DMABuffer剖析
Dma buffer分析
基本概念
-
在Camra中,往往涉及到图像相关的buffer都是来自于DMA-BUF,比如我们pipeline里面source buffer、internel buffer、Sink Buffer以及各个进程之间传递的image buffer,gralloc buffer等等。ION、DMA-BUF HEPAS正是由dma-buf实现的。
-
dma-buf的出现就是为了解决各个驱动之间buffer共享的问题,它本质上是buffer与file的结合,即dma-buf既是块物理buffer,又是个linux file。buffer是内容,file是媒介,只有通过file这个媒介才能实现同一buffer在不同驱动之间流转。
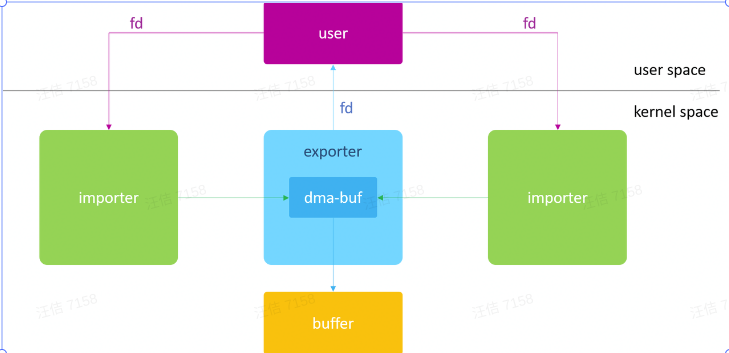
一个典型的dma-buf应用框图如下:

通常,我们将分配buffer的模块称为exporter,,将使用该buffer的模块称为importer或user。
Inode
理解inode,要从文件储存说起。
文件储存在硬盘上,硬盘的最小存储单位叫做"扇区"(Sector)。每个扇区储存512字节(相当于0.5KB)。
操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个"块"(block)。这种由多个扇区组成的"块",是文件存取的最小单位。"块"的大小,最常见的是4KB,即连续八个 sector组成一个 block。
文件数据都储存在"块"中,那么很显然,我们还必须找到一个地方储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做inode,中文译名为"索引节点"。
每一个文件都有对应的inode,里面包含了与该文件有关的一些信息。

下图为linux文件系统,其中inode便来自VFS,文件系统中的每个文件都有唯一的 inode 编号,即对于系统&进程来说,inode是惟一的。

由于dma-buf是基于文件实现的,所以每一个buffer都有唯一一个inode。
一个inode如果没有硬链接,此时inode的链接数为0,文件系统将回收该inode所指向的存储块,并回收该inode自身。
我们平时通过dmabuf_dump看进程ION/DMA_BUF HEAPS内存,它便会打印inode以及buffer size等信息:
(base) ➜ camx git:(54d910d) campid
cameraserver 14578 1 3039888 44096 binder_wait_for_work 0 S cameraserver
u0_a127 18164 14575 7596284 221076 do_epoll_wait 0 S com.android.camera
cameraserver 21480 1 7348236 291984 futex_wait_queue_me 0 S vendor.qti.camera.provider-service_64
(base) ➜ camx git:(54d910d) adb shell dmabuf_dump 21480
vendor.qti.came:21480
Name Rss Pss nr_procs Inode
<unknown> 4 kB 4 kB 1 389660
<unknown> 4 kB 4 kB 1 394391
PROCESS TOTAL 8 kB 8 kB
----------------------
dmabuf total: 8 kB kernel_rss: 0 kB userspace_rss: 8 kB userspace_pss: 8 kBFd
fd(file descriptors),文件描述符是进程用来标识打开文件的无符号整数。open、pipe、creat 和 fcntl 子例程都生成文件描述符。 文件描述符通常对每个进程都是唯一的,但它们可以由使用 fork 子例程创建的子进程共享或由 fcntl、dup 和 dup2 子例程复制。
对于linux进程来说,都有一个task_struct(/common/include/linux/sched.h )表示,其中files_struct便记录着当前进程打开的所有file。
struct task_struct{
#ifdef CONFIG_THREAD_INFO_IN_TASK/*
* For reasons of header soup (see current_thread_info()), this
* must be the first element of task_struct.
*/struct thread_info thread_info;
#endif
unsigned int __state;
#ifdef CONFIG_PREEMPT_RT/* saved state for "spinlock sleepers" */
unsigned int saved_state;
#endif
...
struct mm_struct *mm;
struct mm_struct *active_mm;
...
/* Filesystem information: */
struct fs_struct *fs;
/* Open file information: */
struct files_struct *files;
...
}
struct files_struct {
/*
* read mostly part
*/
atomic_t count;
bool resize_in_progress;
wait_queue_head_t resize_wait;
struct fdtable __rcu *fdt;
struct fdtable fdtab;
/*
* written part on a separate cache line in SMP
*/
spinlock_t file_lock ____cacheline_aligned_in_smp;
unsigned int next_fd;
unsigned long close_on_exec_init[1];
unsigned long open_fds_init[1];
unsigned long full_fds_bits_init[1];
//记录file,数组下标即为fd
struct file __rcu * fd_array[NR_OPEN_DEFAULT];
};
struct fdtable {
unsigned int max_fds;
struct file __rcu **fd; /* current fd array */
unsigned long *close_on_exec;
unsigned long *open_fds;
unsigned long *full_fds_bits;
struct rcu_head rcu;
};每一个fd对应一个file对象,fd_array是一个file数组,我们常说的fd便是fd_array的下标,NR_OPEN_DEFAULT一般为64,对于像provider这种大进程,超过64的file对象,变存储在fdtable里面,内部同样记录了一个file数组。
从这里可以看出,fd是进程级别的概念,每个进程之间的fd并不共享,同时内存申请释放的时候,fd会被复用,会干扰调试。
即可以通过将进程的fd连接到inode上,实现buffer的使用即流转。
Handle
在camera app/provider/service/display等进程申请&释放&流转buffer的过程中,利用了binder通信,常用handle传递信息,handle中的一个“父类”为native_handle_t
typedef struct native_handle
{
int version; /* sizeof(native_handle_t) */
int numFds; /* number of file-descriptors at &data[0] */
int numInts; /* number of ints at &data[numFds] */
#if defined(__clang__)
#pragma clang diagnostic push
#pragma clang diagnostic ignored "-Wzero-length-array"
#endif
//这边data记录的便是fd
int data[0]; /* numFds + numInts ints */
#if defined(__clang__)
#pragma clang diagnostic pop
#endif
} native_handle_t;DMA设计分析
DMA cannot get virtual address through MMU, DMA needs continuous physical address, there are 2 ways:
1. Reserve a continuous physical address for DMA, which is a waste of memory.
2. Mapping through SMMU, so that the IO device can use the dma address after SMMU mapping, so it doesn't matter even if the physical addresses are not continuous

msm-kernel/include/linux/mmzone.h
enum zone_type {
ZONE_DMA,
ZONE_DMA32,
ZONE_NORMAL,
ZONE_HIGHMEM,
ZONE_MOVABLE,
ZONE_DEVICE,
};1.对于一般CPU访问内存,是如上这幅图所示:虚拟地址经过 MMU/TLB ,然后再经过 memory cache 缓存,最后会到达物理地址,进而访问计算机的硬件资源。
2.DMA(Direct memory acess):它是一种, IO设备不通过CPU而直接与内存交换数据的接口技术。DMA不能像CPU一样通过MMU操作虚拟地址, DMA需要连续的物理地址,一般有两种实现方式:
第一种:预留连续的物理地址供DMA使用 .如左下角这张图,会预留一块ZONE_DMA内存出来,这种方式比较浪费内存,如果没有用到DMA,那么这块内存就会被浪费了。
第二种:如左上角第二张图所示,通过SMMU(IOMMU)将buffer里的散列物理地址和dma addr映射, IO设备使用dma addr, 实现DMA功能。有了SMMU之后,就并不需要物理地址是连续的。
在相机中,是怎么使用dma_buf的?

如这张图所示,这是一条简单的 pipeline 图。
Sensor 出一帧,送给高通的 IFE,然后在送给IPE,IPE会分为三路:
第一路:TARGET_BUFFER 有可能被CPU访问,或者可能被GPU访问。如果这个buffer 是要放回给应用层做显示用的,那么这个buffer 可能会被display 访问。
第二路:送给ASD node 这路,取决于ASD算法是CPU实现的,还是GPU实现的。
第三路:如果FDManager 是高通硬件做的,那么可能会被高通的 cvp 访问,如果是软件算法,那么会被cpu访问。所以,IPE输出的一个 buffer 可能被 CPU,GPU,display,cvp 所共享。
DMA-BUF主要解决CPU和各种外设之间的buffer共享。其次, DMA-BUF 设计之初就是为满足那些大内存访问需求的硬件而设计的,如GPU/DPU/NPU。在这种场景下,如果使用CPU直接去访memory,那么性能会大大降低。
DMA是怎么样实现共享buffer?
1.为了解决CPU和各种外设之间的buffer共享,dma_buf 提供了一种思路:在内核中将一个Buffer和一个File关联起来,一个Buffer对应唯一一个 inode。将这个file的fd返回给应用层,用户层通过这个fd能够唯一找到这个FIle,找到这个File,就可以唯一找到这个Buffer。
2.同时通过binder实现进程之间的fd共享,比如上图中的client0 传递给fd 给 client1。Client1 拥有和 Client0 同样唯一的 File 和 Buffer ,这样就实现了 Buffer 在不同的进程间的共享。
3.dma-buf.c 这个文件实现了 怎么讲将一个 Buffer 和一个 File 相关联起来。dma-heap.c 申请释放 Buffer 在这个文件中,经常在这个文件中做一些hook的操作。
4./common/drivers/dma-buf/heaps/ heaps就是各种 heaps 的实现,kernel mainline 就有2个,cma_heap 和 system_heap ,高通实现了自己的 heap。

DMA_BUF底层原理:为了实现buffer的共享,在内核中将DMA-BUF将buffer与file关联起来,一个Buffer对应唯一一个File,一个File对应唯一一个 inode,将这个file的fd返回给应用层,通过binder实现进程之间的fd传递(dup),进而拿到唯一的File 和 Buffer。
DMA Buffer在相机中的运用
HAL层 Image buffer

- 从这一张图开始引入,这是一张我们camera provider中,简单的pipeline图,pipeline 是有node 链接起来的,node之间是有对应的port连接起来的,这个imagebuffermanager就是管理对应port的buffer的。
- 我们可以看到,Node之间链接的port 就是 imagebuffer 。Node内部可能会用到一些 heap/dma_buf/gpu 内存。
Qcom imagebuffer buffer 的分配

- 一旦request被提交,CHI会拿到一个虚拟的imagebuffer handle被分配并绑定到outport,一般情况imagebuffer直到真正要被使用的时候才会被分配真正的内存空间。
- ChiBuffer也有manager,从代码上看是camx buffer Manager的封装,最终调用的还是camx的manager;
- 高通为camx 和chi 都设计了一套buffer 管理机制,但是有标志位来使能让chi 也走camx 的buffer 管理,这样有一个好处方便统一管理
1.这个是高通对BufferManager管理的框架原理图,在chi那边有一套BufferManager的管理机制,在底层camx也有一套BufferManager的管理机制,chi 那边的BufferManager一般走的是camx的BufferManager的管理机制。这样有一个好处方便统一管理,有标志位来使能让chi 也走camx 的buffer 管理。
2.在我们 create node 的时候,就会去 创建imagebuffermanager,然后他会到MemPoolManager中去要Buffer,最终会有两种分配Buffer的接口,一种是CSL ,一种是 Gralloc的。CSL接口这种大多是由camera driver到内核中去申请dma_buf的,gralloc 接口这种是要经过HIDL接口去跨进程到 display.allocator 这个进程的,最终通过这个 display.allocator 进程到内核中去申请dma_buf的。
3.无论是CSL 接口,还是 gralloc接口,最终申请的都是 dma_buf内存的。
4.然后怎么选择这两种Buffer,是在pipeline XML 中配置的,如果配置的是 EGL,那么走的gralloc 接口,如果配置的ION 那么走的 CSL接口。
EGL/ION
- pipeline XML 中配置EGL=>走gralloc;配置ION=>走CSL

Gralloc:HAL层以上的gralloc image buffer都是由 vendor.qti.hardware.display.allocator-service 这个进程来分配的

在 HAL层以上,有一个 vendor.qti.hardware.display.allocator-service这个进程,用来分配 gralloc imagebuffer。
Gralloc Buffer一般是在camera app、camera service、camera provider进程中进行轮转的。
ImageBuffer架构模型

- ImageBufferManager在初始化(注册)/析构(取消注册)获取MemPoolBufferManager操作句柄。
- MemPoolMgr是单例模式,在provider初始化中已经创建好。管理拍照MemPoolGroupLists和预览MemPoolGroupLists.
- MemPoolMgr and ImagebufferManger have interface to manager these buffers.
- ImageBufferManager是对MemPoolMgr、MemPoolGroup的封装.
- MemPoolBuffer will be converted to ImageBuffer via bufferInfo.
这张图代表的是BufferManager的一个整体架构模型,里面有几个关键点,我分别来讲解一下。
1.ImageBufferManager 是管理 imagebuffer的,ImageBufferManager中有2条链表 m_freeBufferList和m_busyBufferList,其中:m_freeBufferList中存放着空闲的Buffer,m_busyBufferList中存放着正在被client 使用的Buffer。
2.ImageBufferManager在初始化(注册)/析构(取消注册)获取MemPoolBufferManager操作句柄,进而与MemPoolManager进行通信。
3.MemPoolManager 是管理 MemPoolGroup的,MemPoolManager中有2条链表 m_groupList 和 m_groupPreviewList,其中,m_groupList中存放的是拍照group,m_groupPreviewList中存放是预览group。
4.MemPoolGroup是管理MemPoolBuffer的,MemPoolGroup 中也有2条链表 m_freeBufferList 和 memPoolBufferList,去管理 memPoolBuffer的,其中 m_freeBufferList 管理的是空闲的memPoolBuffer,memPoolBufferList管理的是正在被client使用的memPoolBuffer。
5.最终会进行一个 Import 操作,把MemPoolBuffer的bufferInfo,传递给 imagebuffer的bufferInfo。因为我们知道 ImageBuffer 在 pipeline node 之间是通过port共享的,他是通过传递这个bufferInfo,把一个node 的outputport 传递给 inputport的。
在userspace层,这个bufferInfo就代表着一个CSL 申请的buffer,或者 gralloc 申请的buffer。这个bufferInfo里面包含buffer 的 fd,buffer的设备地址:CSLDeviceAddress deviceAddr,buffer的虚拟地址:VOID* pVirtualAddr,还有buffer的 offset,size 等等
Imagebuffer内存池模型

- 这几个接口已经能够满足一个基本的内存池所需的。高通丰富了一下使用接口
- 在相机刚起来的时候,或者在RegisterBufferManafer的时候,不想去申请内存,因为申请内存需要消耗资源,想要在pipeline streamon的时候才开始使用内存,所以等到后面activate的时候才去申请内存。
- bind接口,为了节省内存。刚刚开始的时候并不想申请内存,而是等到要用buffer的时候,才去申请内存。只是拿到imagebuffer,但并没有拿到mempoolBuffer,bind的时候将 mempoolBuffer拷贝到imagebuffer中。
- 还有一个MPM线程,周期性的回收多余空闲的buffer,为了节省内存考虑的。
- 为什么要设计一个这样的内存池?第一:为了性能考虑,避免每次通过系统调用,陷入内核态,这样申请内存需要大量的时间。第二:为了节省内存,直接从freeList上去拿Buffer。很多设计都是这样的,比如:系统对堆空间的管理:空闲链表法,原理类似。
- memPoolGroup和imageBufferManager的关系是:一对多的关系。每一个imagebuffermanager是管理inputport 和 outputport,可能有多组port,这些port size 可能大小相近,那么就可以共享一个 memPoolGroup,size 可以允许上下相差 4M。memPollGroup 是针对一组size大小相近的 port,imagebuffermananger是针对port之间。
1.这个是从高通框架中抽象出来一个简易的 imagebuffermanager 管理框架,右边虚线框出来的是一个内存池。主要有以下这几个接口。
-
create: 就是向kernel申请内存,放到内存池当中
-
Destroy:既然有create,那肯定有destroy,不然就内存泄露了。就是要释放内存,把内存归还给内核。
-
GetImageBuffer:从内存池中去拿Buffer
-
ReleaseReference:将Buffer归还给内存池
其实,只需要这4个接口,就能够满足一个基础的框架。
2.高通在这个基础框架上丰富了一下,加了几个其他的接口:ActivateImageBuffers,DeactivateBufferManager,BindInputOutputBuffers,MPM线程。
3.高通为什么要加上 ActivateImageBuffers,DeactivateBufferManager 是因为:在相机刚起来的时候,或者在RegisterBufferManafer的时候,不想去申请内存,因为申请内存需要消耗资源,想要在pipeline streamon的时候才开始使用内存,所以等到后面activate的时候才去申请内存。
4.高通为什么要加上bind接口(延迟绑定):为了节省内存,刚刚开始的时候并不想申请内存,而是等到要用buffer的时候,才去申请内存。
5.还有一个 MPM线程:周期性的回收多余空闲的buffer,为了节省内存考虑的。
6.为什么要设计一个这样的内存池?第一:为了性能考虑,避免每次通过系统调用,陷入内核态,这样申请内存需要大量的时间。第二:为了节省内存,频繁的进行申请释放操作,会造成的大量的内存碎片,这样其实是很浪费内存的。如果我们有了一个这样的内存池,其实是可以直接从freeList上去拿Buffer,这样就避免了内存碎片,以达到节省内存的目的。其实在很多硬件或者软件中设计都是这样的,为了性能或者内存考虑,在中间加了一层缓存,比如:系统对堆空间的管理:空闲链表法,原理类似。
///
memPoolGroup和imageBufferManager的关系是:一对多的关系。每一个imagebuffermanager是管理inputport 和 outputport,可能有多组port,这些port size 可能大小相近,那么就可以共享一个 memPoolGroup,size 可以允许上下相差 4M。memPollGroup 是针对一组size大小相近的 port,imagebuffermananger是针对port之间。
///
ImageBuffer复用

-
在caxsetting.xml会进行设置,会把 size 大小相近的Buffer会放在一个Group里面,然后默认值是15M,允许有4M的差距。比如你要27M的buffer,可能拿到的并不是27M的buffer,而是27M上下左右相差的Buffer。
-
如右图所示:MemPoolGroup中存着大小相近的 MemPoolBuffer。
代码流程分析
接下来,我会讲解一下关键流程。每个流程我会用简单的言语总结一下,它做的核心的事情。有些流程比较复杂,不会一点一点去讲解,而是去总结一下它做的核心事情。如果大家想了解每个流程的细节,可以根据我画出来的时序图,去看对应的开源代码。
Create
Create .Allocate buffer .Insert buffer to freeBufferList

首先,讲解一下create流程,从node开始,会进行imagebuffermanager的创建并初始化。第一个主要流程:然后会到MemPoolManager中去注册BufferManager,注册过程另外附上流程图说明,然后到MemPoolGroup中去进行注册BufferManager,然后会根据Buffer的类型不同,去申请不同的Buffer,然后会将MemPoolBuffer挂载到MemPoolGroup中的freeList上。第二个主要流程:就是会对imagebuffer创建并进行初始化,并加入到 imagebuffermanager的freeList上。
Allocate
Allocate 从内存池中拿buffer,如果拿不到就调用cslAlloc/gralloc向系统申请buffer

1.我们知道第一次肯定是向系统申请内存,并放Buffer到内存池中去,经过前面的 create 流程,Buffer 已经存放在内存池中。
2.首先会从内存池中去拿Buffer,如果内存池中没有buffer,就会用cslAlloc/gralloc向系统申请buffer。
CSLAlloc

CSLAlloc 接口往下申请buffer的流程,我这里讲解一下。
1.首先会将buffer长度,对其方式,flags设置好,然后会调用ioctl 申请内存,经过SMMU 映射。ioctl 成功后,就会从内核返回buf_handle,fd,len等。
2.然后,就会调用用户层的mmap,将内核中内存指针映射到应用层,此时就会得到应用层的虚拟地址。
3.最后,会做一个深拷贝,将分配好的buffer,保存在pBufferInfo中。上层的ImageBufferManager,ImageBuffer,MemPoolMgr,MemPoolGroup,MemPoolBuffer,都是围绕着这个bufferinfo展开的。
Gralloc 申请
-
之前我们讲过有2种方式申请buffer,一种是CSLAlloc,另外一种就是gralloc,现在我们来看一下gralloc申请过程。
-
从我们camera这边,会通过HIDL接口调到 vendor.qti.hardware.display.allocator-service进程,然后在构造函数QtiAllocator() 中对BufferManager进行实例化,然后去申请Buffer的时候,会根据一个property进行选择,到底是会走 DMA_BUF_HEAPS,还是 ION,最后也是会调用 ioctl 去申请 dma_buf。
Gralloc申请
Gralloc 申请,Allocate buffer .Insert buffer to freeBufferList

gralloc/gr_alloc_interface.cpp

确定是走DMA_BUF_HEAPS 还是 ION
Destroy
Destroy,Free buffer

1.既然有申请buffer的流程,就肯定有释放的流程。当退出相机或者imagebuffer处理完的时候,就会destroy buffer。
2.这个里面首先就会对buffer release ,然后就会取消注册bufferManager,然后会做一个DeactiveBufferManager 这些另外附上流程图说明,然后会看一下,是否有buffer需要释放,如果有则释放一下Buffer,这个是 MPM线程做的事情,后面会讲到。最后会调用释放接口,释放内存。
Gralloc 释放 1.这个gralloc释放流程,其实和申请流程差不多,这里就不多讲解。我这里强调一点,就是会走DMA_BUF_HEAPS去释放,而不是ION去释放。
Gralloc释放
Gralloc 释放,Free buffer

GetImageBuffer
GetImageBuffer Get buffer from freeBufferList.Insert to busyBufferList.

4次去拿buffer
这个 m_maxBufferCount 代表可以申请最大Buffer的个数,是在我们 pipeline xml 中进行配置的。
ReleaseReference
Get buffer from busyBufferList. Insert to freeBufferList.

如果发现这个 imagebuffer 已经处理完图像了,并且没有任何 client 正在使用它。那么这个时候就会进行 ReleaseReference。
AddReference

RegisterBufferManager
RegisterBufferManager .Get MemPoolBufferMgrHandle included MemPoolGroup and MemPoolBufMgr

- 注册BufferManager,主要就是拿到一个MemPoolBufferMgrHandle 句柄,让MemPoolBufferManager 和 Imagebuffermanager进行交互。
- 首先,注册只支持2种 Heap,一共有4种Heap,其他两种不支持。
- 然后会到MemPoolGroup中进行实际的注册,这里会判断现有的 MemPoolGroup是否匹配,如果匹配直接到现有的MemPoolGroup中去进行注册,并保存在g_groupList中。如果不匹配,会重新创建一个MemPoolGroup并对其进行初始化,然后在这个新的MemPoolGroup中进行注册,注册成功,并保存在g_groupList中。
- 通知MPM线程,可以进行对MemPoolGroup 以及 buffer 进行回收 。
- 创建ImageBufferManager时注册ImageBuffer管理器到MemPoolGroup,没有CSL buffer和Gralloc buffer区分。注册管理后,全局memPoolMgr会对注册管理的MemPoolGroup进行统一的回收管理。
UnregisterBufferManager
UnregisterBufferManager, free MemPoolBufferMgrHandleData

- 既然有RegisterBufferManager,就肯定有UnregisterBufferManager。首先判断MemPoolGroup是否存在groupList中,如果不存在就不能进行取消注册。
- 然后进行 deactiveBufferManager,然后会进行一定的更新的操作。然后看一下可以释放多少个Buffer,这里和注册BufferManager类似。
- 通知MPM线程不能进行buffer回收。
ActivateImageBuffers
ActivateImageBuffers ,Allocate buffer.

1.Activate的功能其实和 create 的功能是差不多的,就是要分配buffer,这里就不多讲解了。
DeactivateBufferManager
DeactivateBufferManager,Free

1.deactive 的功能其实和 destroy的功能是差不多的,就是要回收buffer,这里就不多讲解了。
BindInputOutputBuffers

1.现在我们来看一下延迟绑定Buffer。我们知道分配Buffer主要有2种方式。
2.第一种:立即分配Buffer,像一下ipe,ife有些buffer是需要常驻的,那么这些buffer是必须要立即分配出来的。
3.第二种:延迟绑定Buffer,当真正需要使用的时候,才真正去分配buffer。

MonitorThread
① Automatic recycling:当一个buffer被停止使用后,buffer被buffer pool持有。若此时有新的buffer manager申请buffer,则此buffer被再次使用;若一段时间内没被再次使用,则MPM线程将其回收,buffer pool将此buffer释放掉。
②initiative recycling:注销buffer manager,此buffer manager相关的buffer 在 buffer pool中立刻被释放。
camx/src/settings/common/camxstting.xml

在provider 进程启动的时候,这个MPM线程就已经开始监测了。然后,在我们provider 进程退出的时候,这个 MPM线程就退出监测了。
MonitorThread:未使用的Buffer在一定时间内会被回收

MonitorThread ,Free buffer of freeBufferList

FreeBuffers
FreeBuffers,Get Buffer from memPoolBufferList of MemPoolBufferManager , Insert to freeBufferList

- 释放Buffers的逻辑和申请也是一样的,首先会将Buffer归还到内存池中,其次,如果没有归还到内存池中,就会释放内存给系统。具体的释放到内存池的过程,以及归还给系统的过程前面已经讲解过,这里就不多讲解了。
思考
为什么要map buffer to devices?call CSLAlloc 同时也做了 map,为什么还要下一步还要 CheckAndMapBufferToDevices ?
一般都是在 DRQ(DeferredRequestQueue) call node::processRequest --> BindInputOutputBuffers 时被调用。
node 使用完 buffer 后,会放回 m_freeBufferList ,此时虽然 buffer 已经被某些devices map,但是可能下一次是其他 Device 使用,需要检查此 buffer 是否被 map 到了此 device,如果没有,则需要 map。
小结


DMA Buffer内存拆解与内存泄露分析
DMA Buffer内存拆解
拆解工具
memory_dump-qcom-loop-v3_8.sh
dmabuf_dump system/memory/libmeminfo/libdmabufinfo/tools/
Systrace
高通平台dma_buf: Memprofile QCTT
memory_dump
统计方法-dma内存 :
8350:adb shell cat /sys/kernel/debug/dma_buf/bufinfo 8450"|"8475"|"8550"
adb shell dmabuf_dump $pid_cameraprovider

memprofile


Perfetto
quickstart https://perfetto.dev/docs/

Perfetto拆解imagebuffer 结果示例

gralloc buffer trace

video_8K_24fps,hal层 imagebuffer拆解结果






DMA Buffer内存泄露
//未完待续...,后续将DMA Buffer泄露补上。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 23
23 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)