Retrieval-Augmented Generation for Large Language Models: A Survey
在大型语言模型时代,RAG的具体定义是指在回答问题或生成文本时,首先从大量文档中检索相关信息的模型。随后,它利用这些检索到的信息来生成响应或文本,从而提高预测的质量。RAG方法允许开发人员避免为每个特定任务重新训练整个大型模型。
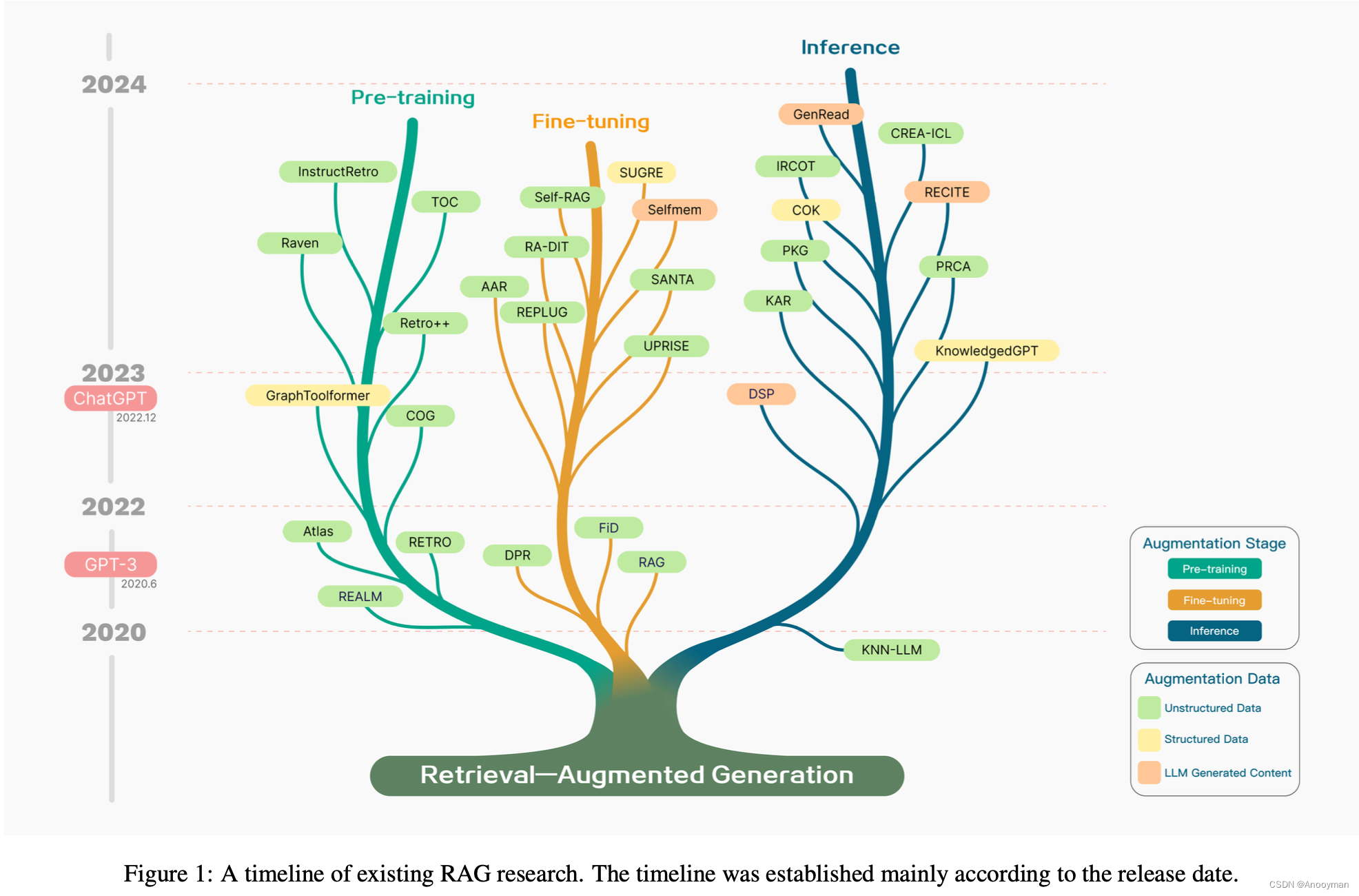
PS: 梳理该 Survey 的整体框架,后续补充相关参考文献的解析整理。本文的会从两个角度来分析总结,因此对于同一种技术可能在不同章节下都会有提及。第一个角度是从整体框架的迭代来看(对应RAG框架章节),第二个是从RAG中不同组成部分来看(对应 Retriever,Generator 和 Augmentation in RAG)。
https://arxiv.org/abs/2312.10997
Introduction
传统上,神经网络通过微调模型来参数化知识,从而适应特定领域或专有信息。虽然这项技术产生了显著的结果,但它需要大量的计算资源,成本高昂,并且需要专门的技术专业知识,使其不太适应不断变化的信息环境。参数化知识和非参数化知识发挥着不同的作用。
- 参数知识:是通过训练LLM获得的,并存储在神经网络权重中,代表模型对训练数据的理解和概括,形成生成响应的基础。
- 非参数知识:存在于矢量数据库等外部知识源中,不直接编码到模型中,而是作为可更新的补充信息处理。
纯参数化语言模型(LLM)将从大量语料库中获取的世界知识存储在模型的参数中。其局限性如下:
- 首先很难保留训练语料库中的所有知识,尤其是不太常见和更具体的知识。
- 由于模型参数不能动态更新,参数知识很容易随着时间的推移而过时。
- 参数的扩展导致训练和推理的计算费用增加。
为了解决纯参数化模型的局限性,语言模型可以采用半参数化方法,将非参数化语料库数据库与参数化模型相集成。
检索增强生成(RAG, Retrieval-Augmented Generation) 最早由Lewis等人于2020引入,将预先训练的检索器与预先训练的seq2seq模型(生成器)相结合,并进行端到端的微调,以更可解释和模块化的方式获取知识。
在大型模型出现之前,RAG主要专注于端到端模型的直接优化。在检索端进行密集检索,例如Karpukhin等人使用基于向量的密集通道检索(DPR, Dense Passage Retrieval) ,以及在生成端训练较小的模型是常见的做法。由于总体参数较小,检索器和生成器通常都会进行同步的端到端训练或微调。
在LLM出现后,生成语言模型成为主流,在各种语言任务中表现出令人印象深刻的性能。然而,LLM仍然面临挑战,如幻觉、知识更新和数据相关问题。这影响了LLM的可靠性,使其在某些严重的任务场景中举步维艰,尤其是在需要获取大量知识的知识密集型任务中,如开放领域问答和常识推理。参数内的隐性知识可能是不完整和不充分的。在随后的研究发现,将RAG引入大型模型的上下文学习(ICL, In-Context Learning)可以缓解上述问题,具有显著且易于实施的效果。

背景知识
RAG 的定义
在大型语言模型时代,RAG的具体定义是指在回答问题或生成文本时,首先从大量文档中检索相关信息的模型。随后,它利用这些检索到的信息来生成响应或文本,从而提高预测的质量。RAG方法允许开发人员避免为每个特定任务重新训练整个大型模型。
总之,RAG系统由两个关键阶段组成:
- 利用编码模型基于问题检索相关文档,如BM25、DPR、ColBERT和类似方法
- 生成阶段:使用检索到的上下文作为条件,系统生成文本
RAG vs Fine-tuning

PS. 在某些情况下,将这两种技术相结合可以实现最佳的模型性能。
现有研究表明,与其他优化大型语言模型的方法相比,检索增强生成(RAG)具有显著的优势:
- RAG通过将答案与外部知识联系起来,减少语言模型中的幻觉问题,并使生成的回答更加准确可靠,从而提高准确性。
- 使用检索技术可以识别最新信息。与仅依赖训练数据的传统语言模型相比,RAG保持了响应的及时性和准确性。
- 透明度是RAG的一个优势。通过引用来源,用户可以验证答案的准确性,增加对模型输出的信任。
- RAG具有定制功能。通过对相关文本语料库进行索引,可以针对不同领域定制模型,为特定领域提供知识支持。
- 在安全和隐私管理方面,RAG凭借其在数据库中内置的角色和安全控制,可以更好地控制数据使用。相比之下,微调后的模型可能缺乏对谁可以访问哪些数据的明确管理。
- RAG的可扩展性更强。它可以处理大规模数据集,而无需更新所有参数和创建训练集,使其更经济高效。
- RAG产生的结果更值得信赖。RAG从最新数据中选择确定性结果,而微调模型在处理动态数据时可能会出现幻觉和不准确,缺乏透明度和可信度。

RAG 框架
Naive RAG
Naive RAG涉及传统的过程:索引、检索和生成,因此也被概括为 “Retrieve”-“Read” 框架。
Indexing
从源获取数据并为其建立 index 的管道通常处于脱机状态。数据索引的构建包括以下步骤:
- 数据索引:清理和提取原始数据,将不同的文件格式(如PDF、HTML、Word、Markdown等)转换为纯文本。
- Chunking: 这包括将加载的文本分成更小的块,因为语言模型通常对其可以处理的上下文数量有限制,因此有必要创建尽可能小的文本块。
- 嵌入和创建索引:这是通过语言模型将文本编码为矢量的过程。得到的向量将用于后续的检索过程,以计算向量和问题向量之间的相似性。嵌入模型需要很高的推理速度。由于需要对大量语料库进行编码,并在用户提问时实时对问题进行编码。
Retrieve
给定用户的输入,使用与第一阶段相同的编码模型将查询转换为向量。计算问题嵌入和文档块在语料库中的嵌入之间的相似性。基于相似性水平,选择前K个文档块作为当前问题的增强上下文信息。
Generation
给定的问题和相关文档将合并到一个新的提示中。大型语言模型的任务是根据所提供的信息回答问题,根据不同任务的需要,可以决定是允许大型模型使用其知识,还是仅基于给定信息进行回答。
Naive RAG的缺点
Naive RAG在三个领域面临主要挑战:
- 检索质量
- 主要问题是精度低,检索集中的所有块都与查询相关,这会导致潜在的幻觉和空中空投问题。
- 低召回率。当没有检索到所有相关块时,会出现这种情况,从而阻止LLM获得足够的上下文来合成答案。
- 过时的信息。即数据冗余或过时的数据可能导致不准确的检索结果。
- 响应生成质量
- 幻觉,模型编造了一个上下文中不存在的答案。
- 不相关,模型生成的答案无法解决查询问题。
- 毒性或偏倚,即模型产生有害或冒犯性反应。
- 扩增过程
- 将检索到的段落中的上下文与当前的生成任务有效地结合起来至关重要。如果处理不当,输出可能会显得不连贯或不连贯。
- 冗余和重复,特别是当多个检索到的段落包含相似的信息,导致生成步骤中的内容重复时。
- 确定多个检索到的段落对生成任务的重要性或相关性是具有挑战性的,并且扩充过程需要适当平衡每个段落的值。检索到的内容也可能来自不同的写作风格或语调,增强过程需要协调这些差异以确保输出的一致性。
- 生成模型可能过度依赖增强信息,导致输出仅重复检索到的内容,而不提供新的价值或合成信息。
Advanced RAG
为了解决Naive RAG遇到的索引问题,Advanced RAG通过滑动窗口、细粒度分割和元数据等方法优化了索引。在检索生成的质量方面,结合了 pre-Retrieval 和 post-Retrieval 的方法。
Pre-Retrieval Process
可以通过优化数据索引提高索引内容的质量
- 增强数据粒度:预索引优化的目标是提高文本的标准化、一致性,并确保事实的准确性,上下文的丰富性和时间敏感性,以保证RAG系统的性能。
- 文本标准化包括去除不相关的信息和特殊字符。
- 就一致性而言,主要任务是消除实体和术语中的歧义,同时消除重复或冗余信息,以简化检索者的工作重点。
- 确保事实的准确性至关重要,只要可能,就应核实每一条数据的准确性。
- 上下文保留,以适应系统在现实世界中的交互上下文,可以通过添加另一层具有特定领域注释的上下文,再加上通过用户反馈循环不断更新来实现。
- 时间敏感性是重要的上下文信息,应设计机制来刷新过时的文档。
- 优化指标结构:这可以通过调整块的大小、更改索引路径和合并图结构信息来实现。
- 调整块(small to big)的方法包括收集尽可能多的相关上下文并将噪声最小化。当构建RAG系统时,chunk size是关键参数。
- 跨多个索引路径查询的方法与以前的元数据过滤和分块方法密切相关,并且可能涉及同时跨不同索引进行查询。
- 引入图结构包括将实体转换为节点,将它们的关系转换为关系。这可以通过利用节点之间的关系来提高准确性,尤其是对于多跳问题。使用图形数据索引可以增加检索的相关性。
- 添加元数据信息:这里的重点是将引用的元数据嵌入到块中。当我们将索引划分为多个块时,检索效率就成了一个问题,首先过滤元数据可以提高效率和相关性。
- 路线优化:此策略主要解决文档之间的一致性问题和差异。对齐概念包括引入假设问题,创建适合每个文档回答的问题,并用文档嵌入(或替换)这些问题。
- 混合检索:这种策略的优势在于利用不同检索技术的优势,包括基于关键字的搜索、语义搜索和矢量搜索。
Embedding
- Fine-tuning Embedding:微调的目的是增强检索内容和查询之间的相关性。通常,微调嵌入的方法分为在特定领域上下文中调整嵌入和优化检索步骤。特别是在处理进化或稀有术语的专业领域,这些定制的嵌入方法可以提高检索相关性。
- Dynamic Embedding:动态嵌入根据单词出现的上下文进行调整,不同于为每个单词使用单个向量的静态嵌入,理想情况下,嵌入应该包含尽可能多的上下文,以确保“healthy”的结果。
Post-Retrieval Process
在从数据库中检索到有价值的上下文后,将其与查询合并以输入LLM会带来挑战。同时向LLM呈现所有相关文档可能会超过上下文窗口限制。将大量文档连接起来形成冗长的检索提示是无效的,这会引入噪声并阻碍LLM对关键信息的关注。为了解决这些问题,有必要对检索到的内容进行额外处理:
- ReRank:重新排序以将最相关的信息重新定位到提示的边缘是一个简单的想法。
- Prompt Compression:重点在于压缩不相关的上下文,突出关键段落,并减少整体上下文长度。
RAG Pipeline Optimization
目前的研究主要集中在智能地结合各种搜索技术,优化检索步骤,引入认知回溯的概念,灵活应用各种查询策略,并利用嵌入相似性。
- 探索混合搜索:通过智能地混合各种技术,如基于关键字的搜索、语义搜索和矢量搜索,RAG系统可以利用每种方法的优势。
- 递归检索和查询引擎:递归检索需要在初始检索阶段获取较小的文档块,以获取关键的语义。在这个过程的后期阶段,具有更多上下文信息的较大块被提供给语言模型(LM)。
- 后退提示:在RAG过程中,逐步后退的快速方法(Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models )鼓励LLM从特定的实例中后退,并对基本的一般概念或原则进行推理。
- Subqueries:可以在不同的场景中使用各种查询策略,包括使用不同框架提供的查询引擎、使用树查询、使用向量查询或使用块的最基本的顺序查询。
- HyDE:这种方法基于这样的假设,即生成的答案在嵌入空间中可能比直接查询更接近。利用LLM,HyDE生成一个假设文档(答案)来响应查询,嵌入文档,并使用这种嵌入来检索与假设文档相似的真实文档。与基于查询寻求嵌入相似性相比,该方法强调从答案到答案的嵌入相似性。然而,它可能不会始终产生有利的结果,特别是在语言模型不熟悉所讨论主题的情况下,这可能会导致更容易出错的实例的生成。
Modular RAG
Modular RAG 结构打破了传统的 Naive RAG 索引、检索和生成框架,在整个过程中提供了更大的多样性和灵活性。Modular RAG范式正在成为 RAG 领域的主流,允许跨多个模块的串行管道或端到端训练方法。
New modules
- Search Module:与Naive/Advanced RAG中查询和语料库之间的相似性检索不同,搜索模块针对特定场景进行定制,在此过程中使用LLM生成的代码、查询语言(如SQL、Cypher)或其他自定义工具对(额外的)语料库进行直接搜索。
- Memory Module:利用LLM本身的记忆能力来指导检索,其原理包括找到与当前输入最相似的记忆。
- Extra Generation Module:在检索的内容中,冗余和噪声是常见的问题。额外生成模块不是直接从数据源检索,而是利用LLM生成所需的上下文。与直接检索相比,LLM生成的内容更有可能包含相关信息。
- Task Adaptable Module:简单来说就是根据不同的 task 构建 task-specific retrievers
- Walking Down the Memory Maze: Beyond Context Limit through Interactive Reading专注于转换RAG以适应各种下游任务,从预先构建的数据池中自动检索给定零样本任务输入的提示,增强了任务和模型的通用性。
- Promptagator: Few-shot Dense Retrieval From 8 Examples利用LLM的泛化能力,仅举几个例子就可以创建特定任务的端到端检索器。
- Alignment Module:查询和文本之间的一致性一直是影响RAG有效性的关键问题,在模块化RAG时代,研究人员发现,在检索器中添加可训练的适配器模块可以有效缓解对齐问题。
- Validation Module:检索不相关的数据可能会导致LLM中出现幻觉。因此,可以在检索文档之后引入额外的验证模块,以评估检索到的文档与查询之间的相关性。
New Pattern
模块化RAG的组织方法是灵活的,允许根据特定的问题上下文替换或重新配置RAG过程中的模块。目前的研究主要探讨两种组织范式,包括模块的添加或替换,以及模块之间组织流动的调整。
- 添加或更换模块:添加或替换模块的策略需要维护检索读取的结构,同时引入额外的模块来增强特定功能。例如,Query Rewriting for Retrieval-Augmented Large Language Models 提出了重写检索-读取过程,利用LLM性能作为重写器模块强化学习的奖励。这允许重写器调整检索查询,从而提高读取器的下游任务性能
- 调整模块之间的流动: 在调整模块之间的流程方面,重点是增强语言模型和检索模型之间的交互。例如,Demonstrate-Search-Predict: Composing retrieval and language models for knowledge-intensive NLP引入了演示搜索预测框架,将上下文学习系统视为一个明确的程序,而不是一个终端任务提示,以解决知识密集型任务。

Retriever
在RAG的中,“R”代表检索,在从庞大的知识库中检索前k个相关文档的RAG管道中发挥作用。如何得到一个好的 retriever 至关重要,因此作者提出了三个方面的问题来探讨
How to acquire accurate semantic representations? 如何获取精准的语义表达?
- Chunk optimization:在选择分块策略时,重要的考虑因素包括:被索引内容的特征、使用的嵌入模型及其最佳块大小、用户查询的预期长度和复杂性,以及检索结果如何在特定应用程序中使用。目前对 RAG 的研究采用了多种块优化方法来提高检索效率和准确性:
- 滑动窗口技术等技术通过多次检索聚合全局相关信息来实现分层检索。
- Small2big技术在搜索过程中使用小的文本块,并将较大的附属文本块提供给语言模型进行处理。
- 摘要嵌入技术对文档摘要执行TopK检索,提供完整的文档上下文。
- 元数据筛选技术利用文档元数据进行筛选。
- 图形索引技术将实体和关系转换为节点和连接,显著增强了多跳问题的相关性。
- Fine-tuning Embedding Models:嵌入模型的任务特定微调对于确保模型理解与内容相关性相关的用户查询至关重要,而未微调的模型可能无法满足特定任务的需求。这通过领域知识注入和下游任务微调在一定程度上改进了语义表示,但是这种微调过的 retriever 对LLM 模型来说没有直接帮助。嵌入微调方法有两个基本范式:
- Domain Knowledge Fine-tuning,领域知识微调:在目前微调嵌入模型的主要方法中,使用的数据集由三部分组成,包括查询、语料库和相关文档。
- Fine-tuning of downstream tasks,下游任务的微调:使嵌入模型适应下游任务同样重要。当在下游任务中使用RAG时,一些工作通过使用LLM的功能对嵌入模型进行了微调。
How to Match the Semantic Space of Queries and Documents? 如何匹配查询和文档的语义空间?
用户的原始查询可能存在表达不佳和缺乏语义信息的问题。因此,对齐用户查询和文档的语义空间是非常必要的。
- Query Rewrite: 调整查询和文档语义的最直观方法是重写查询。例如,Query2doc: Query Expansion with Large Language Models 利用大型语言模型的固有能力,通过引导生成伪文档,然后将原始查询与该伪文档合并,形成新的查询。
- Embedding Transformation:如果有像重写查询这样的粗粒度方法,那么也应该有专门用于嵌入操作的细粒度实现。例如,LlamaIndex 中可以在查询编码器之后连接适配器,并微调适配器以优化查询嵌入的表示,将其映射到更适合特定任务的潜在空间。当查询和外部文档的数据结构不同时,例如非结构化查询和结构化外部文档,使查询与文档对齐是非常重要的。
How to Aligning Retriever’s Output and LLM’s Preference? 如何调整检索器的输出和LLM的偏好?
在RAG pipeline 中,即使我们采用上述技术来提高检索命中率,也可能无法提高RAG的最终效果,因为检索到的文档可能不是LLM所需要的。论文介绍了两种方法来调整检索器的输出和LLM的偏好:
- LLM supervised training: 许多工作利用来自大型语言模型的各种反馈信号来微调嵌入模型。例如,Augmentation-adapted retriever improves generalization of language models as generic plug-in. 通过编码器-编码器架构 LM 为预先训练的检索器提供监督信号。通过FiD交叉注意力得分确定 LM 的首选文档,然后使用硬负采样和标准交叉熵损失对检索器进行微调。最终,微调寻回器可以直接用于增强看不见的目标LM,从而在目标任务中表现更好。
- Plug in an adapter:由于诸如利用API来实现嵌入功能或本地计算资源不足之类的因素,微调嵌入模型可能是具有挑战性的,因此,有些作品选择外部连接适配器进行对齐。例如,RECOMP: Improving Retrieval-Augmented LMs with Compression and Selective Augmentation 提出了抽取式和生成式压缩器,通过选择相关句子或合成文档信息来生成摘要,以实现多文档查询焦点摘要。
Generator
在RAG中,生成器的输入不仅包括传统的上下文信息,还包括通过检索器获得的相关文本片段。这使生成器能够更好地理解问题背后的背景,并产生信息更丰富的回答。此外,生成器以检索到的文本为指导,以确保生成的内容和检索到的信息之间的一致性。正是输入数据的多样性导致了生成阶段的一系列有针对性的工作,所有这些工作都旨在使大型模型更好地适应查询和文档中的输入数据。如何得到一个好的 Generator 也是非常重要的,本文从两个方面分析了这个问题
How Can Retrieval Results be Enhanced via Post-retrieval Processing? 如何通过检索后处理增强检索结果?
检索后处理是指对检索器从大型文档数据库中检索到的相关信息进行进一步处理、过滤或优化的过程。其主要目的是提高检索结果的质量,以更好地满足用户需求或后续任务。
- Information Compression(Prompt Compression): 简言之,信息浓缩的重要性主要体现在以下几个方面:减少噪音、应对上下文长度限制和增强生成效果。例如,Large Language Model Is Not a Good Few-shot Information Extractor, but a Good Reranker for Hard Samples! 提出了“过滤-排序”范式,该范式融合了大型语言模型(LLM)和小型语言模型(SLM)的优势。在这个范例中,SLM充当过滤器,而LLM充当重新排序代理。通过促使LLM重新排列SLM识别的困难样本的部分,研究结果表明,在各种信息提取(IE)任务中都有显著改进。
- ReRank:核心思想包括重新排列文档记录,将最相关的项目放在顶部,从而将文档总数减少到固定数量。Open-source Large Language Models are Strong Zero-shot Query Likelihood Models for Document Ranking.发现这不仅解决了检索过程中可能遇到的上下文窗口扩展问题,而且有助于提高检索效率和响应能力。
How to Optimize a Generator to Adapt Input data? 如何优化生成器以适应输入数据?
优化生成器的目标是确保生成的文本既自然又有效地利用检索到的文档,从而更好地满足用户的查询需求。需要注意的是,RAG中微调生成器的方法基本上类似于LLM的一般微调方法。
- General Optimization Process:指包含成对(输入,输出)的训练数据,旨在训练模型在给定输入x的情况下生成输出y的能力。例如,在Lift Yourself Up: Retrieval-augmented Text Generation with Self Memory的工作中,采用了相对经典的训练过程。给定输入x,检索相关文档z(在论文中选择Top-1),在对(x,z)进行积分后,模型生成输出y。该工作利用了两种常见的微调范式,即 Joint-Encoder和Dual-Encoder。
- Utillizing Contrastive Learning:在准备训练数据的阶段,通常生成输入和输出之间的成对交互。在这种情况下,模型只能访问唯一的真实输出,这可能会引发“暴露偏差”问题:在训练阶段,模型只暴露于单个真实反馈,而不访问任何其他生成的令牌。这可能会损害模型在应用中的性能,因为它可能过于适合训练数据中的特定反馈,而不会有效地推广到其他场景。Structure-Aware Language Model Pretraining Improves Dense Retrieval on Structured Data 的工作在处理涉及结构化数据的检索任务时,利用三阶段训练过程来充分理解结构和语义信息。具体来说,在检索器的训练阶段,采用了对比学习,主要目标是优化查询和文档的嵌入表示。
Augmentation in RAG
RAG in Augmentation Stages
作为一项知识密集型任务,RAG在语言模型训练的预训练、微调和推理阶段采用了不同的技术方法。
- Pre-training Stage:自从预训练模型出现以来,研究人员一直致力于通过预训练阶段的检索方法来提高预训练语言模型在开放领域问答(QA)中的性能。在预先训练的模型中识别和扩展隐含知识可能具有挑战性。例如,Neuro-Symbolic Language Modeling with Automaton-augmented Retrieval 引入了一种更模块化和可解释的知识嵌入方法。遵循掩蔽语言模型(MLM)范式,REALM将预训练和微调建模为一个先检索后预测的过程,其中语言模型通过基于掩蔽句子x预测掩蔽标记y来进行预训练。
- 趋势:随着标度定律的发现,模型参数迅速增加,使自回归模型成为主流。
- 总结:
- 从积极的方面来看,这种方法提供了一个更强大的基础模型,在困惑、文本生成质量和下游任务性能方面优于标准GPT模型。
- 纯预训练的模型相比,它通过使用更少的参数来实现更高的效率
- 也存在一些缺点,包括需要大量的预训练数据和更大的训练资源,以及更新速度较慢的问题。
- Fine-tuning Stage:在下游微调阶段,研究人员采用了各种方法来微调检索器和生成器,以改进信息检索,主要是在开放领域的问答任务中。
- 总结:
- 微调LLM和检索器可以更好地适应特定任务,提供同时微调一个或两个的灵活性。
- 这种微调的好处扩展到适应不同的下游任务,使模型更加通用。
- 微调使模型能够更好地适应各种语料库中的不同数据结构,特别有利于图结构语料库。
- 这一阶段的微调也有局限性,例如需要专门为RAG微调准备的数据集,以及与推理阶段的RAG相比需要大量的计算资源。
- 总结:
- Inference Stage:推理阶段增强方法具有重量轻、成本效益高、不需要额外训练以及利用强大的预训练模型的优点。
- 主要优势在于在微调过程中冻结LLM的参数,专注于提供更适合需求的上下文,具有快速和低成本的特点。
- 这种方法也有一些局限性,包括需要额外的数据处理和流程优化,同时受到基础模型能力的限制。
- 这种方法通常与过程优化技术相结合,如逐步推理、迭代推理和自适应检索,以更好地满足不同任务的要求。
Augmentation Data Source
- Augmented with Unstrctured Data:就文本粒度而言,除了常见的组块(包括句子)之外,检索单元可以是标记、短语和文档段落。
- 在单词级别,FLARE采用主动检索策略,仅当LM生成低概率单词时才进行检索。
- 在组块级别,RETRO使用前一个组块来检索最近的相邻组块,并将该信息与前一组块的上下文信息集成,以指导下一组块生成。
- Augmented with Structured Data:像知识图(KG)这样的结构化数据源逐渐被整合到RAG的范式中。经过验证的KGs可以提供更高质量的上下文,降低模型幻觉的可能性。
- LLM Generated Content RAG:这种方法利用LLM本身生成的内容进行检索,旨在提高下游任务的性能。
Augmentation Process
目前优化检索过程的方法主要包括迭代检索和自适应检索。这些允许模型在检索过程中多次迭代,或者自适应地调整检索过程,以更好地适应不同的任务和场景。
- Iterative Retrieval:在多次迭代检索中提供额外的参考提高了后续答案生成的稳健性。然而,这种方法可能在语义上是不连续的,并可能导致收集有噪声和无用的信息,因为它主要依赖于n个令牌的序列来分离生成和检索的文档。递归检索可以首先通过结构化索引处理数据,然后逐级检索。当检索层次丰富的文档时,可以为整个文档或长PDF中的每个部分进行摘要。然后基于该摘要执行检索。在确定文档后,对内部块进行第二次检索,从而实现递归检索。
- Adaptive Retrieval:事实上,前两节中描述的RAG方法遵循被动方法,其中检索是优先的。这种方法涉及查询相关文档并根据上下文输入LLM,可能会导致效率问题。引入自适应检索方法优化了RAG检索过程,使LLM能够主动判断检索的时间和内容。

RAG Evaluation
Evaluation Methods
- Independent Evaluation:
- Retrieval Module:一套衡量系统(如搜索引擎、推荐系统或信息检索系统)根据查询或任务对项目进行排名的有效性的指标通常用于评估RAG检索模块的性能。示例包括命中率、MRR、NDCG、精度等。
- Generation Module:这里的生成模块是指通过将检索到的文档补充到查询中而形成的增强或合成输入,与通常端到端评估的最终答案/响应生成不同。生成模块的评估指标主要集中在上下文相关性上,测量检索到的文档与查询问题的相关性。
- End-to-End Evaluation:端到端评估评估RAG模型对给定输入生成的最终响应,包括模型生成的答案与输入查询的相关性和一致性。从内容生成目标的角度来看,评价可以分为未标记内容和标记内容。未标记内容评估指标包括答案保真度、答案相关性、无害性等,而标记内容评估标准包括准确性和EM。
Key Metrics and Abilities
- Key Metrics:
- Faithfulness:该指标强调,模型生成的答案必须与给定的上下文保持一致,确保答案与上下文信息一致,不会偏离或矛盾。评估的这一方面对于解决大型模型中的幻觉至关重要。
- Answer Relevance:这个指标强调生成的答案需要与提出的问题直接相关。
- Context Relevance:该度量要求检索到的上下文信息尽可能准确和有针对性,避免不相关的内容。该度量反映了RAG检索模块的搜索优化水平。低召回率表明潜在地需要优化搜索功能,例如引入重新排序机制或微调嵌入,以确保更相关的内容检索。
- Key abilities:
- Noise Robustness:该度量反映了RAG检索模块的搜索优化水平。低召回率表明潜在地需要优化搜索功能,例如引入重新排序机制或微调嵌入,以确保更相关的内容检索。
- Negative Rejection:当模型检索到的文档缺乏回答问题所需的知识时,模型应该正确地拒绝响应。在阴性拒绝的测试设置中,外部文件仅包含噪音。理想情况下,LLM应发出“信息不足”或类似的拒绝信号。
- Information Integration:这种能力评估模型是否可以集成来自多个文档的信息来回答更复杂的问题。
- Counterfactual Robustness:该测试旨在评估当收到关于检索信息中潜在风险的指令时,模型是否能够识别和处理文档中的已知错误信息。反事实稳健性测试包括LLM可以直接回答的问题,但相关的外部文件包含事实错误。
Evaluation Frameworks
最近,LLM社区一直在探索使用“LLM作为判断”进行自动评估,许多LLM使用强大的LLM(如GPT-4)来评估自己的LLM应用程序输出。在RAG评估框架领域,RAGAS和ARES是相对较新的。这些评估的核心重点是三个主要指标:答案的真实性、答案相关性和上下文相关性
- RAGAS:
- Assessing Answer Faithfulness:使用LLM将答案分解为各个语句,并验证每个语句是否与上下文一致。最终,通过将支持的陈述数量与陈述总数进行比较来计算“可信度分数”。
- Assessing Answer Relevance: 使用LLM生成潜在问题,并计算这些问题与原始问题之间的相似性。答案相关性得分是通过计算所有生成问题与原始问题的平均相似性得出的。
- Assessing Context Relevance:使用LLM生成潜在问题,并计算这些问题与原始问题之间的相似性。答案相关性得分是通过计算所有生成问题与原始问题的平均相似性得出的。
- ARES:RAGAS作为一种基于简单手写提示的较新评估框架,对新的RAG评估设置的适应性有限,这也是ARES工作的意义之一。
- Generating Synthetic Dataset:ARES最初使用语言模型从目标语料库中的文档中生成合成问题和答案,以创建正样本和负样本。
- Preparing LLM Judges:ARES使用合成数据集对轻量级语言模型进行微调,以训练它们评估上下文相关性、答案可信度和答案相关性。
- Ranking RAG Systems Using Confidence Intervals:ARES应用这些判断模型对RAG系统进行评分,并使用PPI方法将其与手动注释的验证集相结合,以生成置信区间,从而可靠地估计RAG系统的性能。
Future Prospects
Vertical Optimization of RAG
- RAG中的长上下文问题
- RAG的鲁棒性
- RAG和Fine-tuning协同工作
- RAG的工程实践
Ecosystem of RAG
- Downstream Tasks and Evaluation:RAG模型不仅提高了下游应用中信息的准确性和相关性,还增加了响应的多样性和深度。同时,改进RAG的评估系统,以评估和优化其在不同下游任务中的应用,对于该模型在特定任务中的效率和效益至关重要。此外,通过RAG增强模型的可解释性,让用户更好地了解模型如何以及为什么做出特定响应,也是一项有意义的任务。
- Technical Stack:
- 在RAG的生态系统中,相关技术堆栈的开发起到了推动作用。例如,随着ChatGPT的普及,LangChain和LLamaIndex迅速广为人知。它们都提供了一套丰富的RAG相关API,逐渐成为大模型时代不可或缺的技术之一。
- 除了AI原生框架,传统软件或云服务提供商也扩大了服务范围。例如,矢量数据库公司Weaviate提供的Verb7专注于个人助理。亚马逊为用户提供了基于RAG思想的智能企业搜索服务工具Kendra。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)