机器学习实战3-利用决策树算法根据天气数据集做出决策
大家好,我是微学AI,今天给大家介绍一下机器学习实战3-利用决策树算法根据天气数据集做出决策,决策树是一种广泛使用的机器学习算法,用于分类和回归问题。每个节点都有一个决策规则,用于判断当前数据样本的特征属性值是否满足要求,根据规则的判断结果,将数据样本分配到该节点的某个子节点。决策树的构建是通过一种递归的分割方式实现的,每一次分割都是为了提高模型的预测准确性。欢迎大家关注与支持。
大家好,我是微学AI,今天给大家介绍一下机器学习实战3-利用决策树算法根据天气数据集做出决策,决策树是一种广泛使用的机器学习算法,用于分类和回归问题。它的基本思想是通过对数据进行分而治之,把复杂的问题转化为简单的决策序列。
一、决策树的介绍
对于决策树算法,想一棵树一样有节点与分支,每个节点代表一个特征属性,对应着数据集中的一个特征。每个节点都有一个决策规则,用于判断当前数据样本的特征属性值是否满足要求,根据规则的判断结果,将数据样本分配到该节点的某个子节点。
决策树的构建是通过一种递归的分割方式实现的,每一次分割都是为了提高模型的预测准确性。决策树的生成过程包括三个步骤:
选择最佳特征,划分数据集和递归建树。选择最佳特征的过程是通过计算数据集中各个特征的信息增益或信息增益比等指标,找到最适合用来进行分割的特征。
在根据最佳特征将数据集划分成子集,每个子集对应着决策树的一个分支,然后递归地对子集进行上述操作,直到达到预定的停止条件为止。
再通过决策树可视化工具,可以将决策树图像化,直观地展示决策树的构建过程和结果。

二、决策树的应用
决策树被广泛用于分类和回归的各种实际问题。在生活中,例如在天气的变化方面,使用决策树可以帮助我们对明天是否出行做出决策。
下面我用一个简单的天气数据集作为例子来演示决策树的应用。我们已经创建了一个包含以下特征的CSV文件:
| Outlook | Temperature | Humidity | Windy | Play |
|---|---|---|---|---|
| Sunny | Hot | High | Weak | No |
| Sunny | Hot | High | Strong | No |
| Overcast | Hot | High | Weak | Yes |
| Rainy | Mild | High | Weak | Yes |
| Rainy | Cool | Normal | Weak | Yes |
| Rainy | Cool | Normal | Strong | No |
| Overcast | Cool | Normal | Strong | Yes |
| Sunny | Mild | High | Weak | No |
| Sunny | Cool | Normal | Weak | Yes |
| Rainy | Mild | Normal | Weak | Yes |
| Sunny | Mild | Normal | Strong | Yes |
| Overcast | Mild | High | Strong | Yes |
| Overcast | Hot | Normal | Weak | Yes |
| Rainy | Mild | High | Strong | No |
其中数据说明:
- 外观(Sunny、Overcast和Rainy)
- 温度(Hot、Mild和Cool)
- 湿度(High和Normal)
- 风(Weak和Strong)
最后列是目标标签,即是否出行。
三、决策树的代码实例
接下来,我们将使用Python代码使用决策树算法来判断明天是否出行。
import pandas as pd
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.tree import DecisionTreeClassifier,plot_tree
import matplotlib.pyplot as plt
#读取csv数据
data = pd.read_csv('weather.csv')
#将字符串编码为数字
label_encoder = LabelEncoder()
data['Outlook'] = label_encoder.fit_transform(data['Outlook'])
data['Temperature'] = label_encoder.fit_transform(data['Temperature'])
data['Humidity'] = label_encoder.fit_transform(data['Humidity'])
data['Windy'] = label_encoder.fit_transform(data['Windy'])
#将数字特征进行独热编码
one_hot_encoder = OneHotEncoder(categories='auto')
encoded_features = one_hot_encoder.fit_transform(data[['Outlook', 'Temperature']]).toarray()
#将Play列映射为二进制类别变量
data['Play'] = data['Play'].map({'Yes': 1, 'No': 0})
#将编码后的特征和标签分割
X = pd.concat([pd.DataFrame(encoded_features), data[['Windy', 'Humidity']]], axis=1)
y = data['Play']
#建立决策树模型并进行拟合
model = DecisionTreeClassifier()
model.fit(X, y)
#预测新数据
#【Sunny,Hot,High,Weak】编码为[0, 0, 1, 0, 1, 0, 1, 0]
new_data = pd.DataFrame([[0, 0, 1, 0, 1, 0, 1, 0]], columns=X.columns)
prediction = model.predict(new_data)
if prediction == 1:
print('Play: No')
else:
print('Play: Yes')输入预测数据:【Sunny,Hot,High,Weak】编码为[0, 0, 1, 0, 1, 0, 1, 0]
运行结果:Play: Yes
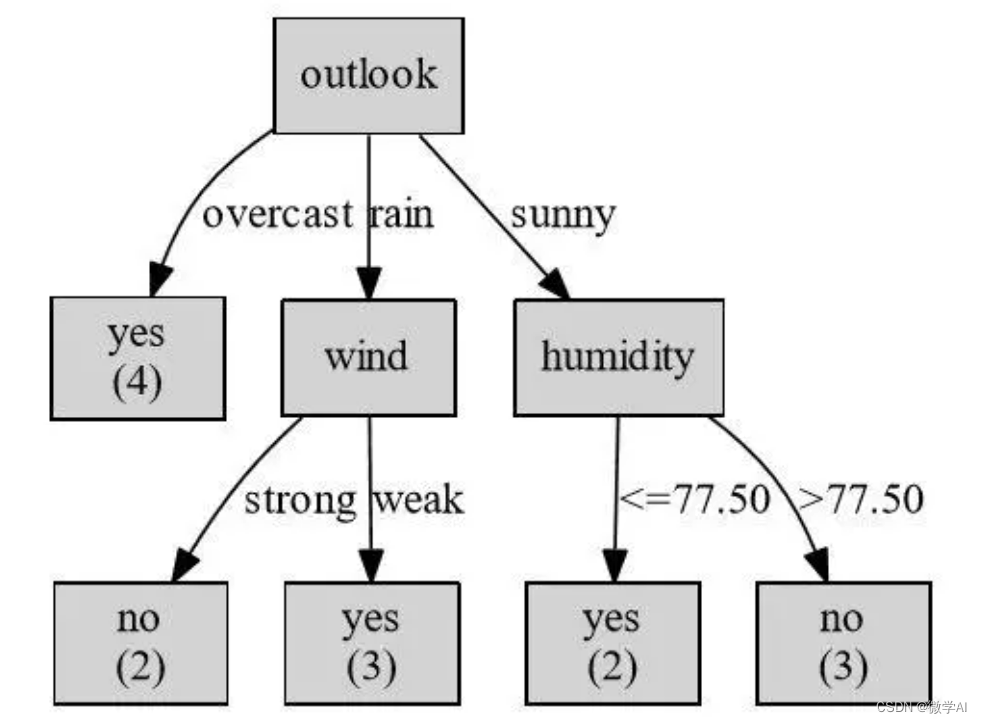
下面用代码生成决策树图:
# 画出决策树
plt.figure(figsize=(8, 8))
plot_tree(model, filled=True, feature_names=X.columns, class_names=['Not Play', 'Play'])
plt.show()
除了作为分类和回归问题的算法外,决策树还有其他应用,例如:
1. 特征选择:通过决策树学习的过程可以得到各个特征在分类中的重要性,从而进行特征选择。
2. 模式识别:决策树可以用于语音识别、手写数字识别等模式识别问题。
3. 数据挖掘:决策树可以用于挖掘数据中的关联规则、异常值等。
4. 购物推荐:决策树可以根据用户的历史购买情况,推荐其可能感兴趣的商品。
5. 医疗诊断:决策树可以用于分析患者的症状和疾病之间的关系,辅助医生进行诊断。
6. 金融风险评估:决策树可以用于评估贷款申请人的信用风险等。 综上所述,决策树在数据分析、人工智能和机器学习等领域有广泛的应用。
欢迎大家关注与支持。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)