AHP层次分析法(Analytic Hierarchy Process)——个人学习笔记
那么如何做一致性判断,以和积法为例其中这个公式用于近似求特征值,计算公式详见图7,可知的计算方式为下图左边的矩阵乘以右边的向量。随后特征值是用于一次性检验用的,为了检验权重是否矛盾,我们还要算一致性指标本题为Ri直接查表就好,是有固定值的;本题是四阶矩阵,查出来就是0.89,如图8所示。最后求得的要和0.1比较大小。
目录
一、相关知识与例子
层次分析法是数学建模过程中最基础的模型之一,主要应用于评价问题。层次分析法是对一些较为复杂、较为模糊的问题作出决策的简易方法,其适用于那些难以完全定量分析的问题。
系统中取得最优的概念。多个方案,多个考虑指标因素,通过比较综合得到的分析权重,用于决策。
处理评价类问题时,首先应当注意三个问题:
1)评价的目标是什么?
2)备选方案有哪些?
3)评价指标是什么?
AHP基本步骤
1)确定三个层级,确定评价指标
2)确定判断矩阵
3)对判断矩阵进行一致性检验
4)计算各决策的权重
实例:
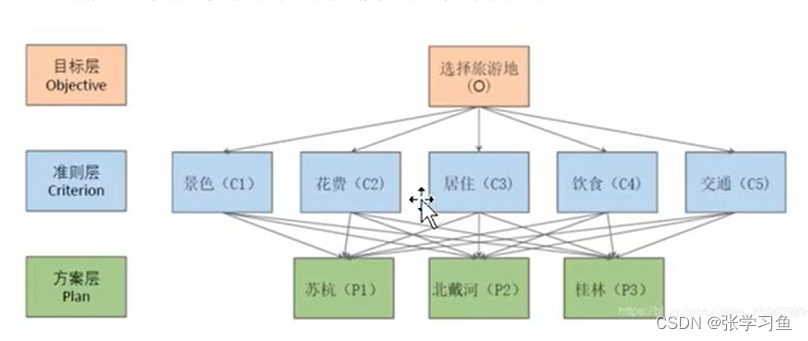
1、构件层次结构(目标层、指标层(指标层可能有很多)、方案层),如图1

图1
通过查阅文献、询问专家等方法,可得到各层之间的判断矩阵,并通过判断矩阵来得到各决策之间的评分,以此来进行哪些决策。
构造了层次关系之后,对于同一层次的各元素关于上一层此的某一准则的重要性进行两两比较,构造判断矩阵。
2、构建判断矩阵
如何比较因素之间的重要程度:如图1中的景色与吃住两两比较,并将这些比较的强烈程度量化成值,制成图2中的右图。

图2
3、计算各层要素对应权重——算术平均法求权重

图3
按列归一化的方法一:算数平均法(和积法)
先求出列的和,再用值去除以这个和;如A1-A1时,是1/8.5
随后用归一化的值,以行为单位算出平均值,用以求权重;第一行的
=(0.12+0.13+0.13+0.09)/4

图4
归一化的方法二:几何平均法(方根法)
将行元素相乘,然后对乘积开四次方;如第一行行成绩=1*(1/4)*2*(1/3) ,开四次方后sqrt**4(行成绩)
然后把开的四次方全部相加,然后再算一个值在这个sum里的总数;如第一行的权重w=0.64/5.46

图5
两种方法差别不大,但这两种算法都是近似算法,实际要算的话很复杂,要用matlab。
权重的大小表示这个因素的重要程度。
最后要做一致性判断,避免矛盾(如A1>A2,A2>A3,又A3>A1)
那么如何做一致性判断,以和积法为例
其中这个公式用于近似求特征值,计算公式详见图7,可知
的计算方式为下图左边的矩阵乘以右边
的向量。
随后特征值
是用于一次性检验用的,为了检验权重是否矛盾,我们还要算一致性指标
本题为
Ri直接查表就好,是有固定值的;本题是四阶矩阵,查出来就是0.89,如图8所示。
最后求得的要和0.1比较大小
若, 一次性检验通过,反之,一致性检验不通过。

图6

图7

图8
在景色维度比较南京、桂林和三亚,可知,当矩阵行列成比例时,CR=0;本图表示桂林的权重最重,桂林的风景最好
图9
图9同样的操作,对吃住、价格、人文作同样的操作,将得到的权重模型列出如图10所示

图10
图10左边一列的四个值,对应的是4个指标权重(他们的重要程度),后面几列是三个城市在四个指标中的比分;最下面的一行是他们比分的平均值。
最后还需要对图10作一次一致性检验。该图CI的计算方式为,用四个指标权重,乘以它们在上图中对应的CI,本题中
RI也许如上图加权平均,CR用算得
二、代码实现
本次代码实现的层次结构,如图11;数据结构,如图12.

图11

图12
第一行是准则层关于目标层的一个判断矩阵,所以它是5X5的矩阵。
第二到六行是方案层关于准则层的一个判断矩阵,它是3X3的矩阵,有9个数
代码实现:
# 利用层次分析法(AHP)进行评价
import numpy as np
# 一致性检验函数
def check(A):
eigen = np.linalg.eig(A)[0] # A的特征值
n = A.shape[0]
CI = (max(eigen) - n) / (n - 1)
RI = [0,0.52,0.89,1.12,1.26,1.36,1.41, 1.46,1.49,1.52,1.54,1.56,1.58,1.59]
CR = CI / RI[n-1]
CI = float(CI)
CR = float(CR)
# 若CI过小,为防止计算误差出现,取0
if abs(CI) < 0.0001:
CI = 0
if abs(CR) < 0.0001:
CR = 0
print('The CI is:{}'.format(CI))
print('The CR is:{}'.format(CR))
# 一致性检验
if CR < 0.1:
return 1
else:
return 0 # 对CR进行判断,用于下面计算权值函数
# 计算权重值
def count_p(A):
q = check(A)
n = A.shape[0]
while q:
weight1 = (np.sum(A/np.sum(A,axis = 1),axis = 1)) / n # 算数平均权重
weight2 = pow(np.prod(A,axis = 1), 1/n) / np.sum(pow(np.prod(A,axis = 1), 1/n)) # 几何平均权重
eigen, F_vector = np.linalg.eig(A)
for i in range(n):
if eigen[i] == np.max(eigen):
index_e = i
best = F_vector[:,index_e]
weight3 = best / np.sum(best) # 特征值权重
print('算术平均权重、几何平均权重和特征值权重分别算出来的权重矩阵:')
print(weight1, '\n',weight2, '\n',weight3,'\n')
return weight1,weight2,weight3
else:
print('Consistency check not pass')
return 0,0,0
# 数据获取与处理
tx = open(r'C:\Users\Aaliy\Desktop\O_R.txt').readlines()
# 下面这样子大咩呀
# tx = [[1,1/2,4,3,3,2,1,7,5,5,1/4,1/7,1,1/2,1/3,1/3,1/5,2,1,1,1/3,1/5,3,1,1],
# [1,2,5,1/2,1,2,1/5,1/2,1],
# [1,1/3,1/8,3,1,1/3,8,3,1],
# [1,1,3,1,1,3,1/3,1/3,1],
# [1,3,4,1/3,1,1,1/4,1,1],
# [1,1,1/4,1,1,1/4,4,4,1]]
for i in range(len(tx)):
tx[i] = np.array(list(eval(tx[i])))
n0 = int((np.size(tx[i]))**0.5)
tx[i] = tx[i].reshape(n0,n0) # 令tx[i]称为矩阵
A0 = tx[0]
print('目标层和指标层的判断矩阵:')
print(A0)
# 有三种方法计算权重,分别传入到o_c1,o_c2,o_c3中
# 它们分别是算数平均权重,几何平均权重,特征值权重
o_c1,o_c2,o_c3 = count_p(A0)
C_P = []
# 这五个判断矩阵,是方案层关于准则层的判断矩阵
print('接下来是方案层关于准则层的判断矩阵:')
for Ai in tx[1:]:
print(Ai)
c_p1,c_p2,c_p3 = count_p(Ai)
# 同样得到三个权重,但是这取用c_p3,将c_p3转化为list,然后添加
C_P.append(list(c_p3))
c_p = np.array(C_P)
print('方案层与准则层的权重矩阵:')
print(c_p)
# print(o_c3)
score = []
for i in range(len(c_p[0,:])):
score.append(sum(o_c3*c_p[:,i])) # 计算权重
print('解决方案们的权重:')
print(score)学习对象:
【AHP层次分析法(python)】 https://www.bilibili.com/video/BV1964y1B7Vc/?share_source=copy_web&vd_source=98fbab4e0ff3ef4e18cd477db479634d
【层次分析法(AHP)步骤详解】 https://www.bilibili.com/video/BV1hK411G76S/?share_source=copy_web&vd_source=98fbab4e0ff3ef4e18cd477db479634d

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐

 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)