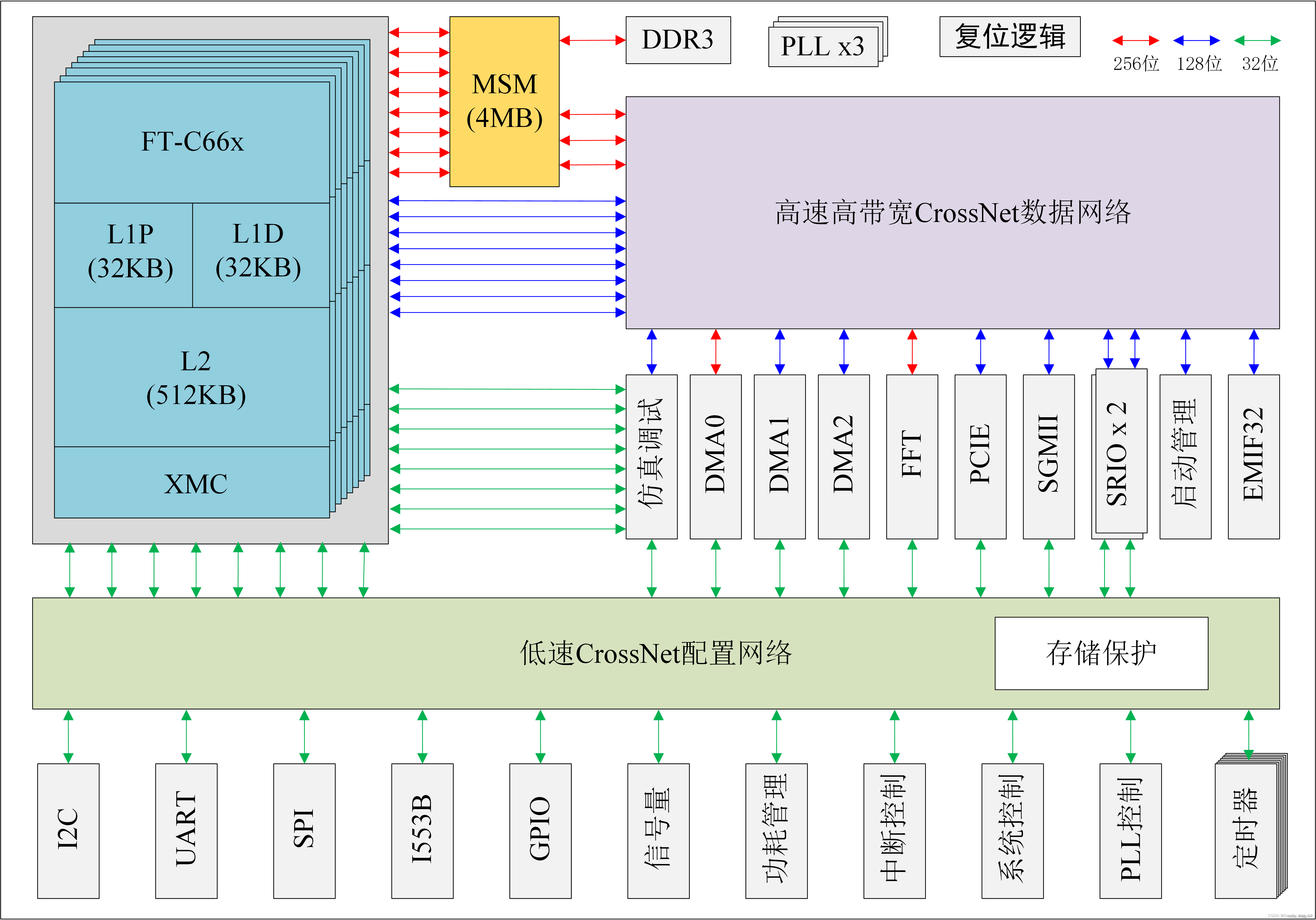
DSP的主频一般设为1GHz,(配置原理见DSP系统时钟配置),FT处理器的架构如下图:

2、内存情况
6678的存储器主要由L1P、L1D、L2、MSM以及DDR3组成,其中L1P、L1D、L2是每个核私有的一片区域,MSM是八个核共享的一段4MB的空间,DDR3是外部挂载的扩展存储空间,FT6678存储器的架构如下图所示。

与C6678相似,M6678同样拥有两级缓存L1和L2。
L1P(program)是DSP取指流水线和一级存储控制器(L1)之间的接口,主要作用是直接向 CPU 提供指令。
L1D(data)是DSP数据和L1之间的接口,是与CPU具有相同工作频率且与CPU最接近的数据存储器。可以通过字节、半字、字、双字的读写完成对CPU存储指令的处理。
L2是高级存储器和L1之间的接口,作为L1D和L1P的下一级存储器,既可以用来存放数据又可以用来存放程序。L2 SRAM中的数据可以通过使用在L1D/L1P Cache中存在的副本,减少对相同数据的重复读取,提高程序的运行效率。
L1P、L1D、L2均支持存储保护、带宽管理机制和低功耗控制等功能,且都可以通过修改相关寄存器,完成Cache/SRAM比例的配置。L1P可以将它的部分存储器配置成一路组相联的大小为4KB,8KB,16KB 或 32KB的Cache;L1D可以将它的部分存储器配置成两路组相联的大小为4KB,8KB,16KB 或 32KB的Cache;L2可以将它的部分存储器配置成四路组相联的大小为32KB,64KB,128KB,256KB或512KB的Cache,可以选择多少空间用作Cache多少空间用作SRAM。
MSM也被称为L3,还提供了可被包括8个FT-M66x内核、DMA控制器等在内的所有主机访问的4MB的片上共享 SRAM,并可以处理上述主机的访问请求,完成请求仲裁。同时还可挂载DDR3以扩展外部存储空间。在时钟频率为1333MHz(最大频率)时,DDR可提供高达10.664GB/s的通信带宽;在1GHz的DSP主频下,MSMC可提供高达64GB/s的通信带宽。
对于上面提到的L1P、L1D、L2、MSMC、DDR等内存空间,都可以通过连接命令文件 (Linker Command Files,CMD 文件 CCS中的linker.cmd)对其重新划分。CMD文件主要由MEMORY和SECTIONS组成:
MEMORY用来配置芯片存储器的区域,用户可以自行定义各存储器区域的起始地址和长度;
SECTIONS用来指定段的存放位置。下图为例子:

下面来分析一下这个例子:
-c为链接器选项,主要与变量的初始化时机有关,当选择-cr时,变量会在加载程序时进行初始化,当选择-c时,程序会在运行main函数前,自动完成变量的初始化。
-heap和-stack为设置的堆和栈的大小(注意堆和栈不是一回事),堆主要用来存放动态内存的数据,对于堆中存放的动态数组,需要用户通过malloc/calloche和free进行手动管理。栈则主要用来存放局部变量。本例中将堆的大小设为了0x30000=192KB,将栈的大小设为了0x8000=32KB。
我们可以在MEMORY中配置芯片存储器的区域,以便更加高效合理利用DSP的内存区域。在编写MEMORY时需要注意起始地址应在相应内存空间的区域之内,且总长度不能超过存储器的长度。以二级存储控制器L2为例,它在FT-M6678中内存的起始地址为0x00800000,总长度为512KB,512KB换算成十六进制为512*1024=0x80000,则它在内存中的地址区域为0x00800000-0x00880000。本文将L2划分为两个区域VECTORS和L2SRAM,前者用来存放中断向量表,后者一名来存放代码、变量等段数据。两个区域的总长度应不大于512KB,且都在L2所在区域内。因此,本文将VECTORS的起始地址设为0x00800000,长度为0x200,则它的地址区域为0x00800000-0x00800200,将L2SRAM的起始地址设为0x00800200,长度为0x7FE00,则它的地址区域为0x00800200-0x00880000。两片区域的总长度为512KB,且都在L2所在的区域内。此外,在分配存储器区域时,区域是一块连续的空间,不同的区域不能有交叉重叠。
我们可以在SECTIONS中指定段的存放位置,在SECTIONS中,前面的名称为段名,后面的名称为MEMORY部分用户自行划分的存储器区域,一般包含一下几个部分:
| vecs | 存放中断向量表,如本例中即将使用的SRIO接口,在收到门铃中断后,需要程序自行跳转至中断服务函数,这个过程由中断向量表来进行控制; |
| .text | 存放二进制可执行代码和常量; |
| .cinit | 存放初始化的变量和常量; |
| .sysmem | 为动态申请的空间保留的存储区; |
| .stack | 栈区,存放局部变量; |
| .far | 存放未初始化的far类型的全局和静态变量; |
| .fardata | 存放显式初始化的非常数的全局和静态变量; |
| .const | 存放初始化的字符串常量、far类型和const类型的全局变量和静态变量; |
| .bss | 存放未初始化的全局和静态变量; |
| .data | 存放初始化的数据常量; |
| .neardata | 存放显示初始化的near类型的非常数全局和静态变量; |
| .rodata | 存放初始化的near类型的全局和静态变量; |
| .cio | 存放C的I/O缓冲区; |
| .switch | 存放switch语句的跳转表 |
上面提到的far和near类型属于C指针的存储属性,表示指针所指地址的远近,具体解释为:
near (近)指针:16位段内偏移地址
far(远)指针:16位段地址+16位段内偏移地址
huge(巨)指针:32位规格化的具有唯一性的内存地址
关于显式初始化和隐式初始化:
显式初始化即为手工给予初值,否则为隐式初始化,将内容设置为默认值。
自动变量在运行时进入函数的时候,才进行分配空间赋值。非自动变量会自隐式清零,而自动变量是不会自隐式清零的。若没有在定义变量时显式初始化,未赋值前,该变量的内容是不确定值。
以上空间,均位于L2上,其中,还有一些本例自定义的空间,位于MSMC上的.data_msmc段和位于DDR上的.data_ddr0段、.data_ddr1段。
合理的内存分配策略,有助于提高程序的运行效率。
对于内存的分配,主要考虑存储器大小、存储器带宽两个方面。越靠近内核的存储器,带宽越高,数据的读取越快。
对于DSP的存储器,按照上图靠近核心的远近,L1最靠近内核,其次是L2,接着是MSMC,最后的DDR。
对于收到的大量数据,由于大小可能会超过L1/L2的大小,可将其放在距离核心较远的DDR上,在对数据进行算法处理时,可以通过DMA将部分数据搬到动态内存上,将动态内存所在的堆区放在L2,这样可以大幅度提升数据的处理速度。
对于程序中一些共用的结构体和全局变量,可以将其放在MSMC上,八个核能共同访问的同时,还能提高数据的读取速度。
特别地,可以使用DATA_SECTION和DATA_ALIGN关键字,将变量置于用户自定义的空间上。使用DATA_SECTION关键字指定目标区域,使用DATA_ALIGN关键字进行字节对齐操作,提高CPU的数据读取效率。
3、多核任务并行处理
3.1 主从模式
在主从模式中,人为地将8个FT-M66x内核分为主核和从核。一般将0核设为主核,1-7核设为从核,由主核负责对任务进行分配,完成流程控制。每个核相互独立,运行相同的算法处理不同的数据,此种模式下数据处理时间可接近单核的八分之一,每个核采用的算法完全相同,易于工程实现。该模式下主从之间的关系如下图所示。
3.2 数据流模式
在数据流模式中,人为地将算法分为八个部分,每个核执行算法的一部分。该模式下,核间不是相互独立的,而是高度依赖的。0核首先执行属于0核的任务,此时1-7核属于等待状态,0核执行完毕后,1核开始处理0核处理后的数据,此时2-7核处于等待状态,0核开始接收下一帧的回波数据并处理,依次循环,当0核收到第九帧的回波数据后,7核正好处理完第一帧的回波数据,并准备处理第二帧的回波数据。此种模式下,只要不断有数据进行处理,再处理完八帧数据后,数据处理的时间的单核的八分之一,但需要按照计算量,严格地对算法就行分割。该模式下各核与任务之间的关系如下图所示:

通过以上的分析发现,两种模式的数据处理时间都可近似达到单核的八分之一。对于主从模式,并非对所有数据都适用,需要行数据或列数据之间不存在耦合性,可以直接对数据进行分块处理;对于数据流模式,对任何数据的处理均适用,但数据流模式下,需要严格地将总算法按计算量分为八份,大大加剧了工程人员的工作量,工程实现较为困难。因此在DSP进行并行处理操作时,需要选用合适的并行处理模式。
四、多核同步
在主从模式下,需要对数据进行分块操作,八个核采用同样的算法对数据进行处理,在有些情况下,只有八个核都处理完后,才能进行下一步的算法处理,如对矩阵的行进行处理,下一步要对矩阵的列进行处理,只有八个核都完成对矩阵的行处理后,才能进行列处理。由于各种原因的限制,八个核不可能做到严格同时处理完,为保证下一步的正常进行,需要做一个同步处理,以提升程序的稳定性和保证程序的正确性。
FT-M6678在工作时,可以支持实时操作系统SYS/BIOS,也可以在裸核状态下工作。对于操作系统和裸核,FT-M6678均提供了核间通信方式以完成多核同步:
对于操作系统,可以采用消息中间件(Notify)同步、消息队列(Message Queue,MessageQ)、核间中断机制(Inter-Processor Communication,IPC)等方法;
对于裸核,可以采用共享存储区变量、硬件信号量(Semaphore)等方式同步。
考虑到SYS/BIOS操作系统的复杂性和不稳定性,在遇到问题时不易排查,一般常选择裸核的工作模式。接下来本节将主要对裸核模式下的共享存储区变量和硬件信号量两种同步方式做重点分析。
4.1 共享存储区变量
通过共享存储区变量实现多核同步的原理较简单。由本章3.2节可知,在FT-M6678的存储系统中,MSMC和DDR是两段公共的区域,八个核都可以进行访问。在进行多核通信之前,需要首先编写cmd文件,按照前面的方法,通过MEMORY在MSM或DDR中开辟一段公共区域,然后在SECTIONS中完成段的映射,最后将结构体定义在该段上:
typedef struct _Radar_FLAG_
{
char sync_flag[8]; //定义了一个有8个元素数组的结构体,每个核有一个元素,作为同步标志位
}RadarFlag_t;
extern RadarFlag_t RadarFlag;
#pragma DATA_SECTION(RadarFlag,".data_msmc"); //将此结构体定义到data_msmc段上
#pragma DATA_ALIGN(data_msmc, 8); //data_msmc 8字节对齐,最后3位为0
RadarFlag_t RadarFlag;
本例在共享存储区的.datda_msmc段上定义了一个结构体,其中sync_flag是一个拥有8个元素的数组,每个核拥有一个元素,作为同步的标志位。具体的使用如下所示。其中CoreNum为0-7核的核号,初始化阶段,将sync_flag数组里的元素都置为0,执行完多核任务后,将sync_flag[CoreNum] 置为1,当检测到sync_flag数组里的所有元素都为1时,则将sync_flag[CoreNum]重新置为0,并开始进入下一步的多核处理任务,否则在while循环里等待,直到其它核的任务处理完。
multi_task0();
RadarFlag.sync_flag[CoreNum]=1; //执行完一个核的任务就将此核的flag置为1
while(!(RadarFlag.sync_flag[0]&RadarFlag.sync_flag[1]&RadarFlag.sync_flag[2]&
RadarFlag.sync_flag[3]&RadarFlag.sync_flag[4]&RadarFlag.sync_flag[5]&
RadarFlag.sync_flag[6]&RadarFlag.sync_flag[7])); //等待所有核完成任务
RadarFlag.sync_flag[CoreNum]=0; //所有核都完成后flag置0
multi_task1();
该方式虽然实现简单,但可能存在存储高速缓存一致性问题,关于这个问题,将在第5节进行详细分析,多个核对同一片区域读写可能会造成数据的读取失败而不能完成多核的同步。可以通过配置相关的MAR寄存器将某片区域配置为关闭Cache,并将结构体定义在这片区域上以解决这一问题。
4.2 硬件信号量
为多核系统提供一套互斥机制是必要的,可以有效防止多核对同一资源的竞争,而信号量则提供了这一机制。FT-M6678共提供了64个独立的信号量,每个FT-M66x核均可通过直接、间接或组合的方式对任意一个信号量进行访问以完成对共享资源的使用申请。
直接方式:最简单的申请信号量的方式,如果信号量被占用,则返回当前正在使用该信号量的核号,如果信号量为空闲,则返回“0x01”。
间接方式:采用了辅助队列,在对信号量发起请求后,如果信号量被占用,则进入请求队列进行排队,持续等待一旦该信号量被其它核释放,处在队列最顶端的请求事件立即被允许,并占用该信号量,如果信号量为空闲,则直接获取该信号量。
组合方式:直接方式和间接方式的混合,如果信号量空闲,则表现为直接方式,如果信号量被占用时,则表现为间接请求。
三种方式的结果是相同的,因此接下来,将采用较为简单的直接方式对信号量的使用进行分析。
FT-M6678可以直接采用TI为TMS320C6678提供的信号量支持库,完成对信号量的操作。在使用之前,需要将csl_semAux.h包含到工程中,csl_semAux.h是信号量的头文件,里面包含了对各种信号量配置的应用程序编程接口,开发人员可以直接进行调用。在使用信号量时主要使用到了三个函数:CSL_semAcquireDirect(N)、CSL_semReleaseSemaphore(N)、CSL_semIsFree(N)。
CSL_semAcquireDirect(N):采用直接方式对第N个信号量进行申请
CSL_semReleaseSemaphore(N):对第N个信号量进行释放
CSL_semIsFree(N):判断第N个信号量是否处于空闲状态,空闲返回1,否则返回0
使用情况如下所示:
multi_task0();
CSL_semAcquireDirect(CoreNum+1);
while(CSL_semIsFree(1)|CSL_semIsFree(2)|CSL_semIsFree(3)|CSL_semIsFree(4)|
CSL_semIsFree(5)|CSL_semIsFree(6)|CSL_semIsFree(7)|CSL_semIsFree(8));
multi_task1();
CSL_semReleaseSemaphore(CoreNum+1);
while(!(CSL_semIsFree(1)&CSL_semIsFree(2)&CSL_semIsFree(3)&CSL_semIsFree(4)&
CSL_semIsFree(5)&CSL_semIsFree(6)&CSL_semIsFree(7)&CSL_semIsFree(8)));
multi_task2();
在DSP上电后,首先释放掉需要用到的八个核各自需要用到的信号量,使它们处于空闲状态。在执行完多核任务后,各核申请编号为核号+1(不存在编号为0的信号量)的信号量,使用到的八个信号量处于被占用状态,之后进入while循环,判断各个核申请的信号量的状态,等到所有的信号量都处于被占用状态了,说明任务已执行完,进入下一步的任务,任务执行完后,各核释放编号为核号+1的信号量,之后进入while循环,在等待所有的信号量都被释放后,开始执行下一步任务。通过交替进行信号量的申请和释放,完成多核同步。
硬件信号量的实现也较为简单,可以直接调用官方的函数实现,相比于共享存储区变量,不会出现高速缓存一致性问题,准确率更高,具有显著的优势。因此本文采用硬件信号量并使用相对简单的直接方式来实现多核同步。
下一篇:DSP——从入门到放弃系列2(持续更新)
本文参考了此文章,原文链接:https://blog.csdn.net/YULANG007_/article/details/125714141

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 8
8 1
1- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)