常用MII接口详解
MII接口作为板内走线的接口,达到25MHz速率还是比较简单的,制约以太网传输跑10M的原因为网线质量、传输长度等限制。以BCM5241 PHY为例,这就是一个百兆PHY,在DS文档中可以看到pin信号定义。因为RX部分信号要兼做配置信号,一开始可能注意不到,但TX部分信号很明显,除了PHY时钟是输出,其它TX信号是输入。细看RX部分信号,时钟为输出,其它RX信号也为输出。为什么这里TX会是输入,
开放式系统互连 (OSI) 模型

以太网层 位于最底部两层 ,物理层(physical)和数据链路层(Date link)。
从百兆以太网接口开始
首先是百兆以太网规定的两种接口
介质无关接口 (MII) Media Independent Interface
介质相关接口 (MDI) Medium Dependent Interface
介质在这里可以理解为接口传输的介质,比如光纤、网线、铜缆等。
介质无关接口,应用在MAC到PHY的连接之间,与PHY的最终接口无关。虽然MII没有说明是什么速率,但是在100M时制定的标准,就代表是速率为100Mbit/s。
MII 接口主要包括四个部分,本文主要讲解其中第一、二部分。
一是从 MAC 层到 PHY 层的发送数据接口;
二是从 PHY 层到 MAC 层的接收数据接口;
三是从PHY 层到 MAC 层的状态指示信号;
四是 MAC 层和 PHY 层之间传送控制、状态信息的SMI(MDC/MDIO)接口。
一、MII接口
MII接口信号, 根据MAC端定义:
- 发送端 :TX_CLK, TX_D[0-3], TX_EN, TX_ER , TXER 为选配。
- 接收端:RX_CLK, RX_D[0-3], RX_DV, RX_ER, CRS, COL
MII接口的数据速率可达100Mbps, 其时钟频25MHz ,单向数据位宽4bits。
25MHz * 4 = 100Mbit/s,2.5MHz * 4 = 10Mbit/s

图1、 MII信号方向
TX_D发送和RX_D接收数据线均为4条。
发送TX_CLK和接收RX_CLK各配置有1个时钟,注意发送和接收时钟均为PHY提供。
控制信号有RX_ER、RX_DV,TX_ER、TX_EN。
25MHz这个时序裕量是很大的,所以MAC发送数据的时钟由PHY提供并不会产生问题。
表1 MII接口信号, 信号方向针对PHY,信号命令针对MAC。
| 信号 | 方向 | 位宽 | 含义 |
| RX_CLK | O | 1 | 发送时钟,PHY芯片产生,100Mbps时为25MHz,10Mbps时为 2.5MHz。 |
| RX_DV | O | 1 | 高电平表示发送的数据有效。 |
| RX_ER | O | 1 | 高电平表示发送数据的错误,接收端不接受该数据。 |
| RX_D | O | 4 | 发送数据总线。 |
| TX_CLK | O | 1 | 接收时钟,PHY芯片产生,频率与RX_CLK一致。 |
| TX_EN | I | 1 | 高电平表示接收的数据有效。 |
| TX_ER | I | 1 | 高电平表示接收的数据包有误,丢弃该数据包。 |
| TX_D | I | 4 | 接收数据总线。 |
| CRS | O | 1 | 载波侦测信号,不需要同步于参考时钟,有数据传输,CRS就有效,仅PHY在半双工模式下有效。 |
| COL | O | 1 | 冲突检测信号,不需要同步于参考时钟,仅PHY在半双工模式下有效。 |
PHY芯片向MAC传输数据时序
PHY芯片在RX_CLK下降沿输出数据RX_DATA,两个时钟发送一字节数据,先发送低四位数据,后发送高四位数据,发送数据时RX_DV信号拉高。MAC侧在时钟上升沿采集RX_DV和RX_DATA状态。

图、 MAC侧接收数据时序
MAC侧发数据给PHY芯片的时序
下降沿输出数据,方便接收端在上升沿对数据进行采样。

图、 MAC侧发送数据时序
MII接口发送、接收的数据线均为4位,则每个时钟周期发送或接收4位数据。
为什么是以100M以太网为标准向下兼容10M,而不是由10M向上升级到100M?
MII接口作为板内走线的接口,达到25MHz速率还是比较简单的,制约以太网传输跑10M的原因为网线质量、传输长度等限制。
以BCM5241 PHY为例,这就是一个百兆PHY,在DS文档中可以看到pin信号定义。


因为RX部分信号要兼做配置信号,一开始可能注意不到,但TX部分信号很明显,除了PHY时钟是输出,其它TX信号是输入。细看RX部分信号,时钟为输出,其它RX信号也为输出。
为什么这里TX会是输入,RX会是输出?因为MII接口定义的TX、RX是以MAC角度来的。
MII的数据线还是比较多的,数据地址时钟加起来就有14根。可以设想一下,在一个所有100M端口都需要连接外部PHY的交换芯片上,32个端口就需要448根信号线。减少信号连接是非常实际的需求。RMII接口应运而生。
二、RMII接口
RMII(Reduced Media Independent Interface)接口其实就是MII接口的简化版本。
RMII接口的数据速率可达100Mbps, 其时钟频50MHz ,单向数据位宽2bits。
50M * 2 = 100Mbit/s , 5MHz* 2 = 10Mbit/s
相比于MII接口,RMII有以下四处变化:
-
TX_CLK 和 RX_CLK 两个时钟信号,合并为一个双向时钟 REF_CLK,由外部的晶振同时给PHY芯片和MAC主控芯片提供时钟信号
-
TX_D和RX_D数据位宽减少到2bit
-
时钟速率由 25MHz 上升到 50MHz,TX_D和RX_D由 4 bits 变为 2 bits
-
CRS 和 RXDV 合并为一个信号 CRSDV
-
取消了 COL 、TX_ER、
RMII信号如下图所示。RMII只要 9 根信号线,相比于MII的 18 根信号可谓有不少的删减。

REF_CLK是指由外部的晶振同时给PHY芯片和MAC主控芯片提供时钟信号,而不是说这个信号是双向的。
表2 RMII接口信号, 信号方向针对PHY,信号命令针对MAC
| 信号 | 方向 | 位宽 | 含义 |
| REF_CLK | I | 1 | 参考时钟,外部晶振产生,100Mbps时为50MHz,10Mbps时为5MHz。 |
| CRS_DV | O | 1 | 高电平表示发送的数据有效。 |
| RX_ER | O | 1 | 高电平表示发送数据的错误,接收端不接受该数据。 |
| RX_D | O | 2 | 发送数据总线。 |
| TX_EN | I | 1 | 高电平表示接收的数据有效。 |
| TX_D | I | 2 | 接收数据总线。 |
注意,如果时钟是由外部晶振提供的,很明显,晶振不可能根据情况自动输出50Mhz、5MHz,明显这个时候是不能100M、10M切换的。如果是需要自适应10/100M,TX_CLK是由PHY芯片发出。
RMII接口时序与MII完全一致,所以不再赘述。
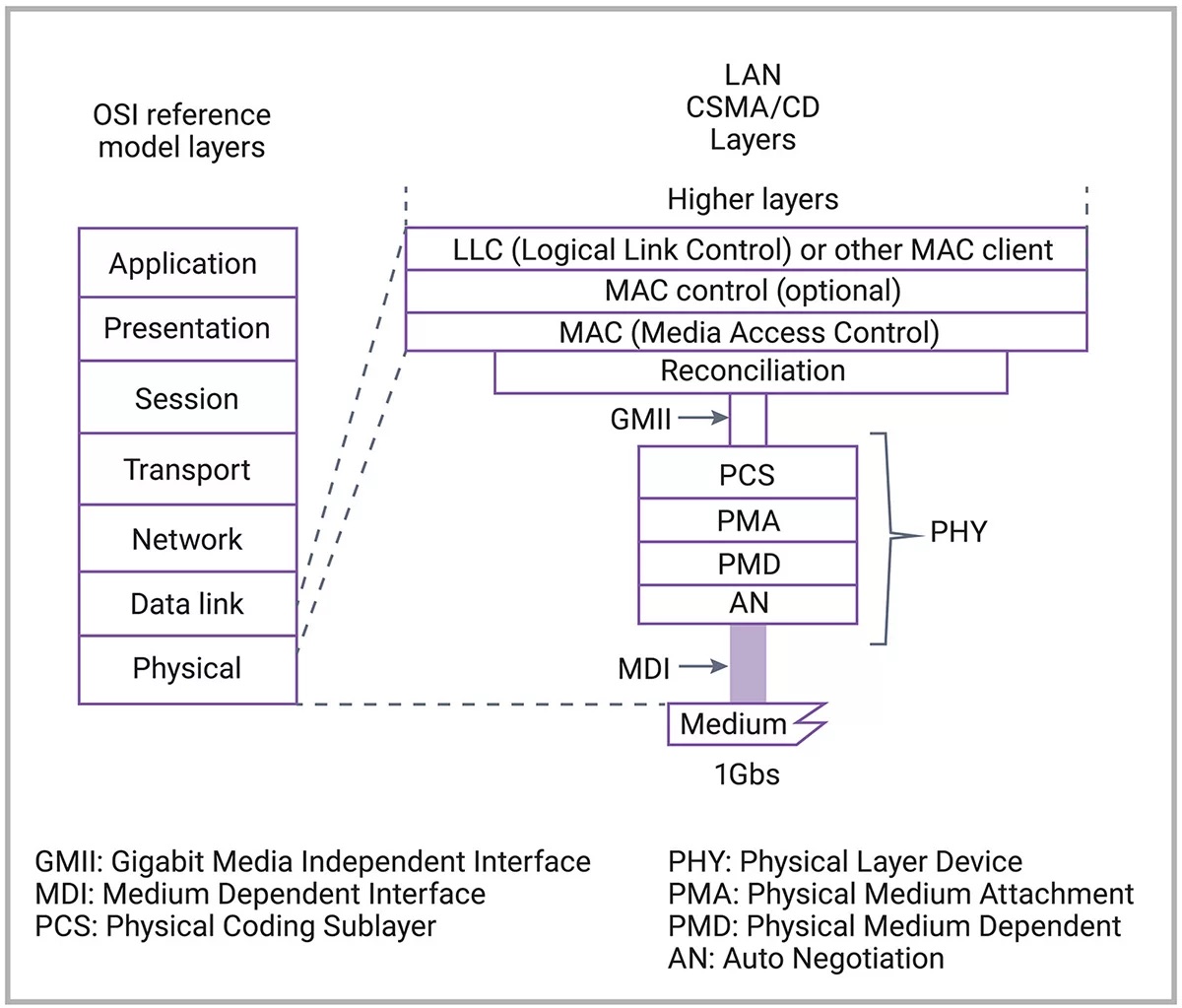
千兆以太网
一、GMII接口
GMII(Gigabit Medium Independent):千兆以太网。在MII前面加了一个代表千兆的G表示千兆以太网的MII接口。
GMII接口其时钟频率为 125MHz ,单向数据位宽 8 bits。GMII向下兼容MII,工作在 100Mbps 和 10Mbps 的数据速率采用降位宽。
125M * 8 = 1000Mbit/s, 25MHz* 4 = 100Mbit/s,2.5MHz * 4 = 10Mbit/s。
GMII接口信号,根据MAC端定义:
- 发送端信号:GTXCLK, (TXCLK), TXD[0-7], TXEN, TXER
- 接收端信号:RXCLK, RXD[0-7], RXDV, RXER, CRS, COL

举例:
从支持GMII接口的BCM53457芯片的DataSheet手册中相关信号定义

收发数据线都是8-bit,控制信号与MII接口时一致。这个是交换芯片的MAC侧,所以TX为发送,RX为接收。
注意可以看到GMII的TX发送端有两个时钟, GTXCLK 和 TXCLK 。在实际应用中,绝大多数GMII接口都是兼容MII接口的,所以,一般的GMII接口都有两个发送参考时钟:TX_CLK和GTX_CLK(两者的方向是不一样的),在用作MII模式时,使用TX_CLK和8根数据线中的4根。
首先GTXCLK,顾名思义就是只在1000M模式下的时钟,改为由MAC输出,所以加了G字母区别于TXCLK,而RXCLK没有这个问题。
GTXCLK1000M模式下使用,原因可能在于1000M时时序裕量明显小于100M时,要MAC发送端根据接收端发过来的时钟触发数据发送由接收端采样难度太大,改为发送时钟也由发送端提供就是一个标准的源同步时钟接口。
但是,当100M、10M模式时,并不是将GTXCLK降低到12.5M、1.25M来实现,这样就没办法兼容之前的100M PHY。因为MII接口上,TXCLK是由PHY提供的,所以也不可能用GTXCLK时钟,而是另外有一个TXCLK时钟。所以100M、10M模式时,TX_CLK提供25M、2.5M,数据线实际都只有低4-bit会工作。要实现1000Mb/s、100Mb/S、10Mb/S自适应,信号连接时必须加上TX_CLK(PHY输出)。
故GMII有3个时钟, Gtx_clk,Rx_clk ,Tx_clk。
1) GTX_CLK仅使用在GMII模式下,时钟频率为125M,发送数据时的时钟。
当工作于1000Mbps 模式时,TXD, TXEN, TXER 是与 GTXCLK (125MHz)同步的,
2) TX_CLK仅使用在MII模式下,发送数据时的时钟。
当工作 10/100Mbps 模式时,数据信号是同步于由PHY提供的TXCLK 的,其中 100Mbps 时是 25MHz,10Mbps 时是 2.5MHz。
3) RX_CLK在GMII和MII模式下均可使用,接收数据的时钟。
PHY发送数据给MAC的时序
与MII接口一样,PHY芯片在RX_CLK下降沿输出数据,MAC在上升沿采集数据,但是GMII接口每个时钟周期传输一字节数据。

MAC发送数据到PHY的时序
在下降沿输出一字节数据即可。

GMII信号线数量又比MII有了明显上升,减少信号连接的需求更为迫切。于是对应RMII的RGMII接口出现。
二、RGMII接口
RGMII(Reduced Gigabit Media Independent Interface)接口就是把GMII接口的数据线做简化处理,也能够实现千兆网。RGMII v1.3 采用 2.5V CMOS 电平,RGMII v2 采用 1.5V HSTL 电平。
在RGMII接口中,其时钟频率为 125MHz ,单向数据位宽 4 bits。
- 1000Mbps 模式,数据在时钟的上/下边沿均采样
- 10/100Mbps 模式,数据仅在时钟上升沿采样
125M * 4 * 2= 1000Mbit/s, 25MHz* 4 = 100Mbit/s,2.5MHz * 4 = 10Mbit/s。
RGMII相比于GMII减小将近一半的管脚数(24 → 12),通过以下两种方式:
- 1000Mbps模式下,在时钟的上/下边沿均采样数据(DDR)
- TX_D和RX_D数据位宽减少到4bit
- 取消不重要的CRS、COL 、TX_EN、TX_ER、RX_ER、RX_DV
- 取消GTXCLK,改为MAC发送TX_CLK、PHY发送RX_CLK
- 增加TX_CTL,RX_CTL

在RGMII接口中 MAC 在 TX_CLK上一直提供时钟信号,而不像在GMII接口中那样,10/100Mbps 模式下时钟是由 PHY 提供(TXCLK),而 1000Mbps 模式下时钟是由 MAC 提供(GTXCLK)。
在RGMII中应用到源同步时钟,即数据与时钟信号是同步的。这要求在PCB设计中,要对时钟信号额外增加 1.5~2 ns 的延迟以保证接收端的建立/保持时间满足要求。在 RGMII v2.0 规范中有定义MAC/PHY内部延迟(RGMII-ID),由此避免PCB设计中再要增加这个延迟。
RXCTL 和 TXCTL 为复用的传输控制信号。RXCTL 在时钟的上升沿代表 RXDV,在时钟的下降沿代表(RXDV xor RXER);TXCTL 在时钟的上升沿代表 TXEN,在时钟的下降沿代表(TXEN xor TXER)。
数据信号每方向由8-bit降到4-bit,控制信号每方向由2-bit降到1-bit。那么时钟信号是不是像RMII由25MHz提高到50MHz那样,由125Mhz提高到250MHz呢?
不是,原因可能是对于当时的硬件设计来说,250MHz单端信号难度还是大。所以RGMII使用了Double Date Rate技术,也就是DDR,双边沿采样。使用125MHz时钟的上升沿和下降沿各采一次,在4-bit数据线下实现了1000Mbit/s的传输。
既然是双边沿采样,MII、GMII的下降沿发出数据、上升沿采样的方式就不能用了。
MAC的发送数据到PHY时序
MAC侧在时钟TX_CLK的上升沿将需要发送数据的低4位输出到数据线TXD,在时钟TX_CLK下降沿将传输数据的高4位输出到数据线TXD。因此每个时钟传输1字节数据,125MHz的时钟就能实现1000Mbps速率。

注意TX_CTL信号,该信号将TX_EN和TX_ER结合,在TX_CLK上升沿,TX_CTL输出TX_EN的状态,高电平表示数据有效,在TX_CLK下降沿,此时输出TX_EN异或TX_ER的结果,所以只有当TX_CTL在TX_CLK上升沿和下降沿同时为高电平时数据才是有效的。
MAC的接收PHY的时序

MAC侧不能直接将TX_CLK输出给PHY芯片使用,因为TX_CLK的上升沿和下降沿对应的TXD信号都处于变化阶段,此时采集数据可能会出错,TX_CLK周期为8ns,将TX_CLK延迟xns后输出给PHY芯片作为TX_CLK,延迟后的信号上升沿和下降沿对应的TXD就是稳定的,此时就可以稳定采集数据。
上升沿输出上升沿采样,下降沿输出下降沿采样,接收端的的数据建立时间怎么来?在没有delay技术出来的时候,只能靠外部走线绕线来实现,TX_CLK靠绕线到达接收端的时机要比数据慢,此时数据在接收端已稳定建立好,可以保证采样正确。
参考RGMII BCM54616手册中的Normal模式建立时间1ns的要求,差不多就是5600mil,15cm左右。在调试FT2000A RGMII接口连接BCM54616时,RGMII不通,delay模式搞不清的情况下,将TXCLK增加了一段15cm的飞线,RGMII正常。通过绕线来降低信号数量,代价还是太大,所以Delay技术应用在了RGMII接口上。
Delay技术,简单来说,比如MAC在发送数据时,内部TXCLK上升沿触发数据发送,但此时时钟并不是也同时发送到信号线上,而是经过一个PLL延时电路延时了1ns在放到信号线上,相当于就起到了绕线的作用。接收方向的Delay则是,当时钟和数据同时到达后,不直接用时钟的边沿采样,而是delay之后再采,保证数据的准确性。
这样就极大方便了RGMII的PCB布线,只要考虑一个方向内时钟和数据线的等长就可以了。
RGMII的两侧,MAC和PHY,每一方的发送和接收都可以加入delay技术,设计时就要注意,一方delay就可以了。有时候还会有比如MAC只能做发送delay,不具备接收delay能力的情况,一定要根据具体情况来设计。
从支持RGMII接口的BCM54616芯片的DataSheet手册相关信号定义

因为是PHY侧,TX为接收,RX为发送。在设置PHY侧的Delay也要注意,既然PHY侧的TX为接收,RX为发送。所以PHY的TX delay实际是指MAC发送、PHY接收这一路的Delay,RX delay是指MAC接收、PHY发送这一路的Delay。
RGMII作为信号减少的接口,尽管12根信号线确实不多,但实际使用中还是觉得使用不便,多端口时布线繁琐。所以现在最常见的千兆MII接口是SGMII。
在说SGMII之前先说了1000Base-X,是因为SGMII和1000 Base-X是脱不开的关系的,从PHY芯片的1000Base-X接口就是SGMII接口就能看出来。
xGMII是IEEE定的标准,SGMII是思科定的标准(1999年10月出的第一版规范),本质上来说,SGMII就是将1000base-X(802.3zclause36 1998年出的规范)的PCS层(8B/10B编码,码组对齐同步和1000base-X物理层pcs编码一样,但自协商功能有差异)和PMA层(串并转换,时钟恢复,早期定义的SGMII规范没有CDR)拿过来用。
实际上SGMII接口就带有1000base-X的特征,1000base-X不需要控制信号,SGMII也就不需要,这个信号在1000base-X的PCS层里就处理好了,不用发送出去。
RGMII的信号数量仍然不少,于是为了更方便快捷的连接千兆以太网的MAC和PHY,采用serdes技术的SGMII:Serial GMII诞生了。
三、SGMII接口
SGMII发送、接收各1对差分对,在时钟信号的上升沿和下降沿均采样(DDR 模式), 发送和接收时钟频率均为 625MHz , 差分对为1.25Gbit/s速率。
采用8b/10b编码方式,在TXD发送的串行数据中,每8比特数据会插入TX_EN/TX_ER 两比特控制信息,同样,在RXD接收数据中,每8比特数据会插入RX_DV/RX_ER 两比特控制信息。
625Mbps * 2 * 1 = 1.25Gbps,1.25Gbps * 80% = 1Gbps
SGMII发送和接受数据各 1 对差分信号(LVDS),有 1 对差分时钟,共 6 根线。对于 MAC/PHY 中包括时钟恢复电路(CDR)系统,TXCLK 可以省略,SGMII接口只需要 4 根线。

但是SGMII规范还设计有随路时钟, 这是因为早期为了节省成本,芯片内没有CDR。现在的芯片基本都可以通过接收端CDR做时钟恢复,进一步减少时钟引脚和时钟与数据之间的skew,也减少了信号pin数量。
SGMII很容易理解成将GMII的并行数据通过串并转换后发送出去,8-bit数据,2-bit控制,刚好满足1.25Gbit/s的实际速率。但是实际并不是这样理解,而是125MHz参考时钟通过PLL进行5倍倍频后,625MHz时钟嵌在数据里,采用DDR模式,故625Mbps * 2 = 1.25Gbps。
SGMII在跑100M速率时,并不是降速到125M,这种速率下无法避免长0或长1的问题,Serdes在这个速率跑不起来。所以实际SGMII跑100M时也是1.25Gbit/s速率,就是把1分数据重复发了10次。1000 BASE-X跑百兆光模块时实际也是这么运行的。
1000base-X为什么要做8b/10b编码,原因就是serdes码流中不能有长时间0或长时间1的情况,长0或长1时接收端不能正确地采样信号,另外还会由于单极性码含有直流分量,这种直流成分会随数据中1和0的随机变化也呈现随机性,这会引起接收端的基线漂移导致接收端误判。
SGMII如果不做8B/10B编码,serdes传输是不能成立的,所以SGMII的1.25Gbit/s速率也是因为8B/10B编码。那么2-bit的控制信号是加扰二进制码,将8bit编码成10bit后,连续的1或者0不能超过5位。
四、QSGMII接口
QSGMII的Q为Quad,4的意思。就是4组SGMII信号放在一组serdes信号上,工作在 DDR 模式,采用8B/10B编码方式,只有1个差分对速率为5Gbps,时钟频率是5Gbps / 2 = 2.5GHz。
2.5GHz * 2 * 1 = 5Gbps,5Gbps * 80% = 4 Gbps
用字节交织的方式发送,即MAC0字节,MAC1字节,MAC2字节,MAC3字节组在一起。QSGMII在MAC端需要占用4个MAC。

以RTL8218D_PHY的DS手册来看
是PHY侧,TX为接收,RX为发送。引脚定义的TX、RX是以MAC端来命令的

-
万兆以太网
有了前面的基础,万兆以太网就比较好理解了。
一、XGMII接口
XGMII是10 Gigabit Media Independent Interface 是“10Gb介质无关接口”,X对应罗马数字10。XGMII 是10G以太网的MAC与PHY设备间通信的接口标准,时钟频率 156.25 MHz ,工作在 DDR 模式。
- 156.25 MHz * 32 bits * 2 = 10 Gbps
根据MAC端定义 :
- 发送端:TXD[31:0],TXC[3:0],TX_CLK
- 接收端:RXD[31:0],RXC[3:0],RX_CLK
图 RXD/TXD 信号表示 32 bits 数据 + 4 bits 控制信号,其中每 8 bits 数据称为 1 个Lane,共用 1 路控制信号。

参考XLR732 CPU上XGMII接口的pin定义和示意图。


即使用了DDR技术,总的信号线数量也达到了74根。而且因为这么多信号线走156.25M速率要保证等长,又因为电气特性的影响,一般XGMII只能支持7cm的PCB走线,XGMII的使用难度很大。实际中一般见到的都是XAUI接口。
二、XAUI接口
XGMII信号数目(74 根)较多,通常用于芯片内的连接,不适合作为芯片间通信的接口,因此协议定义XGXS(XGMII eXtender Sublayer)子层以缩减信号数目,简化硬件设计。
XGXS 子层主要完成 8b/10b 编码和不同Lane之间的去偏斜等功能。如图所示,在信号链的两端,MAC和PHY 都包括XGXS子层,XAUI 是 XGXS 之间通信的接口。

XAUI 接口4对差分对(收发),共 16 根信号。每组差分对(Lane)的数据速率为 3.125 Gbp,工作在 DDR 模式,时钟频率是3.125Gbps / 2 = 1.5625GHz。
1.5625GHz *2 * 4 = 12.5 Gbps, 12.5Gbps * 80% = 10 Gbps。

XAUI在XGMII的基础上实现了XGMII接口的物理距离扩展,将PCB走线的传输距离增加到50cm,使背板走线成为可能。
这里提一下,虽然XAUI有4serdes组信号,但它仍然是串行总线而不是并行总线,因为这4组sedes并不共用时钟,时钟都是从各自CDR中恢复的。这4组serdes也没有等长的要求,因为它们之间没有时序关系。这个结论可以推广到所有4组serdes组成的以太网接口。
XAUI也有自己的信号数量降低版本,RXAUI,2组serdes,速率提高到6.25Gbit/s。
到这个阶段,实际上所谓的MII是MAC层和PHY层的介质无关接口的定义已经名不副实了。要实现serdes的长距离传输,物理层是不可或缺的,XAUI包括SGMII,实际上连接就已经是物理层对物理层了。
-
超高速率以太网
更高速率的以太网显而易见,已经不可能再在芯片外部走线上使用并行总线,只能用serdes来实现。
这里看一下盛科CTC9280芯片手册上的端口。这些名称都不太标准,但是可以帮助理解。

一、XFI接口
XFI是10G以太网 PMA和 PMD之间的接口标准,它只有2对差分线(收/发),共 4 根线。XFI 接口速度达到 10.3125 Gbps,工作在 DDR 模式,采用 64B/66B 编码,每对差分线速率5.15625Gbps,每对时钟频率2.578125GHz,在XAUI与XFI之间使用到 SerDes 以减小信号数。
2.578125GHz * 2 * 2 = 10.3125 Gbps,10.3125 Gbps *(64/66)= 10Gbps

XFI和SFI接口都是高速串行接口,但是它们的物理层和电气特性不同。XFI接口是10G以太网物理层接口,而SFI接口是SONETISDH物理层接口。此外,XFI接口使用的是单模光纤,而SFI接口使用的是多模光纤。
XFP(10 Gigabit Small Form Factor Pluggable)是指应用XFI接口的光模块,应用于10G以太网的光传输。XFP光模块的尺寸略大于 SFP 和 SFP+ 光模块,三种光模块的详细对比见如下地址
Difference between XFP, SFP and SFP+ | XFP vs SFP vs SFP+
二、XLAUI接口
XLAUI:参照XAUI,XL是罗马数字40的意思,就是40G的XAUI接口,占用4个Lane。
100G的类似接口为CAUI,C为罗马数字100。
三、25G接口
25G:25G以太网接口,可以理解为25G的SFI。
四、50G接口
50G NRZ:两组25G组成的50G。一个50G占用两个Lane。
NRZ的意思是指不归零码Non Return to Zero。区别于归零码。区别看下图简单理解。

50G PAM4:对比25G NRZ为12.5GHz时钟实现25Gbps速率,50 PAM4则为12.5GHz时钟实现50Gbps速率。
PAM4 (4 Pulse Amplitude Modulation) 指四电平脉冲幅度调制)。是一种PAM(脉冲幅度调制)调制技术。PAM4采用4个不同的信号电平来进行信号传输,每个符号周期可以表示2个bit的逻辑信息(0、1、2、3),也就是一个时间单位内是四个电平。也就是一次时钟边沿采样可以采用2-bit数据。
PAM技术可以在基频不变的情况下提升serdes速率,但缺点也很明显,极大复杂化了信号。

100G NRZ:4组25G NRZ组成100G。
200G R4: 4组50G PAM4组成200G。
400G R8:8组50G PAM4组成400G。
400G R4:4组100G PAM4组成400G。
800G R8:8组 100G PAM4组成800G。
在PCB上serdes速率越来越接近理论极限的情况下,PAM技术已经越来越多的出现在各种接口上。比如,PCIe 6.0引入PAM4,将速率由5.0的32Gbps提升至64Gbps。
结束。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 42
42 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)