Apache Doris
Apache Doris数据模型、Bitmap函数、聚合函数、Doris性能优化、Doris使用方式、Doris数据库管理、Doris安装部署、数据导入、物化视图、Rollup等等。
Apache Doris
- 1 Doris的介绍
- 2 Doris整体架构
- 3 使用场景
- 4 OLAP、OLTP、HATP
- 5 Doris部署
- 6 Doris名词解释
- 7 元数据结构
- 8 数据分发
- 9 Doris实践
- 9.1 账户管理
- 9.2 CREATE TABLE(创建表)
- 9.3 数据更新
- 9.4 数据导入
- 9.5 表结构变更
- 9.6 数据删除
- 9.7 数据查询优化
- 9.8 数据湖分析
- 9.9 常用命令
- 9.9.1 SHOW DATA
- 9.9.2 SHOW DATA SKEW
- 9.9.3 SHOW PARTITIONS
- 9.9.4 SHOW FRONTENDS
- 9.9.5 SHOW BACKENDS
- 9.9.6 SHOW BROKER
- 9.9.7 SHOW CREATE TABLE
- 9.9.8 SHOW LOAD
- 9.9.9 CANCEL LOAD
- 9.9.10 SHOW STREAM LOAD
- 9.9.11 CREATE FILE
- 9.9.12 DELETE
- 9.9.13 SHOW ALTER TABLE MATERIALIZED VIEW
- 9.9.14 SHOW CATALOG RECYCLE BIN
- 9.9.15 SHOW VARIABLES
- 9.9.16 SHOW GRANTS
- 9.9.17 SHOW FILES
- 9.9.18 REFRESH CATALOG
- 10 数据库管理
- 10.1 ADMIN DIAGNOSE TABLET
- 10.2 ADMIN SHOW CONFIG
- 10.3 KILL
- 10.4 ADMIN CHECK TABLET
- 10.5 ADMIN CLEAN TRASH
- 10.6 RECOVER
- 10.7 ADMIN SET REPLICA STATUS
- 10.8 ADMIN SHOW REPLICA DISTRIBUTION
- 10.9 ADMIN REPAIR TABLE
- 10.10 ADMIN SHOW REPLICA STATUS
- 10.11 ADMIN CANCEL REPAIR
- 10.12 SET VARIABLE
- 10.13 ADMIN SET CONFIG
- 10.14 ADMIN SHOW TABLET STORAGE FORMAT
- 10.15 ADMIN COPY TABLET
- 10.16 ADMIN-REBALANCE-DISK
- 10.17 ADMIN CANCEL REBALANCE DISK
- 11 分区缓存
- 12 函数
- 12.1 聚合函数
- 12.1.1 COLLECT_SET
- 12.1.2 COLLECT_LIST
- 12.1.3 GROUP_CONCAT
- 12.1.4 PERCENTILE
- 12.1.5 PERCENTILE_ARRAY
- 12.1.6 PERCENTILE_APPROX
- 12.1.7 MAX_BY
- 12.1.8 MIN_BY
- 12.1.9 APPROX_COUNT_DISTINCT
- 12.1.10 ANY_VALUE
- 12.1.11 RETENTION
- 12.1.12 BITMAP_UNION
- 12.1.13 BITMAP_UNION_COUNT
- 12.1.14 GROUP_BITMAP_XOR
- 12.1.15 BITMAP_INTERSECT
- 12.1.16 HLL_UNION_AGG
- 12.1.17 TOPN
- 12.1.18 TOPN_ARRAY
- 12.2 Bitmap函数
- 12.2.1 TO_BITMAP
- 12.2.2 BITMAP_FROM_STRING
- 12.2.3 BITMAP_TO_STRING
- 12.2.4 BITMAP_TO_ARRAY
- 12.2.5 BITMAP_FROM_ARRAY
- 12.2.6 BITMAP_AND
- 12.2.7 BITMAP_AND_COUNT
- 12.2.8 BITMAP_OR
- 12.2.9 BITMAP_OR_COUNT
- 12.2.10 BITMAP_XOR
- 12.2.11 BITMAP_XOR_COUNT
- 12.2.12 BITMAP_EMPTY
- 12.2.13 BITMAP_HASH
- 12.2.14 BITMAP_HASH64
- 12.2.15 BITMAP_MIN
- 12.2.16 BITMAP_MAX
- 12.2.17 BITMAP_HAS_ANY
- 12.2.18 BITMAP_HAS_ALL
- 12.2.19 BITMAP_CONTAINS
- 12.2.20 BITMAP_COUNT
- 12.2.21 BITMAP_NOT
- 12.3 HLL函数
1 Doris的介绍
Apache Doris是一个基于MPP架构的高性能、实时的分析型数据库,以极速易用的特点被人们所熟知,仅需亚秒级响应时间即可返回海量数据下的查询结果,不仅可以支持高并发的点查询场景,也能支持高吞吐的复杂分析场景。基于此,Apache Doris能够较好的满足报表分析、即席查询、统一数仓构建、数据湖联邦查询加速等使用场景,用户可以在此之上构建用户行为分析、AB 实验平台、日志检索分析、用户画像分析、订单分析等应用。
MPP(Massively Parallel Processing),即大规模并行处理,在数据库非共享集群中,每个节点都有独立的磁盘存储系统和内存系统,业务数据根据数据库模型和应用特点划分到各个节点上,每台数据节点通过专用网络或者商业通用网络互相连接,彼此协同计算,作为整体提供数据库服务。非共享数据库集群有完全的可伸缩性、高可用、高性能、优秀的性价比、资源共享等优势。简单来说,MPP是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果。
2 Doris整体架构

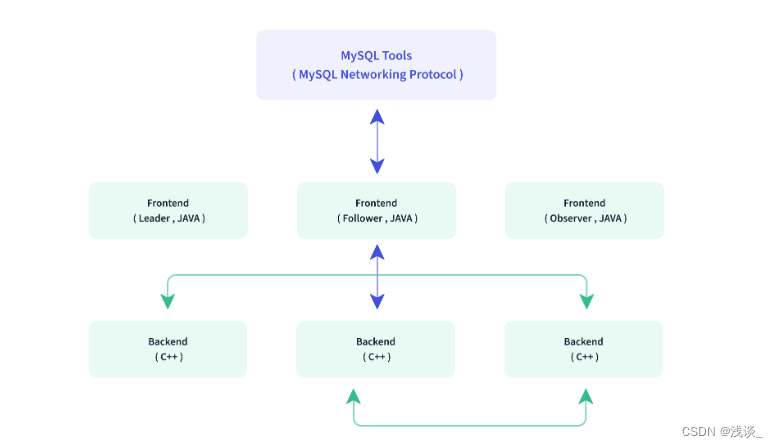
Doris的架构很简洁,使用MySQL协议,用户可以使用任何MySQL ODBC/JDBC和MySQL客户端直接访问Doris,只设FE(Frontend)、BE(Backend)两种角色、两个进程,不依赖于外部组件,方便部署和运维。
Frontend,即Doris的前端节点。主要负责接收和返回客户端请求、元数据以及集群管理、查询计划生成等工作。FE主要有两个角色,一个是Follower,另一个是Observer。多个Follower组成选举组,会选出一个Master,Master是Follower的一个特例,Master跟Follower,主要是用来达到元数据的高可用,保证单节点宕机的情况下,元数据能够实时地在线恢复,而不影响整个服务。需要保证Follower节点的个数为奇数。Observer节点仅从Leader节点进行元数据同步,不参与选举。可以横向扩展以提供元数据的读服务的扩展性。
Backend,即Doris的后端节点。主要负责数据存储与管理、查询计划执行等工作。数据的可靠性由BE保证,BE会对整个数据存储多副本或者是三副本。副本数可根据需求动态调整。
FE,BE都可线性扩展。单集群可以支持到数百台机器,数十PB的存储容量。并且这两类进程通过一致性协议来保证服务的高可用和数据的高可靠。这种高度集成的架构设计极大的降低了一款分布式系统的运维成本。
3 使用场景
3.1 报表分析
实时看板、面向企业内部分析师和管理者的报表、面向用户或者客户的高并发报表分析;比如面向网站主的站点分析、面向广告主的广告报表,并发通常要求成千上万的QPS,查询延时要求毫秒级响应。著名的电商公司京东在广告报表中使用Apache Doris,每天写入100亿行数据,查询并发QPS上万,99分位的查询延时150ms。
3.2 即席查询(Ad-hoc Query)
面向分析师的自助分析,查询模式不固定,要求较高的吞吐。小米公司基于Doris构建了增长分析平台,利用用户行为数据对业务进行增长分析,平均查询延时10s,95分位的查询延时30s以内,每天的SQL查询量为数万条。
3.3 统一数仓构建
一个平台满足统一的数据仓库建设需求,简化繁琐的大数据软件栈。海底捞基于Doris构建的统一数仓,替换了原来由Spark、Hive、Kudu、Hbase、Phoenix组成的旧架构,架构大大简化。
3.4 数据湖联邦查询
通过外表的方式联邦分析位于Hive、Iceberg、Hudi中的数据,在避免数据拷贝的前提下,查询性能大幅提升。
4 OLAP、OLTP、HATP
4.1 OLTP(Online Transaction Processing)
OLTP的查询一般只会访问少量的记录,且大多时候都会利用索引。比如最常见的基于主键的CRUD操作,并且都支持事务处理。
4.2 OLAP(OnLine Analytical Processing)
OLAP的查询一般需要Scan大量数据,大多时候只访问部分列,聚合的需求(Sum,Count,Max,Min等)会多于明细的需求(查询原始的明细数据)。
4.2.1 MOLAP
通过预计算,提供稳定的切片数据,实现多次查询一次计算,减轻了查询时的计算压力,保证了查询的稳定性,是"空间换时间"的最佳路径。实现了基于Bitmap的去重算法,支持在不同维度下去重指标的实时统计,效率较高。Kylin就是一个MOLAP引擎。MOLAP应用层模型复杂,根据业务需要以及Kylin生产需要,还要做较多模型预处理。这样在不同的业务场景中,模型的利用率也比较低。由于MOLAP不支持明细数据的查询,在"汇总+明细"的应用场景中,明细数据需要同步到DBMS引擎来响应交互,增加了生产的运维成本。较多的预处理伴随着较高的生产成本。
4.2.2 ROLAP
基于实时的大规模并行计算,对集群的要求较高。MPP引擎的核心是通过将数据分散,以实现CPU、IO、内存资源的分布,来提升并行计算能力。在当前数据存储以磁盘为主的情况下,数据Scan需要的较大的磁盘IO,以及并行导致的高CPU,仍然是资源的短板。因此,高频的大规模汇总统计,并发能力将面临较大挑战,这取决于集群硬件方面的并行计算能力。传统去重算法需要大量计算资源,实时的大规模去重指标对CPU、内存都是一个巨大挑战。目前Doris最新版本已经支持Bitmap算法,配合预计算可以很好地解决去重应用场景。Doris就是一个ROLAP引擎。ROLAP应用层模型设计简化,将数据固定在一个稳定的数据粒度即可。比如商家粒度的星形模型,同时复用率也比较高。App层的业务表达可以通过视图进行封装,减少了数据冗余,同时提高了应用的灵活性,降低了运维成本。同时支持"汇总+明细"。模型轻量标准化,极大的降低了生产成本。
4.3 HATP
HTAP是Hybrid Transactional(混合事务)/Analytical Processing(分析处理)的简称。基于创新的计算存储框架,HTAP数据库能够在一份数据上同时支撑业务系统运行和OLAP场景,避免在传统架构中,在线与离线数据库之间大量的数据交互。此外,HTAP基于分布式架构,支持弹性扩容,可按需扩展吞吐或存储,轻松应对高并发、海量数据场景。目前,实现HTAP的数据库不多,主要有PingCAP的TiDB、阿里云的HybridDB for MySQL、百度的BaikalDB等。其中,TiDB是国内首家开源的 HTAP 分布式数据库。
4.4 开源OLAP引擎对比

5 Doris部署
5.1 环境分配
| IP | HOSTS | 进程 | 内存 | 硬盘空间 |
|---|---|---|---|---|
| 192.168.130.12 | twdt1 | FE,BE | 32G | 500G |
| 192.168.130.13 | twdt2 | FE,BE | 32G | 500G |
| 192.168.130.14 | twdt3 | FE,BE | 32G | 500G |
5.2 前置条件
# 1. 查看Linux版本,doris适用于CentOs7.1以上和Ubuntu16.04以上。
cat /etc/redhat-release
# 2. 查看Linux是否支持avx2指令集。
cat /proc/cpuinfo |grep avx2
# 3. 下载二进制包。我这里安装的是1.1.2版本。如果支持avx2指令集的话可以下载apache-doris-be-1.1.2-bin-x86_64.tar.gz,如果不支持的话就下载apache-doris-be-1.1.2-bin-x86_64-noavx2.tar.gz,然后下载apache-doris-fe-1.1.2-bin.tar.gz
https://archive.apache.org/dist/doris/1.1/1.1.2-rc05/
# 4. 安装JDK,1.8及以上,自行安装并配置环境变量以及三台机器之间的免密登录。
# 5. 设置系统最大句柄数
vim /etc/security/limits.conf
* soft nofile 65535 #任何用户打开的最大文件数都是65535,如果超过这个数会有警告。
* hard nofile 65535 #任何用户打开的最大文件数都是65535,如果超过这个数会报错。
ulimit -n 65535 # 临时修改打开的最大文件数。
# 6. 时钟同步 因为集群之间要进行心跳检测,Doris规定各个服务器之间的时间差距要小于5秒钟,所以要配置时间同步,另外因为各个服务器都可以联网,则只需要同步网络时间服务器即可。
yum -y install ntpdate #安装ntpdate服务
# 使用crond定时服务和网络时间同步
Systemctl status crond # 检查crond服务的状态,是否已经启动
crontab -e
*/2 * * * * /usr/sbin/ntpdate cn.pool.ntp.org #配置2分钟同步一次网络时间
# 7. 关闭交换内存
swapoff -a #临时关闭
# 注释掉/etc/fstab文件关于swap的一行内容则为永久关闭
5.3 FE部署
# 1. 解压fe到指定目录
tar -zxvf apache-doris-fe-1.1.2-bin.tar.gz -C /opt/
# 2. 修改配置文件
vim /opt/apache-doris-fe-1.1.2-bin/fe/conf/fe.conf
LOG_DIR=/opt/apache-doris-fe-1.1.2-bin/fe/log # 配置log日志目录
meta_dir=/opt/apache-doris-fe-1.1.2-bin/fe/doris-meta # 配置元数据目录
priority_networks=192.168.130.12/16 ##通过ip addr命令查询
# 3. 服务目录分发到其他两台机器上,并且把对应的priority_networks配置项改为对应的服务器ip。
scp -r apache-doris-fe-1.1.2-bin twdt2:$PWD
scp -r apache-doris-fe-1.1.2-bin twdt3:$PWD
# 4. 启动FE进程,第一个启动的FE进程的服务器默认为集群的Master节点。
bin/start_fe.sh --daemon # 第一台启动FE服务的命令
bin/start_fe.sh --helper leader_host:9010 --daemon # 其他Follower节点或者Observer节点启动FE服务的命令
# 5. 安装mysql客户端,连接FE支持的mysql协议。
rpm -qa|grep mariadb # 查看CentOs自带的mysql rpm包并删除。
rpm -e --nodeps mariadb-libs-5.5.68-1.el7.x86_64 # 删除自带的mysql rpm包
rpm -ivh mysql-community-client-5.7.40-1.el7.x86_64.rpm # 只需要安装Client rpm即可。可以直接在请求https://cdn.mysql.com/archives/mysql-5.7/mysql-community-libs-5.7.39-1.el7.x86_64.rpm地址下载
# 6. 登录doris实现mysql协议的服务端
mysql -P9030 -htwdt1 -uroot
# 7. 查看当前的FE节点信息
show frontends\G;
# 8. 增加另外两台服务器节点到frontends集群,这一步相当于扩容。
alter system add follower/observer "twdt2:9010";
# 缩容的话可以使用
alter system drop follower/observer "twdt2:9010"; # 在缩容的时候,删除 Follower FE 时,确保最终剩余的 Follower(包括 Master)节点为奇数。
# 9. 至此FE集群安装完毕。Follower节点建议最多部署 3 个组成高可用(HA)模式即可。当FE处于高可用部署时(1个 Master,2个 Follower),我们建议通过增加 Observer FE 来扩展 FE 的读服务能力。当然也可以继续增加 Follower FE,但几乎是不必要的。通常一个 FE 节点可以应对 10-20 台 BE 节点。建议总的 FE 节点数量在 10 个以下。而通常 3 个即可满足绝大部分需求。
5.4 BE部署
# 1. 解压be到指定目录
tail -zxvf apache-doris-be-1.1.2-bin-x86_64-noavx2.tar.gz -C /opt/
# 2. 修改配置文件
PPROF_TMPDIR="/opt/apache-doris-be-1.1.2-bin-x86_64-noavx2/be/log/"
priority_networks=192.168.130.12/16
storage_root_path=/opt/apache-doris-be-1.1.2-bin-x86_64-noavx2/be/storage,100;/opt/apache-doris-be-1.1.2-bin-x86_64-noavx2/be/storage1,100;/opt/apache-doris-be-1.1.2-bin-x86_64-noavx2/be/storage2 # 逗号后面的是容量限制,这里前面两个目录都限制在100G,最后一个目录没有限制。这里也可以配置存储目录介质,SSD或者HDD
sys_log_dir=/opt/apache-doris-be-1.1.2-bin-x86_64-noavx2/be/log # 配置BE服务的日志目录
# 3. 在安装Doris的时候注意端口,因为Doris涉及的端口有好几个,防止和别的端口冲突。
# 4. 修改完之后把服务分发到另外两台服务器上并修改priority_networks配置项改为对应的服务器ip
# 5. 登录mysql客户端后添加BE服务
mysql -P9030 -htwdt1 -uroot
# 6. 添加BE服务到Doris集群中,在BE扩容的时候也是使用如下命令。
alter system add backend "安装be服务的ip:be服务的心跳端口默认9050,...";
# 删除 BE 节点 。DROP BACKEND 会直接删除该 BE,并且其上的数据将不能再恢复!!!所以我们强烈不推荐使用 DROP BACKEND 这种方式删除 BE 节点。当你使用这个语句时,会有对应的防误操作提示。缩容的时候删除BE节点即可。
alter system drop backend "安装be服务的ip:be服务的心跳端口默认9050,...";
# DECOMMISSION 命令说明:
# 该命令用于安全删除 BE 节点。命令下发后,Doris 会尝试将该 BE 上的数据向其他 BE 节点迁移,当所有数据都迁移完成后,Doris 会自动删除该节点。
# 该命令是一个异步操作。执行后,可以通过 SHOW PROC '/backends'; 看到该 BE 节点的 SystemDecommissioned 状态为 true。表示该节点正在进行下线。
# 该命令不一定执行成功。比如剩余 BE 存储空间不足以容纳下线 BE 上的数据,或者剩余机器数量不满足最小副本数时,该命令都无法完成,并且 BE 会一直处于 SystemDecommissioned 为 true 的状态。
# DECOMMISSION 的进度,可以通过 show backends; 中的 TabletNum 查看,如果正在进行,TabletNum 将不断减少。
# 该操作可以通过:CANCEL DECOMMISSION BACKEND "安装be服务的ip:be服务的心跳端口默认9050,...";命令取消。取消后,该 BE 上的数据将维持当前剩余的数据量。后续 Doris 重新进行负载均衡。
ALTER SYSTEM DECOMMISSION BACKEND "安装be服务的ip:be服务的心跳端口默认9050,...";
# 7. 启动be服务
bin/start_be.sh --daemon
# 在BE 节点的扩容和缩容过程,不影响当前系统运行以及正在执行的任务,并且不会影响当前系统的性能。数据均衡会自动进行。根据集群现有数据量的大小,集群会在几个小时到1天不等的时间内,恢复到负载均衡的状态。
5.5 Broker部署
# Broker 以插件的形式,独立于 Doris 部署。如果需要从第三方存储系统导入数据,需要部署相应的 Broker,默认提供了读取 HDFS 、对象存储的 fs_broker。fs_broker 是无状态的,建议每一个 FE 和 BE 节点都部署一个 Broker。
# Broker添加
ALTER SYSTEM ADD BROKER broker_name "broker_host:broker_ipc_port,...";
# Broker删除
ALTER SYSTEM DROP BROKER broker_name "broker_host:broker_ipc_port";
ALTER SYSTEM DROP ALL BROKER broker_name;
# Broker 是无状态的进程,可以随意启停。当然,停止后,正在其上运行的作业会失败,重试即可。
5.6 检查部署情况
mysql -P9030 -htwdt1 -uroot # 连接mysql服务之后分别使用show frontends\G;命令和show backends\G;查看FE和BE的集群状态,如果和下面的状态类似则部署成功。部署成功后可以通过http://twdt1:8030访问doris的web端查看情况。可以使用默认用户root、admin登录

5.7 Doris各端口说明

6 Doris名词解释
| 名词 | 说明 |
|---|---|
| FE | Frontend,即Doris的前端节点。主要负责接收和返回客户端请求、元数据以及集群管理、查询计划生成等工作。 |
| BE | Backend,即Doris的后端节点。主要负责数据存储和管理、查询计划执行等工作。 |
| Tablet | Tablet是一张表实际的物理存储单元,一张表按照分区和分桶后在BE构成分布式存储层中以Tablet为单位进行存储,每个Tablet包括元数据及若干连续的Rowset。 |
| Rowset | Rowset是Tablet中一次数据变更的数据集合,数据变更包括了数据导入、删除、更新等。Rowset按版本信息进行记录。每次变更会生成一个版本。 |
| Version | 由Start、End两个属性构成,维护数据变更的记录信息。通常用来表示Rowset的版本范围,在一次新导入后生成一个Start,End相等的Rowset,在Compaction后生成一个带范围的Rowset版本。 |
| Segment | 表示Rowset中的数据分段。多个Segment构成一个Rowset。 |
| Compaction | 连续版本的Rowset合并的过程称为Compaction,合并过程中会对数据进行压缩操作。 |
7 元数据结构

Doris采用Paxos协议以及Memory + Checkpoint + Journal的机制来确保元数据的高性能及高可靠。元数据的每次更新,都会遵照以下几步:
1. 首先写入到磁盘的日志文件中。
2. 然后再写到内存中。
3. 最后定期checkpoint到本地磁盘上。
相当于是一个纯内存的一个结构,也就是说所有的元数据都会缓存在内存之中,从而保证FE在宕机后能够快速恢复元数据,而且不丢失元数据。Leader、Follower和Observer它们三个构成一个可靠的服务,如果发生节点宕机的情况,一般是部署一个Leader两个Follower,目前来说基本上也是这么部署的。就是说三个节点去达到一个高可用服务。单机的节点故障的时候其实基本上三个就够了,因为FE节点毕竟它只存了一份元数据,它的压力不大,所以如果FE太多的时候它会去消耗机器资源,所以多数情况下三个就足够了,可以达到一个很高可用的元数据服务。
8 数据分发

数据主要都是存储在BE里面,BE节点上物理数据的可靠性通过多副本来实现,默认是3副本,副本数可配置且可随时动态调整,满足不同可用性级别的业务需求。FE调度BE上副本的分布与补齐。
如果说用户对可用性要求不高,而对资源的消耗比较敏感的话,我们可以在建表的时候选择建两副本或者一副本。比如在百度云上我们给用户建表的时候,有些用户对它的整个资源消耗比较敏感,因为他要付费,所以他可能会建两副本。但是我们一般不太建议用户建一副本,因为一副本的情况下可能一旦机器出问题了,数据直接就丢了,很难再恢复。一般是默认建三副本,这样基本可以保证一台机器单机节点宕机的情况下不会影响整个服务的正常运作。
9 Doris实践
9.1 账户管理
9.1.1 SET PASSWORD(修改密码)
# 格式
SET PASSWORD [FOR user_identity] = PASSWORD('password');
# SET PASSWORD命令可以用于修改一个用户的登录密码。如果[FOR user_identity]字段不存在,那么修改当前用户的密码。
# user_identity = 'username'%'192.%'。
# 注意这里的user_identity必须完全匹配在使用CREATE USER创建用户时指定的user_identity,否则会报错用户不存在。如果不指定user_identity,则当前用户为'username'@'ip',这个当前用户,可能无法匹配任何user_identity。可以通过SHOW GRANTS查看当前用户。
# 如果修改其他用户的密码,需要具有管理员权限。
# 示例
SET PASSWORD = PASSWORD('123456') # 修改当前用户的登录名
SET PASSWORD FOR 'jack'@'192.%' = PASSWORD('123456') # 修改用户名为'jack'并且登录ip为192开头的用户密码
9.1.2 CREATE USER(创建用户)
# 格式
CREATE USER [IF EXISTS] user_identity [IDENTIFIED BY 'password'] [DEFAULT ROLE 'role_name'] [password_policy]
# 在Doris中,一个user_identity唯一标识一个用户。user_identity由两部分组成,user_name和host,其中username为用户名。host标识用户端连接所在的主机地址。host部分可以使用%进行模糊匹配。如果不指定host,默认为'%',即表示该用户可以从任意host连接到Doris。
password_policy:#是用于指定密码认证登录相关策略的子句,目前支持以下策略:
1. PASSWORD_HISTORY [n] # 是否允许当前用户重置密码时使用历史密码。如 PASSWORD_HISTORY 10 表示禁止使用过去10次设置过的密码为新密码。0表示不启用这个功能。默认为0。
2. PASSWORD_EXPIRE [INTERVAL n DAY/HOUR/SECOND] # 设置当前用户密码的过期时间。如 PASSWORD_EXPIRE INTERVAL 10 DAY 表示密码会在 10 天后过期。
3. FAILED_LOGIN_ATTEMPTS n PASSWORD_LOCK_TIME [n DAY/HOUR/SECOND|UNBOUNDED]
# FAILED_LOGIN_ATTEMPTS 和 PASSWORD_LOCK_TIME:设置当前用户登录时,如果使用错误的密码登录n次后,账户将被锁定,并设置锁定时间。如 FAILED_LOGIN_ATTEMPTS 3 PASSWORD_LOCK_TIME 1 DAY 表示如果3次错误登录,则账户会被锁定一天。
# 如果指定了角色(ROLE),则会自动将该角色所拥有的权限赋予新创建的这个用户。如果不指定,则该用户默认没有任何权限。指定的 ROLE 必须已经存在。
# 示例
CREATE USER 'jack'; # 创建一个无密码用户(不指定 host,则等价于 jack@'%')
CREATE USER jack@'172.10.1.10' IDENTIFIED BY '123456'; # 创建一个有密码用户,允许从 '172.10.1.10' 登陆。
CREATE USER 'jack' IDENTIFIED BY '12345' PASSWORD_HISTORY 8; # 创建一个用户,并限制不可重置密码为最近8次是用过的密码。
CREATE USER 'jack' IDENTIFIED BY '12345' PASSWORD_EXPIRE INTERVAL 10 DAY FAILED_LOGIN_ATTEMPTS 3 PASSWORD_LOCK_TIME 1 DAY;# 创建一个用户,设定密码10天后过期,并且设置如果3次错误登录则账户会被锁定一天。
CREATE USER 'jack'@'%' IDENTIFIED BY '12345' DEFAULT ROLE 'my_role'; # 创建一个用户,并指定一个角色
9.1.3 DROP USER(删除用户)
# 格式
DROP USER 'user_identity';
# 示例
DROP USER 'jack'@'192.%'; # 删除用户 jack@'192.%'
9.1.4 CREATE ROLE(创建角色)
# 格式
CREATE ROLE rol_name;
# 示例
CREATE ROLE role1;
# 在实际应用中可以对权限分角色,不同的角色使用不同的组合权限。
9.1.5 DROP ROLE(删除角色)
# 格式
DROP ROLE [IF EXISTS] role1;
# 示例
DROP ROLE role1;
9.1.4 GRANT(赋予权限)
# 格式
GRANT privilege_list ON priv_level TO user_identity [ROLE role_name];
GRANT privilege_list ON RESOURCE resource_name TO user_identity [ROLE role_name];
GRANT role_list TO user_identity;
# privilege_list是需要赋予的权限列表,以逗号分隔。当前支持如下权限:
NODE_PRIV:# 集群节点操作权限,包括节点上下线等操作,只有 root 用户有该权限,不可赋予其他用户。
ADMIN_PRIV:# 除NODE_PRIV以外的所有权限。
GRANT_PRIV:# 操作权限的权限。包括创建删除用户、角色,授权和撤权,设置密码等。
SELECT_PRIV:# 对指定的库或表的读取权限
LOAD_PRIV:# 对指定的库或表的导入权限
ALTER_PRIV:# 对指定的库或表的schema变更权限
CREATE_PRIV:# 对指定的库或表的创建权限
DROP_PRIV:# 对指定的库或表的删除权限
USAGE_PRIV: # 对指定资源的使用权限
# priv_level支持以下四种形式:
# 1. *.*.* 权限可以应用于所有catalog及其中的所有库表
# 2. ctl.*.* 权限可以应用于指定catalog中的所有库表
# 3. ctl.db.* 权限可以应用于指定库下的所有表
# 4. ctl.db.tbl 权限可以应用于指定库下的指定表
# 这里指定的ctl或库或表可以是不存在的库和表。
# resource_name 支持以下两种形式:
# 1. * 权限应用于所有资源
# 2. resource 权限应用于指定资源
# 这里指定的资源可以是不存在的资源。
# user_identity必须是已经创建过的。user_identity中的host可以是域名,如果是域名的话,权限的生效时间可能会有1分钟左右的延迟。也可以将权限赋予指定的 ROLE,如果指定的ROLE不存在,则会自动创建。
# role_list是需要赋予的角色列表,以逗号分隔,指定的角色必须存在。
# 示例
GRANT SELECT_PRIV ON *.*.* TO 'jack'@'%'; # 授予所有catalog和库表的查询权限给任何地址登录的jack用户。
GRANT SELECT_PRIV,ALTER_PRIV,LOAD_PRIV ON ctl1.db1.tbl1 TO 'jack'@'192.8.%'; # 授予指定库表的权限给任何地址登录的jack用户。
GRANT LOAD_PRIV ON ctl1.db1.* TO ROLE 'my_role'; # 授予指定库表的导入权限给角色。
GRANT USAGE_PRIV ON RESOURCE * TO 'jack'@'%'; # 授予所有资源的使用权限给用户。
GRANT USAGE_PRIV ON RESOURCE 'spark_resource' TO 'jack'@'%'; # 授予指定资源的使用权限给用户。
GRANT USAGE_PRIV ON RESOURCE 'spark_resource' TO ROLE 'my_role'; # 授予指定资源的使用权限给角色。
GRANT 'role1','role2' TO 'jack'@'%'; # 将指定角色授予某用户,这样角色所对应的权限也会授予用户。
9.1.5 REVOKE(撤销权限)
# 格式
REVOKE privilege_list ON db_name[.tbl_name] FROM user_identity [ROLE role_name]
REVOKE privilege_list ON RESOURCE resource_name FROM user_identity [ROLE role_name]
REVOKE role_list FROM user_identity
# 示例
REVOKE SELECT_PRIV ON db1.* FROM 'jack'@'192.%'; # 撤销通过192开头的ip地址登录的jack用户的数据库名为db1的查询权限。
REVOKE USAGE_PRIV ON RESOURCE 'spark_resource' FROM 'jack'@'192.%';# 撤销通过192开头的ip地址登录的jack用户的指定资源使用权限。
REVOKE 'role1','role2' FROM 'jack'@'192.%'; # 撤销通过192开头的ip地址登录的jack用户的role1、role2角色所拥有的权限。
9.1.6 ALTER USER(修改用户)
#格式
ALTER USER [IF EXISTS] user_identity [IDENTIFIED BY 'password'][password_policy]
# password_policy:
# ACCOUNT_UNLOCK 命令用于解锁一个被锁定的用户。
# 其他功能参考CREATE USER
# 在一个 ALTER USER 命令中,只能同时对以下账户属性中的一项进行修改:
# 1. 修改密码
# 2. 修改 PASSWORD_HISTORY
# 3. 修改 PASSWORD_EXPIRE
# 4. 修改 FAILED_LOGIN_ATTEMPTS 和 PASSWORD_LOCK_TIME
# 5. 解锁用户
# 示例
ALTER USER jack@‘%’ IDENTIFIED BY "12345"; # 修改通过任何地址登录的jack用户的密码为12345。
ALTER USER jack@'%' FAILED_LOGIN_ATTEMPTS 3 PASSWORD_LOCK_TIME 1 DAY; # 修改通过任何地址登录的jack用户的密码策略。
ALTER USER jack@'%' ACCOUNT_UNLOCK # 解锁通过任何地址登录的jack用户。
9.2 CREATE TABLE(创建表)
在Doris中,数据都以表(Table)的形式进行逻辑上的描述。一张表包括行(Row)和列(Column)。Row即用户的一行数据,Column即一行数据中不同的字段。Column可以分为两大类:Key和Value。从业务角度看,Key和Value可以分别对应维度列和指标列。从聚合模型的角度来说,Key列相同的行,会聚合成一行。其中Value列的聚合方式由用户在建表时指定。
在Doris的存储引擎中,用户数据被水平划分为若干个数据分片(Tablet,也称作数据分桶)。每个Tablet包含若干数据行。各个Tablet之间的数据没有交集,并且在物理上是独立存储的。
多个Tablet在逻辑上归属于不同的分区(Partition)。一个Tablet只属于一个Partition。而一个Partition包含若干个Tablet。因为Tablet在物理上是独立存储的,所以可以视为Partition在物理上也是独立。Tablet是数据移动、复制等操作的最小物理存储单元。
若干个Partition组成一个Table。Partition可以视为是逻辑上最小的管理单元。数据的导入与删除,仅能针对一个Partition进行。
Doris支持两层的数据划分。第一层是Partition,支持Range和List的划分方式。第二层是Bucket(Tablet),仅支持Hash的划分方式。也可以仅使用一层分区。使用一层分区时,只支持Bucket划分。
CREATE TABLE [IF NOT EXISTS] [database.]table
(
column_name column_type [KEY] [aggr_type] [NULL] [default_value] [column_comment] # 列定义
[index_definition_list] # 索引
)
[engine_type] # 引擎
[keys_type] # 数据模型
[table_comment] # 表名注释
[partition_info] # 分区信息
distribution_desc # 分桶信息
[rollup_list] # Rollup
[properties] # 属性
9.2.1 数据类型
BOOLEAN,BOOL # 1个字节,0:false;1:true
TINYINT # 1字节有符号整数,范围[-128, 127]
SMALLINT # 2字节有符号整数,范围[-32768, 32767]
INT # 4字节有符号整数,范围[-2147483648, 2147483647]
BIGINT # 8字节有符号整数,范围[-9223372036854775808, 9223372036854775807]
LARGEINT # 16字节有符号整数,范围[-2^127 + 1 ~ 2^127 - 1]
FLOAT # 4字节浮点数
DOUBLE # 8字节浮点数
CHAR(M) # 定长字符串,M代表的是定长字符串的字节长度。M的范围是1-255。
VARCHAR(M) # 变长字符串,M代表的是变长字符串的字节长度。M的范围是1-65533。变长字符串是以UTF-8编码存储的,因此通常英文字符占1个字节,中文字符占3个字节。
STRING # 变长字符串,最大(默认)支持1048576 字节(1MB)。String类型的长度还受be配置`string_type_length_soft_limit_bytes`(字符串类型长度的软限制), String类型只能用在value列,不能用在key列和分区、分桶列。
DECIMALV3(M[,D]) # 高精度定点数,M 代表一共有多少个有效数字,D代表小数位有多少数字,有效数字M的范围是[1,38],小数位数字数量D的范围是[0,M]。默认值为DECIMALV3(9,0)。占用空间根据M进行动态调整,当M小于等于8,则占用4个字节,当M小于等于18,则占用8个字节,当M小于等于38则占用16个字节。
DATEV2 # 日期类型,目前的取值范围是['0000-01-01', '9999-12-31'], 默认的打印形式是'yyyy-MM-dd'。DATEV2类型相比DATE类型更加高效,在计算时,DATEV2相比DATE可以节省一半的内存使用量。
DATETIMEV2([P]) # 日期时间类型,可选参数P表示时间精度,取值范围是[0, 6],即最多支持6位小数(微秒)。不设置时为0。取值范围是['0000-01-01 00:00:00[.000000]', '9999-12-31 23:59:59[.999999]']。打印的形式是'yyyy-MM-dd HH:mm:ss.SSSSSS'。
HLL # HLL不能作为key列使用,只能使用在Aggregate模型中,建表时配合聚合类型为HLL_UNION。用户不需要指定长度和默认值。长度根据数据的聚合程度系统内控制。并且HLL列只能通过配套的HLL_UNION_AGG、HLL_RAW_AGG、HLL_CARDINALITY、HLL_HASH函数进行查询或使用。HLL是模糊去重,在数据量大的情况性能优于COUNT DISTINCT。HLL的误差通常在1%左右,有时会达到2%。
BITMAP # BITMAP不能作为key列使用,只能使用在Aggregate模型中,建表时配合聚合类型为BITMAP_UNION。用户不需要指定长度和默认值。长度根据数据的聚合程度系统内控制。并且BITMAP列只能通过配套的BITMAP_UNION_COUNT、BITMAP_UNION、BITMAP_HASH、BITMAP_HASH64等函数进行查询或使用。离线场景下使用BITMAP会影响导入速度,在数据量大的情况下查询速度会慢于HLL,并优于COUNT DISTINCT。注意:实时场景下BITMAP如果不使用全局字典,使用了BITMAP_HASH()可能会导致有千分之一左右的误差。如果这个误差不可接受,可以使用BITMAP_HASH64。
ARRAY<T> # 由T类型元素组成的数组,不能作为key列使用。目前支持在Duplicate模型的表中使用。
JSONB # 二进制JSON类型,采用二进制JSONB格式存储,通过jsonb函数访问JSON内部字段。与普通STRING类型存储的JSON字符串相比,JSONB类型有两点优势:1. 数据写入时进行JSON格式校验;2.二进制存储格式更加高效,通过jsonb_extract等函数可以高效访问JSON内部字段,比get_json_xx函数快几倍。JSONB类型的列会自动转成JSON string展示。$在json path中代表root,即整个json。
9.2.2 Partition(分区)
9.2.2.1 特点
- Partition列可以指定一列或多列,分区列必须为KEY列。
- 不论分区列是什么类型,在写分区值时,都需要加双引号。
- 分区数量理论上没有上限。
- 当不使用Partition建表时,系统会自动生成一个和表名同名的,全值范围的Partition。该Partition对用户不可见,并且不可删改。
- 创建分区时不可添加范围重叠的分区。
- Doris 中的表可以分为分区表和无分区的表。这个属性在建表时确定,之后不可更改。即对于分区表,可以在之后的使用过程中对分区进行增删操作,而对于无分区的表,之后不能再进行增加分区等操作。
- 分区列在表创建之后不可更改,也不能更改分区列的类型,更不能对这些列进行任何增删操作。
9.2.2.2 场景
有时间维度或类似带有有序值的维度,可以以这类维度列作为分区列。分区粒度可以根据导入频次、分区数据量等进行评估。
历史数据删除需求:如有删除历史数据的需求(比如仅保留最近N 天的数据)。使用复合分区,可以通过删除历史分区来达到目的。也可以通过在指定分区内发送 DELETE 语句进行数据删除。
解决数据倾斜问题:每个分区可以单独指定分桶数量。如按天分区,当每天的数据量差异很大时,可以通过指定分区的分桶数,合理划分不同分区的数据,分桶列建议选择区分度大的列。
9.2.2.3 Range分区
9.2.2.3.1 特点
- 分区列通常为时间列,以方便的管理新旧数据。
- Partition支持通过VALUES LESS THAN(…)仅指定上界,系统会将前一个分区的上界作为该分区的下界,生成一个左闭右开的区间。也支持通过VALUES[…) 指定上下界,生成一个左闭右开的区间。同时,也支持通过
FROM(...) TO (...) INTERVAL ...来批量创建分区。 - 分区的删除不会改变已存在分区的范围。删除分区可能出现空洞。通过VALUES LESS THAN语句增加分区时,分区的下界紧接上一个分区的上界。分区空洞范围内的数据导入不进去分区表。
9.2.2.3.2 示例
# 在创建表的时候使用如下示例创建分区
PARTITION BY RANGE(`date`)
(
PARTITION `p202301` VALUES LESS THAN ("2023-02-01"),
PARTITION `p202302` VALUES LESS THAN ("2023-03-01"),
PARTITION `p202303` VALUES LESS THAN ("2023-04-01")
)
========================================================
PARTITION BY RANGE(`date`)
(
PARTITION `p202301` VALUES [("1970-01-01"), ("2023-02-01")),
PARTITION `p202302` VALUES [("2023-02-01"), ("2023-03-01")),
PARTITION `p202303` VALUES [("2023-03-01"), ("2023-04-01"))
)
========================================================
PARTITION BY RANGE(`date`)
(
FROM ("2023-02-01") TO ("2023-04-01") INTERVAL 1 MONTH
)
========================================================
PARTITION BY RANGE(`date`, `id`)
(
PARTITION `p202301_1000` VALUES LESS THAN ("2023-02-01", "1000"),
PARTITION `p202302_2000` VALUES LESS THAN ("2023-03-01", "2000"),
PARTITION `p202303_all` VALUES LESS THAN ("2023-04-01")
)
9.2.2.4 List分区
9.2.2.4.1 特点
- 分区列支持BOOLEAN,TINYINT,SMALLINT,INT,BIGINT,LARGEINT,DATEV2,DATETIMEV2,CHAR,VARCHAR数据类型,分区值为枚举值。只有当数据为目标分区枚举值其中之一时,才可以命中分区。
- Partition支持通过VALUES IN(…)来指定每个分区包含的枚举值。
9.2.2.4.2 示例
PARTITION BY LIST(`city`)
(
PARTITION `p_cn` VALUES IN ("Beijing", "Shanghai", "Hong Kong"),
PARTITION `p_usa` VALUES IN ("New York", "San Francisco"),
PARTITION `p_jp` VALUES IN ("Tokyo")
)
============================================================
PARTITION BY LIST(`id`, `city`)
(
PARTITION `p1_city` VALUES IN (("1", "Beijing"), ("1", "Shanghai")),
PARTITION `p2_city` VALUES IN (("2", "Beijing"), ("2", "Shanghai")),
PARTITION `p3_city` VALUES IN (("3", "Beijing"), ("3", "Shanghai"))
)
9.2.2.5 动态分区
9.2.2.5.1 特点
动态分区目前只支持Range分区。在某些使用场景下,用户会将表按照天进行分区划分,每天定时执行例行任务,这时需要使用方手动管理分区,否则可能由于使用方没有创建分区导致数据导入失败,这给使用方带来了额外的维护成本。
通过动态分区功能,用户可以在建表时设定动态分区的规则。FE会启动一个后台线程,根据用户指定的规则创建或删除分区。用户也可以在运行时对现有规则进行变更。
动态分区的规则可以在建表时指定,或者在运行时进行修改。当前仅支持对单分区列的分区表设定动态分区规则。
# 建表时指定
CREATE TABLE table_name(
...
)
PROPERTIES
(
"dynamic_partition.prop1" = "value1",
"dynamic_partition.prop2" = "value2",
...
)
# 运行时修改
ALTER TABLE table_name SET
(
"dynamic_partition.prop1" = "value1",
"dynamic_partition.prop2" = "value2",
...
)
9.2.2.5.2 动态分区规则
# 动态分区的规则参数都以dynamic_partition.为前缀:
# 是否开启动态分区特性。可指定为TRUE或FALSE。如果不填写,默认为TRUE。如果为FALSE,则Doris会忽略该表的动态分区规则。
dynamic_partition.enable
# 动态分区调度的单位。可指定为HOUR、DAY、WEEK、MONTH。分别表示按小时、按天、按星期、按月进行分区创建或删除。当指定为HOUR时,动态创建的分区名后缀格式为yyyyMMddHH,例如2020032501。小时为单位的分区列数据类型不能为DATE;当指定为DAY时,动态创建的分区名后缀格式为yyyyMMdd,例如20200325;当指定为WEEK时,动态创建的分区名后缀格式为yyyy_ww。即当前日期属于这一年的第几周,例如2020-03-25创建的分区名后缀为 2020_13, 表明目前为2020年第13周;当指定为MONTH时,动态创建的分区名后缀格式为yyyyMM,例如202003。
dynamic_partition.time_unit
# 动态分区的时区,如果不填写,则默认为当前机器的系统的时区,例如Asia/Shanghai,如果想获取当前支持的时区设置,可以参考https://en.wikipedia.org/wiki/List_of_tz_database_time_zones。
dynamic_partition.time_zone
# # 动态分区的起始偏移,为负数。根据time_unit属性的不同,以当天(星期/月)为基准,分区范围在此偏移之前的分区将会被删除。如果不填写,则默认为-2147483648,即不删除历史分区。
dynamic_partition.start
# 动态分区的结束偏移,为正数。根据 time_unit 属性的不同,以当天(星期/月)为基准,提前创建对应范围的分区。
dynamic_partition.end
# 动态创建的分区名前缀。
dynamic_partition.prefix
# 动态创建的分区所对应的分桶数量。
dynamic_partition.buckets
# 动态创建的分区所对应的副本数量,如果不填写,则默认为该表创建时指定的副本数量。
dynamic_partition.replication_num
# 当time_unit为WEEK时,该参数用于指定每周的起始点。取值为1到7。其中1表示周一,7表示周日。默认为1,即表示每周以周一为起始点。
dynamic_partition.start_day_of_week
# 当time_unit为MONTH时,该参数用于指定每月的起始日期。取值为1到28。其中1表示每月1号,28表示每月28号。默认为1,即表示每月以1号位起始点。暂不支持以29、30、31号为起始日,以避免因闰年或闰月带来的歧义。
dynamic_partition.start_day_of_month
# 指定创建的动态分区的默认存储介质。默认是HDD,可选择SSD。注意,当设置为SSD时,hot_partition_num属性将不再生效,所有分区将默认为SSD存储介质并且冷却时间为 9999-12-31 23:59:59。
dynamic_partition.storage_medium
# 默认为false。当置为true时,Doris会自动创建所有分区,具体创建规则见下文。同时,FE的参数max_dynamic_partition_num会限制总分区数量,以避免一次性创建过多分区。当期望创建的分区个数大于max_dynamic_partition_num值时,操作将被禁止。当不指定start属性时,该参数不生效。
dynamic_partition.create_history_partition
# 当create_history_partition为true时,该参数用于指定创建历史分区数量。默认值为-1, 即未设置。
dynamic_partition.history_partition_num
# 指定最新的多少个分区为热分区。对于热分区,系统会自动设置其storage_medium参数为SSD,并且设置storage_cooldown_time。若存储路径下没有SSD磁盘路径,配置该参数会导致动态分区创建失败。hot_partition_num是往前n天和未来所有分区。
dynamic_partition.hot_partition_num
# 假设今天是2021-05-20,按天分区,动态分区的属性设置为:hot_partition_num=2,end=3,start=-3。则系统会自动创建以下分区,并且设置storage_medium和storage_cooldown_time参数:
p20210517:["2021-05-17", "2021-05-18") storage_medium=HDD storage_cooldown_time=9999-12-31 23:59:59
p20210518:["2021-05-18", "2021-05-19") storage_medium=HDD storage_cooldown_time=9999-12-31 23:59:59
p20210519:["2021-05-19", "2021-05-20") storage_medium=SSD storage_cooldown_time=2021-05-21 00:00:00
p20210520:["2021-05-20", "2021-05-21") storage_medium=SSD storage_cooldown_time=2021-05-22 00:00:00
p20210521:["2021-05-21", "2021-05-22") storage_medium=SSD storage_cooldown_time=2021-05-23 00:00:00
p20210522:["2021-05-22", "2021-05-23") storage_medium=SSD storage_cooldown_time=2021-05-24 00:00:00
p20210523:["2021-05-23", "2021-05-24") storage_medium=SSD storage_cooldown_time=2021-05-25 00:00:00
# 可以通过运行时修改保留需要的本来应该被删除的分区。当dynamic_partition.time_unit设置为 "DAY/WEEK/MONTH"时,需要以[yyyy-MM-dd,yyyy-MM-dd],[...,...]格式进行设置。当dynamic_partition.time_unit设置为"HOUR"时,需要以[yyyy-MM-dd HH:mm:ss,yyyy-MM-dd HH:mm:ss],[...,...]的格式来进行设置。如果不设置,默认为"NULL"。
dynamic_partition.reserved_history_periods
# 假设今天是 2021-09-06,按天分类,动态分区的属性设置为:time_unit="DAY/WEEK/MONTH", end=3, start=-3, reserved_history_periods="[2020-06-01,2020-06-20],[2020-10-31,2020-11-15]"。则系统会自动保留:
["2020-06-01","2020-06-20"],
["2020-10-31","2020-11-15"]
9.2.2.6 临时分区
9.2.2.6.1 应用场景
原子的覆盖写操作:某些情况下,用户希望能够重写某一分区的数据,但如果采用先删除再导入的方式进行,在中间会有一段时间无法查看数据。这时,用户可以先创建一个对应的临时分区,将新的数据导入到临时分区后,通过替换操作,原子的替换原有分区,以达到目的。
修改分桶数:某些情况下,用户在创建分区时使用了不合适的分桶数。则用户可以先创建一个对应分区范围的临时分区,并指定新的分桶数。然后通过 INSERT INTO 命令将正式分区的数据导入到临时分区中,通过替换操作,原子的替换原有分区,以达到目的。
合并或分割分区:某些情况下,用户希望对分区的范围进行修改,比如合并两个分区,或将一个大分区分割成多个小分区。则用户可以先建立对应合并或分割后范围的临时分区,然后通过 INSERT INTO 命令将正式分区的数据导入到临时分区中,通过替换操作,原子的替换原有分区,以达到目的。
9.2.2.6.2 特点
- 临时分区是归属于某一分区表的。只有分区表可以创建临时分区。
- 临时分区的分区列和正式分区相同,且不可修改。
- 一张表所有临时分区之间的分区范围不可重叠,但临时分区的范围和正式分区范围可以重叠。
- 临时分区的分区名称不能和正式分区以及其他临时分区重复。
- 临时分区的添加和正式分区的添加操作相似。临时分区的分区范围独立于正式分区。
- 临时分区可以独立指定一些属性。包括分桶数、副本数、存储介质等信息。
- 删除临时分区,不影响正式分区的数据。
- 使用Drop操作直接删除数据库或表后,可以通过Recover命令恢复数据库或表(限定时间内),但临时分区不会被恢复。
- 使用Alter命令删除正式分区后,可以通过Recover命令恢复分区(限定时间内)。操作正式分区和临时分区无关。
- 使用Alter命令删除临时分区后,无法通过Recover命令恢复临时分区。
- 使用Truncate命令清空表,表的临时分区会被删除,且不可恢复。
- 使用Truncate命令清空正式分区时,不影响临时分区。
- 不可使用Truncate命令清空临时分区。
- 当表存在临时分区时,无法使用Alter命令对表进行Schema Change、Rollup等变更操作。
- 当表在进行变更操作时,无法对表添加临时分区。
9.2.2.6.3 功能
9.2.2.6.3.1 添加
ALTER TABLE table_name ADD TEMPORARY PARTITION tp1 VALUES LESS THAN("2020-02-01");
ALTER TABLE table_name ADD TEMPORARY PARTITION tp1 VALUES [("2020-01-01"), ("2020-02-01"));
ALTER TABLE table_name ADD TEMPORARY PARTITION tp1 VALUES LESS THAN("2020-02-01")
("replication_num" = "1")
DISTRIBUTED BY HASH(k1) BUCKETS 5;
ALTER TABLE table_name ADD TEMPORARY PARTITION tp1 VALUES IN ("Beijing", "Shanghai");
ALTER TABLE table_name ADD TEMPORARY PARTITION tp1 VALUES IN ((1, "Beijing"), (1, "Shanghai"));
9.2.2.6.3.2 删除
ALTER TABLE table_name DROP TEMPORARY PARTITION tp1;
9.2.2.6.3.3 替换
- 可以通过 ALTER TABLE REPLACE PARTITION 语句将一个表的正式分区替换为临时分区。
- 替换操作有两个特殊的可选参数:
- strict_range:默认为true。对于Range分区,当该参数为true时,表示要被替换的所有正式分区的范围并集需要和替换的临时分区的范围并集完全相同。当置为false时,只需要保证替换后,新的正式分区间的范围不重叠即可;对于List分区,该参数恒为true。要被替换的所有正式分区的枚举值必须和替换的临时分区枚举值完全相同。
- use_temp_partition_name:默认为false。当该参数为false,并且待替换的分区和替换分区的个数相同时,则替换后的正式分区名称维持不变。如果为true,则替换后,正式分区的名称为替换分区的名称。
# 示例
================================================
正式分区 p1, p2, p3 的范围 (=> 并集): [10, 20), [20, 30), [40, 50) => [10, 30), [40, 50)
临时分区 tp1, tp2 的范围(=> 并集):[10, 30), [40, 45), [45, 50) => [10, 30), [40, 50)
范围并集相同,则可以使用 tp1 和 tp2 替换 p1, p2, p3。
================================================
正式分区 p1 的范围 (=> 并集):[10, 50) => [10, 50)
临时分区 tp1, tp2 的范围(=> 并集):[10, 30), [40, 50) => [10, 30), [40, 50)
范围并集不相同,如果 strict_range 为 true,则不可以使用 tp1 和 tp2 替换 p1。如果为 false,且替换后的两个分区范围 [10, 30), [40, 50) 和其他正式分区不重叠,则可以替换。
================================================
# 分区替换成功后,被替换的分区将被删除且不可恢复。
# 示例
ALTER TABLE table_name REPLACE PARTITION (p1, p2) WITH TEMPORARY PARTITION (tp1, tp2)
PROPERTIES (
"strict_range" = "false",
"use_temp_partition_name" = "true"
);
# 导入数据到临时分区
INSERT INTO table_name TEMPORARY PARTITION(tp1, tp2, ...) SELECT ....
# 查询临时分区数据
SELECT ... FROM
table_name TEMPORARY PARTITION(tp1, tp2, ...)
JOIN
table_name TEMPORARY PARTITION(tp1, tp2, ...)
ON ...
WHERE ...;
9.2.3 Bucket(分桶)
9.2.3.1 特点
- 分桶列在表创建之后不可更改,也不能更改分桶列的类型,更不能对这些列进行任何增删操作。
- 如果使用了Partition,则DISTRIBUTED …语句描述的是数据在各个分区内的划分规则。如果不使用Partition,则描述的是对整个表的数据的划分规则。
- 分桶列可以是多列,Aggregate和Unique模型的分桶列必须为Key列,Duplicate模型因为没有Key列和Value列,它指定的只是数据排序的顺序,所以分桶列可以是任何列。分桶列可以和Partition列相同或不同。
- 分桶列的选择,是在“查询吞吐”和“查询并发”之间的一种权衡:
- 如果选择多个分桶列,则数据分布更均匀。如果一个查询条件不包含所有分桶列的等值条件,那么该查询会触发所有分桶同时扫描,这样查询的吞吐会增加,单个查询的延迟随之降低。这个方式适合大吞吐低并发的查询场景。
- 如果仅选择一个或少数分桶列,则对应的点查询可以仅触发一个分桶扫描。此时,当多个点查询并发时,这些查询有较大的概率分别触发不同的分桶扫描,各个查询之间的IO影响较小(尤其当不同桶分布在不同磁盘上时),所以这种方式适合高并发的点查询场景。
- 分桶的数量理论上没有上限。
- 一个表的Tablet总数量等于(PartitionNum * BucketNum)。
- 一个表的Tablet数量,在不考虑扩容的情况下,推荐略多于整个集群的磁盘数量。每个Tablet使用一个磁盘IO的情况下,数据读写的速度最大。
- 单个Tablet的数据量理论上没有上下界,但建议在1G - 10G的范围内。如果单个Tablet数据量过小,则数据的聚合效果不佳,且元数据管理压力大。如果数据量过大,则不利于副本的迁移、补齐,且会增加Schema Change或者Rollup操作失败重试的代价(这些操作失败重试的粒度是 Tablet)。
- 当Tablet的数据量原则和数量原则冲突时,建议优先考虑数据量原则。
- 在建表时,每个分区的Bucket数量统一指定。但是在动态增加分区时(ADD PARTITION),可以单独指定新分区的Bucket数量。可以利用这个功能方便的应对数据缩小或膨胀。
- 一个Partition的Bucket数量一旦指定,不可更改。所以在确定Bucket数量时,需要预先考虑集群扩容的情况。比如当前只有3台host,每台host有1块盘。如果Bucket的数量只设置为3或更小,那么后期即使再增加机器,也不能提高并发度。
- 在确定分区和分桶的时候可以根据表原始的数据量、3年的数据增量以及BE服务端的安装机器数和每台机器的磁盘个数等来确定。
- 表的数据量可以通过SHOW DATA命令查看,结果除以副本数,即表的数据量。
# 示例
DISTRIBUTED BY HASH(`user_id`) BUCKETS 16
DISTRIBUTED BY HASH(`user_id`,`sex`) BUCKETS 16
9.2.3.2 Random Distribution
不指定分桶列设置成Random Distribution对数据进行随机分布。
如果OLAP表没有更新类型的字段,将表的数据分桶模式设置为RANDOM,则可以避免严重的数据倾斜(数据在导入表对应的分区的时候,单次导入作业每个batch的数据将随机选择一个tablet进行写入)。
当表的分桶模式被设置为RANDOM 时,因为没有分桶列,无法根据分桶列的值仅对几个分桶查询,对表进行查询的时候将对命中分区的全部分桶同时扫描,该设置适合对表数据整体的聚合查询分析而不适合高并发的点查询。
如果OLAP表的是Random Distribution的数据分布,那么在数据导入的时候可以设置单分片导入模式(将load_to_single_tablet设置为true),那么在大数据量的导入的时候,一个任务在将数据写入对应的分区时将只写入一个分片,这样将能提高数据导入的并发度和吞吐量,减少数据导入和Compaction导致的写放大问题,保障集群的稳定性。
DISTRIBUTED BY RANDOM BUCKETS 5
9.2.3.3 自动分桶
用户经常设置不合适的bucket,导致各种问题,这里提供一种方式,来自动设置分桶数。暂时而言只对olap表生效。
开启autobucket之后,在SHOW CREATE TABLE的时候看到的schema也是BUCKETS AUTO.如果想要查看确切的bucket数,可以通过SHOW PARTITIONS来查看。
# 使用自动分桶推算的创建语法
DISTRIBUTED BY HASH(site) BUCKETS AUTO
properties("estimate_partition_size" = "100G")
# estimate_partition_size:表示一个单分区的数据量。该参数是可选的,如果没有给出则 Doris 会将 estimate_partition_size 的默认值取为 10GB。
9.2.4 数据模型
Duplicate、Aggregate、Unique 模型,都会在建表指定 key 列,然而实际上是有所区别的:对于 Duplicate 模型,表的key列,可以认为只是 “排序列”,并非起到唯一标识的作用。而 Aggregate、Unique 模型这种聚合类型的表,key 列是兼顾 “排序列” 和 “唯一标识列”,是真正意义上的“ key 列”。
因为数据模型在建表时就已经确定,且无法修改。所以,选择一个合适的数据模型非常重要。
9.2.4.1 Aggregate模型
9.2.4.1.1 使用场景
Aggregate 模型可以通过预聚合,极大地降低聚合查询时所需扫描的数据量和查询的计算量,非常适合有固定模式的报表类查询场景。但是该模型对 count(*) 查询很不友好。同时因为固定了 Value 列上的聚合方式,在进行其他类型的聚合查询时,需要考虑语意正确性。
9.2.4.1.2 使用方式
CREATE TABLE IF NOT EXISTS example_db.example_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
AGGREGATE KEY(`user_id`, `date`, `city`, `age`, `sex`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
- 表中的列按照是否设置了 AggregationType,没有设置 AggregationType 的,如 user_id、date、age … 等称为 Key列,而设置了 AggregationType 的称为 Value列。
- 当我们导入数据时,对于 Key 列相同的行会聚合成一行,而 Value 列会按照设置的 AggregationType 进行聚合。 AggregationType 目前有以下四种聚合方式:
- SUM:求和,多行的 Value 进行累加。
- REPLACE:替代,下一批数据中的 Value 会替换之前导入过的行中的 Value。
- MAX:保留最大值。
- MIN:保留最小值。
按照如上的表结构进行数据导入后,Doris 中最终只会存储聚合后的数据。换句话说,即明细数据会丢失,用户不能够再查询到聚合前的明细数据了。如果想存储明细数据的话,可以使用如下表结构:
CREATE TABLE IF NOT EXISTS example_db.example_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`timestamp` DATETIME NOT NULL COMMENT '数据灌入的时间戳',
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
AGGREGATE KEY(`user_id`, `date`, `timestamp`,`city`, `age`, `sex`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
- 即增加了一列timestamp,记录精确到秒的数据灌入时间。同时也将timestamp添加到Key列中。
- 只要保证导入的数据中,每一行的 Key 都不完全相同,那么即使在聚合模型下,Doris 也可以保存完整的明细数据。
- 数据的聚合,在 Doris 中有如下三个阶段发生:
- 每一批次数据导入的 ETL 阶段。该阶段会在每一批次导入的数据内部进行聚合。
- 底层 BE 进行数据 Compaction 的阶段。该阶段,BE 会对已导入的不同批次的数据进行进一步的聚合。
- 数据查询阶段。在数据查询时,对于查询涉及到的数据,会进行对应的聚合。
- 对于用户而言,用户只能查询到聚合后的数据。即不同的聚合程度对于用户查询而言是透明的。用户需始终认为数据以最终的完成的聚合程度存在,而不应假设某些聚合还未发生。
9.2.4.1.3 聚合模型的局限性
在聚合模型中,模型对外展现的,是最终聚合后的数据。也就是说,任何还未聚合的数据(比如说两个不同导入批次的数据),必须通过某种方式,以保证对外展示的一致性。我们在查询引擎中加入了聚合算子,来保证数据对外的一致性。这样就会导致在查询的时候会先有一步聚合的操作。如果设置到全表的情况,性能会很差。例如:
# count(*) 慢的原因
# batch1
user_id date cost
10001 2017-11-20 50
10002 2017-11-21 39
# batch2
user_id date cost
10001 2017-11-20 1
10001 2017-11-21 5
10003 2017-11-22 22
如上两个批次在导入后,select count() from table;正确的结果应该为 4。但如果我们只扫描 user_id 这一列,如果加上查询时聚合,最终得到的结果是 3(10001, 10002, 10003)。而如果不加查询时聚合,则得到的结果是 5(两批次一共5行数据)。可见这两个结果都是不对的。
为了得到正确的结果,我们必须同时读取 user_id 和 date 这两列的数据,再加上查询时聚合,才能返回 4 这个正确的结果。也就是说,在 count() 查询中,Doris 必须扫描所有的 AGGREGATE KEY 列(这里就是 user_id 和 date),并且聚合后,才能得到语意正确的结果。当聚合列非常多时,count() 查询需要扫描大量的数据。
因此,当业务上有频繁的 count() 查询时,我们建议用户通过增加一个值恒为 1 的,聚合类型为 SUM 的列来模拟 count()。增加一个 count 列,并且导入数据中,该列值恒为 1。则 select count() from table; 的结果等价于 select sum(count) from table;。而后者的查询效率将远高于前者。不过这种方式也有使用限制,就是用户需要自行保证,不会重复导入 AGGREGATE KEY 列都相同的行。否则,select sum(count) from table; 只能表述原始导入的行数,而不是 select count() from table; 的语义。
另一种方式,就是 将如上的 count 列的聚合类型改为 REPLACE,且依然值恒为 1。那么 select sum(count) from table; 和 select count() from table; 的结果将是一致的。并且这种方式,没有导入重复行的限制。
9.2.4.2 Unique模型
9.2.4.2.1 应用场景
Unique 模型针对需要唯一主键约束的场景,可以保证主键唯一性约束。但是无法利用 ROLLUP 等预聚合带来的查询优势。
对于聚合查询有较高性能需求的用户,推荐使用自1.2版本加入的写时合并实现。Unique 模型仅支持整行更新,如果用户既需要唯一主键约束,又需要更新部分列(例如将多张源表导入到一张 Doris 表的情形),则可以考虑使用 Aggregate 模型,同时将非主键列的聚合类型设置为 REPLACE_IF_NOT_NULL。适用于有更新数据需求的分析业务。
9.2.4.2.2 使用方式
在某些多维分析场景下,用户更关注的是如何保证 Key 的唯一性,即如何获得 Primary Key 唯一性约束。因此,我们引入了 Unique 数据模型。在1.2版本之前,该模型本质上是聚合模型的一个特例,也是一种简化的表结构表示方式。由于聚合模型的实现方式是读时合并(merge on read),因此在一些聚合查询上性能不佳,在1.2版本我们引入了Unique模型新的实现方式,写时合并(merge on write),通过在写入时做一些额外的工作,实现了最优的查询性能。
CREATE TABLE IF NOT EXISTS example_db.example_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`username` VARCHAR(50) NOT NULL COMMENT "用户昵称",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`phone` LARGEINT COMMENT "用户电话",
`address` VARCHAR(500) COMMENT "用户地址",
`register_time` DATETIME COMMENT "用户注册时间"
)
UNIQUE KEY(`user_id`, `username`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
如上,这是一个典型的用户基础信息表。这类数据没有聚合需求,只需保证主键唯一性。(这里的主键为 user_id + username)。上面这个表结构完全同等于以下使用聚合模型描述的表结构。
CREATE TABLE IF NOT EXISTS example_db.example_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`username` VARCHAR(50) NOT NULL COMMENT "用户昵称",
`city` VARCHAR(20) REPLACE COMMENT "用户所在城市",
`age` SMALLINT REPLACE COMMENT "用户年龄",
`sex` TINYINT REPLACE COMMENT "用户性别",
`phone` LARGEINT REPLACE COMMENT "用户电话",
`address` VARCHAR(500) REPLACE COMMENT "用户地址",
`register_time` DATETIME REPLACE COMMENT "用户注册时间"
)
AGGREGATE KEY(`user_id`, `username`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
即Unique 模型的读时合并实现完全可以用聚合模型中的 REPLACE 方式替代。其内部的实现方式和数据存储方式也完全一样。但是,Unqiue模型的写时合并实现,与聚合模型就是完全不同的两种模型了,查询性能更接近于duplicate模型,在有主键约束需求的场景上相比聚合模型有较大的查询性能优势,尤其是在聚合查询以及需要用索引过滤大量数据的查询中。
在 1.2.0 版本中,写时合并默认关闭,用户可以通过添加下面的property来开启。
CREATE TABLE IF NOT EXISTS example_db.example_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`username` VARCHAR(50) NOT NULL COMMENT "用户昵称",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`phone` LARGEINT COMMENT "用户电话",
`address` VARCHAR(500) COMMENT "用户地址",
`register_time` DATETIME COMMENT "用户注册时间"
)
UNIQUE KEY(`user_id`, `username`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1",
"enable_unique_key_merge_on_write" = "true" -- 开启写时合并
);
在开启了写时合并选项的Unique表上,数据在导入阶段就会去将被覆盖和被更新的数据进行标记删除,同时将新的数据写入新的文件。在查询的时候,所有被标记删除的数据都会在文件级别被过滤掉,读取出来的数据就都是最新的数据,消除掉了读时合并中的数据聚合过程,并且能够在很多情况下支持多种谓词的下推。因此在许多场景都能带来比较大的性能提升,尤其是在有聚合查询的情况下。
写时合并只能在建表的时候通过property指定,读时合并无法无缝升级到写时合并,如果需要改为使用写时合并的实现方式,需要通过insert into unique_new_table_name select * from source_table_name。在Unique模型上独有的delete sign(批量删除使用)和 sequence col(按需更新使用),在写时合并的新版实现中仍可以正常使用,用法没有变化。
9.2.4.2.3 sequence 列
9.2.4.2.3.1 介绍
Uniqe模型主要针对需要唯一主键的场景,可以保证主键唯一性约束,但是由于使用REPLACE聚合方式,替换顺序不做保证,替换顺序无法保证则无法确定最终导入到表中的具体数据,存在了不确定性。
为了解决这个问题,Doris支持了sequence列,通过用户在导入时指定sequence列,相同key列下,REPLACE聚合类型的列将按照sequence列的值进行替换,较大值可以替换较小值,反之则无法替换。
sequence列目前只支持Uniqe模型。
9.2.4.2.3.2 基本原理
通过增加一个隐藏列__DORIS_SEQUENCE_COL__实现,该列的类型由用户在建表时指定,在导入时确定该列具体值,并依据该值对REPLACE列进行替换。
创建Unique模型表时,将按照用户指定类型自动添加一个隐藏列_DORIS_SEQUENCE_COL_。
请求包含value列时需要额外读取__DORIS_SEQUENCE_COL__列,该列用于在相同key列下,REPLACE聚合函数替换顺序的依据,较大值可以替换较小值,反之则不能替换。
导入时,FE在解析的过程中将隐藏列的值设置成 order by 表达式的值(broker load和routine load),或者function_column.sequence_col表达式的值(stream load),value列将按照该值进行替换。隐藏列__DORIS_SEQUENCE_COL__的值既可以设置为数据源中一列,也可以是表结构中的一列。
9.2.4.2.3.3 使用方法
在新建表时如果设置了function_column.sequence_col或者function_column.sequence_type ,则新建表将支持sequence column。对于一个不支持sequence column的Unique表,如果想要使用该功能,可以使用如下语句:
ALTER TABLE db_name.table_name ENABLE FEATURE "SEQUENCE_LOAD" WITH PROPERTIES ("function_column.sequence_col" = "cloumn_name")
# 查看一张表是否支持sequence列可以通过如下命令查看。如果输出中有__DORIS_SEQUENCE_COL__ 列则支持,如果没有则不支持。
SET show_hidden_columns=true;
desc table_name;
# 查询完成后,关闭显示隐藏列,防止对数据查询有影响。
SET show_hidden_columns=false;
9.2.4.3 Duplicate模型
Duplicate 适合任意维度的 Ad-hoc 查询。虽然同样无法利用预聚合的特性,但是不受聚合模型的约束,可以发挥列存模型的优势(只读取相关列,而不需要读取所有 Key 列)。适用于数据无需提前聚合的分析业务。
9.2.4.3.1 应用场景
9.2.4.3.2 使用方式
在某些多维分析场景下,数据既没有主键,也没有聚合需求。因此,我们引入 Duplicate 数据模型来满足这类需求。
CREATE TABLE IF NOT EXISTS example_db.example_tbl
(
`timestamp` DATETIME NOT NULL COMMENT "日志时间",
`type` INT NOT NULL COMMENT "日志类型",
`error_code` INT COMMENT "错误码",
`error_msg` VARCHAR(1024) COMMENT "错误详细信息",
`op_id` BIGINT COMMENT "负责人id",
`op_time` DATETIME COMMENT "处理时间"
)
DUPLICATE KEY(`timestamp`, `type`, `error_code`)
DISTRIBUTED BY HASH(`type`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
这种数据模型区别于 Aggregate 和 Unique 模型。数据完全按照导入文件中的数据进行存储,不会有任何聚合。即使两行数据完全相同,也都会保留。 而在建表语句中指定的 DUPLICATE KEY,只是用来指明底层数据按照那些列进行排序。(更贴切的名称应该为 “Sorted Column”,这里取名 “DUPLICATE KEY” 只是用以明确表示所用的数据模型。
这种数据模型适用于既没有聚合需求,又没有主键唯一性约束的原始数据的存储。
9.2.5 索引
- 目前 Doris 主要支持两类索引:
- 内建的智能索引,包括前缀索引和 ZoneMap 索引。其中 ZoneMap 索引是在列存格式上,对每一列自动维护的索引信息,包括 Min/Max,Null 值个数等等。这种索引对用户透明。
- 用户手动创建的二级索引,包括 倒排索引、 bloomfilter索引、 ngram bloomfilter索引 和bitmap索引。
9.2.5.1 前缀索引
不同于传统的数据库设计,Doris 不支持在任意列上创建索引。Doris 这类 MPP 架构的 OLAP 数据库,通常都是通过提高并发,来处理大量数据的。本质上,Doris 的数据存储在类似 SSTable(Sorted String Table)的数据结构中。该结构是一种有序的数据结构,可以按照指定的列进行排序存储。在这种数据结构上,以排序列作为条件进行查找,会非常的高效。前缀索引,即在排序的基础上,实现的一种根据给定前缀列,快速查询数据的索引方式。在Doris中前缀索引使用稀疏索引进行构建。
将一行数据的前 36 个字节 作为这行数据的前缀索引。当遇到 VARCHAR 类型时,前缀索引会直接截断。并且VARCHAR字段只会匹配前20个字节。所以在建表的时候VARCHAR最好放在排序的最后一位,如果出现在前面会导致索引长度不足36字节。当我们的查询条件,是前缀索引的前缀时,可以极大的加快查询速度。所以在建表时,正确的选择列顺序,能够极大地提高查询效率。因为建表时已经指定了列顺序,所以一个表只有一种前缀索引。这对于使用其他不能命中前缀索引的列作为条件进行的查询来说,效率上可能无法满足需求。因此,我们可以通过创建 Rollup 来人为的调整列顺序。
9.2.5.2 倒排索引
9.2.5.2.1 介绍
倒排索引,是信息检索领域常用的索引技术,将文本分割成一个个词,构建 词 -> 文档编号 的索引,可以快速查找一个词在哪些文档出现。
9.2.5.2.2 原理
Doris使用CLucene作为底层的倒排索引库。CLucene是一个用C++实现的高性能、稳定的Lucene倒排索引库。Doris进一步优化了CLucene,使得它更简单、更快、更适合数据库场景。在Doris的倒排索引实现中,table的一行对应一个文档、一列对应文档中的一个字段,因此利用倒排索引可以根据关键词快速定位包含它的行,达到WHERE子句加速的目的。与Doris中其他索引不同的是,在存储层倒排索引使用独立的文件,跟segment文件有逻辑对应关系、但存储的文件相互独立。这样的好处是可以做到创建、删除索引不用重写tablet和segment文件,大幅降低处理开销。
9.2.5.2.3 功能
- 支持字符串全文检索,包括同时匹配多个关键字MATCH_ALL、匹配任意一个关键字MATCH_ANY。
- 支持字符串数组类型的全文检索。
- 支持英文、中文分词。
- 支持字符串、数值、日期时间类型的 =, !=, >, >=, <, <= 快速过滤。
- 字符串、数字、日期时间数组类型的 =, !=, >, >=, <, <=。
- 索引对OR NOT逻辑的下推。
- 多个条件的任意AND OR NOT组合。
- 在创建表上定义倒排索引。
- 在已有的表上增加倒排索引,而且支持增量构建倒排索引,无需重写表中的已有数据。
- 删除已有表上的倒排索引,无需重写表中的已有数据。
9.2.5.2.4 语法
- USING INVERTED 是必须的,用于指定索引类型是倒排索引。
- PROPERTIES 是可选的,用于指定倒排索引的额外属性,目前有一个属性parser指定分词器。
- 默认不指定代表不分词。
- english是英文分词,适合被索引列是英文的情况,用空格和标点符号分词,性能高。
- chinese是中文分词,适合被索引列有中文或者中英文混合的情况,采用jieba分词库,性能比english分词低。
- COMMENT 是可选的,用于指定注释。
9.2.5.2.5 示例
# 创建表的时候添加索引
CREATE TABLE table_name
(
columns_difinition,
INDEX idx_name1(column_name1) USING INVERTED [PROPERTIES("parser" = "english|chinese")] [COMMENT 'comment']
INDEX idx_name2(column_name2) USING INVERTED [PROPERTIES("parser" = "english|chinese")] [COMMENT 'comment']
)
table_properties;
# 已有表增加倒排索引
CREATE INDEX idx_name ON table_name(column_name) USING INVERTED [PROPERTIES("parser" = "english|chinese")] [COMMENT 'comment'];
ALTER TABLE table_name ADD INDEX idx_name(column_name) USING INVERTED [PROPERTIES("parser" = "english|chinese")] [COMMENT 'comment'];
# 删除倒排索引
DROP INDEX idx_name ON table_name;
ALTER TABLE table_name DROP INDEX idx_name;
# 利用倒排索引加速查询
# logmsg中包含keyword1的行
SELECT * FROM table_name WHERE logmsg MATCH_ANY 'keyword1';
# logmsg中包含keyword1或者keyword2的行,后面还可以添加多个keyword
SELECT * FROM table_name WHERE logmsg MATCH_ANY 'keyword2 keyword2';
# logmsg中同时包含keyword1和keyword2的行,后面还可以添加多个keyword。
SELECT * FROM table_name WHERE logmsg MATCH_ALL 'keyword2 keyword2';
# 普通等值、范围、IN、NOT IN,正常的SQL语句即可
SELECT * FROM table_name WHERE id = 123;
SELECT * FROM table_name WHERE ts > '2023-01-01 00:00:00';
SELECT * FROM table_name WHERE op_type IN ('add', 'delete');
9.2.5.3 bloomfilter索引
9.2.5.3.1 介绍
BloomFilter是由Bloom在1970年提出的一种多哈希函数映射的快速查找算法。通常应用在一些需要快速判断某个元素是否属于集合,但是并不严格要求100%正确的场合。
布隆过滤器实际上是由一个超长的二进制位数组和一系列的哈希函数组成。二进制位数组初始全部为0,当给定一个待查询的元素时,这个元素会被一系列哈希函数计算映射出一系列的值,所有的值在位数组的偏移量处置为1。
下图所示出一个 m=18, k=3 (m是该Bit数组的大小,k是Hash函数的个数)的Bloom Filter示例。集合中的 x、y、z 三个元素通过 3 个不同的哈希函数散列到位数组中。当查询元素w时,通过Hash函数计算之后因为有一个比特为0,因此w不在该集合中,如果通过Hash函数计算后索引比特都是1,则这个元素可能存在。
Doris的BloomFilter索引可以通过建表的时候指定,或者通过表的ALTER操作来完成。Bloom Filter本质上是一种位图结构,用于快速的判断一个给定的值是否在一个集合中。这种判断会产生小概率的误判。即如果返回false,则一定不在这个集合内。而如果范围true,则有可能在这个集合内。
BloomFilter索引也是以Block为粒度创建的。每个Block中,指定列的值作为一个集合生成一个BloomFilter索引条目,用于在查询是快速过滤不满足条件的数据。

9.2.5.3.2 特点
- 空间效率高的概率型数据结构,用来检查一个元素是否在一个集合中。
- 对于一个元素检测是否存在的调用,BloomFilter会告诉调用者两个结果之一:可能存在或者一定不存在。
- 缺点是存在误判,告诉你可能存在,不一定真实存在。
9.2.5.3.3 使用场景
- 首先BloomFilter适用于非前缀过滤。
- 查询会根据该列高频过滤,而且查询条件大多是 in 和 = 过滤。
- BloomFilter适用于高基数列。比如UserID。因为如果创建在低基数的列上,比如 “性别” 列,则每个Block几乎都会包含所有取值,导致BloomFilter索引失去意义。
9.2.5.3.4 注意事项
- 不支持对Tinyint、Float、Double 类型的列建Bloom Filter索引。
- Bloom Filter索引只对 in 和 = 过滤查询有加速效果。
- 如果要查看某个查询是否命中了Bloom Filter索引,可以通过查询的Profile信息查看。
9.2.5.3.5 语法
BloomFilter索引的创建是通过在建表语句的PROPERTIES里加上"bloom_filter_columns"=“k1,k2,k3”,这个属性,k1,k2,k3是你要创建的BloomFilter索引的Key列名称。
# 查看BloomFilter索引
show create table table_name;
# 删除BloomFilter索引
alter table table_name set ("bloom_filter_columns" = "");
# 修改BloomFilter索引
alter table table_name set ("bloom_filter_columns" = "k1,k3");
9.2.5.4 ngram bloomfilter索引
9.2.5.4.1 特点
- 为了提升like的查询性能,增加了NGram BloomFilter索引,其实现主要参照了ClickHouse的ngrambf。
- NGram BloomFilter只支持字符串列。
- NGram BloomFilter索引和BloomFilter索引为互斥关系,即同一个列只能设置两者中的一个。
- NGram大小和BloomFilter的字节数,可以根据实际情况调优,如果NGram比较小,可以适当增加BloomFilter大小。
- 如果要查看某个查询是否命中了NGram Bloom Filter索引,可以通过查询的Profile信息查看。
9.2.5.4.2 语法
- NGram BloomFilter索引和倒排索引类似,创建索引的时候USING INVERTED改为USING NGRAM_BF ,有两个参数需要设置:
- gram_size:gram的个数跟实际查询场景相关,通常设置为大部分查询字符串的长度。
- bf_size:bloom filter字节数,可以通过测试得出,通常越大过滤效果越好,可以从256开始进行验证测试看看效果。当然字节数越大也会带来索引存储、内存cost上升。如果数据基数比较高,字节数可以不用设置过大,如果基数不是很高,可以通过增加字节数来提升过滤效果。
CREATE INDEX idx_ngrambf ON table_name(column_name) USING NGRAM_BF PROPERTIES("gram_size" = "3","bf_size"="256") [COMMENT 'comment'];
9.2.5.5 bitmap索引
9.2.5.5.1 特点
- 位图索引,是一种快速数据结构,能够加快查询速度。
- bitmap 索引仅在单列上创建。
- 目前索引仅支持 bitmap 类型的索引。
- bitmap 索引能够应用在 Duplicate、Uniqe 数据模型的所有列和 Aggregate模型的key列上。
- bitmap索引仅在 Segment V2 下生效。当创建 index 时,表的存储格式将默认转换为 V2 格式。
9.2.5.5.1 语法
Bitmap的索引语法和倒排索引类似,创建索引的时候USING INVERTED 改为USING BITMAP,bitmap索引没有相关参数。
9.2.6 Rollup
9。2.6.1 Rollup介绍
在 Doris 中,我们将用户通过建表语句创建出来的表称为 Base 表(Base Table)。Base 表中保存着按用户建表语句指定的方式存储的基础数据。在 Base 表之上,我们可以创建任意多个 ROLLUP 表。这些 ROLLUP 的数据是基于 Base 表产生的,并且在物理上是独立存储的。
ROLLUP 最根本的作用是提高某些查询的查询效率(无论是通过聚合来减少数据量,还是修改列顺序以匹配前缀索引)。
ROLLUP 是附属于 Base 表的,可以看做是 Base 表的一种辅助数据结构。用户可以在 Base 表的基础上,创建或删除 ROLLUP,但是不能在查询中显式的指定查询某 ROLLUP。是否命中 ROLLUP 完全由 Doris 系统自动决定。
ROLLUP 的数据是独立物理存储的。因此,创建的 ROLLUP 越多,占用的磁盘空间也就越大。同时对导入速度也会有影响(导入的ETL阶段会自动产生所有 ROLLUP 的数据),但是不会降低查询效率(只会更好)。
ROLLUP 的数据更新与 Base 表是完全同步的。用户无需关心这个问题。
ROLLUP 中列的聚合方式,与 Base 表完全相同。在创建 ROLLUP 无需指定,也不能修改。
查询能否命中 ROLLUP 的一个必要条件(非充分条件)是,查询所涉及的所有列(包括 select list 和 where 中的查询条件列等)都存在于该 ROLLUP 的列中。否则,查询只能命中 Base 表。
某些类型的查询(如 count(*))在任何条件下,都无法命中 ROLLUP。
可以通过 EXPLAIN your_sql; 命令获得查询执行计划,在执行计划中,查看是否命中 ROLLUP。
可以通过 DESC tbl_name ALL; 语句显示 Base 表和所有已创建完成的 ROLLUP。
在查询的时候要命中Rollup的话,需要查询或者子查询中涉及的所有列都存在一张独立的 Rollup 中。如果查询或者子查询中有 Join,则 Join 的类型需要是 Inner join。
在查询的时候具体命中哪个Rollup则根据前缀索引以及各个Rollup的数据条数判断。
9.2.6.2 Aggregate模型的Rollup
CREATE TABLE IF NOT EXISTS example_db.example_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`timestamp` DATETIME NOT NULL COMMENT '数据灌入的时间戳',
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
AGGREGATE KEY(`user_id`, `date`, `timestamp`,`city`, `age`, `sex`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
ROLLUP(
r1(`user_id`,`cost`),
r2(`city`,`age`,`cost`,`max_dwell_time`,`min_dwell_time`)
)
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
SELECT user_id, sum(cost) FROM table GROUP BY user_id;# 会命中r1那个rollup
SELECT city, age, sum(cost), max(max_dwell_time), min(min_dwell_time) FROM table GROUP BY city, age; # 会命中r2那个rollup
SELECT city, sum(cost), max(max_dwell_time), min(min_dwell_time) FROM table GROUP BY city;# 会命中r2那个rollup
SELECT city, age, sum(cost), min(min_dwell_time) FROM table GROUP BY city, age; # 会命中r2那个rollup
# 示例
+-------------+-------+--------------+------+-------+---------+-------+
| IndexName | Field | Type | Null | Key | Default | Extra |
+-------------+-------+--------------+------+-------+---------+-------+
| test_rollup | k1 | TINYINT | Yes | true | N/A | |
| | k2 | SMALLINT | Yes | true | N/A | |
| | k3 | INT | Yes | true | N/A | |
| | k4 | BIGINT | Yes | true | N/A | |
| | k5 | DECIMAL(9,3) | Yes | true | N/A | |
| | k6 | CHAR(5) | Yes | true | N/A | |
| | k7 | DATE | Yes | true | N/A | |
| | k8 | DATETIME | Yes | true | N/A | |
| | k9 | VARCHAR(20) | Yes | true | N/A | |
| | k10 | DOUBLE | Yes | false | N/A | MAX |
| | k11 | FLOAT | Yes | false | N/A | SUM |
| | | | | | | |
| rollup2 | k1 | TINYINT | Yes | true | N/A | |
| | k2 | SMALLINT | Yes | true | N/A | |
| | k3 | INT | Yes | true | N/A | |
| | k10 | DOUBLE | Yes | false | N/A | MAX |
| | k11 | FLOAT | Yes | false | N/A | SUM |
| | | | | | | |
| rollup1 | k1 | TINYINT | Yes | true | N/A | |
| | k2 | SMALLINT | Yes | true | N/A | |
| | k3 | INT | Yes | true | N/A | |
| | k4 | BIGINT | Yes | true | N/A | |
| | k5 | DECIMAL(9,3) | Yes | true | N/A | |
| | k10 | DOUBLE | Yes | false | N/A | MAX |
| | k11 | FLOAT | Yes | false | N/A | SUM |
+-------------+-------+--------------+------+-------+---------+-------+
SELECT SUM(k11) FROM test_rollup WHERE k1 = 10 AND k2 > 200 AND k3 in (1,2,3);
首先判断查询是否可以命中聚合的 Rollup表,经过查上面的图是可以的,然后条件中含有 k1,k2,k3 三个条件,这三个条件 test_rollup、rollup1、rollup2 的前三列都含有,所以前缀索引长度一致,然后比较行数显然 rollup2 的聚合程度最高行数最少所以选取 rollup2。
9.2.6.3 Unique模型的Rollup
因为Unique 数据模型表中的所有 Value 列都是 REPLACE 聚合类型。所以Rollup仅仅是作为调整Key的顺序以命中前缀索引。
9.2.6.4 Duplicate模型的Rollup
因为 Duplicate 模型没有聚合的语意。没有Key列也没有Value列,所以该模型中的 ROLLUP仅仅是作为调整所有列的顺序以命中前缀索引的作用。
因为建表时已经指定了列顺序,所以一个表只有一种前缀索引。这对于使用其他不能命中前缀索引的列作为条件进行的查询来说,效率上可能无法满足需求。因此,我们可以通过创建 ROLLUP 来人为的调整列顺序。
9.2.7 properties
# 默认三副本机制。按照资源标签来指定副本分布。
"replication_allocation" = "tag.location.default:3"
# 用于声明表数据的初始存储介质
"storage_medium" = "SSD"
# 用于设定到期时间
"storage_cooldown_time" = "2020-11-20 00:00:00"
# 如上两个参数设置表示:数据存放在 SSD 中,并且在 2020-11-20 00:00:00 到期后,会自动迁移到 HDD 存储上。
# 当需要使用 Colocation Join 功能时,使用这个参数设置 Colocation Group。可以查看9.7.4.1相关内容。
"colocate_with" = "group1"
# 用户指定需要添加 Bloom Filter 索引的列名称列表。各个列的 Bloom Filter 索引是独立的,并不是组合索引。
"bloom_filter_columns" = "k1, k2, k3"
# Doris 表的默认压缩方式是 LZ4。1.1版本后,支持将压缩方式指定为ZSTD以获得更高的压缩比。
"compression"="zstd"
# 当使用 UNIQUE KEY 模型时,可以指定一个sequence列,当KEY列相同时,将按照 sequence 列进行 REPLACE(较大值替换较小值,否则无法替换)。该列可以为整型和时间类型,sequence列可以查看Unique模型相关内容
"function_column.sequence_col" = 'column_name'
# 是否使用light schema change优化。如果设置成 true, 对于schema change的操作,可以更快地,同步地完成。该功能在 1.2.1 及之后版本默认开启。
"light_schema_change" = 'true'
# 是否对这个表禁用自动compaction。如果这个属性设置成 true, 后台的自动compaction进程会跳过这个表的所有tablet。
"disable_auto_compaction" = "false"
# 动态分区的相关参数可以查看9.2.3.1分区目录。
9.2.8 建表示例
# 创建一个明细模型的表,分区,指定排序列,设置副本数为1
CREATE TABLE example_db.table_hash
(
k1 DATE,
k2 DECIMAL(10, 2) DEFAULT "10.5",
k3 CHAR(10) COMMENT "string column",
k4 INT NOT NULL DEFAULT "1" COMMENT "int column"
)
DUPLICATE KEY(k1, k2)
COMMENT "my first table"
PARTITION BY RANGE(k1)
(
PARTITION p1 VALUES LESS THAN ("2020-02-01"),
PARTITION p2 VALUES LESS THAN ("2020-03-01"),
PARTITION p3 VALUES LESS THAN ("2020-04-01")
)
DISTRIBUTED BY HASH(k1) BUCKETS 32
PROPERTIES (
"replication_allocation" = "tag.location.default:1"
);
# 创建一个主键唯一模型的表,设置初始存储介质和冷却时间
CREATE TABLE example_db.table_hash
(
k1 BIGINT,
k2 LARGEINT,
v1 VARCHAR(2048),
v2 SMALLINT DEFAULT "10"
)
UNIQUE KEY(k1, k2)
DISTRIBUTED BY HASH (k1, k2) BUCKETS 32
PROPERTIES(
"storage_medium" = "SSD",
"storage_cooldown_time" = "2015-06-04 00:00:00"
);
# 创建一个聚合模型表,使用固定范围分区描述
CREATE TABLE table_range
(
k1 DATE,
k2 INT,
k3 SMALLINT,
v1 VARCHAR(2048) REPLACE,
v2 INT SUM DEFAULT "1"
)
AGGREGATE KEY(k1, k2, k3)
PARTITION BY RANGE (k1, k2, k3)
(
PARTITION p1 VALUES [("2014-01-01", "10", "200"), ("2014-01-01", "20", "300")),
PARTITION p2 VALUES [("2014-06-01", "100", "200"), ("2014-07-01", "100", "300"))
)
DISTRIBUTED BY HASH(k2) BUCKETS 32
# 创建一个包含 HLL 和 BITMAP 列类型的聚合模型表
CREATE TABLE example_db.example_table
(
k1 TINYINT,
k2 DECIMAL(10, 2) DEFAULT "10.5",
v1 HLL HLL_UNION,
v2 BITMAP BITMAP_UNION
)
ENGINE=olap
AGGREGATE KEY(k1, k2)
DISTRIBUTED BY HASH(k1) BUCKETS 32
# 创建两张同一个 Colocation Group 自维护的表。
CREATE TABLE t1 (
id int(11) COMMENT "",
value varchar(8) COMMENT ""
)
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 10
PROPERTIES (
"colocate_with" = "group1"
);
CREATE TABLE t2 (
id int(11) COMMENT "",
value1 varchar(8) COMMENT "",
value2 varchar(8) COMMENT ""
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 10
PROPERTIES (
"colocate_with" = "group1"
);
# 创建一个带有 bitmap 索引以及 bloom filter 索引的表
CREATE TABLE example_db.table_hash
(
k1 TINYINT,
k2 DECIMAL(10, 2) DEFAULT "10.5",
v1 CHAR(10) REPLACE,
v2 INT SUM,
INDEX k1_idx (k1) USING BITMAP COMMENT 'my first index'
)
AGGREGATE KEY(k1, k2)
DISTRIBUTED BY HASH(k1) BUCKETS 32
PROPERTIES (
"bloom_filter_columns" = "k2"
);
# 创建一个动态分区表。该表每天提前创建3天的分区,并删除3天前的分区。
CREATE TABLE example_db.dynamic_partition
(
k1 DATE,
k2 INT,
k3 SMALLINT,
v1 VARCHAR(2048),
v2 DATETIME DEFAULT "2014-02-04 15:36:00"
)
DUPLICATE KEY(k1, k2, k3)
PARTITION BY RANGE (k1) ()
DISTRIBUTED BY HASH(k2) BUCKETS 32
PROPERTIES(
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.start" = "-3",
"dynamic_partition.end" = "3",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "32"
);
# 创建一个带有物化视图(ROLLUP)的表。
CREATE TABLE example_db.rolup_index_table
(
event_day DATE,
siteid INT DEFAULT '10',
citycode SMALLINT,
username VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(event_day, siteid, citycode, username)
DISTRIBUTED BY HASH(siteid) BUCKETS 10
ROLLUP (
r1(event_day,siteid),
r2(event_day,citycode),
r3(event_day)
)
PROPERTIES("replication_num" = "3");
# 通过 replication_allocation 属性设置表的副本。
CREATE TABLE example_db.table_hash
(
k1 TINYINT,
k2 DECIMAL(10, 2) DEFAULT "10.5"
)
DISTRIBUTED BY HASH(k1) BUCKETS 32
PROPERTIES (
"replication_allocation"="tag.location.group_a:1, tag.location.group_b:2"
);
# 通过storage_policy属性设置表的冷热分离数据迁移策略
CREATE TABLE IF NOT EXISTS create_table_use_created_policy
(
k1 BIGINT,
k2 LARGEINT,
v1 VARCHAR(2048)
)
UNIQUE KEY(k1)
DISTRIBUTED BY HASH (k1) BUCKETS 3
PROPERTIES(
"storage_policy" = "test_create_table_use_policy",
"replication_num" = "1"
);
# 为表的分区添加冷热分离数据迁移策略
CREATE TABLE create_table_partion_use_created_policy
(
k1 DATE,
k2 INT,
V1 VARCHAR(2048) REPLACE
) PARTITION BY RANGE (k1) (
PARTITION p1 VALUES LESS THAN ("2022-01-01") ("storage_policy" = "test_create_table_partition_use_policy_1" ,"replication_num"="1"),
PARTITION p2 VALUES LESS THAN ("2022-02-01") ("storage_policy" = "test_create_table_partition_use_policy_2" ,"replication_num"="1")
) DISTRIBUTED BY HASH(k2) BUCKETS 1;
# 批量创建分区
CREATE TABLE create_table_multi_partion_date
(
k1 DATE,
k2 INT,
V1 VARCHAR(20)
) PARTITION BY RANGE (k1) (
FROM ("2000-11-14") TO ("2021-11-14") INTERVAL 1 YEAR,
FROM ("2021-11-14") TO ("2022-11-14") INTERVAL 1 MONTH,
FROM ("2022-11-14") TO ("2023-01-03") INTERVAL 1 WEEK,
FROM ("2023-01-03") TO ("2023-01-14") INTERVAL 1 DAY,
PARTITION p_20230114 VALUES [('2023-01-14'), ('2023-01-15'))
) DISTRIBUTED BY HASH(k2) BUCKETS 1
PROPERTIES(
"replication_num" = "1"
);
9.3 数据更新
9.3.1 特点
- 数据更新对Doris的版本有限制,只能在Doris Version 0.15.x + 才可以使用。
- update 命令只能在 Unique 数据模型的表中执行。并且只能更新Value列。
- 对满足某些条件的行,修改他的取值。
- 点更新,小范围更新,待更新的行最好是整个表的非常小的一部分。
- 由于表是Unique模型,如果开启了写入合并的话,写入数据后会和之前的旧数据进行合并。
9.3.2 基本原理
利用查询引擎自身的 where 过滤逻辑,从待更新表中筛选出需要被更新的行。再利用 Unique 模型自带的 Value 列新数据替换旧数据的逻辑,将待更新的行变更后,再重新插入到表中,从而实现行级别更新。
9.3.3 性能
待更新的行数:待更新的行数越多,Update 语句的速度就会越慢。这和导入的原理是一致的。 Doris 的更新比较合适偶发更新的场景,比如修改个别行的值。 Doris 并不适合大批量的修改数据。大批量修改会使得 Update 语句运行时间很久。
condition 的检索效率:Doris 的 Update 实现原理是先将满足 condition 的行读取处理,所以如果 condition 的检索效率高,则 Update 的速度也会快。 condition 列最好能命中索引或者分区分桶裁剪,这样 Doris 就不需要扫全表,可以快速定位到需要更新的行,从而提升更新效率。 强烈不推荐 condition 列中包含 UNIQUE 模型的 value 列。
9.3.4 并发控制
默认情况下,并不允许同一时间对同一张表并发进行多个 Update 操作。主要原因是,Doris 目前支持的是行更新,这意味着,即使用户声明的是 SET v2 = 1,实际上,其他所有的 Value 列也会被覆盖一遍(尽管值没有变化)。这就会存在一个问题,如果同时有两个 Update 操作对同一行进行更新,那么其行为可能是不确定的,也就是可能存在脏数据。但在实际应用中,如果用户自己可以保证即使并发更新,也不会同时对同一行进行操作的话,就可以手动打开并发限制。通过修改 FE 配置 enable_concurrent_update,当配置值为 true 时,则对更新并发无限制。
由于 Doris 目前支持的是行更新,并且采用的是读取后再写入的两步操作,则如果 Update 语句和其他导入或 Delete 语句刚好修改的是同一行时,存在不确定的数据结果。所以用户在使用的时候,一定要注意用户侧自己进行 Update 语句和其他 DML 语句的并发控制。
9.3.5 更新步骤
- 根据condition检索具体的行或者具体的某些行。
- 变更这些行的列的值。
- 将更新后的行再插入回表中,从而达到更新的效果。
9.4 数据导入
9.4.1 原子性保证
Doris 中的所有导入操作都有原子性保证,即一个导入作业中的数据要么全部成功,要么全部失败。不会出现仅部分数据导入成功的情况。在 BROKER LOAD 中我们也可以实现多表的原子性导入。对于表所附属的物化视图,也同时保证和基表的原子性和一致性。
9.4.2 Label机制
Doris 的导入作业都可以设置一个 Label。这个 Label 通常是用户自定义的、具有一定业务逻辑属性的字符串。Label 的主要作用是唯一标识一个导入任务,并且能够保证相同的 Label 仅会被成功导入一次。Label 机制可以保证导入数据的不丢不重。如果上游数据源能够保证 At-Least-Once 语义,则配合 Doris 的 Label 机制,能够保证 Exactly-Once 语义。Label 在一个数据库下具有唯一性。Label 的保留期限默认是 3 天。即 3 天后,已完成的 Label 会被自动清理,之后 Label 可以被重复使用。
###9.4.3 Label机制最佳实践
Label通常被设置为业务逻辑+时间的格式。如:business_20220330_125000。这个Label通常用于表示:这个business业务在2022-03-30 12:50:00 产生的一批数据。通过这种Label设定,业务上可以通过 Label 查询导入任务状态,来明确的获知该时间点批次的数据是否已经导入成功。如果没有成功,则可以使用这个Label继续重试导入。
9.4.4 STREAM LOAD
9.4.4.1 介绍
Stream load 是一个同步的导入方式,用户通过发送 HTTP 协议发送请求将本地文件或数据流导入到 Doris 中。Stream load 同步执行导入并返回导入结果。用户可直接通过请求的返回体判断本次导入是否成功。Stream load 主要适用于导入本地文件,或通过程序导入数据流中的数据。
9.4.4.2 基本原理
下图展示了 Stream load 的主要流程,省略了一些导入细节。
^ +
| |
| | 1A. User submit load to FE
| |
| +--v-----------+
| | FE |
5. Return result to user | +--+-----------+
| |
| | 2. Redirect to BE
| |
| +--v-----------+
+---+Coordinator BE| 1B. User submit load to BE
+-+-----+----+-+
| | |
+-----+ | +-----+
| | | 3. Distrbute data
| | |
+-v-+ +-v-+ +-v-+
|BE | |BE | |BE |
+---+ +---+ +---+
- Stream load 中,Doris 会选定一个BE节点作为 Coordinator 节点。该节点负责接数据并分发数据到其他数据节点。
- 用户通过 HTTP 协议提交导入命令。如果提交到 FE,则 FE 会通过 HTTP redirect 指令将请求转发给某一个 BE。用户也可以直接提交导入命令给某一指定 BE。
- 导入的最终结果由 Coordinator BE 返回给用户。
9.4.4.3 支持的数据格式
- CSV(文本)、JSON、PARQUET 和 ORC
9.4.4.4 操作
Stream Load 通过 HTTP 协议提交和传输数据。这里通过 curl 命令展示如何提交导入。
curl --location-trusted -u user:passwd [-H ""]... -T data.file -XPUT http://fe_host:http_port/api/{db}/{table}/_stream_load
该语句用于向指定的 table 导入数据,这种导入方式是同步导入。这种导入方式仍然能够保证一批导入任务的原子性,要么全部数据导入成功,要么全部失败。该操作会同时更新和此 base table 相关的 rollup table 的数据。这是一个同步操作,整个数据导入工作完成后返回给用户导入结果。
9.4.4.4.1 参数说明
# Doris 系统会根据签名验证用户身份和导入权限。这里的user:passwd为doris数据库的登录用户以及密码
user/passwd
# 用户可以通过HTTP的Header部分来传入导入参数
# 导入任务的标识。每个导入任务,都有一个在单 database 内部唯一的 label。label 是用户在导入命令中自定义的名称。通过这个 label,用户可以查看对应导入任务的执行情况。label 的另一个作用,是防止用户重复导入相同的数据。强烈推荐用户同一批次数据使用相同的 label。这样同一批次数据的重复请求只会被接受一次,保证了 At-Most-Once当 label 对应的导入作业状态为 CANCELLED 时,该 label 可以再次被使用。
label
# 用于指定导入文件中的列分隔符,默认为\t。如果是不可见字符,则需要加\x作为前缀,使用十六进制来表示分隔符。如hive文件的分隔符\x01,需要指定为-H "column_separator:\x01"。可以使用多个字符的组合作为列分隔符。
column_separator
# 用于指定导入文件中的换行符,默认为\n。可以使用做多个字符的组合作为换行符。
line_delimiter
# 用于指定导入文件中的列和 table 中的列的对应关系。如果源文件中的列正好对应表中的内容,那么是不需要指定这个字段的内容的。有如下几种形式。
# 1. 原始数据有三列(src_c1,src_c2,src_c3), 目标Doris表也有三列(dst_c1,dst_c2,dst_c3)顺序一一对应,则写法如下:
columns: dst_c1, dst_c2, dst_c3
# 2. 原始数据有三列(src_c1,src_c2,src_c3), 目标Doris表也有三列(dst_c1,dst_c2,dst_c3),如果原始表的src_c1列对应目标表dst_c2列,原始表的src_c2列对应目标表dst_c3列,原始表的src_c3列对应目标表dst_c1列,则写法如下:columns: dst_c2, dst_c3, dst_c1。
# 3. 原始数据有四列(src_c1,src_c2,src_c3,src_c4), 目标Doris表只有三列(dst_c1,dst_c2,dst_c3),前三列数据一一对应,但是源数据有多余的一列;则写法如下:columns: dst_c1,dst_c2,dst_c3,xxx。
# 4. 原始数据有三列(src_c1,src_c2,src_c3), 目标Doris表有四列(dst_c1,dst_c2,dst_c3,dst_c4),前三列一一对应,dst_c4希望用默认值填充;则写法如下:columns: dst_c1,dst_c2,dst_c3。如果有默认值则会填充默认值,如果没有默认值但是可以为null,则会填充null值,否则导入作业会报错。
# 5. 原始文件有两列,目标表也有两列(c1,c2)但是原始文件的两列均需要经过函数变换才能对应目标表的两列,则写法如下:columns: tmp_c1, tmp_c2, c1 = year(tmp_c1), c2 = month(tmp_c2)。其中 tmp_*是一个占位符,代表的是原始文件中的两个原始列。
columns
# 导入任务指定的过滤条件。Stream load 支持对原始数据指定 where 语句进行过滤。被过滤的数据将不会被导入,也不会参与 filter ratio 的计算,但会被计入num_rows_unselected。
where
# 导入任务的最大容忍率,默认为0容忍,取值范围是0~1。当导入的错误率超过该值,则导入失败。如果用户希望忽略错误的行,可以通过设置这个参数大于 0,来保证导入可以成功。数据不规范不包括通过 where 条件过滤掉的行。dpp.abnorm.ALL 表示数据质量不合格的行数。如类型错误、精度错误、字符串长度超长、文件列数不匹配等数据格式问题,以及因没有对应的分区而被过滤掉的数据行。dpp.norm.ALL 指的是导入过程中正确数据的条数。可以通过 SHOW LOAD 命令查询导入任务的正确数据量。则当(dpp.abnorm.ALL / (dpp.abnorm.ALL + dpp.norm.ALL ) ) > max_filter_ratio,导入任务失败。数据回滚。
max_filter_ratio
# 用于指定这次导入所设计的partition。如果用户能够确定数据对应的partition,推荐指定该项。不满足这些分区的数据将被过滤掉。这些数据将计入 dpp.abnorm.ALL,如果这时候设置的容忍率为0,则导入失败。比如指定导入到p1, p2分区,-H "partitions: p1, p2"
partitions
# 指定导入的超时时间。单位秒。默认是 600 秒。可设置范围为 1 秒 ~ 259200 秒。
timeout
# 用户指定此次导入是否开启严格模式,默认为关闭。开启方式为 -H "strict_mode: true"。严格模式的意思是对于导入过程中的列类型转换进行严格过滤。严格过滤的策略如下:
# 原始数据并不为null,但是可能因为原始数据和目标数据的类型不同或者别的情况导致类型转换失败后结果为null的这一类数据,严格模式会对这类数据进行过滤,如果是由函数计算得出的null值并不会进行过滤。如果类型转换成功,但是因为Doris中的表的数据范围设置的小而不能存放,严格模式也不会进行过滤。这类数据会在其他处理流程的时候进行过滤。
strict_mode
# 指定本次导入所使用的时区。默认为东八区。该参数会影响所有导入涉及的和时区有关的函数结果。
timezone
# 导入内存限制。默认为 2GB。单位为字节。
exec_mem_limit
# 指定导入数据格式,支持csv、json、 csv_with_names(支持csv文件行首过滤)、csv_with_names_and_types(支持csv文件前两行过滤)、parquet、orc,默认是csv。
format
# 当 enable_profile 为 true 时,Stream Load profile将会打印到日志中。否则不会打印。
enable_profile
# 整型,用于设置发送批处理数据的并行度,如果并行度的值超过 BE 配置中的 max_send_batch_parallelism_per_job,那么作为协调点的 BE 将使用 max_send_batch_parallelism_per_job 的值。
send_batch_parallelism
# 用于指定导入数据中包含的隐藏列,在Header中不包含columns时生效,多个hidden column用逗号分割。
# hidden_columns: __DORIS_DELETE_SIGN__,__DORIS_SEQUENCE_COL__ 。系统会使用用户指定的数据导入数据。在上述用例中,导入数据中最后一列数据为__DORIS_SEQUENCE_COL__。
hidden_columns
# 指定文件的压缩格式。目前只支持 csv 文件的压缩。支持 gz, lzo, bz2, lz4, lzop, deflate 压缩格式。
compress_type
# 布尔类型,默认值为 false,为 true 时表示裁剪掉 csv 文件每个字段最外层的双引号。
trim_double_quotes
# 整数类型, 默认值为0, 含义为跳过csv文件的前几行. 当设置format设置为 csv_with_names 或、csv_with_names_and_types 时, 该参数会失效.
skip_lines
# 字符串类型, 默认值为空. 给任务增加额外的信息.
comment
# Stream load 导入可以开启两阶段事务提交模式:在Stream load过程中,数据写入完成即会返回信息给用户,此时数据不可见,事务状态为PRECOMMITTED,用户手动触发commit操作之后,数据才可见。
two_phase_commit
# 数据的合并类型,一共支持三种类型APPEND、DELETE、MERGE 其中,APPEND是默认值,表示这批数据全部需要追加到现有数据中,DELETE 表示删除与这批数据key相同的所有行,MERGE 语义 需要与delete 条件联合使用,表示满足delete 条件的数据按照DELETE 语义处理其余的按照APPEND 语义处理, 示例:-H "merge_type: MERGE" -H "delete: flag=1"
merge_type
# 布尔类型,为true表示支持一个任务只导入数据到对应分区的一个 tablet,默认值为 false,该参数只允许在对带有 random 分桶的 olap 表导数的时候设置。
load_to_single_tablet
# json相关的参数
# 布尔类型,为true表示json将以第一行为schema 进行解析,开启这个选项可以提高 json 导入效率,但是要求所有json 对象的key的顺序和第一行一致, 默认为false,仅用于json 格式
fuzzy_parse
# 布尔类型,为true表示在解析json数据时会将数字类型转为字符串,然后在确保不会出现精度丢失的情况下进行导入。
num_as_string
# 布尔类型,为true表示支持每行读取一个json对象,默认值为false。
read_json_by_line
# json_root为合法的jsonpath字符串,用于指定json document的根节点,默认值为""。
json_root
# 导入json方式分为:简单模式和匹配模式。简单模式:没有设置jsonpaths参数即为简单模式,这种模式下要求json数据是对象类型,例如:{"k1":1, "k2":2, "k3":"hello"},其中k1,k2,k3是列名字。匹配模式:用于json数据相对复杂,需要通过jsonpaths参数匹配对应的value。例如-H "jsonpaths: [\"$.k2\", \"$.k1\"]"。
jsonpaths
# 布尔类型,为true表示json数据以数组对象开始且将数组对象中进行展平,默认值是false。例如:
[{"k1" : 1, "v1" : 2},{"k1" : 3, "v1" : 4}]
# 当strip_outer_array为true,最后导入到doris中会生成两行数据。
strip_outer_array
9.4.4.4.2 示例
# 本地文件'testData'中的数据导入到数据库'testDb'中'testTbl'的表,使用Label用于去重。指定超时时间为 100 秒
curl --location-trusted -u root -H "label:123" -H "timeout:100" -T testData http://host:port/api/testDb/testTbl/_stream_load
# 将本地文件'testData'中的数据导入到数据库'testDb'中'testTbl'的表,使用Label用于去重, 并且只导入k1等于20180601的数据
curl --location-trusted -u root -H "label:123" -H "where: k1=20180601" -T testData http://host:port/api/testDb/testTbl/_stream_load
# 将本地文件'testData'中的数据导入到数据库'testDb'中'testTbl'的表, 允许20%的错误率(用户是defalut_cluster中的
curl --location-trusted -u root -H "label:123" -H "max_filter_ratio:0.2" -T testData http://host:port/api/testDb/testTbl/_stream_load
# 将本地文件'testData'中的数据导入到数据库'testDb'中'testTbl'的表, 允许20%的错误率,并且指定文件的列名(用户是defalut_cluster中的)
curl --location-trusted -u root -H "label:123" -H "max_filter_ratio:0.2" -H "columns: k2, k1, v1" -T testData http://host:port/api/testDb/testTbl/_stream_load
# 将本地文件'testData'中的数据导入到数据库'testDb'中'testTbl'的表中的p1, p2分区, 允许20%的错误率。
curl --location-trusted -u root -H "label:123" -H "max_filter_ratio:0.2" -H "partitions: p1, p2" -T testData http://host:port/api/testDb/testTbl/_stream_load
# 使用streaming方式导入。
seq 1 10 | awk '{OFS="\t"}{print $1, $1 * 10}' | curl --location-trusted -u root -T - http://host:port/api/testDb/testTbl/_stream_load
# 导入含有HLL列的表,可以是表中的列或者数据中的列用于生成HLL列,也可使用hll_empty补充数据中没有的列
curl --location-trusted -u root -H "columns: k1, k2, v1=hll_hash(k1), v2=hll_empty()" -T testData http://host:port/api/testDb/testTbl/_stream_load
# 导入数据进行严格模式过滤,并设置时区为 Africa/Abidjan
curl --location-trusted -u root -H "strict_mode: true" -H "timezone: Africa/Abidjan" -T testData http://host:port/api/testDb/testTbl/_stream_load
# 导入含有BITMAP列的表,可以是表中的列或者数据中的列用于生成BITMAP列,也可以使用bitmap_empty填充空的Bitmap
curl --location-trusted -u root -H "columns: k1, k2, v1=to_bitmap(k1), v2=bitmap_empty()" -T testData http://host:port/api/testDb/testTbl/_stream_load
# 通过指定format=csv_with_names过滤首行导入
# id,name,age
# 1,doris,20
# 2,flink,10
curl --location-trusted -u root -T test.csv -H "label:1" -H "format:csv_with_names" -H "column_separator:," http://host:port/api/testDb/testTbl/_stream_load
# 导入数据到含有sequence列的UNIQUE_KEYS表中,会根据source_sequence字段进行筛选替换。
curl --location-trusted -u root -H "columns: k1,k2,source_sequence,v1,v2" -H "function_column.sequence_col: source_sequence" -T testData http://host:port/api/testDb/testTbl/_stream_load
# 将这批数据中与flag 列为ture 的数据相匹配的列删除,其他行正常追加
curl --location-trusted -u root: -H "column_separator:," -H "columns: siteid, citycode, username, pv, flag" -H "merge_type: MERGE" -H "delete: flag=1" -T testData http://host:port/api/testDb/testTbl/_stream_load
# 删除与这批导入key 相同的数据
curl --location-trusted -u root -H "merge_type: DELETE" -T testData http://host:port/api/testDb/testTbl/_stream_load
# 简单模式,导入json数据。
# 表结构:category varchar(512) NULL COMMENT "", author varchar(512) NULL COMMENT "", title varchar(512) NULL COMMENT "", price double NULL COMMENT ""
# json数据格式:{"category":"C++","author":"avc","title":"C++ primer","price":895}
curl --location-trusted -u root -H "label:123" -H "format: json" -T testData http://host:port/api/testDb/testTbl/_stream_load # 为了提升吞吐量,支持一次性导入多条json数据,每行为一个json对象,默认使用\n作为换行符,需要将read_json_by_line设置为true,json数据格式如下:
#{"category":"C++","author":"avc","title":"C++ primer","price":89.5}
#{"category":"Java","author":"avc","title":"Effective Java","price":95}
#{"category":"Linux","author":"avc","title":"Linux kernel","price":195}
# 匹配模式,导入json数据。json数据格式:
[
{"category":"xuxb111","author":"1avc","title":"SayingsoftheCentury","price":895}, {"category":"xuxb222","author":"2avc","title":"SayingsoftheCentury","price":895},
{"category":"xuxb333","author":"3avc","title":"SayingsoftheCentury","price":895}
]
# 如果json数据是以数组开始,并且数组中每个对象是一条记录,则需要将strip_outer_array设置成true,表示展平数组。
# 如果json数据是以数组开始,并且数组中每个对象是一条记录,在设置jsonpath时,我们的ROOT节点实际上是数组中对象。
curl --location-trusted -u root -H "columns: category, price, author" -H "label:123" -H "format: json" -H "jsonpaths: [\"$.category\",\"$.price\",\"$.author\"]" -H "strip_outer_array: true" -T testData http://host:port/api/testDb/testTbl/_stream_load
# 用户指定json根节点 。json数据格式:
{
"RECORDS":[
{"category":"11","title":"SayingsoftheCentury","price":895,"timestamp":1589191587},
{"category":"22","author":"2avc","price":895,"timestamp":1589191487},
{"category":"33","author":"3avc","title":"SayingsoftheCentury","timestamp":1589191387}
]
}
curl --location-trusted -u root -H "columns: category, price, author" -H "label:123" -H "format: json" -H "jsonpaths: [\"$.category\",\"$.price\",\"$.author\"]" -H "strip_outer_array: true" -H "json_root: $.RECORDS" -T testData http://host:port/api/testDb/testTbl/_stream_load
# 发起stream load预提交操作
curl --location-trusted -u user:passwd -H "two_phase_commit:true" -T test.txt http://fe_host:http_port/api/{db}/{table}/_stream_load
# 对事务触发commit操作,commit 的时候可以省略 url 中的 {table}
curl -X PUT --location-trusted -u user:passwd -H "txn_id:18036" -H "txn_operation:commit" http://fe_host:http_port/api/{db}/{table}/_stream_load_2pc
# 对事务触发abort操作,abort 的时候可以省略 url 中的 {table}
curl -X PUT --location-trusted -u user:passwd -H "txn_id:18037" -H "txn_operation:abort" http://fe_host:http_port/api/{db}/{table}/_stream_load_2pc
9.4.4.5 返回结果
Stream Load 是一个同步导入过程,语句执行成功即代表数据导入成功。导入的执行结果会通过 HTTP 返回值同步返回。并以 Json 格式展示。示例如下:
{
"TxnId": 17,
"Label": "707717c0-271a-44c5-be0b-4e71bfeacaa5",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 5,
"NumberLoadedRows": 5,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 28,
"LoadTimeMs": 27,
"BeginTxnTimeMs": 0,
"StreamLoadPutTimeMs": 2,
"ReadDataTimeMs": 0,
"WriteDataTimeMs": 3,
"CommitAndPublishTimeMs": 18
}
- TxnId: 导入事务ID,由系统自动生成,全局唯一。
- Label: 导入Label,如果没有指定,则系统会生成一个 UUID。
- Status: 导入结果。有如下取值:
- Success:表示导入成功,并且数据已经可见。
- Publish Timeout:该状态也表示导入已经完成,只是数据可能会延迟可见。可能说明目前集群某些资源(如IO)紧张导致导入的数据无法最终生效。Publish Timeout 状态的导入任务已经成功,无需重试,但此时建议减缓或停止新导入任务的提交,并观察集群负载情况。
- Label Already Exists:Label 重复,需更换 Label。通过SHOW LOAD查看是否已经存在一个 FINISHED 导入的 Label 和用户申请创建的 Label 相同。或者是否是 Stream load 同一个作业被重复提交了。由于 Stream load 是 HTTP 协议提交创建导入任务,一般各个语言的 HTTP Client 均会自带请求重试逻辑。Doris 系统在接受到第一个请求后,已经开始操作 Stream load,但是由于没有及时返回给 Client 端结果, Client 端会发生再次重试创建请求的情况。这时候 Doris 系统由于已经在操作第一个请求,所以第二个请求已经就会被报 Label Already Exists 的情况。排查上述可能的方法:使用 Label 搜索 FE Master 的日志,看是否存在同一个 Label 出现了两次 redirect load action to destination 的日志。如果有就说明,请求被 Client 端重复提交了。建议用户根据当前请求的数据量,计算出大致导入的时间,并根据导入超时时间,将Client 端的请求超时间改成大于导入超时时间的值,避免请求被 Client 端多次提交。
- Fail:导入失败。需根据具体原因查看问题。解决后,可以使用相同的 Label 重试。
- Message 导入错误信息。
- NumberTotalRows 导入总处理的行数。
- NumberLoadedRows 成功导入的行数。
- NumberFilteredRows 数据质量不合格的行数。
- NumberUnselectedRows 被 where 条件过滤的行数。
- LoadBytes 导入的字节数。
- LoadTimeMs 导入完成时间。单位毫秒。
- BeginTxnTimeMs 向Fe请求开始一个事务所花费的时间,单位毫秒。
- StreamLoadPutTimeMs 向Fe请求获取导入数据执行计划所花费的时间,单位毫秒。
- ReadDataTimeMs 读取数据所花费的时间,单位毫秒。
- WriteDataTimeMs 执行写入数据操作所花费的时间,单位毫秒。
- CommitAndPublishTimeMs 向Fe请求提交并且发布事务所花费的时间,单位毫秒。
- ErrorURL 如果有数据质量问题,通过访问这个 URL 查看具体错误行。
- ExistingJobStatus:已存在的 Label 对应的导入作业的状态。这个字段只有在当 Status 为 “Label Already Exists” 时才会显示。用户可以通过这个状态,知晓已存在 Label 对应的导入作业的状态。“RUNNING” 表示作业还在执行,“FINISHED” 表示作业成功。
9.4.4.6 注意事项
由于 Stream load 是同步的导入方式,所以并不会在 Doris 系统中记录导入信息,用户无法异步的通过查看导入命令看到 Stream load。使用时需监听创建导入请求的返回值获取导入结果。
在某些情况下,用户的 HTTP 连接可能会异常断开导致无法获取最终的返回结果。此时可以使用相同的 Label 重新提交导入任务,重新提交的任务可能有如下结果:
- Status 状态为 Success,Fail 或者 Publish Timeout。此时按照正常的流程处理即可。
- Status 状态为 Label Already Exists。则此时需继续查看 ExistingJobStatus 字段。如果该字段值为 FINISHED,则表示这个 Label 对应的导入任务已经成功,无需在重试。如果为 RUNNING,则表示这个 Label 对应的导入任务依然在运行,则此时需每间隔一段时间(如10秒),使用相同的 Label 继续重复提交,直到 Status 不为 Label Already Exists,或者 ExistingJobStatus 字段值为 FINISHED 为止。
- Stream Load 适合导入几个GB以内的数据,因为数据为单线程传输处理,因此导入过大的数据性能得不到保证。当有大量本地数据需要导入时,可以并行提交多个导入任务。Doris 同时会限制集群内同时运行的导入任务数量,通常在 10-20 个不等。之后提交的导入作业会被拒绝。
- 已提交切尚未结束的导入任务可以通过 CANCEL LOAD 命令取消。取消后,已写入的数据也会回滚,不会生效。
- 用户可以通过SHOW STREAM LOAD 来查看已经完成的 stream load 任务。
9.4.4.7 最佳实践
- 使用 Stream load 的最合适场景就是原始文件在内存中或者在磁盘中。其次,由于 Stream load 是一种同步的导入方式,所以用户如果希望用同步方式获取导入结果,也可以使用这种导入。
- 由于 Stream load 的原理是由 BE 发起的导入并分发数据,建议的导入数据量在 1G 到 10G 之间。由于默认的最大 Stream load 导入数据量为 10G,所以如果要导入超过 10G 的文件需要修改 BE 的配置 streaming_load_max_mb参数,这个参数是Stream load 的最大导入大小,默认为 10G,单位是 MB。如果用户的原始文件超过这个值,则需要调整这个参数。
- Stream load 的默认超时为 600秒,按照 Doris 目前最大的导入限速来看,约超过 3G 的文件就需要修改导入任务默认超时时间了。如果经常导入的问题都大于3G,则可以调整stream_load_default_timeout_second这个参数,这个参数是全局的Stream load超时时间,在FE配置文件中修改并重启。
- 导入任务时间 = 导入数据量 / 每秒导入的数据量
- 用户在开启 BE 上的 Stream Load 记录后,查询不到记录。这是因为拉取速度慢造成的,可以尝试调整下面的参数:
- 调大 BE 配置 stream_load_record_batch_size,这个配置表示每次从 BE 上最多拉取多少条 Stream load 的记录数,默认值为50条,可以调大到500条。
- 调小 FE 的配置 fetch_stream_load_record_interval_second,这个配置表示获取 Stream load 记录间隔,默认每120秒拉取一次,可以调整到60秒。
- 如果要保存更多的 Stream load 记录(不建议,占用 FE 更多的资源)可以将 FE 的配置 max_stream_load_record_size 调大,默认是5000条。
9.4.5 ROUTINE LOAD
9.4.5.1 介绍
例行导入(Routine Load)功能,支持用户提交一个常驻的导入任务,通过不断的从指定的数据源读取数据,将数据导入到 Doris 中。当前只支持从Kafka中进行导入。支持无认证的Kafka访问、SSL认证访问以及Kerberos认证访问。支持的消息格式为 csv, json 文本格式。csv 每一个 message 为一行,且行尾不包含换行符。
9.4.5.2 基本原理
+---------+
| Client |
+----+----+
|
+-----------------------------+
| FE | |
| +-----------v------------+ |
| | | |
| | Routine Load Job | |
| | | |
| +---+--------+--------+--+ |
| | | | |
| +---v--+ +---v--+ +---v--+ |
| | task | | task | | task | |
| +--+---+ +---+--+ +---+--+ |
| | | | |
+-----------------------------+
| | |
v v v
+---+--+ +--+---+ ++-----+
| BE | | BE | | BE |
+------+ +------+ +------+
- FE 通过 JobScheduler 将一个导入作业拆分成若干个 Task。每个 Task 负责导入指定的一部分数据。Task 被 TaskScheduler 分配到指定的 BE 上执行。
- 在 BE 上,一个 Task 被视为一个普通的导入任务,通过 Stream Load 的导入机制进行导入。导入完成后,向 FE 汇报。
- FE 中的 JobScheduler 根据汇报结果,继续生成后续新的 Task,或者对失败的 Task 进行重试。
- 整个 Routine Load 作业通过不断的产生新的 Task,来完成数据不间断的导入。
9.4.5.3 创建任务
9.4.5.3.1 语法
CREATE ROUTINE LOAD [db.]job_name ON table_name
[merge_type]
[load_properties]
[job_properties]
FROM KAFKA [data_source_properties]
[COMMENT "comment"]
- [db.]job_name:导入作业的名称,在同一个 database 内,相同名称只能有一个 job 在运行。
- table_name:指定导入到那张表中。
- merge_type:数据合并类型。默认为 APPEND,表示导入的数据都是普通的追加写操作。MERGE 和 DELETE 类型仅适用于 Unique Key 模型表。其中 MERGE 类型需要配合 [DELETE ON] 语句使用,以标注 Delete Flag 列。而 DELETE 类型则表示导入的所有数据皆为删除数据。WITH MERGE
- load_properties:用于描述导入数据:
- column_separator:指定列分隔符,默认为’\t’,COLUMNS TERMINATED BY “,”
- columns_mapping:用于指定文件列和表中列的映射关系,以及各种列转换等。可以查看Stream load关于列转换的描述。COLUMNS(k1, k2)。
- preceding_filter:列前置过滤。PRECEDING FILTER k1 = 1。
- where_predicates:列后置过滤。根据条件对导入的数据进行过滤。WHERE k1 > 100 and k2 = 1000。
- partitions:指定导入目的表的哪些 partition 中。如果不指定,则会自动导入到对应的 partition 中。PARTITION(p1, p2, p3)
- DELETE ON:需配合 MEREGE 导入模式一起使用,仅针对 Unique Key 模型的表。用于指定导入数据中表示 Delete Flag 的列和计算关系。DELETE ON v3 >100。
- ORDER BY:仅针对 Unique Key 模型的表。用于指定导入数据中表示 Sequence Col 的列。主要用于导入时保证数据顺序。
- job_properties:用于指定例行导入作业的通用参数。
- desired_concurrent_number:期望的并发度。一个例行导入作业会被分成多个子任务执行。这个参数指定一个作业最多有多少任务可以同时执行。必须大于0。默认为3。这个并发度并不是实际的并发度,实际的并发度,会通过集群的节点数、负载情况,以及数据源的情况综合考虑。
- max_batch_interval/max_batch_rows/max_batch_size:每个子任务最大执行时间,单位是秒。范围为 5 到 60。默认为10;每个子任务最多读取的行数。必须大于等于200000。默认是200000;每个子任务最多读取的字节数。单位是字节,范围是 100MB 到 1GB。默认是 100MB。这三个参数,用于控制一个子任务的执行时间和处理量。当任意一个达到阈值,则任务结束。
- max_error_number:采样窗口内,允许的最大错误行数。必须大于等于0。默认是 0,即不允许有错误行。采样窗口为 max_batch_rows * 10。即如果在采样窗口内,错误行数大于 max_error_number,则会导致例行作业被暂停,需要人工介入检查数据质量问题。被 where 条件过滤掉的行不算错误行。
- strict_mode、timezone、jsonpaths、strip_outer_array、json_root、send_batch_parallelism、load_to_single_tablet可以查看Stream load参数说明。
- format:指定导入数据格式,默认是csv,支持json格式。
- data_source_properties
- kafka_broker_list:Kafka 的 broker 连接信息。格式为 ip:host。多个broker之间以逗号分隔。
- kafka_topic:指定要订阅的 Kafka 的 topic。
- kafka_partitions/kafka_offsets:指定需要订阅的 kafka partition,以及对应的每个 partition 的起始 offset。如果指定时间,则会从大于等于该时间的最近一个 offset 处开始消费。offset可以有如下设置:
- OFFSET_BEGINNING: 从有数据的位置开始订阅。
- OFFSET_END: 从末尾开始订阅。
- 时间格式,如:“2021-05-22 11:00:00”。
- 具体的offset数字。
- 如果没有指定,则默认从 OFFSET_END 开始订阅 topic 下的所有 partition。时间格式不能和 OFFSET 格式混用。
- 如果没有指定 kafka_partitions/kafka_offsets,默认消费所有分区。此时可以指定 kafka_default_offsets 指定起始 offset。默认为
OFFSET_END,即从末尾开始订阅。 - property:指定自定义kafka参数。当参数的 value 为一个文件时,需要在 value 前加上关键词:“FILE:”。关于如何创建文件,请参阅 CREATE FILE 命令文档。其他参数可以查看C++ API。
9.4.5.3.2 示例
CREATE ROUTINE LOAD example_db.test1 ON example_tbl
WITH MERGE
COLUMNS TERMINATED BY ",",
COLUMNS(k1, k2, k3, v1, v2, v3 = k1 * 100)
WHERE k1 > 100 and k2 like "%doris%"
PARTITION(p1, p2, p3)
DELETE ON v3 >100
ORDER BY v1
PRECEDING FILTER k1 = 1,
PROPERTIES
(
"desired_concurrent_number"="3",
"max_batch_interval" = "20",
"max_batch_rows" = "300000",
"max_batch_size" = "209715200",
"strict_mode" = "true",
"format" = "csv",
"timezone" = "Asia/Shanghai"
)
FROM KAFKA
(
"kafka_broker_list" = "broker1:9092,broker2:9092,broker3:9092",
"kafka_topic" = "my_topic",
"property.group.id" = "xxx",
"property.client.id" = "xxx",
"kafka_partitions" = "0,1,2,3",
"kafka_offsets" = "101,0,0,200"
);
# 通过 SSL 认证方式,从 Kafka 集群导入数据。
CREATE ROUTINE LOAD example_db.test1 ON example_tbl
WITH MERGE
COLUMNS TERMINATED BY ",",
COLUMNS(k1, k2, k3, v1, v2, v3 = k1 * 100)
WHERE k1 > 100 and k2 like "%doris%"
PARTITION(p1, p2, p3)
DELETE ON v3 >100
ORDER BY v1
PROPERTIES
(
"desired_concurrent_number"="3",
"max_batch_interval" = "20",
"max_batch_rows" = "300000",
"max_batch_size" = "209715200",
"strict_mode" = "true",
"format" = "csv",
"timezone" = "Asia/Shanghai"
)
FROM KAFKA
(
"kafka_broker_list" = "broker1:9092,broker2:9092,broker3:9092",
"kafka_topic" = "my_topic",
"property.security.protocol" = "ssl",
"property.ssl.ca.location" = "FILE:ca.pem",
"property.ssl.certificate.location" = "FILE:client.pem",
"property.ssl.key.location" = "FILE:client.key",
"property.ssl.key.password" = "abcdefg",
"property.client.id" = "my_client_id"
);
# 导入 Json 数据,并通过 Jsonpaths 抽取字段,并指定 Json 文档根节点
CREATE ROUTINE LOAD example_db.test1 ON example_tbl
COLUMNS(category, author, price, timestamp, dt=from_unixtime(timestamp, '%Y%m%d'))
PROPERTIES
(
"desired_concurrent_number"="3",
"max_batch_interval" = "20",
"max_batch_rows" = "300000",
"max_batch_size" = "209715200",
"strict_mode" = "false",
"format" = "json",
"jsonpaths" = "[\"$.category\",\"$.author\",\"$.price\",\"$.timestamp\"]",
"json_root" = "$.RECORDS"
"strip_outer_array" = "true"
)
FROM KAFKA
(
"kafka_broker_list" = "broker1:9092,broker2:9092,broker3:9092",
"kafka_topic" = "my_topic",
"kafka_default_offset" = "2021-05-21 10:00:00"
);
# 通过 KERBEROS 认证方式,从 Kafka 集群导入数据。
# 若要使 Doris 访问开启kerberos认证方式的Kafka集群,需要在 Doris 集群所有运行节点上部署 Kerberos 客户端 kinit,并配置 krb5.conf,填写KDC 服务信息等。
# 配置 property.sasl.kerberos.keytab 的值需要指定 keytab 本地文件的绝对路径,并允许 Doris 进程访问该本地文件。
CREATE ROUTINE LOAD db1.job1 on tbl1
PROPERTIES (
"desired_concurrent_number"="1",
)
FROM KAFKA
(
"kafka_broker_list" = "broker1:9092,broker2:9092",
"kafka_topic" = "my_topic",
"property.security.protocol" = "SASL_PLAINTEXT",
"property.sasl.kerberos.service.name" = "kafka",
"property.sasl.kerberos.keytab" = "/etc/krb5.keytab",
"property.sasl.kerberos.principal" = "doris@YOUR.COM"
);
9.4.5.4 查看作业状态
# 查看一个指定的 ROUTINE LOAD 作业的当前正在运行的子任务情况。
SHOW ROUTINE LOAD TASK WHERE JobName = "job_name";
{
TaskId: d67ce537f1be4b86-abf47530b79ab8e6 #子任务的唯一 ID。
TxnId: 4 # 子任务对应的导入事务 ID。
TxnStatus: UNKNOWN # 子任务对应的导入事务状态。通常为 UNKNOWN。并无实际意思。
JobId: 10280 # 子任务对应的作业 ID。
CreateTime: 2020-12-12 20:29:48 # 子任务的创建时间。
ExecuteStartTime: 2020-12-12 20:29:48 # 子任务被调度执行的时间,通常晚于创建时间。
Timeout: 20 # 子任务超时时间,通常是作业设置的 MaxIntervalS 的两倍。
BeId: 10002 # 执行这个子任务的 BE 节点 ID。
DataSourceProperties: {"0":19} # 子任务准备消费的 Kafka Partition 的起始 offset。是一个 Json 格式字符串。Key 为 Partition Id。Value 为消费的起始 offset。
}
# 查看 ROUTINE LOAD 作业运行状态
SHOW [ALL] ROUTINE LOAD [FOR jobName];
{
Id: # 作业ID
Name: # 作业名称
CreateTime: # 作业创建时间
PauseTime: # 最近一次作业暂停时间
EndTime: # 作业结束时间
DbName: # 对应数据库名称
TableName: # 对应表名称
State: # 作业运行状态,NEED_SCHEDULE:作业等待被调度;RUNNING:作业运行中;PAUSED:作业被暂停;STOPPED:作业已结束;CANCELLED:作业已取消
DataSourceType: # 数据源类型:KAFKA
CurrentTaskNum: # 当前子任务数量
JobProperties: # 作业配置详情
DataSourceProperties: # 数据源配置详情
CustomProperties: # 自定义配置
Statistic: # 作业运行状态统计信息
Progress: # 作业运行进度,显示每个分区当前已消费的offset。如 {"0":"2"} 表示Kafka分区0的消费进度为2。
Lag: # 作业延迟状态,显示每个分区的消费延迟。如{"0":10} 表示Kafka分区0的消费延迟为10。
ReasonOfStateChanged: # 作业状态变更的原因
ErrorLogUrls: # 被过滤的质量不合格的数据的查看地址
OtherMsg: # 其他错误信息
}
# 该语句用于展示例行导入作业的创建语句。结果中的 kafka partition 和 offset 展示的当前消费的 partition,以及对应的待消费的 offset。
SHOW [ALL] CREATE ROUTINE LOAD for load_name;
9.4.5.5 修改作业属性
ALTER ROUTINE LOAD FOR [db.]job_name
[job_properties]
FROM KAFKA
[data_source_properties]
# 如果指定了KAFKA分区消费,在修改的时候不能新增分区
9.4.5.6 作业控制
# 语法
PAUSE [ALL] ROUTINE LOAD FOR job_name; # 暂停一个 ROUTINE LOAD 作业
RESUME [ALL] ROUTINE LOAD FOR job_name; # 重启一个被暂停的 ROUTINE LOAD 作业
STOP ROUTINE LOAD FOR job_name; # 停止一个 ROUTINE LOAD 作业
# 示例
# 暂停名称为 test1 的例行导入作业。
PAUSE ROUTINE LOAD FOR test1;
# 暂停所有例行导入作业。
PAUSE ALL ROUTINE LOAD;
# 重启名称为 test1 的例行导入作业。
RESUME ROUTINE LOAD FOR test1;
# 重启所有例行导入作业。
RESUME ALL ROUTINE LOAD;
# 停止名称为 test1 的例行导入作业。
STOP ROUTINE LOAD FOR test1;
9.5 表结构变更
9.5.1 Schema 变更
9.5.1.1 原理
执行 Schema Change 的基本过程,是通过原 Index 的数据,生成一份新 Schema 的 Index 的数据。其中主要需要进行两部分数据转换,一是已存在的历史数据的转换,二是在 Schema Change 执行过程中,新到达的导入数据的转换。
+----------+
| Load Job |
+----+-----+
|
| Load job generates both origin and new index data
|
| +------------------+ +---------------+
| | Origin Index | | Origin Index |
+------> New Incoming Data| | History Data |
| +------------------+ +------+--------+
| |
| | Convert history data
| |
| +------------------+ +------v--------+
| | New Index | | New Index |
+------> New Incoming Data| | History Data |
+------------------+ +---------------+
在开始转换历史数据之前,Doris 会获取一个最新的 Transaction ID。并等待这个 Transaction ID 之前的所有导入事务完成。这个 Transaction ID 成为分水岭。意思是,Doris 保证在分水岭之后的所有导入任务,都会同时为原 Index 和新 Index 生成数据。这样当历史数据转换完成后,可以保证新的 Index 中的数据是完整的。
9.5.1.2 执行命令
该语句用于对已有 table 进行 Schema change 操作。schema change 是异步的,任务提交成功则返回,之后可使用SHOW ALTER TABLE COLUMN 命令查看进度。
ALTER TABLE [database.]table alter_clause;
# alter_clause支持以下修改方式:
# 1. 向指定 index 的指定位置添加一列
ADD COLUMN column_name column_type [KEY | agg_type] [DEFAULT "default_value"]
[AFTER column_name|FIRST]
[TO rollup_index_name]
[PROPERTIES ("key"="value", ...)]
# 聚合模型如果增加 value 列,需要指定 agg_type
# 非聚合模型(如 DUPLICATE KEY)如果增加key列,需要指定KEY关键字
# 不能在 rollup index 中增加 base index 中已经存在的列(如有需要,可以重新创建一个 rollup index)
# 2. 向指定 index 添加多列
ADD COLUMN (column_name1 column_type [KEY | agg_type] DEFAULT "default_value", ...)
[TO rollup_index_name]
[PROPERTIES ("key"="value", ...)]
# 3. 从指定 index 中删除一列
DROP COLUMN column_name
[FROM rollup_index_name]
# 不能删除分区列
# 如果是从 base index 中删除列,则如果 rollup index 中包含该列,也会被删除
# 4. 修改指定 index 的列类型以及列位置
MODIFY COLUMN column_name column_type [KEY | agg_type] [NULL | NOT NULL] [DEFAULT "default_value"]
[AFTER column_name|FIRST]
[FROM rollup_index_name]
[PROPERTIES ("key"="value", ...)]
# 分区列和分桶列不能做任何修改
# 只能修改列的类型,列的其他属性维持原样
# 5. 对指定 index 的列进行重新排序
ORDER BY (column_name1, column_name2, ...)
[FROM rollup_index_name]
[PROPERTIES ("key"="value", ...)]
# index 中的所有列都要写出来
# value 列在 key 列之后
# 6. 修改表注释
MODIFY COMMENT "new table comment";
# 7. 修改列注释
MODIFY COLUMN col1 COMMENT "new column comment";
# 8. 修改表名
RENAME new_table_name;
# 9. 修改 rollup index 名称
RENAME ROLLUP old_rollup_name new_rollup_name;
# 10. 修改 partition 名称
RENAME PARTITION old_partition_name new_partition_name;
# 11. 修改 column 名称
RENAME COLUMN old_column_name new_column_name;
# 12. 创建 rollup index
ADD ROLLUP rollup_name (column_name1, column_name2, ...)
[FROM from_index_name]
[PROPERTIES ("key"="value", ...)]
# 如果没有指定 from_index_name,则默认从 base index 创建。
# rollup 表中的列必须是 from_index 中已有的列。
# 13. 批量创建 rollup index
ADD ROLLUP [rollup_name (column_name1, column_name2, ...)
[FROM from_index_name]
[PROPERTIES ("key"="value", ...)],...]
# 14. 删除 rollup index
DROP ROLLUP rollup_name,...;
# 15. 增加分区
ADD PARTITION [IF NOT EXISTS] partition_name
partition_desc ["key"="value"]
[DISTRIBUTED BY HASH (k1[,k2 ...]) [BUCKETS num]]
# 只能给分区表增加分区。
# 如指定分桶方式,只能修改分桶数,不可修改分桶方式或分桶列。如果指定了分桶方式,但是没有指定分桶数,则分桶数会使用默认值10,不会使用建表时指定的分桶数。如果要指定分桶数,则必须指定分桶方式。
# 16. 删除分区
DROP PARTITION [IF EXISTS] partition_name [FORCE]
# 使用分区方式的表至少要保留一个分区。
# 执行 DROP PARTITION 一段时间内,可以通过 RECOVER 语句恢复被删除的分区。
# 如果执行 DROP PARTITION FORCE,则系统不会检查该分区是否存在未完成的事务,分区将直接被删除并且不能被恢复,一般不建议执行此操作
# 17. 修改分区属性
MODIFY PARTITION p1|(p1[, p2, ...]) SET ("key" = "value", ...)
# 18. 创建bitmap 索引
ADD INDEX [IF NOT EXISTS] index_name (column [, ...],) [USING BITMAP] [COMMENT 'balabala'];
# 19. 删除索引
DROP INDEX [IF EXISTS] index_name;
# 20. 修改表的 bloom filter 列
SET ("bloom_filter_columns"="k1,k2,k3");
# 21. 修改表的Colocate 属性
SET ("colocate_with" = "t1");
# 22. 将表的分桶方式由 Hash Distribution 改为 Random Distribution
SET ("distribution_type" = "random");
# 23. 修改表的动态分区属性(支持未添加动态分区属性的表添加动态分区属性)
SET ("dynamic_partition.enable" = "false",...);
# 24. 启用 批量删除功能
ENABLE FEATURE "BATCH_DELETE";
# 25. 启用按照sequence column的值来保证导入顺序的功能
ENABLE FEATURE "SEQUENCE_LOAD" WITH PROPERTIES ("function_column.sequence_type" = "Date");
# 27. 将表的默认分桶数改为50
MODIFY DISTRIBUTION DISTRIBUTED BY HASH(k1) BUCKETS 50;
# 28. 修改副本数
SET ("replication_num" = "2");
# 29. 打开light_schema_change
SET ("light_schema_change" = "true");
9.5.1.3 查看作业
# 该语句用于展示当前正在进行的各类修改任务的执行情况
SHOW ALTER TABLE [COLUMN | ROLLUP] [FROM db_name];
# TABLE COLUMN:展示修改列的 ALTER 任务
# 支持语法[WHERE TableName|CreateTime|FinishTime|State][ORDER BY] [LIMIT]
# TABLE ROLLUP:展示创建或删除 ROLLUP index 的任务
# 如果不指定 db_name,使用当前默认 db
# 展示默认 db 的所有修改列的任务执行情况
SHOW ALTER TABLE COLUMN;
*************************** 1. row ***************************
JobId: 20021 # 每个 Schema Change 作业的唯一 ID。
TableName: tbl1 # Schema Change 对应的基表的表名。
CreateTime: 2019-08-05 23:03:13 # 作业创建时间。
FinishTime: 2019-08-05 23:03:42 # 作业结束时间。如未结束,则显示 "N/A"。
IndexName: tbl1 # 本次修改所涉及的某一个 Index 的名称。
IndexId: 20022 # 新的 Index 的唯一 ID。
OriginIndexId: 20017 # 旧的 Index 的唯一 ID。
SchemaVersion: 2:792557838 # 以 M:N 的格式展示。其中 M 表示本次 Schema Change 变更的版本,N 表示对应的 Hash 值。每次 Schema Change,版本都会递增。
TransactionId: 10023 # 转换历史数据的分水岭 transaction ID。
State: FINISHED # 作业所在阶段。PENDING:作业在队列中等待被调度;WAITING_TXN:等待分水岭 transaction ID 之前的导入任务完成;RUNNING:历史数据转换中;FINISHED:作业成功;CANCELLED:作业失败。
Msg: # 如果作业失败,这里会显示失败信息。
Progress: NULL # 作业进度。只有在 RUNNING 状态才会显示进度。进度是以 M/N 的形式显示。其中 N 为 Schema Change 涉及的总副本数。M 为已完成历史数据转换的副本数。
Timeout: 86400 # 作业超时时间。单位秒。
# 展示某个表最近一次修改列的任务执行情况
SHOW ALTER TABLE COLUMN WHERE TableName = "table1" ORDER BY CreateTime DESC LIMIT 1;
# 展示指定 db 的创建或删除 ROLLUP index 的任务执行情况
SHOW ALTER TABLE ROLLUP FROM example_db;
9.5.1.4 取消作业
在作业状态不为 FINISHED 或 CANCELLED 的情况下,可以通过以下命令取消 Schema Change 作业:
CANCEL ALTER TABLE COLUMN FROM tbl_name;
9.5.2 替换表
Doris 支持对两个表进行原子的替换操作。 该操作仅适用于 OLAP 表。
9.5.2.1 场景
某些情况下,用户希望能够重写某张表的数据,但如果采用先删除再导入的方式进行,在中间会有一段时间无法查看数据。这时,用户可以先使用 CREATE TABLE LIKE 语句创建一个相同结构的新表,将新的数据导入到新表后,通过替换操作,原子的替换旧表,以达到目的。
9.5.2.2 语法
# 将表 tbl1 替换为表 tbl2。
ALTER TABLE [db.]table_name1 REPLACE WITH TABLE table_name2
[PROPERTIES('swap' = 'true')];
# 如果 swap 参数为 true,则替换后,名称为 table_name1 表中的数据为原 table_name2 表中的数据。而名称为 table_name2 表中的数据为原 table_name1 表中的数据。即两张表数据发生了互换。
# 如果 swap 参数为 false,则替换后,名称为 table_name1 表中的数据为原 table_name2 表中的数据。而名称为 table_name2 表被删除。table_name1的数据将被删除且无法恢复。
# 替换操作仅能发生在两张 OLAP 表之间,且不会检查两张表的表结构是否一致。
# 替换操作不会改变原有的权限设置。因为权限检查以表名称为准。
9.6 数据删除
9.6.1 DELETE删除
使用delete语句的方式删除时,每执行一次delete都会生成一个新的数据版本,如果频繁删除会严重影响查询性能,并且在使用delete方式删除时,是通过生成一个空的rowset来记录删除条件实现,每次读取都要对删除条件进行过滤,同样在条件较多时会对性能造成影响。
Delete不同于其他导入方式,它是一个同步过程,与Insert into相似,所有的Delete操作在Doris中是一个独立的导入作业,一般Delete语句需要指定表和分区以及删除的条件来筛选要删除的数据,并将会同时删除base表和rollup表的数据。删除操作查看DELETE。
delete删除是一个同步操作,命令执行后会有如下几种情况:
- ERROR 1064 (HY000)表示删除失败。
- Query OK 表示删除执行成功。
- 如果status为COMMITTED,表示数据仍不可见,用户可以稍等一段时间再用show delete命令查看结果。
- 如果status为VISIBLE,表示数据删除成功。
9.6.2 批量删除
9.6.2.1 批量删除原理
批量删除只支持在UNIQUE模型上使用。通过增加一个隐藏列_DORIS_DELETE_SIGN_,这个隐藏列为BOOLEAN类型,在数据导入的时候把DELETE ON 相关的行的隐藏列设置为true,其他导入方式不变。在数据读取的时候当读取的表是有隐藏列__DORIS_DELETE_SIGN__的时候,则默认添加_DORIS_DELETE_SIGN_ != true过滤条件。达到批量删除的目的。数据会在进行合并的时候彻底删除。查看一个表是否是支持批量删除,可以通过如下命令:
SET show_hidden_columns=true;
desc tablename;
# 如果输出中有__DORIS_DELETE_SIGN__ 列则支持,如果没有则不支持。
# 查询完成后,关闭显示隐藏列,防止对数据查询有影响。
SET show_hidden_columns=false;
启用批量删除功能可以通过修改FE的配置enable_batch_delete_by_default=true外还可以通过ALTER TABLE操作。具体的删除操作可以查看导入目录的merge_type参数相关内容。
9.7 数据查询优化
9.7.1 Pipeline 执行引擎
9.7.1.1 介绍
Pipeline 执行引擎 是 Doris 在 2.0 版本加入的实验性功能。目标是为了替换当前 Doris 的火山模型的执行引擎,充分释放多核 CPU 的计算能力,并对 Doris 的查询线程的数目进行限制,解决 Doris 的执行线程膨胀的问题。
9.7.1.2 原理
- 当前的Doris的SQL执行引擎是基于传统的火山模型进行设计,在单机多核的场景下存在下面的一些问题:
- 无法充分利用多核计算能力,提升查询性能,多数场景下进行性能调优时需要手动设置并行度,在生产环境中几乎很难进行设定。
- 单机查询的每个 Instance 对应线程池的一个线程,这会带来额外的两个问题。
- 线程池一旦打满。Doris的查询引擎会进入假性死锁,对后续的查询无法响应。同时有一定概率进入逻辑死锁的情况:比如所有的线程都在执行一个 Instance 的 Probe 任务。
- 阻塞的算子会占用线程资源,而阻塞的线程资源无法让渡给能够调度的 Instance,整体资源利用率上不去。
- 阻塞算子依赖操作系统的线程调度机制,线程切换开销较大(尤其在系统混布的场景中)
由此带来的一系列问题驱动 Doris 需要实现适应现代多核 CPU 的体系结构的执行引擎。Pipeline执行引擎基于多核CPU的特点,重新设计由数据驱动的执行引擎:

- 将传统 Pull 拉取的逻辑驱动的执行流程改造为 Push 模型的数据驱动的执行引擎
- 阻塞操作异步化,减少了线程切换,线程阻塞导致的执行开销,对于 CPU 的利用更为高效
- 控制了执行线程的数目,通过时间片的切换的控制,在混合负载的场景中,减少大查询对于小查询的资源挤占问题
9.7.1.3 使用方式
# 将session变量enable_pipeline_engine设置为true,则BE在进行查询执行时就会默认将SQL的执行模型转变Pipeline的执行方式。
set enable_pipeline_engine = true;
# parallel_fragment_exec_instance_num代表了SQL查询进行查询并发的Instance数目。Doris默认的配置为1,这个配置会影响非Pipeline执行引擎的查询线程数目,而在Pipeline执行引擎中不会有线程数目膨胀的问题。这里推荐配置为16,用户也可以实际根据自己的查询情况进行调整。
set parallel_fragment_exec_instance_num = 16;
# 如果设置为0,则在Pipeline执行引擎中的并发数会自动的设置为cpu核心数目的一半。并且parallel_fragment_exec_instance_num不能设置超过fe.conf中的max_instance_num(默认128)。
9.7.2 高并发点查
9.7.2.1 介绍
Doris基于列存格式引擎构建,在高并发服务场景中,用户总是希望从系统中获取整行数据。但是,当表宽时,列存格式将大大放大随机读取 IO。Doris 查询引擎和计划对于某些简单的查询(如点查询)来说太重了。需要一个在 FE 的查询规划中规划短路径来处理这样的查询。为了解决上述问题,我们在 Doris 中引入了行存、短查询路径来解决上诉问题,下面是开启这些优化的指南。这些优化在2.0.0版本提供。并且只针对UNIQUE模型。
9.7.2.2 行存
用户可以在OLAP表中开启行存模式,但是需要额外的空间来存储行存。目前的行存实现是将行存编码后存在单独的一列中,这样做是用于简化行存的实现。行存模式默认是关闭的,如果您想开启则可以在建表语句的 property 中指定如下属性。
"store_row_column" = "true"
行存用于在 Unique 模型下开启 Merge-On-Write 策略是减少点查时的 IO 开销。当enable_unique_key_merge_on_write与store_row_column在创建 Unique 表开启时,对于主键的点查会走短路径来对 SQL 执行进行优化,仅需要执行一次 RPC 即可执行完成查询。下面是点查结合行存在 在 Unique 模型下开启 Merge-On-Write 策略的一个例子:
CREATE TABLE `tbl_point_query` (
`key` int(11) NULL,
`v1` decimal(27, 9) NULL,
`v2` varchar(30) NULL,
`v3` varchar(30) NULL,
`v4` date NULL,
`v5` datetime NULL,
`v6` float NULL,
`v7` datev2 NULL
) ENGINE=OLAP
UNIQUE KEY(`key`)
COMMENT 'OLAP'
DISTRIBUTED BY HASH(`key`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1",
"enable_unique_key_merge_on_write" = "true",
"light_schema_change" = "true"
"store_row_column" = "true"
);
- enable_unique_key_merge_on_write应该被开启, 存储引擎需要根据主键来快速点查。
- 当条件只包含主键时,如select * from tbl_point_query where key = 123,类似的查询会走短路径来优化查询。
- light_schema_change应该被开启, 因为主键点查的优化依赖了轻量级 Schema Change 中的column unique id来定位列。
9.7.2.3 开启行缓存
为了增加行缓存命中率,单独引入了行存缓存,行缓存复用了 Doris 中的 LRU Cache 机制来保障内存的使用,通过指定下面的的BE配置来开启:
# 开启行缓存
disable_storage_row_cache = true
# 指定 Row cache 占用内存的百分比, 默认 20% 内存
row_cache_mem_limit = 20
9.7.3 物化视图
9.7.3.1 介绍
物化视图是将预先计算(根据定义好的SELECT语句)好的数据集,存储在Doris中的一个特殊的表。物化视图的出现主要是为了满足用户,既能对原始明细数据的任意维度分析,也能快速的对固定维度进行分析查询。
9.7.3.2 适用场景
- 需求中即涉及到明细数据查询也包括固定维度查询两方面。
- 查询仅涉及表中的很小一部分列或行。
- 查询包含一些耗时处理操作,比如:时间很久的聚合操作等。
- 查询需要匹配不同前缀索引。
9.7.3.3 优点
- 对于那些经常重复的使用相同的子查询结果的查询性能大幅提升。
- Doris自动维护物化视图的数据,无论是新的导入,还是删除操作都能保证 Base 表和物化视图表的数据一致性,无需任何额外的人工维护成本。
- 查询时,会自动匹配到最优物化视图,并直接从物化视图中读取数据。
9.7.3.4 局限性
- 物化视图的聚合函数的参数不支持表达式仅支持单列,比如:sum(a+b)不支持。在2.0版本开始支持。
- 如果删除语句的条件列,在物化视图中不存在,则不能进行删除操作。如果一定要删除数据,则需要先将物化视图删除,然后方可删除数据。
- 单表上过多的物化视图会影响导入的效率。因为在导入数据时,物化视图和 Base 表数据是同步更新的。
- 相同列,不同聚合函数,不能同时出现在一张物化视图中,比如:select sum(a), min(a) from table不支持。在2.0版本开始支持。
- 物化视图针对UNIQUE KEY数据模型,只能改变列顺序,不能起到聚合的作用,所以在UNIQUE KEY模型上不能通过创建物化视图的方式对数据进行粗粒度聚合操作。
9.7.3.5 使用物化视图
9.7.3.5.1 创建物化视图
9.7.3.5.1.1 建议
- 从查询语句中抽象出,多个查询共有的分组和聚合方式作为物化视图的定义。一个物化视图如果抽象出来,并且多个查询都可以匹配到这张物化视图。这种物化视图效果最好。因为物化视图的维护本身也需要消耗资源。如果物化视图只和某个特殊的查询很贴合,而其他查询均用不到这个物化视图。则会导致这张物化视图的性价比不高,既占用了集群的存储资源,还不能为更多的查询服务。
- 不需要给所有维度组合都创建物化视图。在实际的分析查询中,并不会覆盖到所有的维度分析。所以给常用的维度组合创建物化视图即可,从而到达一个空间和时间上的平衡。
- 不建议在同一张表上建多个形态类似的物化视图,这可能会导致多个物化视图之间的冲突使得查询命中失败。
9.7.3.5.1.2 语法
物化视图是一个异步操作,提交成功后会立即返回。需通过SHOW ALTER TABLE MATERIALIZED VIEW查看作业进度。在状态显示FINISHED后既可通过下面的命令来查看物化视图的schema了。
desc table_name all;
# 示例
desc mv_test all;
+-----------+---------------+-----------------+----------+------+-------+---------+--------------+
| IndexName | IndexKeysType | Field | Type | Null | Key | Default | Extra |
+-----------+---------------+-----------------+----------+------+-------+---------+--------------+
| mv_test | DUP_KEYS | k1 | INT | Yes | true | NULL | |
| | | k2 | BIGINT | Yes | true | NULL | |
| | | k3 | LARGEINT | Yes | true | NULL | |
| | | k4 | SMALLINT | Yes | false | NULL | NONE |
| | | | | | | | |
| mv_2 | AGG_KEYS | k2 | BIGINT | Yes | true | NULL | |
| | | k4 | SMALLINT | Yes | false | NULL | MIN |
| | | k1 | INT | Yes | false | NULL | MAX |
| | | | | | | | |
| mv_3 | AGG_KEYS | k1 | INT | Yes | true | NULL | |
| | | to_bitmap(`k2`) | BITMAP | No | false | | BITMAP_UNION |
| | | | | | | | |
| mv_1 | AGG_KEYS | k4 | SMALLINT | Yes | true | NULL | |
| | | k1 | BIGINT | Yes | false | NULL | SUM |
| | | k3 | LARGEINT | Yes | false | NULL | SUM |
| | | k2 | BIGINT | Yes | false | NULL | MIN |
+-----------+---------------+-----------------+----------+------+-------+---------+--------------+
# 如上面的查询结果就有三张物化视图。
CREATE MATERIALIZED VIEW [mv_name] as [query][PROPERTIES ("key" = "value")]
# mv_name 物化视图的名称,必填项。相同表的物化视图名称不可重复。
# query 用于构建物化视图的查询语句,查询语句的结果既物化视图的数据。支持分组排序。排序列的声明顺序必须和查询的列声明顺序一致。如果不声明order by,则根据规则自动补充排序列。如果物化视图是聚合类型,则所有的分组列自动补充为排序列。如果物化视图是非聚合类型,则前36个字节自动补充为排序列。如果自动补充的排序个数小于3个,则前三个作为排序列。如果query中包含分组列的话,则排序列必须和分组列一致。
# PROPERTIES 可以在这里加上当前这个物化视图创建的超时时间。
# 如果物化视图包含了base表的分区列和分桶列,那么这些列必须作为物化视图中的key列。
9.7.3.5.2 物化视图支持的聚合函数
目前物化视图创建语句支持的聚合函数有:SUM、MIN、MAX、COUNT、BITMAP_UNION及HLL_UNION。
9.7.3.5.3 查询自动匹配
物化视图创建成功后,用户的查询不需要发生任何改变,也就是还是查询的Base 表。Doris会根据当前查询的语句去自动选择一个最优的物化视图并对查询语句进行改写,从物化视图中读取数据并计算。用户可以通过EXPLAIN命令来检查当前查询是否使用了物化视图。
EXPLAIN SELECT store_id, sum(sale_amt) FROM sales_records GROUP BY store_id;
+----------------------------------------------------------------------------------------------+
| Explain String |
+----------------------------------------------------------------------------------------------+
| ... |
| 0:VOlapScanNode |
| TABLE: default_cluster:test.sales_records(store_amt), PREAGGREGATION: ON |
| partitions=1/1, tablets=10/10, tabletList=50028,50030,50032 ... |
| cardinality=1, avgRowSize=1520.0, numNodes=1 |
+----------------------------------------------------------------------------------------------+
# default_cluster:test.sales_records(store_amt) 如果显示类似这样,db_name.tab_name(mv_name) 则表示查询命中了物化视图。
物化视图中的聚合和查询中聚合的匹配关系:
| 物化视图聚合 | 查询中聚合 |
|---|---|
| sum | sum |
| min | min |
| max | max |
| count | count |
| bitmap_union | bitmap_union、bitmap_union_count、count(distinct) |
| hll_union | hll_raw_agg、hll_union_agg、ndv、approx_count_distinct |
9.7.3.5.4 删除物化视图
DROP MATERIALIZED VIEW [IF EXISTS] mv_name ON table_name;
9.7.3.5.5 查看物化视图创建语句
# 该语句用于查询创建物化视图的语句。
SHOW CREATE MATERIALIZED VIEW mv_name ON table_name;
mysql> show create materialized view id_col1 on table3;
+-----------+----------+----------------------------------------------------------------+
| TableName | ViewName | CreateStmt |
+-----------+----------+----------------------------------------------------------------+
| table3 | id_col1 | create materialized view id_col1 as select id,col1 from table3 |
+-----------+----------+----------------------------------------------------------------+
9.7.3.5.6 取消创建物化视图
CANCEL ALTER TABLE MATERIALIZED VIEW FROM db_name.table_name;
9.7.4 Join
9.7.4.1 Colocation Join
9.7.4.1.1 名词解释
- Colocation Group(CG):一个CG中会包含一张及以上的Table。在同一个Group内的Table有着相同的Colocation Group Schema,并且有着相同的数据分片分布。
- Colocation Group Schema(CGS):用于描述一个CG中的Table,和Colocation相关的通用Schema信息。包括分桶列,分桶数以及副本数等。分桶列会作为Join的关联列。
9.7.4.1.2 原理
Colocation Join功能,是将一组拥有相同CGS的Table组成一个CG。并保证这些Table对应的数据分片会落在同一个BE节点上。使得当CG内的表进行分桶列上的Join操作时,可以通过直接进行本地数据Join,减少数据在节点间的传输耗时。
一个表的数据,最终会根据分桶列值Hash、对桶数取模后落在某一个分桶内。假设一个Table的分桶数为8,则共有 [0, 1, 2, 3, 4, 5, 6, 7]8个分桶(Bucket),我们称这样一个序列为一个BucketsSequence。每个Bucket内会有一个或多个数据分片(Tablet)。根据前面说的Tablet个数 = PartitionNum * BucketNum,当表为单分区表时,一个Bucket内仅有一个Tablet。如果是多分区表,则会有多个。
为了使得Table能够有相同的数据分布,同一CG内的Table必须保证以下属性相同:
- 分桶列和分桶数:分桶列决定了一张表的数据通过哪些列的值进行Hash划分到不同的Tablet中。同一CG内的Table必须保证分桶列一致,并且桶数也要一致,才能保证多张表的数据分片能够一一对应的进行分布控制。
- 副本数:同一个CG内所有表的所有分区的副本数必须一致。如果不一致,可能出现某一个Tablet 的某一个副本,在同一个BE上没有其他的表分片的副本对应。
同一个 CG 内的表,分区的个数、范围以及分区列的类型不要求一致。
CG内所有表的数据都会按照上面的规则进行统一分布,这样就保证了,分桶列值相同的数据都在同一个BE节点上,可以进行本地数据Join。
9.7.4.1.3 使用
9.7.4.1.3.1 建表
建表时,可以在PROPERTIES中指定属性"colocate_with" = “group_name”,表示这个表是一个Colocation Join表,并且归属于一个指定的Colocation Group。
如果指定的group_name不存在,则Doris会自动创建一个只包含当前这张表的Group。如果group_name已存在,则Doris会检查当前表是否满足Colocation Group Schema。如果满足,则会创建该表,并将该表加入Group。同时,表会根据已存在的Group中的数据分布规则创建分片和副本。Group归属于一个Database,Group的名字在一个Database内唯一。在内部存储是Group的全名为dbId_groupName,但用户只感知groupName。
当Group中最后一张表彻底删除后(彻底删除是指从回收站中删除。通常,一张表被删除后,会在回收站默认停留一天的时间后,再删除),该Group也会被自动删除。
CREATE TABLE tbl (k1 int, v1 int sum)
DISTRIBUTED BY HASH(k1)
BUCKETS 8
PROPERTIES(
"colocate_with" = "group1"
);
9.7.4.1.3.2 查看Group
SHOW PROC '/colocation_group';
+-------------+--------------+--------------+------------+----------------+----------+----------+
| GroupId | GroupName | TableIds | BucketsNum | ReplicationNum | DistCols | IsStable |
+-------------+--------------+--------------+------------+----------------+----------+----------+
| 10005.10008 | 10005_group1 | 10007, 10040 | 8 | 3 | int(11) | true |
+-------------+--------------+--------------+------------+----------------+----------+----------+
# GroupId : 一个 Group 的全集群唯一标识,前半部分为 db id,后半部分为 group id。
# GroupName :Group 的全名。
# TabletIds :该 Group 包含的 Table 的 id 列表。
# BucketsNum :分桶数。
# ReplicationNum :副本数。
# DistCols :Distribution columns,即分桶列类型。
# IsStable : 该 Group 是否稳定,当 IsStable 为 true 时,表示当前 Group 内的表的所有分片没有正在进行变动,Colocation 特性可以正常使用。当 IsStable 为 false 时,表示当前 Group 内有部分表的分片正在做修复或迁移,此时,相关表的 Colocation Join 将退化为普通 Join。
SHOW PROC '/colocation_group/10005.10008'; # 可以通过GroupId进一步查看各个Bucket在BE节点上的分布。
+-------------+---------------------+
| BucketIndex | BackendIds |
+-------------+---------------------+
| 0 | 10004, 10002, 10001 |
| 1 | 10003, 10002, 10004 |
| 2 | 10002, 10004, 10001 |
| 3 | 10003, 10002, 10004 |
| 4 | 10002, 10004, 10003 |
| 5 | 10003, 10002, 10001 |
| 6 | 10003, 10004, 10001 |
| 7 | 10003, 10004, 10002 |
+-------------+---------------------+
修改CG分组可以通过ALTER TABLE命令进行。
当对一个具有Colocation属性的表进行增加分区、修改副本数时,Doris会检查修改是否会违反Colocation Group Schema,如果违反则会拒绝。
9.7.4.1.3.3 Colocation副本修复
副本只能存储在指定的BE节点上。所以当某个BE不可用时(宕机、Decommission 等),需要寻找一个新的BE进行替换。Doris会优先寻找负载最低的BE进行替换。替换后,该Bucket内的所有旧BE上的数据分片都要做修复。迁移过程中,Group的IsStable为false。为了防止迁移过程中,Colocation join退化为普通join可以在FE节点上设置disable_colocate_relocate = true配置,这个参数只对Colocation表副本修复有用。
9.7.4.1.3.4 Colocation副本均衡
Doris会尽力将Colocation表的分片均匀分布在所有BE节点上。对于普通表的副本均衡,是以单副本为粒度的,即单独为每一个副本寻找负载较低的BE节点即可。而Colocation表的均衡是Bucket级别的,即一个Bucket内的所有副本都会一起迁移。我们采用一个简单的均衡算法,即在不考虑副本实际大小,而只根据副本数量,将BucketsSequence均匀的分布在所有BE上。对于各BE节点的磁盘容量、数量、磁盘类型(SSD、HDD)不一致的情况,副本均衡的效果不佳。可能出现小容量的BE节点和大容量的BE节点存储了相同的副本数量。为了防止副本均衡过程中,Colocation join退化为普通join可以在FE节点上设置disable_colocate_balance = true配置,这个参数只对Colocation表的副本均衡有用。
9.7.4.1.3.5 查询
对于CG分组中的表之间进行join的时候,可以通过EXPLAIN命令查看是否有使用Colocation join。
+----------------------------------------------------+
| Explain String |
+----------------------------------------------------+
| 2:HASH JOIN |
| | join op: INNER JOIN |
| | hash predicates: |
| | colocate: true |
| | `tbl1`.`k2` = `tbl2`.`k2` |
| ... |
+----------------------------------------------------+
# 如上 HASH JOIN的colocate:true则表示查询使用了Colocation join。
9.7.4.2 Bucket Shuffle Join
9.7.4.2.1 原理
Doris支持的常规分布式Join方式包括了shuffle join和broadcast join。这两种join都会导致不小的网络开销,例如:A JOIN B
- Broadcast Join:如果根据数据分布,查询规划出A表有3个执行的HashJoinNode,那么需要将B表全量的发送到3个HashJoinNode,那么它的网络开销是3B,它的内存开销也是3B。
- Shuffle Join:Shuffle Join会将A,B两张表的数据根据哈希计算分散到集群的节点之中,所以它的网络开销为 A + B,内存开销为B。
Bucket Shuffle Join是如果做的:

在FE之中保存了Doris每个表的数据分布信息,如果join语句命中了表的数据分布列,我们应该使用数据分布信息来减少join语句的网络与内存开销。上面的图片展示了Bucket Shuffle Join的工作原理。SQL语句为 A表 join B表,并且join的等值表达式命中了A的数据分布列。而Bucket Shuffle Join会根据A表的数据分布信息,将B表的数据发送到对应的A表的数据存储计算节点。网络开销为B,内存开销也为B。可见,相比于Broadcast Join与Shuffle Join,Bucket Shuffle Join有着较为明显的性能优势。减少数据在节点间的传输耗时和Join时的内存开销。相对于Doris原有的Join方式,它有着下面的优点:
1. 首先,Bucket-Shuffle-Join降低了网络与内存开销,使一些Join查询具有了更好的性能。尤其是当FE能够执行左表的分区裁剪与桶裁剪时。
2. 其次,同时与Colocation Join不同,它对于表的数据分布方式并没有侵入性,这对于用户来说是透明的。对于表的数据分布没有强制性的要求,不容易导致数据倾斜的问题。
9.7.4.2.2 使用方式
# 将session变量enable_bucket_shuffle_join设置为true,则FE在进行查询规划时就会默认将能够转换为Bucket Shuffle Join的查询自动规划为Bucket Shuffle Join。
set enable_bucket_shuffle_join = true;
# 在FE进行分布式查询规划时,优先选择的顺序为 Colocate Join -> Bucket Shuffle Join -> Broadcast Join -> Shuffle Join。但是如果用户显式hint了Join的类型,则上述的选择优先顺序则不生效。
select * from test join [shuffle] baseall on test.k1 = baseall.k1;
# 可以通过EXPLAIN命令来查看Join是否命中Bucket Shuffle Join;
+--------------------------------------------------------------+
| Explain String |
+--------------------------------------------------------------+
| 2:HASH JOIN |
| | join op: INNER JOIN (BUCKET_SHUFFLE) |
| | hash predicates: |
| | colocate: false, reason: table not in the same group |
| | equal join conjunct: `test`.`k1` = `baseall`.`k1` |
+--------------------------------------------------------------+
# 如上,在Join类型之中会指明使用的Join方式为:BUCKET_SHUFFLE。
9.7.4.2.3 Bucket Shuffle Join的规划规则
- Bucket Shuffle Join只生效于Join条件为等值的场景,原因与Colocation Join类似,它们都依赖hash来计算确定的数据分布。
- 在等值Join条件之中包含两张表的分桶列,当左表的分桶列为等值的Join条件时,它有很大概率会被规划为Bucket Shuffle Join。
- Join字段的类型需要保持一致,因为不同类型的值的Hash值不同。
- Bucket Shuffle Join只作用于Doris原生的OLAP表,对于ODBC,MySQL,ES等外表,当其作为左表时是无法规划生效的。
- 对于分区表,由于每一个分区的数据分布规则可能不同,所以Bucket Shuffle Join只能保证左表为单分区时生效。所以在SQL执行之中,需要尽量使用where条件使分区裁剪的策略能够生效。
- 假如左表为Colocation的表,那么它每个分区的数据分布规则是确定的,Bucket Shuffle Join能在Colocation表上表现更好。
9.8 数据湖分析
9.8.1 资源管理
为了节省Doris集群内的计算、存储资源,Doris需要引入一些其他外部资源来完成相关的工作,因此我们引入资源管理机制来管理Doris使用的这些外部资源。一个资源包含名字、类型等基本信息,名字为全局唯一,不同类型的资源包含不同的属性,资源的创建和删除只能由拥有admin权限的用户进行操作。一个资源隶属于整个Doris集群。拥有admin权限的用户可以将某个资源的使用权限usage_priv赋给普通用户。
9.8.1.1 CREATE RESOURCE
该语句用于创建资源。仅root或admin用户可以创建资源。常用的有Spark,JDBC,HDFS,HMS(Hive MetaStore),ES等外部资源。
9.8.1.1.1 语法
CREATE [EXTERNAL] RESOURCE "resource_name"
PROPERTIES ("key"="value", ...);
- PROPERTIES中需要指定资源的类型 “type” = “[spark|jdbc|hdfs|hms|es]”。
- 根据资源类型的不同PROPERTIES有所不同。
- EXTERNAL表示用于外部资源。
9.8.1.1.2 SPARK
# 创建yarn cluster 模式,名为 spark0 的 Spark 资源。
CREATE EXTERNAL RESOURCE "spark0"
PROPERTIES
(
"type" = "spark",
"spark.master" = "yarn",
"spark.submit.deployMode" = "cluster",
"spark.jars" = "xxx.jar,yyy.jar",
"spark.files" = "/tmp/aaa,/tmp/bbb",
"spark.executor.memory" = "1g",
"spark.yarn.queue" = "queue0",
"spark.hadoop.yarn.resourcemanager.address" = "127.0.0.1:9999",
"spark.hadoop.fs.defaultFS" = "hdfs://127.0.0.1:10000",
"working_dir" = "hdfs://127.0.0.1:10000/tmp/doris",
"broker" = "broker0",
"broker.username" = "user0",
"broker.password" = "password0"
);
- spark.master: 必填,目前支持yarn、spark://host:port。
- spark.submit.deployMode: Spark 程序的部署模式,必填,支持 cluster,client 两种。
- spark.hadoop.yarn.resourcemanager.address: master为yarn时必填。
- spark.hadoop.fs.defaultFS: master为yarn时必填。
- 其他参数为可选,参考这里。
- Spark资源如果用于Spark Load需要指定working_dir和broker。
- working_dir: ETL 使用的目录。spark作为ETL资源使用时必填。例如:hdfs://host:port/tmp/doris。
- broker: broker 名字。spark作为ETL资源使用时必填。需要使用ALTER SYSTEM ADD BROKER 命令提前完成配置。
- broker.property_key: broker读取ETL生成的中间文件时需要指定的认证信息等。
9.8.1.1.3 JDBC
CREATE RESOURCE mysql_resource PROPERTIES (
"type"="jdbc",
"user"="root",
"password"="123456",
"jdbc_url" = "jdbc:mysql://127.0.0.1:3316/doris_test?useSSL=false",
"driver_url" = "https://doris-community-test-1308700295.cos.ap-hongkong.myqcloud.com/jdbc_driver/mysql-connector-java-8.0.25.jar",
"driver_class" = "com.mysql.cj.jdbc.Driver"
);
9.8.1.1.4 HDFS
CREATE RESOURCE hdfs_resource PROPERTIES (
"type"="hdfs",
"username"="user",
"password"="passwd",
"dfs.nameservices" = "my_ha",
"dfs.ha.namenodes.my_ha" = "my_namenode1, my_namenode2",
"dfs.namenode.rpc-address.my_ha.my_namenode1" = "nn1_host:rpc_port",
"dfs.namenode.rpc-address.my_ha.my_namenode2" = "nn2_host:rpc_port",
"dfs.client.failover.proxy.provider" = "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
);
9.8.1.1.5 HMS
CREATE RESOURCE hms_resource PROPERTIES (
'type'='hms',
'hive.metastore.uris' = 'thrift://127.0.0.1:7004',
'dfs.nameservices'='HANN',
'dfs.ha.namenodes.HANN'='nn1,nn2',
'dfs.namenode.rpc-address.HANN.nn1'='nn1_host:rpc_port',
'dfs.namenode.rpc-address.HANN.nn2'='nn2_host:rpc_port',
'dfs.client.failover.proxy.provider.HANN'='org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider'
);
# hive.metastore.uris: hive metastore server地址 可选参数:
# dfs.*: 如果 hive 数据存放在hdfs,需要添加类似 HDFS resource 的参数,也可以将 hive-site.xml 拷贝到 fe/conf 目录下
9.8.1.1.6 ES
CREATE RESOURCE es_resource PROPERTIES (
"type"="es",
"hosts"="http://127.0.0.1:29200",
"nodes_discovery"="false",
"enable_keyword_sniff"="true"
);
# nodes_discovery: 是否开启 ES 节点发现,默认为 true,在网络隔离环境下设置为 false,只连接指定节点。
# http_ssl_enabled: ES 是否开启 https 访问模式,目前在 fe/be 实现方式为信任所有。
# enable_keyword_sniff: 是否对 ES 中字符串分词类型 text.fields 进行探测,通过 keyword 进行查询(默认为 true,设置为 false 会按照分词后的内容匹配)
# enable_docvalue_scan: 是否开启通过 ES/Lucene 列式存储获取查询字段的值,默认为 true
9.8.1.2 SHOW RESOURCE
该语句用于展示用户有使用权限的资源。普通用户仅能展示有使用权限的资源,root或admin用户会展示所有的资源。
SHOW RESOURCES
[
WHERE
[NAME [ = "your_resource_name" | LIKE "name_matcher"]]
[RESOURCETYPE = ["SPARK"]]
]
[ORDER BY ...]
[LIMIT limit][OFFSET offset];
9.8.1.3 DROP RESOURCE
该语句用于删除一个已有的资源。仅root或admin用户可以删除资源。
DROP RESOURCE 'resource_name';
9.8.2 基本概念
其实 Doris 本身是一套完备的数据库管理系统,包括查询层和存储层。在我们正常使用 Doris 的时候,只需要把数据灌入到 Doris 中来,就可以在 Doris 内部对数据进行管理、存储和查询,我们叫做内置数据存储(Internal Storage)。在实际业务应用中,还会有大量数据存储在外部数据源中的,比如可能有很多历史数据,本身已经存在 Hive 系统中,或者是最近比较火的 Iceberg、Hudi 等数据湖格式中。如果用户要把这些系统中的数据通过导入操作导入到 Doris 中来,代价是非常大的,因为数据量可能是 TB 甚至 PB 级别的。把这些数据进行一次清理加工的计算量和存储开销都是非常大的。所以很多用户希望借助 Doris 的高速查询能力,直接对外部数据源的数据进行分析。这也是 Doris 数据湖分析、或者外部数据源加速分析的一个初衷。
所以在 Doris 的新版本中,通过引入 Catalog 的概念,简化这一操作,让用户可以通过一行命令就能快速开始对外部数据进行分析。

Catalog 是标准 SQL 定义中的三个层级之一,就是 Catalog-Database-Table。我们将 Catalog 分为两大类,一类是 Internal Catalog,另一类是 External Catalog。其中 Internal Catalog 是管理 Doris 的内部表。External Catalog 可以直接映射到一个数据源。比如一个 Hive 集群、 ES 集群、 MySQL 数据库等等。通过数据源映射,Doris 内部会自动的把外部的 database 和 table 进行同步。所以在上图中可以看到,中间这一层, database 和 table 用虚线来表示。也就是当创建完 Catalog 后,Doris 内部会自动把数据源中的 database,table 的信息全都同步过来,从而省去了单独手动映射每一张表的繁琐工作,快速接入到这些外部数据源进行查询。通过这种方式,可以极大的降低对外部数据源接入的门槛儿。
目前Doris支持几种主要的数据源。第一类为Hive MetaStore,第二类为JDBC Catalog;第三类为ElasticSearch。
可以通过 CREATE CATALOG 命令创建一个 External Catalog。创建后,可以通过 SHOW CATALOGS 命令查看已创建的 Catalog。
用户可以通过如下命令在不同的Catalog之间进行切换。切换后,可以直接通过 SHOW DATABASES,USE DB 等命令查看和切换对应 Catalog 中的 Database。Doris 会自动通过 Catalog 中的 Database 和 Table。用户可以像使用 Internal Catalog 一样,对 External Catalog 中的数据进行查看和访问。当前,Doris 只支持对 External Catalog 中的数据进行只读访问。
External Catalog 中的 Database 和 Table 都是只读的。但是可以删除 Catalog(Internal Catalog无法删除)。可以通过 DROP CATALOG 命令删除一个 External Catalog。该操作仅会删除 Doris 中该 Catalog 的映射信息,并不会修改或变更任何外部数据目录的内容。
SWITCH INTERNAL;
SWITCH HIVE_CATALOG;
9.8.3 CREATE CATALOG
1.2.1版本之后,可以通过RESOURCE进行CATALOG的创建。
CREATE CATALOG [IF NOT EXISTS] catalog_name [WITH RESOURCE resource_name][PROPERTIES ("key"="value", ...)];
CREATE RESOURCE hms_resource PROPERTIES (
'type'='hms',
'hive.metastore.uris' = 'thrift://127.0.0.1:7004',
'dfs.nameservices'='HANN',
'dfs.ha.namenodes.HANN'='nn1,nn2',
'dfs.namenode.rpc-address.HANN.nn1'='nn1_host:rpc_port',
'dfs.namenode.rpc-address.HANN.nn2'='nn2_host:rpc_port',
'dfs.client.failover.proxy.provider.HANN'='org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider'
);
CREATE CATALOG hive WITH RESOURCE hms_resource;
CREATE RESOURCE es_resource PROPERTIES (
"type"="es",
"hosts"="http://127.0.0.1:9200"
);
CREATE CATALOG es WITH RESOURCE es_resource;
CREATE RESOURCE mysql_resource PROPERTIES (
"type"="jdbc",
"user"="root",
"password"="123456",
"jdbc_url" = "jdbc:mysql://127.0.0.1:3316/doris_test?useSSL=false",
"driver_url" = "https://doris-community-test-1308700295.cos.ap-hongkong.myqcloud.com/jdbc_driver/mysql-connector-java-8.0.25.jar",
"driver_class" = "com.mysql.cj.jdbc.Driver"
);
CREATE CATALOG jdbc WITH RESOURCE mysql_resource;
9.8.3.1 Hive
在连接Hive的时候可以增加这个参数specified_database_list,表示同步指定的database,以逗号分割。默认情况下是同步所有的database。db名称大小写敏感。file.meta.cache.ttl-second这个参数也可以增加,表示使用File Cache优化方法设置的文件缓存过期时间。单位为秒。Doris 可以正确访问不同 Hive 版本中的 Hive Metastore。在默认情况下,Doris 会以 Hive 2.3 版本的兼容接口访问 Hive Metastore。你也可以在创建 Catalog 时通过hive.version参数指定具体的版本。
9.8.3.2 JDBC
除了基本的连接参数之外,还有如下的参数:
| 参数 | 是否必须 | 默认值 | 说明 |
|---|---|---|---|
| only_specified_database | 否 | “false” | 指定是否只同步指定的 database |
| lower_case_table_names | 否 | “false” | 是否以小写的形式同步jdbc外部数据源的表名 |
| oceanbase_mode | 否 | “” | 当连接的外部数据源为OceanBase时,必须为其指定模式为mysql或oracle |
| include_database_list | 否 | “” | 当only_specified_database=true时,指定同步多个database,以’,'分隔。db名称是大小写敏感的。 |
| exclude_database_list | 否 | “” | 当only_specified_database=true时,指定不需要同步的多个database,以’,'分割。db名称是大小写敏感的。 |
| 在Doris中建立JDBC Catalog后,可以通过insert into语句直接写入数据,也可以将Doris执行完查询之后的结果写入JDBC Catalog,或者是从一个JDBC外表将数据导入另一个JDBC外表。 |
9.8.3.3 Elasticsearch
9.8.3.3.1 查询Elasticsearch的原理
+----------------------------------------------+
| |
| Doris +------------------+ |
| | FE +--------------+-------+
| | | Request Shard Location
| +--+-------------+-+ | |
| ^ ^ | |
| | | | |
| +-------------------+ +------------------+ | |
| | | | | | | | |
| | +----------+----+ | | +--+-----------+ | | |
| | | BE | | | | BE | | | |
| | +---------------+ | | +--------------+ | | |
+----------------------------------------------+ |
| | | | | | |
| | | | | | |
| HTTP SCROLL | | HTTP SCROLL | |
+-----------+---------------------+------------+ |
| | v | | v | | |
| | +------+--------+ | | +------+-------+ | | |
| | | | | | | | | | |
| | | DataNode | | | | DataNode +<-----------+
| | | | | | | | | | |
| | | +<--------------------------------+
| | +---------------+ | | |--------------| | | |
| +-------------------+ +------------------+ | |
| Same Physical Node | |
| | |
| +-----------------------+ | |
| | | | |
| | MasterNode +<-----------------+
| ES | | |
| +-----------------------+ |
+----------------------------------------------+
- FE会请求建表指定的主机,获取所有节点的HTTP端口信息以及index的shard分布信息等,如果请求失败会顺序遍历host列表直至成功或完全失败。
- 查询时会根据FE得到的一些节点信息和index的元数据信息,生成查询计划并发给对应的BE节点。
- BE节点会根据就近原则即优先请求本地部署的ES节点,BE通过HTTP Scroll方式流式的从ES index的每个分片中并发的从_source或docvalue中获取数据。
- Doris计算完结果后,返回给用户。
9.8.4 SHOW CATALOGS
# 该语句用于显示已存在是数据目录(catalog)
SHOW CATALOGS [LIKE];
# 返回结果说明:
1. CatalogId # 数据目录唯一ID
2. CatalogName # 数据目录名称。其中 internal 是默认内置的 catalog,不可修改。
3. Type # 数据目录类型。
4. IsCurrent # 是否为当前正在使用的数据目录。
SHOW CATALOGS;
+-----------+-------------+----------+-----------+
| CatalogId | CatalogName | Type | IsCurrent |
+-----------+-------------+----------+-----------+
| 130100 | hive | hms | |
| 0 | internal | internal | yes |
+-----------+-------------+----------+-----------+
9.8.5 SHOW CREATE CATALOG
# 该语句查看doris数据目录的创建语句。
SHOW CREATE CATALOG catalog_name;
9.8.6 DROP CATALOG
# 该语句用于删除外部数据目录(catalog)
DROP CATALOG [IF EXISTS] catalog_name;
9.8.7 列类型映射
用户创建 Catalog 后,Doris 会自动同步数据目录的数据库和表,针对不同的数据目录和数据表格式,Doris 会进行以下列映射关系。对于当前无法映射到 Doris 列类型的外表类型,如 UNION, INTERVAL 等。Doris 会将列类型映射为 UNSUPPORTED 类型。对于 UNSUPPORTED 类型的查询,示例如下:
k1 INT,
k2 INT,
k3 UNSUPPORTED,
k4 INT
select * from table; // Error: Unsupported type 'UNSUPPORTED_TYPE' in '`k3`
select * except(k3) from table; // Query OK.
select k1, k3 from table; // Error: Unsupported type 'UNSUPPORTED_TYPE' in '`k3`
select k1, k4 from table; // Query OK.
9.8.8 元数据更新
9.8.8.1 手动更新
默认情况下,外部数据源的元数据变动,如创建、删除表,加减列等操作,不会同步给 Doris。用户需要通过REFRESH CATALOG 命令手动刷新元数据。
9.8.8.2 定时更新
在创建catalog时,在properties 中指定刷新时间参数metadata_refresh_interval_sec ,以秒为单位,若在创建catalog时设置了该参数,FE 的master节点会根据参数值定时刷新该catalog。目前支持三种类型 hms、es、jdbc。
9.8.9 计算节点
9.8.9.1 需求场景
目前Doris是一个典型Share-Nothing的架构, 通过绑定数据和计算资源在同一个节点获得非常好的性能表现. 但随着Doris计算引擎性能持续提高, 越来越多的用户也开始选择使用Doris直接查询数据湖数据. 这类场景是一种Share-Disk场景, 数据往往存储在远端的HDFS/S3上, 计算在Doris中, Doris通过网络获取数据, 然后在内存完成计算. 而如果这两个负载都混合在同一个集群时, 对于目前Doris的架构就会出现以下不足:
- 资源隔离差, 两个负载对集群的响应要求不一, 混合部署会有相互的影响.
- 集群扩容时, 数据湖查询只需要扩容计算资源, 而目前只能存储计算一起扩容, 导致磁盘使用率变低.
- 扩容效率差, 扩容后会启动Tablet数据的迁移, 整体过程比较漫长. 而数据湖查询有着明显的高峰低谷, 需要小时级弹性能力.
9.8.9.2 解决方案
实现一种专门用于联邦计算的BE节点角色: 计算节点, 计算节点专门处理数据湖这类远程的联邦查询. 原来的BE节点类型称为混合节点, 这类节点既能做SQL查询, 又有Tablet数据存储管理. 而计算节点只能做SQL查询, 它不会保存任何数据。有了计算节点后, 集群部署拓扑也会发生变化: 混合节点用于OLAP类型表的数据计算, 这个节点根据存储的需求而扩容, 而计算节点用于联邦查询, 该节点类型随着计算负载而扩容。此外, 计算节点由于没有存储, 因此在部署时, 计算节点可以混部在HDD磁盘机器或者部署在容器之中。
9.8.9.3 使用
# 在BE的配置文件be.conf中添加配置项:
be_node_role=computation
# 该配置项默认为mix, 即原来的BE节点类型, 设置为computation后, 该节点为计算节点.
# 可以通过show backend\G;命令看到其中NodeRole字段的值, 如果是mix, 则为混合节点, 如果是computation, 则为计算节点。
# 在 fe.conf 中添加配置项
prefer_compute_node_for_external_table=true # 设置为true的话,则对外部表的查询将优先分配给计算节点。如果设置为 false,对外部表的查询将分配给任何节点。
min_backend_num_for_external_table=3 # 仅在 prefer_compute_node_for_external_table 为 true 时生效。如果计算节点数小于此值,则对外部表的查询将尝试使用一些混合节点,让节点总数达到这个值。 如果计算节点数大于这个值,外部表的查询将只分配给计算节点。
9.8.10 文件缓存
文件缓存(File Cache)通过缓存最近访问的远端存储系统(HDFS 或对象存储)的数据文件,加速后续访问相同数据的查询。在频繁访问相同数据的查询场景中,File Cache 可以避免重复的远端数据访问开销,提升热点数据的查询分析性能和稳定性。
9.8.10.1 原理
File Cache 将访问的远程数据缓存到本地的 BE 节点。原始的数据文件会根据访问的 IO 大小切分为 Block,Block 被存储到本地文件 cache_path/hash(filepath).substr(0, 3)/hash(filepath)/offset 中,并在 BE 节点中保存 Block 的元信息。当访问相同的远程文件时,doris 会检查本地缓存中是否存在该文件的缓存数据,并根据 Block 的 offset 和 size,确认哪些数据从本地 Block 读取,哪些数据从远程拉起,并缓存远程拉取的新数据。BE 节点重启的时候,扫描 cache_path 目录,恢复 Block 的元信息。当缓存大小达到阈值上限的时候,按照 LRU 原则清理长久未访问的 Block。
9.8.10.2 使用
File Cache 默认关闭,需要在 FE 和 BE 中设置相关参数进行开启。
# FE 配置
SET GLOBAL enable_file_cache = true;
# BE 配置,添加参数到 BE 节点的配置文件 conf/be.conf 中,并重启 BE 节点让配置生效。
enable_file_cache = true;
9.8.10.3 查看 File Cache 命中情况
执行 set enable_profile=true 打开会话变量,可以在 FE 的 web 页面的 Queris 标签中查看到作业的 Profile。File Cache 相关的指标如下:
- FileCache:
- IOHitCacheNum: 552 # 命中缓存的次数
- IOTotalNum: 835 # 远程访问的次数
- ReadFromFileCacheBytes: 19.98 MB # 从缓存文件中读取的数据量
- ReadFromWriteCacheBytes: 0.00 #
- ReadTotalBytes: 29.52 MB # 总共读取的数据量
- WriteInFileCacheBytes: 915.77 MB # 保存到缓存文件中的数据量
- WriteInFileCacheNum: 283 # 保存的 Block 数量,所以 WriteInFileCacheBytes/WriteInFileCacheBytes 为 Block 的平均大小。
- SkipCacheBytes: # 创建缓存文件失败,或者缓存文件被删,需要再次从远程读取的数据量
# IOHitCacheNum / IOTotalNum 等于1,表示缓存完全命中。
# ReadFromFileCacheBytes / ReadTotalBytes 等于1,表示缓存完全命中。
9.9 常用命令
9.9.1 SHOW DATA
SHOW DATA [FROM db_name[.table_name]] [ORDER BY ...];
如果不指定 FROM 子句,则展示当前 db 下细分到各个 table 的数据量和副本数量。其中数据量为所有副本的总数据量。而副本数量为表的所有分区以及所有物化视图的副本数量。
SHOW DATA;
+-----------+-------------+--------------+
| TableName | Size | ReplicaCount |
+-----------+-------------+--------------+
| tbl1 | 900.000 B | 6 |
| tbl2 | 500.000 B | 3 |
| Total | 1.400 KB | 9 |
| Quota | 1024.000 GB | 1073741824 |
| Left | 1021.921 GB | 1073741815 |
+-----------+-------------+--------------+
如果指定 FROM 子句,则展示 table 下细分到各个物化视图的数据量、副本数量和统计行数。其中数据量为所有副本的总数据量。副本数量为对应物化视图的所有分区的副本数量。统计行数为对应物化视图的所有分区统计行数。统计行数时,以多个副本中,行数最大的那个副本为准。结果集中的 Total 行表示汇总行。Quota 行表示当前数据库设置的配额。Left 行表示剩余配额。可以使用 ORDER BY 对任意列组合进行排序。可以通过SHOW PARTITIONS查看各个分区的数据情况。
SHOW DATA FROM example_db.test;
+-----------+-----------+-----------+--------------+----------+
| TableName | IndexName | Size | ReplicaCount | RowCount |
+-----------+-----------+-----------+--------------+----------+
| test | r1 | 10.000MB | 30 | 10000 |
| | r2 | 20.000MB | 30 | 20000 |
| | test2 | 50.000MB | 30 | 50000 |
| | Total | 80.000 | 90 | |
+-----------+-----------+-----------+--------------+----------+
SHOW DATA ORDER BY ReplicaCount desc,Size asc;
+-----------+-------------+--------------+
| TableName | Size | ReplicaCount |
+-----------+-------------+--------------+
| table_c | 3.102 KB | 40 |
| table_d | .000 | 20 |
| table_b | 324.000 B | 20 |
| table_a | 1.266 KB | 10 |
| Total | 4.684 KB | 90 |
| Quota | 1024.000 GB | 1073741824 |
| Left | 1024.000 GB | 1073741734 |
+-----------+-------------+--------------+
9.9.2 SHOW DATA SKEW
# 该语句用于查看表或某个分区的数据倾斜情况。
SHOW DATA SKEW FROM [db_name.]tbl_name PARTITION (partition_name);
# 1. 必须指定且仅指定一个分区。对于非分区表,分区名称同表名。
# 2. 结果将展示指定分区下,各个分桶的数据行数,数据量,以及每个分桶数据量在总数据量中的占比。
9.9.3 SHOW PARTITIONS
# 语法
SHOW [TEMPORARY] PARTITIONS FROM [db_name.]table_name [WHERE] [ORDER BY] [LIMIT];
SHOW DYNAMIC PARTITION TABLES [FROM db_name];
SHOW PARTITION [partition_id]
# 示例
SHOW PARTITIONS FROM example_db.table_name;
SHOW TEMPORARY PARTITIONS FROM example_db.table_name;
SHOW PARTITIONS FROM example_db.table_name WHERE PartitionName = "p1";
SHOW PARTITIONS FROM example_db.table_name ORDER BY PartitionId DESC LIMIT 1;
SHOW PARTITION 10002;
SHOW DYNAMIC PARTITION TABLES FROM database;
9.9.4 SHOW FRONTENDS
SHOW FRONTENDS;
# name: 表示该 FE 节点在系统中的名称。
# Join: 为 true 表示该节点曾经加入过集群。但不代表当前还在集群内(可能已失联)
# Alive: 表示节点是否存活。
# ReplayedJournalId:表示该节点当前已经回放的最大元数据日志id。
# LastHeartbeat:是最近一次心跳。
# IsHelper:表示该节点是否是系统中的 helper 节点。
# ErrMsg:用于显示心跳失败时的错误信息。
# CurrentConnected:表示是否是当前连接的FE节点
9.9.5 SHOW BACKENDS
SHOW BACKENDS;
# 1. LastStartTime 表示最近一次 BE 启动时间。
# 2. LastHeartbeat 表示最近一次心跳。
# 3. Alive 表示节点是否存活。
# 4. SystemDecommissioned 为 true 表示节点正在安全下线中。
# 5. ClusterDecommissioned 为 true 表示节点正在从当前集群中下线。
# 6. TabletNum 表示该节点上分片数量。
# 7. DataUsedCapacity 表示实际用户数据所占用的空间。
# 8. AvailCapacity 表示磁盘的可使用空间。
# 9. TotalCapacity 表示总磁盘空间。TotalCapacity = AvailCapacity + DataUsedCapacity + 其他非用户数据文件占用空间。
# 10. UsedPct 表示磁盘已使用量百分比。
# 11. ErrMsg 用于显示心跳失败时的错误信息。
# 12. Status 用于以 JSON 格式显示BE的一些状态信息, 目前包括最后一次BE汇报其tablet的时间信息。
9.9.6 SHOW BROKER
SHOW BROKER;
# 1. LastStartTime 表示最近一次 BE 启动时间。
# 2. LastHeartbeat 表示最近一次心跳。
# 3. Alive 表示节点是否存活。
# 4. ErrMsg 用于显示心跳失败时的错误信息。
9.9.7 SHOW CREATE TABLE
# 用于展示数据表的创建语句.
SHOW [BRIEF] CREATE TABLE [DBNAME.]TABLE_NAME;
[BRIEF] : 返回结果中不展示分区信息
SHOW CREATE TABLE demo.tb1;
9.9.8 SHOW LOAD
9.9.8.1 语法
# 该语句用于展示指定的导入任务的执行情况
SHOW LOAD
[FROM db_name]
[
WHERE
[LABEL [ = "your_label" | LIKE "label_matcher"]]
[STATE = ["PENDING"|"ETL"|"LOADING"|"FINISHED"|"CANCELLED"|]]
]
[ORDER BY ...]
[LIMIT limit][OFFSET offset];
# 1) 如果不指定 db_name,使用当前默认db
# 2) 如果使用 LABEL LIKE,则会匹配导入任务的 label 包含 label_matcher 的导入任务
# 3) 如果使用 LABEL = ,则精确匹配指定的 label
# 4) 如果指定了 STATE,则匹配 LOAD 状态
# 5) 可以使用 ORDER BY 对任意列组合进行排序
# 6) 如果指定了 LIMIT,则显示 limit 条匹配记录。否则全部显示
# 7) 如果指定了 OFFSET,则从偏移量offset开始显示查询结果。默认情况下偏移量为0。
9.9.8.2 示例
# 展示默认 db 的所有导入任务
SHOW LOAD;
# 展示指定 db 的导入任务,label 中包含字符串 "2014_01_02",展示最老的10个
SHOW LOAD FROM example_db WHERE LABEL LIKE "2014_01_02" LIMIT 10;
# 展示指定 db 的导入任务,指定 label 为 "load_example_db_20140102" 并按 LoadStartTime 降序排序
SHOW LOAD FROM example_db WHERE LABEL = "load_example_db_20140102" ORDER BY LoadStartTime DESC;
# 展示指定 db 的导入任务,指定 label 为 "load_example_db_20140102" ,state 为 "loading", 并按 LoadStartTime 降序排序
SHOW LOAD FROM example_db WHERE LABEL = "load_example_db_20140102" AND STATE = "loading" ORDER BY LoadStartTime DESC;
# 展示指定 db 的导入任务 并按 LoadStartTime 降序排序,并从偏移量5开始显示10条查询结果
SHOW LOAD FROM example_db ORDER BY LoadStartTime DESC limit 5,10;
9.9.9 CANCEL LOAD
9.9.9.1 语法
# 该语句用于撤销指定 label 的导入作业。或者通过模糊匹配批量撤销导入作业
CANCEL LOAD [FROM db_name] WHERE [LABEL = "load_label" | LABEL like "label_pattern" | STATE = "PENDING/ETL/LOADING"]
9.9.9.2 示例
# 撤销数据库 db_name上label为example_db_test_load_label 的导入作业
CANCEL LOAD FROM example_db WHERE LABEL = "example_db_test_load_label";
# 撤销数据库 db_name上所有label包含 example 的导入作业。
CANCEL LOAD FROM example_db WHERE LABEL like "example_";
# 当使用状态进行过滤的时候,只能取消处于 PENDING、ETL、LOADING 状态的未完成的导入作业。
当执行批量撤销时,Doris 不会保证所有对应的导入作业原子的撤销。即有可能仅有部分导入作业撤销成功。用户可以通过SHOW LOAD 语句查看作业状态,并尝试重复执行 CANCEL LOAD 语句。
9.9.10 SHOW STREAM LOAD
9.9.10.1 语法
# 该语句用于展示指定的Stream Load任务的执行情况
SHOW STREAM LOAD
[FROM db_name]
[
WHERE
[LABEL [ = "your_label" | LIKE "label_matcher"]]
[STATUS = ["SUCCESS"|"FAIL"]]
]
[ORDER BY ...]
[LIMIT limit][OFFSET offset];
# 1. 默认 BE 是不记录 Stream Load 的记录,如果你要查看需要在 BE 上启用记录,配置参数是:enable_stream_load_record=true。
# 2. 如果不指定 db_name,使用当前默认db。
# 3. 如果使用 LABEL LIKE,则会匹配Stream Load任务的 label 包含 label_matcher 的任务。
# 4. 如果使用 LABEL = ,则精确匹配指定的 label。
# 5. 如果指定了 STATUS,则匹配 STREAM LOAD 状态。
# 6. 可以使用 ORDER BY 对任意列组合进行排序。
# 7. 如果指定了 LIMIT,则显示 limit 条匹配记录。否则全部显示。
# 8. 如果指定了 OFFSET,则从偏移量offset开始显示查询结果。默认情况下偏移量为0。
9.9.10.2 示例
# 展示默认 db 的所有Stream Load任务
SHOW STREAM LOAD;
# 展示指定 db 的Stream Load任务,label 中包含字符串 "2014_01_02",展示最老的10个
SHOW STREAM LOAD FROM example_db WHERE LABEL LIKE "2014_01_02" LIMIT 10;
# 展示指定 db 的Stream Load任务,指定 label 为 "load_example_db_20140102"。
SHOW STREAM LOAD FROM example_db WHERE LABEL = "load_example_db_20140102";
# 展示指定 db 的Stream Load任务,指定 status 为 "success", 并按 StartTime 降序排序
SHOW STREAM LOAD FROM example_db WHERE STATUS = "success" ORDER BY StartTime DESC;
# 展示指定 db 的导入任务 并按 StartTime 降序排序,并从偏移量5开始显示10条查询结果。
SHOW STREAM LOAD FROM example_db ORDER BY StartTime DESC limit 5,10;
9.9.11 CREATE FILE
该语句用于创建并上传一个文件到 Doris 集群。 该功能通常用于管理一些其他命令中需要使用到的文件,如证书、公钥私钥等等。该命令只用 admin 权限用户可以执行。 某个文件都归属与某一个的 database。对 database 拥有访问权限的用户都可以使用该文件。
单个文件大小限制为 1MB。 一个 Doris 集群最多上传 100 个文件。
9.9.11.1 语法
CREATE FILE "file_name" [IN database] [properties]
# file_name: 自定义文件名。
# database: 文件归属于某一个 db,如果没有指定,则使用当前 session 的 db。
# properties 支持以下参数:
# url:必须。指定一个文件的下载路径。当前仅支持无认证的 http 下载路径。命令执行成功后,文件将被保存在 doris 中,该 url 将不再需要。
# catalog:必须。对文件的分类名,可以自定义。但在某些命令中,会查找指定 catalog 中的文件。比如例行导入中的,数据源为 kafka 时,会查找 catalog 名为 kafka 下的文件。
# md5: 可选。文件的 md5。如果指定,会在下载文件后进行校验。
9.9.11.2 示例
# 创建文件 ca.pem ,分类为 kafka
CREATE FILE "ca.pem" PROPERTIES("url" = "https://test.bj.bcebos.com/kafka-key/ca.pem","catalog" = "kafka");
# 创建文件 client.key,分类为 kafka
CREATE FILE "client.key" IN my_database PROPERTIES("url" = "https://test.bj.bcebos.com/kafka-key/client.key","catalog" = "kafka","md5" = "b5bb901bf10f99205b39a46ac3557dd9");
9.9.12 DELETE
# 适用于所有模型
DELETE FROM table_name [PARTITION partition_name | PARTITIONS (partition_name [, partition_name])] WHERE condition;
# 只适用于UNIQUE模型
DELETE FROM table_name [PARTITION partition_name | PARTITIONS (partition_name [, partition_name])][USING additional_tables] WHERE condition;
- 对于分区表的话,指定的分区如果不存在,会报错。
- USING additional_tables表示如果需要在WHERE语句中使用其他的表来帮助识别需要删除的行,则可以在USING中指定这些表或者查询。
- 使用聚合类的表模型(AGGREGATE、UNIQUE)只能指定 key 列上的条件。
- 当选定的 key 列不存在于某个 rollup 中时,无法进行 delete。
- 条件之间不能使用或,这个在Doris中是不支持的。
- 如果为分区表,需要指定分区,如果不指定,Doris 会从条件中推断出分区。如果无法推断出分区的话,当会话变量delete_without_partition 为 true时,此时delete语句会应用到整个分区中。
- delete语句会降低执行后一段时间内的查询效率。影响程度取决于语句中指定的删除条件的数量。指定的条件越多,影响越大。
9.9.13 SHOW ALTER TABLE MATERIALIZED VIEW
SHOW ALTER TABLE MATERIALIZED VIEW [FROM database] [WHERE] [ORDER BY][LIMIT OFFSET];
# database: 查看指定数据库下的作业。如不指定,使用当前数据库。
# WHERE:可以对结果列进行筛选,目前仅支持对以下列进行筛选:
# TableName:仅支持等值筛选。
# State:仅支持等值筛选。
# Createtime/FinishTime:支持 =,>=,<=,>,<,!=
# ORDER BY:可以对结果集按任意列进行排序。
# LIMIT:配合 ORDER BY 进行翻页查询。
# 查询结果
JobId # 作业唯一ID。
TableName # 基表名称
CreateTime # 作业创建时间
FinishTime # 作业结束时间
BaseIndexName # 基表名称
RollupIndexName # 物化视图名称
RollupId # 物化视图的唯一ID
TransactionId # 在正式开始产生物化视图数据前,会等待当前这个表上的正在运行的导入事务完成。而 TransactionId 字段就是当前正在等待的事务ID。
State # PENDING:作业准备中;WAITING_TXN:作业等待中;RUNNING:作业运行中;FINISHED:作业运行成功;CANCELLED:作业运行失败。
Msg # 错误信息
Progress # 作业进度。这里的进度表示 已完成的tablet数量/总tablet数量。创建物化视图是按 tablet 粒度进行的。
Timeout # 作业超时时间,单位秒。
9.9.14 SHOW CATALOG RECYCLE BIN
# 该语句用于展示回收站中可回收的库,表或分区元数据信息
SHOW CATALOG RECYCLE BIN [ WHERE NAME [ = "name" | LIKE "name_matcher"] ];
#结果
1. Type: # 元数据类型:Database、Table、Partition
2. Name: # 元数据名称
3. DbId: # database对应的id
4. TableId: # table对应的id
5. PartitionId: # partition对应的id
6. DropTime: # 元数据放入回收站的时间
9.9.15 SHOW VARIABLES
该语句是用来显示Doris系统变量,可以通过条件查询。SHOW VARIABLES主要是用来查看系统变量的值。执行SHOW VARIABLES命令不需要任何权限,只要求能够连接到服务器就可以.
SHOW [GLOBAL | SESSION] VARIABLES [LIKE 'pattern' | WHERE expr];
# 这里默认的就是对Variable_name进行匹配,这里是准确匹配
show variables like 'max_connections';
# 通过百分号(%)这个通配符进行匹配,可以匹配多项
show variables like '%connec%';
# 使用 Where 子句进行匹配查询
show variables where variable_name = 'version';
9.9.16 SHOW GRANTS
该语句用于查看用户权限。
SHOW [ALL] GRANTS [FOR user_identity];
# SHOW ALL GRANTS 可以查看所有用户的权限。
# 如果指定 user_identity,则查看该指定用户的权限。且该 user_identity 必须为通过 CREATE USER 命令创建的。
# 如果不指定 user_identity,则查看当前用户的权限。
9.9.17 SHOW FILES
# 该语句用于展示一个数据库内,由 CREATE FILE 命令创建的文件。
SHOW FILE [FROM database];
# 返回结果说明:
1. FileId: # 文件ID,全局唯一
2. DbName: # 所属数据库名称
3. Catalog: # 自定义分类
4. FileName: # 文件名
5. FileSize: # 文件大小,单位字节
6. MD5: # 文件的 MD5
9.9.18 REFRESH CATALOG
该语句用于刷新指定 Catalog/Database/Table 的元数据。刷新Catalog的同时,会强制使对象相关的 Cache 失效。包括Partition Cache、Schema Cache、File Cache等。
REFRESH CATALOG catalog_name;
REFRESH DATABASE [catalog_name.]database_name;
REFRESH TABLE [catalog_name.][database_name.]table_name;
10 数据库管理
10.1 ADMIN DIAGNOSE TABLET
# 该语句用于诊断指定 tablet。结果中将显示这个 tablet 的信息和一些潜在的问题。
ADMIN DIAGNOSE TABLET tblet_id;
1. TabletExist: # Tablet是否存在
2. TabletId: # Tablet ID
3. Database: # Tablet 所属 DB 和其 ID
4. Table: # Tablet 所属 Table 和其 ID
5. Partition: # Tablet 所属 Partition 和其 ID
6. MaterializedIndex: # Tablet 所属物化视图和其 ID
7. Replicas(ReplicaId -> BackendId): # Tablet 各副本和其所在 BE。
8. ReplicasNum: # 副本数量是否正确。
9. ReplicaBackendStatus: # 副本所在 BE 节点是否正常。
10.ReplicaVersionStatus: # 副本的版本号是否正常。
11.ReplicaStatus: # 副本状态是否正常。
12.ReplicaCompactionStatus: # 副本 Compaction 状态是否正常。
10.2 ADMIN SHOW CONFIG
# 该语句用于展示当前FE集群的所有配置
ADMIN SHOW FRONTEND CONFIG [LIKE "pattern"];
1. Key # 配置项名称
2. Value # 配置项值
3. Type # 配置项类型
4. IsMutable # 是否可以通过 ADMIN SET CONFIG 命令设置
5. MasterOnly # 是否仅适用于 Master FE
6. Comment # 配置项说明
10.3 KILL
# 每个 Doris 的连接都在一个单独的线程中运行。 您可以使用 KILL processlist_id 语句终止线程。线程进程列表标识符可以从 INFORMATION_SCHEMA PROCESSLIST 表的 ID 列、SHOW PROCESSLIST 输出的 Id 列和性能模式线程表的 PROCESSLIST_ID 列确定。
KILL processlist_id;
10.4 ADMIN CHECK TABLET
# 该语句用于对一组 tablet 执行副本数据一致性检查。
ADMIN CHECK TABLET (tablet_id1, tablet_id2, ...)
PROPERTIES("type" = "consistency");
# 该命令为异步命令,发送后,Doris 会开始执行检查。最终的结果,将体现在 SHOW PROC "/cluster_health/tablet_health"; 结果中的 InconsistentTabletNum 列。
10.5 ADMIN CLEAN TRASH
# 该语句用于清理 backend 内的垃圾数据
ADMIN CLEAN TRASH [ON ("BackendHost1:BackendHeartBeatPort1", "BackendHost2:BackendHeartBeatPort2", ...)];
# 以 BackendHost:BackendHeartBeatPort 表示需要清理的 backend ,不添加on限定则清理所有 backend 。
10.6 RECOVER
该语句用于恢复之前删除的 database、table 或者 partition。支持通过name、id来恢复指定的元信息,并且支持将恢复的元信息重命名。可以通过SHOW CATALOG RECYCLE BIN来查询当前可恢复的元信息。
# 以name恢复 database
RECOVER DATABASE db_name;
# 以name恢复 table
RECOVER TABLE [db_name.]table_name;
# 以name恢复 partition
RECOVER PARTITION partition_name FROM [db_name.]table_name;
# 以name恢复 database 并设定新名字
RECOVER DATABASE db_name AS new_db_name;
# 以name恢复 table 并设定新名字
RECOVER TABLE [db_name.]table_name AS new_tb_name;
# 以name恢复 partition 并设定新名字
RECOVER PARTITION partition_name AS new_partition_name FROM [db_name.]table_name;
10.7 ADMIN SET REPLICA STATUS
该语句用于设置指定副本的状态。该命令目前仅用于手动将某些副本状态设置为 BAD 或 OK,从而使得系统能够自动修复这些副本。注意,设置为Bad状态的副本可能立刻被删除,请谨慎操作。
ADMIN SET REPLICA STATUS PROPERTIES ("tablet_id" = "value","backend_id"="","status"="bad or ok");
# 如果指定的副本不存在,或状态已经是 bad,则会被忽略。
# 设置 tablet 10003 在 BE 10001 上的副本状态为 bad。
ADMIN SET REPLICA STATUS PROPERTIES("tablet_id" = "10003", "backend_id" = "10001", "status" = "bad");
# 设置 tablet 10003 在 BE 10001 上的副本状态为 ok。
ADMIN SET REPLICA STATUS PROPERTIES("tablet_id" = "10003", "backend_id" = "10001", "status" = "ok");
10.8 ADMIN SHOW REPLICA DISTRIBUTION
# 该语句用于展示一个表或分区副本分布状态
ADMIN SHOW REPLICA DISTRIBUTION FROM [db_name.]tbl_name [PARTITION (p1, ...)];
ADMIN SHOW REPLICA DISTRIBUTION FROM tbl1;
ADMIN SHOW REPLICA DISTRIBUTION FROM db1.tbl1 PARTITION(p1, p2);
10.9 ADMIN REPAIR TABLE
该语句用于尝试优先修复指定的表或分区。该语句仅表示让系统尝试以高优先级修复指定表或分区的分片副本,并不保证能够修复成功。用户可以通过下一个命令ADMIN SHOW REPLICA STATUS查看修复情况。默认的 timeout 是 14400 秒(4小时)。超时意味着系统将不再以高优先级修复指定表或分区的分片副本。需要重新使用该命令设置
ADMIN REPAIR TABLE table_name[ PARTITION (p1,...)];
ADMIN REPAIR TABLE tbl1;
ADMIN REPAIR TABLE tbl1 PARTITION (p1, p2);
10.10 ADMIN SHOW REPLICA STATUS
该语句用于展示一个表或分区的副本状态信息。
ADMIN SHOW REPLICA STATUS FROM [db_name.]tbl_name [PARTITION (p1, ...)][where_clause];
# STATUS
# replica_status: OK
# DEAD : replica 所在 Backend 不可用
# VERSION_ERROR : replica 数据版本有缺失
# SCHEMA_ERROR : replica 的 schema hash 不正确
# MISSING : replica 不存在
ADMIN SHOW REPLICA STATUS FROM db1.tbl1;
ADMIN SHOW REPLICA STATUS FROM tbl1 PARTITION (p1, p2) WHERE STATUS = "VERSION_ERROR";
ADMIN SHOW REPLICA STATUS FROM tbl1 WHERE STATUS != "OK";
10.11 ADMIN CANCEL REPAIR
该语句用于取消以高优先级修复指定表或分区。该语句仅表示系统不再以高优先级修复指定表或分区的分片副本。系统仍会以默认调度方式修复副本。
ADMIN CANCEL REPAIR TABLE table_name[ PARTITION (p1,...)];
ADMIN CANCEL REPAIR TABLE tbl PARTITION(p1);
10.12 SET VARIABLE
该语句主要是用来修改Doris系统变量,这些系统变量可以分为全局以及会话级别层面来修改,有些也可以进行动态修改。你也可以通过SHOW VARIABLE 来查看这些系统变量。只有 ADMIN 用户可以设置变量的全局生效。全局生效的变量不影响当前会话的变量值,仅影响新的会话中的变量。
SET [GLOBAL|SESSION] system_var_name = expr;
- time_zone:用于设置当前会话的时区。时区会对某些时间函数的结果产生影响。
- wait_timeout:用于设置空闲连接的连接时长。当一个空闲连接在该时长内与Doris没有任何交互,则Doris会主动断开这个链接。默认为8小时,单位为秒。
- enable_profile:用于设置是否需要查看查询的profile。默认为false,即不需要profile。默认情况下,只有在查询发生错误时,BE才会发送 profile给FE,用于查看错误。正常结束的查询不会发送profile。发送profile会产生一定的网络开销,对高并发查询场景不利。当用户希望对一个查询的profile进行分析时,可以将这个变量设为true后,发送查询。查询结束后,可以通过在当前连接的FE的web页面查看fe_host:fe_http_port/query
- query_timeout:用于设置查询超时。该变量会作用于当前连接中所有的查询语句。默认为5分钟,单位为秒。
- insert_timeout:用于设置针对INSERT语句的超时。该变量仅作用于INSERT语句,建议在INSERT行为易持续较长时间的场景下设置。默认为4小时,单位为秒。
- exec_mem_limit:用于设置单个查询的内存限制。单位为B/K/KB/M/MB/G/GB/T/TB/P/PB, 默认为B。当出现Memory Exceed Limit错误时,可以尝试指数级增加该参数,如4G、8G、16G等。
- batch_size:用于指定在查询执行过程中,各个节点传输的单个数据包的行数。默认一个数据包的行数为 1024 行,即源端节点每产生 1024 行数据后,打包发给目的节点。较大的行数,会在扫描大数据量场景下提升查询的吞吐,但可能会在小查询场景下增加查询延迟。同时,也会增加查询的内存开销。建议设置范围 1024 至 4096。
- allow_partition_column_nullable:建表时是否允许分区列为NULL。默认为true,表示允许为NULL。false 表示分区列必须被定义为NOT NULL
- insert_visible_timeout_ms:在执行INSERT语句时,导入动作(查询和插入)完成后,还需要等待事务提交,使数据可见。此参数控制等待数据可见的超时时间,默认为10000,最小可设置为1000。
- enable_fold_constant_by_be:用于控制常量折叠的计算方式。默认是false,即在FE进行计算;若设置为true,则通过RPC请求经BE计算。
- default_rowset_type:用于设置计算节点存储引擎默认的存储格式。默认的格式为beta。数据存储格式为V2。
- default_password_lifetime:默认的密码过期时间。默认值为0,即表示不过期。单位为天。该参数只有当用户的密码过期属性为DEFAULT值时,才启用。
- password_history:默认的历史密码次数。默认值为0,即不做限制。该参数只有当用户的历史密码次数属性为DEFAULT值时,才启用。
- validate_password_policy:密码强度校验策略。默认为不做校验。可以设置为STRONG或2。当设置为STRONG或2时,通过 ALTER USER 或 SET PASSWORD 命令设置密码时,密码必须包含“大写字母”,“小写字母”,“数字”和“特殊字符”中的3项,并且长度必须大于等于8。特殊字符包括:~!@#$%^&*()_+|<>,.?/:;'[]{}"。
- show_hidden_columns:是否显示隐藏字段,默认为false。
- lower_case_table_names:用于控制用户表表名大小写是否敏感。值为0时,表名大小写敏感。默认为0。值为1时,表名大小写不敏感,doris在存储和查询时会将表名转换为小写。查询时表名可以写成任何大小写形式。值为2时,表名大小写不敏感,doris存储建表语句中指定的表名,查询时转换为小写进行比较。同一sql语句中表名只能使用一种形式。只能在集群初始化之前在fe配置文件修改,初始化完成后不能通过任何方式进行修改。
- rewrite_count_distinct_to_bitmap_hll:是否将bitmap和hll类型的count distinct查询重写为bitmap_union_count和hll_union_agg 。默认值为true。
- enable_exchange_node_parallel_merge:在一个排序的查询之中,一个上层节点接收下层节点有序数据时,会在exchange node上进行对应的排序来保证最终的数据是有序的。但是单线程进行多路数据归并时,如果数据量过大,会导致exchange node的单点的归并瓶颈。Doris在这部分进行了优化处理,如果下层的数据节点过多。exchange node会启动多线程进行并行归并来加速排序过程。该参数默认为False,即表示 exchange node 不采取并行的归并排序,来减少额外的CPU和内存消耗。
- parallel_exchange_instance_num:用于设置执行计划中,一个上层节点接收下层节点数据所使用的 exchange node 数量。默认为 -1,即表示 exchange node 数量等于下层节点执行实例的个数(默认行为)。当设置大于0,并且小于下层节点执行实例的个数,则 exchange node 数量等于设置值。在一个分布式的查询执行计划中,上层节点通常有一个或多个 exchange node 用于接收来自下层节点在不同 BE 上的执行实例的数据。通常 exchange node 数量等于下层节点执行实例数量。在一些聚合查询场景下,如果底层需要扫描的数据量较大,但聚合之后的数据量很小,则可以尝试修改此变量为一个较小的值,可以降低此类查询的资源开销。如在 DUPLICATE KEY 明细模型上进行聚合查询的场景。
10.13 ADMIN SET CONFIG
该语句用于设置集群的配置项(当前仅支持设置FE的配置项)。 可设置的配置项,可以通过ADMIN SHOW FRONTEND CONFIG; 命令查看。
ADMIN SET FRONTEND CONFIG ("key" = "value");
10.14 ADMIN SHOW TABLET STORAGE FORMAT
该语句用于显示Backend上的存储格式信息(仅管理员使用)。
ADMIN SHOW TABLET STORAGE FORMAT [VERBOSE];
admin show tablet storage format;
+-----------+---------+---------+
| BackendId | V1Count | V2Count |
+-----------+---------+---------+
| 10002 | 0 | 2867 |
+-----------+---------+---------+
admin show tablet storage format verbose;
+-----------+----------+---------------+
| BackendId | TabletId | StorageFormat |
+-----------+----------+---------------+
| 10002 | 39227 | V2 |
| 10002 | 39221 | V2 |
| 10002 | 39215 | V2 |
| 10002 | 39199 | V2 |
+-----------+----------+---------------+
10.15 ADMIN COPY TABLET
该语句用于为指定的 tablet 制作快照,主要用于本地加载 tablet 来复现问题。该命令需要使用ROOT用户
# ADMIN COPY TABLET tablet_id PROPERTIES("xxx");
# PROPERTIES 支持如下属性:
# backend_id:指定副本所在的 BE 节点的 id。如果不指定,则随机选择一个副本。
# version:指定快照的版本。该版本需小于等于副本的最大版本。如不指定,则使用最大版本。
# expiration_minutes:快照保留时长。默认为1小时。超时后会自动清理。单位分钟。
# 对指定 BE 节点上的指定副本做快照
ADMIN COPY TABLET 10010 PROPERTIES("backend_id" = "10001");
# 对指定 BE 节点上的指定副本,做指定版本的快照
ADMIN COPY TABLET 10010 PROPERTIES("backend_id" = "10001", "version" = "10");
1. TabletId: # tablet id
2. BackendId: # BE 节点 id
3. Ip: # BE 节点 ip
4. Path: # 快照所在目录
5. ExpirationMinutes: # 快照过期时间
6. CreateTableStmt: # tablet 对应的表的建表语句。该语句不是原始的建表语句,而是用于之后本地加载 tablet 的简化后的建表语句。
10.16 ADMIN-REBALANCE-DISK
该语句用于尝试优先均衡指定的BE磁盘数据。该语句表示让系统尝试优先均衡指定BE的磁盘数据,不受限于集群是否均衡。 默认的 timeout 是 24小时。超时意味着系统将不再优先均衡指定的BE磁盘数据。需要重新使用该命令设置。 指定BE的磁盘数据均衡后,该BE的优先级将会失效。
ADMIN REBALANCE DISK [ON ("BackendHost1:BackendHeartBeatPort1", "BackendHost2:BackendHeartBeatPort2", ...)];
# 尝试优先均衡集群内的所有BE
ADMIN REBALANCE DISK;
# 尝试优先均衡指定BE
ADMIN REBALANCE DISK ON ("192.168.1.1:1234", "192.168.1.2:1234");
10.17 ADMIN CANCEL REBALANCE DISK
该语句用于取消优先均衡BE的磁盘。该语句仅表示系统不再优先均衡指定BE的磁盘数据。系统仍会以默认调度方式均衡BE的磁盘数据。
ADMIN CANCEL REBALANCE DISK [ON ("BackendHost1:BackendHeartBeatPort1", "BackendHost2:BackendHeartBeatPort2", ...)];
# 取消集群所有BE的优先磁盘均衡
ADMIN CANCEL REBALANCE DISK;
# 取消指定BE的优先磁盘均衡
ADMIN CANCEL REBALANCE DISK ON ("192.168.1.1:1234", "192.168.1.2:1234");
11 分区缓存
11.1 需求场景
大部分数据分析场景是写少读多,数据写入一次,多次频繁读取,比如一张报表涉及的维度和指标,数据在凌晨一次性计算好,但每天有数百甚至数千次的页面访问,因此非常适合把结果集缓存起来。在数据分析或BI应用中,存在下面的业务场景:
- 高并发场景,Doris可以较好的支持高并发,但单台服务器无法承载太高的QPS。
- 复杂图表的看板,复杂的Dashboard或者大屏类应用,数据来自多张表,每个页面有数十个查询,虽然每个查询只有数十毫秒,但是总体查询时间会在数秒。
- 趋势分析,给定日期范围的查询,指标按日显示,比如查询最近7天内的用户数的趋势,这类查询数据量大,查询范围广,查询时间往往需要数十秒。
- 用户重复查询,如果产品没有防重刷机制,用户因手误或其他原因重复刷新页面,导致提交大量的重复的SQL。
11.2 解决方案
本分区缓存策略可以解决上面的问题,优先保证数据一致性,在此基础上细化缓存粒度,提升命中率,因此有如下特点:
- 用户无需担心数据一致性,通过版本来控制缓存失效,缓存的数据和从BE中查询的数据是一致的。
- 没有额外的组件和成本,缓存结果存储在BE的内存中,用户可以根据需要调整缓存内存大小。
- 实现了两种缓存策略,SQLCache和PartitionCache,后者缓存粒度更细。
- 用一致性哈希解决BE节点上下线的问题,BE中的缓存算法是改进的LRU。
11.3 SQLCache
SQLCache按SQL的签名、查询的表的分区ID、分区最新版本来存储和获取缓存。三者组合确定一个缓存数据集,任何一个变化了,如SQL有变化,如查询字段或条件不一样,或数据更新后版本变化了,会导致命中不了缓存。如果多张表Join,使用最近更新的分区ID和最新的版本号,如果其中一张表更新了,会导致分区ID或版本号不一样,也一样命中不了缓存。SQLCache,更适合T+1更新的场景,凌晨数据更新,首次查询从BE中获取结果放入到缓存中,后续相同查询从缓存中获取。实时更新数据也可以使用,但是可能存在命中率低的问题,可以参考如下PartitionCache。
# 开启SQLCache
# 确保fe.conf的cache_enable_sql_mode=true(默认是true)
# 在MySQL命令行中设置变量
set [global] enable_sql_cache=true;
11.4 PartitionCache
11.4.1 设计原理
- SQL可以并行拆分,Q = Q1 ∪ Q2 … ∪ Qn,R= R1 ∪ R2 … ∪ Rn,Q为查询语句,R为结果集。
- 拆分为只读分区和可更新分区,只读分区缓存,更新分区不缓存。
11.4.2 示例
如下,在2020-03-09当天查询前7天的用户数,2020-03-03至2020-03-07的数据来自缓存,2020-03-08第一次查询来自分区,后续的查询来自缓存,2020-03-09因为当天在不停写入,所以来自分区。因此,查询N天的数据,数据更新最近的D天,每天只是日期范围不一样相似的查询,只需要查询D个分区即可,其他部分都来自缓存,可以有效降低集群负载,减少查询时间。
SELECT eventdate,count(userid) FROM testdb.appevent WHERE eventdate>="2020-03-03" AND eventdate<="2020-03-09" GROUP BY eventdate ORDER BY eventdate;
+------------+-----------------+
| eventdate | count(`userid`) |
+------------+-----------------+
| 2020-03-03 | 15 |
| 2020-03-04 | 20 |
| 2020-03-05 | 25 |
| 2020-03-06 | 30 |
| 2020-03-07 | 35 |
| 2020-03-08 | 40 | //第一次来自分区,后续来自缓存
| 2020-03-09 | 25 | //来自分区
+------------+-----------------+
- Partition缓存,适合按日期分区,部分分区实时更新,查询SQL较为固定。
- 分区字段也可以是其他字段,但是需要保证只有少量分区更新。
11.4.3 限制
- 只支持OlapTable,其他存储如MySQL的表没有版本信息,无法感知数据是否更新。
- 只支持按分区字段分组,不支持按其他字段分组,按其他字段分组,该分组数据都有可能被更新,会导致缓存都失效。
11.4.4 开启PartitionCache
# 确保fe.conf的cache_enable_partition_mode=true(默认是true)
# 在MySQL命令行中设置变量
set [global] enable_partition_cache=true;
11.5 SQLCache和PartitionCache
如果同时开启了两个缓存策略,下面的参数,需要注意一下:
cache_last_version_interval_second=900
分区最新版本的时间到当前时间的间隔如果大于这个参数,说明更新的很慢,这时候则会优先把整个查询结果缓存。如果小于这个间隔,如果符合PartitionCache的条件,则按PartitionCache查询数据。
12 函数
12.1 聚合函数
12.1.1 COLLECT_SET
collect_set(expr[,max_size])
返回一个对expr去重后的数组。得到的结果数组中不包含NULL元素,数组中的元素顺序不固定。可选参数max_size,通过设置该参数能够将结果数组的大小限制为 max_size个元素。类似于GROUP_CONCAT(DISTINCT expr)。
+------+------------+-------+
| k1 | k2 | k3 |
+------+------------+-------+
| 1 | 2023-01-01 | hello |
| 2 | 2023-01-01 | NULL |
| 2 | 2023-01-02 | hello |
| 3 | NULL | world |
| 3 | 2023-01-02 | hello |
| 4 | 2023-01-02 | doris |
| 4 | 2023-01-03 | sql |
+------+------------+-------+
select k1,collect_set(k2),collect_set(k3,1) from table_name group by k1 order by k1;
+------+-------------------------+--------------------------+
| k1 | collect_set(`k2`) | collect_set(`k3`,1) |
+------+-------------------------+--------------------------+
| 1 | [2023-01-01] | [hello] |
| 2 | [2023-01-01,2023-01-02] | [hello] |
| 3 | [2023-01-02] | [world] |
| 4 | [2023-01-02,2023-01-03] | [sql] |
+------+-------------------------+--------------------------+
12.1.2 COLLECT_LIST
collect_list(expr[,max_size])
返回一个包含expr中所有元素(不包括NULL)的数组,可选参数max_size,通过设置该参数能够将结果数组的大小限制为max_size个元素。 得到的结果数组中不包含NULL元素,数组中的元素顺序不固定。
+------+------------+-------+
| k1 | k2 | k3 |
+------+------------+-------+
| 1 | 2023-01-01 | hello |
| 2 | 2023-01-02 | NULL |
| 2 | 2023-01-02 | hello |
| 3 | NULL | world |
| 3 | 2023-01-02 | hello |
| 4 | 2023-01-02 | sql |
| 4 | 2023-01-03 | sql |
+------+------------+-------+
select collect_list(k1),collect_list(k1,3) from table_name;
+-------------------------+--------------------------+
| collect_list(`k1`) | collect_list(`k1`,3) |
+-------------------------+--------------------------+
| [1,2,2,3,3,4,4] | [1,2,2] |
+-------------------------+--------------------------+
12.1.3 GROUP_CONCAT
GROUP_CONCAT([DISTINCT] expr, [sep])
GROUP_CONCAT将结果集中的多行结果连接成一个字符串。第二个参数sep为字符串之间的连接符号,该参数可以省略。
+------+------------+-------+
| k1 | k2 | k3 |
+------+------------+-------+
| 1 | 2023-01-01 | hello |
| 2 | 2023-01-01 | NULL |
| 2 | 2023-01-02 | hello |
| 3 | NULL | world |
| 3 | 2023-01-02 | hello |
| 4 | 2023-01-02 | doris |
| 4 | 2023-01-03 | sql |
+------+------------+-------+
select k1,GROUP_CONCAT(DISTINCT K2) FROM table_name GROUP BY K1;
+------+--------------------------------+
| k1 | GROUP_CONCAT(DISTINCT K2) |
+------+--------------------------------+
| 1 | 2023-01-01 |
| 2 | 2023-01-01,2023-01-02 |
| 3 | 2023-01-02,NULL |
| 4 | 2023-01-02,2023-01-03 |
+------+--------------------------------+
12.1.4 PERCENTILE
PERCENTILE(expr, DOUBLE p)
计算精确的百分位数,因为数据要进行排序,所以只适用于小数据量。先对指定列降序排列,然后取精确的第p位百分数。p的值介于0到1之间。很多时候平均值并不能反映一组数据的分布情况,这时候我们就可以使用百分位数,如上面的函数如果p为0.5,则计算的就是这组数据的中位数,而0.99或0.999这种指标在统计中会经常进行计算。参数说明expr:必填。值为整数(最大为bigint)类型的列。 p:常量必填。需要精确的百分位数。取值为[0.0,1.0]。
select `table`, percentile(cost_time,0.99) from log_statis group by `table`;
+---------------------+---------------------------+
| table | percentile(`cost_time`, 0.99) |
+----------+--------------------------------------+
| test | 54.22 |
+----------+--------------------------------------+
12.1.5 PERCENTILE_ARRAY
PERCENTILE_ARRAY(BIGINT, ARRAY_DOUBLE p)
和PERCENTILE(expr,p)函数类似,这个函数可以一次计算多个百分位数。
select percentile_array(k1,[0.3,0.5,0.9]) from baseall;
+----------------------------------------------+
| percentile_array(`k1`, ARRAY(0.3, 0.5, 0.9)) |
+----------------------------------------------+
| [5.2, 8, 13.6] |
+----------------------------------------------+
12.1.6 PERCENTILE_APPROX
PERCENTILE_APPROX(expr, DOUBLE p[DOUBLE compression])
返回第p个百分位点的近似值,p的值介于0到1之间。compression参数是可选项,可设置范围是[2048, 10000],值越大,精度越高,内存消耗越大,计算耗时越长。 compression参数未指定或设置的值在[2048, 10000]范围外,以10000的默认值运行。该函数使用固定大小的内存,因此对于高基数的列可以使用更少的内存,可用于计算tp99等统计值。
select `table`,percentile_approx(cost_time,0.99) from log_statis group by `table`;
+---------------------+---------------------------+
| table | percentile_approx(`cost_time`, 0.99) |
+----------+--------------------------------------+
| test | 54.22 |
+----------+--------------------------------------+
12.1.7 MAX_BY
MAX_BY(expr1, expr2)
返回与expr2的最大值关联的expr1的值。
+------+------+------+------+
| k1 | k2 | k3 | k4 |
+------+------+------+------+
| 0 | 3 | 2 | 100 |
| 1 | 2 | 3 | 4 |
| 4 | 3 | 2 | 1 |
| 3 | 4 | 2 | 1 |
+------+------+------+------+
select max_by(k1, k4) from tbl;
+--------------------+
| max_by(`k1`, `k4`) |
+--------------------+
| 0 |
+--------------------+
12.1.8 MIN_BY
MIN_BY(expr1, expr2)
返回与expr2的最小值关联的expr1的值。
+------+------+------+------+
| k1 | k2 | k3 | k4 |
+------+------+------+------+
| 0 | 3 | 2 | 100 |
| 1 | 2 | 3 | 4 |
| 4 | 3 | 2 | 1 |
| 3 | 4 | 2 | 1 |
+------+------+------+------+
select min_by(k1, k4) from tbl;
+--------------------+
| min_by(`k1`, `k4`) |
+--------------------+
| 4 |
+--------------------+
12.1.9 APPROX_COUNT_DISTINCT
APPROX_COUNT_DISTINCT(expr)
返回类似于COUNT(DISTINCT col)结果的近似值聚合函数。它比COUNT和 DISTINCT组合的速度更快,并使用固定大小的内存,因此对于高基数的列可以使用更少的内存。
select approx_count_distinct(query_id) from log_statis group by datetime;
+-----------------+
| approx_count_distinct(`query_id`) |
+-----------------+
| 17721 |
+-----------------+
12.1.10 ANY_VALUE
ANY_VALUE(expr)
判断expr是否存在非NULL值,如果存在非NULL值,返回任意非NULL值,否则返回 NULL。
select id, any_value(name) from cost2 group by id;
+------+-------------------+
| id | any_value(`name`) |
+------+-------------------+
| 3 | jack |
| 2 | jack |
+------+-------------------+
12.1.11 RETENTION
retention(event1, event2, ... , event32)
留存函数,将一组条件作为参数,用来表示事件是否满足特定条件,任何条件都可以指定为参数。简单来讲,返回值数组第1位表示event1的真假,第二位表示event1真假与event2真假相与,第三位表示event1真假与event3真假相与,等等。如果event1为假,则返回全是0的数组。
+------+---------------------+
| uid | date |
+------+---------------------+
| 0 | 2022-10-14 00:00:00 |
| 0 | 2022-10-13 00:00:00 |
| 0 | 2022-10-12 00:00:00 |
| 1 | 2022-10-13 00:00:00 |
| 1 | 2022-10-12 00:00:00 |
| 2 | 2022-10-12 00:00:00 |
+------+---------------------+
# =================================================
SELECT uid,retention(date = '2022-10-12') AS r FROM retention_test GROUP BY uid ORDER BY uid ASC;
+------+------+
| uid | r |
+------+------+
| 0 | [1] |
| 1 | [1] |
| 2 | [1] |
+------+------+
# =================================================
SELECT uid,retention(date = '2022-10-12', date = '2022-10-13') AS r FROM retention_test GROUP BY uid ORDER BY uid ASC;
+------+--------+
| uid | r |
+------+--------+
| 0 | [1, 1] |
| 1 | [1, 1] |
| 2 | [1, 0] |
+------+--------+
# ================================================
SELECT uid,retention(date = '2022-10-12', date = '2022-10-13', date = '2022-10-14') AS r FROM retention_test GROUP BY uid ORDER BY uid ASC;
+------+-----------+
| uid | r |
+------+-----------+
| 0 | [1, 1, 1] |
| 1 | [1, 1, 0] |
| 2 | [1, 0, 0] |
+------+-----------+
12.1.12 BITMAP_UNION
BITMAP_UNION(BITMAP value)
聚合函数,用于计算分组后的bitmap并集。常见使用场景如:计算PV,UV。输入一组bitmap值,求这一组bitmap值的并集,并返回。
+-----------+-----------------------------+
| page_id | bitmap_to_string(user_id) |
+-----------+-----------------------------+
| 0 | 3 |
| 0 | 1 |
| 1 | 2 |
| 1 | 2 |
| 4 | 3 |
| 4 | 4 |
| 3 | 4 |
+-----------+-----------------------------+
select page_id, bitmap_count(bitmap_union(user_id)) cnt from table group by page_id;
select page_id, count(distinct user_id) cnt from table group by page_id;
# 和BITMAP_COUNT函数组合使用可以求得网页的UV数据。上面两个sql的查询结果等价。
+-----------+-----------+
| page_id | cnt |
+-----------+-----------+
| 0 | 2 |
| 1 | 1 |
| 3 | 1 |
| 4 | 2 |
+-----------+-----------+
12.1.13 BITMAP_UNION_COUNT
BITMAP_UNION_COUNT(expr)
聚合函数,用于计算分组后的bitmap并集并返回其数量。常见使用场景如:计算PV,UV。和BITMAP_COUNT(BITMAP_UNION(expr))等价。
+-----------+-----------------------------+
| page_id | bitmap_to_string(user_id) |
+-----------+-----------------------------+
| 0 | 3 |
| 0 | 1 |
| 1 | 2 |
| 1 | 2 |
| 4 | 3 |
| 4 | 4 |
| 3 | 4 |
+-----------+-----------------------------+
select page_id, bitmap_union_count(user_id) cnt from table group by page_id;
# 对于 TINYINT,SMALLINT 和 INT 类型的列还可以使用bitmap_union_int
+-----------+-----------+
| page_id | cnt |
+-----------+-----------+
| 0 | 2 |
| 1 | 1 |
| 3 | 1 |
| 4 | 2 |
+-----------+-----------+
12.1.14 GROUP_BITMAP_XOR
GROUP_BITMAP_XOR(expr)
用于计算分组后的bitmap差集。
+------+-----------------------------+
| page | bitmap_to_string(`user_id`) |
+------+-----------------------------+
| m | 4,7,8 |
| m | 1,3,6,15 |
| m | 4,7 |
+------+-----------------------------+
select page, bitmap_to_string(group_bitmap_xor(user_id)) from pv_bitmap group by page;
+------+-----------------------------------------------+
| page | bitmap_to_string(group_bitmap_xor(`user_id`)) |
+------+-----------------------------------------------+
| m | 1,3,6,8,15 |
+------+-----------------------------------------------+
12.1.15 BITMAP_INTERSECT
BITMAP_INTERSECT(BITMAP value)
聚合函数,用于计算分组后的bitmap交集。常见使用场景如:计算用户留存率。
# 求今天和昨天不同 tag 下留存的用户都是哪些
select tag, bitmap_to_string(bitmap_intersect(user_id)) from (select tag, date, bitmap_union(user_id) user_id from table where date in ('2020-05-18', '2020-05-19') group by tag, date) a group by tag;
12.1.16 HLL_UNION_AGG
HLL_UNION_AGG(hll)
HLL是基于HyperLogLog算法的工程实现,用于保存HyperLogLog计算过程的中间结果。它只能作为表的value列类型、通过聚合来不断的减少数据量,以此来实现加快查询的目的。基于它得到的是一个估算结果,误差大概在1%左右,hll列是通过其它列或者导入数据里面的数据生成的。导入的时候通过hll_hash函数来指定数据中哪一列用于生成hll列,它常用于替代count distinct,通过结合rollup在业务上用于快速计算uv等。
select HLL_UNION_AGG(uv_set) from test_uv;
+-------------------------+
| HLL_UNION_AGG(`uv_set`) |
+-------------------------+
| 17721 |
+-------------------------+
12.1.17 TOPN
topn(expr, INT top_num[, INT space_expand_rate])
该topn函数使用Space-Saving算法计算expr中的top_num个频繁项,结果为频繁项及其出现次数,该结果为近似值。space_expand_rate参数是可选项,默认值为50,值越大,结果越准确。
select topn(keyword,10) from keyword_table where date>= '2020-06-01' and date <= '2020-06-19' ;
+----------------------------------------------------------------------+
| topn(`keyword`, 10) |
+----------------------------------------------------------------------+
| a:157, b:138, c:133, d:133, e:131, f:127, g:124, h:122, i:117, k:117 |
+----------------------------------------------------------------------+
# =============================================================
select date,topn(keyword,10,100) from keyword_table where date>= '2020-06-17' and date <= '2020-06-19' group by date;
+------------+----------------------------------------------------+
| date | topn(`keyword`, 10, 100) |
+------------+----------------------------------------------------+
| 2020-06-19 | a:11, b:8, c:8, d:7, e:7, f:7, g:7, h:7, i:7, j:7 |
| 2020-06-18 | a:10, b:8, c:7, f:7, g:7, i:7, k:7, l:7, m:6, d:6 |
| 2020-06-17 | a:9, b:8, c:8, j:8, d:7, e:7, f:7, h:7, i:7, k:7 |
+------------+----------------------------------------------------+
12.1.18 TOPN_ARRAY
ARRAY<T> topn_array(expr, INT top_num[, INT space_expand_rate])
该topn_array函数使用Space-Saving算法计算expr中的top_num个频繁项,返回由前top_num个组成的数组,该结果为近似值。space_expand_rate参数是可选项,默认值为50,值越大,结果越准确。
select topn_array(k3,3) from baseall;
+--------------------------+
| topn_array(`k3`, 3) |
+--------------------------+
| [3021, 2147483647, 5014] |
+--------------------------+
# =============================================================
select topn_array(k3,3,100) from baseall;
+--------------------------+
| topn_array(`k3`, 3, 100) |
+--------------------------+
| [3021, 2147483647, 5014] |
+--------------------------+
12.2 Bitmap函数
12.2.1 TO_BITMAP
TO_BITMAP(expr)
输入为取值在0 ~ 18446744073709551615区间的无符号整型,输出为包含该元素的bitmap。当输入值不在此范围时,会返回NULL。
select bitmap_count(to_bitmap(10));
+-----------------------------+
| bitmap_count(to_bitmap(10)) |
+-----------------------------+
| 1 |
+-----------------------------+
# =============================================================
select bitmap_to_string(to_bitmap(-1));
+---------------------------------+
| bitmap_to_string(to_bitmap(-1)) |
+---------------------------------+
| |
+---------------------------------+
12.2.2 BITMAP_FROM_STRING
BITMAP BITMAP_FROM_STRING(VARCHAR input)
将一个字符串转化为一个BITMAP,字符串是由逗号分隔的一组unsigned bigint数字组成.(数字取值在:0 ~ 18446744073709551615) 比如"0, 1, 2"字符串会转化为一个Bitmap,其中的第0, 1, 2位被设置. 当输入字段不合法时,返回NULL。
select bitmap_from_string("-1, 0, 1, 2") result;
+--------+
| result |
+--------+
| NULL |
+--------+
# ===================================================================
select bitmap_to_string(bitmap_from_string("0, 1, 18446744073709551615")) result;
+-------------------------+
| result |
+-------------------------+
| 0,1,18446744073709551615|
+-------------------------+
12.2.3 BITMAP_TO_STRING
VARCHAR BITMAP_TO_STRING(BITMAP input)
将一个bitmap转化成一个逗号分隔的字符串,字符串中包含所有设置的BIT位。输入是null的话会返回null。
select bitmap_to_string(null);
+------------------------+
| bitmap_to_string(NULL) |
+------------------------+
| NULL |
+------------------------+
# ===================================================================
select bitmap_to_string(bitmap_empty());
+----------------------------------+
| bitmap_to_string(bitmap_empty()) |
+----------------------------------+
| |
+----------------------------------+
# ===================================================================
select bitmap_to_string(to_bitmap(1));
+--------------------------------+
| bitmap_to_string(to_bitmap(1)) |
+--------------------------------+
| 1 |
+--------------------------------+
# ===================================================================
select bitmap_to_string(bitmap_or(to_bitmap(1), to_bitmap(2)));
+---------------------------------------------------------+
| bitmap_to_string(bitmap_or(to_bitmap(1), to_bitmap(2))) |
+---------------------------------------------------------+
| 1,2 |
+---------------------------------------------------------+
12.2.4 BITMAP_TO_ARRAY
ARRAY_BIGINT bitmap_to_array(BITMAP input)
将一个bitmap转化成一个array 数组。 输入是null的话会返回null。
select bitmap_to_array(null);
+------------------------+
| bitmap_to_array(NULL) |
+------------------------+
| NULL |
+------------------------+
# ===================================================================
select bitmap_to_array(bitmap_empty());
+---------------------------------+
| bitmap_to_array(bitmap_empty()) |
+---------------------------------+
| [] |
+---------------------------------+
# ===================================================================
select bitmap_to_array(to_bitmap(1));
+-------------------------------+
| bitmap_to_array(to_bitmap(1)) |
+-------------------------------+
| [1] |
+-------------------------------+
# ===================================================================
select bitmap_to_array(bitmap_from_string('1,2,3,4,5'));
+--------------------------------------------------+
| bitmap_to_array(bitmap_from_string('1,2,3,4,5')) |
+--------------------------------------------------+
| [1, 2, 3, 4, 5] |
+--------------------------------------------------
12.2.5 BITMAP_FROM_ARRAY
BITMAP BITMAP_FROM_ARRAY(ARRAY input)
将一个TINYINT/SMALLINT/INT/BIGINT类型的数组转化为一个BITMAP 当输入字段不合法时,结果返回NULL。
select *, bitmap_to_string(bitmap_from_array(c_array)) from array_test;
+------+-----------------------+------------------------------------------------+
| id | c_array | bitmap_to_string(bitmap_from_array(`c_array`)) |
+------+-----------------------+------------------------------------------------+
| 1 | [NULL] | NULL |
| 2 | [1, 2, 3, NULL] | NULL |
| 2 | [1, 2, 3, -10] | NULL |
| 3 | [1, 2, 3, 4, 5, 6, 7] | 1,2,3,4,5,6,7 |
| 4 | [100, 200, 300, 300] | 100,200,300 |
+------+-----------------------+------------------------------------------------+
12.2.6 BITMAP_AND
BITMAP_AND(BITMAP lhs, BITMAP rhs)
计算两个及以上输入bitmap的交集,两个Bitmap的数相同,则返回这个数的BitMap值。
select bitmap_count(bitmap_and(to_bitmap(1), to_bitmap(2))) cnt;
+------+
| cnt |
+------+
| 0 |
+------+
# =============================================================
select bitmap_to_string(bitmap_and(to_bitmap(1), to_bitmap(1))) result;
+--------+
| result |
+--------+
| 1 |
+--------+
# =============================================================
select bitmap_to_string(bitmap_and(bitmap_from_string('1,2,3'), bitmap_from_string('1,2'), bitmap_from_string('1,2,3,4,5'))) result;
+--------+
| result |
+--------+
| 1,2 |
+--------+
# =============================================================
select bitmap_to_string(bitmap_and(bitmap_from_string('1,2,3'), bitmap_from_string('1,2'), bitmap_from_string('1,2,3,4,5'),bitmap_empty())) result;
+--------+
| result |
+--------+
| |
+--------+
# =============================================================
select bitmap_to_string(bitmap_and(bitmap_from_string('1,2,3'), bitmap_from_string('1,2'), bitmap_from_string('1,2,3,4,5'),NULL)) result;
+--------+
| result |
+--------+
| NULL |
+--------+
12.2.7 BITMAP_AND_COUNT
BigIntVal bitmap_and_count(BITMAP lhs, BITMAP rhs, ...)
计算两个及以上输入bitmap的交集,返回交集的个数。等价于BITMAP_COUNT(BITMAP_AND())。
select bitmap_and_count(bitmap_from_string('1,2,3'),bitmap_empty()) result;
+-------+
| result|
+-------+
| 0 |
+-------+
# ===================================================================
select bitmap_and_count(bitmap_from_string('1,2,3'),bitmap_from_string('1,2,3')) result;
+-------+
| result|
+-------+
| 3 |
+-------+
# ===================================================================
select bitmap_and_count(bitmap_from_string('1,2,3'), bitmap_from_string('1,2'), bitmap_from_string('1,2,3,4,5')) result;
+-------+
| result|
+-------+
| 2 |
+-------+
# ===================================================================
select bitmap_and_count(bitmap_from_string('1,2,3'), bitmap_from_string('1,2'), bitmap_from_string('1,2,3,4,5'),bitmap_empty()) result;
+-------+
| result|
+-------+
| 0 |
+-------+
# ===================================================================
select bitmap_and_count(bitmap_from_string('1,2,3'), bitmap_from_string('1,2'), bitmap_from_string('1,2,3,4,5'), NULL) result;
+-------+
| result|
+-------+
| NULL |
+-------+
12.2.8 BITMAP_OR
BITMAP_OR(BITMAP lhs, BITMAP rhs, ...)
计算两个及以上输入bitmap的并集。
select bitmap_count(bitmap_or(to_bitmap(1), to_bitmap(2))) cnt;
+------+
| cnt |
+------+
| 2 |
+------+
# ===================================================================
select bitmap_count(bitmap_or(to_bitmap(1), to_bitmap(1))) cnt;
+------+
| cnt |
+------+
| 1 |
+------+
# ===================================================================
select bitmap_to_string(bitmap_or(to_bitmap(1), to_bitmap(2))) result;
+--------+
| result |
+--------+
| 1,2 |
+--------+
# ===================================================================
select bitmap_to_string(bitmap_or(to_bitmap(1), to_bitmap(2), to_bitmap(10), to_bitmap(0), NULL)) result;
+--------+
| result |
+--------+
| NULL |
+--------+
# ===================================================================
select bitmap_to_string(bitmap_or(to_bitmap(1), to_bitmap(2), to_bitmap(10), to_bitmap(0), bitmap_empty())) result;
+---------+
| result |
+---------+
| 0,1,2,10|
+---------+
12.2.9 BITMAP_OR_COUNT
BigIntVal bitmap_or_count(BITMAP lhs, BITMAP rhs, ...)
计算两个及以上输入bitmap的并集,返回并集的个数。和BITMAP_COUNT(BITMAP_OR())等价。
select bitmap_or_count(bitmap_from_string('1,2,3'),bitmap_empty()) result;
+--------+
| result |
+--------+
| 3 |
+--------+
# ===================================================================
select bitmap_or_count(bitmap_from_string('1,2,3'),bitmap_from_string('1,2,3')) result;
+--------+
| result |
+--------+
| 3 |
+--------+
# ===================================================================
select bitmap_or_count(bitmap_from_string('1,2,3'), bitmap_from_string('3,4,5'), to_bitmap(100), bitmap_empty()) result;
+--------+
| result |
+--------+
| 6 |
+--------+
# ===================================================================
select bitmap_or_count(bitmap_from_string('1,2,3'), bitmap_from_string('3,4,5'), to_bitmap(100), NULL) result;
+-------+
| result|
+-------+
| NULL |
+-------+
12.2.10 BITMAP_XOR
BITMAP_XOR(BITMAP lhs, BITMAP rhs, ...)
计算两个及以上输入Bitmap的差集,返回新的Bitmap。当输入Bitmap的个数大于2个的时候,前两个先进行计算,计算结果在和第三个进行计算,后面以此类推。
mysql> select bitmap_to_string(bitmap_xor(bitmap_from_string('2,3'),bitmap_from_string('1,2,3,4'))) result;
+--------+
| result |
+--------+
| 1,4 |
+--------+
# ===================================================================
select bitmap_to_string(bitmap_xor(bitmap_from_string('2,3'),bitmap_from_string('1,2,3,4'),bitmap_from_string('3,4,5'))) result;
+--------+
| result |
+--------+
| 1,3,5 |
+--------+
# ===================================================================
select bitmap_to_string(bitmap_xor(bitmap_from_string('2,3'),bitmap_from_string('1,2,3,4'),bitmap_from_string('3,4,5'),bitmap_empty())) result;
+--------+
| result |
+--------+
| 1,3,5 |
+--------+
# ===================================================================
select bitmap_to_string(bitmap_xor(bitmap_from_string('2,3'),bitmap_from_string('1,2,3,4'),bitmap_from_string('3,4,5'),NULL)) result;
+--------+
| result |
+--------+
| NULL |
+--------+
12.2.11 BITMAP_XOR_COUNT
BIGINT BITMAP_XOR_COUNT(BITMAP lhs, BITMAP rhs, ...)
计算两个及以上输入bitmap的差集并返回结果集的大小。和BITMAP_COUNT(BITMAP_XOR())等价。
select bitmap_xor_count(bitmap_from_string('1,2,3'),bitmap_from_string('3,4,5')) result;
+--------+
| result |
+--------+
| 4 |
+--------+
# ===================================================================
select bitmap_xor_count(bitmap_from_string('2,3'),bitmap_from_string('1,2,3,4'),bitmap_from_string('3,4,5')) result;
+--------+
| result |
+--------+
| 3 |
+--------+
# ===================================================================
select (bitmap_xor_count(bitmap_from_string('2,3'),bitmap_from_string('1,2,3,4'),bitmap_from_string('3,4,5'),bitmap_empty())) result;
+--------+
| result |
+--------+
| 3 |
+--------+
# ===================================================================
select (bitmap_xor_count(bitmap_from_string('2,3'),bitmap_from_string('1,2,3,4'),bitmap_from_string('3,4,5'),NULL)) result;
+-------+
| result|
+-------+
| NULL |
+-------+
12.2.12 BITMAP_EMPTY
BITMAP_EMPTY()
返回一个空bitmap。主要用于导入数据时填充默认值。
12.2.13 BITMAP_HASH
BITMAP_HASH(<any_value>)
对任意类型的输入,计算其32位的哈希值,并返回包含该哈希值的bitmap。该函数使用的哈希算法为 MurMur3。
select bitmap_to_string(bitmap_hash('hello'));
12.2.14 BITMAP_HASH64
BITMAP_HASH64(expr)
对任意类型的输入,计算其64位的哈希值,并返回包含该哈希值的bitmap。主要用于导入任务将非整型字段导入Doris表的bitmap字段。
SELECT bitmap_to_string(bitmap_hash64('hello'));
12.2.15 BITMAP_MIN
BITMAP_MIN(BITMAP input)
计算并返回 bitmap 中的最小值。
select bitmap_min(bitmap_from_string('')) value;
+-------+
| value |
+-------+
| NULL |
+-------+
# ===================================================================
select bitmap_min(bitmap_from_string('1,9999999999')) value;
+-------+
| value |
+-------+
| 1 |
+-------+
12.2.16 BITMAP_MAX
BITMAP_MAX(BITMAP input)
计算并返回 bitmap 中的最大值。
select bitmap_max(bitmap_from_string('')) value;
+-------+
| value |
+-------+
| NULL |
+-------+
# ===================================================================
select bitmap_max(bitmap_from_string('1,9999999999')) value;
+------------+
| value |
+------------+
| 9999999999 |
+------------+
12.2.17 BITMAP_HAS_ANY
BOOLEAN BITMAP_HAS_ANY(BITMAP lhs, BITMAP rhs)
计算两个Bitmap列是否存在相交元素,返回值是Boolean值。
select bitmap_has_any(to_bitmap(1),to_bitmap(2)) cnt;
+------+
| cnt |
+------+
| 0 |
+------+
# ===================================================================
select bitmap_has_any(to_bitmap(1),to_bitmap(1)) cnt;
+------+
| cnt |
+------+
| 1 |
+------+
12.2.18 BITMAP_HAS_ALL
BOOLEAN BITMAP_HAS_ALL(BITMAP lhs, BITMAP rhs)
如果第一个bitmap包含第二个bitmap的全部元素,则返回true。如果第二个bitmap包含的元素为空,返回true。
select bitmap_has_all(bitmap_from_string("0, 1, 2"), bitmap_from_string("1, 2")) cnt;
+------+
| cnt |
+------+
| 1 |
+------+
# ===================================================================
select bitmap_has_all(bitmap_empty(), bitmap_from_string("1, 2")) cnt;
+------+
| cnt |
+------+
| 0 |
+------+
12.2.19 BITMAP_CONTAINS
BOOLEAN BITMAP_CONTAINS(BITMAP bitmap, BIGINT input)
计算输入值是否在Bitmap列中,返回值是Boolean值。
select bitmap_contains(to_bitmap(1),2) cnt;
+------+
| cnt |
+------+
| 0 |
+------+
# ===================================================================
select bitmap_contains(to_bitmap(1),1) cnt;
+------+
| cnt |
+------+
| 1 |
+------+
12.2.20 BITMAP_COUNT
BITMAP BITMAP_COUNT(BITMAP lhs)
返回输入bitmap的个数。
select bitmap_count(to_bitmap(1)) cnt;
+------+
| cnt |
+------+
| 1 |
+------+
12.2.21 BITMAP_NOT
BITMAP BITMAP_NOT(BITMAP lhs, BITMAP rhs)
计算lhs减去rhs之后的集合,返回新的bitmap。
select bitmap_count(bitmap_not(bitmap_from_string('2,3'),bitmap_from_string('1,2,3,4'))) cnt;
+------+
| cnt |
+------+
| 0 |
+------+
# ===================================================================
select bitmap_to_string(bitmap_not(bitmap_from_string('2,3,5'),bitmap_from_string('1,2,3,4'))) result;
+-------+
| result|
+-------+
| 5 |
+-------+
12.3 HLL函数
12.3.1 HLL_HASH
HLL_HASH(value)
HLL_HASH 将一个值转换为HLL类型。通常用于导入数据时,将普通类型的值导入到HLL列中。
select HLL_CARDINALITY(HLL_HASH('abc'));
+----------------------------------+
| hll_cardinality(HLL_HASH('abc')) |
+----------------------------------+
| 1 |
+----------------------------------+
12.3.2 HLL_EMPTY
HLL_EMPTY(value)
HLL_EMPTY 返回一个HLL类型的空值。
select hll_cardinality(hll_empty());
+------------------------------+
| hll_cardinality(hll_empty()) |
+------------------------------+
| 0 |
+------------------------------+
12.3.3 HLL_CARDINALITY
HLL_CARDINALITY(hll)
HLL_CARDINALITY 用于计算HLL类型值的基数。可以用来统计UV。存在误差。
select HLL_CARDINALITY(uv_set) from test_uv;
+---------------------------+
| hll_cardinality(`uv_set`) |
+---------------------------+
| 3 |
+---------------------------+

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)