MotionBert论文解读及详细复现教程
我们提出了一个统一的视角来处理各种以人为中心的视频任务,通过从大规模和异质的数据资源中学习人类运动表示。具体来说,我们提出了一个预训练阶段,在该阶段,一个运动编码器被训练来从嘈杂的部分2D观察中恢复底层的3D运动。通过这种方式获得的运动表示结合了几何、运动学和物理知识,可以轻易地转移到多个下游任务。我们使用一种双流空间-时间转换器(DSTformer)神经网络实现运动编码器。它能全面而灵活地捕获骨
MotionBert:统一视角学习人体运动表示
通过学习人体运动表征,论文原作者提出了处理以人为中心的视频任务的统一方法。使用双流时空transformer(DSTformer)网络实现运动编码器,能够全面、自适应地捕获骨骼关节之间的远程时空关系。所学运动表征能轻松转移到多个下游任务,并在三个任务上实现最先进性能,证明其多功能性。
相关链接:
Paper: Learning Human Motion Representations: A Unified Perspective
Github: MotionBert
笔者出于学习目的,整理MotionBert相关内容如下:
本文内容中出现的一切论文直接相关的文字、图片版权归论文原作者所有,此处展示仅供参考学习。
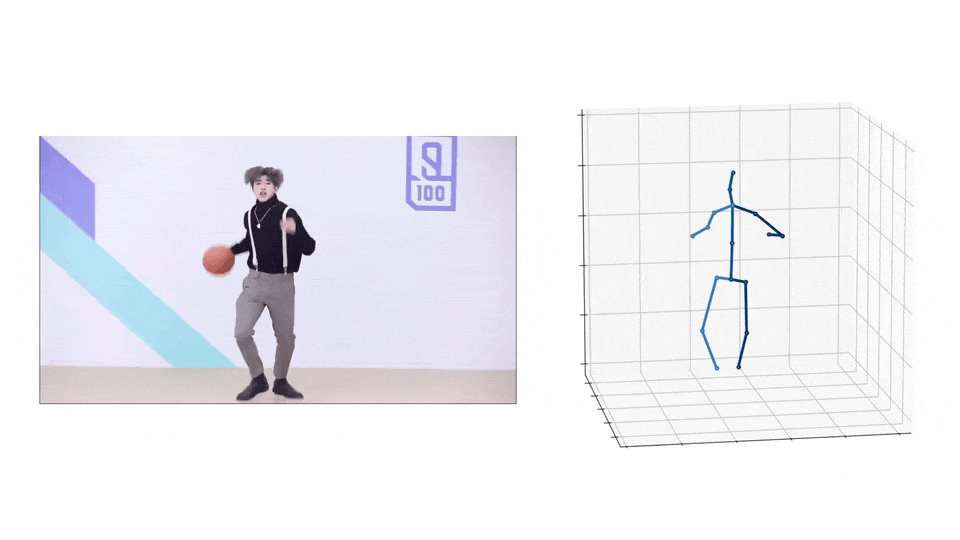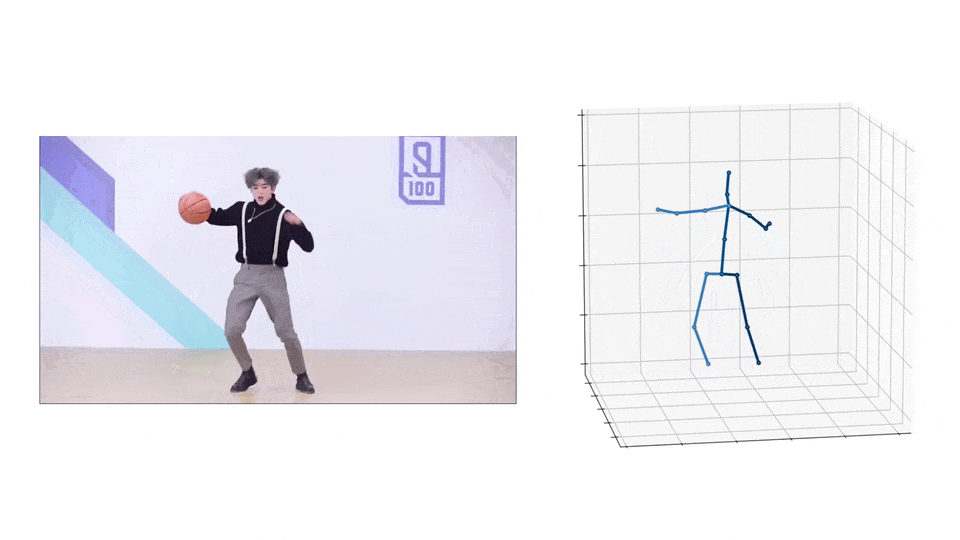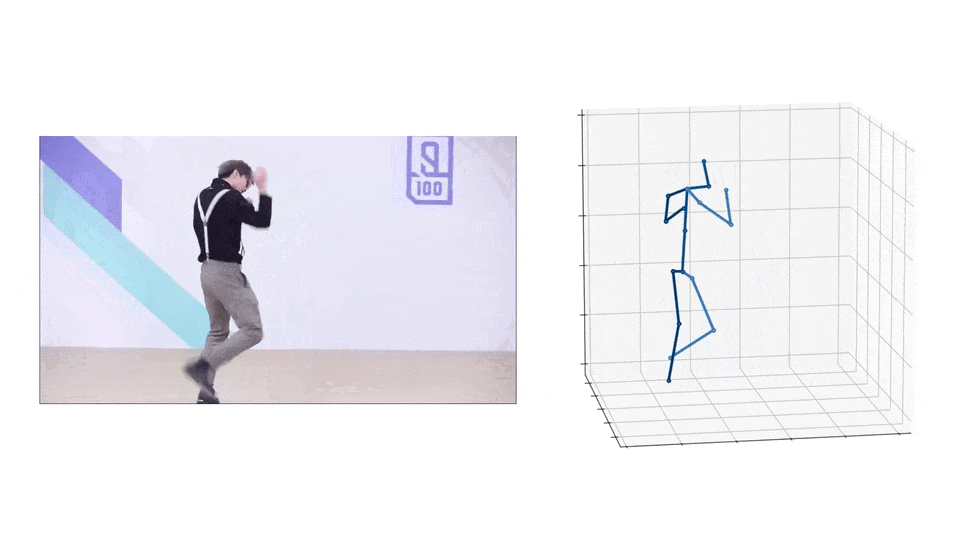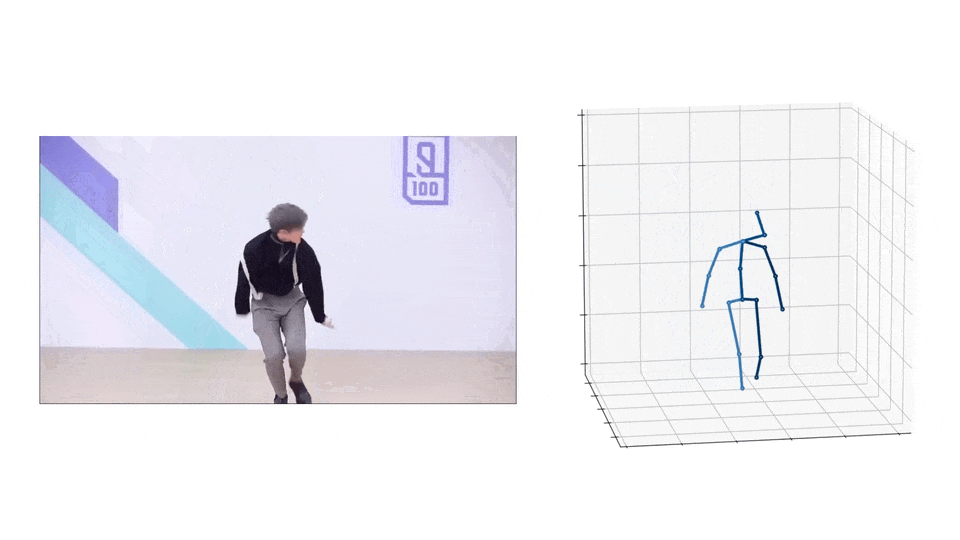
效果演示

实测过程
注意: 该配置测试的时间及环境为:Ubuntu22.04、2023-7-18,以下内容在该环境下测试可行。
1.配置alphapose
MotionBert的2D Pose输入来自alphapose,因此需要先将视频放入alphapose进行处理。
# 1. Create a conda virtual environment.
conda create -n alphapose python=3.7 -y
conda activate alphapose
# 2. Install specific pytorch version
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
# 3. Get AlphaPose
git clone https://github.com/MVIG-SJTU/AlphaPose.git
cd AlphaPose
# 4. install dependencies
export PATH=/usr/local/cuda/bin/:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64/:$LD_LIBRARY_PATH
sudo apt-get install libyaml-dev
pip install cython==0.27.3 ninja easydict halpecocotools munkres natsort opencv-python pyyaml scipy tensorboardx terminaltables timm==0.1.20 tqdm visdom jinja2 typeguard pycocotools
################Only For Ubuntu 18.04#################
locale-gen C.UTF-8
# if locale-gen not found
sudo apt-get install locales
export LANG=C.UTF-8
######################################################
# 5. install AlphaPose
python setup.py build develop
# 6. Install PyTorch3D (Optional, only for visualization)
conda install -c fvcore -c iopath -c conda-forge fvcore iopath
conda install -c bottler nvidiacub
pip install pytorch3d
从github的项目页下载yolov3-spp.weights到AlphaPose/detector/yolo/data ,如果没有这个文件夹就创建一个。

下载FastPose预训练模型到AlphaPose/pretrained_models

2.测试alphapose
python scripts/demo_inference.py --cfg configs/halpe_26/resnet/256x192_res50_lr1e-3_1x.yaml --checkpoint pretrained_models/halpe26_fast_res50_256x192.pth --indir examples/demo/ --save_img
AlphaPose/examples/demo文件夹下的图片将被用作处理,AlphaPose/examples/res文件夹下将出现处理后的结果


3.将视频导入模型进行姿态估计
python scripts/demo_inference.py --cfg configs/halpe_26/resnet/256x192_res50_lr1e-3_1x.yaml --checkpoint pretrained_models/halpe26_fast_res50_256x192.pth --video examples/demo/test_video.mp4 --save_video

4.配置motionbert
conda create -n motionbert python=3.7 anaconda
conda activate motionbert
# Please install PyTorch according to your CUDA version.
conda install pytorch torchvision torchaudio pytorch-cuda=11.6 -c pytorch -c nvidia
pip install -r requirements.txt
5.在motionbert中生成3D pose
参考motionbert-3dpose,下载checkpoint文件并保存到checkpoint/pose3d/FT_MB_lite_MB_ft_h36m_global_lite/
在MotionBERT目录下执行
mkdir -p checkpoint/pose3d/FT_MB_lite_MB_ft_h36m_global_lite
将best_epoch.bin文件放入该文件夹
随后在MotionBERT目录下执行
python infer_wild.py \
--vid_path <your_video.mp4> \
--json_path <alphapose-results.json> \
--out_path <output_path>
按照我的例子则是:
python infer_wild.py \
--vid_path test_demo/AlphaPose_test_video.mp4 \
--json_path test_demo/alphapose-results.json \
--out_path test_demo
注意:需要切换到motionbert 的Conda Env执行该文件
conda activate motionbert
如果报错如下:
qt.qpa.plugin: Could not load the Qt platform plugin "xcb" in "/home/hermanye/anaconda3/envs/motionbert/lib/python3.7/site-packages/cv2/qt/plugins" even though it was found.
This application failed to start because no Qt platform plugin could be initialized. Reinstalling the application may fix this problem.
就重装opencv
pip uninstall opencv-python
pip install opencv-python-headless

6.在motionbert中建立mesh
参考motionbert-mesh,下载checkpoint文件并保存到checkpoint/mesh/FT_MB_release_MB_ft_pw3d/
在MotionBERT目录下执行
mkdir -p checkpoint/mesh/FT_MB_release_MB_ft_pw3d
将best_epoch.bin文件放入该文件夹
注意: 与步骤4的文件名相同,但并非同一文件,需要鉴别。
前往smplify下载SMPL ,需要注册账号。

将/smplify_public/code/models/basicModel_neutral_lbs_10_207_0_v1.0.0.pkl重命名为SMPL_NEUTRAL.pkl,放入MotionBERT/data/mesh文件夹,如果没有该文件夹就建一个。
然后前往下载数据集,将MotionBERT提供的数据集放置在MotionBERT/data/mesh文件夹下

遇到了报错:
Traceback (most recent call last):
File "infer_wild_mesh.py", line 71, in <module>
model = MeshRegressor(args, backbone=model_backbone, dim_rep=args.dim_rep, hidden_dim=args.hidden_dim, dropout_ratio=args.dropout)
File "/home/hermanye/motion_bert_ws/src/MotionBERT/lib/model/model_mesh.py", line 87, in __init__
self.head = SMPLRegressor(args, dim_rep, num_joints, hidden_dim, dropout_ratio)
File "/home/hermanye/motion_bert_ws/src/MotionBERT/lib/model/model_mesh.py", line 30, in __init__
mean_params = np.load(self.smpl.smpl_mean_params)
File "/home/hermanye/anaconda3/envs/motionbert/lib/python3.7/site-packages/numpy/lib/npyio.py", line 417, in load
fid = stack.enter_context(open(os_fspath(file), "rb"))
FileNotFoundError: [Errno 2] No such file or directory: 'data/mesh/smpl_mean_params.npz'
估计是在MotionBERT作者给的数据集下的命名不对,需要将h36m_mean_smpl.npz改为smpl_mean_params.npz
随后在MotionBERT目录下执行
python infer_wild_mesh.py \
--vid_path <your_video.mp4> \
--json_path <alphapose-results.json> \
--out_path <output_path> \
--ref_3d_motion_path <3d-pose-results.npy> # Optional, use the estimated 3D motion for root trajectory.
按照我的例子则是:
python infer_wild_mesh.py \
--vid_path test_demo/AlphaPose_test_video.mp4 \
--json_path test_demo/alphapose-results.json \
--out_path test_demo \
--ref_3d_motion_path test_demo/X3D.npy # Optional, use the estimated 3D motion for root trajectory.

复现成功,但是和@咬人猫 对比起来不知道为什么感觉怪怪的。
其实今天上午看MotionBert效果很好,本来打算用于机械臂的动作实时同步映射的,测着测着发现从处理时长过长和MotionBert原有的代码结构来说太过麻烦,就此作罢,开摆开摆。
论文译文
提示:
笔者水平有限,以下译文和批注可能存在事实性错误。
如需了解论文详细内容,请参考原作者论文Page。

标题
Learning Human Motion Representations: A Unified Perspective
作者
Wentao Zhu1 Xiaoxuan Ma1 Zhaoyang Liu2 Libin Liu1 Wayne Wu2,3 Yizhou Wang1
1 Peking University 2 SenseTime Research 3 Shanghai AI Laboratory
{wtzhu,maxiaoxuan,libin.liu,yizhou.wang}@pku.edu.cn
{zyliumy,wuwenyan0503}@gmail.com
摘要
我们提出了一个统一的视角来处理各种以人为中心的视频任务,通过从大规模和异质的数据资源中学习人类运动表示。具体来说,我们提出了一个预训练阶段,在该阶段,一个运动编码器被训练来从嘈杂的部分2D观察中恢复底层的3D运动。通过这种方式获得的运动表示结合了几何、运动学和物理知识,可以轻易地转移到多个下游任务。我们使用一种双流空间-时间转换器(DSTformer)神经网络实现运动编码器。它能全面而灵活地捕获骨骼关节之间的长距离空间-时间关系,如当从头开始训练时,展现出了迄今为止最低的3D姿态估计错误。此外,我们提出的框架通过简单地微调预训练的运动编码器,并附加一个简单的回归头(1-2层),在所有三个下游任务中都取得了最新的表现,这证明了所学习的运动表示的通用性。
摘要批注
这篇论文的主要贡献是提出了一种新的方法来学习人类运动的表现形式,然后将这种学习到的表现形式应用到不同的任务中。在预训练阶段,作者训练一个模型来从噪声和部分的2D观测中恢复3D的人类动作。然后,这个模型可以在后续的任务中进行微调以适应特定的任务。这种方法的一个重要特点是它使用了双流空间-时间转换器网络,该网络能够在空间和时间上捕获人体骨骼的关系。这使得模型能够在训练时,就能够展现出非常低的3D姿态估计错误。

1. 引言
理解并感知人类的活动长久以来一直是机器智能的核心追求。为此,研究人员定义了各种任务来从视频中估算关于人的语义标签,例如骨架关键点、动作类别和表面网格。虽然在这些任务上取得了显著的进展,但他们往往被视为独立的问题进行建模,而非相互连接的问题。例如,空间时间图卷积网络(ST-GCN)已经被用来建模人体关节在3D姿势估计和动作识别中的时空关系,但这些模型之间的联系尚未被充分探索。直觉上,这些模型应该都已经学会了识别典型的人体运动模式,尽管他们是为不同的问题设计的。然而,当前的方法未能挖掘和利用这些任务之间的共性。理想情况下,我们可以开发一种统一的、面向人的视频表示,可以在所有相关任务中共享。
开发这样的表示的一个重大挑战是可用数据资源的异质性。动作捕捉(Mocap)系统提供由标记和传感器获得的高保真度3D运动数据,但捕捉视频的外观通常受限于简单的室内场景。动作识别数据集提供了动作语义的注释,但它们要么不包含人体姿势标签,要么只具有日常活动的有限动作。相比之下,户外视频提供了外观和运动的广泛和多样化的范围。然而,获取精确的2D姿势注释需要消耗大量的精力,获取3D关节位置的真实数据几乎是不可能的。因此,大多数现有的研究都专注于使用单一类型的人体运动数据来解决特定的任务,而无法享受其他数据资源的优点。
在这项工作中,我们为学习人类运动表示提供了新的视角。关键的想法是,我们可以从异质数据资源中以统一的方式学习到通用的人类运动表示,并以统一的方式利用该表示来处理不同的下游任务。我们提出了一个两阶段的框架,包括预训练和微调,如图1所示。在预训练阶段,我们从多样化的运动数据源中提取2D骨架序列,并用随机的遮罩和噪声对其进行破坏。随后,我们训练运动编码器从损坏的2D骨架中恢复3D运动。这个具有挑战性的预文本任务本质上需要运动编码器i)从其时间移动中推断出潜在的3D人体结构;ii)恢复错误和缺失的观察结果。以这种方式,运动编码器隐式地捕获了人类运动的常识,如关节连接、解剖约束和时间动态。在实践中,我们提出了双流空时变换器(DSTformer)作为运动编码器来捕获骨架关键点之间的长程关系。我们假设从大规模和多样化的数据资源中学习到的运动表示可以在不同的下游任务中共享,并提高其性能。因此,对于每个下游任务,我们使用任务特定的训练数据和监督信号以及一个简单的回归头(regression head) 来调整预训练的运动表示。
总的来说,本工作的贡献是三方面的:1)我们提供了通过学习人类运动表示解决各种面向人的视频任务的新视角。2)我们提出了一种预训练方法,利用大规模但异质的人体运动资源,学习通用的人体运动表示。我们的方法可以同时利用3D mocap数据的精度和户外RGB视频的多样性。3)我们设计了一个双流Transformer网络,配备了串联的空时自注意力块,可以作为人体运动建模的通用骨架。实验表明,上述设计使得可以将通用的人体运动表示转移到多个下游任务,超越了任务特定的最先进的方法。
引言批注
这个研究提供了一个全新的视角,旨在通过学习人体运动表示来解决多种面向人类的视频任务。为了达到这个目标,作者提出了一个两阶段的框架,包括预训练和微调。预训练阶段是利用各种异质数据资源来训练一个能从噪声和部分2D观察中恢复3D运动的运动编码器。这个阶段的训练要求模型能够理解和捕获人体运动的基本规律,如关节连接,解剖约束和时间动态。为此,作者提出了双流空时变换器(DSTformer),这是一个能够捕获骨架关键点间长距离关系的神经网络。预训练阶段完成后,将对每个下游任务进行微调,只需简单的回归头,便可以调整预训练的运动表示。这项工作的主要贡
献包括提供了一种新视角来解决面向人的视频任务,提出了一种能够充分利用大规模异质数据的预训练方法,以及设计了一个可以作为人体运动建模的通用神经网络。
2. 相关工作
学习人体运动表示
早期的研究利用隐马尔科夫模型和图形模型来描述人体运动。Kanazawa等人设计了一个时间编码器和一个幻想器来学习3D人体动力学的表示。Zhang等人以自监督的方式预测未来的3D动力学。Sun等人进一步结合了行动标签和行动记忆库。从行动识别的角度出发,设计了各种自我监督的前文任务来学习运动表示,包括未来的预测、拼图、骨架对比、速度变化、交叉视图的一致性和对比重建。类似的技术也在动作评估和动作重定位任务中被探索。这些方法利用同质性的动作数据,设计相应的前文任务,并将其应用于特定的下游任务。在这项工作中,我们提出了一个统一的预训练-微调框架,整合了各种异质数据资源,并展示了它在各种下游任务中的通用性。
3D人体姿态估计
从单目RGB视频中恢复3D人体姿态是一个经典问题,方法可以分为两类。第一类是直接从图像中使用CNN来估计3D姿态。然而,由于当前的数据收集技术,这些方法的一个局限性是3D姿态精度和外观多样性之间存在权衡。第二类是先提取2D姿态,然后用另一个神经网络将估计的2D姿态升级为3D。提升可以通过全连接网络、时间卷积网络、GCN和Transformer来实现。我们的框架基于第二类,我们使用提出的DSTformer来完成2D到3D的提升。
基于骨架的行为识别
开创性的工作指出了行为识别和人体姿态估计之间的内在联系。为了建模人体关节之间的时空关系,以前的研究主要采用了LSTM和GCN。最近,PoseConv3D提出在堆叠的2D关节热图上应用3D-CNN,并取得了改进的结果。除了完全监督的行动识别任务,NTU-RGB+D120引起了对一次性行动识别问题的关注。为此,SL-DML对多模态信号应用了深度度量学习。Sabater等人在治疗场景中探讨了一次性识别。我们证明了预训练的运动表示可以很好地推广到行动识别任务,预训练-微调框架是一次性挑战 (one-shot challenges) 的合适解决方案。
人体网格恢复
基于如SMPL等参数化人体模型,许多研究工作集中在从单个图像中回归人体网格。尽管他们每帧的结果很有希望,但是当应用到视频时,这些方法产生的结果会抖动和不稳定。为了提高他们的时间连贯性,PoseBERT和SmoothNet提出在单帧预测中使用去噪和平滑模块。几项工作将视频剪辑作为输入来利用时间线索。另一个常见的问题是配对的图像和GT网格大多是在受限的场景中捕获的,这限制了上述方法的泛化能力。为此,Pose2Mesh提出首先使用现成的姿态估计器提取2D骨架,然后将其提升到3D网格顶点。我们的方法与最先进的人体网格恢复方法互补,并可以通过预训练的运动表示进一步提高他们的时间连贯性。
相关工作批注
-
本节回顾了四个主要领域的研究:人体运动表示学习、3D人体姿态估计、基于骨架的行为识别和人体网格恢复。作者提到了这些领域内的关键技术和方法,包括隐马尔科夫模型、图形模型、深度度量学习、CNN、Transformer等。此外,作者强调了本研究工作的创新之处,即提出了一个统一的预训练-微调框架,可以整合各种异质数据资源,并在各种下游任务中表现出通用性。
-
人体运动表示学习的关键是从大量数据中学习有关人体动作的信息,然后将这些信息应用于各种任务中。通过利用深度学习的技术,研究者可以创建复杂的模型来理解和预测人体运动。
-
3D人体姿态估计是从2D图像或视频中恢复3D人体姿态的任务。有两种主要的方法:直接从图像中估计3D姿态,或者先提取2D姿态,然后将其提升到3D。这个领域的一个关键挑战是如何平衡3D姿态的精确性和模型对不同人体形态和姿势的处理能力。
-
基于骨架的行为识别是根据人的姿态或运动来
识别其正在进行的行为的任务。这个任务的难点在于要理解人体关节之间的复杂时空关系。
-
人体网格恢复则是根据2D图像或视频恢复出3D人体模型的任务。这需要处理诸如时间连续性和模型泛化能力等问题。
-
提出的DSTformer是基于Transformer的新模型,用于理解和建模人体运动,旨在解决以上领域的问题。
3.方法
3.1概述
如第一部分所讨论的,我们的方法由两个阶段组成,即统一预训练和任务特定的微调。在第一阶段,我们训练一个动作编码器来完成2D到3D的任务,我们使用所提出的双流空间时间转换器(DSTformer)作为主干网络。在第二阶段,我们对预训练的动作编码器和一些新的层进行微调以适应下游任务。我们在预训练和微调阶段都使用2D骨骼序列作为输入,因为它们可以从各种运动源中可靠地提取出来,并且对变化更加稳健。已有的研究已经展示了使用2D骨骼序列处理不同下游任务的有效性。我们将首先介绍DSTformer的架构,然后详细描述训练方案。

3.2网络架构
上图显示了2D到3D转换的网络架构。给定一个输入2D骨骼序列,我们首先将其投影到一个高维特征,然后添加可学习的空间位置编码和时间位置编码。然后我们使用序列到序列模型DSTformer计算特征,其中N是网络深度。我们使用带有tanh激活函数的线性层来计算动作表示。最后,我们对动作表示进行线性变换来估计3D动作。这里,T表示序列长度,J表示身体关节的数量。Cin、Cf、Ce、Cout分别表示输入、特征、嵌入和输出的通道数量。我们首先介绍DSTformer的基本构建块,即带有多头自注意力(MHSA)的空间和时间块,然后解释DSTformer架构设计。
空间块
空间多头自注意力(S-MHSA)旨在模拟同一时间步内关节之间的关系。我们使用自注意力来获取每个head的查询、键和值。
时间块
时间多头自注意力(T-MHSA)旨在模拟一个身体关节在时间步中的关系。它的计算过程与S-MHSA相似,只是MHSA应用于每个关节的时间特征,并在空间维度上并行化。
双流空间时间转换器
给定捕获帧内和帧间身体关节交互的空间和时间MHSA,我们组装基本构建块以在流中融合空间和时间信息。我们设计了一个双流架构,基于以下假设:1)两个流应该能够模拟全面的时空上下文。2)每个流应该专门处理不同的时空方面。3)两个流应该被融合在一起,融合权重应根据输入的时空特性动态平衡。因此,我们以不同的顺序堆叠空间和时间MHSA块,形成两个并行的计算分支。两个分支的输出特征使用由注意力回归器预测的自适应权重进行融合。然后重复N次双流融合模块。

3.3. 统一预训练
我们在设计统一预训练框架时,主要解决两个关键挑战:1) 如何通过通用的预训练任务学习强大的运动表示。2) 如何利用各种格式的大规模但异构的人体运动数据。
对于第一个挑战,我们借鉴了语言[12, 29, 88]和视觉[7, 35]建模的成功实践,来构建监督信号,即遮蔽部分输入,并使用编码的表示来重建整个输入。需要注意的是,这种**“填空”任务在人体运动分析中自然存在,即从2D视觉观察中恢复丢失的深度信息,也就是3D人体姿态估计**。受此启发,我们利用大规模的3D动捕数据[74],并设计了一个2D到3D提升的预训练任务。我们首先通过正交投影3D运动来提取2D骨骼序列。然后,我们通过随机遮蔽和添加噪声来破坏,从而产生被破坏的2D骨骼序列,这些序列也类似于2D检测结果,因为它包含遮挡、检测失败和错误。对关节级和帧级的遮罩应用特定的概率。我们使用上述的运动编码器获取运动表示E并重建3D运动。然后,我们计算?和GT 3D运动?之间的关节损失L3D。我们还加入了速度损失LO,这是遵循之前的工作[87, 132]。3D重建损失因此由原论文内容给出。
对于第二个挑战,我们注意到2D骨骼可以作为一种通用媒介,因为它们可以从各种运动数据源中提取出来。我们进一步将户外RGB视频纳入2D到3D提升框架进行统一预训练。对于RGB视频,2D骨骼?可以通过手动注释[3]或2D姿态估计器[14, 101]给出,而提取的2D骨骼的深度通道本质上是“被遮蔽的”。同样,我们添加额外的遮罩和噪声来降级?(如果?已经包含检测噪声,只应用遮罩)。由于这些数据没有可用的3D运动GT?,我们应用一个加权的2D重投影损失,该损失由?计算。
其中,?是估计的3D运动?的2D正交投影,而δ ∈ RT×J是由可视性注释或2D检测置信度给出。
总的预训练损失由公式?计算。
3.4. 任务特定的微调
所学习的特征嵌入E充当了对3D和时间感知的人体运动表示。对于下游任务,我们采用了极简的设计原则,即实现一个浅层的下游网络,并且无需任何附加的复杂性进行训练。在实践中,我们使用了额外的线性层或一个包含一个隐藏层的MLP。然后,我们对整个网络进行端到端的微调。
3D姿态估计
由于我们使用2D到3D提升作为预训练任务,所以我们简单地重用整个预训练网络。在微调期间,输入的2D骨骼是从视频中估计出来的,没有额外的遮罩或噪声。
基于骨架的动作识别。我们直接对不同人和时间步进行全局平均池化。然后将结果输入到一个包含一个隐藏层的MLP中。网络使用交叉熵分类损失进行训练。对于单次学习,我们在池化特征后应用一个线性层来提取剪辑级动作表示。我们在第4.4节中介绍了单次学习的详细设置。
人体网格恢复
我们使用SMPL[70]模型来表示人体网格并回归其参数。SMPL模型由姿态参数θ ∈ R72和形状参数β ∈ R10组成,计算3D网格为M(θ, β) ∈ R6890×3。为了回归每一帧的姿态参数,我们将运动嵌入E输入到一个包含一个隐藏层的MLP中,得到θˆ ∈ RT×72。为了估计形状参数,考虑到视频序列中的人体形状应该是一致的,我们首先在时间维度上对E进行平均池化,然后将其输入到另一个MLP中回归一个单独的βˆ,然后将其扩展到整个序列,得到βˆ ∈ RT×10。形状MLP的结构与姿态回归的结构相同,它们分别以均值形状和姿态初始化,如[45]中所述。整体损失计算如下:
注意,运动?中的每个3D姿态在帧t由网格顶点通过?回归。
方法批注
该部分存在较多公式,Markdown重写较为麻烦,笔者以?或省略来替代,建议直接参考原论文。
概述部分描述了方法的总体设计和具体实现。首先,作者们描述了他们的两阶段方法,包括预训练阶段和微调阶段。他们使用的输入数据是2D骨骼序列,这是因为这种类型的数据能够从各种运动源中可靠地提取,并且对于变化有很好的鲁棒性。
然后,他们介绍了他们的网络架构,即DSTformer,它是一种序列到序列的模型,适用于处理时间序列数据。他们在这个网络中使用了空间和时间的多头自注意力(MHSA),以分别捕捉帧内和帧间的关节交互。
其次,他们设计了一个双流架构,它同时考虑了空间和时间的信息,并且能够动态地平衡两者的融合权重,以此来适应不同的输入特性。
统一预训练部分描述了统一预训练的方法,主要解决了两个关键问题。首先,作者们使用一个“填空”任务,这种任务在人体运动分析中是自然存在的,来学习强大的运动表示。这个任务的目标是从2D视觉观察中恢复丢失的深度信息,也就是3D人体姿态估计。其次,他们采用了一种将2D骨骼作为通用媒介的方法,从各种运动数据源中提取信息,并对2D骨骼进行预训练,这样的话,骨骼的2D到3D的转换就可以用来做统一的预训练。
任务特定的微调部分描述了任务特定的微调方法。作者们对所学习到的特征进行了微调,以适应特定的任务,如3D姿态估计,基于骨架的动作识别和人体网格恢复。为了适应这些任务,他们在预训练的网络上增加了一些简单的修改,如增加线性层或使用MLP,然后对网络进行端到端的微调。在每个任务中,他们都采用了一种适应性的方法,如在3D姿态估计中,他们简单地重用了预训练网络,在基于骨架的动作识别中,他们对不同的人和时间步进行了全局平均池化,然后将结果输入到MLP中。在人体网格恢复中,他们使用SMPL模型,并采用一种针对每一帧的姿态参数回归的方法。
4. 实验
4.1. 实现
我们使用深度N = 5,头数h = 8,特征尺寸Cf = 512,嵌入尺寸Ce = 512来实现提出的双流空间-时间Transformer(DSTformer)动作编码器。在预训练阶段,我们使用的序列长度T = 243。由于采用了基于Transformer的骨架,预训练模型可以处理不同的输入长度。在微调阶段,我们将骨架的学习率设置为新层学习率的0.1倍。我们会在接下来的部分中分别介绍实验数据集。更多的实验细节请参考补充材料。
批注
此部分描述了实验的实施细节。DSTformer是一种基于Transformer的深度学习模型,用于从数据中学习和编码人类的运动信息。其中,深度(N)表示模型的层数,头数(h)是Transformer的一个关键参数,它控制模型的并行度,特征尺寸(Cf)和嵌入尺寸(Ce)是描述输入数据和输出数据的尺寸的参数。预训练阶段的序列长度(T)指模型在一次训练中处理的连续帧的数量。
4.2. 预训练
我们从两个数据集Human3.6M [37] 和AMASS [74] 中收集了丰富并且真实的3D人体动作数据。Human3.6M [37] 是一个常用的室内3D人体姿态估计数据集,包含了360万视频帧,视频中的专业演员们在进行日常行动。参照之前的工作 [76, 87],我们使用1、5、6、7、8号被试进行训练,使用9、11号被试进行测试。AMASS [74] 集成了大部分现有的基于标记的运动捕捉(Mocap)数据集 [1,2,5,11,15,18,33,36,51,68,71,75,82,95,108,109],并使用了统一的表示方法。在预训练阶段,我们并未使用两个数据集的图像或2D检测结果,因为Mocap数据集通常不提供原始视频。相反,我们使用正交投影获取未被污染的2D骨架。我们还结合了两个野外RGB视频数据集PoseTrack [3](已注释)和InstaVariety [41](未注释)以提高运动的多样性。我们将人体关键点的定义与Human3.6M对齐,并根据 [27] 将摄像机坐标校准到像素坐标。我们随机零化15%的关节,并从高斯和均匀分布的混合中 [17] 抽样噪声。我们首先只在3D数据上进行30个epoch的训练,然后在3D数据和2D数据上进行60个epoch的训练,这遵循了课程学习的做法 [9, 116]。
批注
在预训练阶段,研究人员使用两个不同的数据集:Human3.6M和AMASS,这两个数据集都包含了大量的3D人体动作数据。他们还引入了两个野外的RGB视频数据集PoseTrack和InstaVariety,以增加训练数据的多样性。为了处理数据集的不同,研究人员将数据集中的关键点定义进行了统一,并且将摄像机坐标校准为像素坐标。此外,他们在训练中引入了噪声和随机失活,这是为了使模型更鲁棒。
4.3. 3D姿态估计
我们在Human3.6M [37] 上评估3D姿态估计的性能,并报告每个关节位置的平均误差(MPJPE)(单位为毫米),该误差度量了在对齐根关节后,预测关节位置和真值之间的平均距离。我们使用堆叠的Hourglass(SH)网络 [84] 从视频中提取2D骨架,并在Human3.6M [37] 训练集上微调整个网络。此外,我们训练了另一个相同结构的模型,但是没有预训练权重,而是随机初始化。如表1(顶部)所示,从零开始训练的模型超越了之前的方法,包括其他采用空间-时间建模的基于Transformer的设计。这显示了我们提出的DSTformer在学习3D几何结构和时间动态方面的有效性。为了进一步评估模型的上限性能,我们比较了使用2D GT姿态序列作为输入时的性能,这消除了不同2D探测器的影响。如表1(底部)所示,我们的模型显著优于所有先前的方法。我们将我们从零开始的模型的性能优势归因于提出的DSTformer设计。我们在第4.6节和补充材料中提供了更多的比较和分析,以展示DSTformer在其他空间-时间架构方面的优势。此外,我们的方法通过提出的预训练阶段达到了更低的误差
。
批注
在3D姿态估计的实验中,研究人员使用了平均每个关节位置误差(MPJPE)这一指标来度量模型的性能。他们比较了模型在使用预训练权重和从零开始训练时的性能,结果表明,使用DSTformer从零开始训练的模型在这个任务上的性能优于其他方法。此外,当输入数据为2D的真实姿态序列时,他们的模型也超过了所有先前的方法,这进一步证明了DSTformer的优越性。
4.4. 基于骨架的动作识别
我们进一步探索了用预训练的人体运动表示学习动作语义的可能性。我们使用了NTU-RGB+D人体动作数据集,它包含了60个动作类别的57K个视频,我们按照数据集的交叉主题(X-Sub)和交叉视图(X-View)划分。此数据集还有一个扩展版本,NTU-RGB+D-120,包含了120个动作类别的114K个视频。我们按照建议的单次动作识别协议在NTU-RGB+D-120上进行操作。对于这两个数据集,我们都使用HRNet来提取2D骨架。同样,我们训练了一个随机初始化的模型以供比较。如表2(左)所示,我们的方法在和最先进方法的比较中表现得相当好或者更好。值得注意的是,预训练阶段对于性能的提升起到了很大的作用。
此外,我们深入探讨了在单次设定中的应用,这对于实际应用非常重要。实际应用往往需要在特定领域如教育、体育和医疗中进行精细的动作识别。然而,这些场景中的动作类别通常不在公开数据集中定义。因此,只有这些新动作类别的有限注释可用,使得准确识别变得具有挑战性。我们在评估集上对20个新类别,每个类别只有1个标记视频的结果进行报告。辅助集包含了其他100个类别,这些类别的所有样本都可以使用。我们利用监督对比学习技术在辅助集上训练模型。对于一批辅助数据,同类别的样本在动作嵌入空间中被拉近,而不同类别的样本被推远。在评估期间,我们计算测试样本和示例之间的余弦距离,并使用1-最近邻来确定类别。表2(右)显示,我们提出的模型在比较中显著优于最先进的方法。此外,值得注意的是,我们的预训练模型在经过1-2轮微调后就达到了最优性能。我们的结果表明,预训练阶段在学习一种对新的下游任务具有很好泛化能力的强健的运动表示方面是有效的,即使在数据注释有限的情况下也是如此。
批注
这个小节主要探讨了利用预训练的人体运动表示进行动作识别的可能性,并使用了NTU-RGB+D数据集进行验证。这个数据集是一个用于动作识别的大型数据集,包含了丰富的动作类别和视频。作者们发现,预训练的人体运动表示模型在动作识别任务上有很好的性能,甚至在有限的数据注释下也表现出了强大的泛化能力。
4.5. 人体网格恢复
我们在Human3.6M和3DPW数据集上进行实验,并在训练期间加入了COCO数据集。我们按照以前的做法,保持了两个数据集的训练和测试划分。我们按照公共实践报告了14个通过JM(θ, β)获得的关节的MPJPE(毫米)和PA-MPJPE(毫米)。PA-MPJPE在翻译、旋转和比例对齐后计算MPJPE。我们进一步报告了由M(θ, β)生成的网格的平均每顶点误差(MPVE)(毫米),这度量了在对齐根关节后,估计的顶点和GT顶点之间的平均距离。值得注意的是,大多数先前的作品在训练期间使用了除COCO之外的更多数据集,如LSP,MPI-INF3DHP等,而我们没有。表3证明了我们的微调模型在Human3.6M和3DPW数据集上都提供了有竞争力的结果,超过了所有最先进的基于视频的方法,包括MAED,特别是在MPVE误差上。然而,我们注意到,仅从稀疏的2D关键点估计全身网格是一个病态问题,因为它缺乏人体形状信息。考虑到这一点,我们提出了一种混合方法,利用了我们的框架(连贯运动)和基于RGB的方法(精确形状)的优势。我们引入了一个可以轻易与现有的基于图像/视频的方法结合的细化模块,类似于以前的工作。具体来说,我们的细化模块是一个MLP,它接收我们预训练的运动表示和初始预测的组合,回归关节旋转的残差。我们的方法有效地改进了最先进的方法,并达到了迄今为止的最低误差。
批注
这一节主要介绍了在人体网格恢复任务上的实验情况。人体网格恢复是一个3D任务,它需要从2D图片中估计出3D的人体姿态。
在这项任务上,预训练的人体运动表示模型同样展现出了很好的性能。然而,由于只从稀疏的2D关键点中估计全身网格是一个非常困难的问题,因此作者们采取了一种混合方法,结合了预训练的人体运动表示和基于RGB的方法,进一步改善了人体网格恢复的结果。
4.6. 消融研究
微调vs.从头开始
我们比较了使用预训练模型进行微调和从头开始训练的训练进度。如图3所示,用预训练权重初始化的模型在所有三个任务上展示出了优越的性能和更快的收敛速度。这项观察表明预训练模型学习了关于人类运动的可转移知识,有助于学习多个下游任务。
局部微调
除了端到端的微调,我们冻结了运动编码器主干,仅对每个下游任务的回归头进行训练。为了验证预训练运动表示的有效性,我们将预训练运动编码器与随机初始化的运动编码器进行比较。我们在Human3.6M上报告了3D姿态和网格的结果,在NTU-RGB+D和NTU RGB+D-120上报告了动作的结果(表格以下也是如此)。从表4可以看出,基于冻结的预训练运动表示,我们的方法仍然在多个下游任务上实现了竞争性能,并且与基线相比有大幅度的提升。预训练和部分微调使得所有的下游任务都能共享同样的主干,显著减少了对多任务推理应用的计算负担。
预训练策略
我们评估了不同预训练策略如何影响下游任务的性能。从零开始的基线,我们逐一应用了所提出的策略。如表5所示,一个基本的2D到3D的预训练阶段对所有的下游任务都有益。引入损坏进一步提高了学习到的运动嵌入。用在野外视频(w. 2D)统一预训练享有更高的运动多样性,这进一步帮助了几个下游任务。
用不同的主干预训练。我们进一步研究了所提出的预训练方法的通用性。我们用两个变体:TCN [87]和PoseFormer [133]来替换运动编码器的主干。模型稍作修改为seq2seq版本,所有的预训练和微调配置都简单地遵循了。表6显示了所提出的方法如何在不同任务上对不同的主干模型产生一致的益处。
模型架构
最后,我们研究了DSTformer的设计选择。从表8的(a)到(f),我们比较了基本变压器模块的不同结构设计。 (a)和(b)是不同顺序的单流版本。 (a)在概念上类似于PoseFormer [133],MH Former [55]和MixSTE [132]。 (c)在融合前将每个流限制为时间或空间建模,类似于MAED [112]。 (d)直接连接S-MHSA和T-MHSA,中间没有MLP,类似于MAED [112]中的MSA-T变体。 (e)将两个流上的自适应融合替换为平均池化。 (f)是我们提出的DSTformer设计。结果统计证实了我们的设计原则,即两个流都应该有能力并且同时具有互补性,如第3.2节所介绍的。此外,我们发现将每个自注意力块与MLP配对是至关重要的,因为它可以投射学习到的特征交互并带来非线性。总的来说,我们为3D姿态估计任务设计了模型架构,并将其应用到所有其他任务,无需额外的调整。
5. 结论和讨论
在这项工作中,我们提供了一个统一的视角来解决各种人类中心的视频任务。我们开发了一种从大规模和异构数据源学习人类运动表示的预训练方法。我们还提出了DSTformer作为一个通用的人类运动编码器。在多个基准测试上的实验结果证明了学习到的运动表示的多功能性。到目前为止,这项工作主要集中在处理单个人的骨骼数据。未来的工作可以探索将学习到的运动表示与通用视频架构融合为人类中心的语义特征,将其应用到更多的任务(例如,动作评估,分割),并显式地建模人类交互。
批注
这篇论文的主要贡献是提出了一个统一的视角来解决各种以人为中心的视频任务。作者们首先通过预训练阶段训练一个运动编码器,从而从大量和混合的数据资源中学习人类运动的表征。然后,他们通过微调预训练的运动编码器来完成多个下游任务。消融研究表明,相比于从零开始训练,预训练模型在性能和收敛速度上都有显著优势,证明了其学习的运动表示具有可转移性。此外,该预训练策略的有效性不受运动编码器主干的影响,证明了其具有通用性。在模型架构方面,作者提出了DSTformer,一种新的网络结构,有效地学习并表达了骨骼关节间的时空关系。未来的工作将进一步探索该运动表示的更多应用。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 14
14 1
1- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)