论文精读 && Co-DETR(Co-DINO、Co-Deformable-DETR)
1. Co-DETR基于DAB-DETR、Deformable-DETR和DINO网络进行了实验。2. Co-DETR发现DETR及其变体网络是一对一标签分配,指出了其中的问题,随之提出一对多标签分配监督多个并行辅助头的方法。3. 为了提高解码器中正样本(positive samples)的训练效率,Co-DETR从辅助头中提取正坐标(positive coordinates)来进行额外定制的正查
DETRs with Collaborative Hybrid Assignments Training
基于协作混合分配训练的DETRs
论文链接:2211.12860.pdf (arxiv.org)
源码链接:https://github.com/Sense-X/Co-DETR
总结:
- Co-DETR基于DAB-DETR、Deformable-DETR和DINO网络进行了实验。
- Co-DETR发现DETR及其变体网络是一对一标签分配,指出了其中的问题,随之提出一对多标签分配监督多个并行辅助头的方法。
- 为了提高解码器中正样本(positive samples)的训练效率,Co-DETR从辅助头中提取正坐标(positive coordinates)来进行额外定制的正查询(positive queries)。
- 辅助头只在训练过程中使用,推断过程中被丢弃,只使用源网络进行推断。
总而言之,Co-DETR通过添加辅助头来提高网络的训练精度,仅仅是一种新型的训练方案,并未提出新的网络。但是,这种方案值得我们借鉴,提升精度不一定要更改网络结构,也可以换一种思路,比如这一篇商汤科技的论文——Co-DETR。
目录
5.4.3 通过降低匈牙利语匹配的稳定性来提高交叉注意力学习
1. 摘要
在本文中,我们观察到,在具有一对一集匹配的DETR中,被分配为正样本的查询太少,导致对编码器输出的稀疏监督,这大大损害了编码器的判别特征学习,反之亦然。为了缓解这种情况,我们提出了一种新颖的协作混合分配训练方案,名为Co-DETR,以从通用的标签分配方式中学习更高效、更有效的基于DETR的检测器。这种新的训练方案可以通过训练由一对多标签分配(如ATSS和Faster RCNN)监督的多个并行辅助头,轻松增强编码器在端到端检测器中的学习能力。此外,我们通过从这些辅助头中提取正坐标来进行额外定制的正查询,以提高解码器中正样本的训练效率。在推断中,这些辅助头被丢弃,因此我们的方法在不需要手工制作的非最大值抑制(NMS)的同时,没有给原始检测器引入额外的参数和计算成本。我们进行了广泛的实验来评估所提出的方法对DETR变体的有效性,包括DAB-DETR、Deformable-DETR和DINO-Deformable-DETR。最先进的带Swin-L的 DINO-Deformable-DETR 在 COCO val 上的AP可从58.5%提高到59.5%。令人惊讶的是,与ViT-L主干相结合,在 COCO test-dev 中实现了66.0%的AP,在LVIS val中实现了67.9%的AP,以更少的模型尺寸优于以前的方法。

图1.使用ResNet-50的模型在COCO val.Co-DETR上的性能大大优于其他模型。
2. 结论
在本文中,我们提出了一种新的协作混合分配训练方案,即Co-DETR,以从通用的标签指派方式中学习更高效、更有效的基于DETR的检测器。这种新的训练方案可以通过训练由一对多标签分配监督的多个并行辅助头来容易地增强编码器在端到端检测器中的学习能力。此外,我们通过从这些辅助头中提取正坐标来进行额外定制的正查询,以提高解码器中正样本的训练效率。在COCO数据集上进行的大量实验证明了Co-DETR的效率和有效性。令人惊讶的是,与ViT-L主干相结合,我们在COCO测试开发中实现了66.0%的AP,在LVIS val中实现了67.9%的AP,建立了新的最先进的检测器,其型号尺寸要小得多。
3. 介绍
目标检测是计算机视觉中的一项基本任务,它要求我们对目标进行定位和分类。开创性的R-CNN家族[11,14,27]和一系列变体[31,37,44],如ATSS[41]、RetinaNet[21]、FCOS[32]和PAA[17],导致了物体检测任务的重大突破。一对多标签分配是它们的核心方案,其中每个 groundtruth box 被分配到检测器输出中的多个坐标,作为与提议[11,27]、锚[21]或窗口中心[32]合作的监督目标。尽管这些探测器的性能很有希望,但它们在很大程度上依赖于许多手工设计的组件,如非最大值抑制程序或锚生成[1]。为了提供更灵活的端到端检测器,DEtection TRansformer(DETR)[1]将对象检测视为集合预测问题,并引入了基于TRansformer编码器-解码器架构的一对一集合匹配方案。通过这种方式,每个基本事实框将只分配给一个特定的查询,并且不再需要对先验知识进行编码的多个手工设计的组件。这种方法引入了一个灵活的检测管道,并鼓励许多DETR变体进一步改进它。然而,普通的端到端对象检测器的性能仍然不如具有一对多标签分配的传统检测器。

图2.编码器中的特征可分辨性得分和解码器中的注意力可分辨性分数的IoF-IoB曲线。
在本文中,我们试图使基于DETR的检测器优于传统检测器,同时保持其端到端的优点。为了应对这一挑战,我们重点关注一对一集合匹配的直观缺点,即它探索了不太积极的查询。这将导致严重的低效训练问题。我们从编码器产生的潜在表示和解码器中的注意力学习两个方面对此进行了详细的分析。我们首先比较了Deformable-DETR和一对多标签分配方法之间潜在特征的可分辨性得分,在该方法中,我们简单地用ATSS头代替解码器。利用每个空间坐标中的特征 L2 范数来表示可辨别性得分。给定编码器的输出F∈RC×H×W,我们可以得到判别性得分映射s∈R1×H×W。当对应区域中的分数较高时,可以更好地检测对象。如图2所示,我们通过对可分辨性得分应用不同的阈值来演示IoF-IoB曲线(IoF:前景上的交集,IoB:背景上的交集)。ATSS中的IoF-IoB曲线越高,表明更容易区分前景和背景。我们在图3 中进一步可视化了可辨别性得分图。很明显,在一对多标签分配方法中,一些显著区域的特征被完全激活,但在一对一集合匹配中较少被探索。为了探索解码器训练,我们还展示了基于Deformable-DETR和Group-DETR的解码器中交叉注意力得分的IoF-IoB曲线,该曲线将更多的正向查询引入到解码器中。图2 中的插图显示,过少的正向查询也会影响注意力学习,在解码器中增加更多的正向查询可以稍微缓解这种情况。

图3.编码器中可辨别性分数的可视化。
这一重要观察结果促使我们提出一种简单但有效的方法,即协作混合分配训练方案(Co-DETR)。Co-DETR的关键见解是使用多功能的一对多标签分配来提高编码器和解码器的训练效率和有效性。更具体地说,我们将辅助头与Transformer编码器的输出集成在一起。这些头可以通过多功能的一对多标签分配进行监督,如ATSS[41]、FCOS[32]和FasterRCNN[27]。不同的标签分配丰富了对编码器输出的监督,这迫使它具有足够的鉴别力,以支持这些头部的训练收敛。为了进一步提高解码器的训练效率,我们精心编码了这些辅助头部中正样本的坐标,包括正锚和正建议。它们作为多组正查询发送到原始解码器,以预测预先分配的类别和边界框。每个辅助头部中的正坐标作为一个独立的组,与其他组隔离。通用的一对多标签分配可以引入大量的(positive query, ground-truth)对,以提高解码器的训练效率。注意,在推理过程中只使用原始解码器,因此所提出的训练方案只在训练过程中引入了额外的开销。
我们进行了大量的实验来评估所提出的方法的效率和有效性。如图3 所示,Co-DETR极大地缓解了编码器在一对一集合匹配中的特征学习不足。作为一种即插即用的方法,我们很容易将其与不同的DETR变体相结合,包括DAB-DETR、Deformable-DETR和DINO-Deformable-DETR。如图1所示,Co-DETR实现了更快的训练收敛,甚至更高的性能。具体来说,我们在12-epoch训练中将基本的Deformable-DETR提高了5.8%AP,在36-epoch的训练中提高了3.2%。使用Swin-L的最先进的DINO可变形DETR在COCO val上仍然可以从58.5%提高到59.5%的AP。令人惊讶的是,与ViT-L[8]主干相结合,我们在COCO test-dev上实现了66.0%的AP,在LVIS val上实现了67.9%的AP,建立了新的最先进、模型尺寸小得多的检测器。
4. 相关工作
4.1 一对多标签分配
对于对象检测中的一对多标签分配,可以在训练阶段将多个候选框分配给与正样本相同的基本事实框。在经典的基于锚的检测器中,如Faster RCNN[27]和RetinaNet[21],样本选择由预定义的IoU阈值以及锚和注释框之间的匹配IoU来指导。无锚FCOS[32]利用中心先验,并将每个边界框中心附近的空间位置分配为正值。此外,自适应机制被结合到一对多标签分配中,以克服固定标签分配的限制。ATSS[41]通过前k个最近锚的统计动态IoU值来执行自适应锚选择。PAA[17]以概率的方式自适应地将锚分为正样本和负样本。在本文中,我们提出了一种协作混合分配方案,通过具有一对多标签分配的辅助头来改进编码器表示。
4.2 一对一匹配
开创性的基于Transformer的检测器DETR[1]将一对一集合匹配方案结合到对象检测中,并执行完全端到端的对象检测。一对一集合匹配策略首先通过匈牙利匹配计算全局匹配成本,并为每个 groud truth 仅分配一个具有最小匹配成本的正样本。DN-DETR[18]证明了一对一集合匹配的不稳定性导致的缓慢收敛,因此引入了去噪训练来消除这一问题。DINO[39]在她的文章中采用了DAB-DETR[23]的高级查询公式,并结合了改进的对比去噪技术,以实现最先进的性能。Group DETR[5]构造逐组的一对多标签分配,以利用多个正对象查询,这类似于H-DETR[16]中的混合匹配方案。与上述后续工作相比,我们提出了一对一集合匹配协同优化的新视角。
5. 方法
5.1 概述
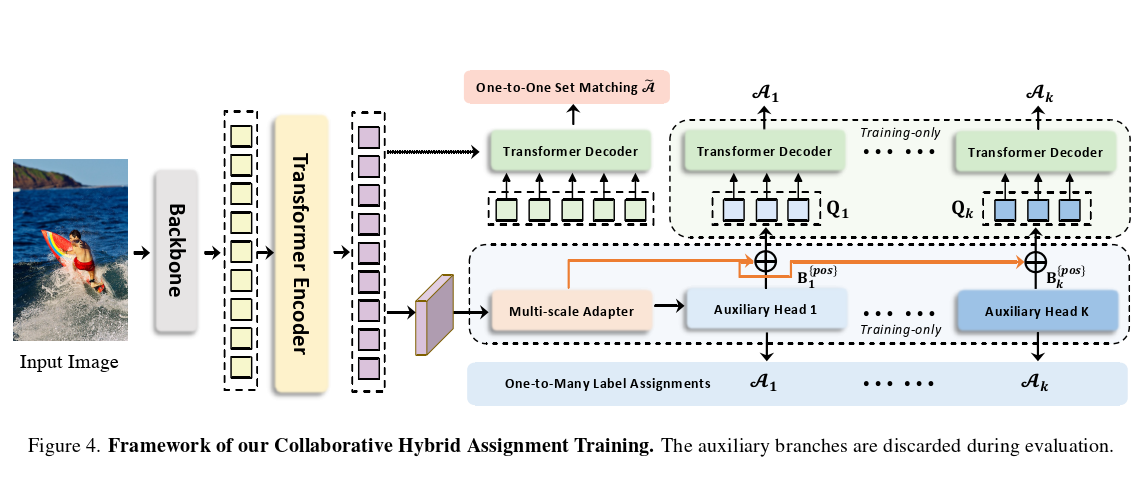
根据标准DETR协议,输入图像被馈送到主干和编码器中,以生成潜在特征。多个预定义的对象查询随后通过交叉关注在解码器中与它们交互。我们引入了Co-DETR,通过协作混合分配训练方案和定制的正向查询生成来改进编码器中的特征学习和解码器中的注意力学习。我们将详细描述这些模块,并深入了解它们为什么能很好地工作。
5.2 协作混合分配训练

表1.辅助头的详细信息。辅助头包括Faster RCNN[27]、ATSS[41]、RetinaNet[21]和FCOS[32]。如果没有另外指定,我们将遵循原始实现,例如,锚点生成。

为了缓解解码器中较少的正向查询对编码器输出的稀疏监督,我们引入了具有不同一对多标签分配范式的通用辅助头,例如ATSS和Faster R-CNN。不同的标签分配丰富了对编码器输出的监督,这迫使它具有足够的鉴别力,以支持这些头部的训练收敛。具体来说,给定编码器的潜在特征F,我们首先通过多尺度适配器将其转换为特征金字塔{F1,··,FJ},其中J表示具有 下采样步长的特征图。与ViT Det[20]类似,特征金字塔是由单尺度编码器中的单个特征映射构建的,而我们使用双线性插值和3×3卷积进行上采样。例如,对于来自编码器的单尺度特征,我们成功地应用下采样(3×3与步长2的卷积)或上采样操作来产生特征金字塔。对于多尺度编码器,我们只对多尺度编码器特征 F 中最粗糙的特征进行下采样,以构建特征金字塔。定义了具有相应标签分配方式的K个协作头
,对于第 i 个协作头,将{F1,··,FJ}发送给它,以获得预测。在第 i 个头处,
用于计算
中正样本和负样本的监督目标。将 G 表示为基本真值集,该过程可以公式化为:
![]()
其中{pos}和{neg}表示由 确定的(j,Fj中的正坐标或负坐标)的对集。j 表示{F1,··,Fj}中的特征索引。
是一组空间正坐标。
和
是相应坐标中的监督目标,包括类别和回归偏移。具体来说,我们在表1中描述了每个变量的详细信息。损失函数可以定义为:
![]()
请注意,对于负样本,将丢弃回归损失。K 个辅助头优化的训练目标如下:

5.3 自定义 Positive 查询生成
在一对一集合匹配范式中,每个 ground-truth box 将只分配给一个特定的查询作为监督目标。如图2所示,积极查询过少会导致转换器解码器中的交叉注意力学习效率低下。为了缓解这种情况,我们根据每个辅助头中的标签分配 精心生成了足够的定制肯定查询。具体而言,给定正坐标集
在第 i 个辅助头中,其中Mi是正样本的数量,额外定制的正查询
可以由下式生成:

其中 PE(·) 代表位置编码,我们根据索引对(j,Fj中的正坐标或负坐标)从 E(·) 中选择相应的特征。
因此,在训练期间,有K1组查询属于单个一对一集匹配分支,并且有K个分支具有一对多标签分配。辅助的一对多标签分配分支与原始主分支中的L个解码器层共享相同的参数。辅助分支中的所有查询都被视为正查询,因此丢弃了匹配过程。
![]()
Pi,l 是指第 i 个辅助分支中的第 l 个解码器层的输出预测。最后,Co-DETR的训练目标是:

其中,![]() 代表原始一对一集合匹配分支[1]中的损耗,λ1 和 λ2 是平衡损耗的系数。
代表原始一对一集合匹配分支[1]中的损耗,λ1 和 λ2 是平衡损耗的系数。
5.4 为什么Co-DETR有效
Co-DETR导致了对基于DETR的检测器的明显改进。在下文中,我们试图从定性和定量两个方面研究其有效性。我们使用36-epoch设置,基于ResNet-50主干的Deformable-DETR进行详细分析。
5.4.1 丰富编码器的监督
直观地说,太少的正向查询会导致稀疏的监督,因为对于每个基本事实,只有一个查询受到回归损失的监督。以一对多标签分配方式的正样本接受更多的定位监督,以帮助增强潜在特征学习。为了进一步探索稀疏监督如何阻碍模型训练,我们详细研究了编码器产生的潜在特征。我们引入IoF-IoB曲线来量化编码器输出的可分辨性得分。具体来说,给定编码器的潜在特征F,受图3中特征可视化的启发,我们计算 IoF(前景上的交叉点)和 IoB(背景上的交叉口)。给定编码器在j级的特征 ,我们首先计算
范数
,并将其调整为图像大小 H×W。可辨别性得分 D(F) 是通过对所有级别的得分进行平均来计算的:


图5.COCO数据集上Deformable-DETR和Co-Deformable-DETR的不稳定性(IS)[18]。这些探测器使用ResNet-50主干进行了12-epoch的训练。
[18] Feng Li,Hao Zhang,Shilong Liu,Jian Guo,Lionel M Ni,and Lei Zhang.Dn-detr:Accelerate detr training by intro-ducing query denoising.In Proceedings of the IEEE/CVFConference on Computer Vision and Pattern Recognition,pages 13619–13627,2022.3,5,7
5.4.2 其中省略了调整大小的操作
我们在图3中可视化了ATSS、Deformable-DETR和Co-Deformable-DETR的可分辨性得分。与Deformable-DETR相比,ATSS和Co-Deformable-DETR都具有更强的区分关键对象区域的能力,而Deformable-DETR几乎受到背景的干扰。因此,
- 我们将前景和背景的指示符分别定义为
 和
和  。
。 - S 是预定义的得分阈值,如果 x 为真,则
 为 1,否则为 0。
为 1,否则为 0。 - 对于前景
的掩码,如果点(h,w)在前景内部,则元素
为1,否则为0。
- 前景上的相交面积
 可以计算为:
可以计算为:

具体来说,我们以类似的方式计算后台区域的交叉面积(IoB),并在图2中通过改变S绘制曲线IoF和IoB。显然,在相同的IoB值下,ATSS和可变形DETR获得的IoF值高于Deformable-DETR和Group-DETR,这表明编码器表示从一对多标签分配中受益。
5.4.3 通过降低匈牙利语匹配的稳定性来提高交叉注意力学习
匈牙利匹配是一对一集合匹配的核心方案。交叉注意是帮助正向查询编码丰富对象信息的重要操作。要做到这一点,需要充分的训练。我们观察到,匈牙利匹配引入了不可控的不稳定性,因为在训练过程中,ground truth 被分配给同一图像中的特定肯定查询。在 DN-DETR 之后,我们在图5 中对不稳定性进行了比较,我们发现我们的方法有助于更稳定的匹配过程。此外,为了量化交叉注意力的优化程度,我们还计算了注意力得分的IoF-IoB曲线。与特征可分辨性得分计算类似,我们为注意力得分设置不同的阈值,以获得多个IoF-IoB对。Deformable-DETR、Group-DETR和Co-Deformable-DETR之间的比较如图2 所示。我们发现,具有更积极查询的DETR的IoF-IoB曲线通常高于Deformable-DETR,这与我们的动机一致。
5.5 与其他方法的比较
我们的方法与其他计数器部分之间的差异。Group-DETR、H-DETR和SQR[2]通过与重复组和重复地面实况框进行一对一匹配来执行一对多分配。Co-DETR显式地为每个 ground truth 指定多个空间坐标作为正值。因此,这些密集的监督信号被直接应用于潜在特征图,以使其更具鉴别性。相比之下,组DETR、H-DETR和SQR缺乏这种机制。尽管在这些对应中引入了更多的正向查询,但匈牙利匹配实现的一对多分配仍然存在一对一匹配的不稳定性问题。我们的方法得益于现成的一对多赋值的稳定性,并继承了它们在正查询和基本事实框之间的特定匹配方式。分组DETR和H-DETR未能揭示一对一匹配与传统的一对多分配之间的互补性。据我们所知,我们是第一个用传统的一对多分配和一对一匹配对探测器进行定量和定性分析的人。这有助于我们更好地理解它们的差异和互补性,这样我们就可以通过利用现成的一对多作业设计来自然地提高DETR的学习能力,而不需要额外的专业一对多设计经验。
解码器中没有引入否定查询。重复的对象查询不可避免地会给解码器带来大量的负面查询,并显著增加GPU内存。然而,我们的方法只处理解码器中的正坐标,因此消耗较少的内存,如表7所示。
6 实验
6.1 设置
数据集和评估指标:我们的实验是在MS COCO 2017数据集[22]和LVISv1.0数据集[12]上进行的。COCO数据集由115K张用于训练的标记图像和5K张用于验证的图像组成。我们默认在val子集上报告检测结果。还报告了我们在测试dev上评估的最大模型(20K图像)的结果。LVIS v1.0是一个大型长尾数据集,有1203个类别用于大型词汇实例分割。为了验证Co-DETR的可扩展性,我们将其进一步应用于大规模对象检测基准,即Objects365[30]。Objects365数据集中有1.7M个标记图像用于训练,80K个图像用于验证。所有结果都遵循标准平均平均精度(AP),在不同物体尺度下,IoU阈值范围为0.5至0.95。
实验细节:我们将我们的Co-DETR纳入当前类似DETR的管道中,并保持训练设置与基线一致。对于K=2,我们采用ATSS和Faster RCNN作为辅助头,对于K=1,我们只保留ATSS。关于我们的辅助头的更多详细信息,请参阅补充材料。我们选择可学习对象查询的数量为300,并将{λ1,λ2}默认设置为{1.0, 2.0}。对于Co-DINO-Deformable-DETR++,我们使用复制粘贴的大规模抖动[10]。
6.2 主要结果



在本节中,我们在表2和表3中实证分析了Co-DETR对不同DETR变体的有效性和泛化能力。所有结果都是使用mmdetection重新生成的[4]。我们首先将协作混合任务训练应用于具有C5特征的单尺度DETR。令人惊讶的是,在长训练计划的基础上,条件性DETR和DAB-DETR都获得了2.4%和2.3%的AP增益。对于具有多尺度特征的Deformable-DETR,检测性能从37.1%显著提高到42.9%。当训练时间增加到36-epoch时,总体上仍有改善(3.2%)。此外,我们在[16]之后对改进的可变形DETR(表示为可变形DETER)进行了实验,其中观察到2.4%的AP增益。采用我们的方法配备的最先进的DINO可变形DETR可实现51.2%的AP,比竞争基线高1.8%的AP。
我们基于两条最先进的基线,进一步将骨干容量从ResNet-50扩展到Swin-L[25]。如表3所示,Co-DETR实现了56.9%的AP,并以很大的幅度(1.7%的AP)超过了可变形DETR基线。具有Swin-L的DINO可变形DETR的性能仍然可以从58.5%提高到59.5%的AP。
6.3 与最先进技术的比较

我们将K=2的方法应用于可变形DETR和DINO。此外,我们的Co-DINO可变形DETR采用了质量聚焦损耗[19]和NMS。我们在表4中报告了COCO值的比较。与其他竞争对手相比,我们的方法收敛得更快。例如,当仅使用具有ResNet-50骨干的12-epoch时,Co-DINO可变形DETR容易地实现52.1%的AP。我们的Swin-L方法在1×调度器上可以获得58.9%的AP,甚至在3×调度器上超过了其他最先进的框架。(SOTA)更重要的是,我们的最佳模型Co-DINO-Deformable-DETR++在36-epoch训练下,使用ResNet-50实现了54.8%的AP,使用Swin-L实现了60.7%的AP,以明显的优势超过了具有相同主干的所有现有检测器。

为了进一步探索我们方法的可扩展性,我们将主干容量扩展到3.04亿个参数。该大规模骨干ViT-L[7]使用自监督学习方法(EVA-02[8])进行预训练。我们首先在Objects365上用ViT-L预训练26个时期的Co-DINO可变形DETR,然后在COCO数据集上微调12个时期。在微调阶段,输入分辨率在480×2400和1536×2400之间随机选择。详细设置可在补充材料中获得。我们的结果是通过增加测试时间来评估的。表5展示了对COCO测试开发基准的最先进的比较。Co-DETR的模型大小(304M个参数)要少得多,在COCO测试开发中创下了66.0%AP的新纪录,比之前的最佳模型InternImage-G[34]高出0.5%AP。


我们还展示了Co-DETR在长尾LVIS检测数据集上的最佳结果。特别是,我们使用与COCO上的模型相同的Co-DINO-Deformable-DETR,但选择FedLoss[42]作为分类损失,以弥补数据分布不平衡的影响。在这里,我们只应用边界框监督并重新报告对象检测结果。比较结果见表6。在LVIS val和minival上,与Swin-L的Co-DETR产生56.9%和62.3%的AP,分别超过了与MAE预训练[13]ViT-H和GLIPv2[40]的ViT-Det 3.5%和2.5%的AP。我们在该数据集上进一步微调了Objects365预训练的Co-Det。在不增加详细的测试时间的情况下,我们的方法在LVIS val和minival上分别获得了67.9%和71.9%的最佳检测性能。与增加了测试时间的30亿参数InternImage-G相比,我们在LVIS值和最小值上分别获得了4.7%和6.1%的AP增益,同时将模型大小减小到1/10。
6.4 消融实验


除非另有说明,所有消融实验均在具有ResNet-50骨干网络的Deformable-DETR上进行。默认情况下,我们将辅助头的数量K选择为1,并将总批量设置为32。在补充材料中可以找到更多的消融和分析。辅助封头的选择标准。我们进一步研究了表7和表8中选择辅助磁头的标准。表8中的结果表明,任何具有一对多标签分配的辅助磁头都能持续提高基线,ATSS实现最佳性能。我们发现,当选择小于3的K时,精度随着K的增加而继续增加。It is worth noting that,当K=6时,性能会下降,我们推测辅助磁头之间的严重冲突会导致这种情况。如果辅助磁头的特征学习不一致,则随着K变大,持续改进将被破坏。接下来,我们还分析了补充材料中多个头的优化一致性。在保险方面,我们可以选择任何一个磁头作为辅助磁头,我们认为ATSS和Faster RCNN是在K≤2时实现最佳性能的常用方法。我们不使用太多不同的头,例如,6个不同的头以避免优化冲突。
冲突分析。当相同的空间坐标被分配给不同的前景框或在不同的辅助头中被视为背景时,冲突就会出现,并且可能混淆检测器的训练。我们首先将头Hi和头Hj之间的距离以及Hi的平均距离定义为:


其中,KL、D、I、C是指KL散度、数据集、输入图像和类激活图(CAM)[29]。如图6所示,我们计算了K>1时辅助磁头之间的平均距离,以及K=1时DETR磁头和单个辅助磁头之间距离。我们发现,当K=1时,距离度量对每个辅助头来说都是不重要的,这一观察结果与我们在表8中的结果一致:当K=1时,DETR头可以与任何头协同改进。当K增加到2时,距离指标略有增加,我们的方法实现了最佳性能,如表7所示。当K从3增加到6时,距离激增,这表明这些辅助磁头之间的严重优化冲突导致性能下降。然而,6ATSS的基线达到了49.5%的AP,并且可以通过用6个不同的头代替ATSS而降低到48.9%的AP。因此,我们推测过多不同的辅助人头,例如超过3个不同的头,会加剧冲突。总之,优化冲突受各种辅助头的数量以及这些头之间的关系的影响。

图6.当K从1到6变化时的距离。
添加的头应该不同吗?使用两个ATSS头部(49.2%的AP)进行协作训练仍然改进了使用一个ATSS头(48.7%的AP)的模型,因为在我们的分析中,ATSS是对DETR头部的补充。此外,引入一种多样且互补的辅助头,而不是与原始磁头相同的头,例如更快的RCNN,可以带来更好的增益(49.5%AP)。请注意,这与上述结论并不矛盾;相反,我们可以在几个不同的头(K≤2)下获得最佳性能,因为冲突是微不足道的,但当使用许多不同的头时(K>3),我们会面临严重的冲突。

每个组件的效果。我们进行了组件消融,以彻底分析表9中每个组件的影响。由于密集的空间监督使编码器功能更具鉴别力,因此合并辅助头可获得显著的增益。 或者,引入定制的肯定查询也对最终结果有显著贡献,同时提高了一对一集合匹配的训练效率。这两种技术都可以加速收敛并提高性能。总之,我们观察到整体改进源于编码器更具鉴别性的特征和解码器更有效的注意力学习。
与较长的训练计划相比。如表10所示,我们发现随着性能饱和,Deformable-DETR无法从更长的训练中受益。相反,Co-DETR大大加速了收敛,同时提高了峰值性能。

辅助分支的性能。令人惊讶的是,在表11中,我们观察到Co-DETR也为辅助头带来了一致的增益。这意味着我们的训练范式有助于更具鉴别性的编码器表示,这提高了解码器和辅助头的性能。

原始肯定查询和自定义肯定查询的分布差异。我们在图7a中可视化了原始肯定查询和自定义肯定查询的位置。每个图像只显示一个对象(绿色框)。解码器中匈牙利匹配指定的肯定查询用红色标记。我们分别用蓝色和橙色标记从Faster RCNN和ATSS中提取的阳性查询。这些定制的查询分布在实例的中心区域周围,并为检测器提供足够的监督信号。
分布差异会导致不稳定吗?我们在图7b 中计算了原始查询和定制查询之间的平均距离。原始否定查询和自定义肯定查询之间的平均距离显著大于原始肯定查询和自定义否定查询之间的距离。由于原始查询和自定义查询之间的分布差距很小,因此在训练过程中不会遇到稳定性问题。
>>>> 如有疑问,欢迎品论区一起探讨。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 30
30 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)