实用篇 | huggingface的一些应用指导
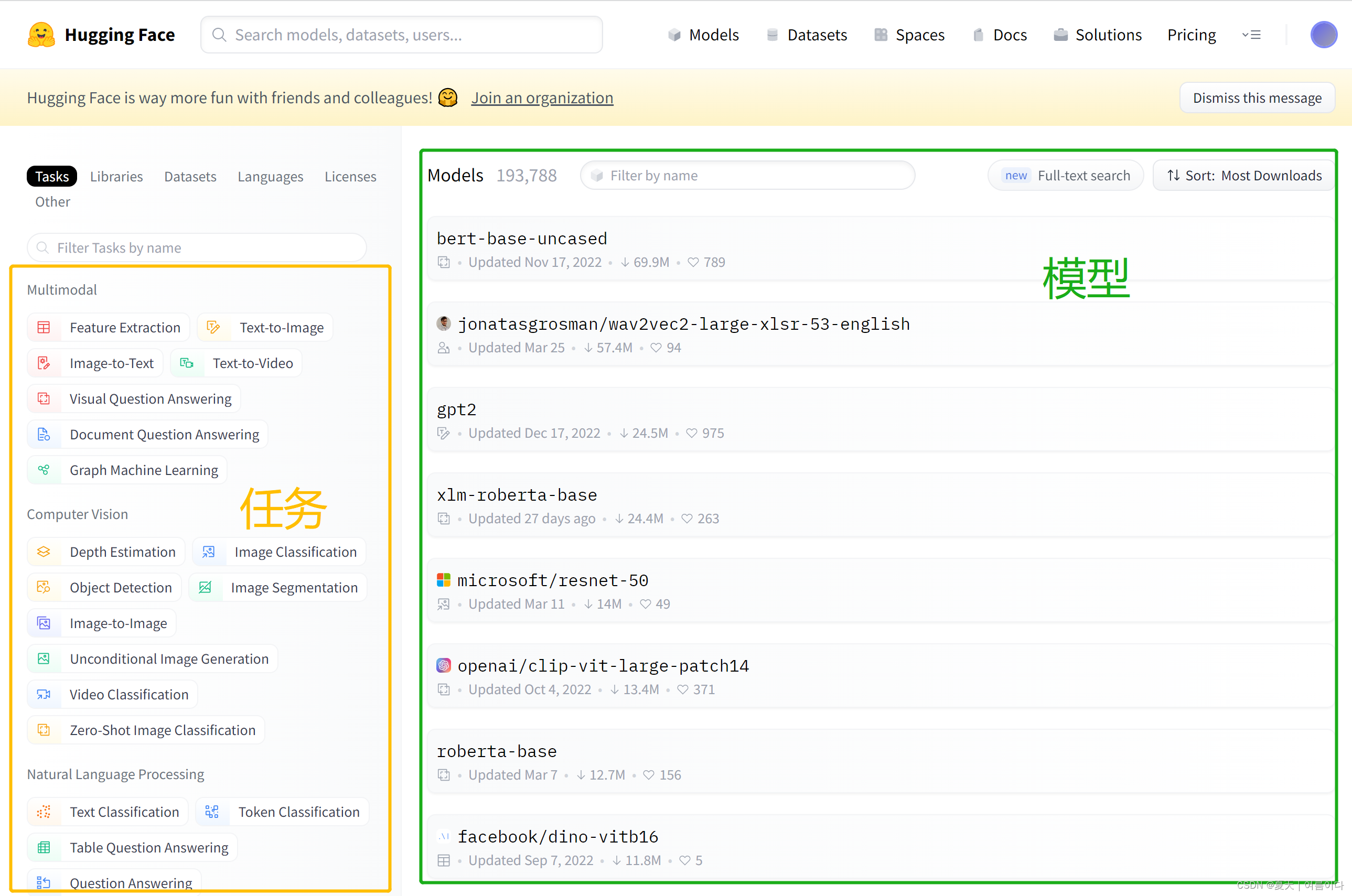
本文主要介绍hugging Face(拥抱脸)的简单介绍以及常见用法,用来模型测试是个好的工具~如下图所示左边框是各项任务,包含多模态(Multimodal),计算机视觉(Computer Vision),自然语言处理(NLP)等,右边是各任务模型。本文测试主要有。
本文主要介绍hugging Face(拥抱脸)的简单介绍以及常见用法,用来模型测试是个好的工具~
如下图所示左边框是各项任务,包含多模态(Multimodal),计算机视觉(Computer Vision),自然语言处理(NLP)等,右边是各任务模型。

本文测试主要有
目录
示例1:语音识别
点击任务栏里的 Audio Classification(语音分类)任务
1.1.语音识别
点开一个模型,是基于语音的情绪识别,有的作者可能有写模型描述(Model description),任务和数据集描述(Task and dataset description),使用示例(Usage examples)有的作者不会写的很详细。

虽然是不同用户的模型,但是实现都是语音情绪识别,相同hubert模型,训练的数据集不同~
使用案例
git clone https://github.com/m3hrdadfi/soxan.git
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchaudio
from transformers import AutoConfig, Wav2Vec2FeatureExtractor
import librosa
import IPython.display as ipd
import numpy as np
import pandas as pd
from src.models import Wav2Vec2ForSpeechClassification, HubertForSpeechClassification
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model_name_or_path = "harshit345/xlsr-wav2vec-speech-emotion-recognition"
config = AutoConfig.from_pretrained(model_name_or_path)
feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained(model_name_or_path)
sampling_rate = feature_extractor.sampling_rate
model = Wav2Vec2ForSpeechClassification.from_pretrained(model_name_or_path).to(device)
def speech_file_to_array_fn(path, sampling_rate):
speech_array, _sampling_rate = torchaudio.load(path)
resampler = torchaudio.transforms.Resample(_sampling_rate)
speech = resampler(speech_array).squeeze().numpy()
return speech
def predict(path, sampling_rate):
speech = speech_file_to_array_fn(path, sampling_rate)
inputs = feature_extractor(speech, sampling_rate=sampling_rate, return_tensors="pt", padding=True)
inputs = {key: inputs[key].to(device) for key in inputs}
with torch.no_grad():
logits = model(**inputs).logits
scores = F.softmax(logits, dim=1).detach().cpu().numpy()[0]
outputs = [{"Emotion": config.id2label[i], "Score": f"{round(score * 100, 3):.1f}%"} for i, score in enumerate(scores)]
return outputs
# path for a sample
path = '/workspace/tts_dataset/studio/studio_audio/studio_a_00000.wav'
outputs = predict(path, sampling_rate)
print(outputs)更改代码中的.wav地址

要运行前必须安装的是huggingface的库,所以之前没有的话安装(建议python3.8以上)
# requirement packages
pip install git+https://github.com/huggingface/datasets.git
pip install git+https://github.com/huggingface/transformers.git
# 语音处理需要以下俩个库,任务不同,所安装的库不同
pip install torchaudio
pip install librosa
1.2.语音情绪识别

原文提供了预测方法,直接是实现不了的,需要修改
def predict_emotion_hubert(audio_file):
""" inspired by an example from https://github.com/m3hrdadfi/soxan """
from audio_models import HubertForSpeechClassification
from transformers import Wav2Vec2FeatureExtractor, AutoConfig
import torch.nn.functional as F
import torch
import numpy as np
from pydub import AudioSegment
model = HubertForSpeechClassification.from_pretrained("Rajaram1996/Hubert_emotion") # Downloading: 362M
feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained("facebook/hubert-base-ls960")
sampling_rate=16000 # defined by the model; must convert mp3 to this rate.
config = AutoConfig.from_pretrained("Rajaram1996/Hubert_emotion")
def speech_file_to_array(path, sampling_rate):
# using torchaudio...
# speech_array, _sampling_rate = torchaudio.load(path)
# resampler = torchaudio.transforms.Resample(_sampling_rate, sampling_rate)
# speech = resampler(speech_array).squeeze().numpy()
sound = AudioSegment.from_file(path)
sound = sound.set_frame_rate(sampling_rate)
sound_array = np.array(sound.get_array_of_samples())
return sound_array
sound_array = speech_file_to_array(audio_file, sampling_rate)
inputs = feature_extractor(sound_array, sampling_rate=sampling_rate, return_tensors="pt", padding=True)
inputs = {key: inputs[key].to("cpu").float() for key in inputs}
with torch.no_grad():
logits = model(**inputs).logits
scores = F.softmax(logits, dim=1).detach().cpu().numpy()[0]
outputs = [{
"emo": config.id2label[i],
"score": round(score * 100, 1)}
for i, score in enumerate(scores)
]
return [row for row in sorted(outputs, key=lambda x:x["score"], reverse=True) if row['score'] != '0.0%'][:2]
当然可以不按作者的写
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchaudio
from transformers import AutoConfig, Wav2Vec2FeatureExtractor
from src.models import Wav2Vec2ForSpeechClassification, HubertForSpeechClassification
#dataset: AVDESS
model_name_or_path = "Rajaram1996/Hubert_emotion"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
config = AutoConfig.from_pretrained(model_name_or_path)
feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained(model_name_or_path)
sampling_rate = feature_extractor.sampling_rate
# for wav2vec
#model = Wav2Vec2ForSpeechClassification.from_pretrained(model_name_or_path).to(device)
# for hubert
model = HubertForSpeechClassification.from_pretrained(model_name_or_path).to(device)
def speech_file_to_array_fn(path, sampling_rate):
speech_array, _sampling_rate = torchaudio.load(path)
resampler = torchaudio.transforms.Resample(_sampling_rate, sampling_rate)
speech = resampler(speech_array).squeeze().numpy()
return speech
def predict(path, sampling_rate):
speech = speech_file_to_array_fn(path, sampling_rate)
inputs = feature_extractor(speech, sampling_rate=sampling_rate, return_tensors="pt", padding=True)
inputs = {key: inputs[key].to(device) for key in inputs}
with torch.no_grad():
logits = model(**inputs).logits
scores = F.softmax(logits, dim=1).detach().cpu().numpy()[0]
outputs = [{"Emotion": config.id2label[i], "Score": f"{round(score * 100, 3):.1f}%"} for i, score in
enumerate(scores)]
if outputs["Score"]
return outputs
# 001.wav =hap
path = "/workspace/dataset/emo/audio/000-001.wav"
outputs = predict(path, sampling_rate)
print(outputs)
1.3.语音合成
在huggingface上新建一个空间(Space),
上传文件,并运行
如果出错请参考【】
示例2:多模态中的vit模型提取图片特征

点进模型后,复制代码(如果想查看输出,还需要自己去进行print)
from transformers import ViTFeatureExtractor, ViTModel
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = ViTFeatureExtractor.from_pretrained('facebook/dino-vitb16')
model = ViTModel.from_pretrained('facebook/dino-vitb16')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
print(outputs,last_hidden_states)
结果

代码会下载其中的文件和打包好的模型,也就是下图这些文件

*注意:这里要求库,安装命令如下
# requirement packages
datasets
transformers
pillow示例3:自然语言处理(NLP)中的翻译实现
选一个 翻译任务(Translation),再选择一个中英翻译模型(一般模型名称都是模型,任务等的简写),例如下方右边的模型就表示Helsinki-NLP提供的数据集为opus,mt(machine translation机器翻译,中文翻英文):

from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("Helsinki-NLP/opus-mt-zh-en")
model = AutoModelForSeq2SeqLM.from_pretrained("Helsinki-NLP/opus-mt-zh-en")
提供的代码只是如何下载模型的代码,如果还要简单测试的话,需要自己编写代码进行测试
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, pipeline
tokenizer = AutoTokenizer.from_pretrained("Helsinki-NLP/opus-mt-zh-en")
model = AutoModelForSeq2SeqLM.from_pretrained("Helsinki-NLP/opus-mt-zh-en")
# Elena
translator = pipeline("translation", model=model, tokenizer=tokenizer)
results = translator("我是一名研究员")
print(results)结果如图

*注意:这里要求库,安装命令如下
#必须安装包
pip install transformers
pip install sentencepiece
#建议安装
pip install sacremoses问题与解决
【PS1】windows系统,anaconda虚拟环境中,pip安装l出错
Could not build wheels for soxr which use PEP 517 and cannot be installed directly

python -m pip install --upgrade pip
python -m pip install --upgrade setuptools
更新后如图

ERROR: Could not build wheels for soxr, which is required to install pyproject.toml-based projects
安装对应的whl文件
下载并安装对应的whl文件,可以通过以下地址下载。
Unofficial Windows Binaries for Python Extension Packages
获得whl文件后,直接 pip install 【whl文件绝对路径】
然后就可以装成功了。
【PS2】运行app.py后出现Build error Build failed with exit code: 1

参考Receiving this error even with a new space - Spaces - Hugging Face Forums
修改README.md,将python版本改为3.9.13

如果依旧出现
ERROR: process "/bin/sh -c pip install --no-cache-dir -r requirements.txt" did not complete successfully: exit code: 1需要设置
libpq-devgcc

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)