实验三 MapReduce实践
参考链接操作步骤参考链接,来自我们老师PPT,我只是写自己的操作过程。
实验目录
来自博主卷毛迷你猪的授权,来自我们老师PPT,我只是写自己的操作过程
实验三 MapReduce实践
- 1.实验目的
- 2.实验原理
- 3.实验准备
- 4.实验内容
1.实验目的
- 通过编写MapReduce程序,进一步掌握MapReduce的基本原理
- 通过编写不同案例的MapRduce程序,理解分支计算思想
- 掌握MapReduce程序的编写模式,能够较为熟练地分解、实现需求
2.实验原理
- map计算以一条记录为单位进行,reduce计算以一组记录为单位进行;
- map+reduce的组合形式,能够有效拆解很多大数据场景下的数据分析(即:计算需求);
- 由于MR计算是放在大数据分布式场景下进行的,所以必须深刻理解网络传输过程中的序列化和反序列化问题;
- 为了提升MR对数据的拉取和IO效率,MR计算框架本身实现了:“分区”和“二次排序”两个功能,综合起来看就是shuffle;
- MR为方便用户个性化操作作,提供了分区(partition)和排序(campare)的接口;
- 其他MR参数设置和接口使用,例如:合并操作(Combine),联表查询(Jion)…;
【注】目前MR计算框架已经不再是主流,但也有一定的适用场景;我们应该学会快速学习应用的能力,很多MR分治计算思维,在后续课程《大数据内存计算》中会被频繁使用。
3.实验准备
- 完成实验一,搭建好伪分布式环境
- 完成实验二,已经配置好网络访问环境
- 完成实验二,具备搭建Maven工程的经验
4.实验内容
【实验项目】项目1、项目2、项目3必做;项目4,及后续项目选做
- 项目1:分析和编写WordCount程序
- 项目2:统计各部门员工薪水总和(序列化+部门分区+Combiner)
- 项目3:统计全体员工工资水平(薪水分区)
- 项目4:进阶理解WordCount背后原理
- 项目5:TopN案例——统计每个月气温最高的两天
- 项目6:好友推荐案例(待2023年完成实验项目编写)
【注】选做项目内容调整说明:
• 原“手机销售统计项目”,我做过之后感觉不太符合大数据分布式计算思维,所以舍弃了,大家吃透项目5和理论课中对项目2、3的讲解就基本达标了;
• 另一个销售案例,限于课时(其实是被假期和xx周冲掉),将放在第三次作业中供大家练习;
• 好友推荐案例,根据当前大家能力和水平,决定放在明年下一届同学再使用,因为后续这门课会改为
48+16,本身实验课就是用来交流技术、讨论问题和验收试验的,手把手的教仅对大一大二同学管用。
4.实验内容【大致步骤】
项目1:分析和编写WordCount程序
建议直接跟着重建,节省很多麻烦,配合我这篇一起
参考链接
【参考链接】(梁老师博客)
https://blog.csdn.net/qq_42881421/article/details/83353640
参考注意
- a.配置主类:在</project>之前添加如下内容这里添的应该是在<\build>前添加
- 里面有这一行<!-- main()所在的类,注意修改 -->,它的下面那一行<mainClass>com.MyWordCount.WordCountMaincom.MyWordCount是你的mave工程,WordCountMain呢是后面用的,可以先自己取推荐就用这个WordCountMain
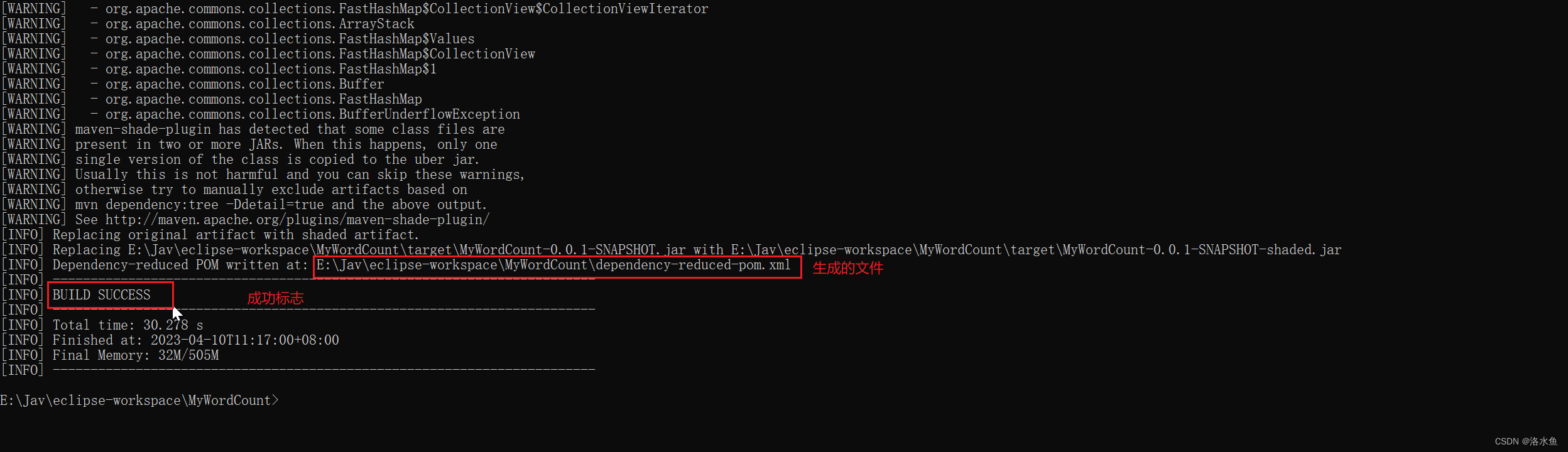
- 运行打包的文件


- 运行Ubuntul,winscp连接不了怎么解决?点击该链接,亲测有效
根据教程到达下面就已经完成了

操作步骤
• 配置eclipse的Maven(提前下载,需要时间,注意镜像配置和网络)
• 编写代码和解释代码
- WordCountMain.java(调用类,主函数所在)
package com.MyWordCount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountMain {
public static void main(String[] args) throws Exception {
//1.创建一个job和任务入口
Job job = Job.getInstance(new Configuration());
job.setJarByClass(WordCountMain.class); //main方法所在的class
//2.指定job的mapper和输出的类型<k2 v2>
job.setMapperClass(WordCountMapper.class);//指定Mapper类
job.setMapOutputKeyClass(Text.class); //k2的类型
job.setMapOutputValueClass(IntWritable.class); //v2的类型
//3.指定job的reducer和输出的类型<k4 v4>
job.setReducerClass(WordCountReducer.class);//指定Reducer类
job.setOutputKeyClass(Text.class); //k4的类型
job.setOutputValueClass(IntWritable.class); //v4的类型
//4.指定job的输入和输出
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//5.执行job
job.waitForCompletion(true);
}
}
- WordCountMapper.java (map类)
package com.MyWordCount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
// 泛型 k1 v1 k2 v2
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
@Override
protected void map(LongWritable key1, Text value1, Context context)
throws IOException, InterruptedException {
//数据: I like MapReduce
String data = value1.toString();
//分词:按空格来分词
String[] words = data.split(" ");
//输出 k2 v2
for(String w:words){
context.write(new Text(w), new IntWritable(1));
}
}
}
map()方法接收三个参数:
- key:表示输入数据的键,通常情况下是数据的偏移量或者行号,使用LongWritable类型表示。
- value:表示输入数据的值,通常情况下是一行文本或者一个数据块,使用Text类型表示。
- context:表示Mapper任务的上下文对象,提供了输出结果和进度更新等操作所需的接口,使用Context类型表示。
- 除了map()方法以外,Mapper类还提供了一些其他的方法,用于初始化、清理和配置Mapper任务等操作。这些方法包括setup()、cleanup()
throws IOException, InterruptedException这个的作用
在Java中,throws关键字用于声明一个方法可能抛出的异常,以便调用该方法的代码可以捕获并处理这些异常。在Hadoop MapReduce框架中,Mapper类的map()方法可能会抛出IOException和InterruptedException两种异常,因此在方法声明中需要使用throws关键字来声明这些异常。
- WordCountReducer.java (reduce类)
package com.MyWordCount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
// k3 v3 k4 v4
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text k3, Iterable<IntWritable> v3,Context context) throws IOException, InterruptedException {
//对v3求和
int total = 0;
for(IntWritable v:v3){
total += v.get();
}
//输出 k4 单词 v4 频率
context.write(k3, new IntWritable(total));
}
}
• Maven命令打包(jar包)
• 上传编译成功的jar包到Linux中
• 在Linux中打开hadoop服务,上传原始数据到HDFS(注意路径)
• 在Linux中执行MapReduce任务,并查看输出结果
【注】本项目先于理论/项目4讲解,且比较简单,所以请完成实验后认真思考每一行代码背后涉及的相关知识。
分析代码:
-
context.write的作用
- context.write()方法可以在Mapper阶段和Reducer阶段都使用。
在Mapper阶段,我们需要将Mapper处理得到的结果输出到磁盘上的某个文件中。具体来说,Mapper处理过程中,我们需要将输入文件中的每行数据转换成一组键值对,其中键表示单词,值表示单词在输入文件中出现的次数。这些键值对需要输出到磁盘上的某个文件中,供后续的Reducer阶段进行处理。
在Reducer阶段,我们需要将Reducer处理得到的结果输出到磁盘上的某个文件中。具体来说,Reducer需要将Mapper阶段输出的键值对按照键进行分组,并对每组中的值进行聚合。聚合结果需要输出到磁盘上的某个文件中,供后续的处理程序进行处理。
在Mapper和Reducer阶段都使用context.write()方法时,需要注意输出键值对的类型需要和相应的阶段输出键值对的类型匹配。在Mapper阶段,我们需要将键值对输出为<Text, IntWritable>类型,其中Text表示单词,IntWritable表示单词在输入文件中出现的次数。在Reducer阶段,我们需要将键值对输出为<Text, IntWritable>类型,其中Text表示单词,IntWritable表示单词在所有输入文件中出现的总次数。
- context.write()方法可以在Mapper阶段和Reducer阶段都使用。
-
MapReduce程序
- 在MapReduce程序中,Mapper的输出结果将被传递给Reducer进行进一步的处理。
- 具体来说,Mapper的输出结果会被分区、排序、合并和分组,然后按照键值对的键进行分组,每组调用一次Reducer的reduce()方法进行处理。
- 在这个例子中,MapReduce程序的处理流程如下:
读取输入文件,将文件的每一行数据传递给Mapper进行处理。
Mapper将输入数据分词,将每个单词以及它出现的次数输出为键值对的形式,传递给框架。
框架进行分区、排序、合并和分组等操作,将相同键的键值对分组到同一个Reducer任务中。
对于每个键值对组,框架调用一次Reducer的reduce()方法进行处理。
Reducer将相同键的所有值相加,输出每个单词以及它在输入文件中出现的总次数。
因此,在这个例子中,输出的结果将被MapReduce框架传递给Reducer进行处理,具体处理过程在Reducer的reduce()方法中完成。
-
Reducer程序
-
Reducer是MapReduce中的一个组件,用于对Mapper的输出结果进行进一步的处理。Reducer的作用是将具有相同键的键值对组合在一起,将它们的值合并为一个结果,最终输出一个键值对。Reducer的处理过程包括三个主要阶段:shuffle、排序和reduce。
-
Shuffle
在MapReduce程序中,Map任务的输出结果会被传递给Reducer进行进一步处理。在此之前,输出结果需要经过Shuffle操作。Shuffle的主要任务是将Mapper的输出结果根据键进行划分,并将相同键的结果发送给同一个Reducer。Shuffle过程包括以下几个步骤:- 分区:将Mapper的输出结果根据键进行分区,每个分区对应一个Reducer任务。
- 排序:在每个分区内,对键进行排序,确保相同键的值相邻。
- 合并:对于每个分区内相同的键,将它们的值合并成一个结果。
- 拷贝:将每个分区的数据拷贝到对应的Reducer节点上。
-
排序
在Reducer节点上,框架会对所有键值对按照键进行排序。排序的目的是将相同键的键值对放在一起,方便Reducer进行合并操作。 -
Reduce
Reducer的reduce()方法会接收所有相同键的键值对组成的迭代器,将它们的值进行合并,最终输出一个键值对。reduce()方法的参数包括:- 键:相同键的键值对的键。
- 值的迭代器:相同键的键值对的值组成的迭代器。
- 上下文对象:可以使用上下文对象将Reducer的输出结果输出到HDFS中。
-
在这个过程中,Reducer将相同键的所有值进行合并,得到键的总计数,最后将键和总计数组成一个键值对,输出到上下文对象中。Reducer的输出结果将被传递给MapReduce框架进行下一步处理,例如输出到HDFS或者传递给下一个Reducer。
-
-
WordCountMain.java程序
- Job对象
在Hadoop中,Job对象是表示一个MapReduce作业的主要对象。Job对象主要用于配置MapReduce作业的输入、输出、Mapper、Reducer等属性,启动MapReduce作业并监控其运行状态。 - .class
在Java中,.class是用于获取类类型的关键字 - job.getInstance()
Job.getInstance()是MapReduce作业中的一个静态方法,用于创建一个新的Job实例。在MapReduce中,Job表示一个完整的作业,包含了作业的所有配置信息和运行时状态。每个Job实例都与一个特定的作业相关联,可以通过该实例来对作业进行配置和控制。
使用Job.getInstance()方法可以创建一个新的Job实例,并将其返回。在创建Job实例时,需要传入一个Configuration对象作为参数,用于配置作业的各种参数。 - job.setJarByClass():
job.setJarByClass()是MapReduce作业中的一个配置方法,用于指定作业运行时所使用的jar包。在MapReduce中,所有的代码都需要打包成一个jar包,并且在运行作业时需要将该jar包上传到Hadoop集群中的某个节点上。因此,在编写MapReduce作业时,需要指定该作业所依赖的类所在的jar包。
job.setJarByClass()方法的作用就是根据指定类的类型信息自动搜索该类所在的jar包,并将其设置为作业运行时的jar包。 - Map阶段参数(Reduce阶段类似)
这几行代码是用来配置Map阶段的相关参数的。
.
job.setMapperClass(WordCountMapper.class)
指定Mapper类为WordCountMapper.class,表示我们要使用自定义的Mapper类来处理输入数据。Mapper类是MapReduce作业的核心组件之一,用于将输入数据转换为键值对形式。
.
job.setMapOutputKeyClass(Text.class)
设置Mapper输出的键的数据类型为Text.class。在WordCount例子中,Mapper输出的键就是单词,因此我们需要将其数据类型设置为Text.class。
.
job.setMapOutputValueClass(IntWritable.class)
设置Mapper输出的值的数据类型为IntWritable.class。在WordCount例子中,Mapper输出的值就是单词的计数值,因此我们需要将其数据类型设置为IntWritable.class。
.
这些配置参数是必需的,因为它们告诉MapReduce框架输入和输出的数据类型,并指定MapReduce作业的处理流程。
- Job对象
4.实验内容【大致步骤】
- 项目1:分析和编写WordCount程序 ==> 思考题1~4 都需要在实验报告中回答,思考题5、6选做,保命
【思考题1】在mapper中,单词每计数一次,就new一个IntWritable对象,这样做合适吗?为什么?
在Mapper中,每计数一次就new一个IntWritable对象是可以的,
因为在MapReduce中,每个Mapper和Reducer都是运行在一个独立的JVM进程中,
它们之间没有数据共享,也不会相互干扰。
因此,每次在Mapper中创建新的对象是安全的,不会对程序的正确性造成影响。
【思考题2】当前数据天然有空格(“ ”),自然就把计算元素分开了;那若没有类似的分隔符,我们应该怎么做呢?
如果没有类似分隔符,可以使用正则表达式来进行分词。
在Hadoop中,可以使用各种自定义分隔符或正则表达式来指定自定义分词规则。
可以在Mapper中使用Java的正则表达式库,对value值进行字符串拆分。
private final Pattern pattern = Pattern.compile(","); // 逗号分隔符正则表达式
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] fields = pattern.split(line); // 使用正则表达式分割字符串
// 对分割后的每个字段进行处理
for (String field : fields) {
// 处理逻辑
context.write(new Text(field), new IntWritable(1));
}
Hadoop中是否存在工具类可以处理此问题?甚至让用户根据需求个性化操作?还是说用户只能手动拆分?
Hadoop还提供了TextInputFormat类
它可以自动将输入文件按行读取,并将每行数据解析为Text类型的对象,方便后续处理。
如果需要进行更加自由的操作,用户也可以自定义InputFormat类和RecordReader类.
还没有试过
【思考题3】在reducer中,为何输入<k3,v3>中的v3是一个迭代器Iterable?什么是迭代器?在MR计算中它的作用是什么?
V3是Iterable是应为要处理Map阶段输出的相同键的多个值而设计的。
。
迭代器允许我们逐个遍历集合中的类型不同的元素,并在遍历过程中执行相应的操作。
。
在Map阶段,迭代器用于读取和处理输入数据。
Map函数通常需要处理大量的数据,由于内存和其他限制,不可能一次性将所有数据加载到内存中。
迭代器就允许Map函数逐个读取输入数据并进行处理。
迭代器提供了一种逐个访问输入数据的机制,使得Map函数能够有效地处理大规模数据集。
4.实验内容【大致步骤】
- 项目1:分析和编写WordCount程序 ==> 思考题1~4 都需要在实验报告中回答,思考题5、6选做,保命
【思考题4】观察两组输入输出的键值对类型
<LongWritable key1, Text value1> ==> <Text key2, IntWritable value2> (mapp( ))
<Text k3, Iterable v3> ==> <Text key4, IntWritable value4> (reduce( ))
为什么MR中要对这些类型进行封装?直接使用不好吗?
在MapReduce中对键值对进行封装的原因是为了提高框架的灵活性、可扩展性和通用性。而直接使用缺少灵活性
【思考题5】无论是map还是reduce,输出数据最后是如何同框架交互的?
在Map阶段中,Map函数输出的<k2, v2>键值对需要被收集器(Collector)收集,而收集器会将<k2, v2>转化为中间键值对<k3, v3>,然后按照k3的值进行排序并分组。最后,中间键值对<k3, v3>被传递到Reduce阶段。
在Reduce阶段中,Reducer接收到的输入数据为<k3, Iterable>,其中Iterable表示v3值的一个迭代器,即多个v2值聚合而成。Reducer的任务就是对同一键的v3值进行聚合并生成最终的<k4, v4>键值对。
最后,所有Reduce函数的输出都会被框架收集器收集,存储在指定的输出文件中。
【思考题6】仔细观察运行时控制台打印信息,在你的环境中有多少个map和reduce参与了计算?其中map()方法和reduce()方法又各自被调用了多少次?有什么依据?
4.实验内容【大致步骤】
项目2 :统计各部门员工薪水总和(序列化+部门分区+Combiner)
参考链接
【参考链接】 (梁老师博客)
https://blog.csdn.net/qq_42881421/article/details/84133800
参考注意
文章最后有代码的整个包导入就可。
- 配置原始cvs文件
- 编写代码
(1)Employee.java(序列化模型类) (4)SalaryTotalPartitioner (分区类)
(2)SalaryTotalMapper.java (mapper类) (5)SalaryTotalMain (程序运行主类)
(3) SalaryTotalReducer.java (reducer类) (6)在SalaryTotalMain 中添加Combiner用法 - Maven命令打包(jar包)
- 上传编译成功的jar包到Linux中(自己学习下文件传输工具)
- 在Linux中打开hadoop服务,上传原始数据文件到HDFS
- 在Linux中执行MapReduce任务,并查看输出结果
操作结果截图:

4.实验内容【大致步骤】
- 项目2 :统计各部门员工薪水总和(序列化+部门分区+Combiner) ==> 思考题7 和 思考题8都需要在实验报告中回答
【思考题7】Hadoop使用的是Java原生的序列化?如果是请说明理由;如果不是请说明原因,并指出Hadoop使用哪种方式做序列化?
Hadoop不使用Java原生的序列化。
Hadoop采用自己的序列化框架Writables。
Java原生的序列化机制存在一些性能和可移植性方面的限制
不适合在大规模数据处理环境中使用。
【思考题8】对于shuffle,MR框架分别对P值和key值做了排序,请问我们可以对这两个排序过程做更加精细的控制吗?即灵活地自定义排序规则?
在MapReduce框架中,对P值和Key值进行排序是为了确保相同Key的记录能够被发送到同一个Reducer进行处理。
对于P值排序,可以通过实现自定义的Partitioner类来控制。
对于Key值排序,可以通过实现自定义的Comparator类来控制。
MapReduce框架提供了默认的排序规则,也允许用户自定义排序规则。
自定义Partitioner和Comparator
可以通过调用setPartitionerClass()和setSortComparatorClass()方法
来指定自定义的Partitioner和Comparator。
项目3:统计全体员工工资水平(薪水分区)
【参考链接】 (梁老师博客)
https://blog.csdn.net/qq_42881421/article/details/84328787
参考注意
直接导入包而已,要注意的就注意Partitioner这个类而已
- 配置原始cvs文件
- 编写代码
(1)Employee.java(序列化模型类) (4)SalaryTotalPartitioner (分区类,相对项目2改写分区规则)
(2)SalaryTotalMapper.java (mapper类) (5)SalaryTotalMain (程序运行主类)
(3) SalaryTotalReducer.java (reducer类) - Maven命令打包(jar包)
- 上传编译成功的jar包到Linux中(自己学习下文件传输工具)
- 在Linux中打开hadoop服务,上传原始数据文件到HDFS
- 在Linux中执行MapReduce任务,并查看输出结果
项目3的结果:


开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)