One-Class SVM详解
One-Class SVM(Support Vector Machine)是一种无监督学习算法,用于异常检测和离群点检测。它的目标是通过仅使用正常数据来建模,识别出与正常模式不同的异常数据点。数据映射:将正常数据映射到高维特征空间中,使得正常数据点能够被一个超平面所包围。这个超平面被称为决策边界。寻找最优超平面:通过最大化超平面与正常数据之间的间隔,寻找一个最优的分割超平面,使得异常点尽可能远离该
简介
One-Class SVM(Support Vector Machine)是一种无监督学习算法,用于异常检测和离群点检测。它的目标是通过仅使用正常数据来建模,识别出与正常模式不同的异常数据点。
One-Class SVM的工作原理如下:
- 数据映射:将正常数据映射到高维特征空间中,使得正常数据点能够被一个超平面所包围。这个超平面被称为决策边界。
- 寻找最优超平面:通过最大化超平面与正常数据之间的间隔,寻找一个最优的分割超平面,使得异常点尽可能远离该超平面。这意味着决策边界要尽可能远离正常数据点。
- 异常检测:对于新的数据点,通过计算其与超平面的距离,来判断该数据点是否为异常。距离较大的数据点更有可能是异常点。
One-Class SVM的关键在于如何选择合适的超平面,以使得正常数据被尽可能包围,而异常数据则被远离。这是通过优化一个目标函数来实现的,其中包括最小化超平面到最近正常数据点的距离和最大化超平面与正常数据之间的间隔。
在One-Class SVM中,还有两个重要的参数需要设置:
- nu参数控制了异常点的比例。它限制了在模型中允许存在的异常点的比例。较小的nu值表示更少的异常点,较大的nu值表示更多的异常点。
- kernel参数定义了用于计算样本之间相似度的核函数,例如线性核、高斯核等。
优缺点
One-Class SVM的优点包括:
- 不需要异常数据进行训练,只需要正常数据即可。
- 对于高维数据和复杂的数据分布具有较好的适应性。
- 可以通过调整模型参数来控制异常点的检测灵敏度。
然而,One-Class SVM也有一些限制:
- 在处理高维数据和大规模数据时,计算复杂度较高。
- 对于数据分布不均匀或存在噪声的情况,效果可能不理想。
- 需要谨慎选择模型参数,以避免过拟合或欠拟合的情况。
One-Class SVM广泛应用于异常检测、离群点检测、网络安全、图像处理等领域。它可以帮助识别潜在的异常情况,对于保护系统的安全和发现异常行为具有重要的作用。
代码示例
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
# 生成训练样本
rng = np.random.RandomState(42)
n_samples = 200
X = 0.3 * rng.randn(n_samples, 2)
X_train = np.r_[X + 2, X - 2]
# 训练OneClassSVM模型
clf = svm.OneClassSVM(nu=0.1, kernel="rbf", gamma=0.1)
clf.fit(X_train)
# 生成测试样本
X_test = np.r_[rng.uniform(low=-6, high=6, size=(50, 2))]
# 预测样本的异常情况
y_pred_train = clf.predict(X_train)
y_pred_test = clf.predict(X_test)
n_error_train = y_pred_train[y_pred_train == -1].size
n_error_test = y_pred_test[y_pred_test == -1].size
print(n_error_train) # 打印出训练集中异常值的个数为40 40/400=0.1 对应nu参数
print(n_error_test)
# 绘制训练样本和测试样本的散点图
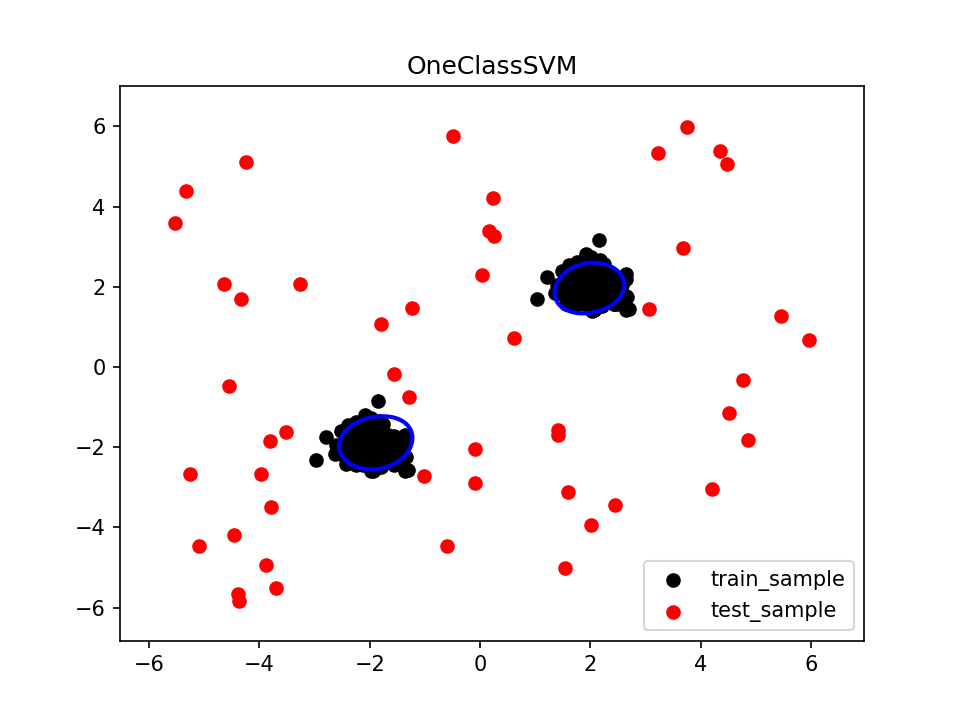
plt.scatter(X_train[:, 0], X_train[:, 1], color='black', label='train_sample')
plt.scatter(X_test[:, 0], X_test[:, 1], color='red', label='test_sample')
# 绘制异常样本的边界
xmin, xmax = X_test[:, 0].min() - 1, X_test[:, 0].max() + 1
ymin, ymax = X_test[:, 1].min() - 1, X_test[:, 1].max() + 1
xx, yy = np.meshgrid(np.linspace(xmin, xmax, 500), np.linspace(ymin, ymax, 500))
Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contour(xx, yy, Z, levels=[0], linewidths=2, colors='blue')
# 设置图形标题和图例
plt.title("OneClassSVM")
plt.legend()
plt.show()

该示例演示了如何使用OneClassSVM进行异常检测。首先,使用随机生成的数据生成训练样本X_train。然后,创建并训练OneClassSVM模型clf。接下来,生成测试样本X_test,并使用训练好的模型预测样本的异常情况。最后,通过绘制训练样本、测试样本和异常边界,展示了异常检测的结果。
请注意,示例中使用了rbf(径向基函数)作为核函数,nu=0.1表示异常点的比例约为10%。你可以根据具体问题和数据集调整这些参数来适应不同的场景。
One-Class SVM常见方法解释:
- fit(X):训练,根据训练样本和上面两个参数探测边界。(注意是无监督)
- predict(X):返回预测值,+1就是正常样本,-1就是异常样本。
- decision_function(X):返回各样本点到超平面的函数距离(signed distance),正的维正常样本,负的为异常样本。
- set_params(**params):设置这个评估器的参数,该方法适用于简单估计器以及嵌套对象(例如管道)
- get_params([deep]):获取这个评估器的参数。
- fit_predict(X[, y]):在X上执行拟合并返回X的标签,对于异常值,返回 -1 ,对于内点,返回1。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 5
5 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)