基于Python的淘宝行为数据可视化分析
基于Python实现淘宝用户行为的数据分析和可视化展示,揭示关于流量、商品和用户的规律,为运营提供 输入。
项目背景&总结:
项目背景
完成如下商业分析任务,通过数据分析和可视化展示,充分挖掘数据的价值,让数据更好地为业务服务:
流量分析:PV/UV是多少,通过分析PV/UV能发现什么规律?
漏斗分析:用户“浏览-收藏-加购-购买”的转化率是怎样的?
用户价值分析:对电商平台什么样的用户是有价值的?要重点关注哪部分用户?
项目总结
一. 本项目对淘宝用户行为数据进行以下角度的处理及分析:
数据探索及清洗:对1225w+的淘宝用户行为数据进行探索及清洗处理,为数据构建分析维度;
流量分析:
基于数据集呈现淘宝月整体流量规模、每日流量分布及每天不同时间段流量分布情况;
对比淘宝日常与双十二不同时间段的流量分布;
对比淘宝日常与双十二转化转化漏斗,揭示平台日常及大促期间的转化率,为持续监控对比提供基准;
品类分析:根据流量及转化情况对品类进行分类,并输出各品类的复购周期,为不同品类运营资源分配提供一定依据;
用户分析:分析用户人均贡献;并基于RFM框架设计价值指标,并对用户数据进行聚类分析,实现用户价值分类,为精细化用户运营提供输入。
二. 本项目使用到的Python模块:
数据处理及统计分析:numpy、pandas、sklearn;
可视化:matplotlib、seaborn、plotly。
三. 不足及展望:
流量分析时因缺乏往期双十一、双十二的数据,无法对大促流量表现作同比环比分析,在实际业务中需要有对比才能说明问题;
进行漏斗分析时,考虑到细分每个品类的话数据量会较少,故只对平台整体数据作分析,实际业务中需要为不同品类输出相关数据及可视化,并结合往期数据作对比;
对用户价值分类时,缺少直接的金额数据,虽然从其他下单几率、购买品类数等角度构建指标,但考虑到不同品类的属性(尤其是价格)是不同的,顾客决策的容易程度也各异,因此有限的指标无法完全真实反映客户价值,实际业务中需要纳入更多信息。
数据获取
数据来源&字段说明
数据来源于阿里天池:淘宝用户购物行为数据可视化分析_数据集,字段说明如下。
注:该数据为脱敏后的一个月淘宝用户数据,且数据集经过一定比例缩小清洗,故后面分析时会发现有些品类流量过小,此处提前说明。

数据导入
首先加载基本的模块:
#加载基本模块
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
import plotly #用来绘制漏斗图导入数据并查看:
data=pd.read_csv('./淘宝用户购物行为数据可视化分析/user_action.csv',sep=',')
data.head()
可以发现'time'字段后面需要拆分成日期date与时hour来分析。
#查看各字段的数据类型&数据规模
data.info()
可以看出:
数据的size为1225w*5;
user_id&item_id&item_category为int,后续分析这两个变量应该需要作为分组变量进行聚合操作,可以转换成object类型。
接着查看各字段缺失值情况,可以看出,各字段都无缺失值,可省去处理缺失值的步骤。

最后,在正式处理和分析前,我们粗略了解该时间段整体的浏览-收藏-加车-下单行为数:
print('用户总数:',data.user_id.nunique())
print('下单用户总数:',data[data.behavior_type==4].user_id.nunique())
print('item总数:',data.item_id.nunique())
print('卖出item总数:',data[data.behavior_type==4].item_id.nunique())
print('类别总数:',data.item_category.nunique())
print('卖出类别总数:',data[data.behavior_type==4].item_category.nunique())
可以发现共有8916个商品类别,后续我们的分析可以除了以上的角度,还可以尝试从类别角度分析,看看对于不同类别商品,用户的行为特征(如复购周期)是否有差异。
数据处理
结合上一环节对数据情况的了解,本环节主要对data作以下处理:
'time'字段拆分成日期date与时hour来分析;
user_id&item_id&item_category为int,转换成object类型。
#time拆分成date&hour两个字段
#map方法可以对series的每个元素进行处理
data['date']=pd.to_datetime(data['time'].map(lambda x: x.split(' ')[0]))
data['hour']=data['time'].map(lambda x: x.split(' ')[1]).astype('int64')
#将user_id&item_id&item_category转化为object
for v in ['user_id','item_id','item_category']:
data[v]=data[v].astype('object',copy=True)
#查看数据前5行
data.head()处理完成后可以看到data增加了date与时hour两个字段。

最后我们查看下数据的时间范围——2014.11.18-2014.12.18。
#看看数据的时间范围
pd.Series(data.date.unique()).sort_values(ignore_index=True)
流量分析
整体流量规模
#整体的pv/uv规模
pv_sum=data.shape[0]
uv_sum=data.user_id.nunique()
print('月整体pv:',pv_sum)
print('月整体uv:',uv_sum)
#人均pv
pv_per_user=pv_sum/uv_sum
print('人均pv',pv_per_user)可以发现,这个月淘宝的人均pv为1225.7,当然对于这些流量指标,在实际业务中是需要按时间持续监测的。

当月流量分布情况
每天流量分布
由于篇幅原因,省去相关聚合及可视化代码,直接呈现结果:

可以发现:
每日的pv与uv的趋势接近,且除了双十二当天外,流量呈现周期性变化———工作日流量逐渐递减至周五达一周谷点,然后周末流量上升至周日达到峰值;
双十二当天流量明显爆发。
一天中不同时间段流量分布

可以发现:
22点用户普遍开始进入休息时间后,uv/pv持续下降,至次日5点开始流量上升,到早上10点开始pv/uv稳定;
与uv从10点到22点比较稳定不同,pv在18点后迎来明显上升到22点达到峰值,可以推断因为下班,刷手机网购的时间多了,工作时间用户可利用碎片化时间浏览,但不如下班后自由,可以持续浏览淘宝。
双十二当天不同时间段流量分布
从前面可以发现双十二当天平台流量暴涨,那么当天的流量具体如何分布的呢:

整体上D12当天流量分布与平时分布区别不大,但白天(10-18点)流量折线不如平日平滑,推测是不同时间段有不同的活动运营,有的时间段活动力度相对大(如10、11、12点)。
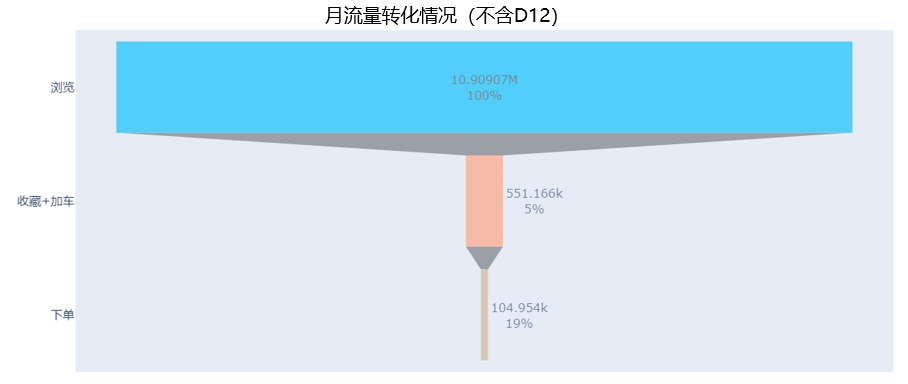
漏斗分析
我们先简单看一下这个月的基于PV的用户行为数据统计:
behavior_count=data.groupby('behavior_type')['user_id'].count()
behavior_count
接着画成漏斗,为简化分析我们将收藏与加车合并为同一个环节,并借助plotly模块实现漏斗图:
from plotly import graph_objects as go
fig = go.Figure(go.Funnel(
y = ['浏览','收藏+加车','下单']
,x = [behavior_count[1],behavior_count[2]+behavior_count[3],behavior_count[4]]
,textposition = ["inside","outside","outside"]
,textinfo = "value+percent initial"#percent previos则是跟上一环节比
,opacity = 0.65
, marker = {"color":["deepskyblue", "lightsalmon", "tan"]}
))
fig.show()
可以看到月整体浏览到收藏/加车转化率为5%,收藏/加车到下单的转化率为21%,整体转化率为1%左右,接着我们可以对比不含双十二的月整体与双十二当天的转化数据:


可以发现双十二当天从浏览到有意向(收藏/加车)的转化率跟平时相差不多,但加车/收藏到下单的转化率为44%是平常19%的两倍多,整体转化率也达到2.2%。
品类分析
根据流量及转化情况对品类进行分类
对data以品类字段item_category作分组计算,算出每个品类的PV(pv)、UV(uv)
、订单总数(orders)字段,并据此算出转化率字段(cr)
#各品类uv/pv
pv_category=data.groupby('item_category')[['user_id']].count().reset_index()
pv_category = pv_category.rename(columns={'user_id':'pv'})
uv_category=data.groupby('item_category')[['user_id']].nunique().reset_index()
uv_category = uv_category.rename(columns={'user_id':'uv'})
view_category=pd.merge(pv_category,uv_category,on='item_category')
#各品类订单数
order_category=data[data['behavior_type']==4].groupby('item_category')[['user_id']].count().reset_index()
order_category=order_category.rename(columns={'user_id':'orders'})
#连接流量表,并将无订单品类na改为0
category=pd.merge(view_category,order_category,on='item_category',how='left')
category=category.fillna({'orders':0})
#计算转化率
category['cr']=category.orders/category.pv
category
因为可能有些类别上架时间长短不一致导致流量规模有区别,为了让不同类别更具可比性,我们还可以挑选日均pv或日均uv作为衡量类别流量规模的指标。
#重命名并计算曝光天数
category=category.rename(columns={'min':'min_date','max':'max_date'})
category['pv_window']=category.max_date-category.min_date+np.timedelta64(1,'D')
category.head()
#将pv_window转化为int
category['pv_window']=category['pv_window'].astype('str').map(lambda x :x[:-5]).astype('int32')
#计算日均pv/uv
category['pv_per_day']=category['pv']/category['pv_window']
category['uv_per_day']=category['uv']/category['pv_window']
category
接着我们通过category.describe()查看各类别流量&转化率变量的基本统计情况:

各类别平均转化率为1.36%,
8916个类别中,75%类别pv大于378,uv大于60。
基于上表我们可以快速筛选出符合特定表现的品类,并按照一定的标准对品类进行分类。作为平台而言,品类可以理解是更大一级的产品,而平台运营投入的资源(如维系不同品类运营的人力资源,以及大促/日常活动的优惠力度)也是有限的,因此有必要根据一定规则对品类的表现(如流量数量、流量质量、转化率、平台投入的运营成本等)进行分类,以优化对不同品类的活动、店铺的策略。
在本例中,根据日均流量(简化分析,仅使用日均pv)与转化率定义以下品类分类规则:
日均pv在[0,50,100,12686]记为['流量低','中等流量','流量大'];
cr[0,0.01,0.05,1]记为['转化率低','中等转化率','转化率高']。
接着,我们按照规则将日均pv与转化率cr进行分箱处理
#按照规则将日均pv与转化率cr进行分箱处理
#需要将categories类型转化为str才可以进行series之间的合并
pv_per_day_cut=pd.cut(category['pv_per_day'],bins=[0,50,100,12686],labels=['流量低','中等流量','流量大']).astype('str')
#因为最小值含0,为满足左开右闭需要将左端点设为负数
cr_cut=pd.cut(category['cr'],bins=[-1,0.01,0.03,1],labels=['转化率低','中等转化率','转化率高']).astype('str')
labels=pv_per_day_cut+'&'+cr_cut
category['labels']=labels
category.head()
接着我们可以看下每类品类的占比:
group_category=category['labels'].value_counts()/category.shape[0]
group_category
可以发现:
有57%的品类流量低且转化率低,接近9成的品类都属于流量低,在此案例中主要是因为数据被筛选过跟实际业务情况会有出入,在实际分析中,需要对分组规则作详细讨论,甚至进行头脑风暴,可以对品类数据进行聚类分析;
得到分类结果后,不同品类运营可根据自身状况置顶针对性运营策略,如针对流量低但转化率高的品类,运营可争取更多平台分发流量资源,并与商家合作推动引入更多平台外流量。
品类复购周期分析
注:
由于本数据集样本有限,故此部分仅对前面标记好的流量大&转化率高的28个品类进行复购周期分析;
同一个用户在同一天多次购买同一个品类的情况,合并记为一天。

首先,筛选出这28个品类每天的下单用户信息,其中rebuy_times是指该用户当天购买统一品类多少个item。
#筛出这28个品类的id
key_item_category=list(category.loc[category['labels']=='流量大&转化率高','item_category'])
#筛选出28个品类每天的下单用户信息
groupby_obj=data[(data.item_category.isin(key_item_category))&(data.behavior_type==4)]
rebuy_by_category=groupby_obj.groupby(['item_category','user_id','date'])['hour'].count().reset_index()
rebuy_by_category=rebuy_by_category.rename(columns={'hour':'rebuy_times'})
rebuy_by_category.head()
接着基于上表,计算每个品类每个用户每次复购的间隔:
#计算每个品类每个用户的单次复购周期
#diff是用于对比的一个函数,在默认情况下是与前一行对比 ,首行用null来填充,参数periods=3表示用前三行进行作差
# 对日期排序(按照先后顺序),给予pandas的date函数计算前后两次购物相差的天数
#dropna去掉了每个用户在数据集周期内第一次购买日期的记录,不加dropna()会导致'item_category','user_id'索引消失
rebuy_win=rebuy_by_category.groupby(['item_category','user_id'])['date'].apply(lambda x:x.sort_values().diff().dropna())
rebuy_win=rebuy_win.reset_index()
rebuy_win=rebuy_win.rename(columns={'date':'rebuy_window'})
#将rebuy_win数据类型由timedelta64转为int
rebuy_win.rebuy_window=rebuy_win.rebuy_window.astype('str').map(lambda x :x[:-5]).astype('int32')
rebuy_win.head()
最后,计算每个品类的复购周期:
品类的复购周期=统计周期内该品类每个用户购买间隔之和/每个复购用户总购买次数,其中:
每个用户购买间隔之和为sum_of_rebuy_window;
每个复购用户总购买次数=复购用户总首购次数first_buy_times+复购用户总复购次数rebuy_times。
#计算每个品类平均复购周期
rebuy_win_by_category=rebuy_win.groupby('item_category').rebuy_window.agg(['nunique','count','sum']).reset_index()
rebuy_win_by_category=rebuy_win_by_category.rename(columns={'nunique':'first_buy_times','count':'rebuy_times','sum':'sum_of_rebuy_window'})
#复购用户总购买时间间隔/复购用户总购买次数
#复购用户总购买时间间隔sum_of_rebuy_window/(总首购次数first_buy_times+总复购次数rebuy_times)
rebuy_win_by_category['avg_rebuy_window']=rebuy_win_by_category.sum_of_rebuy_window/(rebuy_win_by_category.first_buy_times+rebuy_win_by_category.rebuy_times)
rebuy_win_by_category
了解每个品类用户的平均复购频率后,该品类的平台/商家运营可在复购期内触达用户,通过运营手段刺激用户复购。
最后将品类表现与分类数据集category及(重点)品类平均复购周期数据集rebuy_win_by_category写入Excel,发给相关同事。
#最后将品类表现与分类数据集category及(重点)品类平均复购周期数据集rebuy_win_by_category写入Excel,发给相关同事。
with pd.ExcelWriter('./淘宝用户购物行为数据可视化分析/category_analysis.xlsx') as writer:
category.to_excel(writer, sheet_name='category', index=False)
rebuy_win_by_category.to_excel(writer, sheet_name='rebuy_win_by_category', index=False)用户价值分析
人均贡献分析
对于平台而言,每天活跃的用户有的购买了有的未购买,因此计算平均一个活跃用户能贡献多少收入体现了平台的转化能力,但本数据集没有下单金额数据,无法计算ARPU&ARPPU,因此从“每个人能买多少量”的角度考虑构建指标:
人均下单商品量:当天下单item数/当天活跃用户数
付费用户人均下单商品量:当天下单item数/当天付费用户数

从上图可知,淘宝每日的活跃用户人均下单商品量在0.5件左右,在双十二当天升至2件;付费用户人均下单商品量日常在2.5件以下,但在双十二当天升至4件左右的水平。
用户价值分类
确定分类变量&分类策略
用户价值分析可以参考经典的RFM模型,最近一次购买距今天数Recency&统计周期(一个月)内购买天数Frequency都可以算出来,但是数据集无付费金额信息,无法直接得到用户关于货币贡献Monetary的指标,因此我们可以考虑从以下三个角度衡量用户消费的价值:
下单商品数:下单item数越多,表明用户在平台购物越多;
下单率=下单item数/浏览过的item数,可以理解为该指标越高的用户,对于给定商品,这些用户转化机会越高;
下单品类数:对于平台而言,可以认为购买多品类的用户粘性与价值会更高。
由于涉及到5个价值变量,我们不大可能像上面给品类那样简单打标签,毕竟即使每个变量分3档,也会有243个类别了。
因此我们确定首先确定第一条分类策略:
将近一个月未下单的用户跟有下单的用户区分开:未下单用户记为待挽回用户,对有下单的用户进行聚类分析;
...
由于计算篇幅较大,因此省去,计算每个用户最近一次购买距今天数recency、统计周期(一个月)内购买天数freq_buy_days、下单商品数ordered_items、下单率order_rate、下单品类数ordered_categories的代码。直接展示存放结果的user数据集并筛选出有购买记录的用户子集bought_user。

接着我们结合user.describe()和箱线图了解各变量的分布特征

结合数据描述统计表可以发现过去一个月:
用户平均在淘宝下单12件商品,涉及8个品类,下单的概率为4%;
用户平均一个月有5天在淘宝下单,75%的用户最近一次下单距今8天

五个变量的箱线图均被压得很扁,说明均有离群值跟大部分用户水平差得太多,而且这些离群值的点看起来不多,但放到淘宝亿级用的商业环境来看也是不小的群体,最关键的是这些离群值也代表着极高的用户价值,因此无法直接删除这些样本,但不处理肯定会对聚类结果产生影响(如聚类出几个数量很小的类别),由此我们得到第二条分组策略
首先确定第二条分类策略:
将近一个月未下单的用户跟有下单的用户区分开,未下单用户记为待挽回用户,对有下单的用户进行聚类分析;
基于淘宝的用户基数,我们假设跟业务确定好以下“极端值”人群直接就是淘宝的超级VIP用户,这个群体不参与聚类分析:
近一个月有购买20个及以上item,且涉及10个及以上品类;
近一个月有至少7天有购买记录;
下单几率在10%及以上。
outlier_con1=(bought_user.ordered_items>(20))
outlier_con2=(bought_user.ordered_categories>(11))
outlier_con3=(bought_user.order_rate>(0.1))
outlier_con4=(bought_user.freq_buy_days>(7))
super_vip=bought_user[outlier_con1 & outlier_con2&outlier_con3&outlier_con4]
super_vip.shape
可以发现这类超级vip占了总客户的1.83%,然后我们对剩余有购买记录的客户样本normal_buyer作聚类分析:
normal_buyer=bought_user[~(outlier_con1 & outlier_con2&outlier_con3&outlier_con4)]
print(normal_buyer.shape)
聚类前准备
因为本次聚类的5个变量都未连续型,因此采用较好解释的kmeans法,但由于kmeans法聚类是基于欧氏距离,为了消除不同变量量纲的区别,我们需要先了解数据的偏度峰度,考虑是否对数据作box-cox处理使之接近正态分布,然后再对数据作标准化处理。
#导入计算数据偏度峰度的模块
from scipy import stats
from scipy.stats import norm, skew
#计算每个待聚类变量的偏度峰度
normal_buyer_value=normal_buyer[['recency','ordered_items','freq_buy_days','ordered_categories','order_rate']]
normal_buyer_value_skew_and_kurt=pd.DataFrame([i for i in zip(normal_buyer_value.columns, user_value.skew(), user_value.kurt())],
columns=['特征', '偏度', '峰度'])
normal_buyer_value_skew_and_kurt
从上表可以发现5个待聚类变量都明显不服从正态分布(偏度与峰度接近0),因此对数据进行box-cox转换(boxcox是将数据分布正态化,使其更加符合后续对数据分布的假设)。
# boxcox转换:注意数据有0时转换会变成无限大,要加0.000001,本例不需要
normal_buyer_value_bc = normal_buyer_value.copy()
for i in normal_buyer_value_bc.columns: # 自动计算λ
normal_buyer_value_bc[i],lmbda = stats.boxcox(normal_buyer_value[i])
# 查看偏度、峰度
pd.DataFrame([i for i in zip(normal_buyer_value_bc.columns, normal_buyer_value_bc.skew(), normal_buyer_value_bc.kurt())],
columns=['特征', '偏度', '峰度'])
可以看到box-cox转换后,各变量相对之前更接近正态分布了,接着对数据进行标准化,以减少不同量纲的影响。
# K-means 的本质是基于欧式距离的数据划分算法,均值和方差大的维度将对数据的聚类产生决定性影响。
# 使用标准化对数据进行预处理可以减小不同量纲的影响。
from sklearn.preprocessing import StandardScaler
standard_scaler = StandardScaler()
standard_scaler.fit(normal_buyer_value_bc)
data_scaler = standard_scaler.transform(normal_buyer_value_bc)#ndarray形式
normal_buyer_value_data_scaler = pd.DataFrame(data_scaler
,columns = ['recency','ordered_items','freq_buy_days','ordered_categories','order_rate']
,index = normal_buyer.index)
normal_buyer_value_data_scaler.head()
数据处理好以后,我们需要确定聚类数k,取多少个聚类数比较合适?这里介绍手肘法:
手肘法的核心思想是:随着聚类数k的增大,样本划分会更加精细,每个簇的聚合程度会逐渐提高,那么误差平方和SSE自然会逐渐变小。并且,当k小于真实聚类数时,由于k的增大会大幅增加每个簇的聚合程度,故SSE的下降幅度会很大,而当k到达真实聚类数时,再增加k所得到的聚合程度回报会迅速变小,所以SSE的下降幅度会骤减,然后随着k值的继续增大而趋于平缓,也就是说SSE和k的关系图是一个手肘的形状,而这个肘部对应的k值就是数据的真实聚类数。当然,这也是该方法被称为手肘法的原因。
但是需要注意的是实际业务环境中,只看手肘法取聚类数通常是不现实的,万一手肘法的推荐的k值过小或过大,与业务实际不符合,这时候需要根据实际情况作权衡。
from sklearn.cluster import KMeans
# 选择K的范围 ,遍历每个值进行评估
inertia_list = []
for k in range(1,10):
model = KMeans(n_clusters = k, max_iter = 500, random_state = 0)
kmeans = model.fit(normal_buyer_value_data_scaler)
inertia_list.append(kmeans.inertia_)#inertia记录着SSE
# 绘图
fig,ax = plt.subplots(figsize=(8,6))
ax.plot(range(1,10), inertia_list, '*-', linewidth=1)
ax.set_xlabel('k')
ax.set_ylabel("SSE")
ax.set_title('SSE变化图')
plt.show()
本次分析中肘部在2的位置,对于电商用户分类而言,2个群组对业务的意义无疑是不大的,因此退而求其次,选择4个。
聚类&结果解读
接着开始聚类,并查看分组的人数
kmeans = KMeans(n_clusters=4, random_state=0).fit(normal_buyer_value_data_scaler)
#查看每个分类的人数
pd.Series(kmeans.labels_).value_counts().sort_index()
可以看到,去除“离群”的超级VIP后,聚类结果大小相对均匀。接着将标签加到normal_buyer表中,再查看各个聚类群组的特征。
normal_buyer['label']=kmeans.labels_
normal_buyer.groupby('label')[['recency','freq_buy_days','ordered_items','ordered_categories','order_rate']].agg(['count','mean','median'])
也可以根据箱型图来看:

4个聚类群组+超级VIP群组特征如下:
高价值用户(24.7%):3天内有过购买,一个月有将近10天都会在淘宝下单,购买的item和品类数多,下单概率中上,是仅次于超级VIP的忠实用户,运营重点是提供优质服务,继续提升购买频率与购买品类数,使其升级为群组0的高价值人群;
一般保持用户(18.9%):有将近两周没在淘宝购买,平均一个月购买天数比较少(不足两次),购买数量少,品类集中,下单几率最低,运营时需要控制好成本;
一般价值用户(27.0%):近期有过购买,但购买天数及购买item&品类数均在中等水平,且下单几率不高,对该群体可以通过优质服务(如客服主动介入、新品类购物时平台赠送运费险)降低其尝新的机会成本,提高下单几率;
一般价值发展用户(16.4%):近10天有过购买,虽然购买天数不多,购买item&品类数均也只在中下水平,但下单几率较高,可见该群体对淘宝(或淘宝特定 品类)比较信任,因此可以通过一些有利益点互动活动,让用户更多留在淘宝,从而提升购买频率及丰富其购买品类。
超级VIP用户(1.83%):在平台买得频、买得多、买得广、下单概率极高;只占总人群1.83%,但以淘宝5亿用户规模来看,该人群实际规模可达几百万,值得重点研究及运营:针对该人群进行用户调研,充分了解群体;给以超高规格&定制化服务或活动策划。
然后将这4个群组及超级vip群的分组组合并回user表
#将消费过的用户分类label合并回user表
super_vip['label']=5
super_vip_id_label=super_vip[['user_id','label']]
bought_user_id_label=normal_buyer[['user_id','label']]
buyer_lable=pd.concat([super_vip_id_label,bought_user_id_label],axis=0)
user=pd.merge(user,buyer_lable,on='user_id',how='left')然后不要忘了还有一部分近一个月都没有购买的“待挽留用户”,我们可以对其简单分为两组:
较长时间(如超过一周)没打开淘宝的用户:通过短信或站内信发送最近一次浏览/收藏/加车的商品优惠信息挽回,需要投入优惠力度要更大一些。
近期(一周内)打开淘宝的用户:发放相关品类的优惠券或发送 降价信息促成交易。
为此我们需要先计算每个用户最近一次行为时间,并筛选出无下单的两类用户,分别对其打标
#计算每个用户最近一次行为时间
recent_date=data.groupby('user_id')['date'].max().reset_index()
recent_act_date=recent_date.rename(columns={'date':'recent_act_date'})
user=pd.merge(user,recent_act_date,on='user_id',how='left')
#将无消费且一周内打开过淘宝的用户分到群组6,无消费且超过一周未打开淘宝的用户分到群组7
user.loc[(user.ordered_items==0)&(user.recent_act_date >= np.datetime64('2014-12-12')),['label']]=6
user.loc[(user.ordered_items==0)&(user.recent_act_date < np.datetime64('2014-12-12')),['label']]=7user.label.value_counts().sort_index()/10000
可以发现这两类用户分别占总用户的9.1%与2.0%。
然后输出每个分组特征cluster_info。
cluster_info=user.groupby('label')[['recency','freq_buy_days','ordered_items','ordered_categories','order_rate']].agg(['count','mean','median'])
#计算每个组别的用户占比
cluster_info[('group_size','size_pct')]=cluster_info[('freq_buy_days', 'count')]/10000
cluster_info
最后,将分组用户信息user及分组特征cluster_info写入同一个Excel表。
#计算每个分组特征分组特征cluster_info
cluster_info=user.groupby('label')[['recency','freq_buy_days','ordered_items','ordered_categories','order_rate']].agg(['count','mean','median'])
#当Pandas要写入多个sheet时,to_excel第一个参数excel_writer要选择ExcelWriter对象,不能是文件的路径。否则,就会覆盖写入
with pd.ExcelWriter('./淘宝用户购物行为数据可视化分析/user_cluster.xlsx') as writer:
user.to_excel(writer, sheet_name='user', index=False)
cluster_size.to_excel(writer, sheet_name='cluster_size', index=True)
开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)