激活函数小结:ReLU、ELU、Swish、GELU等
激活函数Sigmoid、Tanh、ReLU、Leaky ReLU、PReLU、ELU、SoftPlus、Maxout、Mish、Swish、GELU、SwiGLU、GEGLU 总结
激活函数是神经网络中的非线性函数,为了增强网络的表示能力和学习能力,激活函数有以下几点性质:
- 连续且可导(允许少数点上不可导)的非线性函数。可导的激活函数可以直接利用数值优化的方法来学习网络参数。
- 激活函数及其导函数要尽可能的简单,有利于提高网络计算效率。
- 激活函数的导函数的值域要在一个合适的区间内(不能太大也不能太小),否则会影响训练的效率和稳定性。
Sigmoid
Sigmoid函数(也被称为Logistic函数)的表达式如下:
σ
(
x
)
=
exp
(
x
)
exp
(
x
)
+
exp
(
0
)
=
1
1
+
e
x
p
(
−
x
)
\sigma(x)=\frac{\exp (x)}{\exp (x)+\exp (0)} = \frac {1}{1+exp(-x)}
σ(x)=exp(x)+exp(0)exp(x)=1+exp(−x)1
其导数为
d
d
x
σ
(
x
)
=
σ
(
x
)
(
1
−
σ
(
x
)
)
\frac{d}{d x} \sigma(x)=\sigma(x)(1-\sigma(x))
dxdσ(x)=σ(x)(1−σ(x))
其图像如下图,是一个S型曲线,所以Sigmoid函数可以看做一个“挤压”函数,把一个实数域的输入“挤压”到(0,1)。当输入值在0附近时,Sigmoid函数近似为线性函数;当输入值靠近两端时,对输入进行抑制;输入越小,越接近于0;输入越大,越接近于1。

from matplotlib import pyplot as plt
import numpy as np
import torch
from torch import nn
x = np.linspace(-6, 6, 600)
m0 = nn.Sigmoid()
output0 = m0(torch.Tensor(x))
plt.plot(x, output0, label='Sigmod')
plt.title("Sigmoid Activation Function")
plt.xlabel("x")
plt.ylabel("Activation")
plt.grid()
plt.legend()
plt.show()
Sigmoid激活函数的缺点:
- 倾向于梯度消失
- 函数输出不是以0为中心,会使其后一层的神经元的输入发生偏置偏移(Bias Shift),进而使得梯度下降的收敛速度变慢,也就是会降低权重更新的效率
- 公式中包括指数运算,计算机运行较慢
Tanh
Tanh 函数也是一种S型函数,其定义为
t
a
n
h
(
x
)
=
exp
(
x
)
−
exp
(
−
x
)
exp
(
x
)
+
exp
(
−
x
)
tanh(x)=\frac{\exp (x) - \exp (-x)}{\exp (x)+\exp (-x)}
tanh(x)=exp(x)+exp(−x)exp(x)−exp(−x)
Tanh函数可以看做放大并平移的Sigmoid函数,其值域为(-1,1),并且Tanh与Sigmoid函数关系如下式:
t
a
n
h
(
x
)
=
2
σ
(
2
x
)
−
1
tanh(x) = 2 \sigma(2x) -1
tanh(x)=2σ(2x)−1
Tanh函数如下图所示,它的输入是零中心化的了。

x = np.linspace(-6, 6, 600)
m0 = nn.Sigmoid()
output0 = m0(torch.Tensor(x))
plt.plot(x, output0, label='Sigmod')
m0_1 = nn.Tanh()
output0_1 = m0_1(torch.Tensor(x))
plt.plot(x, output0_1, label='Tanh')
plt.title("Sigmoid and Tanh Activation Functions")
plt.xlabel("x")
plt.ylabel("Activation")
plt.grid()
plt.legend()
plt.show()
ReLU
ReLU(Rectified Linear unit)是最常见的激活函数,其公式为:
R
e
L
U
(
x
)
=
{
x
x
≥
0
0
x
<
0
=
m
a
x
(
0
,
x
)
\begin {aligned} ReLU(x) &= \begin{cases} x \ \ \qquad x \ge 0 \\ 0 \ \ \qquad x<0 \end{cases} \\ &= max(0, x) \end {aligned}
ReLU(x)={x x≥00 x<0=max(0,x)
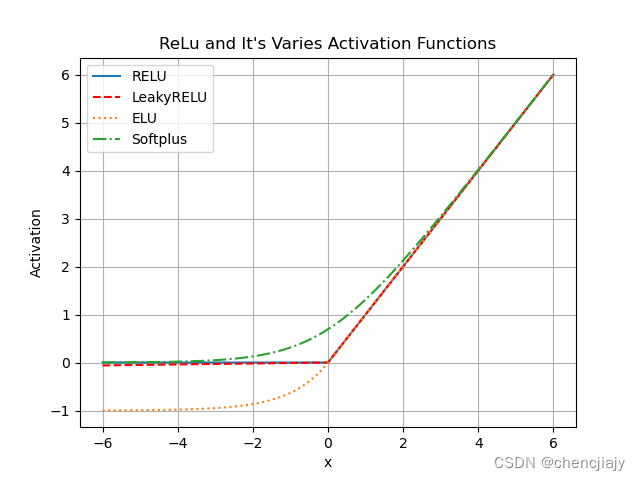
ReLU函数示意及后面会介绍的几种变种如下图所示:

x = np.linspace(-6, 6, 600)
m0 = nn.ReLU()
output0 = m0(torch.Tensor(x))
plt.plot(x, output0, label='RELU')
m1 = nn.LeakyReLU()
output1 = m1(torch.Tensor(x))
plt.plot(x, output1, label='LeakyRELU', color='red', linestyle='--')
m2 = nn.ELU()
output2 = m2(torch.Tensor(x))
plt.plot(x, output2, label='ELU', linestyle='dotted')
m3 = nn.Softplus()
output3 = m3(torch.Tensor(x))
plt.plot(x, output3, label='Softplus', linestyle='-.')
plt.title("ReLu and It's Varies Activation Functions")
plt.xlabel("x")
plt.ylabel("Activation")
plt.grid()
plt.legend()
plt.show()
ReLU函数的优点是:1. 采用ReLU的神经元只需要进行加、乘和比较的操作,计算上更加高效。2. ReLU函数被认为具有生物学合理性,比如单侧抑制、宽兴奋边界。在生物神经网络中,同时处于兴奋状态的神经元非常稀疏,比如人脑中在同一时刻大概只有 1% ∼ 4% 的神经元处于活跃状态。Sigmoid 型激活函数会导致一个非稀疏的神经网络,而 ReLU 却具有很好的稀疏性,大约 50% 的神经元会处于激活状态.3. 相对于sigmoid函数的两端饱和,ReLU函数为左饱和函数,且在x>0时的导数为1,所以相比之下一定程度上缓解了梯度消失问题,加速梯度下降的收敛速度。
ReLU函数的缺点是:1. 函数输出是非零中心化的,会使其后一层的神经元的输入发生偏置偏移(Bias Shift),进而使得梯度下降的收敛速度变慢。2. ReLU神经元在训练时比较容易”dead",如果参数在一次不恰当的更新后,第一个隐藏层中的某个ReLU神经元在所有的训练数据上都不能被激活,那么这个神经元自身参数的梯度永远都会是0,在以后的训练过程中永远不能被激活,这种现象被称为死亡ReLU问题(Dying ReLU Problem)。(其他隐藏层也是有可能发生的)
为了避免ReLU的缺点,有以下几种广泛使用的ReLU变种
Leaky ReLU
Leaky ReLU的公式如下,也就是使输入x<0时,保持一个很小的梯度
γ
\gamma
γ,使得神经元非激活时也有一个非零的梯度可以更新参数,避免永远不能被激活:
L
e
a
k
y
R
e
L
U
(
x
)
=
{
x
x
>
0
γ
x
x
≤
0
=
m
a
x
(
0
,
x
)
+
γ
m
i
n
(
0
,
x
)
\begin {aligned} LeakyReLU(x) &= \begin{cases} x \ \ \qquad x > 0 \\ \gamma x \ \ \qquad x \le 0 \end{cases} \\ &= max(0, x) + \gamma min(0,x) \end {aligned}
LeakyReLU(x)={x x>0γx x≤0=max(0,x)+γmin(0,x)
γ
\gamma
γ是一个很小的常数,如0.01。 当
γ
<
1
\gamma <1
γ<1时,Leaky ReLU 也可以写为
L
e
a
k
y
R
e
L
U
(
x
)
=
m
a
x
(
x
,
γ
x
)
LeakyReLU(x) = max(x, \gamma x)
LeakyReLU(x)=max(x,γx)
PReLU
PRuLU(Parametric ReLU)引入了一个可学习的参数,不同神经元可以有不同的参数。对第i个神经元的PReLU定义为:
P
R
e
L
U
i
(
x
)
=
{
x
x
>
0
γ
i
x
x
≤
0
=
m
a
x
(
0
,
x
)
+
γ
i
m
i
n
(
0
,
x
)
\begin {aligned} PReLU_i(x) &= \begin{cases} x \ \ \qquad x > 0 \\ \gamma_i x \ \ \qquad x \le 0 \end{cases} \\ &= max(0, x) + \gamma_i min(0,x) \end {aligned}
PReLUi(x)={x x>0γix x≤0=max(0,x)+γimin(0,x)
其中
γ
i
\gamma_i
γi为
x
≤
0
x \le 0
x≤0时函数的斜率,所以PReLU也是非饱和函数。
如果 γ i = 0 \gamma_i=0 γi=0,PReLU就退化为ReLU。
如果 γ i \gamma_i γi是一个很小的常数,则PReLU就可以看作LeakyReLU。
PReLU可以允许不同神经元具有不同的参数,也可以一组神经元共享一个参数。
ELU
ELU(Exponential Linear Unit)的定义如下:
E
R
e
L
U
(
x
)
=
{
x
x
>
0
γ
(
e
x
p
(
x
)
−
1
)
x
≤
0
=
m
a
x
(
0
,
x
)
+
m
i
n
(
0
,
γ
(
e
x
p
(
x
)
−
1
)
)
\begin {aligned} EReLU(x) &= \begin{cases} x \ \ \qquad x > 0 \\ \gamma (exp(x) - 1) \ \ \qquad x \le 0 \end{cases} \\ &= max(0, x) + min(0,\gamma (exp(x) - 1)) \end {aligned}
EReLU(x)={x x>0γ(exp(x)−1) x≤0=max(0,x)+min(0,γ(exp(x)−1))
定义中的
γ
≥
0
\gamma \ge 0
γ≥0是一个超参数,决定
x
≤
0
x \le 0
x≤0时的饱和曲线,并调整输出均值在0附近,所以ELU是一个近似的零中心化的非线性函数。
SoftPlus
SoftPlus可以看作ReLU函数的平滑版本,其定义为:
S
o
f
t
p
l
u
s
(
x
)
=
l
o
g
(
1
+
e
x
p
(
x
)
)
Softplus(x) = log(1 + exp(x))
Softplus(x)=log(1+exp(x))
SoftPlus的导数是Sigmoid函数
SoftPlus函数也有与ReLU函数一样的单侧抑制、宽兴奋边界的特性,但没有稀疏激活性。
Maxout
Maxout的输入是上一层神经元的全部原始输出,是一个向量 x = [ x 1 ; x 2 ; ⋯ , ; x D ] \mathbf{x} = [x_1;x_2;\cdots,;x_D] x=[x1;x2;⋯,;xD]
每个Maxout单元有K个权重向量
w
k
∈
R
D
\mathbf{w}_k \in \mathbb{R}^D
wk∈RD (
w
k
=
[
w
k
,
1
,
⋯
,
w
k
,
D
]
T
\mathbf{w}_k = [w_{k, 1}, \cdots, w_{k,D}]^T
wk=[wk,1,⋯,wk,D]T 为第k个权重向量) 和偏置
b
k
(
1
≤
k
≤
K
)
b_k(1 \le k \le K)
bk(1≤k≤K), 对于输入
x
\mathbf{x}
x,可以得到K个净输入
z
k
z_k
zk,
1
≤
k
≤
K
1 \le k \le K
1≤k≤K:
z
k
=
w
k
T
x
+
b
k
z_k = \mathbf{w}_k^T x + b_k
zk=wkTx+bk
Maxout单元的非线性函数定义为
m
a
x
o
u
t
(
x
)
=
max
k
∈
[
1
,
K
]
(
z
k
)
maxout(\mathbf{x}) = \max_{k\in[1,K]} (z_k)
maxout(x)=k∈[1,K]max(zk)
Maxout激活函数可以看做任意凸函数的分段线性近似,并且在有限的点上是不可微的。
Mish
Mish的表达如下式
M
i
s
h
(
x
)
=
x
∗
t
a
n
h
(
S
o
f
t
p
l
u
s
(
x
)
)
=
x
∗
t
a
n
h
(
l
n
(
1
+
e
x
)
)
\begin{aligned} Mish(x) &=x∗tanh(Softplus(x)) \\ &= x*tanh(ln(1+e^x)) \end {aligned}
Mish(x)=x∗tanh(Softplus(x))=x∗tanh(ln(1+ex))
Mish的函数图像如下图

m1 = nn.Mish()
output1 = m1(torch.Tensor(x))
plt.plot(x, output1, label='Mish')
plt.title("Mish Activation Function")
plt.xlabel("x")
plt.ylabel("Activation")
plt.grid()
plt.legend()
plt.show()
Swish
Swish的定义如下:
s
w
i
s
h
(
x
)
=
x
σ
(
β
x
)
=
x
1
1
+
e
x
p
(
−
β
x
)
\begin {aligned} swish(x) &= x \sigma(\beta x) \\ &= x \frac{1}{1+exp(-\beta x)} \end {aligned}
swish(x)=xσ(βx)=x1+exp(−βx)1
σ
\sigma
σ是sigmoid函数,
β
\beta
β是可学习的参数或者一个固定超参数。
σ
(
.
)
∈
(
0
,
1
)
\sigma(.) \in (0,1)
σ(.)∈(0,1) 可以看作一种软性的门控机制,当
σ
(
β
x
)
\sigma(\beta x)
σ(βx) 接近于1时,门的状态为“开”状态,激活函数的输出近似于x本身;当
σ
(
β
x
)
\sigma(\beta x)
σ(βx) 接近于0时,门的状态为“关”,激活函数的输出近似于0.
Swish函数的示意图如下图

x = np.linspace(-6, 6, 600)
m1 = nn.SiLU()
output1 = m1(torch.Tensor(x))
plt.plot(x, output1, label='Swish')
plt.title("Swish Activation Function")
plt.xlabel("x")
plt.ylabel("Activation")
plt.grid()
plt.legend()
plt.show()
- 当 β = 0 \beta=0 β=0时, Swish函数变成线性函数x/2
- 当 β = 1 \beta=1 β=1时, Swish函数在x>0时近似线性,在x<0时近似饱和,同时有一定的单调性
- 当 β → + ∞ \beta \rightarrow + \infty β→+∞时, Swish函数近似为ReLU函数
所以Swish函数可以看做线性函数和ReLU函数之间的非线性插值函数,其程度由 β \beta β控制
GELU
GELU (Gaussian Error Linear Unit) 也是通过门控机制来调整其输出值的激活函数,其表达式为:
G
E
L
U
(
x
)
=
x
P
(
X
≤
x
)
GELU(x) = xP(X \le x)
GELU(x)=xP(X≤x)
其中的
P
(
X
≤
x
)
P(X \le x)
P(X≤x)是高斯分布
N
(
μ
,
σ
2
)
\mathcal{N}(\mu, \sigma^2)
N(μ,σ2)的累积分布函数,
μ
\mu
μ和
σ
\sigma
σ也是超参数,一般取标准分布,即
μ
=
0
,
σ
=
1
\mu=0, \sigma=1
μ=0,σ=1。
由于高斯分布的累积分布函数为S型函数,所以它可以用Tanh和Sigmoid函数来近似:
G
E
L
U
(
x
)
≈
0.5
x
(
1
+
t
a
n
h
(
2
π
(
x
+
0.044715
x
3
)
)
)
G
E
L
U
(
x
)
≈
x
σ
(
1.702
x
)
GELU(x) \approx 0.5x \left( 1 + tanh (\sqrt{\frac{2}{\pi}} (x+0.044715x^3) ) \right) \\ GELU(x) \approx x \sigma(1.702x)
GELU(x)≈0.5x(1+tanh(π2(x+0.044715x3)))GELU(x)≈xσ(1.702x)
当用sigmoid函数来近似时,GELU相当于一种特殊的Swish函数。
GELU的示意图如下:

x = np.linspace(-6, 6, 600)
m1 = nn.GELU()
output1 = m1(torch.Tensor(x))
plt.plot(x, output1, label='GELU')
plt.title("GELU Activation Function")
plt.xlabel("x")
plt.ylabel("Activation")
plt.grid()
plt.legend()
plt.show()
大模型gpt3使用GELU激活函数
GLU
Gated Linear Units (GLU) 是在论文《Language Modeling with Gated Convolutional Networks》 中被提出来的,计算表达式为:
G
L
U
(
a
,
b
)
=
a
⊗
σ
(
b
)
GLU(a, b) = a \ \otimes \ \sigma(b)
GLU(a,b)=a ⊗ σ(b)
上式中的
σ
\sigma
σ是sigmoid函数,
⊗
\otimes
⊗是矩阵间的按元素乘。
从直觉上来说,对于语言模型门控(gate)机制允许选择对于预测下一个单词更重要的单词或特征。
在论文《GLU Variants Improve Transformer》 中下面几种GLU变种被提出。
ReGLU
ReGLU是采用ReLU函数作为激活函数的GLU变体
R
e
G
L
U
(
x
,
W
,
V
,
b
,
c
)
=
m
a
x
(
0
,
x
W
+
b
)
⊗
(
x
V
+
c
)
ReGLU(x, W, V, b, c) = max(0, xW + b) \otimes (xV +c)
ReGLU(x,W,V,b,c)=max(0,xW+b)⊗(xV+c)
JINA EMBEDDINGS 2 对于large版本使用的是ReGLU,其作者说对于大模型使用GEGLU相对没有那么稳定。
SwiGLU
SwiGLU可以看做采用Swish作为激活函数的GLU变体
S
w
i
G
L
U
(
x
,
W
,
V
,
b
,
c
)
=
S
w
i
s
h
1
(
x
W
+
b
)
⊗
(
x
V
+
c
)
SwiGLU(x, W, V, b, c) = Swish_1(xW + b) \otimes (xV +c)
SwiGLU(x,W,V,b,c)=Swish1(xW+b)⊗(xV+c)
Meta开源的LLaMA 和 LLaMA2 以及 Baichuan大模型使用的激活函数是SwiGLU。
GEGLU
GEGLU则可以看做采用GELU作为激活函数的GLU变体
G
E
G
L
U
(
x
,
W
,
V
,
b
,
c
)
=
G
E
L
U
(
x
W
+
b
)
⊗
(
x
V
+
c
)
GEGLU(x, W, V, b, c) = GELU(xW + b) \otimes (xV +c)
GEGLU(x,W,V,b,c)=GELU(xW+b)⊗(xV+c)
GLM-130B 大模型使用的是GEGLU。
资源
- https://www.jiqizhixin.com/articles/2021-02-24-7
- 邱锡鹏《神经网络与深度学习》
- A Survey of Large Language Models
- https://zhuanlan.zhihu.com/p/650237644

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)